bert ranking pairwise demo
下面是用bert 训练pairwise rank 的 demo
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import BertModel, BertTokenizer
from sklearn.metrics import pairwise_distances_argmin_minclass PairwiseRankingDataset(Dataset):def __init__(self, sentence_pairs, tokenizer, max_length):self.input_ids = []self.attention_masks = []for pair in sentence_pairs:encoded_pair = tokenizer(pair, padding='max_length', truncation=True, max_length=max_length, return_tensors='pt')self.input_ids.append(encoded_pair['input_ids'])self.attention_masks.append(encoded_pair['attention_mask'])self.input_ids = torch.cat(self.input_ids, dim=0)self.attention_masks = torch.cat(self.attention_masks, dim=0)def __len__(self):return len(self.input_ids)def __getitem__(self, idx):input_id = self.input_ids[idx]attention_mask = self.attention_masks[idx]return input_id, attention_maskclass BERTPairwiseRankingModel(torch.nn.Module):def __init__(self, bert_model_name):super(BERTPairwiseRankingModel, self).__init__()self.bert = BertModel.from_pretrained(bert_model_name)self.dropout = torch.nn.Dropout(0.1)self.fc = torch.nn.Linear(self.bert.config.hidden_size, 1)def forward(self, input_ids, attention_mask):outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)pooled_output = self.dropout(outputs[1])logits = self.fc(pooled_output)return logits.squeeze()# 初始化BERT模型和分词器
bert_model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(bert_model_name)# 示例输入数据
sentence_pairs = [('I like cats', 'I like dogs'),('The sun is shining', 'It is raining'),('Apple is a fruit', 'Car is a vehicle')
]# 超参数
batch_size = 8
max_length = 128
learning_rate = 1e-5
num_epochs = 5# 创建数据集和数据加载器
dataset = PairwiseRankingDataset(sentence_pairs, tokenizer, max_length)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 初始化模型并加载预训练权重
model = BERTPairwiseRankingModel(bert_model_name)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)# 训练模型
model.train()for epoch in range(num_epochs):total_loss = 0for input_ids, attention_masks in dataloader:optimizer.zero_grad()logits = model(input_ids, attention_masks)# 计算损失函数(使用对比损失函数)pos_scores = logits[::2] # 正样本分数neg_scores = logits[1::2] # 负样本分数loss = torch.relu(1 - pos_scores + neg_scores).mean()total_loss += loss.item()loss.backward()optimizer.step()print(f"Epoch {epoch+1}/{num_epochs} - Loss: {total_loss:.4f}")# 推断模型
model.eval()with torch.no_grad():embeddings = model.bert.embeddings.word_embeddings(dataset.input_ids)pairwise_distances = pairwise_distances_argmin_min(embeddings.numpy())# 输出结果
for i, pair in enumerate(sentence_pairs):pos_idx = pairwise_distances[0][2 * i]neg_idx = pairwise_distances[0][2 * i + 1]pos_dist = pairwise_distances[1][2 * i]neg_dist = pairwise_distances[1][2 * i + 1]print(f"Pair: {pair}")print(f"Positive example index: {pos_idx}, Distance: {pos_dist:.4f}")print(f"Negative example index: {neg_idx}, Distance: {neg_dist:.4f}")print()相关文章:

bert ranking pairwise demo
下面是用bert 训练pairwise rank 的 demo import torch from torch.utils.data import DataLoader, Dataset from transformers import BertModel, BertTokenizer from sklearn.metrics import pairwise_distances_argmin_minclass PairwiseRankingDataset(Dataset):def __ini…...
