python正则表达式笔记2
由 '\' 和一个字符组成的特殊序列在以下列出。
如果普通字符不是ASCII数位或者ASCII字母,那么正则样式将匹配第二个字符。比如,\$ 匹配字符 '$'.
\number
匹配数字代表的组合。每个括号是一个组合,组合从1开始编号。
比如 (.+) \1 匹配 'the the' 或者 '55 55', 但不会匹配 'thethe' (注意组合后面的空格)。
这个特殊序列只能用于匹配前面99个组合。
如果 number 的第一个数位是0, 或者 number 是三个八进制数,它将不会被看作是一个组合,而是八进制的数字值。
在 '[' 和 ']' 字符集合内,任何数字转义都被看作是字符。
print('============================')
# 保留中间空格,左右重复字符串,其他数据排除
str_list1 = ['python python', 'python java', 'helloworld', '2023 2023', '20221212']
get_list1 = []
for ss in str_list1:# 查找匹配的字符, 注意组合后面的空格, \1 代表重复前面括号组合规则(.+)if re.search(r"(.+) \1", ss):print('保留')get_list1.append(ss)else:print('去除')continue
print(get_list1)
# ['python python', '2023 2023']
print('============================')\A
只匹配字符串开始。
\Z
只匹配字符串结尾。
print('============================')
# 保留数字或小数的金额格式数据,其他数据排除
str_list2 = ['5005', '200.85', '¥12450', '¥100.50', '张三', '2023.08.09']
get_list2 = []
for ss in str_list2:# 查找匹配的字符,下面方法等价匹配if re.search(r'\A\d+\.?\d*\Z', ss):# if re.search(r'(\A\d+\.?\d*\Z)', ss):# if re.search(r'(^\d+\.?\d*$)', ss):# if re.search(r'^\d+\.?\d*$', ss):# if re.fullmatch(r'\d+\.?\d*', ss):print('保留')get_list2.append(ss)else:print('去除')continue
print(get_list2)
# ['5005', '200.85', '¥12450', '¥100.50']
print('============================')\b
匹配空字符串,但只在单词开始或结尾的位置。一个单词被定义为一个单词字符的序列。
注意,通常 \b 定义为 \w 和 \W 字符之间,或者 \w 和字符串开始/结尾的边界,
意思就是 r'\bfoo\b' 匹配 'foo', 'foo.', '(foo)', 'bar foo baz' 但不匹配 'foobar' 或者 'foo3'。
默认情况下,Unicode字母和数字是在Unicode样式中使用的,但是可以用 ASCII 标记来更改。
如果 LOCALE 标记被设置的话,词的边界是由当前语言区域设置决定的,\b 表示退格字符,以便与Python字符串文本兼容。
print('============================')
str_list3 = ['foo', 'foo.', '(foo)', 'bar foo baz', 'foobar', 'foo3']
for ss in str_list3:# 查找匹配的字符print(re.search(r'\bfoo\b', ss))
print('============================')
'''
<re.Match object; span=(0, 3), match='foo'>
<re.Match object; span=(0, 3), match='foo'>
<re.Match object; span=(1, 4), match='foo'>
<re.Match object; span=(4, 7), match='foo'>
None
None
'''
\B
匹配空字符串,但不能在词的开头或者结尾。
意思就是 r'py\B' 匹配 'python', 'py3', 'py2', 但不匹配 'py', 'py.', 或者 'py!'.
\B 是 \b 的取非,所以Unicode样式的词语是由Unicode字母,数字或下划线构成的,
虽然可以用 ASCII 标志来改变。如果使用了 LOCALE 标志,则词的边界由当前语言区域设置。
print('============================')
str_list3 = ['python', 'py3', 'py2', 'py', 'py.', 'py!']
for ss in str_list3:# 查找匹配的字符print(re.search(r'py\B', ss))
print('============================')
'''
<re.Match object; span=(0, 2), match='py'>
<re.Match object; span=(0, 2), match='py'>
<re.Match object; span=(0, 2), match='py'>
None
None
None
'''\d
1, 对于 Unicode (str) 样式:
匹配任何Unicode十进制数(就是在Unicode字符目录[Nd]里的字符)。
这包括了 [0-9] ,和很多其他的数字字符。如果设置了 ASCII 标志,就只匹配 [0-9] 。
2, 对于8位(bytes)样式:
匹配任何十进制数,就是 [0-9]。
\D
匹配任何非十进制数字的字符。
就是 \d 取非。 如果设置了 ASCII 标志,就相当于 [^0-9] 。
print('============================')
