【腾讯云 Cloud Studio 实战训练营】使用python爬虫和数据可视化对比“泸州老窖和五粮液4年内股票变化”
Cloud Studio
简介
Cloud Studio是腾讯云发布的云端开发者工具,支持开发者利用Web IDE(集成开发环境),实现远程协作开发和应用部署。
现在的Cloud Studio已经全面支持Java Spring Boot、Python、Node.js等多种开发模板示例库,让开发者们可以更轻松地上手。它还具备在线开发、调试、预览等强大的功能,让你可以轻松实现各种开发需求。而且,我还听说Cloud Studio已经在内测中集成了在线开发协作模块,下一个版本将会全量开放,这意味着你将能够随时随地与团队成员一起设计、讨论和开发项目。
还有一点非常重要的是,Cloud Studio具备SSH连接能力,这意味着你可以安全地连接到云端工作空间,更加方便地连接云资源。这样一来,你可以随时随地享受到云端开发的便利,不再受限于地点和设备。
另外,Cloud Studio还具备标准化的云端安装部署能力,支持主流代码仓库的云端克隆。这就意味着你可以将你的代码库轻松地迁移到云端,让你的开发过程更加规范化和便捷化。
创建账号
Cloud Studio 的官网: https://cloudstudio.net/
目前共有三种登录方式:CODING,微信,GITHUB
如果没有GitHub,可以使用微信登录。

