python selenium 爬虫教程
Python和Selenium是很强大的爬虫工具,可以用于自动化地模拟浏览器行为,从网页中提取数据。下面是一个简单的使用Python和Selenium进行爬虫的案例。
入门:
1. 安装和配置:
首先,你需要安装Python和Selenium。可以使用pip命令来安装Selenium库:pip install selenium。
然后,你还需要下载对应浏览器的驱动,比如Chrome浏览器的驱动。可以通过访问 https://sites.google.com/a/chromium.org/chromedriver/ 下载,下载完成后,将驱动文件添加到系统环境变量中。
2. 编写代码:
from selenium import webdriver# 创建一个浏览器驱动实例
driver = webdriver.Chrome()# 打开网页
driver.get('https://www.example.com')# 执行爬取操作
# ...# 关闭浏览器
driver.quit()
3. 执行爬取操作:
使用Selenium的API,可以模拟浏览器的操作,例如点击按钮、填写表单、滚动页面等。下面是一些常用的操作示例:
- 查找元素:使用find_element方法根据元素的选择器查找页面元素。
element = driver.find_element_by_css_selector('.class_name')
- 点击元素:
element.click()
- 填写表单:
input_element = driver.find_element_by_css_selector('input[name="username"]')
input_element.send_keys('your username')
- 提取数据:
element_text = element.text
- 截屏保存网页:
driver.save_screenshot('screenshot.png')
4. 高级功能:
Selenium还提供了一些高级功能,例如切换窗口、处理弹窗、执行JavaScript等。你可以根据具体需求使用这些功能来完成更复杂的爬虫任务。
5. 异常处理:
在使用Selenium进行爬取时,可能会遇到一些异常,例如元素找不到、网络超时等。你可以使用try-except语句来进行异常处理,确保程序的健壮性。
以上是一个简单的使用Python和Selenium进行爬虫的案例。通过Selenium提供的API,我们可以方便地模拟浏览器行为,从网页中提取所需的数据。当然,爬虫的使用需要遵守相关法律法规,并尊重网站的爬取规则,以避免造成不必要的麻烦。
安全:
在使用Python和Selenium进行爬虫时,需要考虑一些安全问题,以确保爬虫的合法性和保护个人信息的安全。以下是一些安全分析的建议:
1. 合法性和隐私保护:
- 遵守网站的使用条款和隐私政策,确保你的爬虫行为是合法的。
- 不要爬取包含个人敏感信息的网站,如银行账号、密码等。
- 做好数据处理和存储安全,确保爬取的数据不会被滥用或泄露。
2. 爬取频率控制:
- 合理设置爬取间隔,避免对目标网站造成过大的负担和影响其正常运行。
- 避免过于频繁的请求,以免被认为是恶意爬虫而被封禁。
3. 反爬机制处理:
- 一些网站会设置反爬机制,如验证码、IP封锁等。使用Selenium可以处理一些简单的验证码,但对于复杂的验证码,可能需要其他技术或手动干预来解决。
- 使用代理IP来轮换请求,以避免被封禁IP。
- 随机化请求头信息,模拟真实用户的行为。
4. 异常处理和容错机制:
- 在代码中添加异常处理机制,对可能出现的异常进行捕获和处理,以保证程序的稳定性。
- 对于请求失败、元素找不到等情况,可以设置重试机制或跳过该条数据,提高爬虫的健壮性。
5. 日志记录和监控:
- 记录爬虫运行过程中的日志,方便排查问题和分析。
- 监控爬虫的运行状态,及时发现和处理异常情况。
6. 使用合法的API:
- 对于一些网站,可能提供了官方的API接口,可以优先使用这些接口进行爬取,以避免对网站造成不必要的负担。
