JavaWeb_LeadNews_Day11-KafkaStream实现实时计算文章分数
JavaWeb_LeadNews_Day11-KafkaStream实现实时计算文章分数
- KafkaStream
- 概述
- 案例-统计单词个数
- SpringBoot集成
- 实时计算文章分值
- 来源
- Gitee
KafkaStream
概述
- Kafka Stream: 提供了对存储与Kafka内的数据进行流式处理和分析的功能
- 特点:
- Kafka Stream提供了一个非常简单而轻量的Library, 它可以非常方便地嵌入任意Java应用中, 也可以任意方式打包和部署
- 除了Kafka外, 无任何外部依赖
- 通过可容错地state, store实现高效地状态操作(如windowed join和aggregation)
- 支持基于事件时间地窗口操作, 并且可处理晚到的数据(late arrival of records)
- 关键概念:
- 源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器.
- Sink处理器: sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题

- KStream:
- 数据结构类似于map, key-value键值对.
- 一段顺序的, 无限长, 不断更新的数据集.
案例-统计单词个数
- 依赖
依赖中有排除部分依赖, 还是一整个放上来好了<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- kafkfa --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusions><exclusion><artifactId>connect-json</artifactId><groupId>org.apache.kafka</groupId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency> </dependencies> - 流式处理
public class KafkaStreamQuickStart {public static void main(String[] args) {// Kafka的配置信息Properties prop = new Properties();prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.174.133:9092");prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-quickstart");// Stream 构建器StreamsBuilder streamsBuilder = new StreamsBuilder();// 流式计算streamProcessor(streamsBuilder);// 创建KafkaStream对象KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), prop);// 开启流式计算kafkaStreams.start();}/*** 流式计算* 消息的内容: hello kafka* @param streamsBuilder*/private static void streamProcessor(StreamsBuilder streamsBuilder) {// 创建Kstream对象, 同时指定从哪个topic中接收消息KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");/*** 处理消息的value*/stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {@Overridepublic Iterable<String> apply(String value) {String[] valAry = value.split(" ");return Arrays.asList(valAry);}})// 按照value聚合处理.groupBy((key, value)->value)// 时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))// 统计单词的个数.count()// 转换为KStream.toStream().map((key, value)->{System.out.println("key:"+key+",value:"+value);return new KeyValue<>(key.key().toString(), value.toString());})// 发送消息.to("itcast-topic-out");} } - 发送消息
for (int i = 0; i < 5; i++) {ProducerRecord<String, String> kvProducerRecord = new ProducerRecord<>("icast-topic-input", "hello kafka");producer.send(kvProducerRecord); } - 接收消息
// 订阅主题 consumer.subscribe(Collections.singleton("itcast-topic-out"));
SpringBoot集成
- 配置
config.java
application.yml/*** 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数*/ @Setter @Getter @Configuration @EnableKafkaStreams @ConfigurationProperties(prefix="kafka") public class KafkaStreamConfig {private static final int MAX_MESSAGE_SIZE = 16* 1024 * 1024;private String hosts;private String group;@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {Map<String, Object> props = new HashMap<>();props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_cid");props.put(StreamsConfig.RETRIES_CONFIG, 10);props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());return new KafkaStreamsConfiguration(props);} }
BeanConfig.javakafka:hosts: 192.168.174.133:9092group: ${spring.application.name}@Slf4j @Configuration public class KafkaStreamHelloListener {@Beanpublic KStream<String, String> KStream(StreamsBuilder streamsBuilder){// 创建Kstream对象, 同时指定从哪个topic中接收消息KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");/*** 处理消息的value*/stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {@Overridepublic Iterable<String> apply(String value) {String[] valAry = value.split(" ");return Arrays.asList(valAry);}})// 按照value聚合处理.groupBy((key, value)->value)// 时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))// 统计单词的个数.count()// 转换为KStream.toStream().map((key, value)->{System.out.println("key:"+key+",value:"+value);return new KeyValue<>(key.key().toString(), value.toString());})// 发送消息.to("itcast-topic-out");return stream;} }
