【Spring Cloud系列】 雪花算法原理及实现
【Spring Cloud系列】 雪花算法原理及实现
文章目录
- 【Spring Cloud系列】 雪花算法原理及实现
- 一、概述
- 二、生成ID规则部分硬性要求
- 三、ID号生成系统可用性要求
- 四、解决分布式ID通用方案
- 4.1 UUID
- 4.2 数据库自增主键
- 4.3 基于Redis生成全局id策略
- 五、SnowFlake(雪花算法)
- 5.1 SnowFlake特点
- 5.2 SnowFlake结构
- 5.3 雪花算法原理
- 5.4 算法实现
- 5.4 雪花算法优点
- 5.5 雪花算法缺点:
- 六、总结
一、概述
分布式高并发的环境下,常见的就是12306节日订票,在大量用户同是抢购一个方向的票,毫秒级的时间下可能生成数万个订单,此时为确保生成订单ID的唯一性变得至关重要。此时秒杀环境下,不仅要保障ID唯一性,还得确保ID生成的优先度。
二、生成ID规则部分硬性要求
- 全局唯一:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL的InnoDB引擎中适用的是聚集索引,由于多数RDBMS使用B+Tree的数据结构来存储索引数据,在主键的选择上我们尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,如事务版本号、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的抓取工作就非常容易,直接按照顺序下载指定URL即可;如果是订单号就危险。
- 含有时间戳:生成的ID包含完整的时间戳信息。
三、ID号生成系统可用性要求
- 高可用:发一个获取分布式ID的请求,服务器就是保证99.9999%的情况下给我创建一个唯一分布式ID。
- 低延迟:发一个获取分布式ID的请求,服务器要快,极速。
- 高QPS:如果一次请求10万个分布式ID,服务器要顶住并成功创建10万个分布式ID。
四、解决分布式ID通用方案
4.1 UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为:8-4-4-4-12的36个字符,示例:1E785B2B-111C-752A-997B-3346E7495CE2;UUID性能非常高,不依赖网络,本地生成。
UUID缺点:
-
无序,无法预测它的生成顺序,不能生成递增有序的数字。在MySql官方推荐主键约短越好,UUID是一个32位的字符串,所以不推荐使用。
-
索引,B+Tree索引的分裂
分布式Id是主键,主键是聚簇索引。Mysql的索引是B+Tree来实现的,每次新的UUID数据的插入,为了新的UUID数据的插入,为了查询的优化,都会对索引底部的B+Tree进行修改;因为UUID数据是无序的,所以每一次UUID数据的插入都会对主键的聚簇索引做很大的修改,在做数据Insert时,会插入主键是无序的,会导致一些中间节点的产生分裂,会导致大量不饱和的节点。这样大大降低了数据库插入的性能。
4.2 数据库自增主键
单机
在分布式里面,数据库的自增ID机制的主要原理是:数据库自增ID和MySql数据库的replace into实现的。
Replace into的含义是插入一条纪录,如果表中唯一索引的值遇到冲突,则替换老数据。
在单体应用的时候,自增长ID使用,但是在集群分布式应用中单体应用就不适合。
- 系统水平扩展比较困难,比如定义好了增长步长和机器台数之后,在大量添加服务器时,需要重新设置初始值,这样可操作性差,所以系统水平扩展方案复杂度高难以实现。
- 数据库压力大,每次获取ID都需要读写一次数据库,非常影响性能,不符合分布式ID里面的延迟低和要高QPS的规则(在高并发下,如果都去数据库里面获取Id,非常影响性能的。)
4.3 基于Redis生成全局id策略
在Redis集群情况下,同样和MySql一样需要设置不同的增长步长,同时key一定要设置有效期。可以使用Redis集群来获取更高的吞吐量。
五、SnowFlake(雪花算法)
而Twitter的SnowFlake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra(由Facebook开发一套开源分布式NoSQL数据库系统) 因为Cassandra没有顺序ID生成机制,所以开发了这样一套全局唯一ID生成服务。SnowFlake每秒能产生26万个自增可排序的ID。
5.1 SnowFlake特点
- Twitter的SnowFlake生成ID能够按照时间有序生成。
- SnowFlake算法生成Id的结果是一个64bit大小的整数,为一个Long型(转换成字符串后长度最多19)。
- 分布式系统内不会产生ID碰撞(由datacenter和workerid作为区分)并且效率较高。
5.2 SnowFlake结构

