一条爬虫抓取一个小网站所有数据
一条爬虫抓取一个小网站所有数据
今天闲来无事,写一个爬虫来玩玩。在网上冲浪的时候发现了一个搞笑的段子网,发现里面的内容还是比较有意思的,于是心血来潮,就想着能不能写一个Python程序,抓取几条数据下来看看,一不小心就把这个网站的所有数据都拿到了。
这个网站主要的数据都是详情在HTML里面的,可以采用lxml模块的xpath对HTML标签的内容解析,获取到自己想要的数据,然后再保存在本地文件中,整个过程是一气呵成的。能够抓取到一页的数据之后,加一个循环就可以抓取到所有页的数据,下面的就是数据展示。
废话少说,直接上Python代码
import requests
import csv
from lxml import etree
import timeclass Page:def __init__(self):self.pre_url = "https://www.biedoul.com"self.start_page = 1self.end_page = 15233def askHTML(self, current_page, opportunity):print("=============================== current page => " + str(current_page) + "===============================")try:pre_url = self.pre_url + "/index/" + str(current_page)page = requests.get(url=pre_url)html = etree.HTML(page.content)articles = html.xpath('/html/body/div/div/div/dl')return articlesexcept Exception as e:if opportunity > 0:time.sleep(500)print("=============================== retry => " + str(opportunity) + "===============================")return self.askHTML(current_page, opportunity - 1)else:return Nonedef analyze(self, articles):lines = []for article in articles:data = {}data["link"] = article.xpath("./span/dd/a/@href")[0]data["title"] = article.xpath("./span/dd/a/strong/text()")[0]data["content"] = self.analyze_content(article)picture_links = article.xpath("./dd/img/@src")if (picture_links is not None and len(picture_links) > 0):# print(picture_links)data["picture_links"] = picture_linkselse:data["picture_links"] = []# data["good_zan"] = article.xpath("./div/div/a[@class='pinattn good']/p/text()")[0]# data["bad_bs"] = article.xpath("./div/div/a[@class='pinattn bad']/p/text()")[0]data["good_zan"] = self.analyze_zan(article, "good")# article.xpath("./div/div/a[@class='pinattn good']/p/text()")[0]data["bad_bs"] = self.analyze_zan(article, "bad")# article.xpath("./div/div/a[@class='pinattn bad']/p/text()")[0]lines.append(data)return lines# 解析文章内容def analyze_content(self, article):# 1. 判断dd标签下是否为文本内容content = article.xpath("./dd/text()")if content is not None and len(content) > 0 and not self.is_empty_list(content):return contentcontent = []p_list = article.xpath("./dd")for p in p_list:# 2. 判断dd/.../font标签下是否为文本内容if len(content) <= 0 or content is None:fonts = p.xpath(".//font")for font_html in fonts:font_content = font_html.xpath("./text()")if font_content is not None and len(font_content) > 0:content.append(font_content)# 3. 判断dd/.../p标签下是否为文本内容if len(content) <= 0 or content is None:fonts = p.xpath(".//p")for font_html in fonts:font_content = font_html.xpath("./text()")if font_content is not None and len(font_content) > 0:content.append(font_content)return contentdef analyze_zan(self, article, type):num = article.xpath("./div/div/a[@class='pinattn " + type + "']/p/text()")if num is not None and len(num) > 0:return num[0]return 0def do_word(self):fieldnames = ['index', 'link', 'title', 'content', 'picture_links', 'good_zan', 'bad_bs']with open('article.csv', 'a', encoding='UTF8', newline='') as f:writer = csv.DictWriter(f, fieldnames=fieldnames)# writer.writeheader()for i in range(self.start_page, self.end_page):articles = self.askHTML(i, 3)if articles is None:continuearticle_list = self.analyze(articles)self.save(writer, article_list)# 保存到文件中def save(self, writer, lines):print("##### 保存中到文件中...")# python2可以用file替代openprint(lines)writer.writerows(lines)print("##### 保存成功...")def is_empty_list(self, list):for l in list:if not self.empty(l):return Falsereturn Truedef empty(self, content):result = content.replace("\r", "").replace("\n", "")if result == "":return Truereturn False# 递归解析文章内容def analyze_font_content(self, font_html, depth):content = []print(depth)font_content_list = font_html.xpath("./font/text()")if font_content_list is not None and len(font_content_list) > 0 and not self.is_empty_list(font_content_list):for font_content in font_content_list:content.append(font_content)else:if depth < 0:return []return self.analyze_font_content(font_html.xpath("./font"), depth - 1)return contentif __name__ == '__main__':page = Page()page.do_word()
在运行下面的代码之前,需要先按照好requests、lxml两个模块,安装命令为:
pip installl requests
pip install lxml
大家对这个爬虫有什么疑问,欢迎给我留言。如果大家对于我这个爬虫创意还不错的话,记得关注微信公众号【智享学习】哟,后续我会分享更多有意思的编程项目。
本文由博客一文多发平台 OpenWrite 发布!
相关文章:
一条爬虫抓取一个小网站所有数据
一条爬虫抓取一个小网站所有数据 今天闲来无事,写一个爬虫来玩玩。在网上冲浪的时候发现了一个搞笑的段子网,发现里面的内容还是比较有意思的,于是心血来潮,就想着能不能写一个Python程序,抓取几条数据下来看看&am…...