实时计算文章分值
- nacos: leadnews-behavior配置kafka生产者
kafka:bootstrap-servers: 192.168.174.133:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer - 修改leadnews-behavior
like
viewpublic ResponseResult likesBehavior(LikesBehaviorDto dto) {...UpdateArticleMess mess = new UpdateArticleMess();mess.setArticleId(dto.getArticleId());mess.setType(UpdateArticleMess.UpdateArticleType.LIKES);if(dto.getOperation() == 0){...mess.setAdd(1);}else{...mess.setAdd(-1);}// kafka: 发送消息, 数据聚合kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC, JSON.toJSONString(mess));... }public ResponseResult readBehavior(ReadBehaviorDto dto) {...// kafka: 发送消息, 数据聚合UpdateArticleMess mess = new UpdateArticleMess();mess.setArticleId(dto.getArticleId());mess.setType(UpdateArticleMess.UpdateArticleType.VIEWS);mess.setAdd(1);kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC, JSON.toJSONString(mess));... } - leadnews-article中添加流式聚合处理
@Slf4j @Configuration public class HotArticleStreamHandler {@Beanpublic KStream<String, String> KStream(StreamsBuilder streamsBuilder){// 接收消息KStream<String, String> stream = streamsBuilder.stream(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC);// 聚合流式处理stream.map((key, value)->{UpdateArticleMess mess = JSON.parseObject(value, UpdateArticleMess.class);// 重置消息的key和valuereturn new KeyValue<>(mess.getArticleId().toString(), mess.getType().name()+":"+mess.getAdd());})// 根据文章id进行聚合.groupBy((key, value)->key)// 时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))// 自行实现聚合计算.aggregate(// 初始方法, 返回值是消息的valuenew Initializer<String>() {@Overridepublic String apply() {return "COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0";}},// 真正的聚合操作, 返回值是消息的valuenew Aggregator<String, String, String>() {@Overridepublic String apply(String key, String value, String aggValue) {if(StringUtils.isBlank(value)){return aggValue;}String[] aggAry = aggValue.split(",");int col=0, com=0, lik=0, vie=0;for (String agg : aggAry) {String[] split = agg.split(":");/*** 获得初始值, 也是时间窗口内计算之后的值*/switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){case COLLECTION:col = Integer.parseInt(split[1]);break;case COMMENT:com = Integer.parseInt(split[1]);break;case LIKES:lik = Integer.parseInt(split[1]);break;case VIEWS:vie = Integer.parseInt(split[1]);break;}}// 累加操作String[] valAry = value.split(":");switch (UpdateArticleMess.UpdateArticleType.valueOf(valAry[0])){case COLLECTION:col += Integer.parseInt(valAry[1]);break;case COMMENT:com += Integer.parseInt(valAry[1]);break;case LIKES:lik += Integer.parseInt(valAry[1]);break;case VIEWS:vie += Integer.parseInt(valAry[1]);break;}String formatStr = String.format("COLLECTION:%d,COMMENT:%d,LIKES:%d,VIEWS:%d", col, com, lik, vie);System.out.println("文章的id "+key);System.out.println("当前时间窗口内的消息处理结果: "+formatStr);return formatStr;}}, Materialized.as("hot-article-stream-count-001")).toStream().map((key, value)->{return new KeyValue<>(key.key().toString(), formatObj(key.key().toString(), value));})// 发送消息.to(HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC);return stream;}/*** 格式化消息的value数据* @param articleId* @param value* @return*/private String formatObj(String articleId, String value) {ArticleVisitStreamMess mess = new ArticleVisitStreamMess();mess.setArticleId(Long.valueOf(articleId));// COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0String[] valAry = value.split(",");for (String val : valAry) {String[] split = val.split(":");switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){case COLLECTION:mess.setCollect(Integer.parseInt(split[1]));break;case COMMENT:mess.setComment(Integer.parseInt(split[1]));break;case LIKES:mess.setLike(Integer.parseInt(split[1]));break;case VIEWS:mess.setView(Integer.parseInt(split[1]));break;}}log.info("聚合消息处理之后的结果为: {}", JSON.toJSONString(mess));return JSON.toJSONString(mess);}} - leadnews-article添加聚合数据监听器