1、搭建前准备
打开Cloud Studio平台,进入个人页面。
点击Cloud Studio官网 Cloud Studio_在线编程_在线IDE_WebIDE_CloudIDE
现在实名认证的话每月会赠送 1000 分钟免费额度。
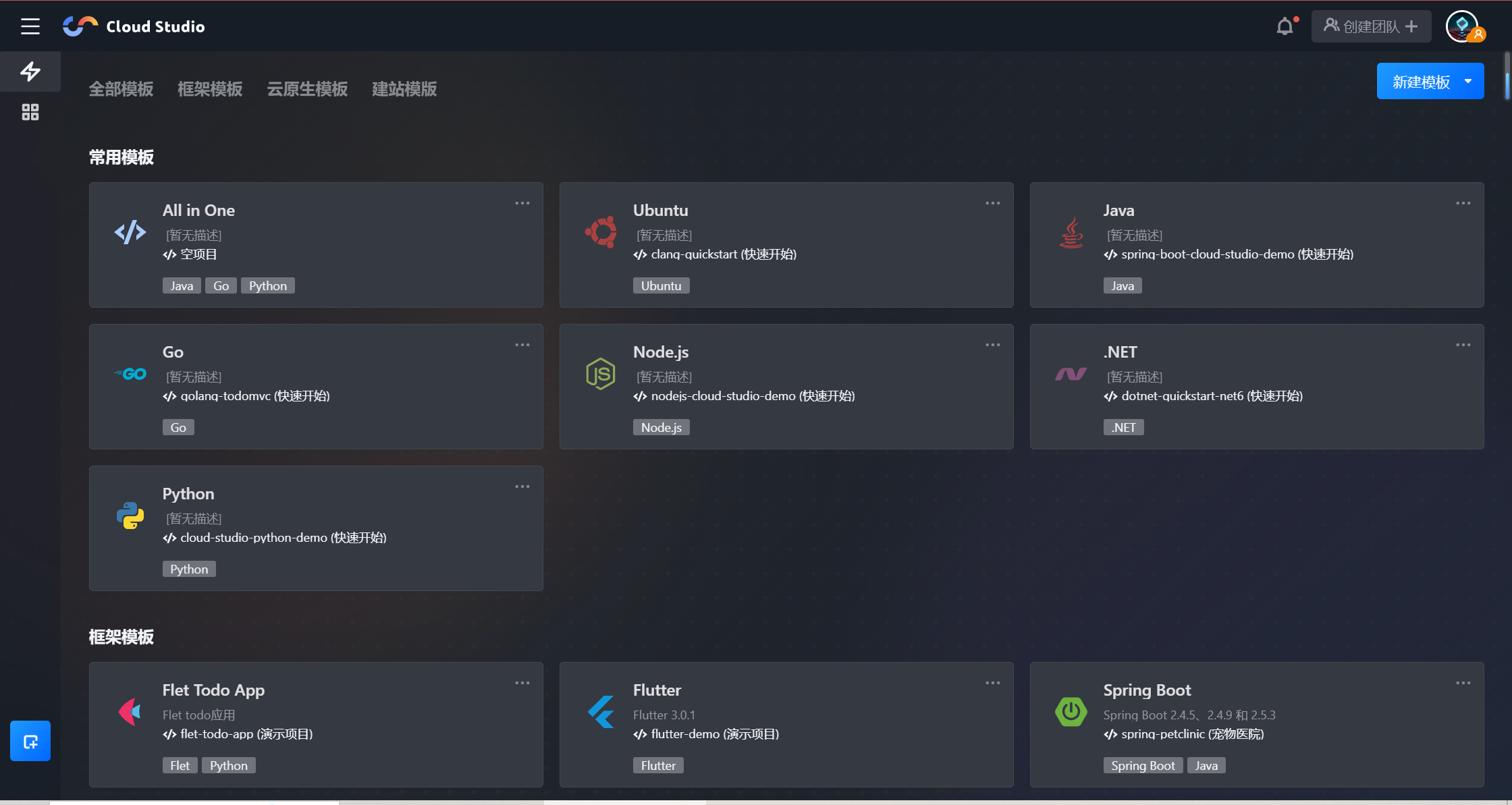
2、选择环境
选择环境模板
Cloud Studio内置 Node.js、Java、Python 等常见环境,这里我们需要选择一个Python模板
3、开始代码环节
3.1、配置运行环境
打开终端
分别执行以下命令下载依赖包
pip install openpyxl
pip install numpy
pip install pandas
pip install matplotlib
3.2、创建 数据爬取.py
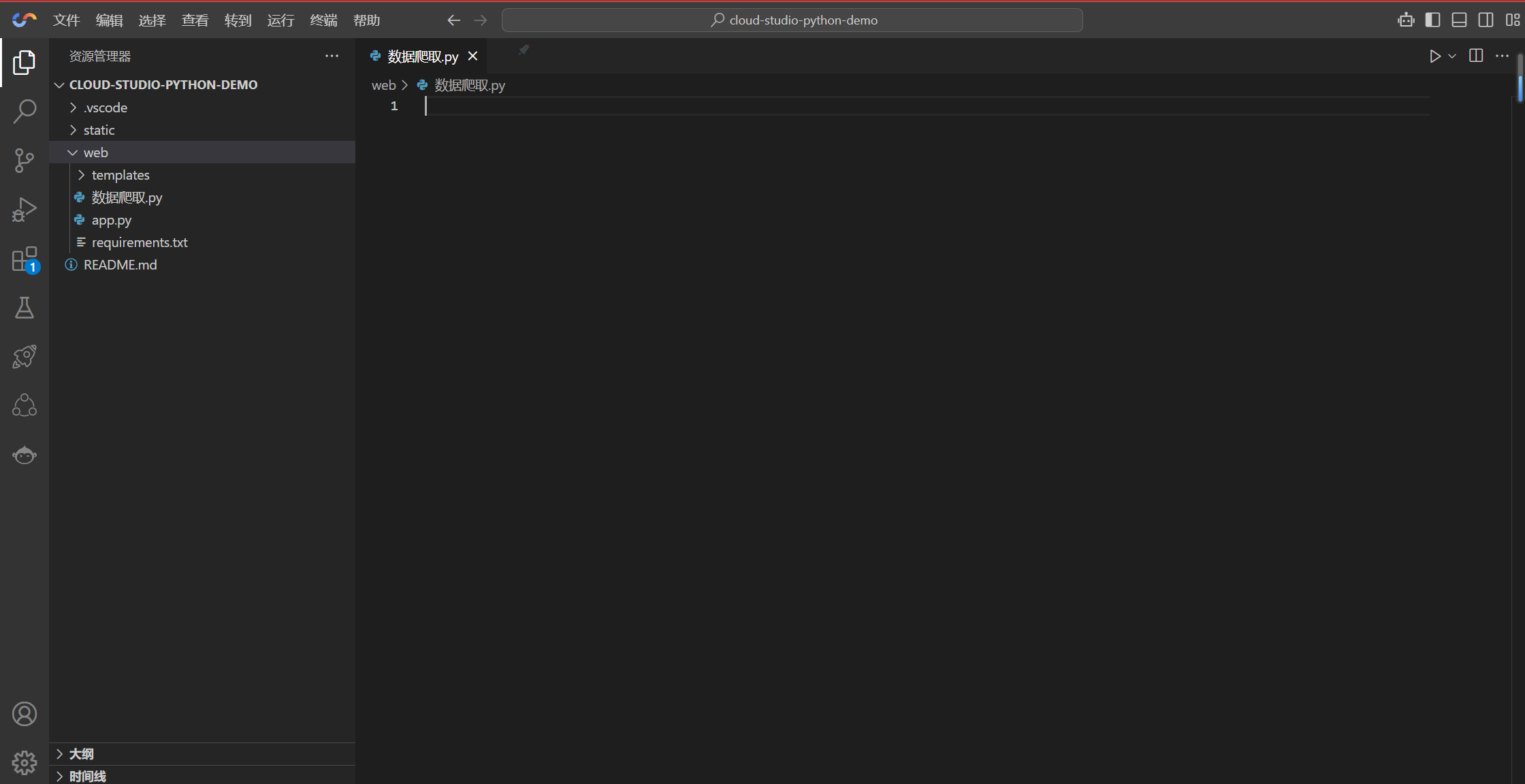
运行如下代码
import requests
from openpyxl import Workbook# 请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}# 将数据转换为json格式
def getTypeJson(url):# 发送请求response = requests.get(url, headers=headers)# 返回json格式数据return response.json()# 获得数据信息
def getInformation(url, ws, name):# 获取json格式的data数据data = getTypeJson(url).get("data")# 获取klines数据klines = data.get("klines")for kline in klines:# 将kline的起始位置加上name字段kline = name + "," + kline# 将kline用,切割并保存一行ws.append(kline.split(","))# 保存数据
def saveInformationToXlsx():wb = Workbook()# 打开第一个表格ws = wb.worksheets[0]# 添加第一行数据ws.append(["名称", "时间", "开盘", "收盘", "最高", "最低", "成交量", "成交额", "振幅", "涨跌幅", "涨跌额", "换手率"])# 爬取五粮液数据url = f"http://push2his.eastmoney.com/api/qt/stock/kline/get?fields1=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13&fields2=f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61&beg=20190101&end=20500101&ut=fa5fd1943c7b386f172d6893dbfba10b&rtntype=6&secid=1.600702&klt=101&fqt=1"getInformation(url, ws, "五粮液")# 爬取泸州老窖数据url = f"http://push2his.eastmoney.com/api/qt/stock/kline/get?fields1=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13&fields2=f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61&beg=20190101&end=20500101&ut=fa5fd1943c7b386f172d6893dbfba10b&rtntype=6&secid=0.000568&klt=101&fqt=1"getInformation(url, ws, "泸州老窖")# 设置标题ws.title = "五粮液和泸州老窖"# 保存数据wb.save("酿酒行业个股资金流.xlsx")# 关闭资源wb.close()# 程序运行
if __name__ == '__main__':saveInformationToXlsx()
酿酒行业个股资金流.xlsx 文件内容如下
爬取的数据来自东方财富:泸州老窖和五粮液
3.3、创建 数据分析.py
运行如下代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import randomdef viewPlot(fileName):# 防止中文乱码plt.rcParams["font.sans-serif"] = ["SimHei"]plt.rcParams["axes.unicode_minus"] = False# 进行数据处理df = dataHandling(fileName)viewPlot1(df)viewPlot2(df)viewPlot3(df)# 对xlsx数据进行整理