八大排序——快速排序
Hello,大家好,今天分享的八大排序里的快速排序,所谓快速排序是一个叫霍尔的人发明,有很多人可能会觉得为什么不叫霍尔排序,其中原因就是因为它快,快速则体现了它的特点,今天我们就来讲一下快速排…...
【ES】笔记-Class类剖析
Class Class介绍与初体验ES5 通过构造函数实例化对象ES6 通过Class中的constructor实列化对象 Class 静态成员实例对象与函数对象的属性不相通实例对象与函数对象原型上的属性是相通的Class中对于static 标注的对象和方法不属于实列对象,属于类。 ES5构造函数继承Cl…...

数学建模--Seaborn库绘图基础的Python实现
目录 1.绘图数据导入 2. sns.scatterplot绘制散点图 3.sns.barplot绘制条形图 4.sns.lineplot绘制线性图 5.sns.heatmap绘制热力图 6.sns.distplot绘制直方图 7.sns.pairplot绘制散图 8.sns.catplot绘制直方图 9.sns.countplot绘制直方图 10.sns.lmplot绘回归图 1.绘图数…...
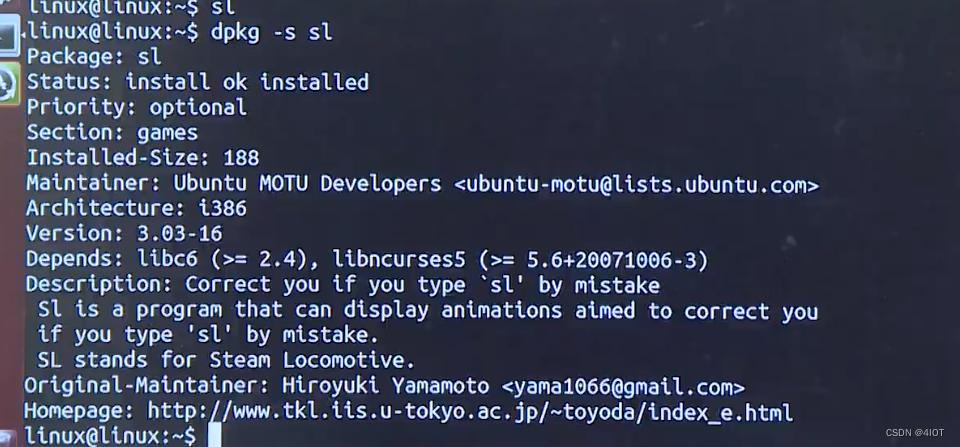
lv3 嵌入式开发-2 linux软件包管理
目录 1 软件包管理 1.1流行的软件包管理机制 1.2软件包的类型 1.3软件包的命名 2 在线软件包管理 2.1APT工作原理 2.2更新软件源 2.3APT相关命令 3 离线软件包管理 1 软件包管理 1.1流行的软件包管理机制 Debian Linux首先提出“软件包”的管理机制---Deb软件包 …...

