高效数据湖构建与数据仓库融合:大规模数据架构最佳实践
文章目录
- 数据湖和数据仓库:两大不同理念
- 数据湖
- 数据仓库
- 数据湖与数据仓库的融合
- 统一数据目录
- 数据清洗和转换
- 数据安全和权限控制
- 数据分析和可视化
- 数据湖与数据仓库融合的优势
- 未来趋势
- 云原生数据湖
- 自动化数据处理
- 边缘计算与数据湖融合
- 结论

🎉欢迎来到云计算技术应用专栏~高效数据湖构建与数据仓库融合:大规模数据架构最佳实践
- ☆* o(≧▽≦)o *☆嗨~我是IT·陈寒🍹
- ✨博客主页:IT·陈寒的博客
- 🎈该系列文章专栏:云计算技术应用
- 📜其他专栏:Java学习路线 Java面试技巧 Java实战项目 AIGC人工智能 数据结构学习 云计算技术应用
- 🍹文章作者技术和水平有限,如果文中出现错误,希望大家能指正🙏
- 📜 欢迎大家关注! ❤️
在当今信息时代,数据被认为是最宝贵的资源之一。企业越来越依赖数据来推动业务决策、改进产品和服务,以及实现创新。因此,构建高效的数据架构变得至关重要。本文将深入探讨如何构建高效的数据湖(Data Lake)并将其与传统数据仓库融合,以满足大规模数据处理的需求。

数据湖和数据仓库:两大不同理念
在讨论高效数据湖和数据仓库融合之前,让我们首先了解一下数据湖和数据仓库的基本概念和区别。
数据湖
数据湖是一个存储海量原始数据的中心存储库,它不仅包括结构化数据(如数据库表),还包括非结构化数据(如文本文档、图像、音频和视频等)。数据湖的主要优势在于其灵活性和扩展性。数据可以以原始格式存储,而不需要事先定义模式或架构。这意味着您可以将任何类型的数据都存储在数据湖中,而无需担心数据丢失或格式不匹配的问题。
数据仓库
与数据湖不同,数据仓库是一个用于存储已清理、已加工和已定义模式的数据的存储库。数据仓库通常用于支持业务智能、报告和数据分析。它们的数据通常以表格形式组织,便于查询和分析。数据仓库通常要求在数据进入仓库之前进行数据清洗和转换,以确保数据的一致性和质量。

数据湖与数据仓库的融合
尽管数据湖和数据仓库有各自的优势,但在大规模数据处理的背景下,将它们结合起来可以实现更好的数据管理和分析。以下是一些融合两者的最佳实践。

统一数据目录
为了实现数据湖和数据仓库的融合,首先需要一个统一的数据目录。数据目录是一个用于记录和管理存储在数据湖和数据仓库中的数据的中心位置。这个目录应该包括数据的元数据信息,如数据来源、数据格式、数据质量等。
# 代码示例:数据目录示例{"data_source": "数据湖","data_format": "Parquet","data_quality": "高","data_description": "销售订单数据"
}
通过统一的数据目录,您可以轻松地查找和访问数据湖和数据仓库中的数据,而无需了解数据存储的具体细节。
数据清洗和转换
虽然数据湖允许存储原始数据,但在将数据用于分析之前,通常需要进行数据清洗和转换。这是数据仓库的一个核心特性。在融合数据湖和数据仓库时,可以借鉴数据仓库的数据清洗和转换流程,将其应用于数据湖中的数据。
# 代码示例:数据清洗和转换# 从数据湖中获取原始数据
raw_data = data_lake.get_data("销售订单数据")# 执行数据清洗和转换操作
cleaned_data = data_warehouse.clean_and_transform(raw_data)# 存储清洗后的数据到数据仓库
data_warehouse.store_data("清洗后的销售订单数据", cleaned_data)

