Spark 6:Spark SQL DataFrame
SparkSQL 是Spark的一个模块, 用于处理海量结构化数据。

SparkSQL是用于处理大规模结构化数据的计算引擎
SparkSQL在企业中广泛使用,并性能极好
SparkSQL:使用简单、API统一、兼容HIVE、支持标准化JDBC和ODBC连接
SparkSQL 2014年正式发布,当下使用最多的2.0版Spark发布于2016年,当下使用的最新3.0办发布于2019年
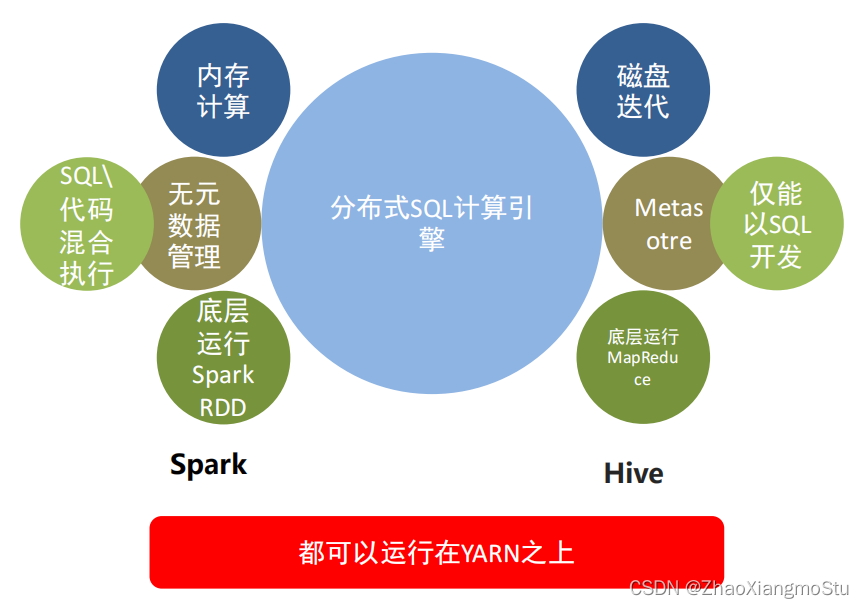
SparkSQL和Hive的异同
Hive和Spark 均是:“分布式SQL计算引擎”。均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。
SparkSQL的数据抽象
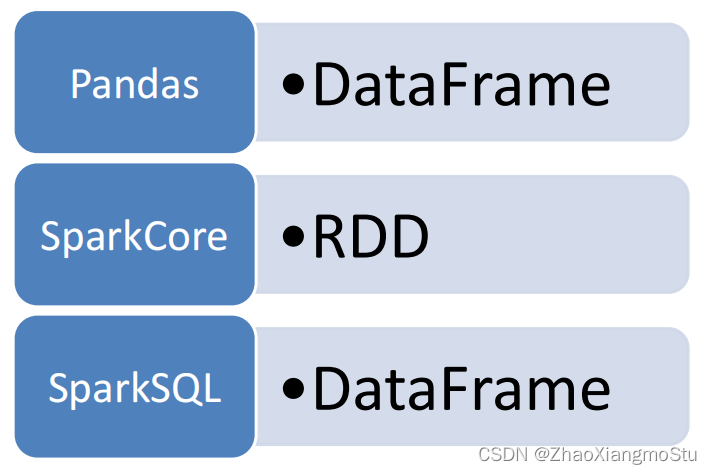
Pandas - DataFrame
• 二维表数据结构
• 单机(本地)集合
SparkCore - RDD
• 无标准数据结构,存储什么数据均可
• 分布式集合(分区)
SparkSQL - DataFrame
• 二维表数据结构
• 分布式集合(分区)

SparkSQL 其实有3类数据抽象对象
• SchemaRDD对象(已废弃)
• DataSet对象:可用于Java、Scala语言
• DataFrame对象:可用于Java、Scala、Python、R
以Python开发SparkSQL,主要使用的就是DataFrame对象作为核心数据结构
DataFrame概述
RDD:有分区的、弹性的、分布式的、存储任意结构数据
DataFrame:有分区的、弹性的、分布式的、存储二维表结构数据
DataFrame和RDD都是:弹性的、分布式的、数据集。只是,DataFrame存储的数据结构“限定”为:二维表结构化数据;而RDD可以存储的数据则没有任何限制,想处理什么就处理什么。
假定有如下数据集
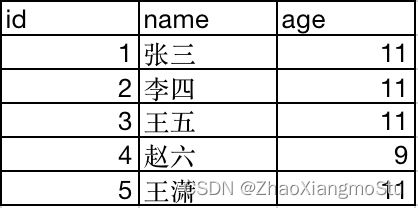
DataFrame按二维表格存储

RDD按数组对象存储

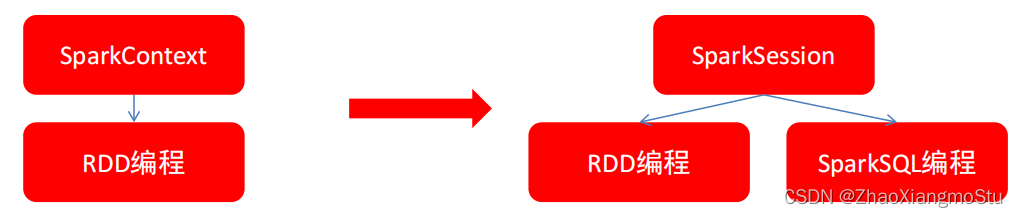
SparkSession对象
在RDD阶段,程序的执行入口对象是: SparkContext
在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象。
SparkSession对象可以:
- 用于SparkSQL编程作为入口对象
- 用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext
所以,后续的代码,执行环境入口对象,统一变更为SparkSession对象
构建SparkSession核心代码
有如下数据集:列1ID,列2学科,列3分数