智能小区与无线网络技术
1.1 智能小区 智能小区指的是具有小区智能化系统的小区。所谓小区智能化系统,指的是在 现代计算机网络和通信技术的基础上,将传统的土木建筑技术与计算机技术、自动 控制技术、通信与信息处理技术、多媒体技术等先进技术相结合的自动化和综…...

如何传输文件流给前端
通过链接下载图片,直接http请求然后将文件流返回 注:music.ly是一个下载tiktok视频的免费接口 https://api19-core-c-useast1a.musical.ly/aweme/v1/feed/?aweme_idxxx func (m *FileBiz) DownloadFileV2(ctx *ctrl.Context, fileLink, fileName strin…...
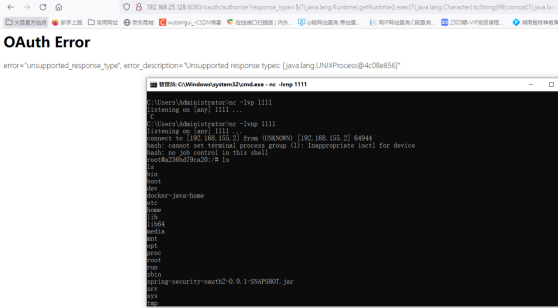
Spring Security OAuth2 远程命令执行漏洞
文章目录 一、搭建环境二、漏洞验证三、准备payload四、执行payload五、变形payload 一、搭建环境 cd vulhub/spring/CVE-2016-4977/ docker-compose up -d 二、漏洞验证 访问 http://192.168.10.171:8080/oauth/authorize?response_type${233*233}&client_idacme&s…...
Python之并发编程介绍
一、并发编程介绍 1.1、串行、并行与并发的区别 串行(serial):一个CPU上,按顺序完成多个任务并行(parallelism):指的是任务数小于等于cpu核数,即任务真的是一起执行的并发(concurrency):一个CPU采用时间片管理方式&am…...
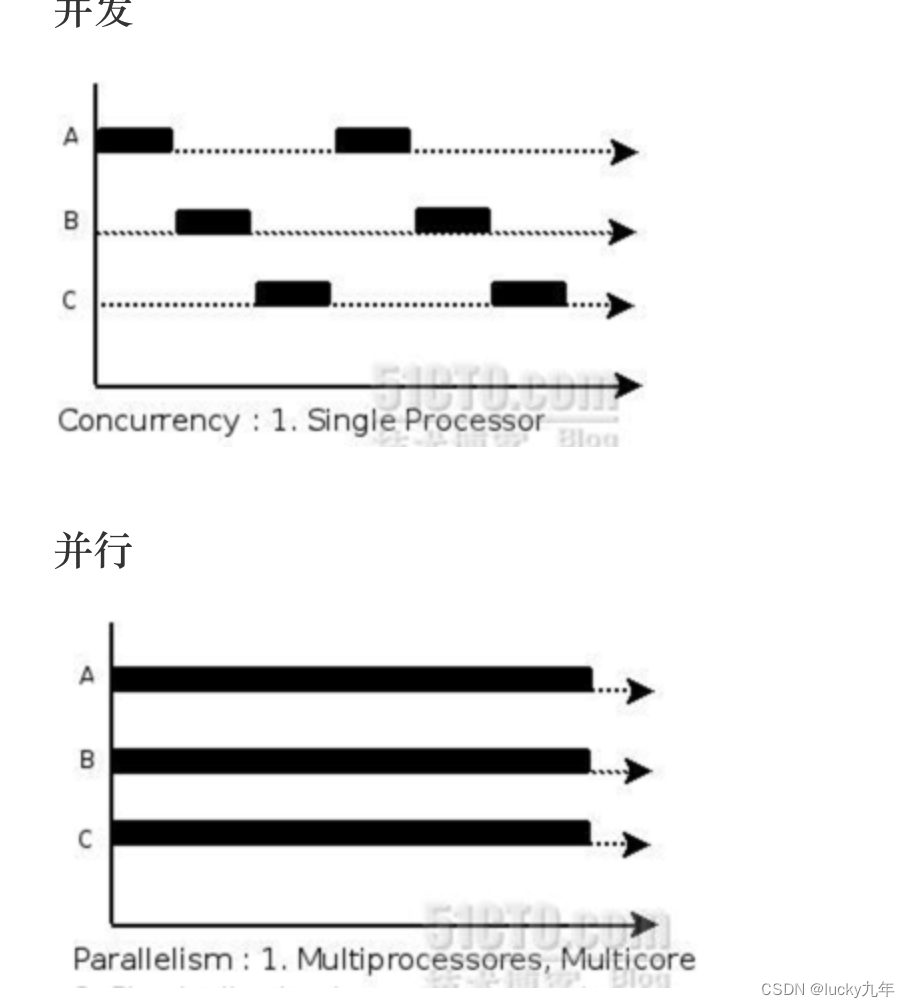
GO语言网络编程(并发编程)并发介绍,Goroutine
GO语言网络编程(并发编程)并发介绍,Goroutine 1、并发介绍 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。 B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更…...