@Slf4j @Component public class ArticleIncrHandlerListener {@Autowiredprivate ApArticleService apArticleService;@KafkaListener(topics = HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC)public void onMessage(String mess){if(StringUtils.isNotBlank(mess)){ArticleVisitStreamMess articleVisitStreamMess = JSON.parseObject(mess, ArticleVisitStreamMess.class);apArticleService.updateScore(articleVisitStreamMess);System.out.println(mess);}}} - 替换redis中的热点数据
/*** 更新 文章分值, 缓存中的热点文章数据* @param mess*/ @Override public void updateScore(ArticleVisitStreamMess mess) {// 1. 更新文章的阅读, 点赞, 收藏, 评论的数量ApArticle apArticle = updateArticleBehavior(mess);// 2. 计算文章的分值Integer score = hotArticleService.computeArticleScore(apArticle);score *= 3;// 3. 替换当前文章对应频道的热点数据replaceDataToRedis(ArticleConstants.HOT_ARTICLE_FIRST_PAGE + apArticle.getChannelId(), apArticle, score);// 4. 替换推荐对应的热点数据replaceDataToRedis(ArticleConstants.HOT_ARTICLE_FIRST_PAGE + ArticleConstants.DEFAULT_TAG, apArticle, score); }/*** 替换数据并且存入到redis中* @param HOT_ARTICLE_FIRST_PAGE* @param apArticle* @param score*/ private void replaceDataToRedis(String HOT_ARTICLE_FIRST_PAGE, ApArticle apArticle, Integer score) {String articleList = cacheService.get(HOT_ARTICLE_FIRST_PAGE);if(StringUtils.isNotBlank(articleList)){List<HotArticleVo> hotArticleVoList = JSON.parseArray(articleList, HotArticleVo.class);boolean flag = true;// 3.1 文章已是热点文章, 则更新文章分数for (HotArticleVo hotArticleVo : hotArticleVoList) {if(hotArticleVo.getId().equals(apArticle.getId())){hotArticleVo.setScore(score);flag = false;break;}}// 3.2 文章还不是热点文章, 则替换分数最小的文章if(flag){if(hotArticleVoList.size() >= 30){// 热点文章超过30条hotArticleVoList = hotArticleVoList.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());HotArticleVo lastHot = hotArticleVoList.get(hotArticleVoList.size() - 1);if(lastHot.getScore() < score){hotArticleVoList.remove(lastHot);HotArticleVo hotArticleVo = new HotArticleVo();BeanUtils.copyProperties(apArticle, hotArticleVo);hotArticleVo.setScore(score);hotArticleVoList.add(hotArticleVo);}}else{// 热点文章没超过30条HotArticleVo hotArticleVo = new HotArticleVo();BeanUtils.copyProperties(apArticle, hotArticleVo);hotArticleVo.setScore(score);hotArticleVoList.add(hotArticleVo);}}// 3.3 缓存到redishotArticleVoList = hotArticleVoList.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());cacheService.set(HOT_ARTICLE_FIRST_PAGE, JSON.toJSONString(hotArticleVoList));} }/*** 更新文章行为数据* @param mess*/ private ApArticle updateArticleBehavior(ArticleVisitStreamMess mess) {ApArticle apArticle = getById(mess.getArticleId());apArticle.setComment(apArticle.getComment()==null?0:apArticle.getComment()+mess.getComment());apArticle.setCollection(apArticle.getCollection()==null?0:apArticle.getCollection()+mess.getCollect());apArticle.setLikes(apArticle.getLikes()==null?0:apArticle.getLikes()+mess.getLike());apArticle.setViews(apArticle.getViews()==null?0:apArticle.getViews()+mess.getView());updateById(apArticle);return apArticle; }
来源
黑马程序员. 黑马头条
Gitee
https://gitee.com/yu-ba-ba-ba/leadnews
相关文章:
JavaWeb_LeadNews_Day11-KafkaStream实现实时计算文章分数
JavaWeb_LeadNews_Day11-KafkaStream实现实时计算文章分数 KafkaStream概述案例-统计单词个数SpringBoot集成 实时计算文章分值来源Gitee KafkaStream 概述 Kafka Stream: 提供了对存储与Kafka内的数据进行流式处理和分析的功能特点: Kafka Stream提供了一个非常简单而轻量的…...