5.3 雪花算法原理
雪花算法的原理就是生成一个的64位比特位的long类型的唯一id
- 最高1位固定值0,因为生成的id是正整数,如果是1就是负值。
- 紧接着是41位存储毫秒级时间戳,2^41/(1000 * 60 * 24 * 365) = 69 ,大概可以使用69年。
- 接下来10位存储机器码,包括5位DataCenterId和5位WorkerId,最多可以部署2^10=1024台机器。
- 最后12位存储序列号,同一毫秒时间戳时,通过这个递增的序列号来区分,即对于同一台机器而言,同一毫秒级时间戳下,可以生成2^12=4096个不重复id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一id的系统,请求雪花算法服务获取id即可。
对于每一个雪花算法服务,需要先指定10位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者时其他区别标识的10位比特位的整数都行。
5.4 算法实现
package com.goyeer;
import java.util.Date;/*** @ClassName: SnowFlakeUtil* @Author: goyeer* @Date: 2023/09/09 19:34* @Description:*/
public class SnowFlakeUtil {private static SnowFlakeUtil snowFlakeUtil;static {snowFlakeUtil = new SnowFlakeUtil();}// 初始时间戳(纪年),可用雪花算法服务上线时间戳的值//private static final long INIT_EPOCH = 1694263918335L;// 时间位取&private static final long TIME_BIT = 0b1111111111111111111111111111111111111111110000000000000000000000L;// 记录最后使用的毫秒时间戳,主要用于判断是否同一毫秒,以及用于服务器时钟回拨判断private long lastTimeMillis = -1L;// dataCenterId占用的位数private static final long DATA_CENTER_ID_BITS = 5L;// dataCenterId占用5个比特位,最大值31// 0000000000000000000000000000000000000000000000000000000000011111private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);// dataCenterIdprivate long dataCenterId;// workId占用的位数private static final long WORKER_ID_BITS = 5L;// workId占用5个比特位,最大值31// 0000000000000000000000000000000000000000000000000000000000011111private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);// workIdprivate long workerId;// 最后12位,代表每毫秒内可产生最大序列号,即 2^12 - 1 = 4095private static final long SEQUENCE_BITS = 12L;// 掩码(最低12位为1,高位都为0),主要用于与自增后的序列号进行位与,如果值为0,则代表自增后的序列号超过了4095// 0000000000000000000000000000000000000000000000000000111111111111private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);// 同一毫秒内的最新序号,最大值可为 2^12 - 1 = 4095private long sequence;// workId位需要左移的位数 12private static final long WORK_ID_SHIFT = SEQUENCE_BITS;// dataCenterId位需要左移的位数 12+5private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;// 时间戳需要左移的位数 12+5+5private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;/*** 无参构造*/public SnowFlakeUtil() {this(1, 1);}/*** 有参构造* @param dataCenterId* @param workerId*/public SnowFlakeUtil(long dataCenterId, long workerId) {// 检查dataCenterId的合法值if (dataCenterId < 0 || dataCenterId > MAX_DATA_CENTER_ID) {throw new IllegalArgumentException(String.format("dataCenterId 值必须大于 0 并且小于 %d", MAX_DATA_CENTER_ID));}// 检查workId的合法值if (workerId < 0 || workerId > MAX_WORKER_ID) {throw new IllegalArgumentException(String.format("workId 值必须大于 0 并且小于 %d", MAX_WORKER_ID));}this.workerId = workerId;this.dataCenterId = dataCenterId;}/*** 获取唯一ID* @return*/public static Long getSnowFlakeId() {return snowFlakeUtil.nextId();}/*** 通过雪花算法生成下一个id,注意这里使用synchronized同步* @return 唯一id*/public synchronized long nextId() {long currentTimeMillis = System.currentTimeMillis();System.out.println(currentTimeMillis);// 当前时间小于上一次生成id使用的时间,可能出现服务器时钟回拨问题if (currentTimeMillis < lastTimeMillis) {throw new RuntimeException(String.format("可能出现服务器时钟回拨问题,请检查服务器时间。