def dataHandling(xlsxName):# 读取excel文件df = pd.read_excel(xlsxName, header=0)# 对时间进行处理df['年月'] = df['时间'].str[0:7]df['时间'] = pd.to_datetime(df['时间'])df['年'] = df['时间'].dt.yeardf['月'] = df['时间'].dt.monthdf['时间'] = df['时间'].dt.date# 处理成交量(将单位从次变为万次)并保留两位小数df['成交量'] = round(df['成交量'] / 10000, 2)# 处理成交额(将单位从元变为亿元)并保留两位小数df['成交额'] = round(df['成交额'] / 100000000, 2)return df# 画图
def viewPlot1(df):# 创建画板plt.figure(figsize=(12, 12), dpi=80)# 设置标题plt.suptitle("4年内酿酒行业个股资金流走势图", fontsize=20)# 获取名称集合nameList = df['名称'].unique()# 绘制第一个子图plt.subplot(2, 1, 1)# 以键值对方式存储数据dic = {}for name in nameList:# 获取数据dic[name] = groupByDayData(df, name)# 子图标题title = nameList[0] + '和' + nameList[1] + "每日成交额"drawSubPlot(dic, title, 10, "成交额(亿元)")# 绘制第二个子图plt.subplot(2, 2, 3)# 以键值对方式存储数据dic = {}for name in nameList:# 获取数据dic[name] = groupByMonthData(df, name)# 子图标题title = nameList[0] + '和' + nameList[1] + "每月平均成交额"drawSubPlot(dic, title, 6, "成交额(亿元)")# 绘制第三个子图plt.subplot(2, 2, 4)# 以键值对方式存储数据dic = {}for name in nameList:# 获取数据dic[name] = groupByMonthMaxData(df, name)# 子图标题title = nameList[0] + '和' + nameList[1] + "每月最大成交额"drawSubPlot(dic, title, 6, "成交额(亿元)")# 存图plt.savefig('./plot1.png')# 展示图片plt.show()# 封装数据并返回
def getData(group):# 获取x轴数据x = group.index# 获取y轴数据y = group.values# 将数据封装为list集合并返回data = [x, y]return data# 按名称和时间分组获取每天成交额
def groupByDayData(df, name):groupByDay = df.groupby("名称").get_group(name).groupby(['时间'])['成交额'].mean()return getData(groupByDay)# 根据名称和年月分组获取每月成交额的平均值
def groupByMonthData(df, name):groupByMonth = df.groupby("名称").get_group(name).groupby(['年月'])['成交额'].mean()return getData(groupByMonth)# 根据名称和年月分组获取每月最大成交额数据
def groupByMonthMaxData(df, name):groupByMonth = df.groupby("名称").get_group(name).groupby(['年月'])['成交额'].max()return getData(groupByMonth)# 折线颜色集合
colors = ['red', 'green', 'blue']
# 折线样式集合
line_style = ['-', '--', '-.']# 子图绘制dic:数据,title:子图标题,step:x轴显示数据的数量,yTitle:y轴单位