数据安全和权限控制
在融合数据湖和数据仓库时,数据的安全性和权限控制至关重要。您需要确保只有经过授权的用户可以访问和修改数据。数据仓库通常提供了强大的权限控制功能,可以用于管理数据的访问权限。这些功能也可以扩展到数据湖中,以确保数据湖中的数据得到充分保护。
数据分析和可视化
一旦数据湖和数据仓库融合,您可以使用各种数据分析和可视化工具来探索和分析数据。这些工具可以连接到统一的数据目录,并从中检索数据,无需了解数据的存储位置。这使得数据分析变得更加灵活和高效。
# 代码示例:数据分析和可视化# 使用分析工具连接到统一的数据目录
analysis_tool.connect(data_catalog)# 从数据目录中选择要分析的数据
selected_data = analysis_tool.select_data("销售订单数据")# 进行数据分析和可视化操作
analysis_tool.analyze_and_visualize(selected_data)
数据湖与数据仓库融合的优势
融合数据湖和数据仓库带来了多重优势:
-
灵活性和扩展性:数据湖提供了存储各种类型和格式数据的灵活性,而数据仓库提供了清洗和转换数据的能力。融合后,您可以同时享受到这两者的优势。
-
更好的数据管理:统一的数据目录和数据清洗流程有助于更好地管理数据,提高数据质量和一致性。
-
更高效的数据分析:数据分析和可视化工具可以轻松地连接到统一的数据目录,提供更高效的数据分析体验。
-
更强的数据安全性:借助数据仓库的权限控制功能,您可以确保数据的安全性,只有经过授权的用户可以访问和修改数据。

未来趋势
随着大规模数据处理需求的不断增长,数据湖与数据仓库融合的趋势将进一步加强。未来,我们可以期待更多创新和技术的出现,以提高数据处理的效率和可扩展性。
云原生数据湖
云原生数据湖是一种将数据湖构建在云计算平台上的方法。它利用云计算的弹性和资源管理功能,使数据湖更容易管理和扩展。未来,云原生数据湖将成为数据湖构建的主要趋势之一。

自动化数据处理
自动化数据处理是利用机器学习和人工智能技术来自动执行数据清洗、转换和分析的方法。未来,我们可以期待更多自动化工具的出现,以减少人工干预并提高数据处理的效率。
边缘计算与数据湖融合
随着边缘计算的兴起,数据湖将与边缘计算相结合,以支持在边缘设备上进行数据处理和分析。这将在物联网和自动化领域带来更多应用。
结论
数据湖与数据仓库的融合代表了数据架构领域的一个重要趋势。通过统一的数据目录、数据清洗和转换、数据安全和权限控制,以及数据分析和可视化工具的应用,我们可以更好地管理和分析大规模数据。未来,随着云原生数据湖、自动化数据处理和边缘计算的发展,我们可以期待数据处理领域的更多创新和突破。这些技术将为企业提供更多数据驱动的机会,推动业务发展和创新。
🧸结尾
❤️ 感谢您的支持和鼓励! 😊🙏
📜您可能感兴趣的内容:
- 【Java面试技巧】Java面试八股文 - 掌握面试必备知识(目录篇)
- 【Java学习路线】2023年完整版Java学习路线图
- 【AIGC人工智能】Chat GPT是什么,初学者怎么使用Chat GPT,需要注意些什么
- 【Java实战项目】SpringBoot+SSM实战:打造高效便捷的企业级Java外卖订购系统
- 【数据结构学习】从零起步:学习数据结构的完整路径
相关文章:
高效数据湖构建与数据仓库融合:大规模数据架构最佳实践
文章目录 数据湖和数据仓库:两大不同理念数据湖数据仓库 数据湖与数据仓库的融合统一数据目录数据清洗和转换数据安全和权限控制数据分析和可视化 数据湖与数据仓库融合的优势未来趋势云原生数据湖自动化数据处理边缘计算与数据湖融合 结论 🎉欢迎来到云…...

Java学习笔记——35多线程02
线程同步 线程同步卖票案例同步代码块同步方法块 线程安全的类StringBufferVectorHashtable Lock锁 线程同步 卖票案例 public class SellTicket implements Runnable{private int tickets10;Overridepublic void run(){while (true){if(tickets>0){System.out.println(Th…...