当前服务器时间戳:%d,上一次使用时间戳:%d", currentTimeMillis,lastTimeMillis));}if (currentTimeMillis == lastTimeMillis) {// 还是在同一毫秒内,则将序列号递增1,序列号最大值为4095// 序列号的最大值是4095,使用掩码(最低12位为1,高位都为0)进行位与运行后如果值为0,则自增后的序列号超过了4095// 那么就使用新的时间戳sequence = (sequence + 1) & SEQUENCE_MASK;if (sequence == 0) {currentTimeMillis = getNextMillis(lastTimeMillis);}} else { // 不在同一毫秒内,则序列号重新从0开始,序列号最大值为4095sequence = 0;}// 记录最后一次使用的毫秒时间戳lastTimeMillis = currentTimeMillis;// 核心算法,将不同部分的数值移动到指定的位置,然后进行或运行// <<:左移运算符, 1 << 2 即将二进制的 1 扩大 2^2 倍// |:位或运算符, 是把某两个数中, 只要其中一个的某一位为1, 则结果的该位就为1// 优先级:<< > |return// 时间戳部分((currentTimeMillis - INIT_EPOCH) << TIMESTAMP_SHIFT)// 数据中心部分| (dataCenterId << DATA_CENTER_ID_SHIFT)// 机器表示部分| (workerId << WORK_ID_SHIFT)// 序列号部分| sequence;}/*** 获取指定时间戳的接下来的时间戳,也可以说是下一毫秒* @param lastTimeMillis 指定毫秒时间戳* @return 时间戳*/private long getNextMillis(long lastTimeMillis) {long currentTimeMillis = System.currentTimeMillis();while (currentTimeMillis <= lastTimeMillis) {currentTimeMillis = System.currentTimeMillis();}return currentTimeMillis;}/*** 获取随机字符串,length=13* @return*/public static String getRandomStr() {return Long.toString(getSnowFlakeId());}/*** 从ID中获取时间* @param id 由此类生成的ID* @return*/public static Date getTimeBySnowFlakeId(long id) {return new Date(((TIME_BIT & id) >> 22) + INIT_EPOCH);}public static void main(String[] args) {SnowFlakeUtil snowFlakeUtil = new SnowFlakeUtil();long id = snowFlakeUtil.nextId();System.out.println(id);Date date = SnowFlakeUtil.getTimeBySnowFlakeId(id);System.out.println(date);long time = date.getTime();System.out.println(time);System.out.println(getRandomStr());}}
5.4 雪花算法优点
- 高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
- 基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
- 不依赖第三方库或者中间件。
- 算法简单,在内存中进行,效率高。
5.5 雪花算法缺点:
- 依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
六、总结
其实雪花算法每一部分占用的比特位数量并不是固定死的。例如你的业务可能达不到 69 年之久,那么可用减少时间戳占用的位数,雪花算法服务需要部署的节点超过1024 台,那么可将减少的位数补充给机器码用。
注意,雪花算法中 41 位比特位不是直接用来存储当前服务器毫秒时间戳的,而是需要当前服务器时间戳减去某一个初始时间戳值,一般可以使用服务上线时间作为初始时间戳值。
对于机器码,可根据自身情况做调整,例如机房号,服务器号,业务号,机器 IP 等都是可使用的。对于部署的不同雪花算法服务中,最后计算出来的机器码能区分开来即可。
相关文章:
【Spring Cloud系列】 雪花算法原理及实现
【Spring Cloud系列】 雪花算法原理及实现 文章目录 【Spring Cloud系列】 雪花算法原理及实现一、概述二、生成ID规则部分硬性要求三、ID号生成系统可用性要求四、解决分布式ID通用方案4.1 UUID4.2 数据库自增主键4.3 基于Redis生成全局id策略 五、SnowFlake(雪花算…...