def drawSubPlot(dic, title, step, yTitle):# 随机生成颜色下标c = random.randint(0, len(colors) - 1)# 随机生成样式下标l = random.randint(0, len(line_style) - 1)i = 0# 遍历dicfor name, data in dic.items():# 折线颜色选取c = (c + i) % len(colors)# 折线样式选取l = (l + i) % len(line_style)# 为了使第二条线和第一条线不相等i = i + 1# 将数据代入x轴和y轴putData(name, data, step, c, l)# 设置x轴名称plt.xlabel("日期", fontdict={'size': 16})# 设置y轴名称plt.ylabel(yTitle, fontdict={'size': 16}, rotation=90)# 设置网格plt.grid(True, linestyle='--', alpha=0.5)# 设置子图标题plt.title(title, fontdict={'size': 16})# 将数据加载到子图中
def putData(name, data, step, c, l):# x轴数据x = data[0]# y轴数据y = data[1]# 将x轴和y轴数据代入并设置颜色折线类型和折线名plt.plot(x, y, c=colors[c], label=name, linestyle=line_style[l])# 设置折线上的点plt.scatter(x[::int(len(x) / step)], y[::int(len(x) / step)], c=colors[c])# 设置图例边框plt.legend(loc='best', edgecolor='blue')# 设置x轴数据plt.xticks(x[::int(len(x) / step)], rotation=30)def viewPlot2(df):# 创建画板plt.figure(figsize=(12, 12), dpi=80)# 设置标题plt.suptitle("4年内酿酒行业个股资金流走势图", fontsize=20)# 获取名称集合nameList = df['名称'].unique()# 绘制第一个子图plt.subplot(2, 2, 1)# 以键值对方式存储数据dic = {}for name in nameList:# 获取数据dic[name] = getMaxAndMinDataByName(df, name)# 子图标题title = nameList[0] + "每月最高和最低股票价格"drawSubPlot(dic[nameList[0]], title, 6, "价格(元/每股)")# 绘制第二个子图plt.subplot(2, 2, 2)# 子图标题title = nameList[1] + "每月最高和最低股票价格"drawSubPlot(dic[nameList[1]], title, 6, "价格(元/每股)")# 绘制第三个子图plt.subplot(2, 1, 2)# 以键值对方式存储数据dic = {}for name in nameList:# 获取数据dic[name] = getMeanDataByName(df, name)# 子图标题title = nameList[0] + "和" + nameList[1] + "每月平均成交量比较"drawSubPlot(dic, title, 10, "成交量(每单)")# 存图plt.savefig('./plot2.png')plt.show()# 通过名称和年月获取每月最高和最低股票价格数据
def getMaxAndMinDataByName(df, name):# 保存数据dic = {}# 通过名称和年月分组groupByNameAndMonth = df.groupby("名称").get_group(name).groupby(['年月'])# 获得每月最大数据getMax = groupByNameAndMonth['最高'].max()dic['最高'] = getData(getMax)# 获得每月最小数据getMin = groupByNameAndMonth['最低'].min()dic['最低'] = getData(getMin)# 返回数据return dic# 按名称和年月分组获取每月成交量的平均值
def getMeanDataByName(df, name):groupByMonth = df.groupby("名称").get_group(name).groupby(['年月'])['成交量'].mean()return getData(groupByMonth)# 通过名称和年分组获得每年成交额的平均值
