如何使用PyTorch训练LLM
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景
像LangChain这样的库促进了上述端到端AI应用程序的实现。我们的教程介绍 LangChain for Data Engineering & Data Applications 概述了您可以使用 Langchain 做什么,包括 LangChain 解决的问题,以及数据用例的示例。
本文将解释训练大型语言模型的所有过程,从设置工作区到使用 Pytorch 2.0.1 的最终实现,Pytorch <>.<>.<> 是一个动态且灵活的深度学习框架,允许简单明了的模型实现。
先决条件
为了充分利用这些内容,重要的是要熟悉 Python 编程,对深度学习概念和转换器有基本的了解,并熟悉 Pytorch 框架。完整的源代码将在GitHub上提供。
在深入研究核心实现之前,我们需要安装和导入相关库。此外,重要的是要注意,训练脚本的灵感来自 Hugging Face 中的这个存储库。
库安装
安装过程详述如下:
首先,我们使用语句在单个单元格中运行安装命令作为 Jupyter 笔记本中的 bash 命令。%%bash
- Trl:用于通过强化学习训练转换器语言模型。
- Peft使用参数高效微调(PEFT)方法来有效地适应预训练的模型。
- Torch:一个广泛使用的开源机器学习库。
- 数据集:用于帮助下载和加载许多常见的机器学习数据集。
变形金刚:由Hugging Face开发的库,带有数千个预训练模型,用于各种基于文本的任务,如分类,摘要和翻译。
现在,可以按如下方式导入这些模块:

数据加载和准备
羊驼数据集,在拥抱脸上免费提供,将用于此插图。数据集有三个主要列:指令、输入和输出。这些列组合在一起以生成最终文本列。
加载数据集的指令在下面通过提供感兴趣的数据集的名称给出,即:tatsu-lab/alpaca

我们可以看到,结果数据位于包含两个键的字典中:
- 特点:包含主列数据
- Num_rows:对应于数据中的总行数

train_dataset的结构
可以使用以下说明显示前五行。首先,将字典转换为熊猫数据帧,然后显示行。


train_dataset的前五行
为了获得更好的可视化效果,让我们打印有关前三行的信息,但在此之前,我们需要安装库以将每行的最大字数设置为 50。第一个 print 语句用 15 个短划线分隔每个块。textwrap