Postgresql 阿里云部署排雷
启动服务bug: 根据你的输出,可以看到 PostgreSQL 服务启动失败,并且显示以下错误消息: pg_ctl: cannot be run as root Please log in (using, e.g., "su") as the (unprivileged) user that will own the server proc…...
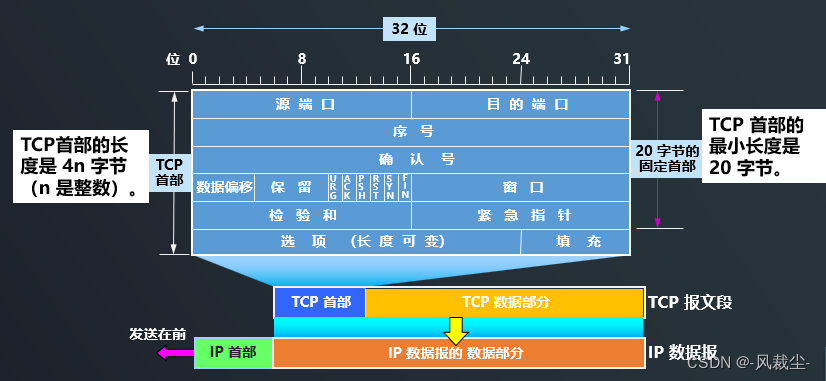
l8-d10 TCP协议是如何实现可靠传输的
一、TCP主要特点 TCP 是面向连接的运输层协议,在无连接的、不可靠的 IP 网络服务基础之上提供可靠交付的服务。为此,在 IP 的数据报服务基础之上,增加了保证可靠性的一系列措施。 TCP主要特点 1.TCP 是面向连接的运输层协议。 每一条 TCP 连…...