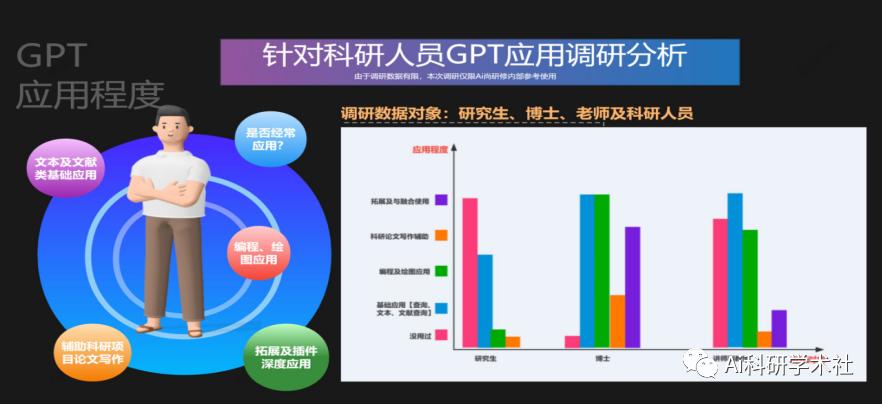
GPT引领前沿与应用突破之GPT4科研实践技术与AI绘图
GPT对于每个科研人员已经成为不可或缺的辅助工具,不同的研究领域和项目具有不同的需求。例如在科研编程、绘图领域:1、编程建议和示例代码: 无论你使用的编程语言是Python、R、MATLAB还是其他语言,都可以为你提供相关的代码示例。2、数据可视…...
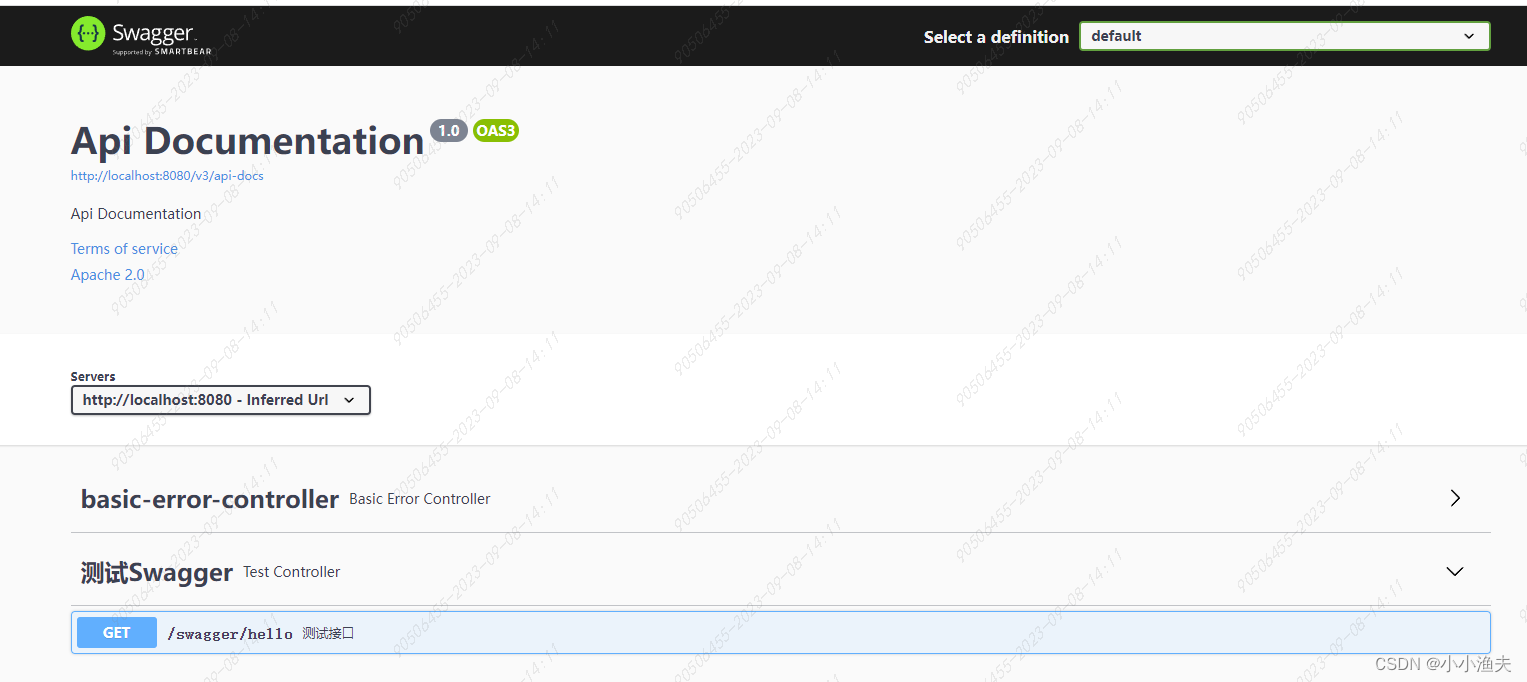
SpringBoot整合Swagger3
前言 swagger是啥,是干什么的,有什么用,我想在这里我就不用介绍了,下面直接代码演示。 添加依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0…...

