【RapidAI】P1 中文文本切割程序
中文文本切割程序
- 基本信息
- 代码解析
- 相关包
- 获取 yaml 关键文件
- 类的构造函数
- 切分语句部分
- 特殊处理 PDF
- 重点切分
- 去除数组中空字符串
- 再度切分后长度
- 附录
- 附录一:完整代码
- 附录二:可继续思考问题
基本信息
文件名: chinese_text_splitter.py
文件地址: E:\Code\Knowledge-QA-LLM\Knowledge-QA-LLM-main\knowledge_qa_llm\text_splitter\chinese_text_splitter.py
Author: @SWHL、@omahs
CSDN Author: me(脚踏实地的大梦想家)
Original Code: url
代码解析
相关包
import re
from pathlib import Path
from typing import List
re 正则表达式。在文本处理中,正则表达式可用于验证、搜索、提取和替换文本中的特定模式。
re.sub(pattern, replacement, string, count=0, flags=0)
# pattern:要被替换的字符串。
# replacement:要替换的字符串。
# string:被操作的字符串的名称。
# count(可选):指定最大替换次数,默认为0,表示替换所有匹配项。
# flags(可选):可以对字符串加以限制,比如忽略大小写等。import retext = "Hello, my name is Alice. Nice to meet you, Alice!"
new_text = re.sub(r'Alice', 'Bob', text)>>> Hello, my name is Bob. Nice to meet you, Bob!
Path 负责路径,通过使用 Path 类,可以创建、连接、分解和操作文件系统路径,而无需直接使用字符串拼接或分割。
# 当前脚本文件的路径
Path(__file__)
# resolve()方法会返回规范化的绝对路径,解析出符号链接和相对路径,使其变为绝对路径
Path(__file__).resolve()
# root_dir为当前脚本的绝对路径下的上级目录的上级目录
root_dir = Path(__file__).resolve().parent.parent
List 用于表示一个列表类型。
# 表明函数的参数或返回值应该是一个字符串类型的列表
List[str]
获取 yaml 关键文件
root_dir = Path(__file__).resolve().parent.parent
config_path = root_dir / "config.yaml"
config = read_yaml(config_path)
上述代码获取了重要描述文件 config.yaml 文件的路径地址信息,然后通过 read_yaml() 函数读取到其中信息。关于 read_yaml() 函数的代码提取如下:
# 首先 read_yaml() 函数在 ..util.util.py 文件中
from ..utils.utils import read_yaml# 提取出 read_yaml() 函数如下:
def read_yaml(yaml_path: Union[str, Path]):with open(str(yaml_path), "rb") as f:data = yaml.load(f, Loader=yaml.Loader)return data
上述代码讲打开 str 字符串类型的地址信息,或者 Path 对象的地址信息;通过代码读取到该地址文件,以二进制的形式返回读取到的结果。
类的构造函数
def __init__(self,pdf: bool = False,sentence_size: int = config.get("SENTENCE_SIZE"),
):self.pdf = pdfself.sentence_size = sentence_size
上述 __init__ 为类 ChineseTextSplitter 的构造函数;
pdf: bool = False 这是一个布尔型参数,默认为False。它用于表示文本是否来自PDF文档。如果设置为True,则表示文本来自PDF,否则为其他来源。
sentence_size: int = config.get("SENTENCE_SIZE"): 从 yaml 文件中获取 SENTENCE_SIZE 的值,作为 sentence_size 的默认值。
切分语句部分
特殊处理 PDF
切分语句 split_text 是定义在 ChineseTextSplitter 类中的一个成员方法,用于将输入的文本分割成句子的列表。
切分语句部分过长,将首先切分开介绍,附录附完整的切分函数代码;
def split_text(self, text: str) -> List[str]: ##此处需要进一步优化逻辑if self.pdf:text = re.sub(r"\n{3,}", r"\n", text)text = re.sub("\s", " ", text)text = re.sub("\n\n", "", text)
text 为待分割的文本,字符串格式;
-> List[str] 是方法的返回类型标注,表示该方法返回一个字符串列表;
re.sub(r"\n{3,}", "\n", text) 将连续三个以上的换行符替换称为单个换行符;
re.sub("\s", " ", text) 将单个/连续的空白字符串替换为单个空格;
text = text.replace("\n\n", "") 将连续两个换行符移除;
重点切分
text = re.sub(r"([;;.!?。!?\?])([^”’])", r"\1\n\2", text)
text = re.sub(r'(\.{6})([^"’”」』])', r"\1\n\2", text) # \.{6} 代表着连续6个英文点,作为英文中省略号
text = re.sub(r'(\…{2})([^"’”」』])', r"\1\n\2", text) # 中文省略号……
text = re.sub(r'([;;!?。!?\?]["’”」』]{0,2})([^;;!?,。!?\?])', r"\1\n\2", text) # 其目标与第一个相反,想要筛选出以及引号为结尾的字段。
text = text.rstrip() # 段尾如果有多余的\n就去掉它
上述代码是本文,本函数的重点部分,总结来说,就是运用 re.sub() 函数将句子按照标点的方式分割;详细阐述如下:
re.sub(r"([;;.!?。!?\?])([^”’])", r"\1\n\2", text) 重点部分拆分:
-
第一个捕获组:
([;;.!?。!?\?])
该部分是一个字符类,包含中英文分号,中英文句号,中英文感叹号以及中英文问号。该捕获组的作用为用来匹配句子分隔符。 -
第二个捕获组:
([^”’])
该部分是一个否定字符类,表示匹配除了有双引号与有单引号之外的任何字符。
将第一个捕获组与第二个捕获组的结合,其意义在于筛选出:以第一个捕获组中字符类为结尾,且没有引号在其后的句子。(一定要注意其后,其前是另一种写法)
e . g . e.g. e.g. 案例见替换模式后下述; -
替换模式:
\1\n\2