9月9日扒面经
堆和栈的区别? 分配方式:堆内存是由程序员手动分配和释放的,而栈内存是由编译器自动分配和释放的。内存管理:堆内存需要手动管理内存的分配和释放,程序员需要显式地调用malloc()或new来分配内存,并使用fre…...
项目实战:ES的增加数据和查询数据
文章目录 背景在ES中增加数据新建索引删除索引 在ES中查询数据查询数据总数量 项目具体使用(实战)引入依赖方式一:使用配置类连接对应的es服务器创建配置类编写业务逻辑----根据关键字查询相关的聊天内容在ES中插入数据 总结提升 背景 最近需…...
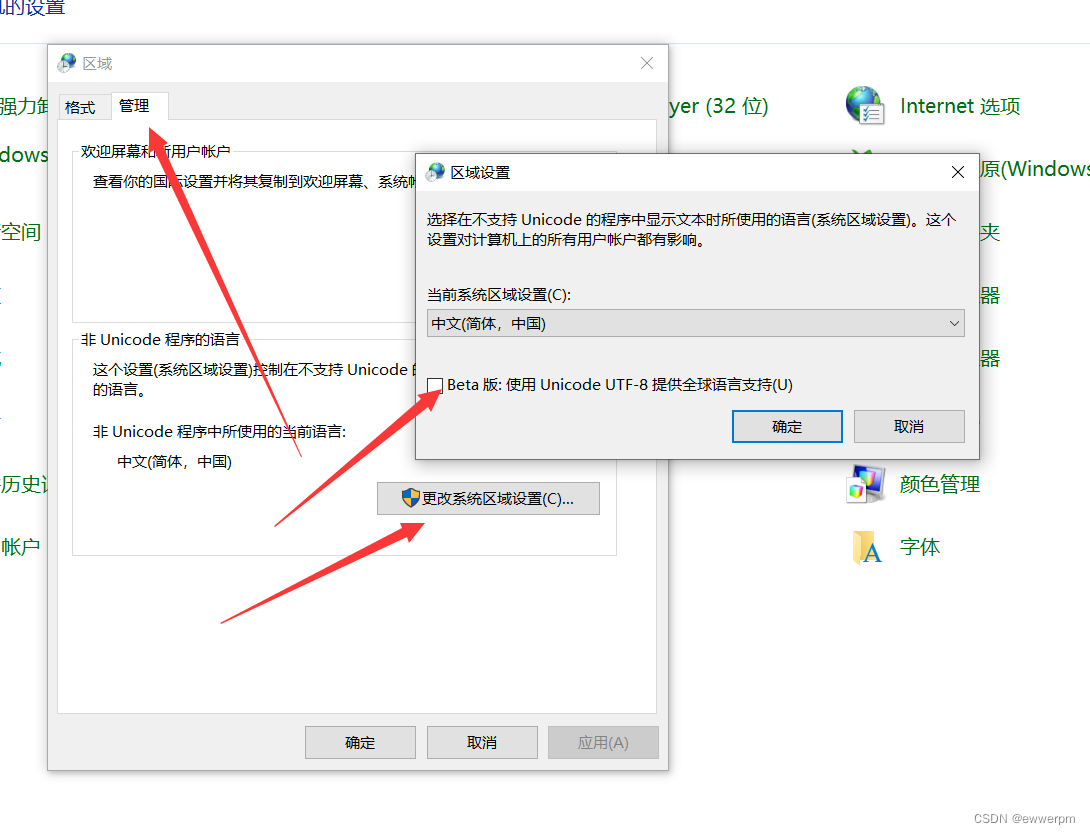
vs code调试rust乱码问题解决方案
在terminal中 用chcp 65001 修改一下字符集,就行了。有的博主推荐 修改 区域中的设置,这会引来很大的问题。千万不要修改如下设置:...
大数据课程K22——Spark的SparkSQL的API调用
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Spark的通过api使用SparkSQL; 一、通过api使用SparkSQL 1. 实现步骤 1. 打开scala IDE开发环境,创建一个scala工程。 2. 导入spark相关依赖jar包。 3. 创建包路径以object类。 4.…...