前三行的详细信息
模型训练
在继续训练模型之前,我们需要设置一些先决条件:
- 预训练模型:我们将使用预训练模型Salesforce/xgen-7b-8k-base,该模型可在Hugging Face上使用。Salesforce 训练了这一系列名为 XGen-7B 的 7B LLM,对高达 8K 的序列进行了标准的密集关注,最多可获得 1.5T 代币。
- 分词器: 这是训练数据上的标记化任务所必需的。加载预训练模型和分词器的代码如下:
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)
训练配置
训练需要一些训练参数和配置,下面定义了两个重要的配置对象,一个是 TrainingArguments 的实例,一个是 LoraConfig 模型的实例,最后是 SFTTrainer 模型。
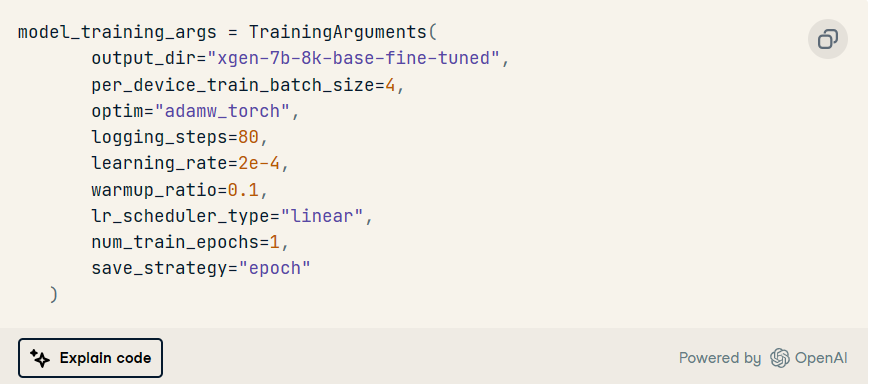
训练参数
这用于定义模型训练的参数。
在此特定场景中,我们首先使用属性定义存储训练模型的目标,然后再定义其他超参数,例如优化方法、优化方法、、 等。output_dirlearning ratenumber of epochs
洛拉康菲格
用于此方案的主要参数是 LoRA 中低秩转换矩阵的秩, 设置为 16.然后, LoRA 中其他参数的比例因子设置为 32.
此外,辍学比率为 0.05,这意味着在训练期间将忽略 5% 的输入单元。最后,由于我们正在处理一个普通语言建模,因此该任务使用属性进行初始化。CAUSAL_LM
SFTTrainer
这旨在使用训练数据、分词器和附加信息(如上述模型)来训练模型。
由于我们使用训练数据中的文本字段,因此查看分布以帮助设置给定序列中的最大令牌数非常重要。
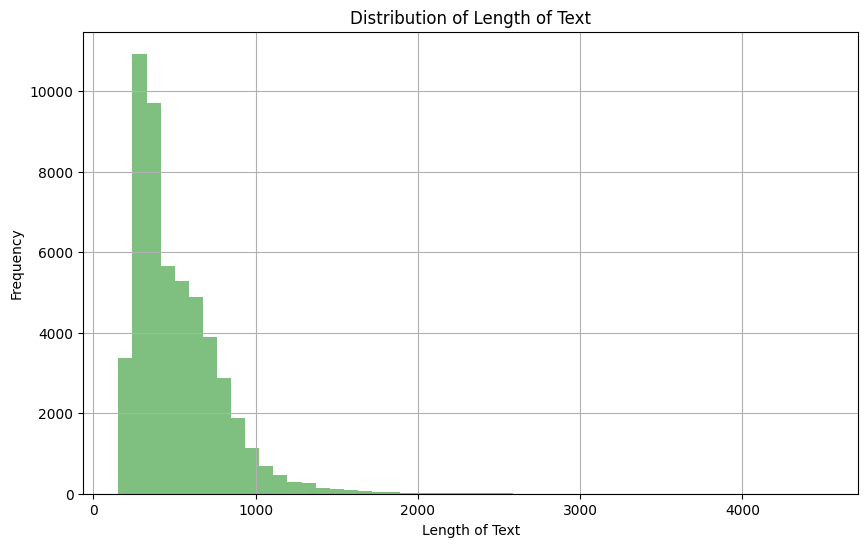
文本列长度的分布
基于上述观察,我们可以看到大多数文本的长度在 0 到 1000 之间。此外,我们可以在下面看到,只有 4.5% 的文本文档的长度大于 1024。
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")
![]()
然后,我们将序列中的最大标记数设置为 1024,以便任何比此长度的文本都被截断。

培训执行
满足所有先决条件后,我们现在可以按如下方式运行模型的训练过程:

值得一提的是,此培训是在具有GPU的云环境中进行的,这使得整个培训过程更快。但是,在本地计算机上进行培训需要更多时间才能完成。
我们的博客,在云中使用LLM与在本地运行LLM的优缺点,提供了为LLM选择最佳部署策略的关键考虑因素
让我们了解上面的代码片段中发生了什么:
- tokenizer.pad_token = tokenizer.eos_token:将填充标记设置为与句尾标记相同。
- model.resize_token_embeddings(len(tokenizer)):调整模型的标记嵌入层的大小,以匹配分词器词汇表的长度。
- model = prepare_model_for_int8_training(model):准备模型以进行 INT8 精度的训练,可能执行量化。
- model = get_peft_model(model, lora_peft_config):根据 PEFT 配置调整给定的模型。
- training_args = model_training_args:将预定义的训练参数分配给training_args。
- trainer = SFT_trainer:将 SFTTrainer 实例分配给变量训练器。
- trainer.train():根据提供的规范触发模型的训练过程。
结论
本文提供了使用 PyTorch 训练大型语言模型的明确指南。从数据集准备开始,它演练了准备先决条件、设置训练器以及最后运行训练过程的步骤。
尽管它使用了特定的数据集和预先训练的模型,但对于任何其他兼容选项,该过程应该大致相同。现在您已经了解如何训练LLM,您可以利用这些知识为各种NLP任务训练其他复杂的模型。
原文链接:如何使用PyTorch训练LLM (mvrlink.com)
相关文章:
如何使用PyTorch训练LLM
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 像LangChain这样的库促进了上述端到端AI应用程序的实现。我们的教程介绍 LangChain for Data Engineering & Data Applications 概述了您可以使用 Langchain 做什么,包括 LangChain 解决的问题…...
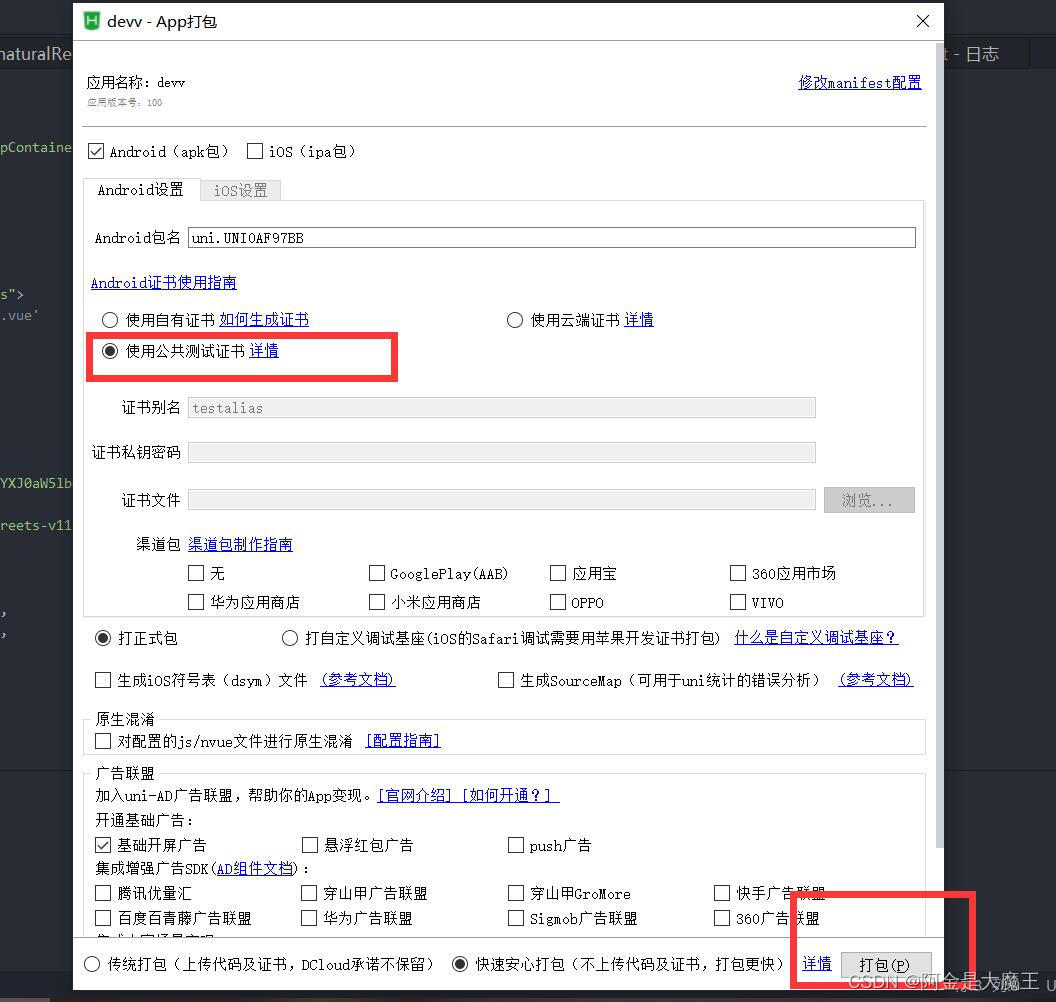
uniapp 手机 真机测试 云打包 要是没申请 可以使用云打包 然后采用 测试权限即可
uniapp 手机 真机测试 打开手机 找到手机的 版本号 点击 知道提示 (启动开发者模式) 然后 在进行usb的连接打开 运行uniapp 到手机基台 手机确认 即可 四, 云打包 要是没申请 可以使用云打包 然后采用 测试权限即可...
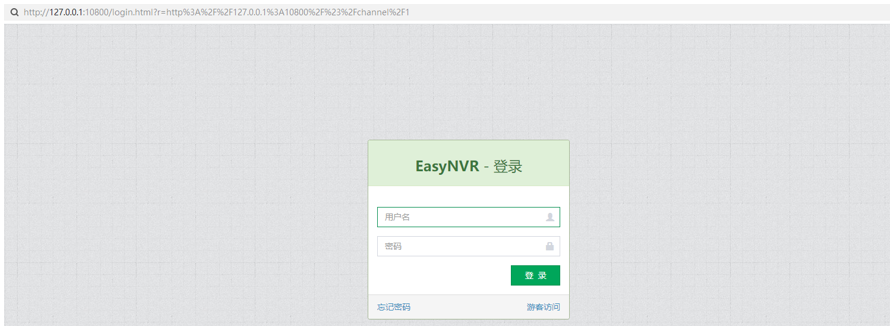
RTSP流媒体服务器EasyNVR视频平台以服务方式启动异常却无报错,该如何解决?
EasyNVR是基于RTSP/Onvif协议的安防视频云服务平台,可实现设备接入、实时直播、录像、检索与回放、云存储、视频分发、级联等视频能力服务,可覆盖全终端平台(电脑、手机、平板等终端),在智慧工厂、智慧工地、智慧社区、…...
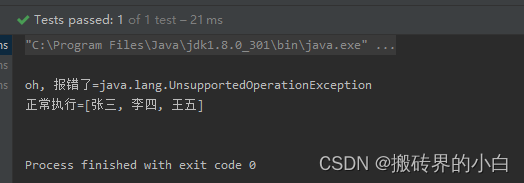
【List篇】使用Arrays.asList生成的List集合,操作add方法报错
早上到公司,刚到工位,测试同事就跑来说"功能不行了,报服务器异常了,咋回事";我一脸蒙,早饭都顾不上吃,要来了测试账号复现了一下,然后仔细观察测试服务器日志,发现报了一个…...