数据集文件:资料\data\sql\stu_score.txt
需求:读取文件,找出学科为“语文”的数据,并限制输出5条where subject = '语文' limit 5
代码如下:
# coding:utf8# SparkSession对象的导包, 对象是来自于 pyspark.sql包中
from pyspark.sql import SparkSessionif __name__ == '__main__':# 构建SparkSession执行环境入口对象spark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()# 通过SparkSession对象 获取 SparkContext对象sc = spark.sparkContext# SparkSQL的HelloWorlddf = spark.read.csv("../data/input/stu_score.txt", sep=',', header=False)df2 = df.toDF("id", "name", "score")df2.printSchema()df2.show()df2.createTempView("score")# SQL 风格spark.sql("""SELECT * FROM score WHERE name='语文' LIMIT 5""").show()# DSL 风格df2.where("name='语文'").limit(5).show()
SparkSQL 和 Hive同样,都是用于大规模SQL分布式计算的计算框架,均可以运行在YARN之上,在企业中广泛被应用。
SparkSQL的数据抽象为:SchemaRDD(废弃)、DataFrame(Python、R、Java、Scala)、DataSet(Java、Scala)。
DataFrame同样是分布式数据集,有分区可以并行计算,和RDD不同的是,DataFrame中存储的数据结构是以表格形式组织的,方便进行SQL计算。
DataFrame对比DataSet基本相同,不同的是DataSet支持泛型特性,可以让Java、Scala语言更好的利用到。
SparkSession是2.0后退出的新执行环境入口对象,可以用于RDD、SQL等编程。
DataFrame的组成
DataFrame是一个二维表结构, 那么表格结构就有无法绕开的三个点:
• 行
• 列
• 表结构描述
比如,在MySQL中的一张表:
• 由许多行组成
• 数据也被分成多个列
• 表也有表结构信息(列、列名、列类型、列约束等)
基于这个前提,DataFrame的组成如下:
在结构层面:
- StructType对象描述整个DataFrame的表结构
- StructField对象描述一个列的信息
在数据层面:
- Row对象记录一行数据
- Column对象记录一列数据并包含列的信息
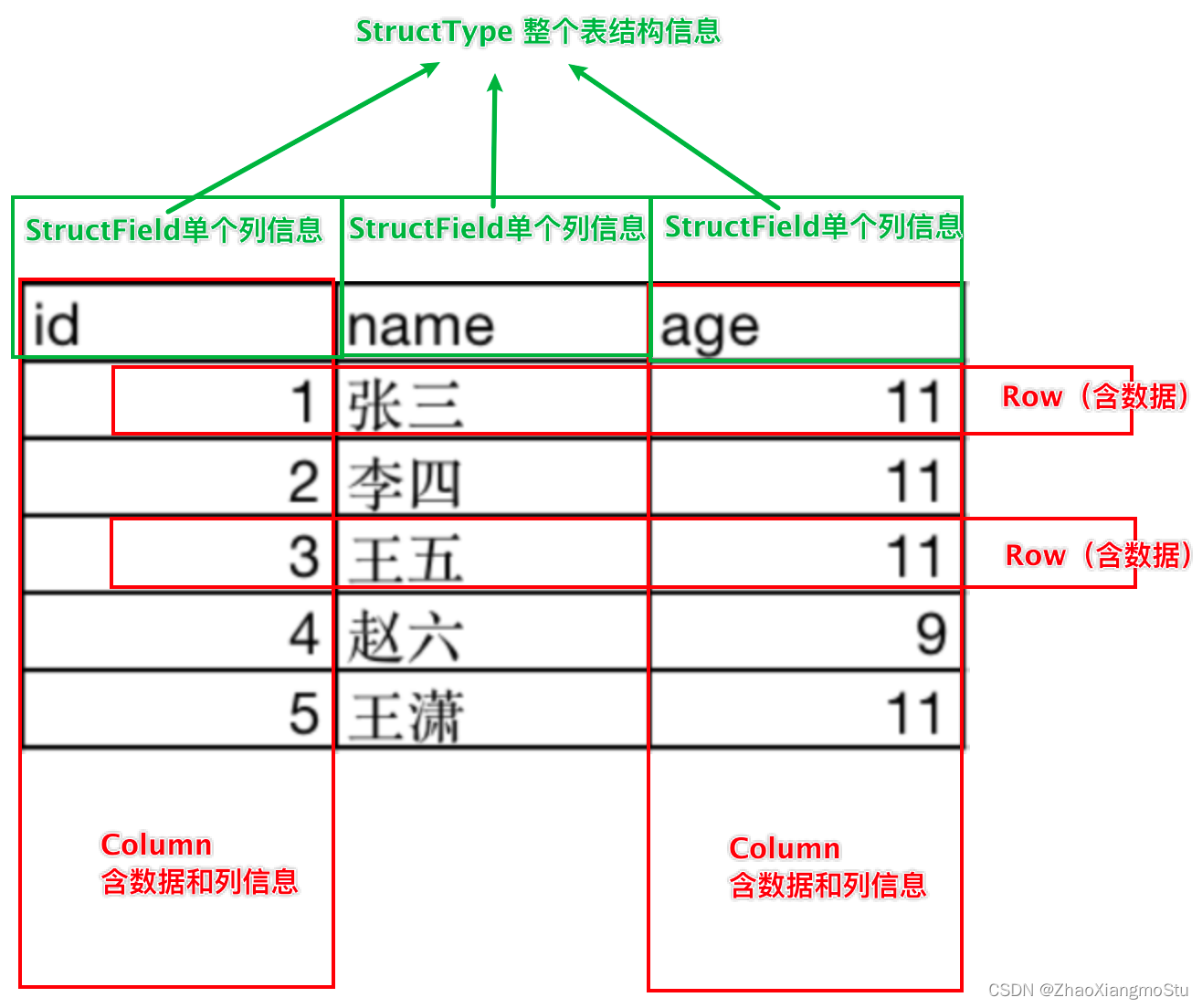
如图, 在表结构层面,DataFrame的表结构由:
StructType描述,如下图