使用Python和Selenium进行爬虫时,需要注意遵守法律法规,尊重网站的规则,并采取安全措施保护数据和个人信息的安全。合理设置爬取频率,处理反爬机制,添加异常处理和容错机制,记录日志和监控爬虫运行状态等,都是保证爬虫安全的重要措施。
案例:爬取商品价格信息
假设你是一个电商公司的数据分析师,需要爬取竞争对手的商品价格信息以进行市场分析。以下是一个案例分析,展示如何使用Python和Selenium进行安全的爬取。
1. 安装必要的库和工具:
- 安装Python和Selenium库。
- 下载并配置WebDriver,如ChromeDriver,以便与Selenium进行交互。
2. 设置爬虫参数:
- 确定要爬取的竞争对手网站的URL。
- 设置合理的爬取间隔,以避免给目标网站带来过大的负担。
3. 编写爬虫代码:
- 使用Selenium打开网页,并使用WebDriver API来查找和提取商品价格信息。
- 可以通过XPath或CSS选择器定位和提取目标元素。
- 设置合理的异常处理机制,例如捕获元素找不到的异常,并跳过该商品继续爬取下一个商品。
4. 添加反爬机制处理:
- 如果目标网站有反爬机制,可以使用Selenium来处理一些简单的验证码,如输入文本验证码。
- 对于复杂的验证码,可能需要其他技术或手动干预来解决。
5. 存储和分析数据:
- 将爬取的商品价格信息存储到数据库或文件中,以便后续的数据分析。
- 对爬取的数据进行清洗和预处理,确保数据的准确性和完整性。
6. 日志记录和监控:
- 在代码中添加日志记录,记录爬虫运行过程中的重要信息和异常情况。
- 设置定期的监控任务,检查爬虫的运行状态,并及时发现和处理问题。
7. 合法性和隐私保护:
- 遵守目标网站的使用条款和隐私政策,确保你的爬虫行为是合法的。
- 不要爬取包含个人敏感信息的网站,如用户账号、密码等。
- 做好数据处理和存储安全,确保爬取的数据不会被滥用或泄露。
通过以上步骤,可以安全地使用Python和Selenium进行商品价格信息的爬取。然后可以对爬取的数据进行分析,比较竞争对手的价格,了解市场动态,并为公司的业务决策提供支持。
除了上述的案例分析,还有一些补充内容可以考虑:
- 爬虫的并发性:对于大规模的数据爬取,可以考虑使用多线程或异步请求来提高爬虫的并发性和效率。
- 反爬机制的处理:针对不同的反爬机制,可以使用代理IP、User-Agent轮换、请求头伪装等技术来规避反爬策略。
- 数据处理和分析:爬取的数据可能需要进行清洗和预处理,例如去除重复数据、填充缺失值等。然后可以使用数据分析工具如Pandas、NumPy等进行进一步的数据探索和分析。
- 定时任务和自动化:可以设置定时任务,定期运行爬虫并更新数据,以保持数据的实时性。也可以考虑将爬虫部署到云服务器上,实现自动化运行。
- 随机性和健壮性:为了降低被目标网站识别为爬虫的概率,可以在爬虫代码中添加一些随机性,如随机的等待时间、随机的浏览器窗口大小等。此外,要做好异常处理,防止程序崩溃或停止运行。
- 合法性和道德性:在进行任何爬虫活动之前,请确保你遵守相关法律法规和目标网站的使用条款。同时,要注意道德准则,不要滥用爬虫技术或对他人造成困扰。
- 安全性和隐私保护:在爬取过程中,要确保目标网站和用户的数据安全,不要进行非法的数据获取或侵犯用户的隐私。同时,要保护爬虫的机密信息,如登录凭证和API密钥。
通过综合考虑以上因素,可以开发出高效、稳定、安全的爬虫系统,为数据分析和业务决策提供有价值的支持。
练习题:
-
编写一个爬虫程序,爬取某度首页的标题和链接,并将结果保存到一个文本文件中。
-
编写一个爬虫程序,爬取某瓣电影Top250的电影名称、评分和链接,并将结果保存到一个Excel文件中。
-
编写一个爬虫程序,爬取某乎某个话题下的问题标题和链接,并将结果保存到一个CSV文件中。
-
编写一个爬虫程序,爬取某个电商网站的商品信息,包括商品名称、价格和销量,并将结果保存到一个MySQL数据库中。
-
编写一个爬虫程序,爬取某个新闻网站的新闻标题、时间和内容,并将结果保存到一个MongoDB数据库中。
这些练习题可以帮助你巩固爬虫的基本知识和技能,并锻炼你的编程能力。你可以使用Python和相关的爬虫库(如Requests、BeautifulSoup、Scrapy等)来完成这些练习。
相关文章:

python selenium 爬虫教程
Python和Selenium是很强大的爬虫工具,可以用于自动化地模拟浏览器行为,从网页中提取数据。下面是一个简单的使用Python和Selenium进行爬虫的案例。 入门: 1. 安装和配置: 首先,你需要安装Python和Selenium。可以使用…...

Linux基础知识及常见指令
Linux简介及相关概念 什么是Linux? Linux是一个免费开源的操作系统内核,最初由Linus Torvalds于1991年创建。它是各种Linux发行版(通常称为“发行版”)的核心组件,这些发行版是完整的操作系统,包括Linux内…...

分享一个基于Python和Django的产品销售收入数据分析系统源码
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! 💕&…...
UniTask保姆级教程
目录 一、UniTask的简介和安装 https://github.com/Cysharp/UniTask.gitpathsrc/UniTask/Assets/Plugins/UniTask 空载性能测试 二、基础用法详解 三、基础用法扩展 四、进阶 五、VContainer简介 六、VContainer基础实例 方便快速查找 一、UniTask的简介和安装 项目地…...
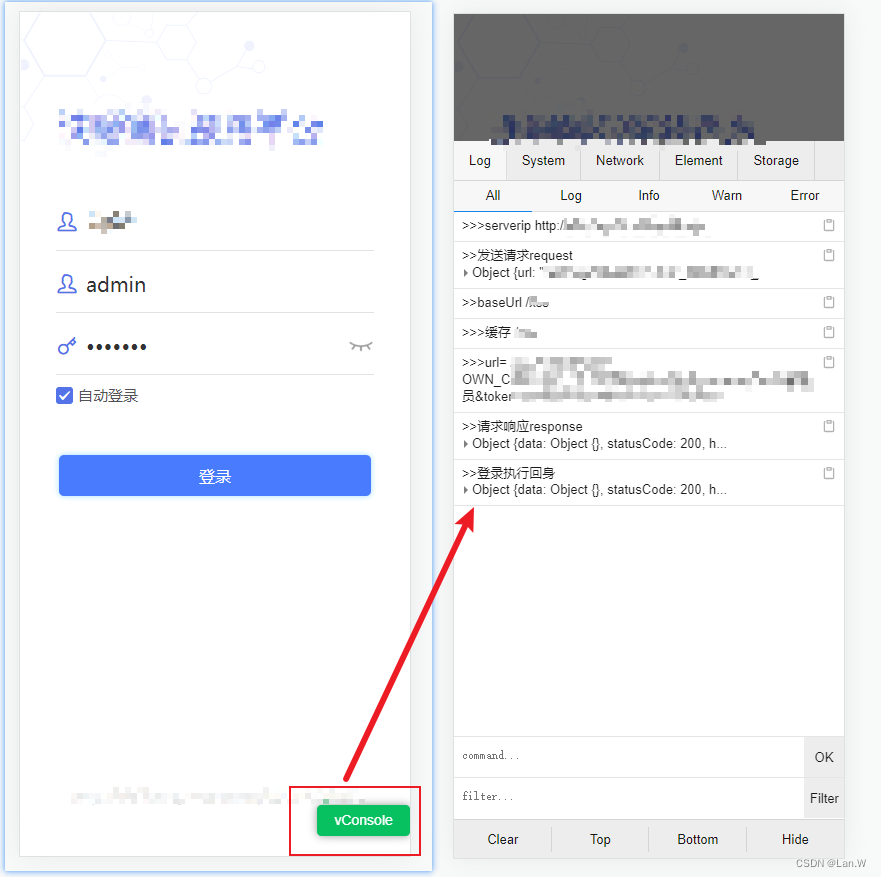
uni-app 可视化创建的项目 移动端安装调试插件vconsole
可视化创建的项目,在插件市场找不到vconsole插件了。 又不好npm install vconsole 换个思路,先创建一个cli脚手架脚手架的uni-app项目,然后再此项目上安装vconsole cli脚手架创建uni-app项目 安装插件 项目Terminal运行命令:npm…...

HOperatorSet.GenRandomRegions 有内存泄漏或缓存,释放不掉
开发环境 VS2022 win7 halcon12 halcon18 随机生成100个园 不释放 private void butTemp_Click(object sender, EventArgs e) { butTemp.Enabled false; HOperatorSet.SetSystem("clip_region", "false"); …...

一维数组笔试题及其解析
Lei宝啊 :个人主页 愿所有美好不期而遇 前言: 数组名在寻常情况下表示首元素地址,但有两种情况例外: 1.sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小 2.&数组名,这里的…...