c++的类模板里,可以直接为静态变量赋值么?
一直以来,咱们学的是,给类模板里的静态变量赋值,要在类外面。但对于类常量,则可以直接在定义时赋值。起因是看STL源码时有这么的写法,又验证了一下。 但是在类模板里直接定义静态活动变量是不可以的,即去…...
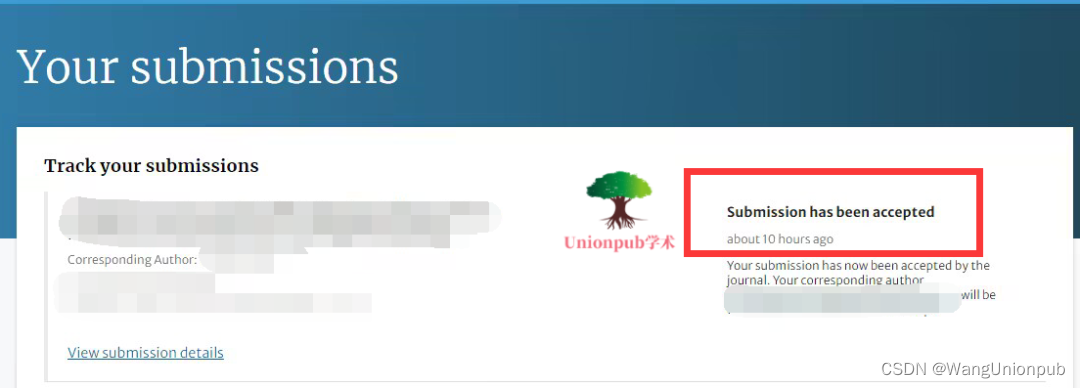
【录用案例】CCF-C类,1/2区SCIEI,3个月14天录用,30天见刊,11天检索
计算机科学类SCI&EI 【期刊简介】IF:5.5-6.0,JCR1/2区,中科院2区 【检索情况】SCI&EI 双检(CCF-C类) 【征稿领域】边缘计算、算法与机器学习的结合研究 录用案例:3个月14天录用,录用…...