一个StructField记录:列名、列类型、列是否运行为空
多个StructField组成一个StructType对象。
一个StructType对象可以描述一个DataFrame:有几个列、每个列的名字和类型、每个列是否为空。同时,一行数据描述为Row对象,如Row(1, 张三, 11)
一列数据描述为Column对象,Column对象包含一列数据和列的信息
DataFrame的代码构建 - 基于RDD方式1
DataFrame对象可以从RDD转换而来,都是分布式数据集,其实就是转换一下内部存储的结构,转换为二维表结构。
通过SparkSession对象的createDataFrame方法来将RDD转换为DataFrame
这里只传入列名称,类型从RDD中进行推断,是否允许为空默认为允许(True)
# coding:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 基于RDD转换成DataFramerdd = sc.textFile("../data/input/sql/people.txt").\map(lambda x: x.split(",")).\map(lambda x: (x[0], int(x[1])))# 构建DataFrame对象# 参数1 被转换的RDD# 参数2 指定列名, 通过list的形式指定, 按照顺序依次提供字符串名称即可df = spark.createDataFrame(rdd, schema=['name', 'age'])# 打印DataFrame的表结构df.printSchema()# 打印df中的数据# 参数1 表示 展示出多少条数据, 默认不传的话是20# 参数2 表示是否对列进行截断, 如果列的数据长度超过20个字符串长度, 后续的内容不显示以...代替# 如果给False 表示不阶段全部显示, 默认是Truedf.show(20, False)# 将DF对象转换成临时视图表, 可供sql语句查询df.createOrReplaceTempView("people")spark.sql("SELECT * FROM people WHERE age < 30").show()
DataFrame的代码构建 - 基于RDD方式2
通过StructType对象来定义DataFrame的“表结构”转换RDD
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 基于RDD转换成DataFramerdd = sc.textFile("../data/input/sql/people.txt").\map(lambda x: x.split(",")).\map(lambda x: (x[0], int(x[1])))# 构建表结构的描述对象: StructType对象schema = StructType().add("name", StringType(), nullable=True).\add("age", IntegerType(), nullable=False)# 基于StructType对象去构建RDD到DF的转换df = spark.createDataFrame(rdd, schema=schema)df.printSchema()df.show()
使用RDD的toDF方法转换RDD
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 基于RDD转换成DataFramerdd = sc.textFile("../data/input/sql/people.txt").\map(lambda x: x.split(",")).\map(lambda x: (x[0], int(x[1])))# toDF的方式构建DataFramedf1 = rdd.toDF(["name", "age"])df1.printSchema()df1.show()# toDF的方式2 通过StructType来构建schema = StructType().add("name", StringType(), nullable=True).\add("age", IntegerType(), nullable=False)df2 = rdd.toDF(schema=schema)df2.printSchema()df2.show()
将Pandas的DataFrame对象,转变为分布式的SparkSQL DataFrame对象
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 基于Pandas的DataFrame构建SparkSQL的DataFrame对象pdf = pd.DataFrame({"id": [1, 2, 3],"name": ["张大仙", "王晓晓", "吕不为"],"age": [11, 21, 11]})df = spark.createDataFrame(pdf)df.printSchema()df.show()
DataFrame的代码构建 - 读取外部数据
通过SparkSQL的统一API进行数据读取构建DataFrame
统一API示例代码:
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 构建StructType, text数据源, 读取数据的特点是, 将一整行只作为`一个列`读取, 默认列名是value 类型是Stringschema = StructType().add("data", StringType(), nullable=True)df = spark.read.format("text").\schema(schema=schema).\load("../data/input/sql/people.txt")df.printSchema()df.show()
读取text数据源:使用format(“text”)读取文本数据,读取到的DataFrame只会有一个列,列名默认称之为:value
schema = StructType().add("data", StringType(), nullable=True)
df = spark.read.format("text")\
.schema(schema)\
.load("../data/sql/people.txt")读取json数据源
使用format(“json”)读取json数据
示例代码:
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# JSON类型自带有Schema信息df = spark.read.format("json").load("../data/input/sql/people.json")df.printSchema()df.show()
读取csv数据源
使用format(“csv”)读取csv数据
示例代码:
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 读取CSV文件df = spark.read.format("csv").\option("sep", ";").\option("header", True).\option("encoding", "utf-8").\schema("name STRING, age INT, job STRING").\load("../data/input/sql/people.csv")df.printSchema()df.show()
读取parquet数据源
使用format(“parquet”)读取parquet数据
parquet: 是Spark中常用的一种列式存储文件格式。和Hive中的ORC差不多, 他俩都是列存储格式。parquet对比普通的文本文件的区别:
● parquet 内置schema (列名\ 列类型\ 是否为空)
● 存储是以列作为存储格式
● 存储是序列化存储在文件中的(有压缩属性体积小)
Parquet文件不能直接打开查看,如果想要查看内容,可以在PyCharm中安装如下插件来查看:
示例代码:
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 读取parquet类型的文件df = spark.read.format("parquet").load("../data/input/sql/users.parquet")df.printSchema()df.show()
DataFrame的入门操作
DataFrame支持两种风格进行编程,分别是:
• DSL风格
• SQL风格
DSL语法风格
DSL称之为:领域特定语言。
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data
比如:df.where().limit()
SQL语法风格
SQL风格就是使用SQL语句处理DataFrame的数据
比如:spark.sql(“SELECT * FROM xxx)
DSL - show 方法
功能:展示DataFrame中的数据, 默认展示20条
语法:
df.show(参数1, 参数2)
- 参数1: 默认是20, 控制展示多少条
- 参数2: 是否阶段列, 默认只输出20个字符的长度, 过长不显示, 要显示的话 请填入 truncate = True
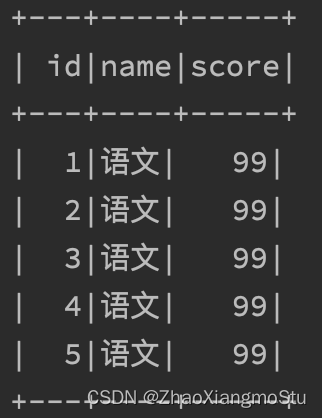
如图,某个df.show后的展示结果:
DSL - printSchema方法
功能:打印输出df的schema信息
语法:
df.printSchema()

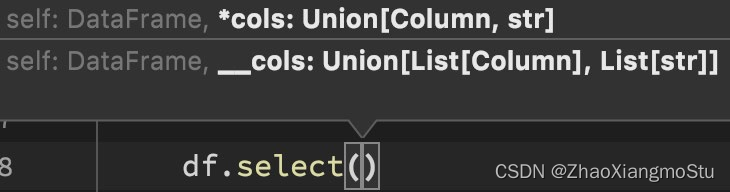
DSL - select
功能:选择DataFrame中的指定列(通过传入参数进行指定)
语法:
df.select()
可传递:
• 可变参数的cols对象,cols对象可以是Column对象来指定列或者字符串
列名来指定列
• List[Column]对象或者List[str]对象, 用来选择多个列
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pdif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContextdf = spark.read.format("csv").\schema("id INT, subject STRING, score INT").\load("../data/input/sql/stu_score.txt")# Column对象的获取id_column = df['id']subject_column = df['subject']# DLS风格演示df.select(["id", "subject"]).show()df.select("id", "subject").show()df.select(id_column, subject_column).show()DSL - filter和where
功能:过滤DataFrame内的数据,返回一个过滤后的DataFrame
语法:
df.filter()
df.where()
where和filter功能上是等价的
# filter APIdf.filter("score < 99").show()df.filter(df['score'] < 99).show()# where APIdf.where("score < 99").show()df.where(df['score'] < 99).show()DSL - groupBy 分组
功能:按照指定的列进行数据的分组, 返回值是GroupedData对象
语法:
df.groupBy()
传入参数和select一样,支持多种形式,不管怎么传意思就是告诉spark按照哪个列分组
# group By APIdf.groupBy("subject").count().show()df.groupBy(df['subject']).count().show()GroupedData对象
GroupedData对象是一个特殊的DataFrame数据集
其类全名:<class 'pyspark.sql.group.GroupedData'>
这个对象是经过groupBy后得到的返回值, 内部记录了 以分组形式存储的数据
GroupedData对象其实也有很多API,比如前面的count方法就是这个对象的内置方法
除此之外,像:min、max、avg、sum、等等许多方法都存在
SQL风格语法 - 注册DataFrame成为表
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中
使用spark.sql() 来执行SQL语句查询,结果返回一个DataFrame。
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:
# 注册成临时表df.createTempView("score") # 注册临时视图(表)df.createOrReplaceTempView("score_2") # 注册 或者 替换 临时视图df.createGlobalTempView("score_3") # 注册全局临时视图 全局临时视图在使用的时候 需要在前面带上global_temp. 前缀
SQL风格语法 - 使用SQL查询

# 可以通过SparkSession对象的sql api来完成sql语句的执行spark.sql("SELECT subject, COUNT(*) AS cnt FROM score GROUP BY subject").show()spark.sql("SELECT subject, COUNT(*) AS cnt FROM score_2 GROUP BY subject").show()spark.sql("SELECT subject, COUNT(*) AS cnt FROM global_temp.score_3 GROUP BY subject").show()pyspark.sql.functions 包
PySpark提供了一个包: pyspark.sql.functions
这个包里面提供了 一系列的计算函数供SparkSQL使用
如何用呢?
导包
from pyspark.sql import functions as F然后就可以用F对象调用函数计算了。
这些功能函数, 返回值多数都是Column对象。
词频统计案例练习
单词计数需求,使用DSL和SQL两种风格来实现。
# coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as Fif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# TODO 1: SQL 风格进行处理rdd = sc.textFile("../data/input/words.txt").\flatMap(lambda x: x.split(" ")).\map(lambda x: [x])df = rdd.toDF(["word"])# 注册DF为表格df.createTempView("words")spark.sql("SELECT word, COUNT(*) AS cnt FROM words GROUP BY word ORDER BY cnt DESC").show()# TODO 2: DSL 风格处理df = spark.read.format("text").load("../data/input/words.txt")# withColumn方法# 方法功能: 对已存在的列进行操作, 返回一个新的列, 如果名字和老列相同, 那么替换, 否则作为新列存在df2 = df.withColumn("value", F.explode(F.split(df['value'], " ")))df2.groupBy("value").\count().\withColumnRenamed("value", "word").\withColumnRenamed("count", "cnt").\orderBy("cnt", ascending=False).\show()
电影评分数据分析案例