数据结构学习系列之顺序表的两种删除方式
方式1:在顺序表的末端删除所存储的数据元素,代码如下:示例代码: int delete_seq_list_1(list_t *seq_list){if(NULL seq_list){printf("入参为NULL\n");return -1;}if(0 seq_list->count){printf("顺序表为空…...

机器学习笔记之最优化理论与方法(七)无约束优化问题——常用求解方法(上)
机器学习笔记之最优化理论与方法——基于无约束优化问题的常用求解方法[上] 引言总体介绍回顾:线搜索下降算法收敛速度的衡量方式线性收敛范围高阶收敛范围 二次终止性朴素算法:坐标轴交替下降法最速下降法(梯度下降法)梯度下降法的特点 针对最速下降法缺…...
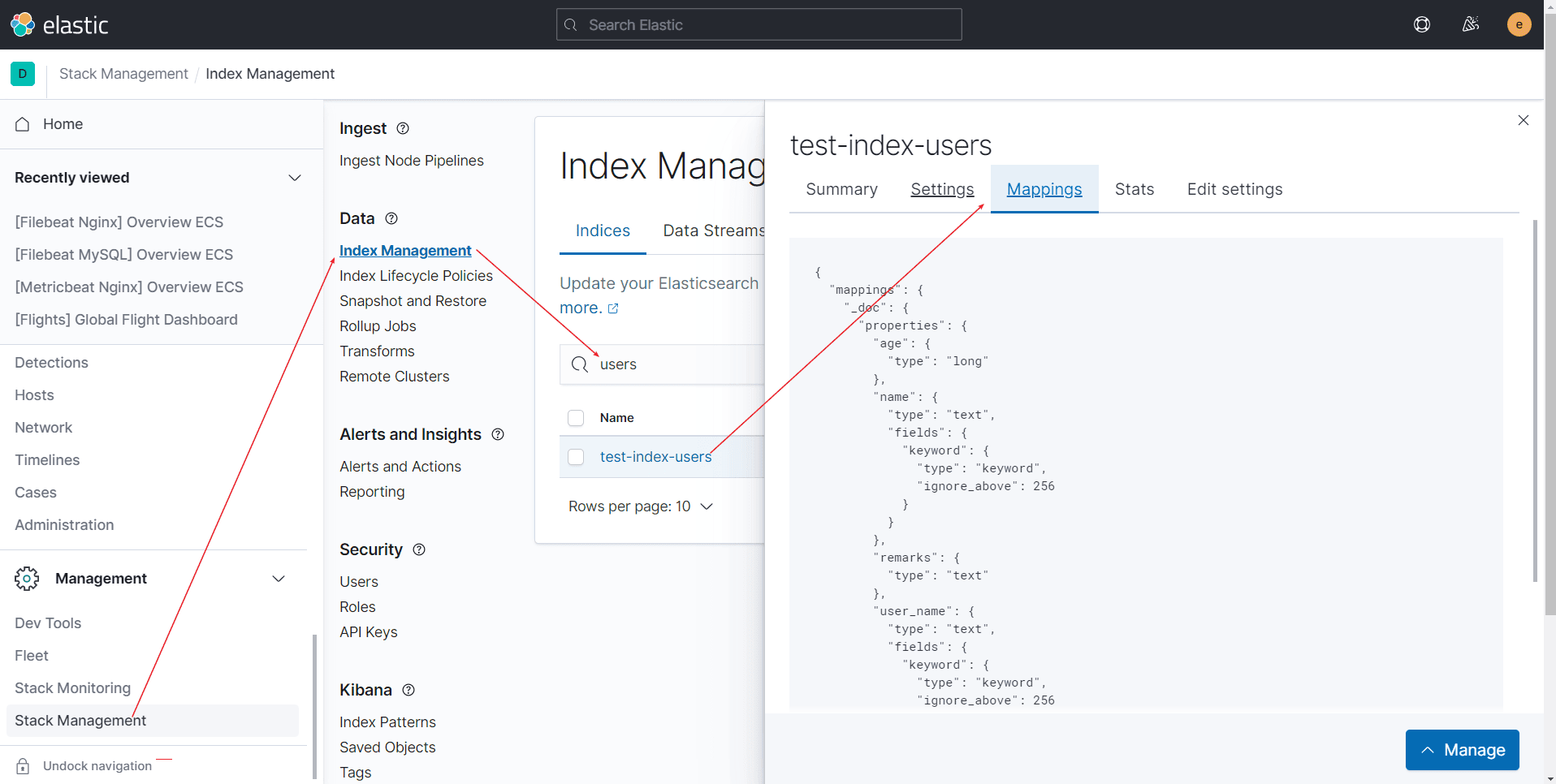
ES-索引管理
前言 数据类型 搜索引擎是对数据的检索,所以我们先从生活中的数据说起。我们生活中的数据总体分为两种: 结构化数据非结构化数据 结构化数据: 也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数…...