qt day 3
1.完成自定义的记事本文件的保存功能 ------------------------------------------------------------------------- widget.cpp ------------------------------------------------------------------------- #include "widget.h" #include "ui_widget.h"…...
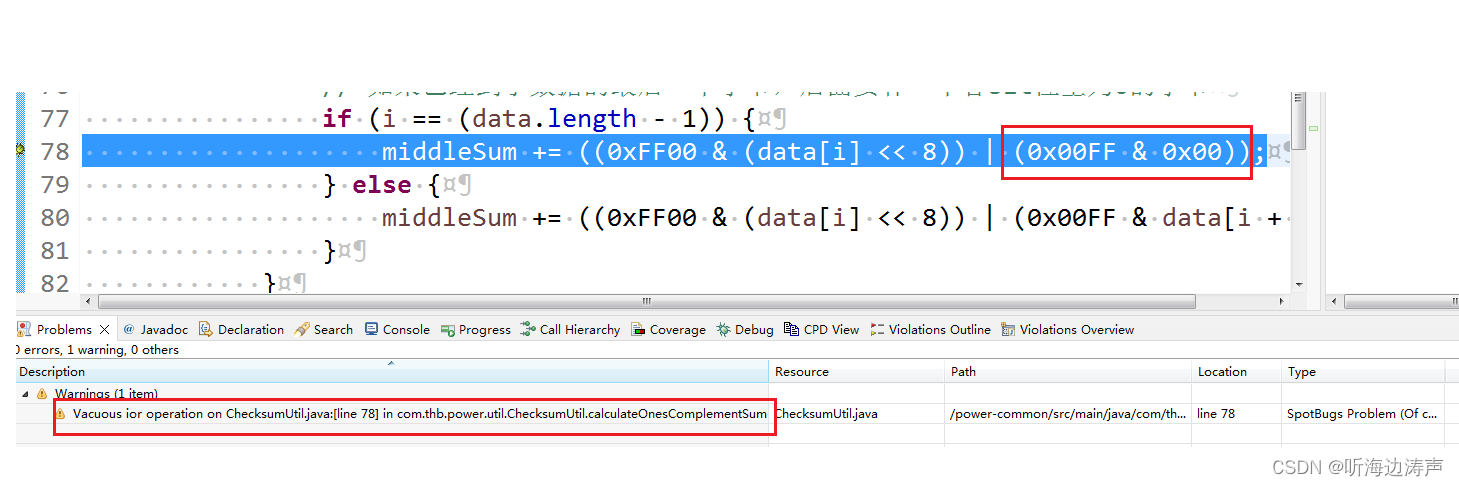
SpotBugs检查java代码:在整数上进行没有起任何实际作用的位操作(INT_VACUOUS_BIT_OPERATION)
https://spotbugs.readthedocs.io/en/latest/bugDescriptions.html#int-vacuous-bit-mask-operation-on-integer-value-int-vacuous-bit-operation 在整数上进行无用的与、异或操作,实质上没有做任何有用的工作。 例如:v & 0xffffffff 再例如&…...
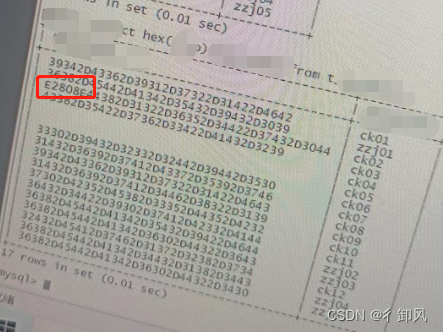
javaWeb录入数据异常,mysql显示错误
由于项目,需要输入 电脑的mac地址 ,在web页面中进行录入,但是某个同事录入一直有问题,数据查询时使用 in 或者 都查询不到 通过like %% 可以查询到,非常奇怪,请广大网友不吝赐教. 通过 toHex 进行显示发现 数据开头多了 E2808E...