# coding:utf8
import timefrom pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as Fif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\getOrCreate()sc = spark.sparkContext# 1. 读取数据集schema = StructType().add("user_id", StringType(), nullable=True).\add("movie_id", IntegerType(), nullable=True).\add("rank", IntegerType(), nullable=True).\add("ts", StringType(), nullable=True)df = spark.read.format("csv").\option("sep", "\t").\option("header", False).\option("encoding", "utf-8").\schema(schema=schema).\load("../data/input/sql/u.data")# TODO 1: 用户平均分df.groupBy("user_id").\avg("rank").\withColumnRenamed("avg(rank)", "avg_rank").\withColumn("avg_rank", F.round("avg_rank", 2)).\orderBy("avg_rank", ascending=False).\show()# TODO 2: 电影的平均分查询df.createTempView("movie")spark.sql("""SELECT movie_id, ROUND(AVG(rank), 2) AS avg_rank FROM movie GROUP BY movie_id ORDER BY avg_rank DESC""").show()# TODO 3: 查询大于平均分的电影的数量 # Rowprint("大于平均分电影的数量: ", df.where(df['rank'] > df.select(F.avg(df['rank'])).first()['avg(rank)']).count())# TODO 4: 查询高分电影中(>3)打分次数最多的用户, 此人打分的平均分# 先找出这个人user_id = df.where("rank > 3").\groupBy("user_id").\count().\withColumnRenamed("count", "cnt").\orderBy("cnt", ascending=False).\limit(1).\first()['user_id']# 计算这个人的打分平均分df.filter(df['user_id'] == user_id).\select(F.round(F.avg("rank"), 2)).show()# TODO 5: 查询每个用户的平局打分, 最低打分, 最高打分df.groupBy("user_id").\agg(F.round(F.avg("rank"), 2).alias("avg_rank"),F.min("rank").alias("min_rank"),F.max("rank").alias("max_rank")).show()# TODO 6: 查询评分超过100次的电影, 的平均分 排名 TOP10df.groupBy("movie_id").\agg(F.count("movie_id").alias("cnt"),F.round(F.avg("rank"), 2).alias("avg_rank")).where("cnt > 100").\orderBy("avg_rank", ascending=False).\limit(10).\show()time.sleep(10000)"""
1. agg: 它是GroupedData对象的API, 作用是 在里面可以写多个聚合
2. alias: 它是Column对象的API, 可以针对一个列 进行改名
3. withColumnRenamed: 它是DataFrame的API, 可以对DF中的列进行改名, 一次改一个列, 改多个列 可以链式调用
4. orderBy: DataFrame的API, 进行排序, 参数1是被排序的列, 参数2是 升序(True) 或 降序 False
5. first: DataFrame的API, 取出DF的第一行数据, 返回值结果是Row对象.
# Row对象 就是一个数组, 你可以通过row['列名'] 来取出当前行中, 某一列的具体数值. 返回值不再是DF 或者GroupedData 或者Column而是具体的值(字符串, 数字等)
"""
SparkSQL Shuffle 分区数目
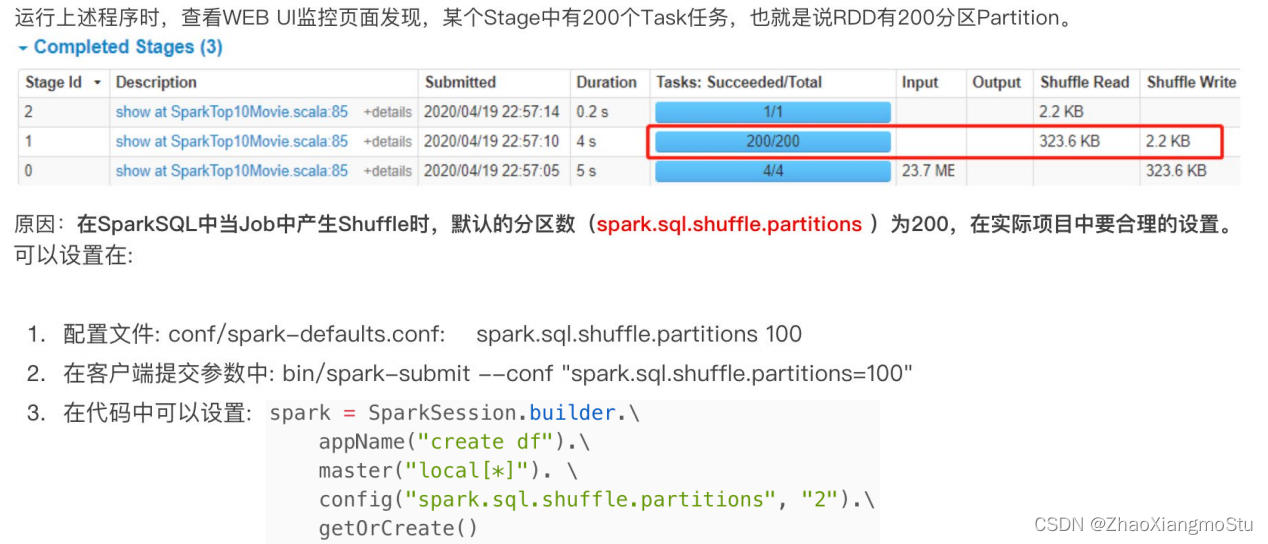
# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\config("spark.sql.shuffle.partitions", 2).\getOrCreate()sc = spark.sparkContext"""spark.sql.shuffle.partitions 参数指的是, 在sql计算中, shuffle算子阶段默认的分区数是200个.对于集群模式来说, 200个默认也算比较合适如果在local下运行, 200个很多, 在调度上会带来额外的损耗所以在local下建议修改比较低 比如2\4\10均可这个参数和Spark RDD中设置并行度的参数 是相互独立的."""SparkSQL 数据清洗API

df.dropDuplicates().show()df.dropDuplicates(['age', 'job']).show() 
df.dropna().show()# # thresh = 3表示, 最少满足3个有效列, 不满足 就删除当前行数据df.dropna(thresh=3).show()df.dropna(thresh=2, subset=['name', 'age']).show()
# 缺失值处理也可以完成对缺失值进行填充# DataFrame的 fillna 对缺失的列进行填充df.fillna("loss").show()# 指定列进行填充df.fillna("N/A", subset=['job']).show()# 设定一个字典, 对所有的列 提供填充规则df.fillna({"name": "未知姓名", "age": 1, "job": "worker"}).show()DataFrame数据写出



# Write text 写出, 只能写出一个列的数据, 需要将df转换为单列dfdf.select(F.concat_ws("---", "user_id", "movie_id", "rank", "ts")).\write.\mode("overwrite").\format("text").\save("../data/output/sql/text")# Write csvdf.write.mode("overwrite").\format("csv").\option("sep", ";").\option("header", True).\save("../data/output/sql/csv")# Write jsondf.write.mode("overwrite").\format("json").\save("../data/output/sql/json")# Write parquetdf.write.mode("overwrite").\format("parquet").\save("../data/output/sql/parquet")DataFrame 通过JDBC读写数据库(MySQL示例)
# 1. 写出df到mysql数据库中df.write.mode("overwrite").\format("jdbc").\option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true").\option("dbtable", "movie_data").\option("user", "root").\option("password", "2212072ok1").\save()

