爬虫数据清洗可视化实战-就业形势分析
基于采集和分析招聘网站的数据的芜湖就业形势的调查研究
一、引言
本报告旨在分析基于大数据的当地就业形势,并提供有关薪资、工作地点、经验要求、学历要求、公司行业、公司福利以及公司类型及规模的详细信息。该分析是通过网络爬虫技术对招聘网站的数据进行采集和分析而得出的。
本文部分内容来自网上搜集与个人实践。如果任何信息存在错误,欢迎读者批评指正。本文仅用于学习交流,不用作任何商业用途。
二、薪资范围分布分析
1. 薪资范围分布直方图
在薪资范围分布直方图中,我们对薪资范围的分布情况进行了分析。以下是主要结果:
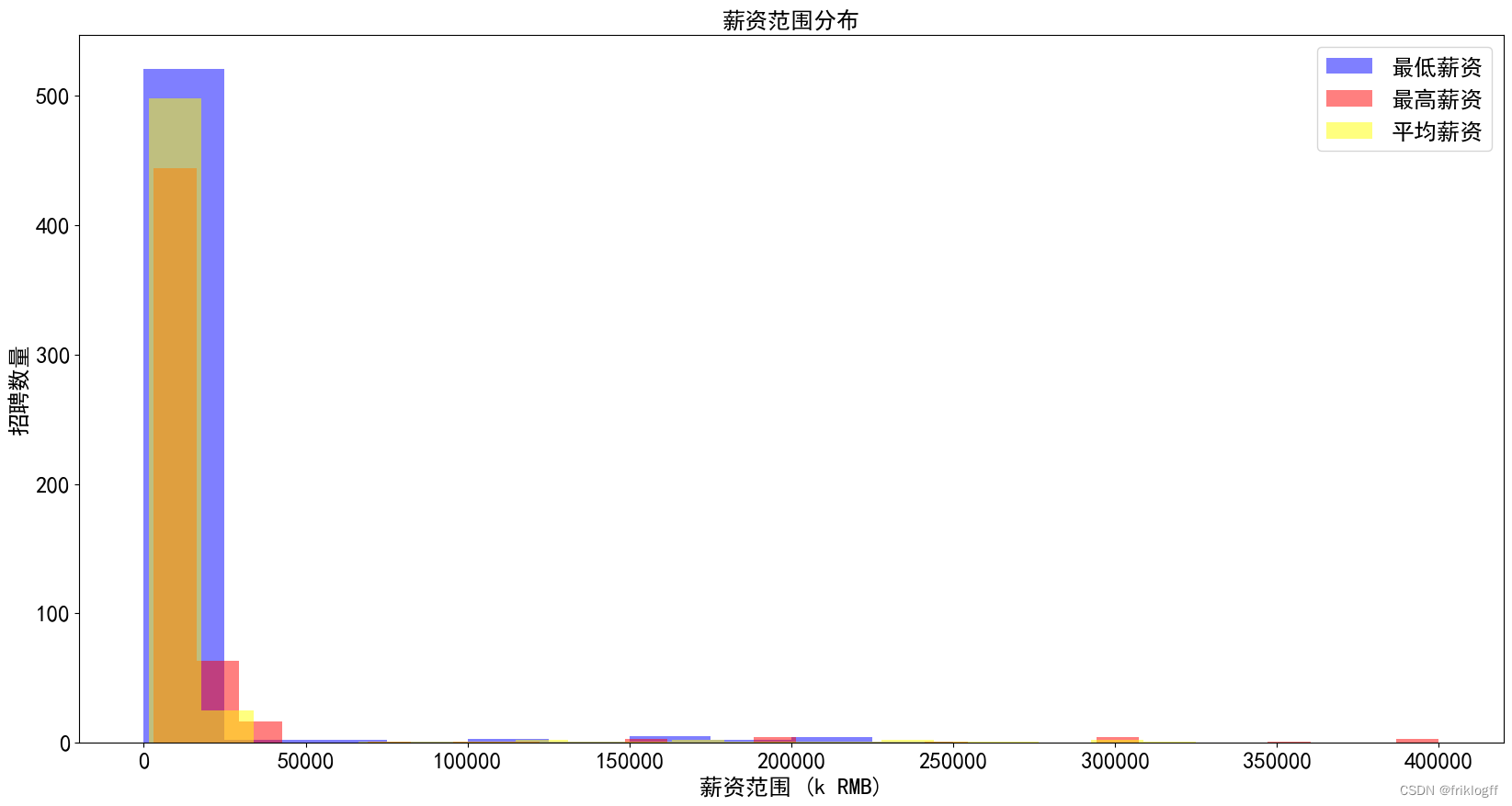
- 图表内容:包括最低薪资和最高薪资的直方图,以薪资范围为 x 轴,招聘数量为 y 轴,以不同颜色表示最低薪资和最高薪资。
- 本地数据存储:我们保存了薪资范围、最低薪资数量和最高薪资数量的文本文件
salary_distribution.txt,以及直方图图像文件salary_distribution.png。
根据提供的薪资范围和数量数据,我们可以分析出不同薪资范围的招聘情况。以下是对数据的分析:
-
分析:
- 最低薪资数量大部分集中在0.0-25000.0的范围内,共计521个职位。
- 最高薪资数量也主要分布在0.0-25000.0范围内,有444个职位。
- 平均薪资数量在不同薪资范围内有较大差异,最高的平均薪资数量在0.0-25000.0范围内,为498。
- 在其他薪资范围内,最低薪资数量、最高薪资数量和平均薪资数量相对较少。
-
结论:
- 大多数招聘职位的薪资范围集中在较低的区间(0.0-25000.0),这可能是大多数职位的薪资水平。
- 在更高薪资范围内的职位数量较少,但平均薪资水平可能更高。
- 从薪资范围的分布情况来看,职位的薪资差异较大,求职者需要根据自身情况和期望进行选择。
这个分析可以帮助求职者了解不同薪资范围内的招聘情况,有助于他们做出更明智的职业决策。
三、工作地点分析
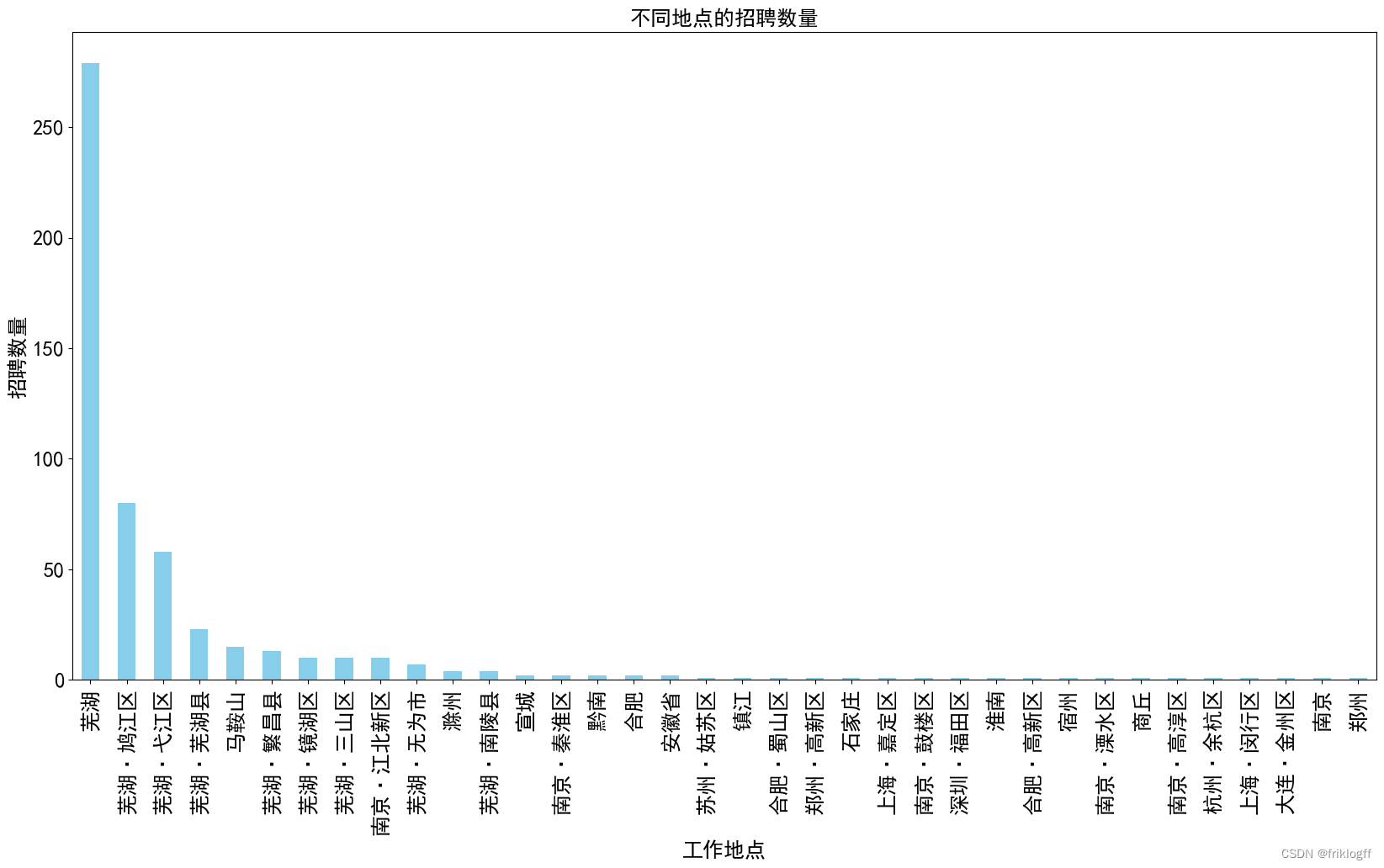
2. 不同地点的招聘数量柱状图
我们分析了不同工作地点的招聘数量情况。以下是主要结果:
-
图表内容:柱状图展示了不同工作地点的招聘数量,x 轴表示工作地点,y 轴表示招聘数量。
-
本地数据存储:我们保存了地点和对应招聘数量的文本文件
location_counts.txt,以及柱状图图像文件location_counts.png。 -
分析:
- 芜湖是最活跃的招聘地点,共有279个招聘职位。
- 芜湖的各个区域也有一定数量的招聘职位,包括芜湖·鸠江区(80个职位)、芜湖·弋江区(58个职位)、芜湖·芜湖县(23个职位)、芜湖·繁昌县(13个职位)、芜湖·镜湖区(10个职位)和芜湖·三山区(10个职位)。
- 南京·江北新区、芜湖·无为市、滁州、芜湖·南陵县等地也有一些招聘职位,但数量较少。
- 其他城市和地区,如马鞍山、宣城、黔南、合肥、安徽省、苏州·姑苏区、镇江、合肥·蜀山区、郑州·高新区、石家庄、上海·嘉定区、南京·鼓楼区、深圳·福田区、淮南、合肥·高新区、宿州、南京·溧水区、商丘、南京·高淳区、杭州·余杭区、上海·闵行区、大连·金州区、南京和郑州等地的招聘数量相对较少,每个地点只有1或2个职位。
-
结论:
- 芜湖是招聘活动最为集中的地点,有着最多的招聘职位。
- 除芜湖外,南京的江北新区也有一定数量的招聘职位。
- 对于求职者来说,了解不同地点的招聘情况有助于选择适合自己的工作地点,以及更好地规划求职策略。
3. 不同地点的平均薪资柱状图
我们进一步分析了不同工作地点的平均薪资情况。以下是主要结果:

-
图表内容:柱状图展示了不同工作地点的平均薪资,x 轴表示工作地点,y 轴表示平均薪资。
-
本地数据存储:我们保存了工作地点和对应平均薪资的文本文件
avg_salary_by_location.txt,以及柱状图图像文件avg_salary_by_location.png。 -
分析:
- 郑州·高新区的平均薪资最高,为150,000.0元。
- 滁州、合肥、黔南和安徽省的平均薪资也在较高水平,分别为119,750.0元、82,500.0元、79,000.0元和53,000.0元。
- 芜湖、南京、杭州、石家庄等地的平均薪资相对较低,不超过15,000.0元。
- 其他地点的平均薪资也有所不同,显示了不同地区的薪资差异。
-
结论:
- 工作地点对于平均薪资有显著影响,一些地区的平均薪资明显高于其他地区。
- 郑州·高新区、滁州、合肥等地的平均薪资较高,可能反映了这些地区的经济发展水平和就业机会较多。
- 薪资水平相对较低的地区可能需要考虑其他因素,如生活成本和就业机会。
这个分析可以帮助求职者了解不同地点的平均薪资情况,有助于他们在选择工作地点时做出更明智的决策。
四、经验和学历要求分析
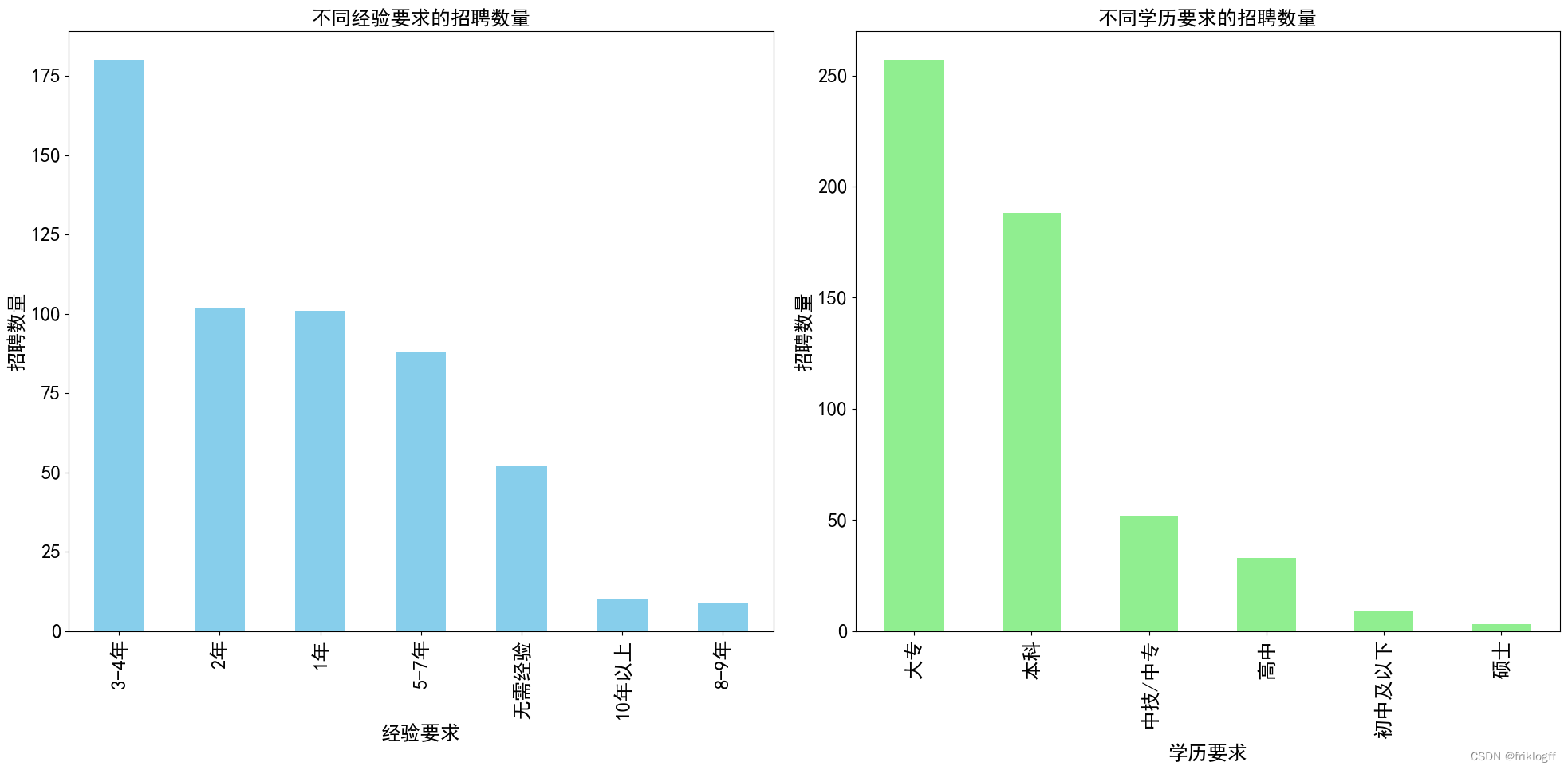
4. 不同经验要求和学历要求的招聘数量柱状图
我们分析了不同经验要求和学历要求的招聘数量情况。以下是主要结果:
-
图表内容:包括两个子图,左侧子图展示不同经验要求的招聘数量,右侧子图展示不同学历要求的招聘数量。
-
本地数据存储:我们保存了经验要求和对应招聘数量、学历要求和对应招聘数量的文本文件
experience_education_counts.txt,以及柱状图图像文件experience_education_counts.png。 -
经验要求分析:
- 最常见的经验要求是3-4年,共有180个职位要求此经验。
- 其次是2年经验,有102个职位。
- 1年经验和5-7年经验的职位数量相近,分别为101和88个职位。
- 无需经验的职位也有一定数量,为52个职位。
- 对于更高级别的经验要求,10年以上和8-9年的职位数量相对较少,分别为10和9个职位。
-
学历要求分析:
- 最常见的学历要求是大专,共有257个职位要求此学历。
- 本科学历要求的职位数量也相对较多,为188个职位。
- 中技/中专、高中和初中及以下学历要求的职位数量依次减少,分别为52、33和9个职位。
- 硕士学历要求的职位数量最少,仅有3个职位。
-
结论:
- 大多数职位对于经验要求集中在1-4年范围内,以及无需经验。
- 学历要求方面,大专和本科是最常见的学历要求,占据了绝大多数职位。
- 对于求职者来说,了解不同经验和学历要求的职位分布有助于更好地匹配自己的背景和目标,以寻找适合的工作机会。
五、公司信息分析
5. 不同公司行业的招聘数量柱状图
我们分析了不同公司行业的招聘数量情况。以下是主要结果:

-
图表内容:柱状图展示了不同公司行业的招聘数量,x 轴表示公司行业,y 轴表示招聘数量。
-
本地数据存储:我们保存了公司行业和对应招聘数量的文本文件
industry_counts.txt,以及柱状图图像文件industry_counts.png。 -
分析:
- 汽车行业
是招聘数量最多的行业,拥有142个职位。 - 新能源和电子技术/半导体/集成电路行业分别拥有59和56个职位,排名第二和第三。
- 机械/设备/重工、汽车零配件、计算机软件等行业也有一定数量的职位,分别为46、39和28个。
- 金融/投资/证券、多元化业务集团公司、环保、仪器仪表/工业自动化等行业的招聘数量相对较少,都在10个以下。
- 汽车行业
-
结论:
- 不同公司行业的招聘情况差异较大,一些行业拥有大量的职位,而其他行业则拥有相对较少的职位。
- 汽车行业、新能源和电子技术/半导体/集成电路行业可能是求职者关注的热门行业,因为它们有较多的职位机会。
- 需要注意的是,金融/投资/证券、多元化业务集团公司等行业的招聘数量相对较少,可能竞争较激烈。
这个分析可以帮助求职者了解不同公司行业的招聘情况,有助于他们根据自己的兴趣和专业选择适合的行业和职位。
6. 不同公司行业的平均薪资柱状图
我们进一步分析了不同公司行业的平均薪资情况。以下是主要结果:

-
图表内容:柱状图展示了不同公司行业的平均薪资,x 轴表示公司行业,y 轴表示平均薪资。
-
本地数据存储:我们保存了公司行业和对应平均薪资的文本文件
avg_salary_by_industry.txt,以及柱状图图像文件avg_salary_by_industry.png。 -
分析:
- 医疗/护理/卫生行业拥有最高的平均薪资,达到116,000元。这可能是因为医疗行业对专业人员有较高的薪资标准。
- 电子技术/半导体/集成电路行业和计算机软件行业的平均薪资也相对较高,分别为24,696元和19,071元。
- 金融/投资/证券行业的平均薪资为47,857元,属于高薪行业之一。
- 汽车、快速消费品(食品、饮料、化妆品)、汽车零配件、建筑/建材/工程等行业的平均薪资也较高,都在10,000元以上。
- 一些行业如广告、生活服务、中介服务等平均薪资较低,都在10,000元以下。
-
结论:
- 不同公司行业的平均薪资差异很大,一些行业的平均薪资相对较高,而其他行业则平均薪资较低。
- 求职者可以根据自己的职业目标和薪资期望选择适合的行业和公司。
- 需要注意的是,平均薪资只是一个参考指标,实际薪资还会受到个人经验、职位级别、地区等多种因素的影响。
这个分析有助于求职者了解不同行业的薪资水平,以便做出更明智的职业选择。
六、公司福利和类型规模分析
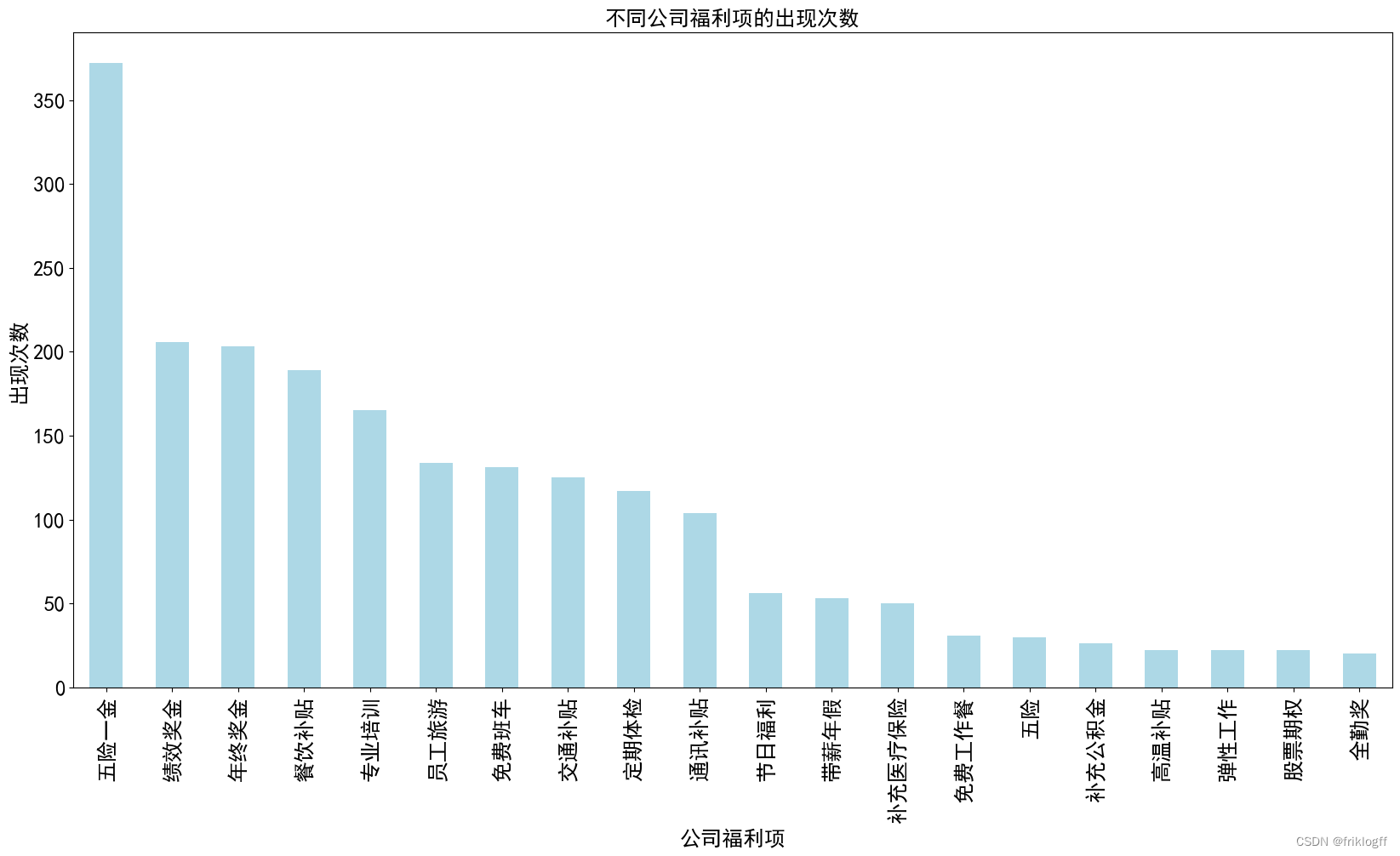
7. 公司福利项出现次数柱状图
我们分析了不同公司福利项的出现次数情况。以下是主要结果:
-
图表内容:柱状图展示了不同公司福利项的出现次数,x 轴表示公司福利项,y 轴表示出现次数。
-
本地数据存储:我们保存了公司福利项和对应出现次数的文本文件
welfare_counts.txt,以及柱状图图像文件welfare_counts.png。 -
分析:
-
从柱状图中,你可以看到"五险一金"是最受欢迎的公司福利项,出现次数最多,表明公司普遍提供这项福利以满足员工的基本社会保障需求。
-
"绩效奖金"和"年终奖金"紧随其后,这表明公司也非常重视员工的绩效评估和激励措施。
-
一些其他福利项,如"员工旅游"和"免费班车",出现次数相对较低,但仍然受到一定关注。
-
"免费员工餐"和"包吃包住"等福利项的出现次数较少,可能只有少数公司提供。
-
常见福利项:出现次数最多的公司福利项是"五险一金",出现了372次,这表明这是大多数公司都提供的标准福利。其他常见福利项包括"绩效奖金"、“年终奖金”、“餐饮补贴"和"专业培训”。
-
标配福利:除了"五险一金"外,“员工旅游”、“免费班车”、“交通补贴”、“定期体检”、"通讯补贴"等福利项也被多家公司采用,这些福利通常是吸引员工和提高员工满意度的常见选择。
-
行业相关福利:某些福利项可能与公司所属行业有关,例如"汽车行业"和"汽车零部件"相关的福利项,包括"汽车"、“出厂检验报告"和"车补”。
-
个性化福利:还有一些公司可能提供一些较为个性化的福利,如"中医平台推广"、“口吃矫正”、"深度学习"等,这些福利可能根据公司的特殊需求或员工的特殊要求而设定。
-
-
结论:
- 福利改进:通过分析这些福利项,您可以了解到其他公司提供的福利,有助于您了解市场竞争和吸引员工的策略。您可以根据这些信息来考虑是否需要改进或新增公司的福利政策,以更好地吸引和留住人才。
- 这些分析可以帮助你了解不同公司在福利方面的偏好,以及哪些福利项可能对员工招聘和保留产生积极影响。当然,具体的福利选择还可能受到公司规模、行业、地理位置等因素的影响。
8. 不同公司类型及规模的招聘数量柱状图
我们分析了不同公司类型及规模的招聘数量情况。以下是主要结果:
-
图表内容:柱状图展示了不同公司类型及规模的招聘数量,x 轴表示公司类型及规模,y 轴表示招聘数量。
-
本地数据存储:我们保存了公司类型及规模和对应招聘数量的文本文件
company_type_and_size_counts.txt,以及柱状图图像文件company_type_and_size_counts.png。