如果捕获成功,即满足非引号作为结尾的句子,以字符类结尾,则使用替换模式。将句子通过换行分隔开。切分前的句子为\1,加入换行符\n,以及切分后的句子\2
e . g . e.g. e.g.
import retext = "你好吗?我很好!你想吃什么?“苹果。”她说。"
text = re.sub(r"([;;.!?。!?\?])([^”’])", r"\1\n\2", text)
print(text)# 结果如下:
>>>你好吗?
我很好!
你想吃什么?
“苹果。”她说。
去除数组中空字符串
ls = [i for i in text.split("\n") if i]
# 将不为空的字符串保留在列表 ls 中。
若当前空字符串满足单句最大长度要求,则视为完成中文句子切分,返回 ls 数组。
再度切分后长度
在去除空元素后,通过调取 yaml 关键信息文件中的 SENTENCE_SIZE 属性信息,获取规定最长的单句文本长度。再根据长度进行判断,若超出规定范围,则需二次切分。
首先切分
切分除 。” 结尾的语句(逗号句号搭配引号)
for ele in ls:if len(ele) > self.sentence_size:ele1 = re.sub(r'([,,.]["’”」』]{0,2})([^,,.])', r"\1\n\2", ele)ele1_ls = ele1.split("\n")
其次切分
切分一个或多个连续的换行符 或 两个或多个连续的空格(后面可能跟随0到2个特定字符)后面紧跟一个非空白字符。然后在这两部分之间插入一个换行符。
for ele_ele1 in ele1_ls:if len(ele_ele1) > self.sentence_size:ele_ele2 = re.sub(r'([\n]{1,}| {2,}["’”」』]{0,2})([^\s])', r"\1\n\2", ele_ele1) # 切分换行以及空格ele2_ls = ele_ele2.split("\n")
继续切分
切分查找一个0到2个特定字符后面跟着的空格,然后紧随一个非空格字符。在这两部分之间插入一个换行符。
然后将会找到 ele2_ls 列表中的元素 ele_ele2,然后用 ele_ele3 字符串中的多个行替换它。
for ele_ele2 in ele2_ls:if len(ele_ele2) > self.sentence_size:ele_ele3 = re.sub('( ["’”」』]{0,2})([^ ])', r"\1\n\2", ele_ele2)ele2_id = ele2_ls.index(ele_ele2)ele2_ls = (ele2_ls[:ele2_id] + [i for i in ele_ele3.split("\n") if i] + ele2_ls[ele2_id + 1 :])
替换超长字符
ele_id = ele1_ls.index(ele_ele1)
ele1_ls = (ele1_ls[:ele_id] + [i for i in ele2_ls if i] + ele1_ls[ele_id + 1 :])id = ls.index(ele)
ls = ls[:id] + [i.strip() for i in ele1_ls if i] + ls[id + 1 :]
至此为止,数组 ls 中所有字符全部都符号长度标准。
附录
附录一:完整代码
import re
from pathlib import Path
from typing import List
from ..utils.utils import read_yamlroot_dir = Path(__file__).resolve().parent.parent
config_path = root_dir / "config.yaml"
config = read_yaml(config_path)class ChineseTextSplitter:def __init__(self,pdf: bool = False,sentence_size: int = config.get("SENTENCE_SIZE"),):self.pdf = pdfself.sentence_size = sentence_sizedef split_text(self, text: str) -> List[str]: ## 此处需要进一步优化逻辑if self.pdf:text = re.sub(r"\n{3,}", r"\n", text)text = re.sub("\s", " ", text)text = re.sub("\n\n", "", text)text = re.sub(r"([;;.!?。!?\?])([^”’])", r"\1\n\2", text)text = re.sub(r'(\.{6})([^"’”」』])', r"\1\n\2", text)text = re.sub(r'(\…{2})([^"’”」』])', r"\1\n\2", text)text = re.sub(r'([;;!?。!?\?]["’”」』]{0,2})([^;;!?,。!?\?])', r"\1\n\2", text)text = text.rstrip()ls = [i for i in text.split("\n") if i]for ele in ls:if len(ele) > self.sentence_size:ele1 = re.sub(r'([,,.]["’”」』]{0,2})([^,,.])', r"\1\n\2", ele)ele1_ls = ele1.split("\n")for ele_ele1 in ele1_ls:if len(ele_ele1) > self.sentence_size:ele_ele2 = re.sub(r'([\n]{1,}| {2,}["’”」』]{0,2})([^\s])', r"\1\n\2", ele_ele1)ele2_ls = ele_ele2.split("\n")for ele_ele2 in ele2_ls:if len(ele_ele2) > self.sentence_size:ele_ele3 = re.sub('( ["’”」』]{0,2})([^ ])', r"\1\n\2", ele_ele2)ele2_id = ele2_ls.index(ele_ele2)ele2_ls = (ele2_ls[:ele2_id]+ [i for i in ele_ele3.split("\n") if i]+ ele2_ls[ele2_id + 1 :])ele_id = ele1_ls.index(ele_ele1)ele1_ls = (ele1_ls[:ele_id]+ [i for i in ele2_ls if i]+ ele1_ls[ele_id + 1 :])id = ls.index(ele)ls = ls[:id] + [i.strip() for i in ele1_ls if i] + ls[id + 1 :]return ls
附录二:可继续思考问题
可继续思考的问题:
- 是否可以优化上述代码中对于长度的限制;
- 为什么要对长度进行限制?长度限制可以调整吗?
- 怎样对重复性的ele2,ele1与ele3的限制??
这些问题我们将在本系列博文最后的部分拓展讨论。
2023年9月5日
徐鸿铎 于 西直门
相关文章:

【RapidAI】P1 中文文本切割程序
中文文本切割程序 基本信息代码解析相关包获取 yaml 关键文件类的构造函数切分语句部分特殊处理 PDF重点切分去除数组中空字符串再度切分后长度 附录附录一:完整代码附录二:可继续思考问题 基本信息 文件名: chinese_text_splitter.py 文件地…...

4、QT中的网络编程
一、Linux中的网络编程 1、子网和公网的概念 子网网络:局域网,只能进行内网的通信公网网络:因特网,服务器等可以进行远程的通信 2、网络分层模型 4层模型:应用层、传输层、网络层、物理层 应用层:用户自…...
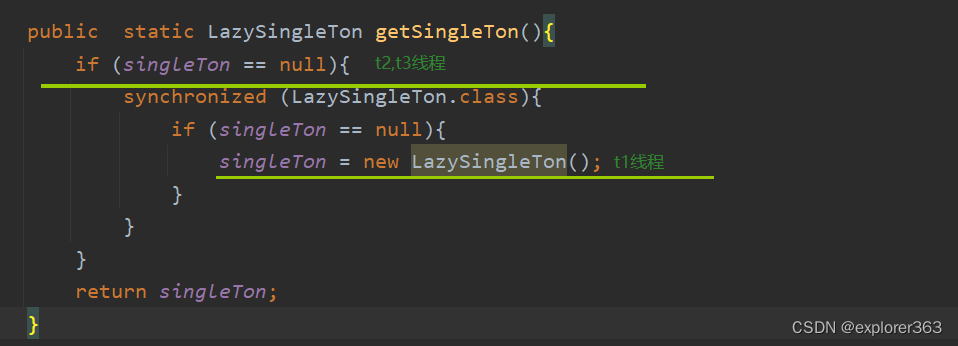
单例模式(饿汉式单例 VS 懒汉式单例)
所谓的单例模式就是保证某个类在程序中只有一个对象 一、如何控制只产生一个对象? 1.构造方法私有化(保证对象的产生个数) 创建类的对象,要通过构造方法产生对象 构造方法若是public权限,对于类的外部,可…...