# 2. 从mysql数据库中读dfdf2 = spark.read.format("jdbc"). \option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true"). \option("dbtable", "movie_data"). \option("user", "root"). \option("password", "2212072ok1"). \load()
DataFrame 在结构层面上由StructField组成列描述,由StructType构造表描述。在数据层面上,Column对象记录列数据,Row对象记录行数据。
DataFrame可以从RDD转换、Pandas DF转换、读取文件、读取JDBC等方法构建。
spark.read.format()和df.write.format() 是DataFrame读取和写出的统一化标准API。
SparkSQL默认在Shuffle阶段200个分区,可以修改参数获得最好性能。
dropDuplicates可以去重、dropna可以删除缺失值、fillna可以填充缺失值。
SparkSQL支持JDBC读写,可用标准API对数据库进行读写操作。
相关文章:
Spark 6:Spark SQL DataFrame
SparkSQL 是Spark的一个模块, 用于处理海量结构化数据。 SparkSQL是用于处理大规模结构化数据的计算引擎 SparkSQL在企业中广泛使用,并性能极好 SparkSQL:使用简单、API统一、兼容HIVE、支持标准化JDBC和ODBC连接 SparkSQL 2014年正式发布,当…...

区块链智能合约编程语言 Solidity
文章目录 前言Solidity 介绍Solidity 文件结构许可声明编译指示数据类型函数事件访问区块元数据 简单的智能合约 前言 上文介绍了区块链生态发展,我们知道以太坊的到来可以使开发人员基于区块链开发DApp,本文介绍 Solidity 编程语言的使用,然…...

将SSL证书设置成HTTPS的详细步骤
在互联网上建立一个安全且可信任的网站,HTTPS是一种常用的解决方案。HTTPS是HTTP的安全版本,通过使用SSL/TLS协议对传输的数据进行加密,确保数据传输的安全性。要实现HTTPS,你需要将SSL证书设置到你的网站上。以下是详细的步骤&am…...
43、Flink之Hive 读写及详细验证示例
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