-
分析:
- 民营公司在不同规模下都有较多的招聘需求,其中民营公司规模在150-500人之间的需求最高,为102个职位。
- 其次是500-1000人规模的民营公司,招聘数量为66个职位。
- 国企中,规模在10000人以上的需求较高,有26个职位。
- 合资公司的需求也相对均衡,500-1000人规模的公司需求最多,为22个职位。
- 有一些公司没有具体规模标识,招聘数量为16个职位,可能是小型的创业公司或者其他类型的公司。
- 外资公司在不同规模下的需求相对较少,多数集中在150-500人规模的公司,有16个职位。
- 已上市的公司需求较为有限,多数集中在10000人以上和500-1000人规模的公司。
-
结论:
- 民营公司和国企是招聘需求较高的公司类型,尤其是规模在150-500人之间的民营公司。
- 合资公司和外资公司的需求相对较少,主要集中在500-1000人和150-500人规模的公司。
- 已上市公司的招聘需求相对较低,多数分布在较大规模的公司中。
- 招聘者可以根据公司类型和规模的分布情况来更好地选择适合自己的职位和公司。
这个分析有助于求职者了解不同公司类型和规模下的招聘情况,以便做出更明智的职业决策。
七、关键词分析
9. 公司行业词云图
我们生成了公司行业的词云图,以展示公司行业的关键词。以下是主要结果:

-
图表内容:词云图展示了不同公司行业的关键词,以词语频率为基础生成,文字颜色随机。
-
本地数据存储:我们保存了公司行业文本数据到本地文件
industry_wordcloud.txt,以及词云图像文件industry_wordcloud.png。 -
分析:
- 词云图中显示了不同行业的关键词,其中最常出现的词语包括"汽车"、“电子”、“技术”、“新能源”、"医疗"等。
- "汽车"是出现频率最高的词语,表明汽车行业在招聘市场上占据重要地位。
- "电子"和"技术"也是热门行业关键词,说明这两个行业也有较多的招聘机会。
-
结论:
- 从词云图中可以看出,汽车、电子、技术等行业是当前招聘市场的热门领域,求职者可以关注这些行业的职业机会。
- 词云图提供了对公司行业数据的可视化呈现,有助于直观地了解不同行业的招聘情况。
10. 公司福利词云图
我们还生成了公司福利的词云图,以展示公司福利的关键词。以下是主要结果:

-
图表内容:词云图展示了不同公司福利的关键词,以词语频率为基础生成,文字颜色随机。
-
本地数据存储:我们保存了公司福利文本数据到本地文件
welfare_wordcloud.txt,以及词云图像文件welfare_wordcloud.png。
以下是根据福利文本数据生成的词云图和分析: -
分析:
- 词云图中显示了不同公司提供的福利待遇,其中最常出现的福利包括"五险一金"、“年终奖金”、“餐饮补贴”、“通讯补贴”、"员工旅游"等。
- "五险一金"是出现频率最高的福利之一,表明大多数公司提供这一基本的社保福利。
- "年终奖金"也是一个常见的福利,可能吸引了求职者的关注。
- 餐饮补贴、通讯补贴等福利也受到一定程度的关注,这些福利有助于提高员工的生活质量。
-
结论:
- 从词云图中可以看出,五险一金、年终奖金、餐饮补贴等福利是吸引求职者的亮点,公司在招聘时可以重点突出这些福利待遇。
- 词云图提供了对公司福利数据的可视化呈现,有助于求职者了解不同公司的福利待遇。
八、总结与展望
通过对招聘数据的多维度分析和可视化呈现,我们得出了关于当地就业形势的一系列重要信息。这些信息不仅有助于学生了解就业市场的趋势,还可以为学校和社会提供有关就业形势的重要参考。
未来,我们可以进一步扩展和改进这项调研工作,包括更多数据源的采集、深入的数据分析方法以及更准确的预测模型的建立,以帮助更多人做出明智的职业选择。
九、致谢
感谢你的关注和阅读,希望这份报告对你的职业生涯规划有所帮助。如果有任何问题或需要进一步的咨询,请随时与我们联系。
这份报告代表了我们对就业形势的深入研究,希望这些分析结果对大家有所帮助。
十、相关代码
11. 数据收集代码
# -*- coding = utf-8 -*-
import csv
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Optionsoption = Options()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--disable-blink-features=AutomationControlled')driver = webdriver.Chrome(options=option)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
headers = ['职位名称', '薪资范围', '工作地点', '经验要求', '学历要求', '公司名称', '公司类型及规模','公司行业', '公司福利']jobs_list = []
count = 1
error_time = 0
try:driver.get("https://we.51job.com/pc/search?jobArea=150300&keyword=&searchType=2&sortType=0&metro=")driver.implicitly_wait(10)for j in range(1, 30):for i in range(1, 21):try:job = driver.find_element(By.CSS_SELECTOR, f'div.j_joblist > div:nth-child({i})')# print(job.get_attribute('innerHTML'))job_name = job.find_element(By.CSS_SELECTOR, '.el > div > span').textsalary = job.find_element(By.CSS_SELECTOR, '.el > p.info > span.sal').textlocation = job.find_element(By.CSS_SELECTOR, '.el > p.info > span.d.at > span:nth-child(1)').textexp = job.find_element(By.CSS_SELECTOR, '.el > p.info > span.d.at > span:nth-child(3)').textedu = job.find_element(By.CSS_SELECTOR, '.el > p.info > span.d.at > span:nth-child(5)').textcompany = job.find_element(By.CSS_SELECTOR, '.er > a').textcompany_type_scale = job.find_element(By.CSS_SELECTOR, '.er > p.dc.at').textindustry = job.find_element(By.CSS_SELECTOR, '.er > p.int.at').texttry:tag = job.find_element(By.CSS_SELECTOR, '.el > p.tags').textexcept:tag = ''except:print("error:" + str(i))error_time += 1if error_time >= 3:input("网络可能断开,输入任意值继续")error_time = 0continuejob_item = {'职位名称': job_name,'薪资范围': salary,'工作地点': location,'经验要求': exp,'学历要求': edu,'公司名称': company,'公司类型及规模': company_type_scale,'公司行业': industry,'公司福利': tag}jobs_list.append(job_item)# 随机等待1-5秒,防止被识别time.sleep(random.randint(2, 6))print(j,i)error_time = 0driver.find_element(By.CSS_SELECTOR,f'div.bottom-page > div > div > div> button.btn-next').click()time.sleep(random.randint(2, 6))
except Exception as e:print("Error:", e)input("网络可能断开,输入任意值继续")finally:with open('51job.csv', 'w', newline='', encoding='utf-8-sig') as f:writer = csv.writer(f)writer.writerow(headers)for job_item in jobs_list:row = list(job_item.values())writer.writerow(row)driver.quit()12.数据清洗与分析代码
from collections import Counter
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import jieba
from wordcloud import WordCloud
import re
# 设置中文字体
font = FontProperties(fname="C:/Windows/Fonts/simhei.ttf", size=12)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 读取CSV文件
df = pd.read_csv('51job.csv')
# 定义提取薪资函数
def extract_salary(s):pattern1 = '([0-9]+\.?[0-9]*)千-([0-9]+\.?[0-9]*)万·([0-9]+\.?[0-9]*)薪'pattern2 = '([0-9]+\.?[0-9]*)-([0-9]+\.?[0-9]*)千'pattern3 = '([0-9]+\.?[0-9]*)千-([0-9]+\.?[0-9]*)万'pattern4 = '([0-9]+\.?[0-9]*)-([0-9]+\.?[0-9]*)千·([0-9]+\.?[0-9]*)薪'pattern5 = '([0-9]+\.?[0-9]*)-([0-9]+\.?[0-9]*)万'pattern6 = '([0-9]+\.?[0-9]*)-([0-9]+\.?[0-9]*)万·([0-9]+\.?[0-9]*)薪'pattern7 = '([0-9]+)元/天'match1 = re.search(pattern1, s)match2 = re.search(pattern2, s)match3 = re.search(pattern3, s)match4 = re.search(pattern4, s)match5 = re.search(pattern5, s)match6 = re.search(pattern6, s)match7 = re.search(pattern7, s)if match1:low, high, extra = match1.groups()low, high, extra = float(low), float(high), float(extra)return low * 1000, high * 10000, extraelif match2:low, high = match2.groups()low, high = float(low), float(high)return low * 1000, high * 1000elif match3:low, high = match3.groups()low, high = float(low), float(high)return low * 1000, high * 10000elif match4:low, high, extra = match4.groups()low, high, extra = float(low), float(high), float(extra)return low * 1000, high * 1000, extraelif match5:low, high = match5.groups()low, high = float(low), float(high)return low * 10000, high * 10000elif match6:low, high, extra = match6.groups()low, high, extra = float(low), float(high), float(extra)return low * 10000, high * 10000, extraelif match7:day = float(match7.group(1))return dayelse:print(s)return None# 计算平均薪资
try:df['最低薪资'] = df['薪资范围'].apply(lambda x: extract_salary(x)[0])df['最高薪资'] = df['薪资范围'].apply(lambda x: extract_salary(x)[1])df['平均薪资'] = (df['最低薪资'].astype(float) + df['最高薪资'].astype(float)) / 2
except:df['日结'] = df['薪资范围'].apply(lambda x: extract_salary(x)[0])df['平均薪资'] = df['日结'] * 30try:df['加成'] = df['薪资范围'].apply(lambda x: extract_salary(x)[2])df['平均薪资'] += df['加成'] * ((df['最低薪资'].astype(float) + df['最高薪资'].astype(float)) / 2) / 12
except:print('无加成')
# 1. 薪资范围分布直方图
plt.figure(figsize=(20, 10))
hist_low = plt.hist(df['最低薪资'], bins=10, alpha=0.5, color='blue', label='最低薪资')
hist_high = plt.hist(df['最高薪资'], bins=30, alpha=0.5, color='red', label='最高薪资')
hist_ave = plt.hist(df['平均薪资'], bins=20, alpha=0.5, color='yellow', label='平均薪资')
plt.xlabel('薪资范围 (k RMB)')
plt.ylabel('招聘数量')
plt.legend()
plt.title('薪资范围分布')# 添加数据标签和保存数据到文本文件
with open('salary_distribution.txt', 'w', encoding='utf-8') as file:# 写入列名file.write('薪资范围\t最低薪资数量\t最高薪资数量\t平均薪资数量\n')# 遍历直方图的每个x轴区间for i in range(len(hist_low[0])):# 构造该区间的字符串bin_str = f'{hist_low[1][i]}-{hist_low[1][i + 1]}'# 获取该区间对应的最低薪资频数low_count = int(hist_low[0][i])# 获取该区间对应的最高薪资频数high_count = int(hist_high[0][i])# 获取该区间对应的平均薪资频数ave_count = int(hist_ave[0][i])# 拼接并写入行数据file.write(f'{bin_str}\t{low_count}\t{high_count}\t{ave_count}\n')
plt.savefig('salary_distribution.png')
# 显示图表
plt.show()# 2. 不同地点的招聘数量柱状图
location_counts = df['工作地点'].value_counts()
# 绘制柱状图
plt.figure(figsize=(20, 10))
location_counts.plot(kind='bar', color='skyblue')
# 设置中文标签
plt.xlabel('工作地点', fontproperties=font)
plt.ylabel('招聘数量', fontproperties=font)
plt.title('不同地点的招聘数量', fontproperties=font)
plt.xticks(rotation=90)
# 添加数据标签和保存数据到文本文件
with open('location_counts.txt', 'w', encoding='utf-8') as file:file.write('地点\t招聘数量\n')for location, count in location_counts.items():file.write(f'{location}\t{count}\n')