def getInformation(df, nameList):# 根据名称分组groupByName = df.groupby("名称")# 根据年分组获取平均值groupByYear = groupByName.get_group(nameList[0]).groupby(['年'])['成交额'].mean()# 将平均值保留两位小数groupByYear = round(groupByYear, 2)# 获取x轴数据x = groupByYear.index# 获取第一组y轴数据y1 = groupByYear.values# 根据年分组获取平均值groupByYear = groupByName.get_group(nameList[1]).groupby(['年'])['成交额'].mean()# 将平均值保留两位小数groupByYear = round(groupByYear, 2)# 获取第二组y轴数据y2 = groupByYear.values# 封装数据并返回data = [x, y1, y2]return data# 柱状图
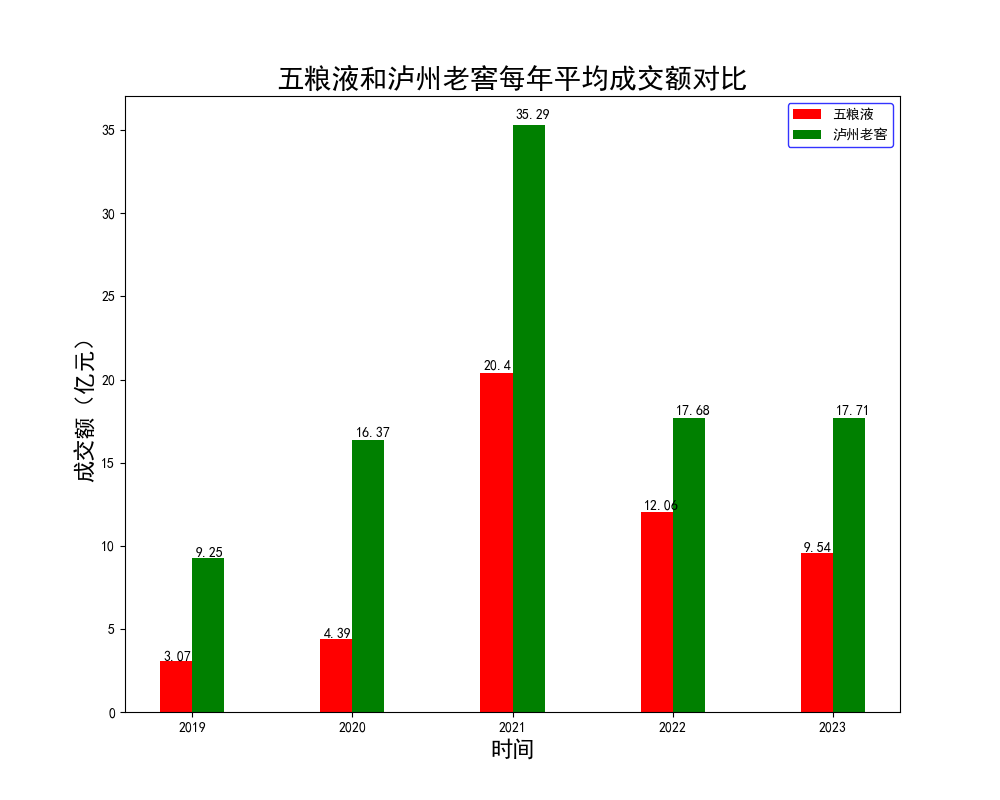
def viewPlot3(df):# 获取不同名称集合nameList = df['名称'].unique()# 获取数据information = getInformation(df, nameList)xData = information[0]y1 = information[1]y2 = information[2]# 设置画板plt.figure(figsize=(10, 8))# 条形宽度width = 0.2# 生成1到len(xData)的数组x = np.arange(len(xData))# 画第一组数据,在x位置画y1的值pa = plt.bar(x, y1, width=width, label=nameList[0], fc="r")# 画第一组数据,在 x + width 位置画y2的值pb = plt.bar(x + width, y2, width=width, label=nameList[1], fc="g")# 在柱上标数字autoLabel(pa)autoLabel(pb)# 原来这里是刻度值,现在把x轴标题替换为横坐标显示plt.xticks(x + width / 2, xData)plt.title(nameList[0] + "和" + nameList[1] + "每年平均成交额对比", fontdict={'size': 20})# 设置图例边框plt.legend(loc='best', edgecolor='blue')# 设置轴名plt.xlabel('时间', fontdict={'size': 16})plt.ylabel('成交额(亿元)', fontdict={'size': 16}, rotation=90)# 存图plt.savefig('./plot3.png')plt.show()# 在柱上显示代表的数量
def autoLabel(rects):# 遍历所有矩形for rect in rects:# 获得矩形高度height = rect.get_height()print(type(height))# 将数据标到柱顶plt.text(rect.get_x() + rect.get_width() * 0.10, 1.01 * height, height)# 运行程序
if __name__ == '__main__':# 读取数据的文件名filename = r"酿酒行业个股资金流.xlsx"# 画图方法viewPlot(filename)
如报 findfont: Generic family ‘sans-serif’ not found because none of the following families were found: SimHei
参考该博客解决:https://blog.csdn.net/ben_na_/article/details/124238611
生成如下三张图
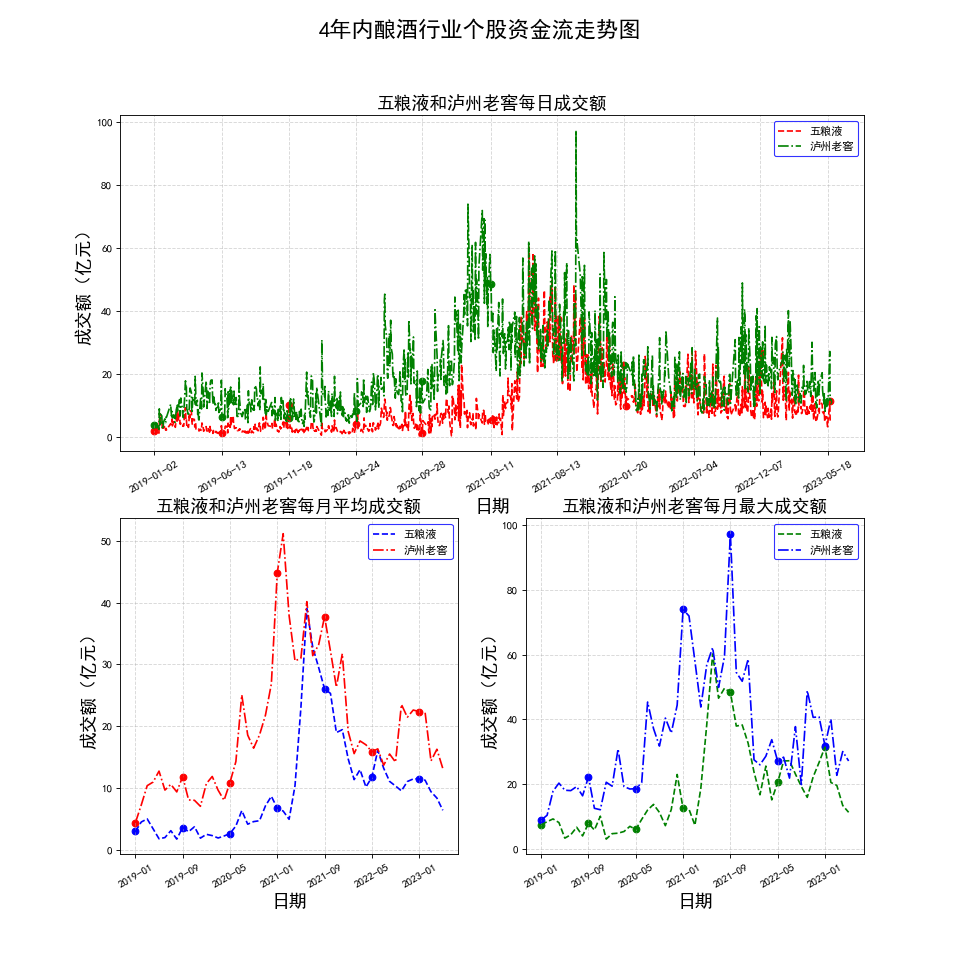
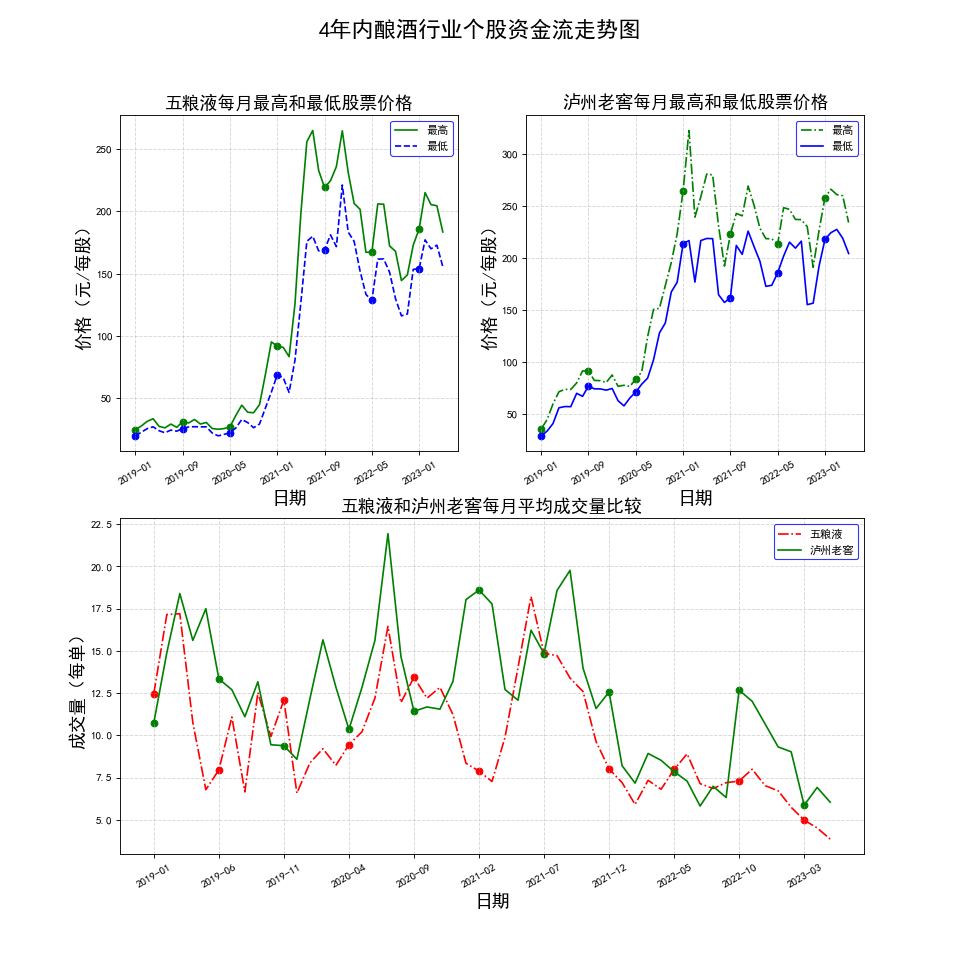
使用感想
Cloud Studio 可以在云端运行代码,帮我们节省了在本地安装和配置软件的成本。
通过我的使用 Cloud Studio 的环境支持功能非常强大,几乎不需要额外配置。
总之,Cloud Studio 操作简单、功能强大,希望这个产品能够越做越好。
相关文章:
【腾讯云 Cloud Studio 实战训练营】使用python爬虫和数据可视化对比“泸州老窖和五粮液4年内股票变化”
Cloud Studio 简介 Cloud Studio是腾讯云发布的云端开发者工具,支持开发者利用Web IDE(集成开发环境),实现远程协作开发和应用部署。 现在的Cloud Studio已经全面支持Java Spring Boot、Python、Node.js等多种开发模板示例库&am…...