2023数模国赛C 题 蔬菜类商品的自动定价与补货决策-完整版创新多思路详解(含代码)
题目简评:看下来C题是三道题目里简单一些的,考察的点比较综合,偏数据分析。涉及预测模型和运筹优化(线性规划),还设了一问开放型问题,适合新手入门,发挥空间大。 题目分析与思路: 背景&#x…...
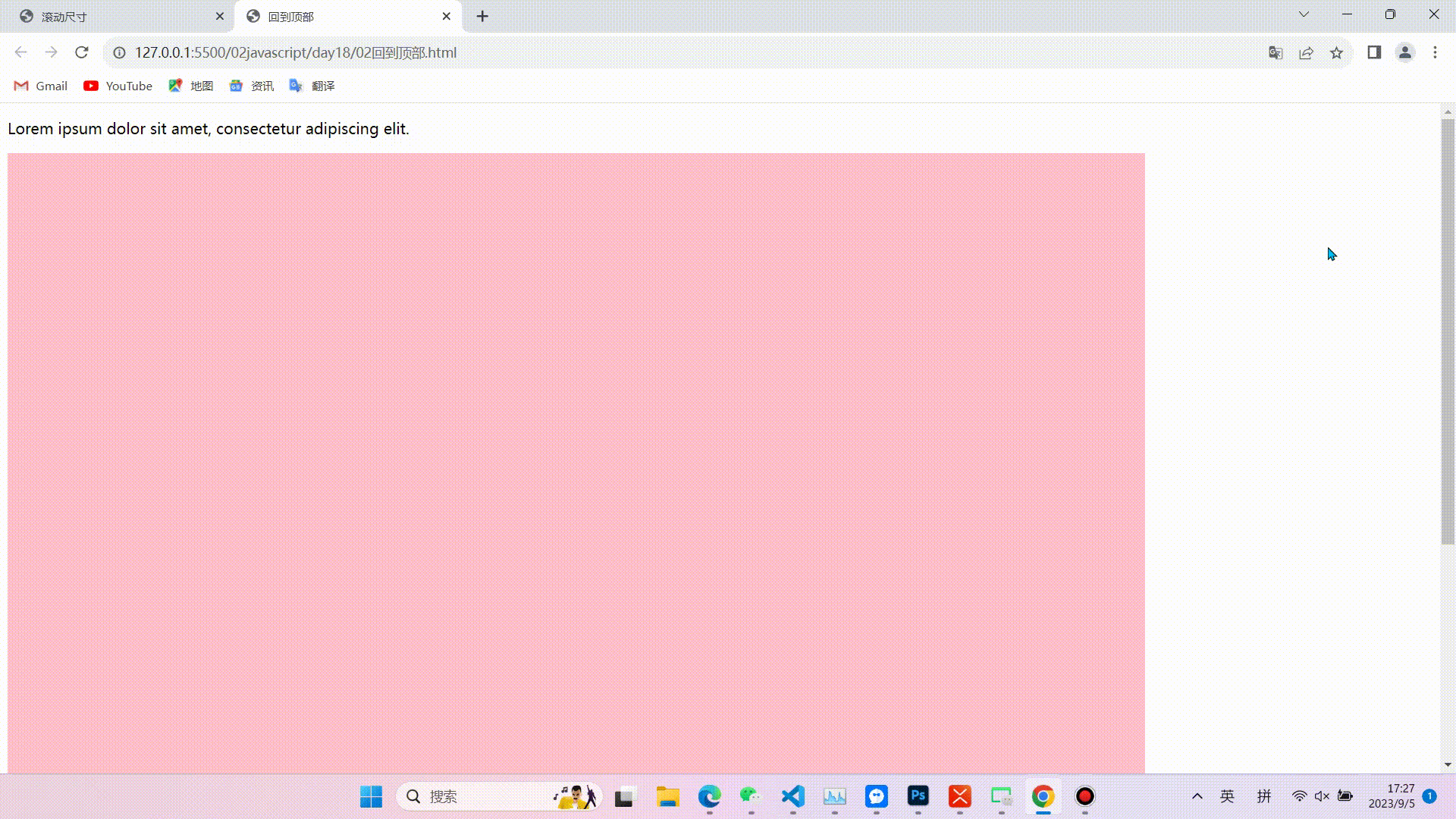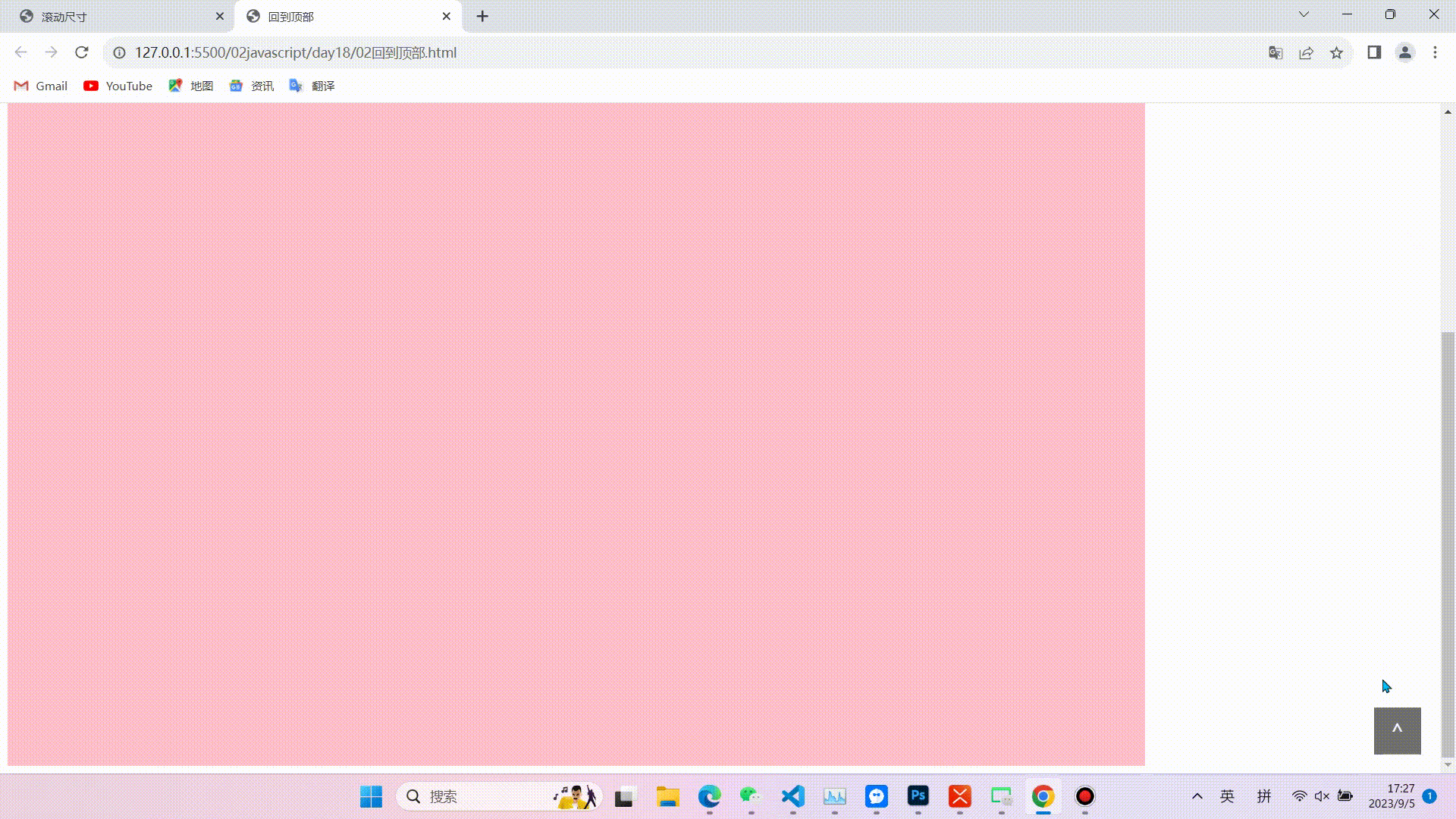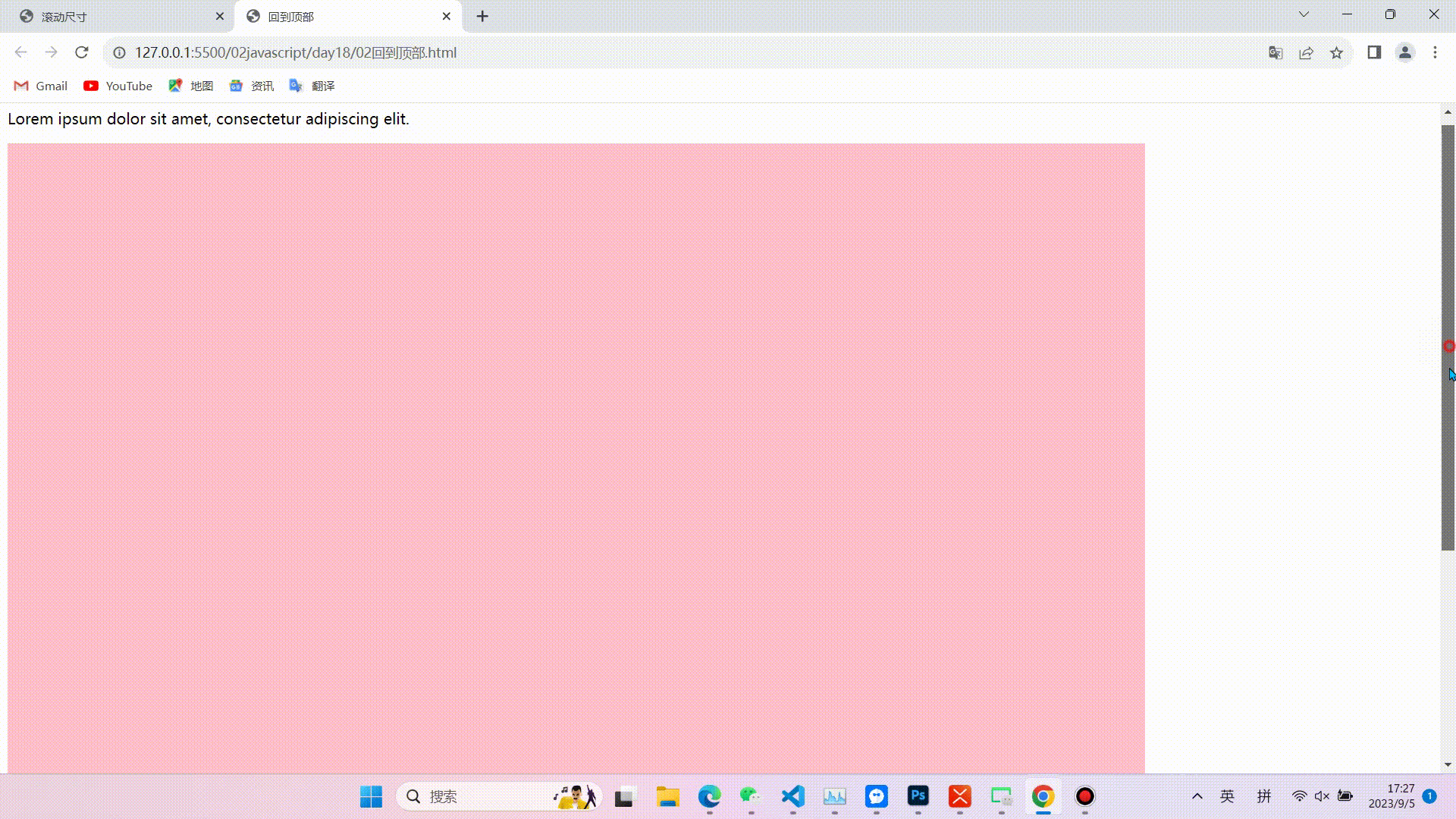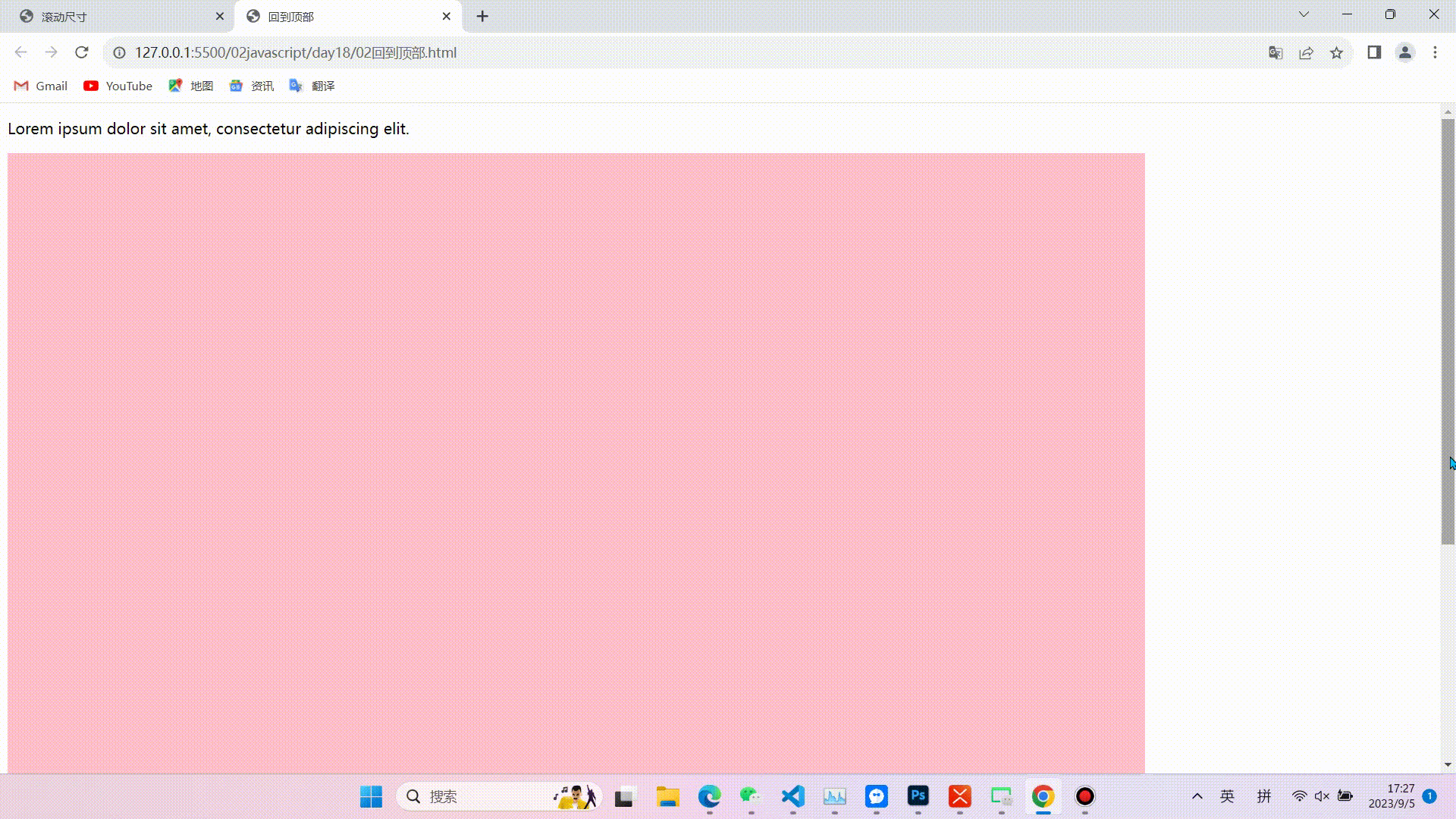
javaScript:DOM中常用尺寸
目录 前言(可以根据图示找到需要的尺寸,便于理解) 内尺寸 clientWidth 包含左右padding和宽度width(忽略滚动条的宽度) clientHeight 包含上下padding和height(忽略滚动条的高度) clientTo…...
决策树算法学习笔记
一、决策树简介 首先决策树是一种有监督的机器学习算法,其采用的方法是自顶向下的递归方法,构建一颗树状结构的树,其具有分类和预测功能。其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为零。决策树的构…...