Vue + Element UI 前端篇(十):动态加载菜单
Vue Element UI 实现权限管理系统 前端篇(十):动态加载菜单 动态加载菜单 之前我们的导航树都是写死在页面里的,而实际应用中是需要从后台服务器获取菜单数据之后动态生成的。 我们在这里就用上一篇准备好的数据格式Mock出模…...
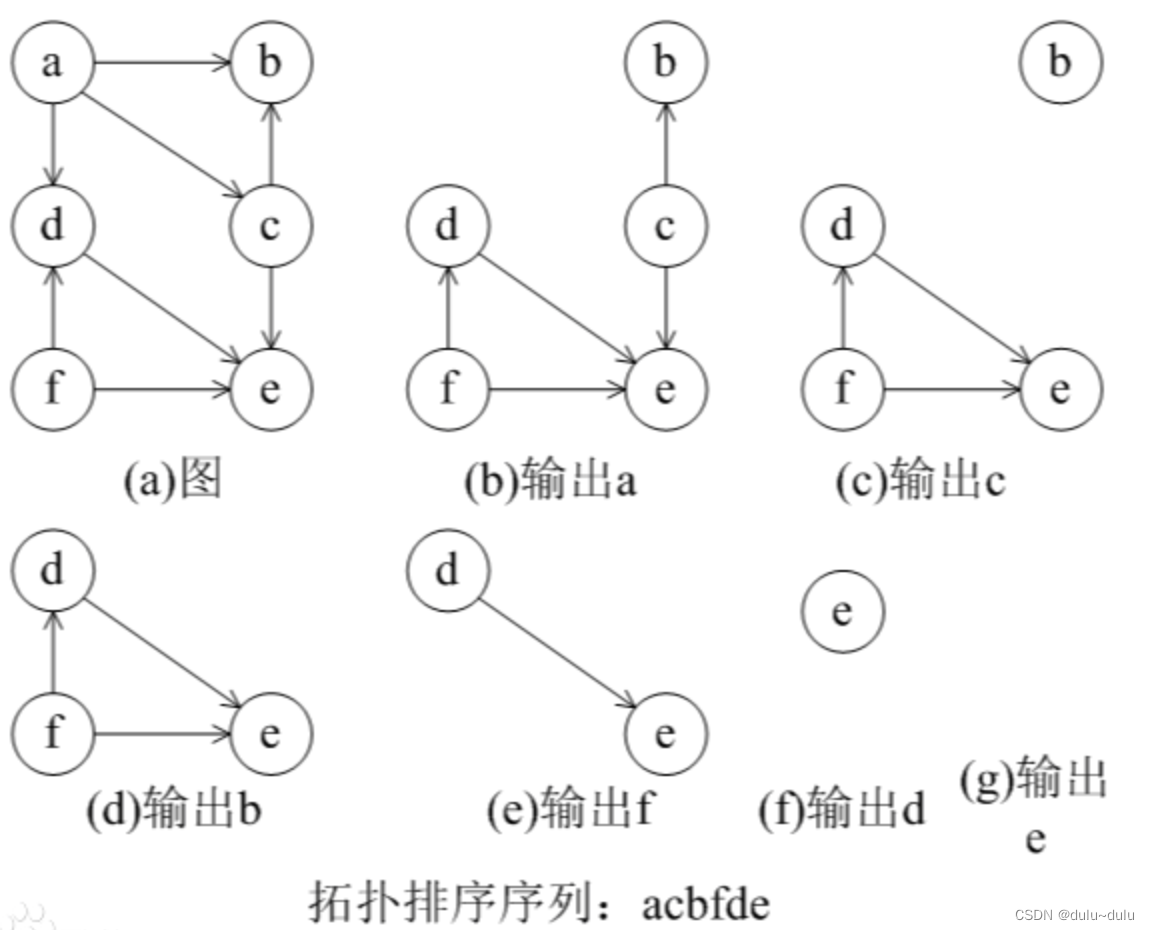
图的应用(最小生成树,最短路径,有向无环图)
目录 一.最小生成树 1.生成树 2.无向图的生成树 3.最小生成树算法 二.最短路径 1.单源最短路径---Dijkstra(迪杰斯特拉)算法 2.所有顶点间的最短路径---Floyd(弗洛伊德)算法 三.有向无环图的应用 1.AOV网(拓扑…...