Linux之Shell概述
目录 Linux之Shell概述 学习shell的原因 shell是什么 shell起源 查看当前系统支持的shell 查看当前系统默认shell Shell 概念 Shell 程序设计语言 Shell 也是一种脚本语言 用途 Shell脚本的基本元素 基本元素构成: Shell脚本中的注释和风格 Shell脚本编…...

手写Spring:第2章-创建简单的Bean容器
文章目录 一、目标:创建简单的Bean容器二、设计:创建简单的Bean容器三、实现:创建简单的Bean容器3.0 引入依赖3.1 工程结构3.2 创建简单Bean容器类图3.3 Bean定义3.4 Bean工厂 四、测试:创建简单的Bean容器4.1 用户Bean对象4.2 单…...

在Windows上通过SSH公私钥实现无密码登录Linux
在Windows上通过SSH公私钥实现无密码登录Linux 在Windows上生成SSH密钥对: 打开命令提示符或PowerShell窗口。 输入以下命令生成SSH密钥对: ssh-keygen -t rsa -b 4096按照提示输入密钥的保存路径和密码(可选)。 在指定的路径下…...
使用ppt和texlive生成eps图片(高清、可插入latex论文)
一、说明 写论文经常需要生成高清的图片插入到论文中,本文以ppt画图生成高质量的eps图片的实现来介绍具体操作方法。关于为什么要生成eps图片,一个是期刊要求(也有不要求的),另一个是显示图像的质量高。 转化获得eps…...
)
html5学习笔记19-SSE服务器发送事件(Server-Sent Events)
https://www.runoob.com/html/html5-serversentevents.html 允许网页获得来自服务器的更新。类似设置回调函数。 if(typeof(EventSource)!"undefined"){var sourcenew EventSource("demo_sse.php");source.onmessagefunction(event){document.getElement…...
高效数据湖构建与数据仓库融合:大规模数据架构最佳实践
文章目录 数据湖和数据仓库:两大不同理念数据湖数据仓库 数据湖与数据仓库的融合统一数据目录数据清洗和转换数据安全和权限控制数据分析和可视化 数据湖与数据仓库融合的优势未来趋势云原生数据湖自动化数据处理边缘计算与数据湖融合 结论 🎉欢迎来到云…...