Oracle数据库连接之TNS-12541异常
在进行数据库开发的时候,通常需要使用PLSQL Developer开发工具连接Oralce数据库,在进行连接时,经常性的会提示TNS-12541:TNS:no listener(没有监听),从而导致PLSQL Developer 无法连接到数据库实例…...
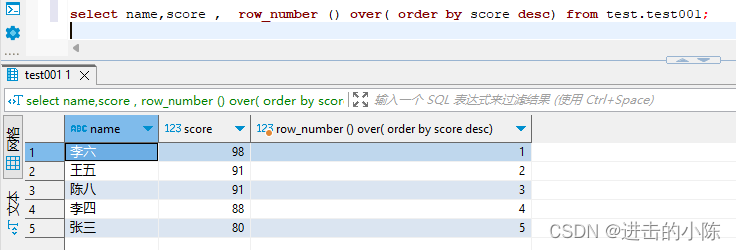
sql中的排序函数dense_rank(),RANK()和row_number()
dense_rank(),RANK()和row_number()是SQL中的排序函数。 为方便后面的函数差异比对清晰直观,准备数据表如下: 1.dense_rank() 函数语法:dense_rank() over( order by 列名 【desc/asc】) DENSE_RANK()是连续排序,比如…...

Flask狼书笔记 | 05_数据库
文章目录 5 数据库5.1 数据库的分类5.2 ORM5.3 使用Flask_SQLAlchemy5.4 数据库操作5.5 定义关系5.6 更新数据库表5.7 数据库进阶小结 5 数据库 这一章学习如何在Python中使用DBMS(数据库管理系统),来对数据库进行管理和操作。本书使用SQLit…...

HJ70 矩阵乘法计算量估算
Powered by:NEFU AB-IN Link 文章目录 HJ70 矩阵乘法计算量估算题意思路代码 HJ70 矩阵乘法计算量估算 题意 矩阵乘法的运算量与矩阵乘法的顺序强相关。 例如: A是一个5010的矩阵,B是1020的矩阵,C是205的矩阵 计算ABC有两种顺序:…...