英语连词总结
前言 总结一些常用的英语连词,以下用法只是我希望我自己这么用。分类我可能分的不好,慢慢积累,慢慢改进。 1)表递进: firstly、secondly、thirdly、finally、af first、at the beginning、in the end、to begin with࿰…...

LeetCode 92. Reverse Linked List II【链表,头插法】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

【图论】Floyd
算法提高课笔记) 文章目录 例题牛的旅行题意思路代码 排序题意思路代码 观光之旅题意思路代码 例题 牛的旅行 原题链接 农民John的农场里有很多牧区,有的路径连接一些特定的牧区。 一片所有连通的牧区称为一个牧场。 但是就目前而言,你…...
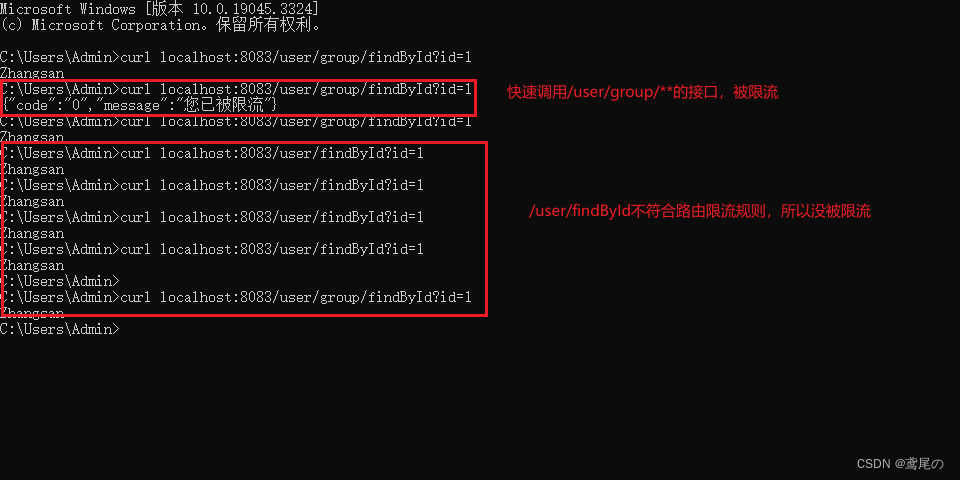
SpringCloudAlibaba Gateway(三)-整合Sentinel功能路由维度、API维度进行流控
Gateway整合Sentinel 前面使用过Sentinel组件对服务提供者、服务消费者进行流控、限流等操作。除此之外,Sentinel还支持对Gateway、Zuul等主流网关进行限流。 自sentinel1.6.0版开始,Sentinel提供了Gateway的适配模块,能针对路由(rou…...