detectron2 install path
>>> import detectron2 >>> detectron2_path detectron2.__file__ >>> print(detectron2.__file__)...
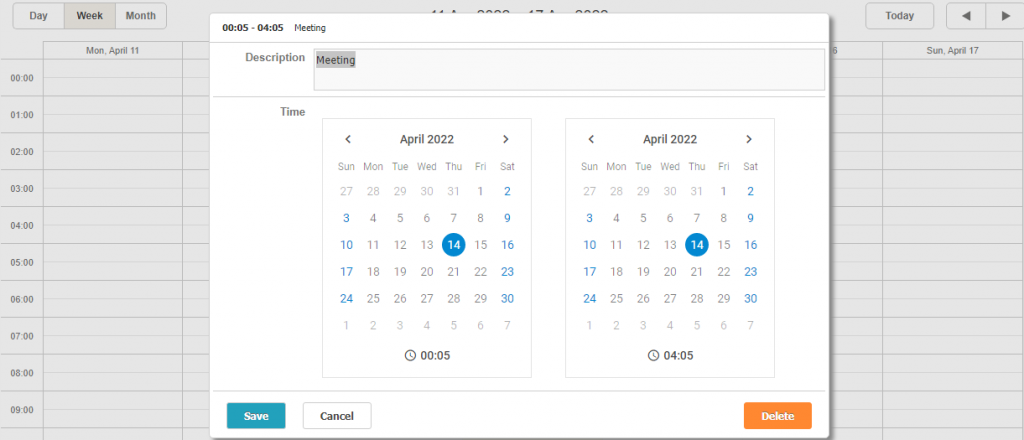
如何将DHTMLX Suite集成到Scheduler Lightbox中?让项目管理更可控!
在构建JavaScript调度器时,通常需要为最终用户提供一个他们喜欢的方式来计划事件,这是Web开发人员喜欢认可DHTMLX Scheduler的重要原因,它在这方面提供了完全的操作自由,它带有lightbox弹出窗口,允许通过各种控件动态更…...
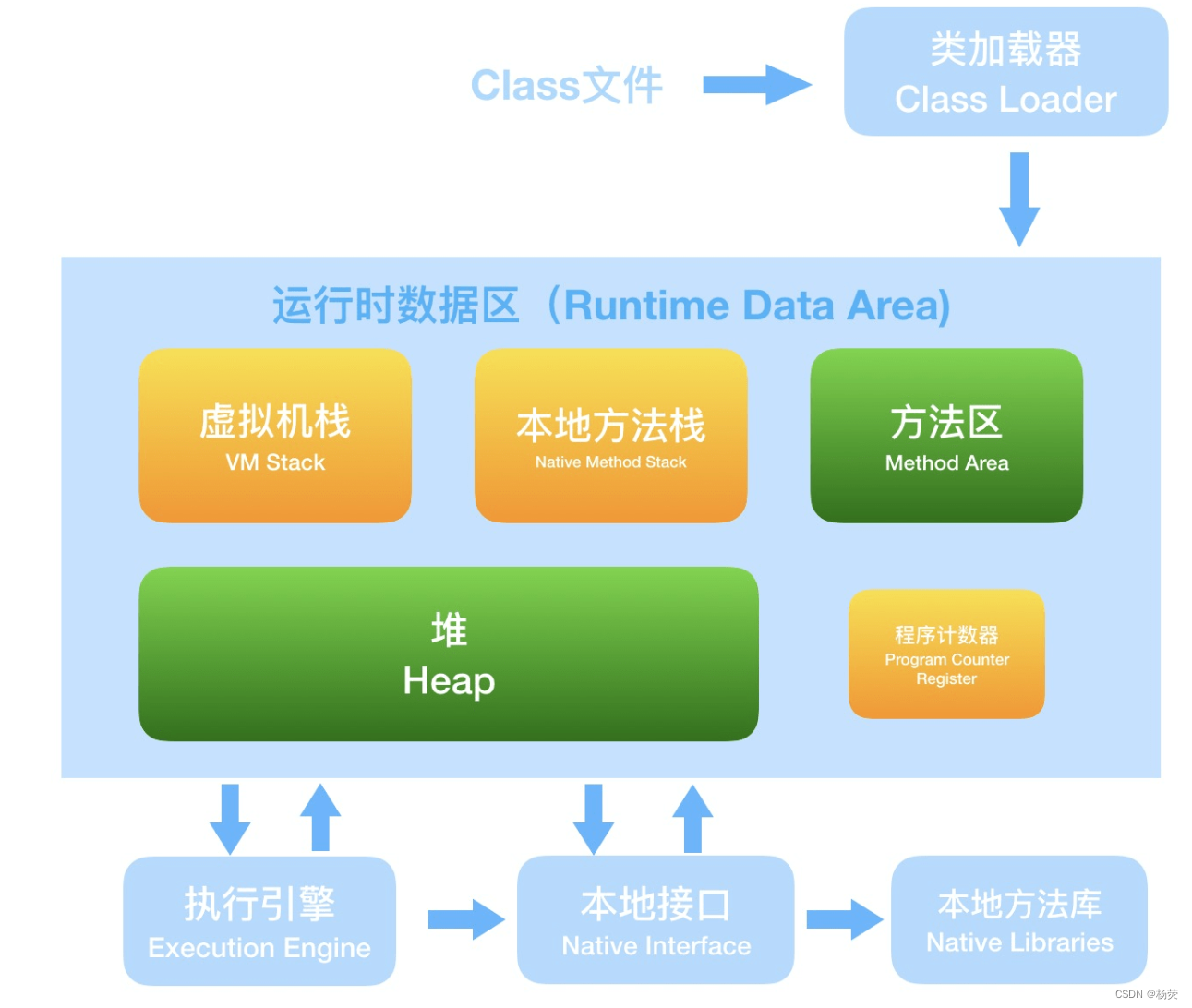
什么是JVM常用调优策略?分别有哪些?