Doris数据库使用记录
新建表 create table tonly_attendance(vin varchar(64),diggings_name varchar(256),area varchar(64),diggings_type varchar(256),work_time decimal(20,2),engine_run_time decimal(20,2),upload_time varchar(64))DUPLICATE KEY (vin)distributed by hash (vin)删除之…...

华为OD机试真题【篮球比赛】
1、题目描述 【篮球比赛】 一个有N个选手参加比赛,选手编号为1~N(3<N<100),有M(3<M<10)个评委对选手进行打分。 打分规则为每个评委对选手打分,最高分10分,最低分1分。…...
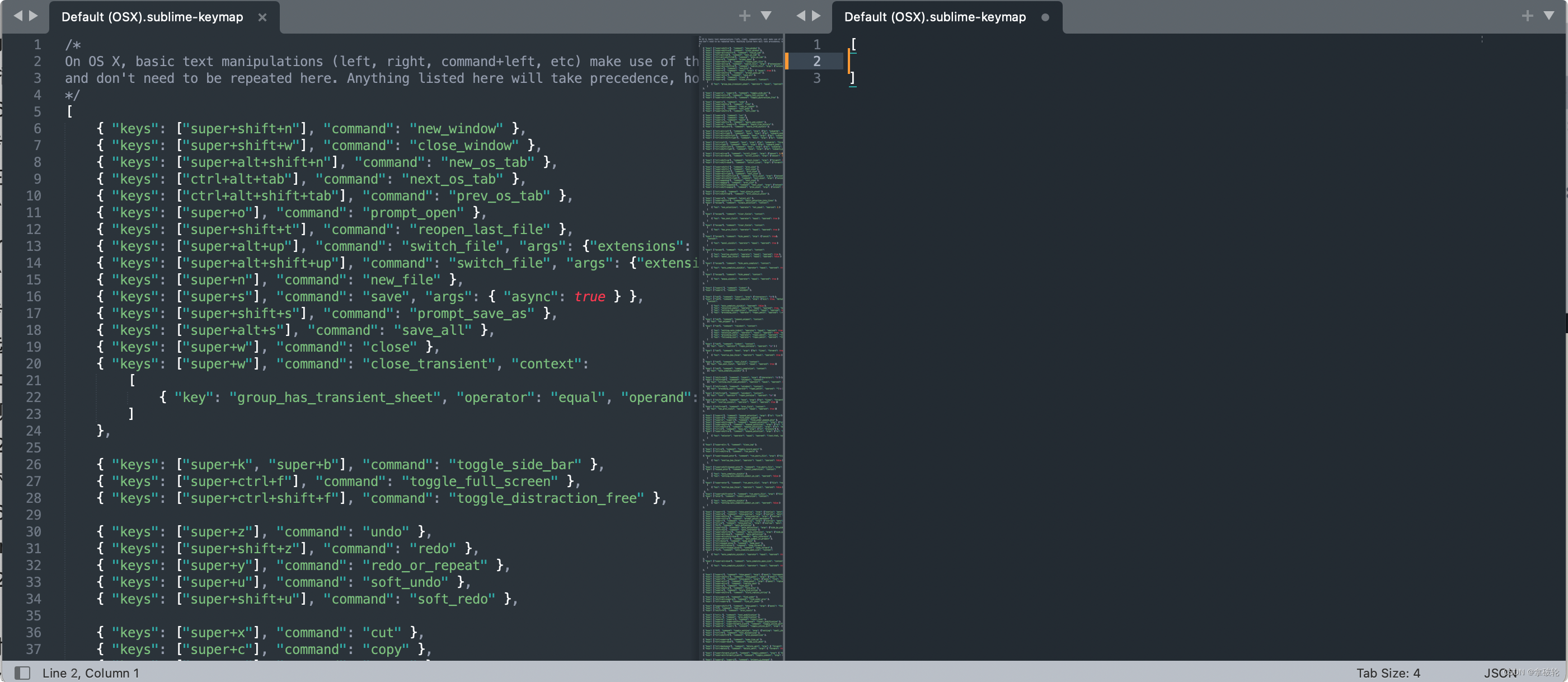
sublime text 格式化json快捷键配置
以 controlcommandj 为例。 打开Sublime Text,依次点击左上角菜单Sublime Text->Preferences->Key Bindings,出现以下文件: 左边的是Sublime Text默认的快捷键,不可编辑。右边是我们自定义快捷键的地方,在中括号…...