每日刷题-3
目录 一、选择题 二、编程题 1、计算糖果 2、进制转换 一、选择题 1、 解析:在C语言中,以0开头的整数常量是八进制的,而不是十进制的。所以,0123的八进制表示相当于83的十进制表示,而123的十进制表示不变。printf函数…...
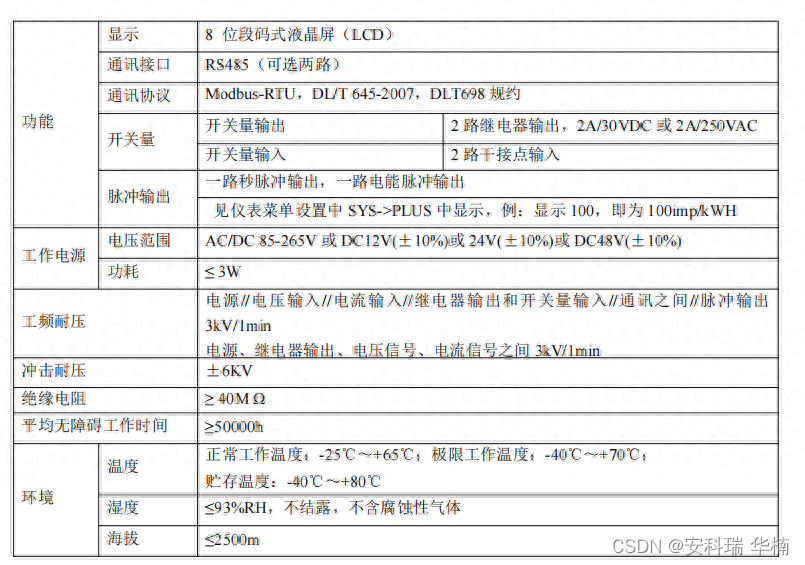
储能直流侧计量表DJSF1352
安科瑞 华楠 具有CE/UL/CPA/TUV认证 DJSF1352-RN导轨式直流电能表带有双路直流输入,主要针对电信基站、直流充电桩、太阳能光伏等应用场合而设计,该系列仪表可测量直流系统中的电压、电流、功率以及正反向电能等。在实际使用现场,即可计量总…...
)
机器学习报错合集(持续更新)
文章目录 1 列表转numpy,尺寸不均匀问题 1 列表转numpy,尺寸不均匀问题 ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (4,) inhomogeneous pa…...