目录 一、JVM调优 二、堆内存大小调整 三、垃圾回收器调优 四、线程池调优 一、JVM调优 Java虚拟机(JVM)的调优主要是为了提高应用程序的性能,包括提高应用程序的响应速度和吞吐量。以下是一些常用的JVM调优策略: 堆内存大小…...

《向量数据库指南》——向量数据库Milvus Cloud 2.3的可运维性:从理论到实践
一、引言 在数据科学的大家庭中,向量数据库扮演着重要角色。它们通过独特的向量运算机制,为复杂的机器学习任务提供了高效的数据处理能力。然而,如何让这些数据库在生产环境中稳定运行,成为了运维团队的重要挑战。本文将深入探讨向量数据库的可运维性,并分享一些有趣的案…...
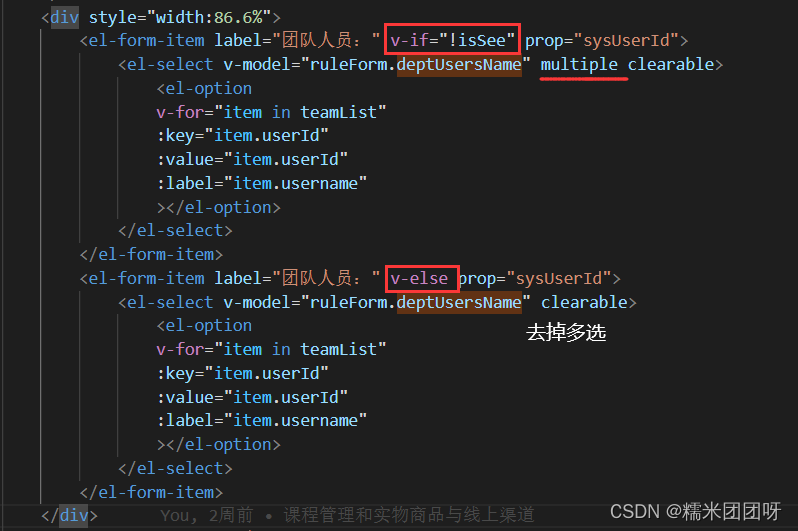
select多选回显问题 (取巧~)
要实现的效果: 实际上select选择框,我想要的是数组对象,但是后端返回来的是个字符串。 以下是解决方法: 以上是一种简单的解决方法~ 也可以自己处理数据或者让后端直接改成想要的格式。...