string = '(python)-12345'
# 提取全部数字字符
nums_str = ''.join(re.findall(r'\d', string))
print(nums_str)
# 12345
# 提取全部非数字字符
char_str = ''.join(re.findall(r'\D', string))
print(char_str)
# (python)-
print('============================')\s
1, 对于 Unicode (str) 样式:
匹配任何Unicode空白字符(包括 [ \t\n\r\f\v] ,还有很多其他字符,比如不同语言排版规则约定的不换行空格)。
如果 ASCII 被设置,就只匹配 [ \t\n\r\f\v] 。
2, 对于8位(bytes)样式:
匹配ASCII中的空白字符,就是 [ \t\n\r\f\v] 。
\S
匹配任何非空白字符。
就是 \s 取非。如果设置了 ASCII 标志,就相当于 [^ \t\n\r\f\v] 。
\w
1, 对于 Unicode (str) 样式:
匹配 Unicode 单词类字符;这包括字母数字字符 (如 str.isalnum() 所定义的) 以及下划线 (_)。
如果使用了 ASCII 旗标,则将只匹配 [a-zA-Z0-9_]。
2, 对于8位(bytes)样式:
匹配ASCII字符中的数字和字母和下划线,就是 [a-zA-Z0-9_] 。
如果设置了 LOCALE 标记,就匹配当前语言区域的数字和字母和下划线。
\W
匹配非单词字符的字符。
这与 \w 正相反。如果使用了 ASCII 旗标,这就等价于 [^a-zA-Z0-9_]。
如果使用了 LOCALE 旗标,则会匹配当前区域中既非字母数字也非下划线的字符。
'''
r'''
绝大部分Python的标准转义字符也被正则表达式分析器支持。:
\a \b \f \n
\N \r \t \u
\U \v \x \\
'''
print('============================')
string = '(python)-12345\t \n \r|张三'
# 提取全部空白字符
blank_str = re.findall(r'\s', string)
print(blank_str)
# ['\t', ' ', '\n', ' ', '\r']# 提取全部非空白字符
no_blank_str = ''.join(re.findall(r'\S', string))
print(no_blank_str)
# (python)-12345|张三# 匹配 Unicode 单词类字符
un_str = ''.join(re.findall(r'\w', string))
print(un_str)
# python12345张三# 匹配非单词字符的字符
no_un_str = re.findall(r'\W', string)
print(no_un_str)
# ['(', ')', '-', '\t', ' ', '\n', ' ', '\r', '|']
print('============================')正则表达式实战笔记
print('=============正则表达式实战笔记===============')string1 = 'home/workspace/python/test.py'
# 去除最后/后面文件名,只保留路径,以下几个方法等价匹配
# print(re.sub(r'test.py', '', string1))
# print(re.sub(r'([a-z]{4}.py$)', '', string1))
print(re.sub(r'(\b[a-z]{4}.py\b)', '', string1))
# 只保留文件名
print(''.join(re.findall(r'(\b[a-z]{4}.py\b)',string1)))url_str = 'https://www.abcxyz.com/861091450/28240726.html'
# 去除最后/后面数字+.html,保留前面的url地址
print(re.sub(r'(\d+\.html\b)', '', url_str))string2 = "5,000.00伍仟元整"
# 提取数字金额
amount = re.findall(r'\d+\.?\d*', string2)
amount = ''.join(amount)
print("数字金额:", amount)
# 提取中文
ch_amount = re.findall(r'[\u4e00-\u9fa5]', string2)
ch_amount = ''.join(ch_amount)
print("中文金额:", ch_amount)# 下面列表元素有1-2个字错误,现在全部替换成统一数据
str_list3 = ['铜鼓县', '刚鼓县', '钢鼓县', '同古县', '铜古县', '铜故县']
for i in range(len(str_list3)):# 匹配替换的字符str_list3[i] = re.sub(r"(.鼓县)|(同古县)|(铜.县)", "铜鼓县", str_list3[i])
print(str_list3)
# ['铜鼓县', '铜鼓县', '铜鼓县', '铜鼓县', '铜鼓县', '铜鼓县']
print('============================')work_date = '610012 星期二 : 2023-06-12 14:23:30 1.0212'
# 只取日期数据 : 2023-06-12
work_date = re.findall(r'\d{4}-\d{1,2}-\d{1,2}',work_date)[0]
print(work_date)str_url = 'https://www.abcxyz.com/60abc12.html'
# 提取url中间的代码数据 : 60abc12
str_code = re.findall(r'https://www.abcxyz.com/(.*?).html', str_url)[0]
print(str_code)相关文章:

python正则表达式笔记2
由 \ 和一个字符组成的特殊序列在以下列出。 如果普通字符不是ASCII数位或者ASCII字母,那么正则样式将匹配第二个字符。比如,\$ 匹配字符 $. \number 匹配数字代表的组合。每个括号是一个组合,组合从1开始编号。 比如 (.) \1 匹配 the the 或…...

matplotlib 的默认字体和默认字体系列
matplotlib 的默认字体和默认字体系列 查看默认字体和默认字体系列查看默认字体系列下包含的字体查看 plt.rcParams 设置的所有参数查看所有支持的字体格式设置默认字体方法1:方法2 今天给大家介绍一下 matplotlib 包中的默认字体以及默认字体系列。 查看默认字体和…...
STMCUBEMX_IIC_DMA_AT24C64读取和写入
STMCUBEMX_IIC_DMA_AT24C64读取和写入 说明: 1、此例程只是从硬件IIC升级到DMA读写,因为暂时存储的掉电不丢失数据不多,一页就可以够用,不用担心跨页读写的问题 2、使用DMA后,程序确实是变快了,但是也要注意…...

wsl2相关问题
磁盘空间 wsl 删除相关文件后,如删除docker 无用的容器和镜像,windows上磁盘仍然无法自动回收空间 (参考:[microsoft/WSL](https://github.com/microsoft/WSL/issues/4699#issuecomment-627133168)) # 如清除无用do…...

使用idea时,光标变成了不能按空格键,只能修改的vim格式,怎么切换回正常光标
情况1 你可能不小心启用了 IntelliJ IDEA 中的 Vim 插件。你可以尝试以下步骤来禁用它: 在 IntelliJ IDEA 中,选择 "File" -> "Settings" (如果你在 macOS 上,选择 "IntelliJ IDEA" -> &quo…...
vue+antd——实现table表格的打印——分页换行,每页都有表头——基础积累
这里写目录标题 场景效果图功能实现1:html代码功能实现2:css样式功能实现3:js代码补充内容page-break-inside 属性page-break-after属性page-break-before 属性 场景 最近在写后台管理系统时,遇到一个需求,就是要实现…...

linux C MD5计算
#include <stdio.h> #include <string.h> #include <openssl/md5.h>int main() {char str[] "Hello, world!"; // 需要计算MD5哈希值的字符串unsigned char digest[MD5_DIGEST_LENGTH]; // 存储MD5哈希值的数组MD5((unsigned char*)&str, str…...
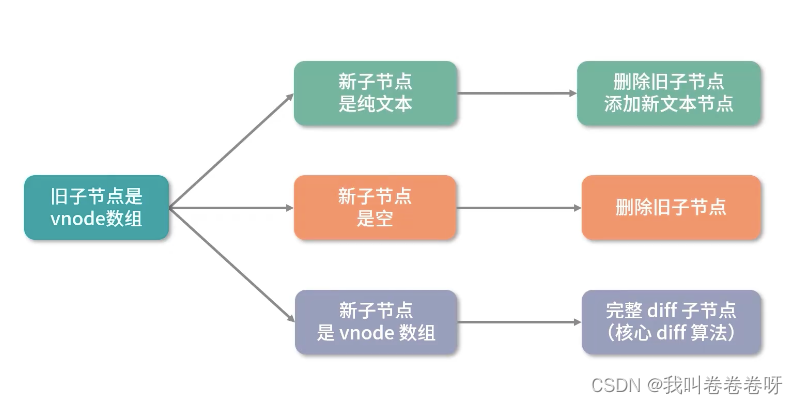
vue3学习源码笔记(小白入门系列)------ 组件更新流程
目录 说明例子processComponentcomponentUpdateFnupdateComponentupdateComponentPreRender 总结 说明 由于响应式相关内容太多,决定先接着上文组件挂载后,继续分析组件后续更新流程,先不分析组件是如何分析的。 例子 将这个 用例 使用 vi…...