【android12-linux-5.1】【ST芯片】【RK3588】【LSM6DSR】驱动移植
一、环境介绍 RK3588主板搭载Android12操作系统,内核是Linux5.10,使用ST的六轴传感器LSM6DSR芯片。 二、芯片介绍 LSM6DSR是一款加速度和角速度(陀螺仪)六轴传感器,还内置了一个温度传感器。该芯片可以选择I2C,SPI通讯,还有可编程终端,可以后置摄像头等设备,功能是很…...
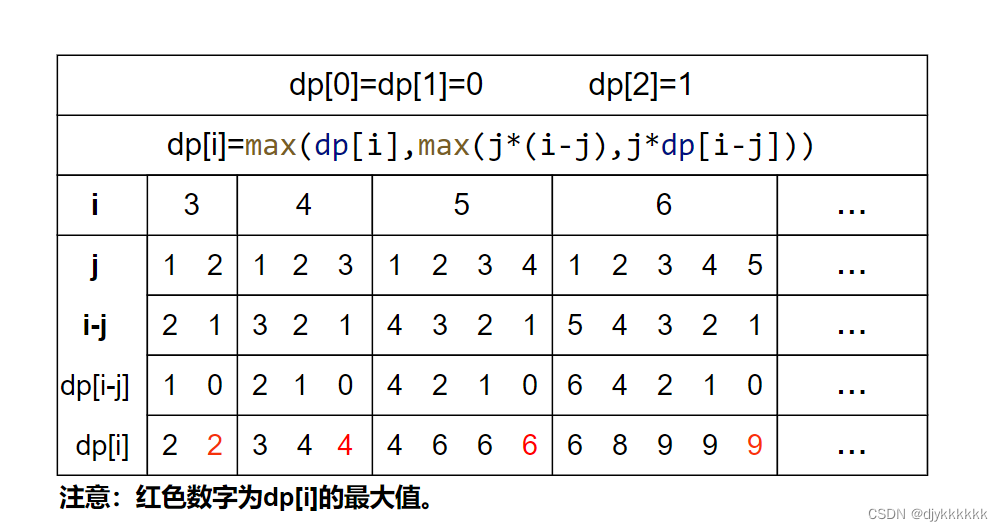
day-41 代码随想录算法训练营(19)动态规划 part 03
343.整数拆分 思路: 1.dp存储的是第i个数,拆分之后最大乘积2.dp[i]max(dp[i],max(j*(i-j),j*dp[i-j]));3.初始化:dp[0]dp[1]0,dp[2]1;4.遍历顺序:外层循环 3-n,内层循环 1-i 2.涉及两次取max: dp[i] 表…...
)
K8S安装部署 初始化操作(一)
准备好服务器和服务器资源 ip hostnameip资源 (2核2G也可以)k8s-master 192.168.37.1184核 4G 40G硬盘k8s-node1192.168.37.1192核 2G 20G硬盘k8s-node2192.168.37.1202核 2G 20G硬盘 初始操作三台同时执行 1、关闭防火墙 [rootlocalhost ~]# s…...
【多线程案例】单例模式(懒汉模式和饿汉模式)
文章目录 1. 什么是单例模式?2. 立即加载/“饿汉模式”3. 延时加载/“懒汉模式”3.1 第一版3.2 第二版3.3 第三版3.4 第四版 1. 什么是单例模式? 提起单例模式,就必须介绍设计模式,而设计模式就是在软件设计中,针对特殊…...
Anaconda - 操作系统安装程序 简要介绍
Anaconda 简要介绍 1. Anaconda 简介2. Anaconda 体系结构3. Anaconda 开发模型4. Anaconda 启动概述5. Anaconda 源码1. 接口2. 自定义组件3. 硬盘分区:使用python-blivet包4. Bootloader5. 各个步骤的配置:6. 安装软件包:7. 安装控制&#…...

【数据库设计】向量搜索HNSW算法优化
做向量存储的过程中,遇到向量搜索的情况处理,HNSW算法是目前向量搜索的主要算法之一,采用的是图算法,主要的问题是使用内存大,训练时间长。做算法优化过程中获得部分技巧,分享出来。 一、算法本身的优化 对…...

多通道振弦数据记录仪应用桥梁安全监测的关键要点
多通道振弦数据记录仪应用桥梁安全监测的关键要点 随着近年来桥梁建设和维护的不断推进,桥梁安全监测越来越成为公共关注的焦点。多通道振弦数据记录仪因其高效、准确的数据采集和处理能力,已经成为桥梁安全监测中不可或缺的设备。本文将从以下几个方面…...

深入了解HTTP代理的工作原理
HTTP代理是一种常见的网络代理方式,它可以帮助用户隐藏自己的IP地址,保护个人隐私和安全。了解HTTP代理的工作原理对于使用HTTP代理的用户来说非常重要。本文将深入介绍HTTP代理的工作原理。 代理服务器的作用 HTTP代理的工作原理基于代理服务器的作用。…...