【笔试强训选择题】Day38.习题(错题)解析
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:笔试强训选择题 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!! 文章目录 前言一、Day…...
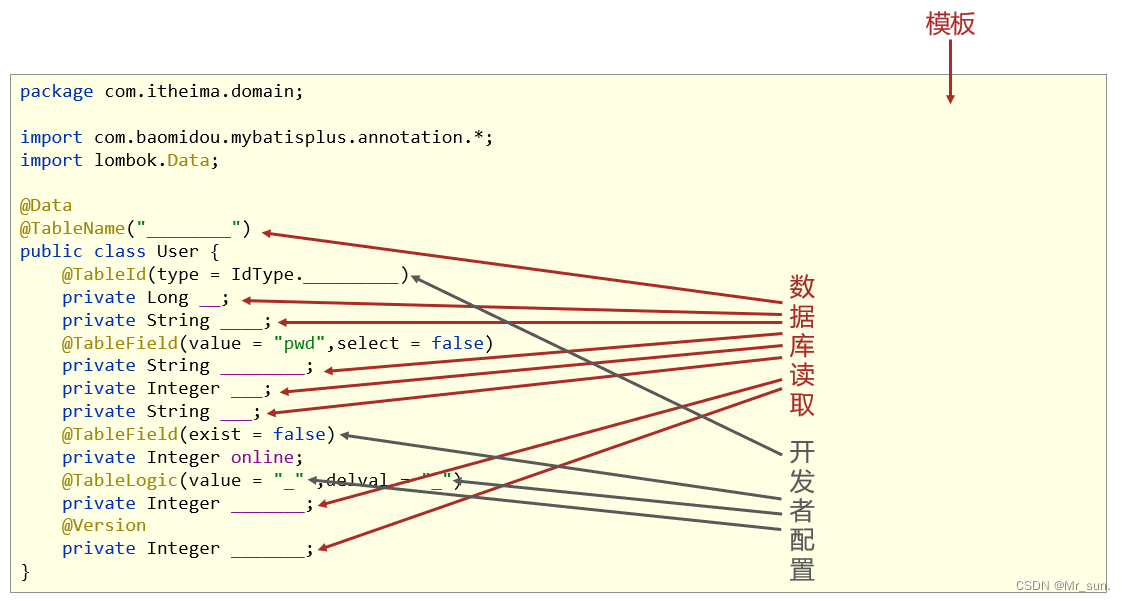
DAY08_MyBatisPlus——入门案例标准数据层开发CRUD-Lombok-分页功能DQL编程控制DML编程控制乐观锁快速开发-代码生成器
目录 一 MyBatisPlus简介1. 入门案例问题导入1.1 SpringBoot整合MyBatisPlus入门程序①:创建新模块,选择Spring初始化,并配置模块相关基础信息②:选择当前模块需要使用的技术集(仅保留JDBC)③:手…...

分光棱镜BS、PB、NPBS的区别
BS(分光棱镜):对入射偏振敏感,线偏振角度会影响分光比。若入射的是自然光或圆偏振光,则按50:50分光。分束的时候只管分能量,理想器件下出射的两路光偏振态还是原来的样子,实际工艺缺…...
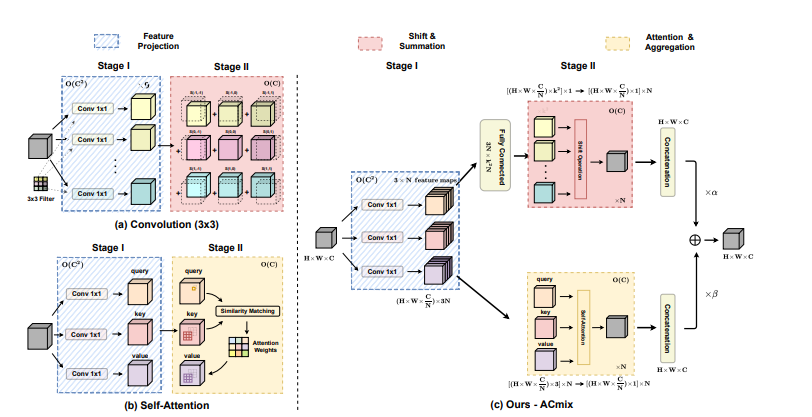
人工智能论文通用创新点(一)——ACMIX 卷积与注意力融合、GCnet(全局特征融合)、Coordinate_attention、SPD(可替换下采样)
1.ACMIX 卷积与注意力融合 论文地址:https://arxiv.org/pdf/2111.14556.pdf 为了实现卷积与注意力的融合,我们让特征图经过两个路径,一个路径经过卷积,另外一个路径经过Transformer,但是,现在有一个问题,卷积路径比较快,Transformer比较慢。因此,我们让Q,K,V通过1*1的…...