plt.savefig('location_counts.png')
# 显示图表
plt.show()# 3. 不同地点的平均薪资柱状图
avg_salary_by_location = df.groupby('工作地点')['最低薪资'].mean()
# 可以选择展示前几个地点的数据
top_avg_salary_by_location = avg_salary_by_location.sort_values(ascending=False)
# 绘制柱状图
plt.figure(figsize=(20, 10))
top_avg_salary_by_location.plot(kind='bar', color='lightgreen')
# 设置中文标签
plt.xlabel('工作地点', fontproperties=font)
plt.ylabel('平均薪资 (k RMB)', fontproperties=font)
plt.title('不同地点的平均薪资', fontproperties=font)
plt.xticks(rotation=90)
# 添加数据标签和保存数据到文本文件
with open('avg_salary_by_location.txt', 'w', encoding='utf-8') as file:file.write('工作地点\t平均薪资\n')for location, avg_salary in top_avg_salary_by_location.items():file.write(f'{location}\t{avg_salary}\n')
plt.savefig('avg_salary_by_location.png')
# 显示图表
plt.show()# 4. 不同经验要求和学历要求的招聘数量柱状图
# 统计不同经验要求的招聘数量
exp_counts = df['经验要求'].value_counts()
# 统计不同学历要求的招聘数量
edu_counts = df['学历要求'].value_counts()
# 可视化经验要求的招聘数量
plt.figure(figsize=(20, 10))
plt.subplot(1, 2, 1)
exp_counts.plot(kind='bar', color='skyblue')
plt.xlabel('经验要求', fontproperties=font)
plt.ylabel('招聘数量', fontproperties=font)
plt.title('不同经验要求的招聘数量', fontproperties=font)
# 可视化学历要求的招聘数量
plt.subplot(1, 2, 2)
edu_counts.plot(kind='bar', color='lightgreen')
plt.xlabel('学历要求', fontproperties=font)
plt.ylabel('招聘数量', fontproperties=font)
plt.title('不同学历要求的招聘数量', fontproperties=font)
plt.tight_layout()
# 添加数据标签和保存数据到文本文件
with open('experience_education_counts.txt', 'w', encoding='utf-8') as file:file.write('经验要求\t招聘数量\n')for experience, count in exp_counts.items():file.write(f'{experience}\t{count}\n')file.write('学历要求\t招聘数量\n')for education, count in edu_counts.items():file.write(f'{education}\t{count}\n')
plt.savefig('experience_education_counts.png')
# 显示图表
plt.show()# 5. 不同公司行业的招聘数量柱状图
# 统计不同公司行业的招聘数量
industry_counts = df['公司行业'].value_counts()# 可视化不同公司行业的招聘数量
plt.figure(figsize=(20, 10))
industry_counts.plot(kind='bar', color='skyblue')
plt.xlabel('公司行业', fontproperties=font)
plt.ylabel('招聘数量', fontproperties=font)
plt.title('不同公司行业的招聘数量', fontproperties=font)
plt.xticks(rotation=90)# 添加数据标签和保存数据到文本文件
with open('industry_counts.txt', 'w', encoding='utf-8') as file:file.write('公司行业\t招聘数量\n')for industry, count in industry_counts.items():file.write(f'{industry}\t{count}\n')
plt.savefig('industry_counts.png')
# 显示图表
plt.show()# 6. 不同公司行业的平均薪资柱状图
# 计算不同公司行业的平均薪资水平
avg_salary_by_industry = df.groupby('公司行业')['平均薪资'].mean()
# 可视化不同公司行业的平均薪资水平
plt.figure(figsize=(20, 10))
avg_salary_by_industry.plot(kind='bar', color='lightgreen')
plt.xlabel('公司行业', fontproperties=font)
plt.ylabel('平均薪资 (k RMB)', fontproperties=font)
plt.title('不同公司行业的平均薪资', fontproperties=font)
plt.xticks(rotation=90)
# 添加数据标签和保存数据到文本文件
with open('avg_salary_by_industry.txt', 'w', encoding='utf-8') as file:file.write('公司行业\t平均薪资\n')for industry, avg_salary in avg_salary_by_industry.items():file.write(f'{industry}\t{avg_salary}\n')
plt.savefig('avg_salary_by_industry.png')
# 显示图表
plt.show()# 7. 公司福利项出现次数柱状图
# 统计不同公司福利的出现次数
def extract_welfare(welfare_str):if isinstance(welfare_str, str):return welfare_str.split('\n')else:return []# 将福利信息分割成列表
df['公司福利'] = df['公司福利'].apply(extract_welfare)
# 统计不同福利项的出现次数
welfare_counts = df['公司福利'].explode().str.strip().value_counts()
# 处理没有福利信息的公司
if '' in welfare_counts:no_welfare_count = welfare_counts['']welfare_counts = welfare_counts.drop('')welfare_counts['无福利'] = no_welfare_count
# 可视化不同福利项的出现次数
plt.figure(figsize=(20, 10))
welfare_counts.nlargest(20).plot(kind='bar', color='lightblue')
plt.xlabel('公司福利项', fontproperties=font)
plt.ylabel('出现次数', fontproperties=font)
plt.title('不同公司福利项的出现次数', fontproperties=font)
plt.xticks(rotation=90)
# 添加数据标签和保存数据到文本文件
with open('welfare_counts.txt', 'w', encoding='utf-8') as file:file.write('公司福利项\t出现次数\n')for welfare, count in welfare_counts.items():file.write(f'{welfare}\t{count}\n')
plt.savefig('welfare_counts.png')
# 显示图表
plt.show()# 8. 不同公司类型及规模的招聘数量柱状图
# 统计不同公司类型及规模的招聘数量
company_type_and_size_counts = df['公司类型及规模'].value_counts()
# 可视化不同公司类型及规模的招聘数量
plt.figure(figsize=(20, 10))
company_type_and_size_counts.plot(kind='bar', color='skyblue')
plt.xlabel('公司类型及规模', fontproperties=font)
plt.ylabel('招聘数量', fontproperties=font)
plt.title('不同公司类型及规模的招聘数量', fontproperties=font)
plt.xticks(rotation=90)
# 添加数据标签和保存数据到文本文件
with open('company_type_and_size_counts.txt', 'w', encoding='utf-8') as file:file.write('公司类型及规模\t招聘数量\n')for company_type, count in company_type_and_size_counts.items():file.write(f'{company_type}\t{count}\n')
plt.savefig('company_type_and_size_counts.png')
# 显示图表
plt.show()# 9. 公司行业词云图
# 合并公司行业文本
industry_text = ' '.join(df['公司行业'].dropna())
# 使用jieba分词
seg_list = jieba.cut(industry_text)
# 创建词云
wordcloud = WordCloud(width=800, height=400, background_color='white',font_path='C:/Windows/Fonts/simhei.ttf').generate(' '.join(seg_list))
# 可视化词云
plt.figure(figsize=(20, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('公司行业词云', fontproperties=font)
# 将公司行业词频信息保存到本地文件
industry_words = list(jieba.cut(industry_text))
industry_word_counts = Counter(industry_words)
with open('industry_wordcloud.txt', 'w', encoding='utf-8') as file:for word, count in industry_word_counts.items():file.write(f'{word}: {count}\n')
# 保存词云图像
wordcloud.to_file('industry_wordcloud.png')
# 显示词云图像
plt.show()# 10. 公司福利词云图
# 合并公司福利文本
welfare_text = ' '.join(df['公司福利'].explode().dropna())
# 使用jieba分词
seg_list = jieba.cut(welfare_text)
# 创建词云
wordcloud = WordCloud(width=800, height=400, background_color='white',font_path='C:/Windows/Fonts/simhei.ttf').generate(' '.join(seg_list))
# 可视化词云
plt.figure(figsize=(20, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('公司福利词云', fontproperties=font)
# 保存词云图像
wordcloud.to_file('welfare_wordcloud.png')
# 将公司福利文本数据保存到本地文件
welfare_words = list(jieba.cut(welfare_text))
welfare_word_counts = Counter(welfare_words)
with open('welfare_wordcloud.txt', 'w', encoding='utf-8') as file:for word, count in welfare_word_counts.items():file.write(f'{word}: {count}\n')
# 显示词云图像
plt.show()
相关文章:
爬虫数据清洗可视化实战-就业形势分析
基于采集和分析招聘网站的数据的芜湖就业形势的调查研究 一、引言 本报告旨在分析基于大数据的当地就业形势,并提供有关薪资、工作地点、经验要求、学历要求、公司行业、公司福利以及公司类型及规模的详细信息。该分析是通过网络爬虫技术对招聘网站的数据进行采集…...
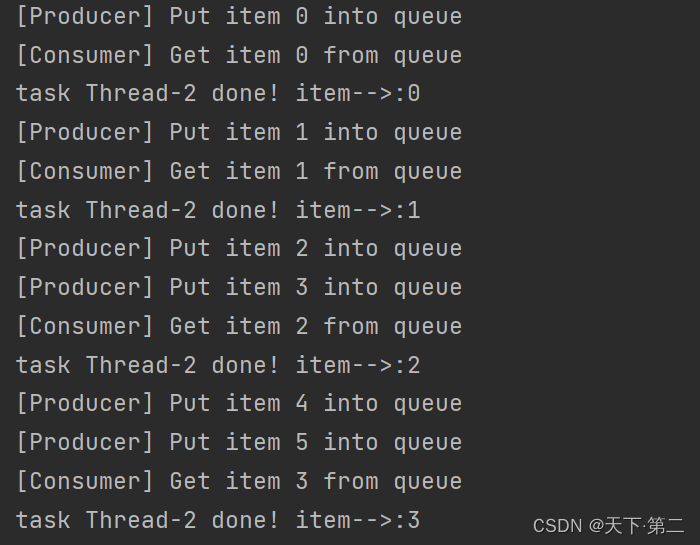
Python - 队列【queue】task_done()和join()基本使用
一. 前言 task_done()是Python中queue模块提供的方法,用于通知队列管理器,已经处理完了队列中的一个项目。 queue.task_done()是Queue对象的一个方法,它用于通知Queue对象,队列中的某一项已经被处理完毕。通常在使用Queue对象时…...