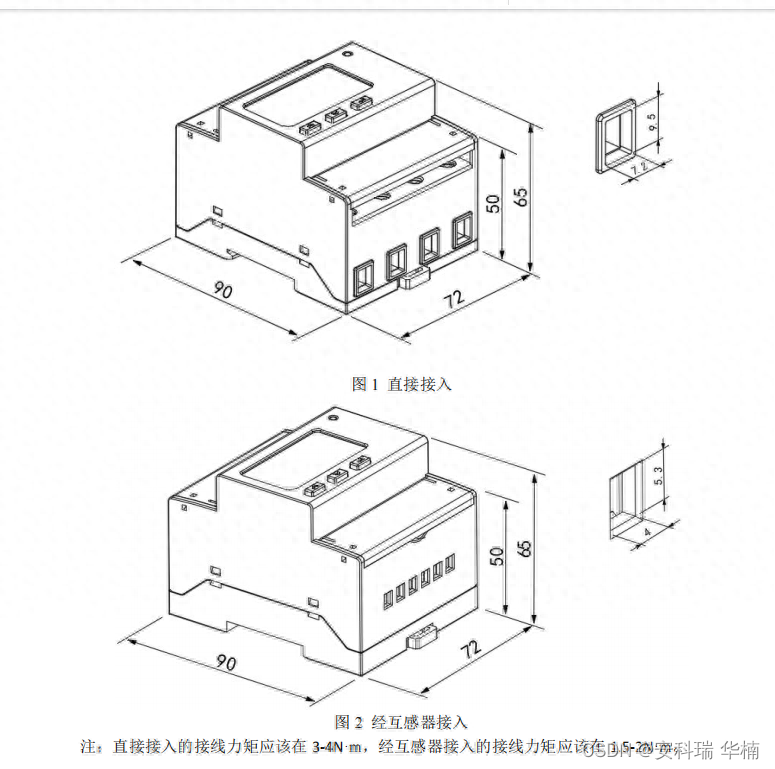
光伏并网双向计量表ADL400
安科瑞 华楠 ADL400 导轨式多功能电能表,是主要针对电力系统,工矿企业,公用设施的电能统计、 管理需求而设计的一款智能仪表,产品具有精度高、体积小、安装方便等优点。集成常见电 力参数测量及电能计量及考核管理,…...
十三、MySQL(DQL)语句执行顺序
1、DQL语句执行顺序: (1)from来决定表 # where来指定查询的条件 (2)group by指定分组 # having指定分组之后的条件 (3)select查询要返回哪些字段 (4)order by根据字段内容&#…...
【高德地图】根据经纬度多边形的绘制(可绘制区域以及任意图形)
官方示例 https://lbs.amap.com/demo/jsapi-v2/example/overlayers/polygon-draw <!doctype html> <html> <head><meta charset"utf-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name&quo…...
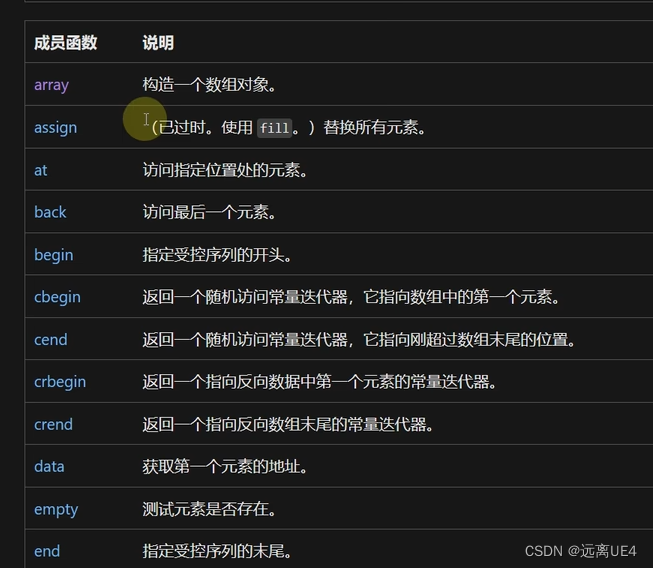
C++ std::pair and std::list \ std::array
std::pair<第一个数据类型, 第二个数据类型> 变量名 例如: std::pair<int, string> myPair; myPair.first;拿到第一个int变量 myPair.second拿到第二个string变量 std::pair需要引入库#include "utility" std::make_pair() 功能制作一个…...