数学建模B多波束测线问题B
数学建模多波束测线问题 1.问题重述: 单波束测深是一种利用声波在水中传播的技术来测量水深的方法。它通过测量从船上发送声波到声波返回所用的时间来计算水深。然而,由于它是在单一点上连续测量的,因此数据在航迹上非常密集,但…...

Pytest 框架执行用例流程浅谈
背景: 根据以下简单的代码示例,我们将从源码的角度分析其中的关键加载执行步骤,对pytest整体流程架构有个初步学习。 代码示例: import pytest def test_add(): assert 1 1 2 def test_sub(): assert 2 - 1 1 通过 pytes…...

C#__资源访问冲突和死锁问题
/// 线程的资源访问冲突:多个线程同时申请一个资源,造成读写错乱。 /// 解决方案:上锁,lock{执行的程序段}:同一时刻,只允许一个线程访问该程序段。 /// 死锁问题: /// 程序中的锁过多…...

机器学习——Logistic Regression
0、前言: Logistic回归是解决分类问题的一种重要的机器学习算法模型 1、基本原理: Logistic Regression 首先是针对二分类任务提出的一种分类方法如果将概率看成一个数值属性,则二元分类问题的概率预测就可以转化为一个回归问题。这种思路最…...

创建husky规范前端项目
创建husky规范前端项目 .husky文件是一个配置文件,用于配置Git钩子。Git钩子是在Git操作时触发的脚本,可以用于自动化一些任务,比如代码格式化、代码检查、测试等。.husky文件可以指定在Git的不同操作(如commit、push等ÿ…...

深浅拷贝与赋值
数据类型 数据类型 在JavaScript中,数据类型有两大类。一类是基本数据类型,一类是引用数据类型。 基本数据类型有六种:number、string、boolean、null、undefined、symbol。 基本数据类型存放在栈中。存放在栈中的数据具有数据大小确定&a…...

bert ranking pairwise demo
下面是用bert 训练pairwise rank 的 demo import torch from torch.utils.data import DataLoader, Dataset from transformers import BertModel, BertTokenizer from sklearn.metrics import pairwise_distances_argmin_minclass PairwiseRankingDataset(Dataset):def __ini…...
GPT引领前沿与应用突破之GPT4科研实践技术与AI绘图
GPT对于每个科研人员已经成为不可或缺的辅助工具,不同的研究领域和项目具有不同的需求。例如在科研编程、绘图领域:1、编程建议和示例代码: 无论你使用的编程语言是Python、R、MATLAB还是其他语言,都可以为你提供相关的代码示例。2、数据可视…...
SpringBoot整合Swagger3
前言 swagger是啥,是干什么的,有什么用,我想在这里我就不用介绍了,下面直接代码演示。 添加依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0…...