Java学习笔记——35多线程02
线程同步 线程同步卖票案例同步代码块同步方法块 线程安全的类StringBufferVectorHashtable Lock锁 线程同步 卖票案例 public class SellTicket implements Runnable{private int tickets10;Overridepublic void run(){while (true){if(tickets>0){System.out.println(Th…...

每日刷题-3
目录 一、选择题 二、编程题 1、计算糖果 2、进制转换 一、选择题 1、 解析:在C语言中,以0开头的整数常量是八进制的,而不是十进制的。所以,0123的八进制表示相当于83的十进制表示,而123的十进制表示不变。printf函数…...
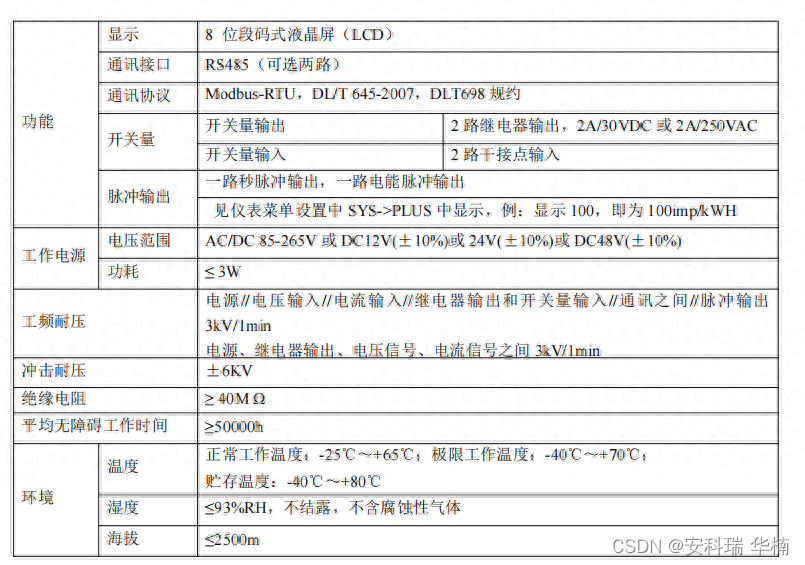
储能直流侧计量表DJSF1352
安科瑞 华楠 具有CE/UL/CPA/TUV认证 DJSF1352-RN导轨式直流电能表带有双路直流输入,主要针对电信基站、直流充电桩、太阳能光伏等应用场合而设计,该系列仪表可测量直流系统中的电压、电流、功率以及正反向电能等。在实际使用现场,即可计量总…...
)
机器学习报错合集(持续更新)
文章目录 1 列表转numpy,尺寸不均匀问题 1 列表转numpy,尺寸不均匀问题 ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (4,) inhomogeneous pa…...

【android12-linux-5.1】【ST芯片】【RK3588】【LSM6DSR】驱动移植
一、环境介绍 RK3588主板搭载Android12操作系统,内核是Linux5.10,使用ST的六轴传感器LSM6DSR芯片。 二、芯片介绍 LSM6DSR是一款加速度和角速度(陀螺仪)六轴传感器,还内置了一个温度传感器。该芯片可以选择I2C,SPI通讯,还有可编程终端,可以后置摄像头等设备,功能是很…...
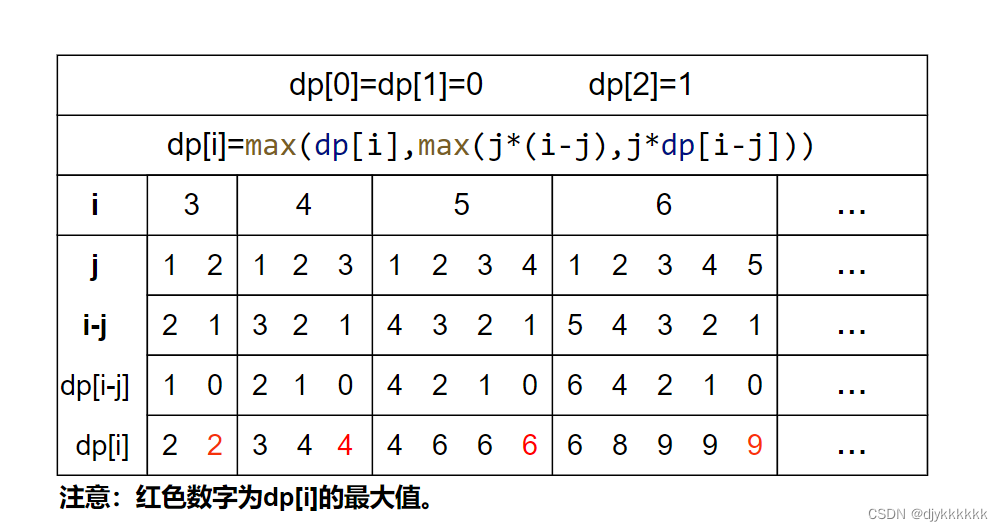
day-41 代码随想录算法训练营(19)动态规划 part 03
343.整数拆分 思路: 1.dp存储的是第i个数,拆分之后最大乘积2.dp[i]max(dp[i],max(j*(i-j),j*dp[i-j]));3.初始化:dp[0]dp[1]0,dp[2]1;4.遍历顺序:外层循环 3-n,内层循环 1-i 2.涉及两次取max: dp[i] 表…...
)
K8S安装部署 初始化操作(一)
准备好服务器和服务器资源 ip hostnameip资源 (2核2G也可以)k8s-master 192.168.37.1184核 4G 40G硬盘k8s-node1192.168.37.1192核 2G 20G硬盘k8s-node2192.168.37.1202核 2G 20G硬盘 初始操作三台同时执行 1、关闭防火墙 [rootlocalhost ~]# s…...
【多线程案例】单例模式(懒汉模式和饿汉模式)
文章目录 1. 什么是单例模式?2. 立即加载/“饿汉模式”3. 延时加载/“懒汉模式”3.1 第一版3.2 第二版3.3 第三版3.4 第四版 1. 什么是单例模式? 提起单例模式,就必须介绍设计模式,而设计模式就是在软件设计中,针对特殊…...
Anaconda - 操作系统安装程序 简要介绍
Anaconda 简要介绍 1. Anaconda 简介2. Anaconda 体系结构3. Anaconda 开发模型4. Anaconda 启动概述5. Anaconda 源码1. 接口2. 自定义组件3. 硬盘分区:使用python-blivet包4. Bootloader5. 各个步骤的配置:6. 安装软件包:7. 安装控制&#…...