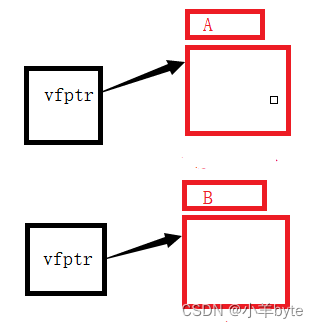
C++的类型转换
前言 我们都知道C是兼容C语言的在C语言中存在两种方式的类型转换,分别是隐式类型转换和显示类型转换(强制类型转换),但是C觉得C语言的这套东西是够好,所以在兼容C语言的基础上又搞了一套自己的关于类型转换的东西。 目…...

【Selenium2+python】自动化unittest生成测试报告
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的。 unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTestRunner 一、导…...
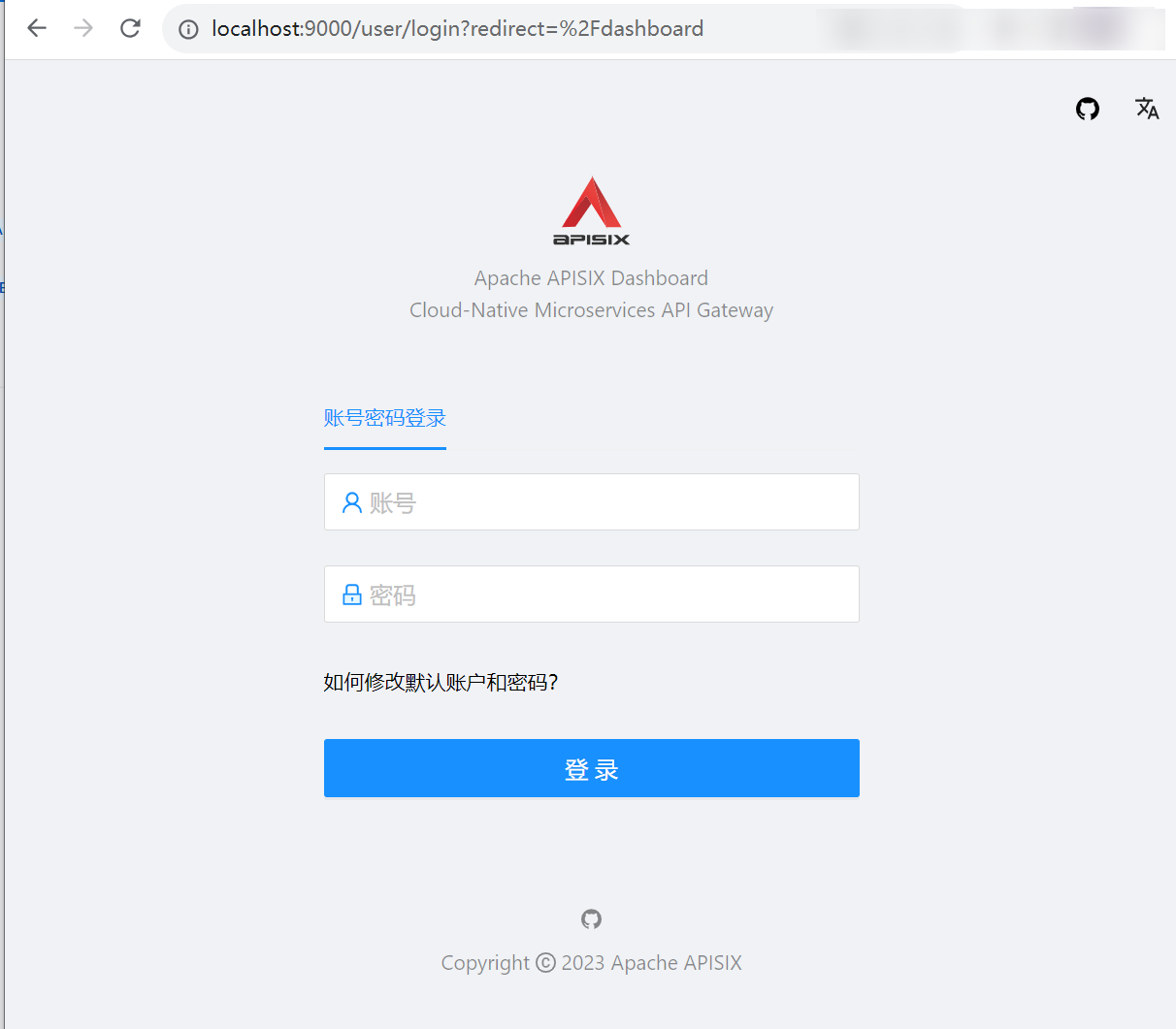
【APISIX】W10安装APISIX
Apache APISIX 是一个动态、实时、高性能的云原生 API 网关,提供了负载均衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等丰富的流量管理功能。以下简单介绍Windows下借助Docker Desktop来安装APISIX。 具体应用场景可参考官网(https://apisix.…...