python tcp server client示例代码
功能: 实现基本的tcp server端、client端,并引入threading, 保证两端任意链接、断链接,保证两端的稳定运行 IP说明: server不输入IP,默认为本机的IP,client需要输入要链接的server端的IP 端口说明&#x…...
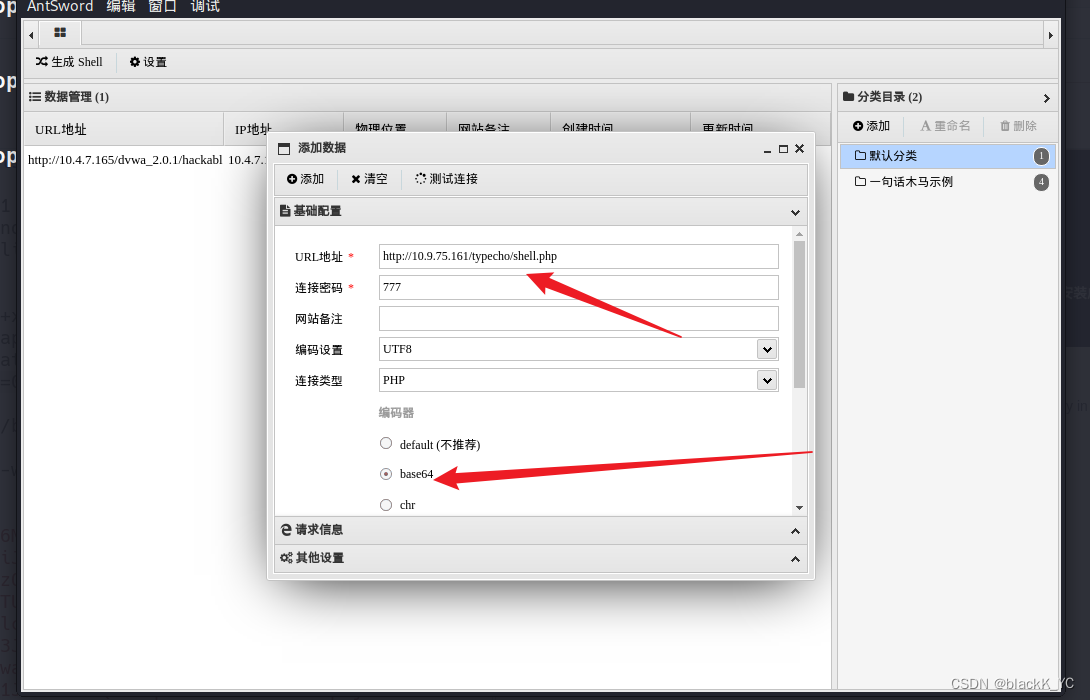
typecho 反序列化漏洞复现
环境搭建 下载typecho14.10.10 https://github.com/typecho/typecho/tags 安装,这里需要安装数据库 PHPINFO POC.php <?php class Typecho_Feed { const RSS1 RSS 1.0; const RSS2 RSS 2.0; const ATOM1 ATOM 1.0; const DATE_RFC822 r; const DATE_W3…...