【数据库设计】向量搜索HNSW算法优化
做向量存储的过程中,遇到向量搜索的情况处理,HNSW算法是目前向量搜索的主要算法之一,采用的是图算法,主要的问题是使用内存大,训练时间长。做算法优化过程中获得部分技巧,分享出来。 一、算法本身的优化 对…...

多通道振弦数据记录仪应用桥梁安全监测的关键要点
多通道振弦数据记录仪应用桥梁安全监测的关键要点 随着近年来桥梁建设和维护的不断推进,桥梁安全监测越来越成为公共关注的焦点。多通道振弦数据记录仪因其高效、准确的数据采集和处理能力,已经成为桥梁安全监测中不可或缺的设备。本文将从以下几个方面…...

深入了解HTTP代理的工作原理
HTTP代理是一种常见的网络代理方式,它可以帮助用户隐藏自己的IP地址,保护个人隐私和安全。了解HTTP代理的工作原理对于使用HTTP代理的用户来说非常重要。本文将深入介绍HTTP代理的工作原理。 代理服务器的作用 HTTP代理的工作原理基于代理服务器的作用。…...

2023年高教社杯数学建模国赛选题人数+C题进阶版修改思路详解
C题思路 修改版 C题保奖 数据预处理 3σ原则 区间判断法、人为判定 问题 1 聚类分析进行简单的分类 相互关系 数据服从正态分布(K-S检验等判定分布类型后) 才能做person相关性 图表结合(热力图、数据结果表) 分布规律 宏…...

突然想写一些东西
---title: blogdate: 2026-05-15 02:18:57tags: ["chitchat"]about: 突然想写一些东西---马上毕业了,在写致谢的时候发现好像想写的东西挺多的,但是不知道怎么写出来了,可能是因为很久没写东西了?也可能是AI用多了自己深…...

AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控
AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...
:从语义解析、权重分配到多模态对齐的完整链路)
Midjourney提示词工程实战手册(工业级Prompt架构白皮书):从语义解析、权重分配到多模态对齐的完整链路
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词工程的核心范式与工业级演进路径 提示词工程已从早期的“关键词堆砌”跃迁为融合语义建模、风格解耦与可控生成的系统性工程。在工业级实践中,其核心范式正围绕**结构化提示…...

人类不擅长做出复杂的决策。人工智能可以指出这些错误。
图片来源:图片由编辑团队使用人工智能生成,仅供参考。来源:https://techxplore.com/news/2026-05-humans-bad-complex-decisions-ai.html当罗列优缺点不足以解决问题时,康奈尔大学研究人员开发的一种新型决策工具可以利用人工智能…...

跨越语言障碍的智能方案:DeepL Chrome扩展助力无缝多语言浏览
跨越语言障碍的智能方案:DeepL Chrome扩展助力无缝多语言浏览 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension 想象一下,当你浏览外文网页时…...

基于CircuitPython的嵌入式记忆游戏开发:状态机与TileGrid实战
1. 项目概述:一个嵌入式平台上的经典记忆配对游戏如果你玩过那种翻牌配对的记忆游戏,现在我们可以把它搬到一块小小的嵌入式开发板上,用CircuitPython来实现。这不仅仅是把游戏逻辑移植过来那么简单,它涉及到在资源受限的微控制器…...

【初阶数据结构】 左右逢源的分支诗律 二叉树1
📖 点击展开/收起 文章目录 文章目录树的概念***树的基础概念***森林树和森林的存储二叉树二叉树的性质二叉树的遍历二叉树的前序遍历二叉树的中序遍历二叉树的后序遍历希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力!树的概念 在讲解…...

48_《智能体微服务架构企业级实战教程》智能助手主应用服务之工具决策节点
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

告别盗版与广告:Office 2021官方纯净部署实战指南
1. 为什么选择官方纯净部署Office 2021? 每次打开电脑看到弹窗广告,或者发现系统莫名变慢的时候,你是不是也怀疑过那些所谓的"破解版"办公软件?我去年就吃过这个亏——用了某个号称"永久激活"的Office安装包…...

开源灵巧手OpenClaw:从机械设计到AI抓取的完整实现指南
1. 项目概述:当开源机械爪遇上AI大脑 最近在机器人开源社区里,一个名为“OpenClaw”的项目引起了我的注意。这个由Turbo Labs团队发布的项目,其核心目标非常明确:打造一个低成本、高性能、且完全开源的机器人灵巧手(或…...