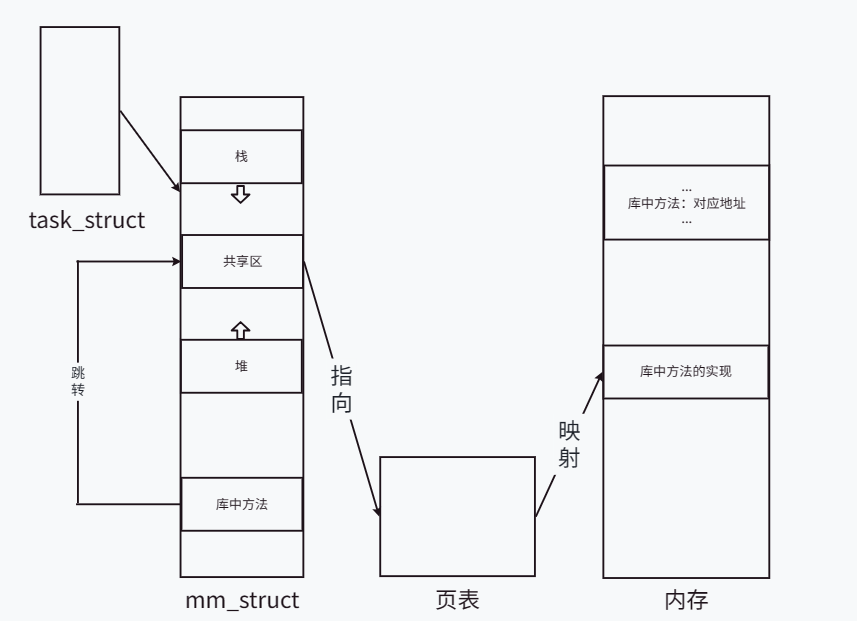
[Linux]动静态库
[Linux]动静态库 文章目录 [Linux]动静态库见一见库存在库的原因编写库模拟编写静态库模拟使用静态库模拟编写动态库模拟使用静态库 库的加载原理静态库的加载原理动态库的加载原理 库在可执行程序中的编址策略静态库在可执行程序中的编址策略动态库在可执行程序中的编址策略 见…...

2023高教社杯数学建模国赛C题思路解析+代码+论文
如下为C君的2023高教社杯全国大学生数学建模竞赛C题思路分析代码论文 C题蔬菜类商品的自动定价与补货决策 在生鲜商超中,一般蔬菜类商品的保鲜期都比较短,且品相随销售时间的增加而变差, 大部分品种如当日未售出,隔日就无法再售。因此&…...
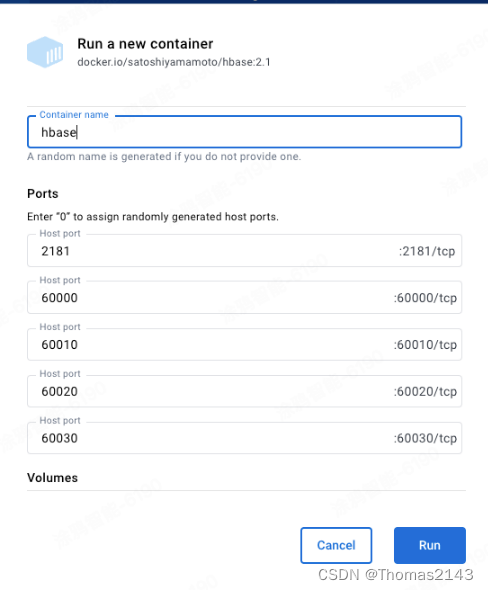
macos13 arm芯片(m2) 搭建hbase docker容器 并用flink通过自定义richSinkFunction写入数据到hbase
搭建hbase docker容器 下载镜像 https://hub.docker.com/r/satoshiyamamoto/hbase/tags 点击run 使用镜像新建容器 填写容器名和 容器与宿主机的端口映射 测试 通过宿主机访问容器内的hbase webUI http://localhost:60010/master-status...