微信小程序源码
1:仿豆瓣电影微信小程序 https://github.com/zce/weapp-demo 2:微信小程序移动端商城 https://github.com/liuxuanqiang/wechat-weapp-mall 3:Gank微信小程序 https://github.com/lypeer/wechat-weapp-gank 4:微信小程序高仿QQ…...

Browserslist 信息和配置使用整理
我们可以在各种前端工程看到 Browserslist 的配置身影,看似简单但实际上可能会有暗坑导致线上兼容问题,借此文来整理下 Browserslist 的信息。 Browserslist 是由 Autoprefixer 团队维护的一个开源项目,用于自动处理 CSS 和 JavaScript 文件…...
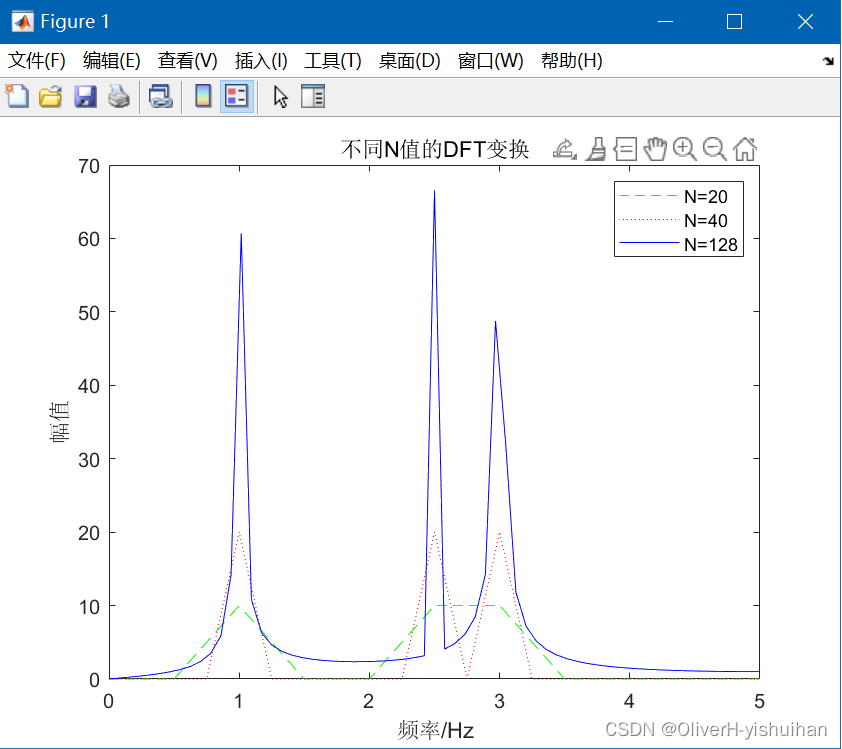
Matlab 如何选择采样频率和信号长度
Matlab 如何选择采样频率和信号长度 1、概述 在实际信号分析中经常会遇到要分辨出频率间隔为 的两个分量,在这种情形中如何选择采样频率和信号的长度呢? 2、案例分析 设有一个信号由三个正弦信号组成,其频率分别为 ,即…...

TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents
本文是LLM系列文章,针对《TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents》的翻译。 TPTU:任务规划和工具使用的LLM Agents 摘要1 引言2 方法3 评估4 相关工作5 结论 摘要 随着自然语言处理的最新进展,大型语言模型&…...