2023年高教社杯数学建模国赛选题人数+C题进阶版修改思路详解
C题思路 修改版 C题保奖 数据预处理 3σ原则 区间判断法、人为判定 问题 1 聚类分析进行简单的分类 相互关系 数据服从正态分布(K-S检验等判定分布类型后) 才能做person相关性 图表结合(热力图、数据结果表) 分布规律 宏…...
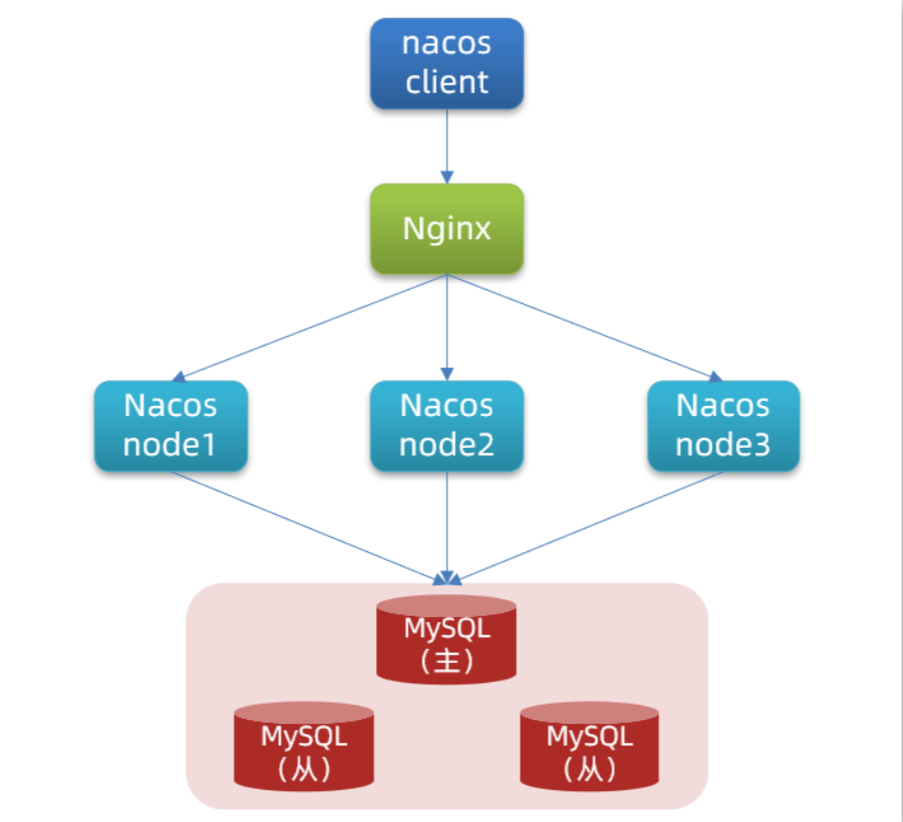
第三章微服务配置中心
文章目录 Nacos配置中心统一配置管理在nacos中添加配置文件从微服务拉取配置 配置热更新多环境共享配置 搭建Nacos集群搭建集群初始化数据库配置Nacos启动nginx反向代理 Nacos配置中心 Nacos配置管理 Nacos除了可以做注册中心,同样可以做配置管理来使用。 统一配置…...