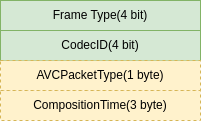
FLV封装格式
摘要:本文描述了FLV的文件格式。 关键字:FLV 1 简介 FLV流媒体格式是sorenson公司开发的一种视频格式,全称为Flash Video。 它的出现有效地解决了视频文件导入Flash后,使导出的SWF文件体积庞大,不能在网络上很好的…...
[NLP]LLM---FineTune自己的Llama2模型
一 数据集准备 Let’s talk a bit about the parameters we can tune here. First, we want to load a llama-2-7b-hf model and train it on the mlabonne/guanaco-llama2-1k (1,000 samples), which will produce our fine-tuned model llama-2-7b-miniguanaco. If you’re …...

告别图形界面!用DM数据库的dlsql命令行工具,5分钟搞定日常数据库运维
命令行利器dlsql:DM数据库高效运维实战指南 在数据库运维的世界里,图形化界面固然直观,但真正的高手往往更青睐命令行工具带来的高效与灵活。DM数据库的dlsql命令行客户端,就是这样一把被许多DBA私藏的"瑞士军刀"。 1. …...

Windows系统优化神器:Winhance中文版全面使用指南
Windows系统优化神器:Winhance中文版全面使用指南 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_CN …...

GEC6818嵌入式Linux智能车库系统开发实战
1. 项目概述这个基于GEC6818嵌入式Linux的智能车库系统,是我去年为一个商业停车场改造项目开发的解决方案。当时客户的主要痛点在于传统人工管理效率低下,经常出现收费纠纷和停车位利用率不高的问题。经过三个月的开发和调试,最终实现了这套集…...

CYBER-VISION零号协议互联网舆情智能监测与分析系统
CYBER-VISION零号协议:构建你的互联网舆情智能监测雷达 最近和几个做市场、公关的朋友聊天,他们都在抱怨同一个问题:每天花大量时间刷新闻、看社交媒体,就为了捕捉行业动态和用户反馈,生怕错过什么重要信息。人工监测…...
)
C语言文件操作:从键盘输入到文件保存的完整流程(附常见错误排查)
C语言文件操作实战:从键盘输入到文件保存的完整指南 在C语言开发中,文件操作是每个程序员必须掌握的技能。无论是保存用户配置、记录日志还是处理数据,文件读写都扮演着关键角色。本文将带你从零开始,通过一个完整的案例ÿ…...

OneMore插件:3大核心功能让OneNote效率提升300%
OneMore插件:3大核心功能让OneNote效率提升300% 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 传统笔记管理vs智能插件:效率差距在哪里&#…...

SenseVoice-Small ONNX开源方案:支持私有化部署的国产语音识别新标杆
SenseVoice-Small ONNX开源方案:支持私有化部署的国产语音识别新标杆 1. 项目简介 SenseVoice-Small ONNX是一个专为普通硬件设计的轻量化语音识别工具。基于FunASR开源框架的SenseVoiceSmall模型,通过Int8量化技术大幅降低资源消耗,让语音…...

ClawdBot优化升级:如何配置国内大模型,提升响应速度与效果
ClawdBot优化升级:如何配置国内大模型,提升响应速度与效果 1. 项目概述 ClawdBot(现更名为MoltBot)是一款开源的个人AI助手工具,它能够在本地设备上运行,通过vLLM提供后端模型能力。这个工具特别适合开发…...

弧形导轨精度等级适配策略
弧形导轨是用于实现曲线运动的线性导向装置,广泛应用于自动化设备、机器人、医疗机械等领域。弧形导轨作为机械传动中的核心部件,其精度等级直接影响设备性能与稳定性。从精密加工到重型机械,不同场景对导轨的制造精度、运行精度及耐磨性要求…...
)
别再只盯着虚短虚断!运放设计必须掌握的6个非理想参数(附MCP6N16实测数据)
运算放大器非理想特性实战指南:从理论到MCP6N16实测 在嵌入式系统设计中,运算放大器如同精密仪器中的齿轮,其微小偏差可能导致整个测量系统的崩溃。许多工程师在初期学习阶段被"虚短虚断"的理想模型所束缚,直到实际项目…...