linux中常用shell脚本整理
linux常见shell脚本整理 备份日志 #!/bin/bash # 每日创建新的备份日志-根据日期备份 tar -czf log-date %Y%m%d.tar.gz /var/log # 通过crontab 每日定时启动 00 03 * * 5 /root/logbak.sh 监控内存和磁盘容量,小于给定值时报警 #!/bin/bash # 实…...

介绍PHP
PHP是一种流行的服务器端编程语言,用于开发Web应用程序。它是一种开源的编程语言,具有易学易用的语法和强大的功能。PHP支持在服务器上运行的动态网页和Web应用程序的快速开发。 PHP可以与HTML标记语言结合使用,从而能够生成动态的Web页面&a…...
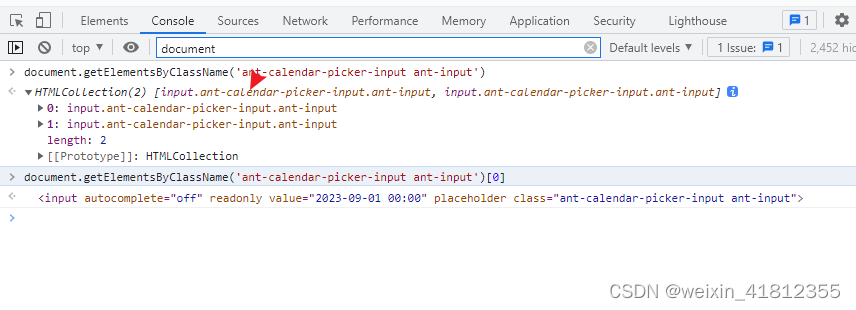
selenium+find_elements用法
1、假如我们遇到多个标签的class一样,比如像下面这样的 我们可以采用js语法去定位,比如: document.getElementsByClassName("ant-calendar-picker-input ant-input")[0]...
1DM+下载器_11.2.1魔改增强版下载
1DM「原:IDM」下载器是一款安卓端的下载工具,多语言解锁版直安装版本,号称是目前 Android 平台最快、最先进的下载管理器应用「支持通过Torrent下载」,而这个版本是改线程的最新idm版本,可用来下载视频、音乐、电影、T…...
vue3:3、项目目录和关键文件
关于vsvode的更改 <!-- 加上setup允许在script中直接编写组合式api --> <script setup> // 组件引入后直接用 import HelloWorld from ./components/HelloWorld.vue import TheWelcome from ./components/TheWelcome.vue</script><!-- 1、js放在最上面&am…...
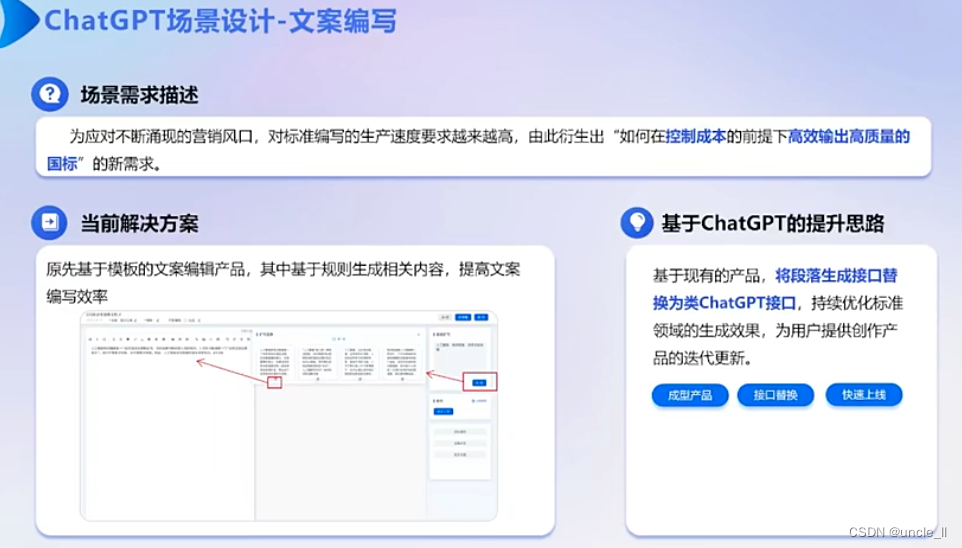
ChatGPT实战与私有化大模型落地
文章目录 大模型现状baseline底座选择数据构造迁移方法评价思考 领域大模型训练技巧Tokenizer分布式深度学习数据并行管道并行向量并行分布式框架——Megatron-LM分布式深度学习框架——Colossal-AI分布式深度学习框架——DeepSpeedP-tuning 微调 资源消耗模型推理加速模型推理…...
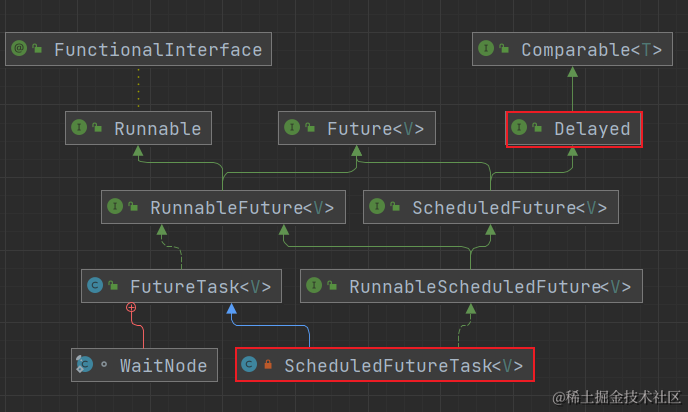
10分钟从实现和使用场景聊聊并发包下的阻塞队列
上篇文章12分钟从Executor自顶向下彻底搞懂线程池中我们聊到线程池,而线程池中包含阻塞队列 这篇文章我们主要聊聊并发包下的阻塞队列 阻塞队列 什么是队列? 队列的实现可以是数组、也可以是链表,可以实现先进先出的顺序队列,…...