springboot web 增加不存在的url返回200状态码 vue 打包设置
spring boot项目增加 html web页面访问 1. 首先 application.properties 文件中增加配置,指定静态资源目录(包括html的存放) spring.resources.static-locationsclasspath:/webapp/,classpath:/webapp/static/ 2. 项目目录 3. 如果有实现 …...

JavaWeb_LeadNews_Day11-KafkaStream实现实时计算文章分数
JavaWeb_LeadNews_Day11-KafkaStream实现实时计算文章分数 KafkaStream概述案例-统计单词个数SpringBoot集成 实时计算文章分值来源Gitee KafkaStream 概述 Kafka Stream: 提供了对存储与Kafka内的数据进行流式处理和分析的功能特点: Kafka Stream提供了一个非常简单而轻量的…...

python tcp server client示例代码
功能: 实现基本的tcp server端、client端,并引入threading, 保证两端任意链接、断链接,保证两端的稳定运行 IP说明: server不输入IP,默认为本机的IP,client需要输入要链接的server端的IP 端口说明&#x…...
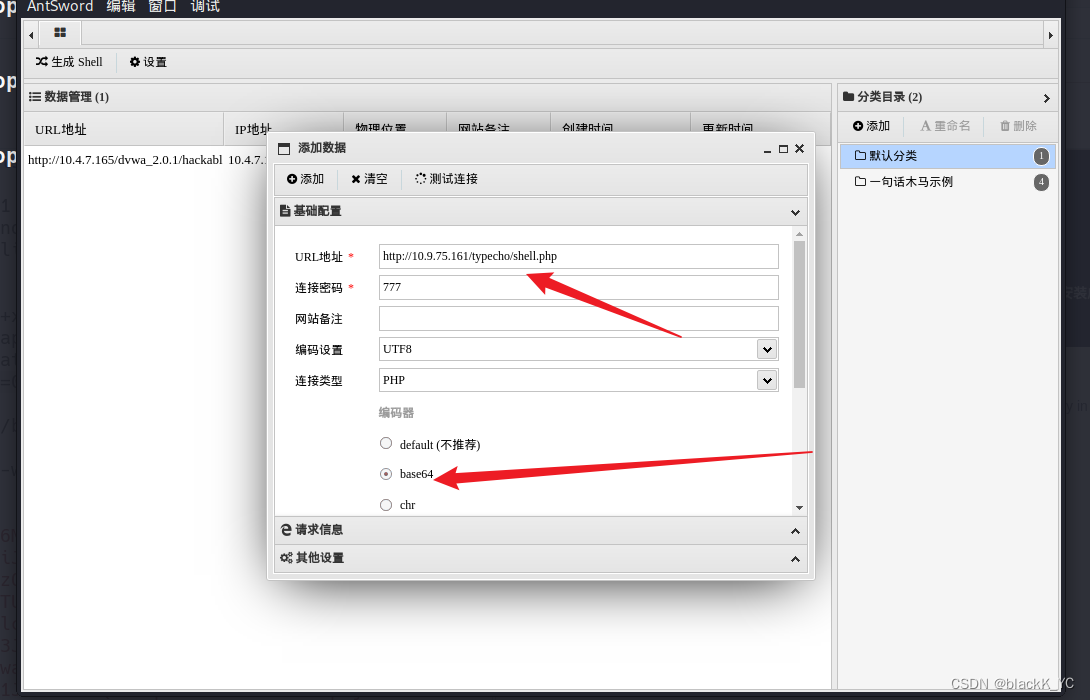
typecho 反序列化漏洞复现
环境搭建 下载typecho14.10.10 https://github.com/typecho/typecho/tags 安装,这里需要安装数据库 PHPINFO POC.php <?php class Typecho_Feed { const RSS1 RSS 1.0; const RSS2 RSS 2.0; const ATOM1 ATOM 1.0; const DATE_RFC822 r; const DATE_W3…...

Python实现SSA智能麻雀搜索算法优化LightGBM分类模型(LGBMClassifier算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出&a…...
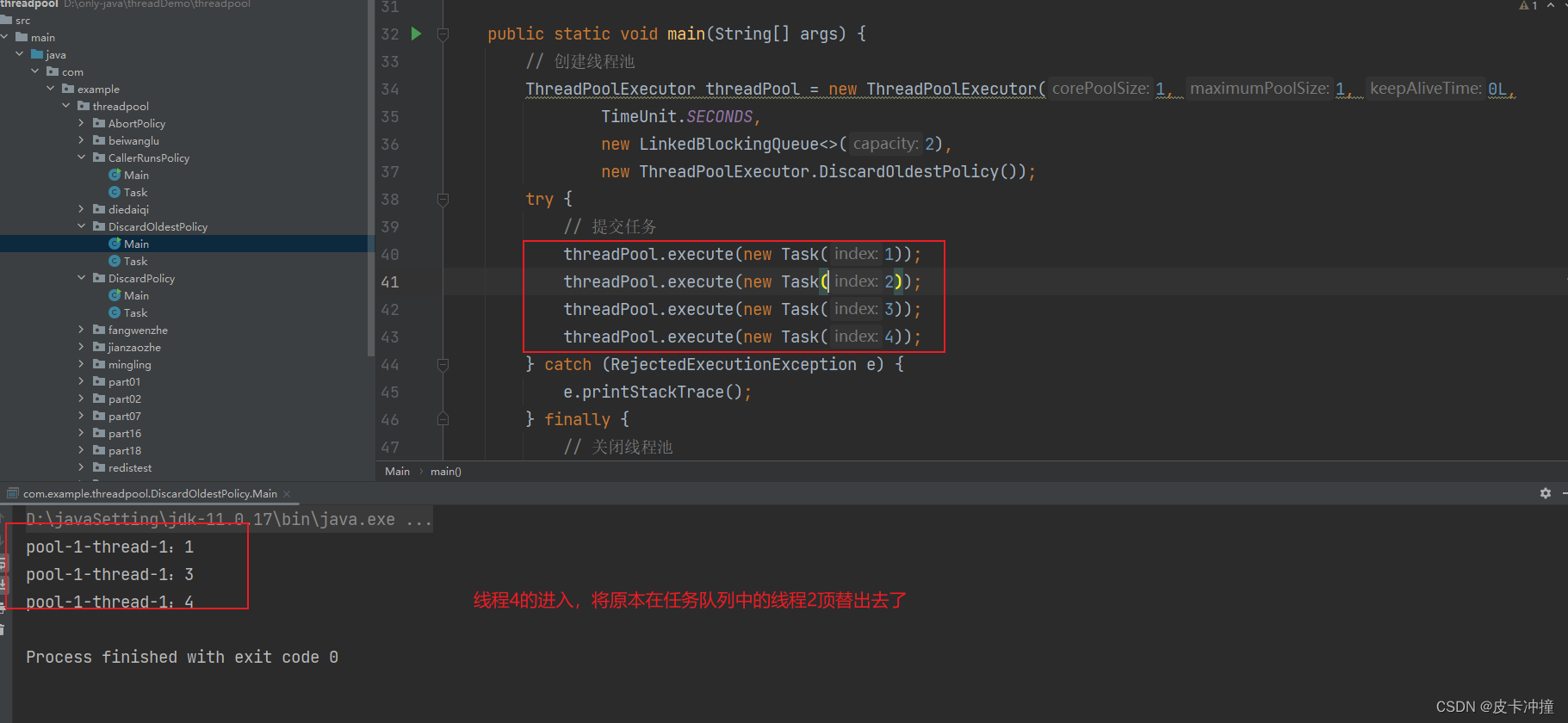
Java多线程4种拒绝策略
文章目录 一、简介二、AbortPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 三、CallerRunsPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 四、DiscardPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 五、DiscardOldes…...

MySQL的MHA
1.什么是 MHA MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的过…...

Java实现链表
在Java中,可以使用类来定义链表的节点,并使用引用数据类型(即类名)来模拟指针进而构建链表。下面是一个简单的示例。 首先,创建一个节点类 Node,它包含一个值和指向下一个节点的引用: public …...
SpringCloud Alibaba(2021.0.1版本)微服务-OpenFeign以及相关组件使用(保姆级教程)
💻目录 前言一、简绍二、代码实现1、搭建服务模块1.1、建立父包1.2、建立两个子包(service-order、service-product)1.3、添加util 工具类 2、添加maven依赖和yml配置文件2.1、springcloud-test父包配置2.2、服务模块配置2.2.1、service-orde…...

豆制品废水处理设备源头厂家方案
豆制品废水处理设备源头厂家方案 豆制品生产过程中产生的废水含有有机物、悬浮物、油脂等污染物,需要经过合理的处理才能达到排放标准或循环再利用。以下是一个可能的豆制品废水处理设备及方案: 1.初步处理: 格栅:用于去除大颗粒的…...

lnmp环境搭建
文章目录 一、环境信息二、LNMP环境搭建2.1 准备编译环境2.2 nginx安装2.3 mysql安装2.4 php安装2.5 nginx配置2.6 mysql配置2.7 配置php 三、常见问题3.1 安装其它版本的nginx服务3.2 php版本过低 一、环境信息 操作系统:公共镜像CentOS 7.8 64位 本文的部署配置…...

全球研发中心城市专题协商会课题调研组莅临麒麟信安考察指导
9月7日上午,长沙市政协党组副书记、副主席石长松,市委统战部副部长、市工商联党组书记何惠风,市政协研究室主任郑志华,市工商联党组成员、副主席王婧等领导一行莅临麒麟信安开展全球研发中心城市专题协商会课题调研,麒…...

ZeroTier客户端连接服务器
ZeroTier客户端连接服务器 下载客户端 https://www.zerotier.com/download/加入新的网络(例如d5e04297a16fa690,由管理员提供)管理员授权并告知服务器IP测试连接:ping 服务器IP使用putty, pycharm, vscode等工具连接即可 官方文…...