Python实现SSA智能麻雀搜索算法优化LightGBM分类模型(LGBMClassifier算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出&a…...
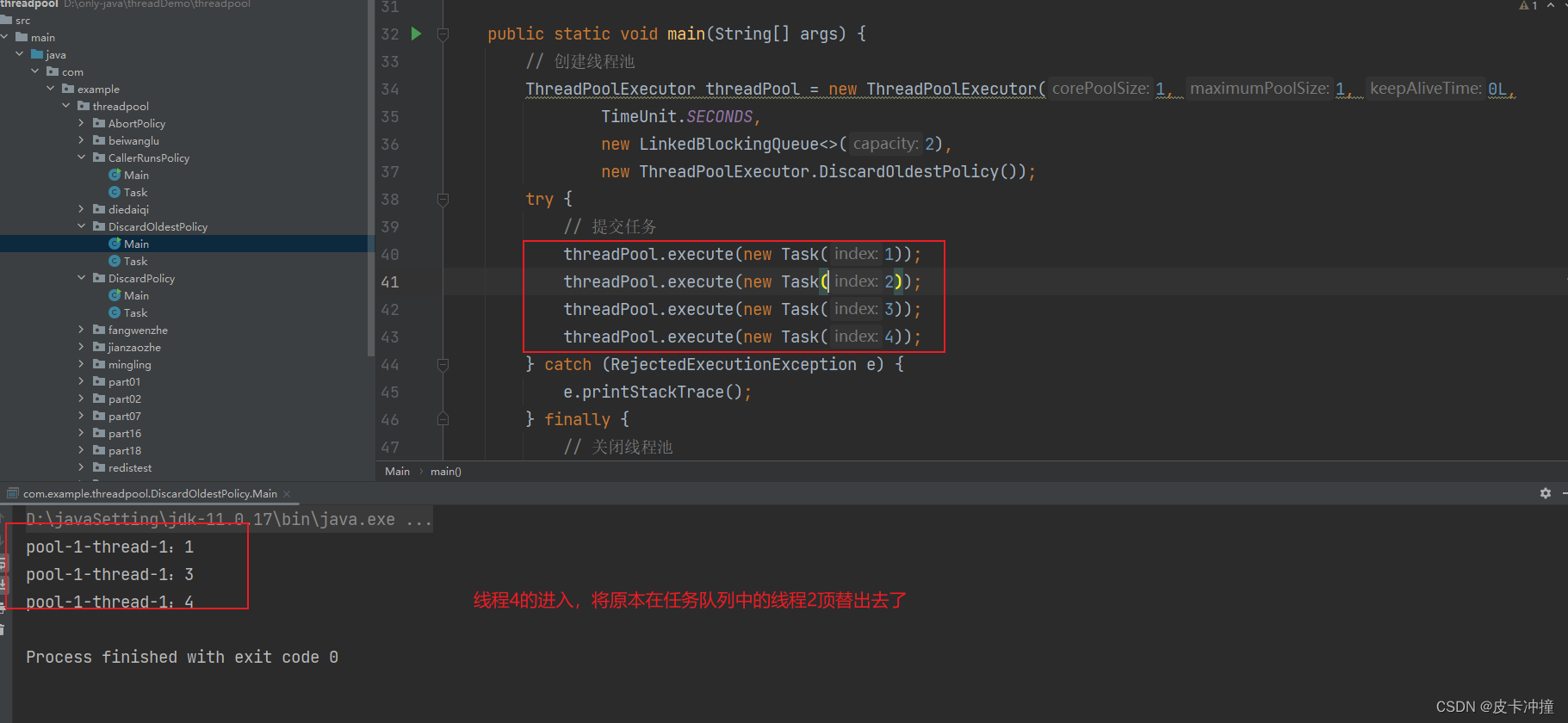
Java多线程4种拒绝策略
文章目录 一、简介二、AbortPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 三、CallerRunsPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 四、DiscardPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 五、DiscardOldes…...