Verilog_mode常用的几个用法
一:verilog mode中如何使用正则表达 在顶层实例化时,有大量的信号需要重新命名,使用模板的话会增加大量的注释内容,不过往往这些信号命名有特定的规律,我们可以使用正则表达式来处理,下面举几个例子&#…...

MySQL之MHA高可用配置及故障切换
目录 一、MHA概念 1、MHA的组成 2、MHA的特点 3、主从复制有多少种复制方法 二、搭建MySqlMHA部署 1.Master、Slave1、Slave2 节点上安装 mysql 2.修改 Master、Slave1、Slave2 节点的 Mysql主配置文件/etc/my.cnf 3. 配置 mysql 一主两从 4、安…...

java实现状态模式
状态模式是一种行为设计模式,它允许对象在内部状态改变时改变其行为。在状态模式中,对象将其行为委托给表示不同状态的状态对象,这些状态对象负责管理其行为。以下是在 Java 中实现状态模式的一般步骤: 创建一个状态接口ÿ…...
)
Selling a Menagerie(cf)
该题考察了拓扑排序dfs 题意:你是一个动物园的主人,该动物园由编号从1到n的n只动物组成。然而,维护动物园是相当昂贵的,所以你决定卖掉它!众所周知,每种动物都害怕另一种动物。更确切地说,动物…...

python-55-打包exe执行
目录 前言一、pyinstaller二、实践打包exe1、遇坑1:Plugin already registered2、遇坑2:OSError 句柄无效 三、总结 前言 你是否有这种烦恼? 别人在使用你的项目时可能还需要安装各种依赖包?别人在使用你的项目,可能…...

linux并发服务器 —— IO多路复用(八)
半关闭、端口复用 半关闭只能实现数据单方向的传输;当TCP 接中A向 B 发送 FIN 请求关闭,另一端 B 回应ACK 之后 (A 端进入 FIN_WAIT_2 状态),并没有立即发送 FIN 给 A,A 方处于半连接状态 (半开关),此时 A 可以接收 B…...
企微SCRM营销平台MarketGo-ChatGPT助力私域运营
一、前言 ChatGPT是由OpenAI(开放人工智能)研发的自然语言处理模型,其全称为"Conversational Generative Pre-trained Transformer",即对话式预训练转换器。它是GPT系列模型的最新版本,GPT全称为"Gene…...
linux C++ 海康截图Demo
项目结构 CMakeLists.txt cmake_minimum_required(VERSION 3.7)project(CapPictureTest)include_directories(include)link_directories(${CMAKE_SOURCE_DIR}/lib ${CMAKE_SOURCE_DIR}/lib/HCNetSDKCom) add_executable(CapPictureTest ${CMAKE_SOURCE_DIR}/src/CapPictureTes…...

MySQL的事务隔离级别
目录 事务隔离级别的概念 脏读(Dirty Read): 不可重复读(Non-Repeatable Read): 幻读(Phantom Read): 读未提交(Read Uncommitted) 读未提交…...