【Spring IoC容器的加载过程】
加载配置文件 Spring IoC容器的配置通常以XML形式存储,并通过ResourceLoader和XmlBeanDefinitionReader类来加载。ResourceLoader主要负责加载Bean配置文件,而XmlBeanDefinitionReader则负责解析这些文件,将Bean定义封装为BeanDefinition对象…...
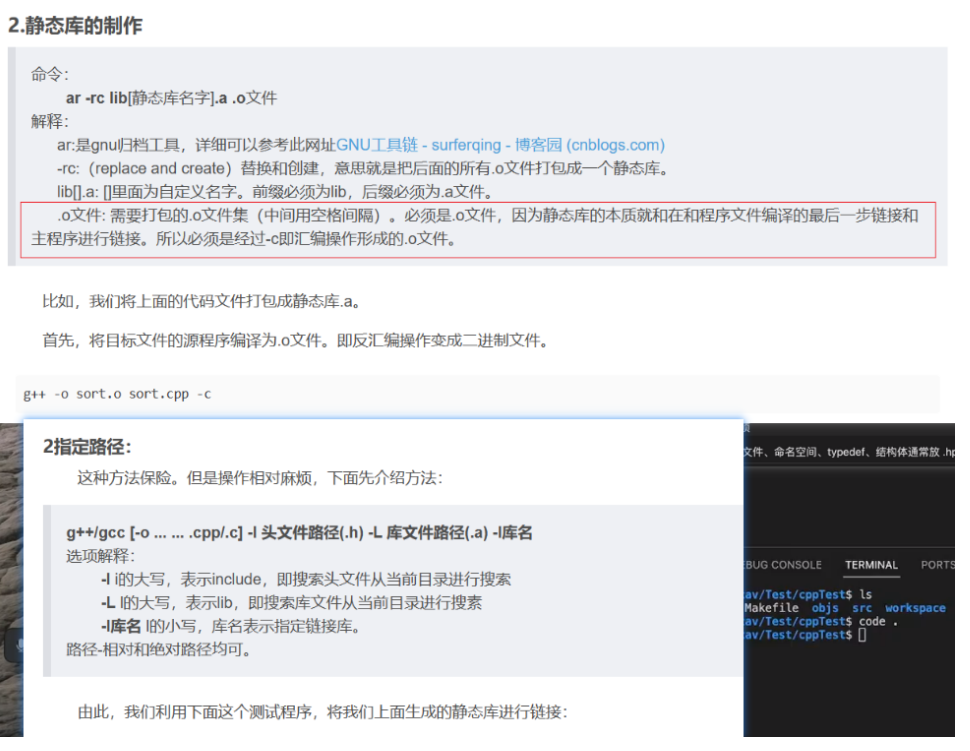
C++多文件类的声明与实现
...
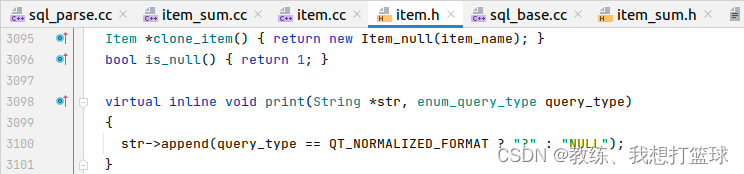
16 “count(*)“ 和 “count(1)“ 和 “count(field1)“ 的差异
前言 经常会有面试题看到这样的问题 “ select count(*) ”, “ select count(field1) ”, “ select count(1) ” 的效率差异啥的 然后 我们这里 就来探索一下 这个问题 我们这里从比较复杂的 select count(field1) 开始看, 因为 较为复杂的处理过程 会留一下一些关键的调试…...

【云原生进阶之PaaS中间件】第一章Redis-1.4过期策略
1 设置带过期时间的 key # 时间复杂度:O(1),最常用方式 expire key seconds# 字符串独有方式 setex(String key, int seconds, String value)除了string独有设置过期时间的方法,其他类型都需依靠expire方法设置时间&a…...
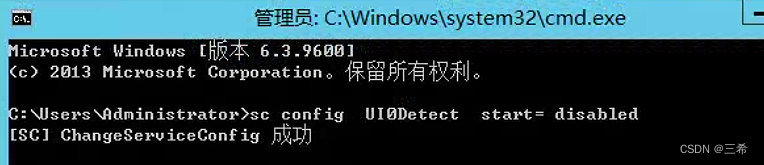
windows弹出交互式服务检测一键取消bat脚本
现象 脚本命令 新建一个bat文件,将下面的脚本拷贝进去,保存,双击即可 禁用服务:重启电脑的时候不会启动 停止服务:立即停止服务,马上生效的 sc config UI0Detect start disabled net stop UI0Detect...
接口使用的最佳时机
1. 引言 接口在系统设计中,以及代码重构优化中,是一个不可或缺的工具,能够帮助我们写出可扩展,可维护性更强的程序。 在本文,我们将介绍什么是接口,在此基础上,通过一个例子来介绍接口的优点。…...

freertos之任务运行时间统计实验
这里写目录标题 任务时间统计函数时间统计API函数使用流程实验 任务时间统计函数 void vTaskGetRunTimeStats(char * pcWriteBuffer); 时间统计API函数使用流程 实验 1.首先现在FreeRTOSConfig.h文件里将configGENERATE_RUN_TIME_STATS 和configUSE_STATS_FORMATTING_FUNCTIO…...