detectron2 install path
>>> import detectron2 >>> detectron2_path detectron2.__file__ >>> print(detectron2.__file__)...
如何将DHTMLX Suite集成到Scheduler Lightbox中?让项目管理更可控!
在构建JavaScript调度器时,通常需要为最终用户提供一个他们喜欢的方式来计划事件,这是Web开发人员喜欢认可DHTMLX Scheduler的重要原因,它在这方面提供了完全的操作自由,它带有lightbox弹出窗口,允许通过各种控件动态更…...
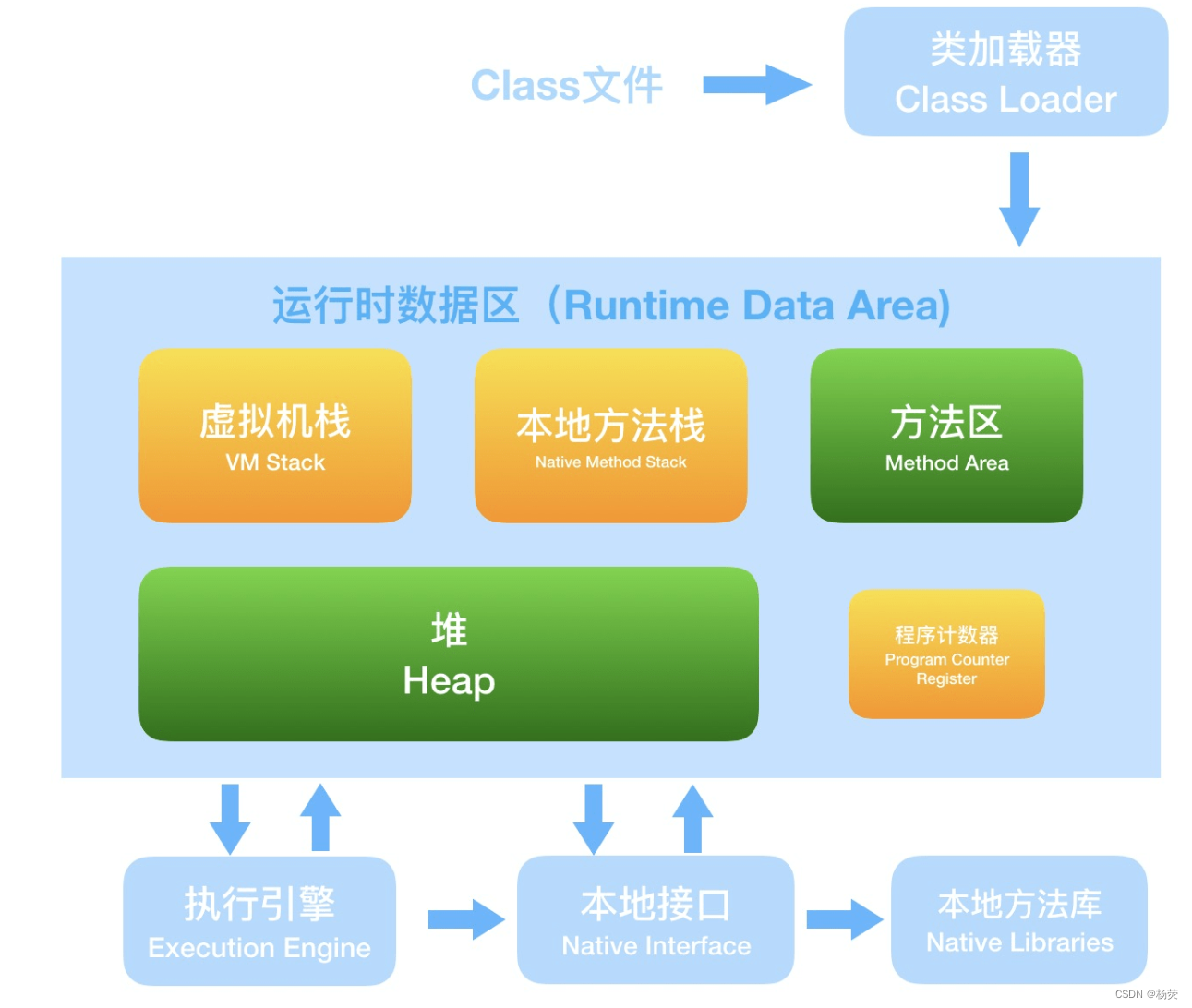
什么是JVM常用调优策略?分别有哪些?
目录 一、JVM调优 二、堆内存大小调整 三、垃圾回收器调优 四、线程池调优 一、JVM调优 Java虚拟机(JVM)的调优主要是为了提高应用程序的性能,包括提高应用程序的响应速度和吞吐量。以下是一些常用的JVM调优策略: 堆内存大小…...