python正则表达式笔记2
由 \ 和一个字符组成的特殊序列在以下列出。 如果普通字符不是ASCII数位或者ASCII字母,那么正则样式将匹配第二个字符。比如,\$ 匹配字符 $. \number 匹配数字代表的组合。每个括号是一个组合,组合从1开始编号。 比如 (.) \1 匹配 the the 或…...

matplotlib 的默认字体和默认字体系列
matplotlib 的默认字体和默认字体系列 查看默认字体和默认字体系列查看默认字体系列下包含的字体查看 plt.rcParams 设置的所有参数查看所有支持的字体格式设置默认字体方法1:方法2 今天给大家介绍一下 matplotlib 包中的默认字体以及默认字体系列。 查看默认字体和…...
STMCUBEMX_IIC_DMA_AT24C64读取和写入
STMCUBEMX_IIC_DMA_AT24C64读取和写入 说明: 1、此例程只是从硬件IIC升级到DMA读写,因为暂时存储的掉电不丢失数据不多,一页就可以够用,不用担心跨页读写的问题 2、使用DMA后,程序确实是变快了,但是也要注意…...

wsl2相关问题
磁盘空间 wsl 删除相关文件后,如删除docker 无用的容器和镜像,windows上磁盘仍然无法自动回收空间 (参考:[microsoft/WSL](https://github.com/microsoft/WSL/issues/4699#issuecomment-627133168)) # 如清除无用do…...

使用idea时,光标变成了不能按空格键,只能修改的vim格式,怎么切换回正常光标
情况1 你可能不小心启用了 IntelliJ IDEA 中的 Vim 插件。你可以尝试以下步骤来禁用它: 在 IntelliJ IDEA 中,选择 "File" -> "Settings" (如果你在 macOS 上,选择 "IntelliJ IDEA" -> &quo…...
vue+antd——实现table表格的打印——分页换行,每页都有表头——基础积累
这里写目录标题 场景效果图功能实现1:html代码功能实现2:css样式功能实现3:js代码补充内容page-break-inside 属性page-break-after属性page-break-before 属性 场景 最近在写后台管理系统时,遇到一个需求,就是要实现…...

linux C MD5计算
#include <stdio.h> #include <string.h> #include <openssl/md5.h>int main() {char str[] "Hello, world!"; // 需要计算MD5哈希值的字符串unsigned char digest[MD5_DIGEST_LENGTH]; // 存储MD5哈希值的数组MD5((unsigned char*)&str, str…...
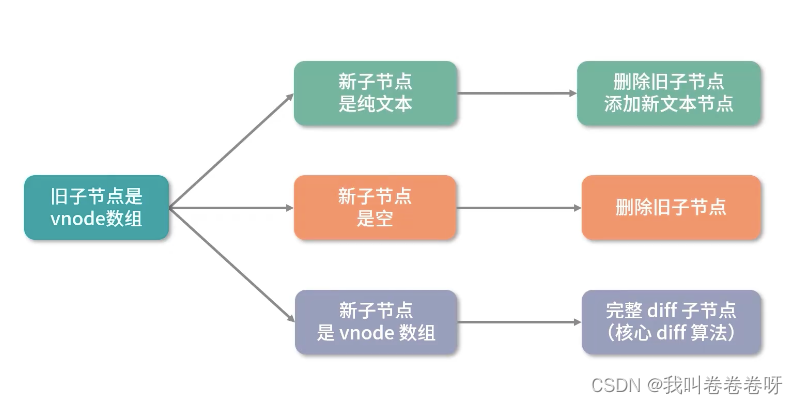
vue3学习源码笔记(小白入门系列)------ 组件更新流程
目录 说明例子processComponentcomponentUpdateFnupdateComponentupdateComponentPreRender 总结 说明 由于响应式相关内容太多,决定先接着上文组件挂载后,继续分析组件后续更新流程,先不分析组件是如何分析的。 例子 将这个 用例 使用 vi…...