箭头函数(arrow function)与普通函数之间的区别是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 语法简洁性:⭐ this 的绑定:⭐ 不能用作构造函数:⭐ 没有 arguments 对象:⭐ 不适用于方法:⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上…...
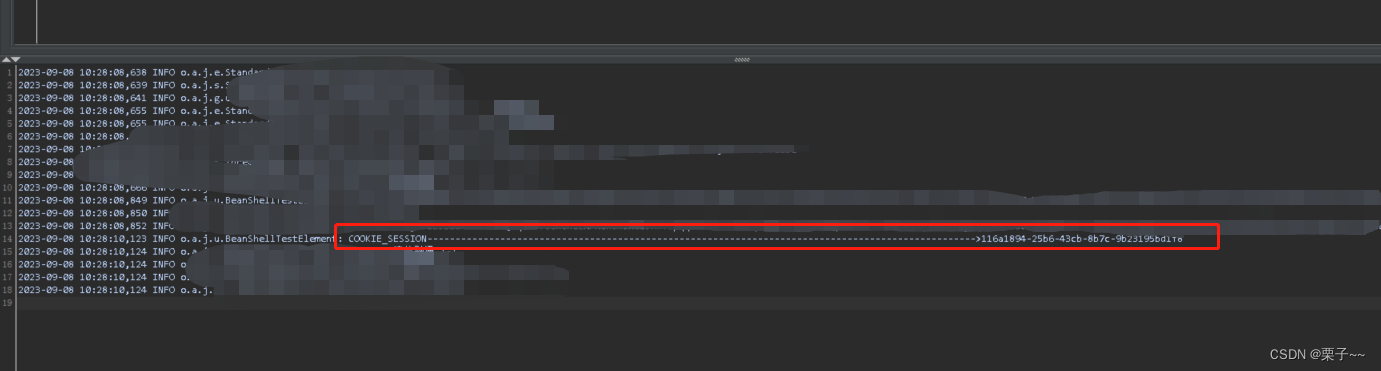
JMeter 4.0 如何获取cookie
文章目录 前言JMeter 4.0 如何获取cookie1. 修改jmeter.properties 文件2. 添加HTTP Cookie 管理器3. 获取cookie信息 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天…...
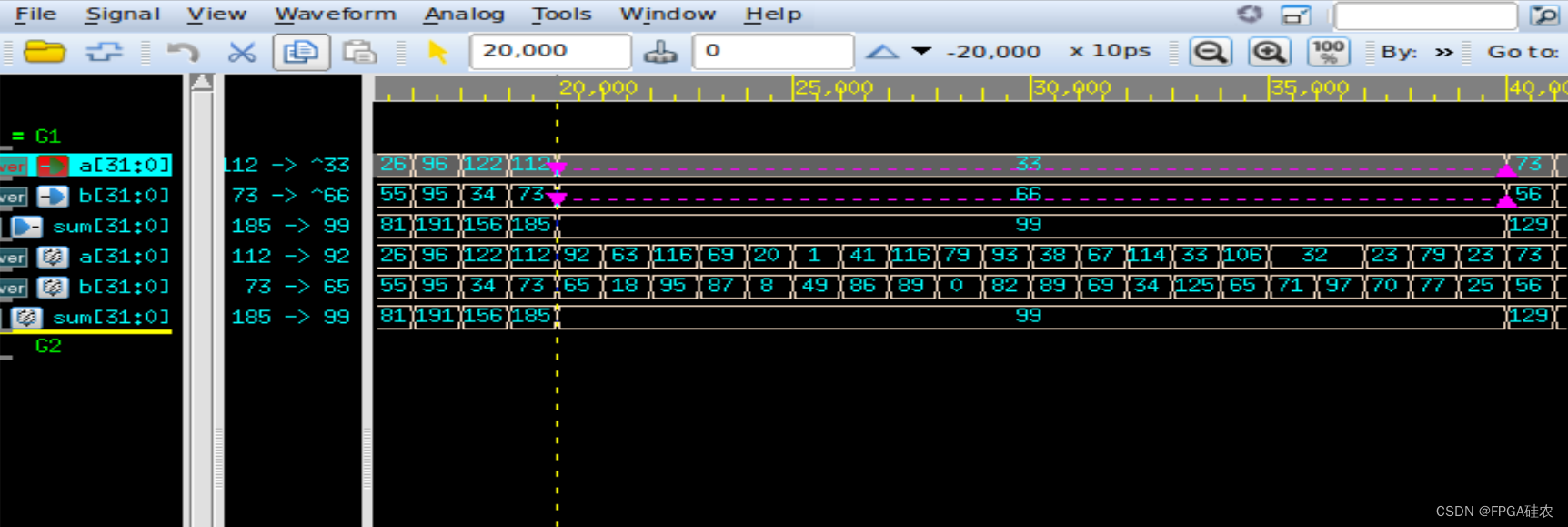
【数字IC/FPGA】Verilog中的force和release
在Verilog中,将force用于variable会覆盖掉过程赋值,或者assign引导的连续(procedural assign)赋值,直到release。 下面通过一个简单的例子展示其用法: 加法器代码 module adder ( input logic [31:0] a, …...