MySQL的MHA
1.什么是 MHA MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的过…...

Java实现链表
在Java中,可以使用类来定义链表的节点,并使用引用数据类型(即类名)来模拟指针进而构建链表。下面是一个简单的示例。 首先,创建一个节点类 Node,它包含一个值和指向下一个节点的引用: public …...
SpringCloud Alibaba(2021.0.1版本)微服务-OpenFeign以及相关组件使用(保姆级教程)
💻目录 前言一、简绍二、代码实现1、搭建服务模块1.1、建立父包1.2、建立两个子包(service-order、service-product)1.3、添加util 工具类 2、添加maven依赖和yml配置文件2.1、springcloud-test父包配置2.2、服务模块配置2.2.1、service-orde…...

豆制品废水处理设备源头厂家方案
豆制品废水处理设备源头厂家方案 豆制品生产过程中产生的废水含有有机物、悬浮物、油脂等污染物,需要经过合理的处理才能达到排放标准或循环再利用。以下是一个可能的豆制品废水处理设备及方案: 1.初步处理: 格栅:用于去除大颗粒的…...

lnmp环境搭建
文章目录 一、环境信息二、LNMP环境搭建2.1 准备编译环境2.2 nginx安装2.3 mysql安装2.4 php安装2.5 nginx配置2.6 mysql配置2.7 配置php 三、常见问题3.1 安装其它版本的nginx服务3.2 php版本过低 一、环境信息 操作系统:公共镜像CentOS 7.8 64位 本文的部署配置…...

全球研发中心城市专题协商会课题调研组莅临麒麟信安考察指导
9月7日上午,长沙市政协党组副书记、副主席石长松,市委统战部副部长、市工商联党组书记何惠风,市政协研究室主任郑志华,市工商联党组成员、副主席王婧等领导一行莅临麒麟信安开展全球研发中心城市专题协商会课题调研,麒…...

ZeroTier客户端连接服务器
ZeroTier客户端连接服务器 下载客户端 https://www.zerotier.com/download/加入新的网络(例如d5e04297a16fa690,由管理员提供)管理员授权并告知服务器IP测试连接:ping 服务器IP使用putty, pycharm, vscode等工具连接即可 官方文…...

NFT Insider#106:The Sandbox 与 Light Matrix 以及鲁比尼拳击场达成战略合作
引言:NFT Insider由NFT收藏组织WHALE Members、BeepCrypto联合出品,浓缩每周NFT新闻,为大家带来关于NFT最全面、最新鲜、最有价值的讯息。每期周报将从NFT市场数据,艺术新闻类,游戏新闻类,虚拟世界类&#…...

【猿灰灰赠书活动 - 04期】- 【分布式统一大数据虚拟文件系统——Alluxio原理、技术与实践】
👨💻本文专栏:赠书活动专栏(为大家争取的福利,免费送书) 👨💻本文简述:博文为大家争取福利,与机械工业出版社合作进行送书活动 👨…...