Js中一些数组常用API总结
前言 Js中数组是一个重要的数据结构,它相比于字符串有更多的方法,在一些算法题中我们经常需要将字符串转化为数组,使用数组里面的API进行操作。本篇文章总结了一些数组中常用的API,我们把它们分成两类,一类是会改变原…...
LlamaIndex:将个人数据添加到LLM
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 LlamaIndex是基于大型语言模型(LLM)的应用程序的数据框架。像 GPT-4 这样的 LLM 是在大量公共数据集上预先训练的,允许开箱即用的令人难以置信的自然语言处理能力。但是,…...

Electron鸿蒙PC上的系统托盘,坑比我想象的多三倍
Electron鸿蒙PC上的系统托盘,坑比我想象的多三倍 上个月我在做一个企业内部工具,需要在鸿蒙PC上实现系统托盘常驻和原生通知推送。本来以为这是个小功能,两三个小时搞定,结果愣是折腾了两天半。把过程记录下来,希望后…...
Transformer与NLP资源全指南:从原理到工程实践的高效学习路径
1. 项目概述:为什么我们需要一个Transformer与NLP的“Awesome”清单?如果你在过去几年里深度参与过自然语言处理(NLP)领域的工作或学习,那么“Transformer”这个词对你来说,可能已经从一种新颖的架构&#…...
图解ConvTranspose1d:从计算图到代码实现的逆向思维
1. 从Conv1d到ConvTranspose1d的思维转换 第一次接触ConvTranspose1d时,我和大多数人一样困惑:为什么要把好好的卷积操作反过来计算?直到在语音合成项目中被迫深入使用后,才明白这种"逆向思维"的价值。想象你正在玩拼图…...

从源码到应用:VTK编译与配置全流程实战
1. VTK简介与环境准备 VTK(Visualization Toolkit)是一款强大的开源三维可视化库,广泛应用于医学影像、科学计算、工程仿真等领域。我第一次接触VTK是在开发一个医学图像处理项目时,当时被它丰富的渲染功能和跨平台特性所吸引。对…...

普通人 0 基础能转网安吗?转行路径全面拆解,告诉你到底值不值得
前言 最近在后台有看到很多朋友问我关于网络安全转行的问题,今天做了一些总结,其中最多的是,觉得目前的工作活多钱少、不稳定、一眼望到头,还有一些就是目前工作稳定但是缺乏上升空间的。总的来说,大家主要的问题是&a…...

TimerBlox:基于电流基准的硬件定时新方案,替代555与MCU
1. 项目概述:重新认识定时电路的设计范式在嵌入式系统、电源管理、电机控制乃至各类信号发生器的设计中,定时功能几乎无处不在。无论是生成一个精确的PWM波去调节LED亮度,还是产生一个可调的时钟信号驱动VCO,亦或是需要一个精准的…...

PCIe 6.0 Flit Mode 实战解析:从TLP到Flit,你的数据包到底经历了什么?
PCIe 6.0 Flit Mode 深度解析:数据包的奇幻漂流之旅 当一颗来自CPU的事务请求被封装成TLP(Transaction Layer Packet)时,它即将开始一段穿越PCIe 6.0协议栈的奇妙旅程。这段旅程不再是传统PCIe版本中的"自由行"…...

LaTeX-PPT:3分钟掌握PowerPoint专业公式编辑的神器
LaTeX-PPT:3分钟掌握PowerPoint专业公式编辑的神器 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint中编辑复杂数学公式而头疼吗?LaTeX-PPT这款开源插件彻底改变了游…...

SQL 中 OR 与 UNION ALL选择指南
一句话总结普通小表、无索引场景:用 OR 更简单、代码更短大表、有索引场景:用 UNION ALL 性能远优于 OR需要去重:必须用 UNION(性能比 UNION ALL 差)核心区别只扫描一次表 / 索引数据库需要同时判断两个条件致命问题&a…...
)
超越‘点亮出图’:深入Sensor AE增益配置的三种模式与实战验证(以SC230AI/OV08A10/IMX335为例)
超越“点亮出图”:深入Sensor AE增益配置的三种模式与实战验证 在嵌入式Camera开发领域,成功点亮Sensor并输出图像仅仅是万里长征的第一步。真正的挑战往往出现在图像质量调优阶段,尤其是自动曝光(AE)与增益配置这一专…...