Python入门学习13(面向对象)
一、类的定义和使用 类的使用语法: 创建类对象的语法: class Student:name None #学生的名字age None #学生的年龄def say_hi(self):print(f"Hi大家好,我是{self.name}")stu Student() stu.name &q…...

哈工大计算机网络课程网络安全基本原理之:身份认证
哈工大计算机网络课程网络安全基本原理之:身份认证 在日常生活中,在很多场景下我们都需要对当前身份做认证,比如使用密码、人脸识别、指纹识别等,这些都是身份认证的常用方式。本节介绍的身份认证,是在计算机网络安全…...

海外代购系统/代购网站怎么搭建
搭建海外代购系统/代购网站的详细步骤涉及到的内容非常多,本文将分为以下几个部分进行详细介绍:前端开发、后端管理系统的开发、数据库设计和代购流程的设计与实现。 一、前端开发 前端开发是整个代购网站的门面,它直接面向用户,…...

LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换
LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为学术论文中复杂的数…...

【目录】运筹优化
运筹学篇章已全部更新完毕......运筹学开篇搜索理论基础线性规划之单纯形法线性规划的对偶理论线性规划之内点法单纯形法的补充与代码实现最短路与动态规划(一)最短路与动态规划(二)最短路与动态规划(三)网…...
)
从IMU到GPS:手把手教你用ESKF实现机器人定位(附代码避坑指南)
从IMU到GPS:手把手教你用ESKF实现机器人定位(附代码避坑指南) 在机器人定位领域,误差状态卡尔曼滤波(Error-State Kalman Filter, ESKF)正逐渐成为处理IMU和GPS数据融合的主流方法。本文将带您深入理解ESK…...

[具身智能-694]:万物皆智能,万物皆 ROS2:未来所有带感知、能运动、可交互的硬件终端,都能用 ROS2 做底座,智能普惠全域设备。万物接入 ROS2,就是接入标准化、开源化、互联化的智能时代。
一、为什么说「万物皆智能」从传统机电设备 → 感知 决策 执行一体化:普通家电、工业设备、移动载体、穿戴设备、楼宇设施,都在加传感器、算力、通信、自主决策,不再是被动受控,而是具备自主感知、逻辑判断、联动协作的智能属性…...

智能体集成德国铁路实时信息:无需API的Node.js工具箱openclaw-bahn详解
1. 项目概述:一个为智能体打造的德国铁路工具箱如果你经常在德国乘坐火车,或者像我一样,需要为一些自动化流程(比如智能体)集成实时交通信息,那么你肯定对德国铁路(Deutsche Bahn, DB࿰…...

开源协作平台Polar:一体化设计如何重塑开发者工作流
1. 项目概述:一个面向开发者的开源协作平台最近在和一些独立开发者朋友聊天时,大家普遍提到一个痛点:当你想启动一个开源项目,或者和几个朋友一起搞点小东西时,整个协作流程其实挺割裂的。代码托管在GitHub或GitLab&am…...

3分钟掌握Mem Reduct:Windows系统内存清理的终极解决方案
3分钟掌握Mem Reduct:Windows系统内存清理的终极解决方案 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct …...

OpenClaw近一月版本更替讲解
如果你最近没追 OpenClaw 的更新,最容易产生一种错觉:它是不是又只是多接了几个模型、多加了几个花哨功能? 我看完最近一个月的变化后,感觉不是这样。 OpenClaw 这一个月真正值得关注的地方,不是“它更炫了”ÿ…...

Redis_7_Streams与高可用集群实战
Redis 7.0 Streams与高可用集群部署实战 从消息队列到分布式架构,全面掌握Redis核心能力 前言 Redis不只是一个缓存数据库。Redis 5.0引入的Streams让它具备了消息队列的能力,Redis 7.0进一步增强了Streams的稳定性和性能。很多团队在用Kafka/RabbitMQ处理消息队列时,其实R…...

从零到一:PyQt-Fluent-Widgets导航组件实战指南
从零到一:PyQt-Fluent-Widgets导航组件实战指南 【免费下载链接】PyQt-Fluent-Widgets A fluent design widgets library based on C Qt/PyQt/PySide. Make Qt Great Again. 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Fluent-Widgets 你是否曾经为P…...