数学建模B多波束测线问题B
数学建模多波束测线问题 1.问题重述: 单波束测深是一种利用声波在水中传播的技术来测量水深的方法。它通过测量从船上发送声波到声波返回所用的时间来计算水深。然而,由于它是在单一点上连续测量的,因此数据在航迹上非常密集,但…...

从原理图到实测:手把手打造Ti电量计通讯盒EV2400
1. 为什么需要自制EV2400通讯盒 搞锂电池开发的朋友应该都熟悉Ti的电量计芯片,比如bq系列。这些芯片需要通过I2C/SMBus或者HDQ接口与电脑通信,这时候就需要一个通讯盒作为桥梁。官方EV2400虽然好用,但价格实在不亲民,而且功能上可…...

2026年全国优质网站建设公司权威甄选榜,推荐十家公司官网搭建与设计制作服务商能力评估正式发布
据Gartner、QuestMobile联合发布的2026年企业数字化服务报告显示,国内网站建设行业市场规模突破1870亿元,同比增长19.3%;上海作为长三角数字经济核心枢纽,企业官网新建与升级需求同比提升27.8%,其中高端定制建站需求增…...

3分钟搞定Windows和Office激活:KMS_VL_ALL_AIO智能脚本使用指南
3分钟搞定Windows和Office激活:KMS_VL_ALL_AIO智能脚本使用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为系统激活烦恼吗?Windows提示许可证过期,…...
)
S32K312实战:用AUTOSAR Icu模块测量PWM占空比与周期(基于NXP MCAL与EB Tresos)
S32K312实战:AUTOSAR Icu模块精准测量PWM信号的工程实践 在汽车电子开发中,PWM信号的精确测量是ECU功能实现的基础环节。无论是发动机控制单元中的转速信号采集,还是车身电子中的执行器状态反馈,都需要对PWM信号的周期、占空比等参…...

seo文章生成工具的原理是什么
SEO文章生成工具的原理是什么? 随着互联网的发展,SEO(搜索引擎优化)在网站运营中的重要性愈加凸显。在这个过程中,SEO文章生成工具逐渐成为许多网站管理者的利器。这些工具究竟是如何运作的呢?本文将详细解…...

实战演练:基于快马平台,快速搭建一个软件密钥授权管理后台原型
实战演练:基于快马平台,快速搭建一个软件密钥授权管理后台原型 最近在开发一个软件授权管理系统时,发现很多项目都需要类似的密钥管理功能。正好用InsCode(快马)平台快速搭建了一个原型,以VMware16密钥管理为例,分享一…...

QGC二次开发---多机协同任务中的智能框选与指令批量下发
1. 多机协同作业的核心痛点与解决方案 在农业植保、物流配送等需要多架无人机协同作业的场景中,操作人员经常面临一个棘手问题:如何快速选择特定区域的无人机并批量下发指令?传统方法需要逐个点击无人机图标,效率低下且容易出错。…...

Cadence Virtuoso实战:从反相器原理图到GDS版图,手把手搞定你的第一个CMOS Layout
Cadence Virtuoso实战:从反相器原理图到GDS版图全流程解析 在集成电路设计领域,从原理图到物理版图的实现是一个充满挑战又极具成就感的过程。对于初入行的工程师或微电子专业学生来说,掌握Cadence Virtuoso工具链的完整工作流程,…...

避开原子操作坑!Keil AC5移植LwRB 3.0.0的保姆级避坑指南
避开原子操作坑!Keil AC5移植LwRB 3.0.0的保姆级避坑指南 在嵌入式开发中,环形缓冲区(Ring Buffer)是一种常见的数据结构,广泛应用于串口通信、DMA传输等场景。LwRB(Lightweight Ring Buffer)作…...

DeerFlow免费开源:字节跳动出品,个人研究者的强大AI工具
DeerFlow免费开源:字节跳动出品,个人研究者的强大AI工具 1. 项目概述 DeerFlow是由字节跳动公司开源的一款深度研究辅助工具,基于LangStack技术框架开发。这个项目通过整合语言模型、网络搜索和Python代码执行等能力,为个人研究…...