Java开发者必看:Istio 1.22正式弃用Mixer后,Prometheus指标丢失、日志脱节、Tracing断链问题的90分钟极速修复方案
第一章:Java开发者必看:Istio 1.22正式弃用Mixer后,Prometheus指标丢失、日志脱节、Tracing断链问题的90分钟极速修复方案Istio 1.22 彻底移除了 Mixer 组件,导致依赖其适配器模型的遥测采集链路全面失效。Java 应用在启用 Istio …...

手把手教你用Python实现熵权PCA:从数据清洗到可视化,一个案例全讲透
用Python实战熵权PCA:电商商品竞争力分析全流程解析 在电商平台的海量商品中,如何快速识别出真正具有竞争力的产品?传统的人工筛选方式不仅效率低下,还容易受到主观偏见的影响。本文将带你用Python实现一个完整的熵权PCA分析流程&…...

手把手教你:5分钟为你的静态网站嵌入AnythingLLM智能聊天机器人
5分钟为静态网站集成AnythingLLM智能聊天室的实战指南 你是否想过在自己的个人博客或产品官网上添加一个能回答访客问题的AI助手?就像那些科技公司官网右下角弹出的智能客服一样。今天我要分享的,是如何用AnythingLLM在5分钟内为任何静态网站嵌入一个私有…...

收藏必备!小白程序员快速入门RAG,轻松提升大模型生成效果与准确性
RAG(检索增强生成)是一种提升大模型生成内容准确性和时效性的技术框架。通过从外部知识库检索信息,再将检索结果与大模型结合,有效解决大模型知识过时和幻觉问题。RAG流程包括知识嵌入存储、相似度检索和增强生成三个核心环节&…...

手把手教你:Trae 中不写一行代码,一句话实现增删查改
1. 下载并运行 RuoYi 项目 基于您提供的下载地址和操作步骤,流程如下: 1.1. 下载 RuoYi 项目 官网地址:如链接3所示,RuoYi的官方网址是 https://www.ruoyi.vip/。 下载:在官网,您可以根据需要下载不同版…...

银河麒麟V10下NFS服务端的高效配置与性能优化指南
1. 银河麒麟V10与NFS服务端基础认知 第一次在银河麒麟V10上折腾NFS服务端时,我踩了不少坑。这个国产操作系统虽然基于Linux,但在软件包管理和服务配置上还是有些特殊之处。NFS(Network File System)作为经典的网络共享协议&#x…...
:操作 DOM 与子组件实例 从入门到精通)
Vue3 模板引用 (ref):操作 DOM 与子组件实例 从入门到精通
前言 在 Vue 的数据驱动思想下,我们通常通过修改数据来驱动视图更新,避免直接操作 DOM。但在实际开发中,总会遇到一些非 DOM 不可的场景:比如获取输入框焦点、调用第三方库初始化画布、获取子组件的数据或方法等。 这时候…...

SpringBoot整合poi-tl实战:如何优雅导出带动态表格和图片的Word并自动压缩成zip
SpringBoot与poi-tl深度整合:企业级Word动态导出与智能压缩方案 在企业级应用开发中,批量生成结构化的Word文档(如报告、合同等)并打包分发的需求日益普遍。传统方案往往面临动态内容渲染复杂、性能瓶颈明显、文件管理混乱等痛点。…...

【esp32使用jtag下载和调试 Can‘t perform JTAG flash, because OpenOCD server is not running!】
ESP-IDF使用USB的JTAG下载调试时报错现象。 2026年初尝试了很多方法jtag下载,网上很多资料都有问题,以下实操烧录成功过程记录。 提示: Can’t perform JTAG flash, because OpenOCD server is not running! ❌ Error: libusb_open() faile…...

App启动总览
特征 / 步骤 冷启动 (Cold Start) 温启动 (Warm Start) 热启动 (Hot Start) 速度 最慢 🐢 中等 🏃 最快 🚀 进程创建 ✅ 需要 ❌ 跳过 ❌ 跳过 Application.onCreate() ✅ 需要调用 ❌ 跳过 ❌ 跳过 Activity.onCreate() ✅ 需要调用 ✅ 需要调用 ❌ 跳过 Activity.onSta…...