前端element表格导出excel
一:安装依赖 npm install xlsx file-saver --save二:在组件中导入 import FileSaver from file-saver import XLSX from xlsx三:给对应表格添加id,绑定方法 <el-table idtableDom> <el-button click"exportExc…...
)
React中的类组件和函数组件(详解)
React的核心思想就是组件化,相对于Vue来说,React的组件化更加灵活和多样。主要可以分为两大类:函数组件,类组件,这两大类组件的名称必须是大写字母开头 一、函数组件 函数组件通常是function进行定义的函数࿰…...
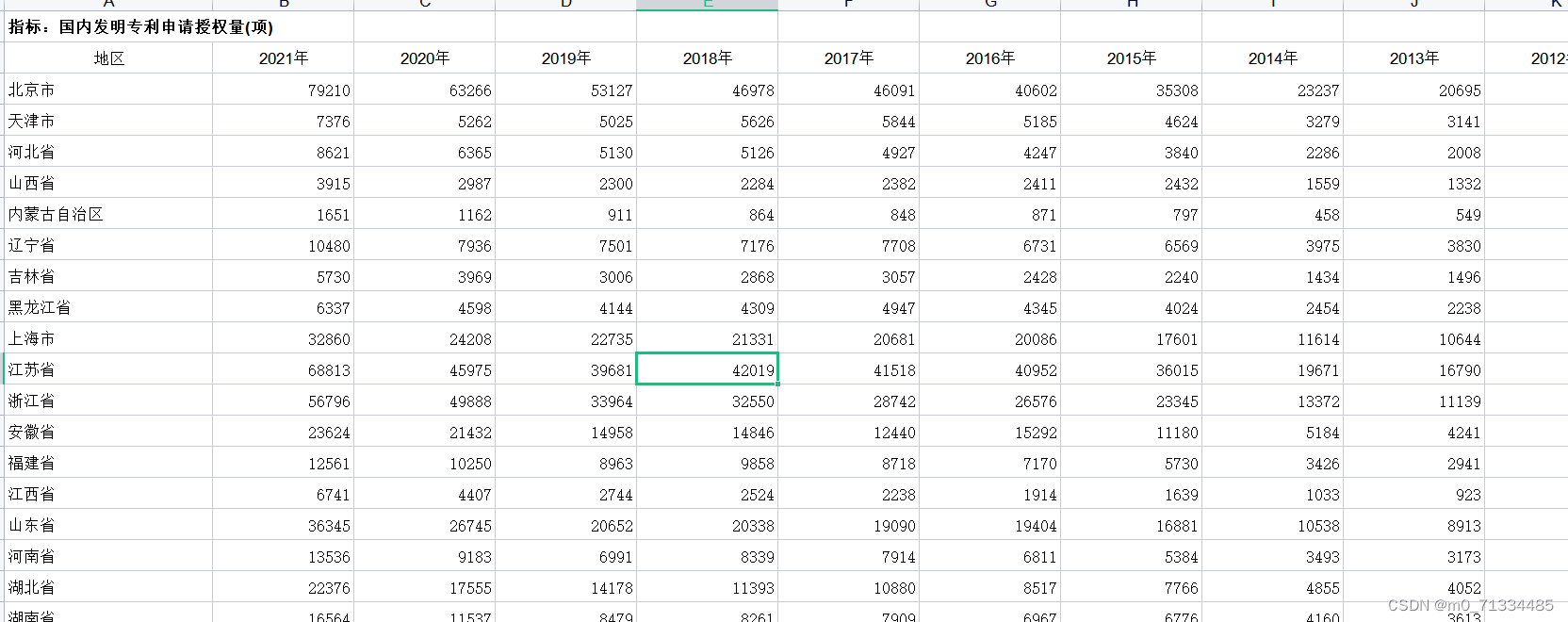
1987-2021年全国31省专利申请数和授权数
1987-2021年全国31省国内三种专利申请数和授权数 1、时间:1987-2021年 2、来源:整理自国家统计局、科技统计年鉴、各省年鉴 3、范围:31省市 4、指标:国内专利申请受理量、国内发明专利申请受理量、国内实用新型专利申请受理量…...

欧洲云巨头OVHcloud收购边缘计算专家 gridscale
边缘计算社区近日获悉,欧洲云巨头OVHcloud已进入全面收购德国公司 gridscale 的谈判,该公司是一家专门从事超融合基础设施的软件提供商。 此次战略收购将标志着 OVHcloud 的另一个重要里程碑,使该集团能够显着加速其地理部署,并进…...
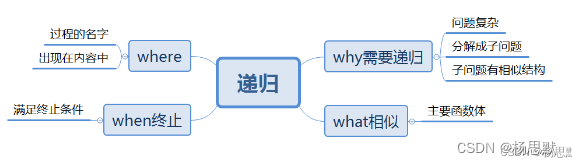
java从入门到起飞(八)——循环和递归
文章目录 Java循环1. 什么是循环?1.1 为什么需要循环?1.2 循环的分类 2. Java中的循环结构2.1 for循环2.2 while循环2.3 do-while循环 3. 循环控制语句3.1 break语句3.2 continue语句 4. 总结 Java递归1. 什么是递归2. 递归的原理3. 递归的实现4. 递归的…...