NFT Insider#106:The Sandbox 与 Light Matrix 以及鲁比尼拳击场达成战略合作
引言:NFT Insider由NFT收藏组织WHALE Members、BeepCrypto联合出品,浓缩每周NFT新闻,为大家带来关于NFT最全面、最新鲜、最有价值的讯息。每期周报将从NFT市场数据,艺术新闻类,游戏新闻类,虚拟世界类&#…...

【猿灰灰赠书活动 - 04期】- 【分布式统一大数据虚拟文件系统——Alluxio原理、技术与实践】
👨💻本文专栏:赠书活动专栏(为大家争取的福利,免费送书) 👨💻本文简述:博文为大家争取福利,与机械工业出版社合作进行送书活动 👨…...

前端element表格导出excel
一:安装依赖 npm install xlsx file-saver --save二:在组件中导入 import FileSaver from file-saver import XLSX from xlsx三:给对应表格添加id,绑定方法 <el-table idtableDom> <el-button click"exportExc…...
)
React中的类组件和函数组件(详解)
React的核心思想就是组件化,相对于Vue来说,React的组件化更加灵活和多样。主要可以分为两大类:函数组件,类组件,这两大类组件的名称必须是大写字母开头 一、函数组件 函数组件通常是function进行定义的函数࿰…...
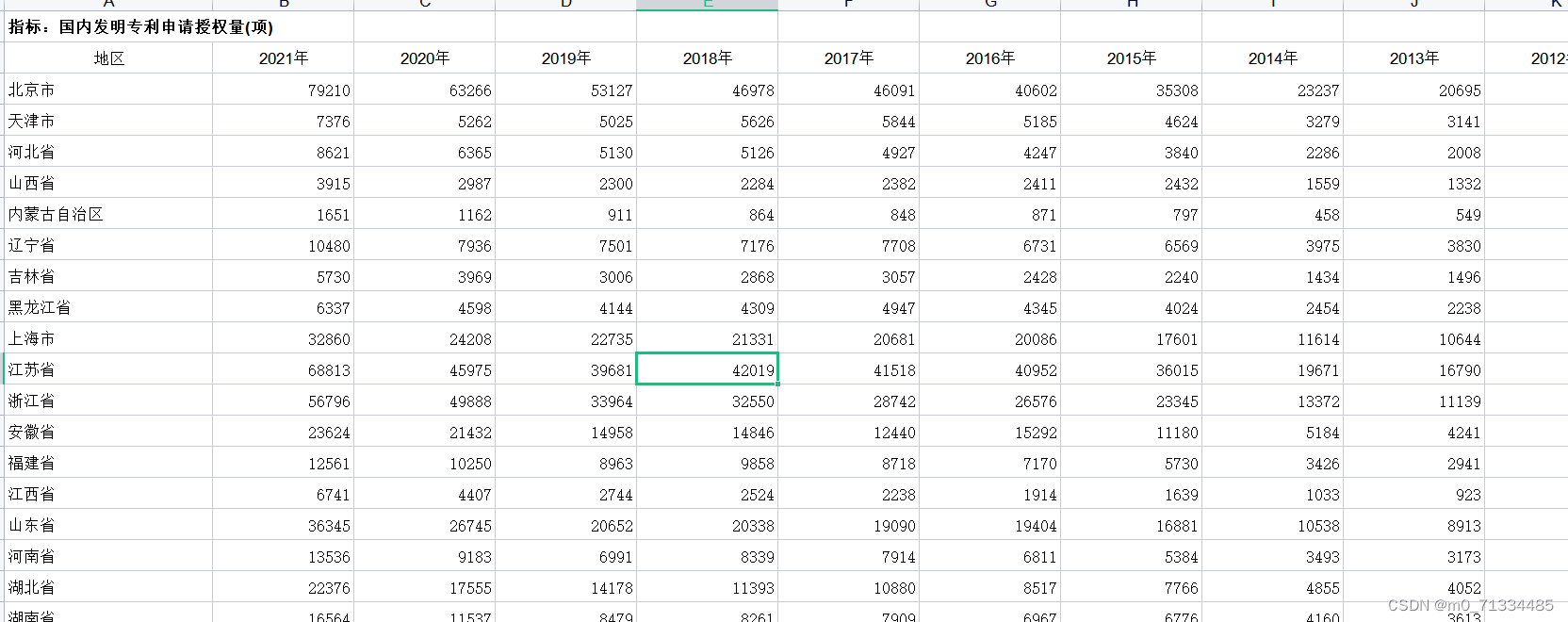
1987-2021年全国31省专利申请数和授权数
1987-2021年全国31省国内三种专利申请数和授权数 1、时间:1987-2021年 2、来源:整理自国家统计局、科技统计年鉴、各省年鉴 3、范围:31省市 4、指标:国内专利申请受理量、国内发明专利申请受理量、国内实用新型专利申请受理量…...

实战指南:利用快马平台为不同项目类型智能定制idea开发环境与工具链
今天想和大家分享一个实战经验:如何根据不同项目类型,快速定制专属的IDEA开发环境。作为开发者,我们经常需要切换不同技术栈,每次手动安装插件、配置SDK的过程实在太费时间。最近发现用InsCode(快马)平台可以智能解决这个问题&…...

实战演练:基于快马平台开发结合openclaw配置模型的工业分拣模拟系统
最近在做一个工业分拣系统的模拟项目,尝试用openclaw配置模型来实现对不同形状物体的智能抓取。整个过程在InsCode(快马)平台上完成,发现这个工具特别适合快速搭建这类机器人控制原型。记录下具体实现过程: 场景搭建 首先用三维引擎创建了一个…...

Win11终极IPX协议兼容方案:IPXWrapper完整配置与优化指南
Win11终极IPX协议兼容方案:IPXWrapper完整配置与优化指南 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 在现代Windows 11系统上重温《星际争霸》、《魔兽争霸》、《暗黑破坏神2》等经典游戏时,你是否遇…...

Kubernetes与存储管理最佳实践
Kubernetes与存储管理最佳实践 1. Kubernetes存储模型 Kubernetes存储模型定义了如何在容器化环境中管理和使用存储资源,是集群存储管理的基础。 1.1 存储模型核心概念 Volume:Pod中的存储卷,可被多个容器共享PersistentVolume (PV)ÿ…...

社交媒体数据采集难题?MediaCrawler让复杂任务变简单
社交媒体数据采集难题?MediaCrawler让复杂任务变简单 【免费下载链接】MediaCrawler-new 项目地址: https://gitcode.com/GitHub_Trending/me/MediaCrawler-new 在信息爆炸的数字时代,企业、研究机构和内容创作者常常需要从各大社交平台获取有价…...

PCB开窗技术:提升电流承载能力的关键工艺
1. PCB开窗技术解析:从概念到应用在PCB设计领域,"开窗"这个术语经常被经验丰富的工程师挂在嘴边,但对于刚入行的新手来说,这个看似简单的操作背后却蕴含着不少设计门道。作为一名有十年硬件设计经验的工程师,…...

GBase 8c 表空间规划和对象迁移
GBase 8c 表空间规划和对象迁移 我最近看 GBase 8c 资料时,越来越强烈的一个感觉是:很多现场不是不会建表空间,而是把表空间用得太晚、太散、太随意。 真正落到现场时,最常见的现象通常不是“不会执行 CREATE TABLESPACE”&#x…...

终极指南:如何用 PHP Steam API 包轻松集成 Steam 游戏数据
终极指南:如何用 PHP Steam API 包轻松集成 Steam 游戏数据 【免费下载链接】Steam A composer package to make use of the steam web api. 项目地址: https://gitcode.com/gh_mirrors/stea/Steam 想要在你的 PHP 或 Laravel 应用中集成 Steam 游戏数据吗&a…...

Windows DLL注入工具Xenos实战指南:问题解决与效能优化
Windows DLL注入工具Xenos实战指南:问题解决与效能优化 【免费下载链接】Xenos Windows dll injector 项目地址: https://gitcode.com/gh_mirrors/xe/Xenos 引言 在Windows系统开发与调试过程中,DLL注入技术扮演着重要角色,无论是插件…...

XXL-SSO用户画像构建:基于认证数据的用户行为分析
XXL-SSO用户画像构建:基于认证数据的用户行为分析 XXL-SSO是一款分布式单点登录框架,通过统一的认证中心实现多系统间的用户身份共享。在实际应用中,XXL-SSO积累的认证数据不仅可用于身份验证,还能通过用户画像构建实现精细化运营…...