Spring Cloud 面试题总结
Spring Cloud和各子项目版本对应关系 Spring Cloud 是一个用于构建分布式系统的开发工具包,它基于Spring Boot提供了一组模块和功能,用于构建微服务架构中的分布式应用程序。Spring Cloud的不同子项目有各自的版本,下面是一些常见的Spring C…...

如何实现24/7客户服务自动化?
传统的客服制胜与否的法宝在于人,互联网时代,对于产品线广的大型企业来说:单靠人力,成本大且效率低,相对于产品相对单一的中小型企业来说:建设传统客服系统的成本难以承受,企业客户服务的转型已…...

2022年12月 C/C++(六级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:区间合并 给定 n 个闭区间 [ai; bi],其中i=1,2,…,n。任意两个相邻或相交的闭区间可以合并为一个闭区间。例如,[1;2] 和 [2;3] 可以合并为 [1;3],[1;3] 和 [2;4] 可以合并为 [1;4],但是[1;2] 和 [3;4] 不可以合并。 我们的任务是…...

【Spring Cloud系列】 雪花算法原理及实现
【Spring Cloud系列】 雪花算法原理及实现 文章目录 【Spring Cloud系列】 雪花算法原理及实现一、概述二、生成ID规则部分硬性要求三、ID号生成系统可用性要求四、解决分布式ID通用方案4.1 UUID4.2 数据库自增主键4.3 基于Redis生成全局id策略 五、SnowFlake(雪花算…...

Postgresql 阿里云部署排雷
启动服务bug: 根据你的输出,可以看到 PostgreSQL 服务启动失败,并且显示以下错误消息: pg_ctl: cannot be run as root Please log in (using, e.g., "su") as the (unprivileged) user that will own the server proc…...
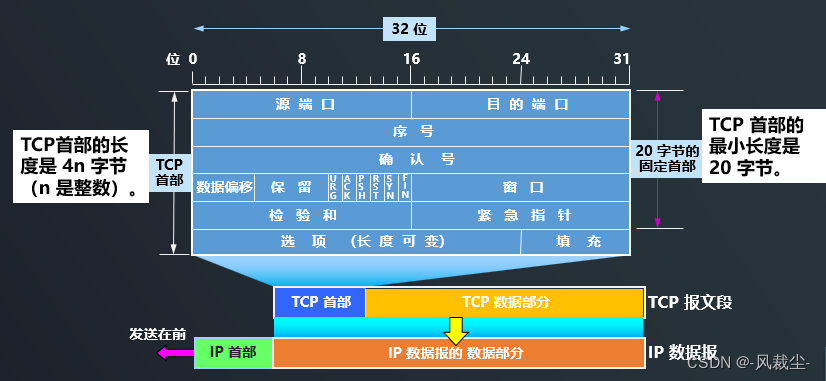
l8-d10 TCP协议是如何实现可靠传输的
一、TCP主要特点 TCP 是面向连接的运输层协议,在无连接的、不可靠的 IP 网络服务基础之上提供可靠交付的服务。为此,在 IP 的数据报服务基础之上,增加了保证可靠性的一系列措施。 TCP主要特点 1.TCP 是面向连接的运输层协议。 每一条 TCP 连…...