进阶C语言-指针的进阶(上)
指针的进阶 📖1.字符指针📖2.指针数组📖3.数组指针🎈3.1 数组指针的定义🎈3.2 &数组名VS数组名🎈3.3 数组指针的使用 📖4.数组参数、指针参数🎈4.1一维数组传参🎈4.2…...

初始化一个 vite + vue 项目
创建项目 首先使用以下命令创建一个vite项目 npm create vite然后根据提示命令 cd 到刚创建的项目目录下,使用npm install安装所需要的依赖包,再使用npm run dev即可启动项目 配置 vite.config.js 添加process.env配置,如果下面 vue-route…...

轻量级文本处理引擎Tokely:从分词到模型推理的部署与优化实战
1. 项目概述与核心价值最近在折腾一些个人项目,经常需要处理文本生成、内容摘要这类任务。市面上现成的API服务虽然方便,但成本、隐私和定制化程度总让人不太放心。于是,我开始寻找一个能自己部署、轻量且功能聚焦的文本处理工具。在这个过程…...

嵌入式音频处理与SD卡系统克隆实战指南
1. 项目概述与核心价值如果你正在捣鼓一块像Chumby Hacker Board这样的嵌入式开发板,或者任何带有音频输出和SD卡存储的Linux设备,那么你迟早会碰到两个绕不开的“硬骨头”:音频信号的处理和存储系统的克隆部署。前者决定了你的设备能不能“好…...

AI Agent工作流引擎:从DAG编排到生产级应用实践
1. 项目概述:AI Agent工作流引擎的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“ai-agent-workflow”。光看名字,你可能觉得这又是一个关于AI智能体的框架,但仔细研究它的代码和设计理念,你会发现它瞄准的是一…...

Vibeproxy:轻量级可编程HTTP代理,实现API Mock与故障注入
1. 项目概述:一个轻量级的HTTP代理工具最近在折腾一些需要模拟不同网络环境或者进行API测试的项目时,我一直在寻找一个足够轻量、灵活且易于集成的HTTP代理工具。市面上成熟的代理方案很多,但要么功能过于臃肿,要么配置起来相当繁…...

基于RAG架构的企业级私有化大模型知识库实战指南
1. 项目概述:当大语言模型遇见企业级数据如果你最近在关注企业级AI应用,特别是如何安全、高效地利用大语言模型来处理和分析内部数据,那么“h2oai/h2ogpt”这个项目绝对值得你花时间深入了解。这不仅仅是一个简单的聊天机器人接口,…...

4.【Python】Python3 注释
第一步:分析与整理 注释1. 注释的作用 不影响程序执行,只提高可读性。帮助理解代码逻辑,方便团队协作。2. 单行注释 以 # 开头,直到行末的所有内容均为注释。 # 这是一个注释 print("Hello, World!") # 这也是注释3. 多…...

Postman+Newman自动化测试报告生成全攻略:让微信小程序接口回归测试5分钟搞定
PostmanNewman自动化测试报告生成全攻略:让微信小程序接口回归测试5分钟搞定 在追求研发效能的今天,手工重复执行接口测试已成为效率瓶颈。想象一下:每次微信小程序迭代更新,测试工程师都需要在Postman中逐个点击上百个接口用例&a…...

为什么顶尖考古团队已弃用传统文献管理?NotebookLM实现遗址报告生成效率提升300%的底层逻辑
更多请点击: https://intelliparadigm.com 第一章:NotebookLM考古学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,正悄然重塑考古学研究的信息处理范式。传统考古工作依赖大量手写笔记、田野报告、碳十四测年数…...

初创团队如何借助 Taotoken 的 Token Plan 有效控制大模型使用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何借助 Taotoken 的 Token Plan 有效控制大模型使用成本 对于初创团队和独立开发者而言,在项目早期验证想法…...

如何提升SQL存储过程逻辑复用_封装通用存储过程函数
SQL Server无函数式存储过程,需用标量函数(单值计算)或表值函数(结果集)替代;标量函数禁用DML和非确定性函数,ITVF性能优于MSTVF;MySQL函数须声明DETERMINISTIC等属性;跨…...