企业大语言模型智能问答的底层基础数据知识库如何搭建?
企业大语言模型智能问答的底层基础数据知识库搭建是一个复杂而关键的过程。下面将详细介绍如何搭建这样一个知识库。 确定知识库的范围和目标: 首先,需要明确知识库的范围,确定所涵盖的领域和主题。这可以根据企业的业务领域和用户需求来确…...
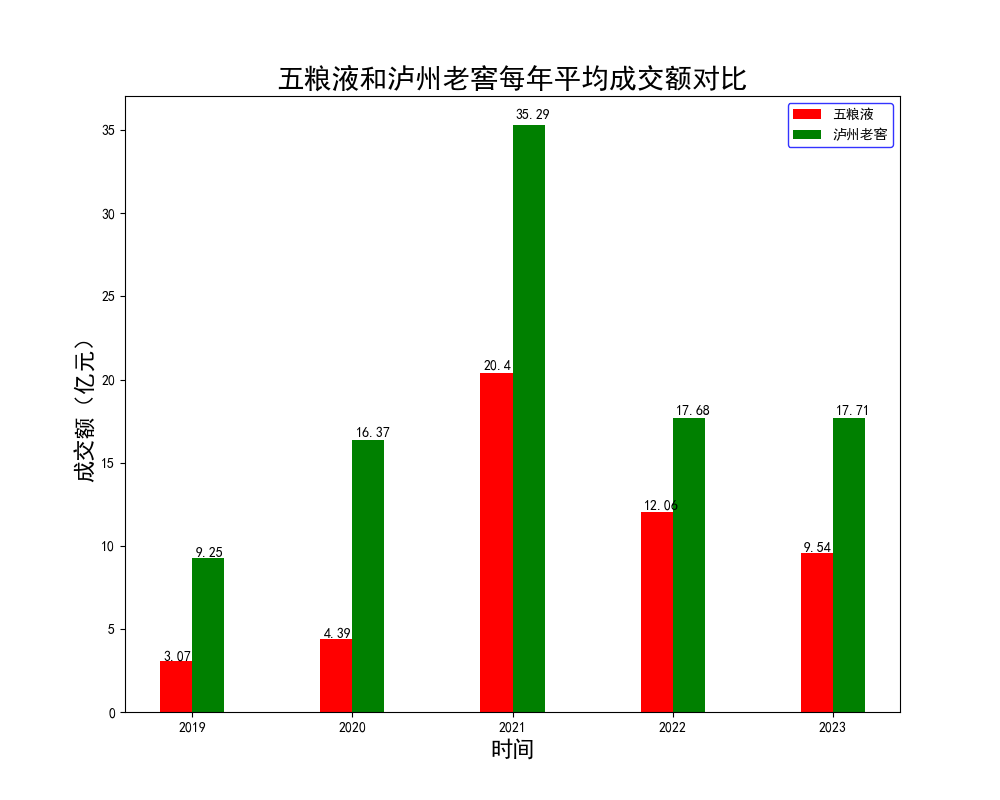
【腾讯云 Cloud Studio 实战训练营】使用python爬虫和数据可视化对比“泸州老窖和五粮液4年内股票变化”
Cloud Studio 简介 Cloud Studio是腾讯云发布的云端开发者工具,支持开发者利用Web IDE(集成开发环境),实现远程协作开发和应用部署。 现在的Cloud Studio已经全面支持Java Spring Boot、Python、Node.js等多种开发模板示例库&am…...

Linux之Shell概述
目录 Linux之Shell概述 学习shell的原因 shell是什么 shell起源 查看当前系统支持的shell 查看当前系统默认shell Shell 概念 Shell 程序设计语言 Shell 也是一种脚本语言 用途 Shell脚本的基本元素 基本元素构成: Shell脚本中的注释和风格 Shell脚本编…...

手写Spring:第2章-创建简单的Bean容器
文章目录 一、目标:创建简单的Bean容器二、设计:创建简单的Bean容器三、实现:创建简单的Bean容器3.0 引入依赖3.1 工程结构3.2 创建简单Bean容器类图3.3 Bean定义3.4 Bean工厂 四、测试:创建简单的Bean容器4.1 用户Bean对象4.2 单…...

九大网盘直链下载助手:一键获取真实下载地址的终极解决方案
九大网盘直链下载助手:一键获取真实下载地址的终极解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 /…...

掌握6个采购管控节点,企业采购成本可直接降低15%—30%
在企业经营管理中,采购成本是企业综合成本的核心组成部分,原材料、耗材、设备、服务等采购支出,直接决定企业利润空间。据行业数据统计,多数中小企业采购环节存在流程漏洞、管控松散、资源浪费等问题,无效成本占比高达…...

FPGA上LUT-DNN稀疏连接优化技术SparseLUT详解
1. 项目概述在边缘计算场景中,FPGA因其可重构性和低功耗特性成为部署深度神经网络(DNN)的理想平台。然而传统DNN在FPGA上的实现面临资源占用高、延迟大等挑战。基于查找表(LUT)的DNN通过将神经元计算映射到FPGA原生LUT资源,显著提升了硬件效率。但现有LU…...

python海龟绘图之窗口背景
可以将海龟绘图的窗口背景设置为纯色或者图片。1 将窗口背景设置为纯色通过bgcolor()函数设置窗口的背景色。该函数有四种使用方法,分别是① bgcolor()② bgcolor(colorstring)③ bgcolor((r, g, b))④ bgcolor(r, g, b)1.1 bgcolor()bgcolor()不带参数的形式&#…...

植物大战僵尸杂交版手机版最新版v3.16.1安卓2026最新下载分享
作为长期沉迷植物大战僵尸改版的老玩家,我近期完整体验了杂交版全新V3.16版本,从植物、关卡到平台适配,逐一实测验证。 整体来说,这是一次诚意满满的更新——既有新鲜玩法创新,又兼顾不同玩家需求。 下载链接&#x…...

从方程到应用:激光雷达核心参数与激光器选型指南
1. 激光雷达方程:从数学公式到物理意义 第一次接触激光雷达方程时,我也被那一堆希腊字母和下标搞得头晕眼花。但后来发现,这个看似复杂的方程其实就像买菜算账一样简单直白。激光雷达方程本质上是个"能量收支平衡表",它…...

不止是记事本!Win10右键新建菜单终极自定义指南:排序、删除、添加任意文件类型
不止是记事本!Win10右键新建菜单终极自定义指南:排序、删除、添加任意文件类型 在Windows 10的日常使用中,右键新建菜单可能是最容易被忽视却高频使用的功能之一。想象一下这样的场景:你刚刚安装了一款专业设计软件,却…...

面向对象与多源遥感协同:eCognition-ENVI在雄安新区土地利用动态监测中的实践
1. 面向对象与多源遥感协同的技术背景 在快速城市化的今天,土地利用动态监测变得越来越重要。传统的像素级分类方法虽然简单直接,但在处理高分辨率遥感影像时,往往会遇到"椒盐效应"——就像用细小的马赛克拼图,每个像素…...

ChatGPT Web:5分钟快速搭建你的专属AI聊天室
ChatGPT Web:5分钟快速搭建你的专属AI聊天室 【免费下载链接】chatgpt-web A third-party ChatGPT Web UI page built with Express and Vue3, through the official OpenAI completion API. / 用 Express 和 Vue3 搭建的第三方 ChatGPT 前端页面, 基于 OpenAI 官方…...

别再手动导数据了!用Python的pandas+pyarrow,3行代码搞定Parquet转JSON
3行代码解锁数据自由:用Python极简实现Parquet到JSON的优雅转换 数据工程师的日常总是与格式转换纠缠不清。当你在凌晨两点收到紧急需求:"立刻把数据仓库里50GB的用户行为Parquet文件转成JSON供下游系统调用",是选择打开文档逐行编…...