9月9日扒面经
堆和栈的区别? 分配方式:堆内存是由程序员手动分配和释放的,而栈内存是由编译器自动分配和释放的。内存管理:堆内存需要手动管理内存的分配和释放,程序员需要显式地调用malloc()或new来分配内存,并使用fre…...
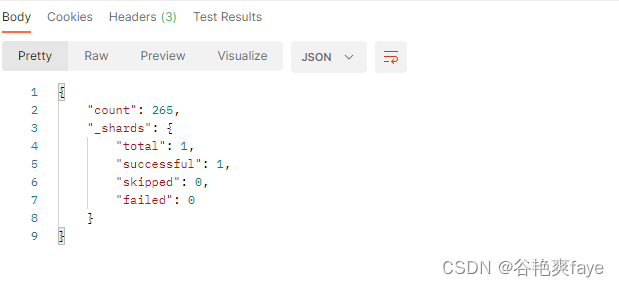
项目实战:ES的增加数据和查询数据
文章目录 背景在ES中增加数据新建索引删除索引 在ES中查询数据查询数据总数量 项目具体使用(实战)引入依赖方式一:使用配置类连接对应的es服务器创建配置类编写业务逻辑----根据关键字查询相关的聊天内容在ES中插入数据 总结提升 背景 最近需…...
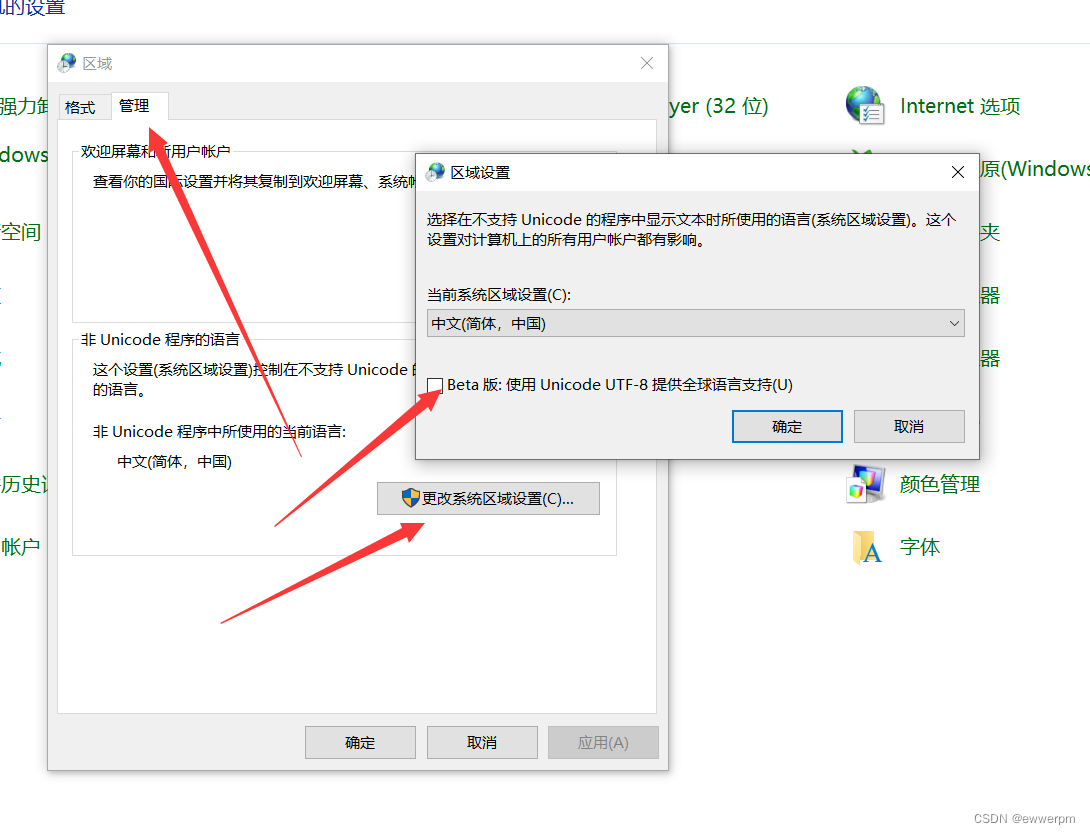
vs code调试rust乱码问题解决方案
在terminal中 用chcp 65001 修改一下字符集,就行了。有的博主推荐 修改 区域中的设置,这会引来很大的问题。千万不要修改如下设置:...
大数据课程K22——Spark的SparkSQL的API调用
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Spark的通过api使用SparkSQL; 一、通过api使用SparkSQL 1. 实现步骤 1. 打开scala IDE开发环境,创建一个scala工程。 2. 导入spark相关依赖jar包。 3. 创建包路径以object类。 4.…...

LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换
LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为学术论文中复杂的数…...

创业早期如何利用导师与代理模型构建核心支持体系
1. 创业早期支持体系的核心价值在技术驱动的创业领域,尤其是半导体、电子设计自动化这类高门槛行业,一个普遍存在的认知是:只要技术足够领先,产品足够创新,成功便是水到渠成。然而,现实往往比这复杂得多。我…...

从科幻到现实:波色量子18.4亿融资背后,量子计算在多领域应用大突破!
【导语:科幻电影《流浪地球2》中智能量子计算机“MOSS”令人印象深刻,如今量子计算已从实验室走向商业化。波色量子成立三年获11轮融资共18.4亿,其量子计算在多领域展现出巨大应用潜力。】波色量子:资本竞逐中的宠儿按照“十五五规…...

重磅!移远通信旗下物联网智能品牌 艾络迅™ 正式发布
物联网技术正深刻重塑产业格局,智能化转型已成为企业核心竞争力的关键。然而,企业在推进物联网项目时普遍面临技术门槛高、开发周期长、系统对接难、全球连接复杂等核心挑战。为破解行业智能化转型难题,帮助更多企业提升物联网开发效率&#…...

观察Taotoken用量看板如何帮助团队透明化管理API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken用量看板如何帮助团队透明化管理API成本 作为团队的技术负责人,管理大模型API成本是一项持续且细致的工作…...

Python ORM实战:SQLAlchemy深度解析
Python ORM实战:SQLAlchemy深度解析 引言 在Python后端开发中,ORM(对象关系映射)是连接应用程序和数据库的重要桥梁。作为一名从Rust转向Python的后端开发者,我深刻体会到SQLAlchemy在处理数据库操作方面的强大能力。S…...

边缘部署模式:在边缘位置部署应用
边缘部署模式:在边缘位置部署应用 一、边缘部署概述 1.1 边缘部署的定义 边缘部署是指将应用或服务部署在靠近用户或数据源的边缘位置,以减少延迟、提高性能、降低带宽消耗并增强数据隐私保护。 1.2 边缘部署的价值 低延迟:减少数据传输延迟高…...

企业微信代开发应用:CallBackUrl验证失败排查与CorpID加密升级实战
1. 企业微信代开发应用验证失败的典型场景 最近不少服务商朋友反馈,代开发应用在验证CallBackUrl时频繁失败。这个问题其实源于企业微信在2022年6月底进行的一次安全升级。当时官方发布公告称,为了提升账户安全性,所有新建的代开发应用都需要…...

Kotlin多平台集成OpenAI API:类型安全与协程流式处理实践
1. 项目概述:当Kotlin遇见OpenAI如果你是一名Android或Kotlin多平台(KMP)开发者,最近想在自己的应用中集成AI对话、图像生成或者语音转文本这类酷炫功能,那么你大概率绕不开OpenAI的API。但当你兴冲冲地打开官方文档&a…...
)
别再只用GitHub了!手把手教你用GitLab搭建团队专属代码仓库(从群组到项目实战)
别再只用GitHub了!手把手教你用GitLab搭建团队专属代码仓库(从群组到项目实战) 在开源生态中,GitHub无疑是代码托管平台的代名词。但对于需要私有化部署和精细权限控制的团队而言,GitLab提供了更完整的DevOps解决方案。…...