架构师成长之路|Redis实现延迟队列的三种方式
延迟队列实现 基于监听key过期实现的延迟队列实现,这里需要继承KeyspaceEventMessageListener类来实现监听redis键过期 public class KeyExpirationEventMessageListener extends KeyspaceEventMessageListener implementsApplicationEventPublisherAware {private static f…...

GraphRAG实战:我是如何用它分析公司内部文档,让客服响应时间缩短近30%的
GraphRAG实战:我是如何用它分析公司内部文档,让客服响应时间缩短近30%的 作为一家中型电商企业的技术负责人,我最近半年一直在与客服团队的一个顽固问题搏斗:每当新品上线或促销活动期间,客服人员需要花费大量时间在不…...

FireRedASR-AED-L从零开始教程:无需Python环境,镜像开箱即用识别中英混合语音
FireRedASR-AED-L从零开始教程:无需Python环境,镜像开箱即用识别中英混合语音 你是不是经常遇到这样的场景?手头有一段重要的会议录音,里面既有中文讨论,又夹杂着几个英文专业术语,想把它转成文字却找不到…...

SecGPT-14B提示工程:提升OpenClaw安全报告可读性的秘诀
SecGPT-14B提示工程:提升OpenClaw安全报告可读性的秘诀 1. 当安全报告遇上OpenClaw:我的真实痛点 上周五凌晨2点,我被OpenClaw的告警邮件惊醒——它发现我的个人服务器存在一个高危漏洞。但当我打开那份自动生成的安全报告时,眼…...

CS231n实战解析:从HOG/HSV特征到图像分类性能提升
1. 图像特征工程入门:为什么HOG和HSV如此重要 第一次接触CS231n作业时,我对HOG和HSV这两个特征提取方法感到既陌生又好奇。直到在CIFAR-10数据集上做了对比实验才发现,使用原始像素训练的模型准确率只有0.51,而加入特征工程后直接…...

轻量工具如何承载复杂项目?揭秘GanttProject的极简主义哲学
轻量工具如何承载复杂项目?揭秘GanttProject的极简主义哲学 【免费下载链接】ganttproject Official GanttProject repository 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 在项目管理领域,存在一个普遍的矛盾:专业工具…...

MySQL 5.7.32 Online DDL避坑指南:如何避免主从延迟和锁等待?
MySQL 5.7.32 Online DDL实战避坑:高并发场景下的零停机表结构变更策略 在数据库运维的日常工作中,表结构变更(DDL)操作总是让人又爱又恨。特别是当面对千万级数据表时,一个简单的ALTER TABLE操作就可能引发连锁反应—…...
Pixel Epic效果实测:不同逻辑发散概率下技术路线图描述准确率对比
Pixel Epic效果实测:不同逻辑发散概率下技术路线图描述准确率对比 1. 测试背景与目的 Pixel Epic作为一款创新型研究报告辅助工具,其核心功能"贤者之智"模块采用了独特的逻辑发散机制。本次测试旨在评估不同逻辑发散概率设置对技术路线图描述…...

seo 站群的优缺点是什么
SEO 站群的优缺点解析 在现代的互联网营销中,SEO(搜索引擎优化)站群是一个重要的概念。SEO 站群是指由多个主题相关的网站组成的集合,这些网站通过某种联系形式运作在一起,以提升整体的搜索引擎排名和流量。虽然 SEO …...

Windows 11 上安装 MinGW-w64 并运行 LVGL SDL 模拟器
目前最推荐的方式是使用 MSYS2。它安装简单、包管理方便(pacman),而且能直接安装 SDL2,避免手动复制头文件和库的麻烦。 以下是完整、推荐的步骤(2026 年最新实践): 1. 安装 MSYS2(…...

【WEB模型】CS架构BS架构HTMLCSSJS
一、CS架构 - Client/Server 客户端/服务器pc安装软件:安卓应用、ios应用需要安装专门软件才能用,软件直接跟服务器通信开发成本高,各个平台都有对应的开发工程师好处:功能强大二、BS架构 - Browser/Server 浏览器/服务器不需要安…...