您的计算机已被[new_day@torguard.tg].faust 勒索病毒感染?恢复您的数据的方法在这里!
导言: 随着科技的迅速发展,网络空间也变得越来越危险,而勒索病毒则是网络威胁中的一个严重问题。 [ new_daytorguard.tg ].faust 勒索病毒是最新的威胁之一,采用高度复杂的加密技术,将受害者的数据文件锁定,…...

18--Elasticsearch
一 Elasticsearch介绍 1 全文检索 Elasticsearch是一个全文检索服务器 全文检索是一种非结构化数据的搜索方式 结构化数据:指具有固定格式固定长度的数据,如数据库中的字段。 非结构化数据:指格式和长度不固定的数据,如电商网站…...

专业术语统计报告_多种能源发电协同发展管控模型及大数据分析研究
专业术语统计报告_多种能源发电协同发展管控模型及大数据分析研究 一、概要简析 【概要分析】 本文档《多种能源发电协同发展管控模型及大数据分析研究》围绕研究主题展开系统性的探讨。文档总字符数达141569,其中中文字符80856个,英文字词5332个&#x…...

BetterJoy控制器配置终极指南:从零开始快速掌握Switch手柄PC使用技巧
BetterJoy控制器配置终极指南:从零开始快速掌握Switch手柄PC使用技巧 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https:…...

软件测试实战:忍者像素绘卷API接口自动化测试用例设计
软件测试实战:忍者像素绘卷API接口自动化测试用例设计 1. 项目背景与测试目标 忍者像素绘卷:天界画坊是一款基于AI技术的像素艺术生成工具,其API接口为开发者提供了丰富的图像生成能力。作为软件测试工程师,我们需要确保API在各…...

零信任实践:OpenClaw+SecGPT-14B构建个人安全决策引擎
零信任实践:OpenClawSecGPT-14B构建个人安全决策引擎 1. 为什么需要个人安全决策引擎 去年某个深夜,我的服务器突然收到大量异常登录尝试。虽然最终没有造成损失,但这件事让我意识到:传统的静态密码和固定权限规则,在…...

OpenClaw权限管控:安全使用SecGPT-14B的5条黄金法则
OpenClaw权限管控:安全使用SecGPT-14B的5条黄金法则 1. 为什么需要特别关注OpenClaw的权限安全? 去年我在调试一个自动整理文档的OpenClaw任务时,曾不小心让AI助手误删了整个工作目录——仅仅因为我在配置时勾选了"允许文件删除"…...

OpenClaw配置备份指南:gemma-3-12b-it模型迁移与快速恢复
OpenClaw配置备份指南:gemma-3-12b-it模型迁移与快速恢复 1. 为什么需要备份OpenClaw配置? 上周我的主力开发机突然硬盘故障,导致精心调校的OpenClaw配置全部丢失。整整两天时间,我都在重新配置模型参数、飞书通道和自定义技能—…...

关键词SEO服务对网站排名有什么影响_关键词SEO服务与移动端优化有什么关系
SEO服务对网站排名有什么影响 在当前数字化时代,网站排名的重要性不言而喻。无论是企业、个人博客还是新媒体,网站的流量直接关系到业务的发展和品牌的影响力。而在这其中,关键词SEO服务起到了至关重要的作用。关键词SEO服务对网站排名究竟有…...

GLM-4.1V-9B-Base部署指南:模型权重校验+SHA256完整性验证流程
GLM-4.1V-9B-Base部署指南:模型权重校验SHA256完整性验证流程 1. 模型简介 GLM-4.1V-9B-Base是智谱开源的视觉多模态理解模型,支持以下核心功能: 图像内容识别与描述场景理解与分析目标检测与问答中文视觉理解任务 该模型采用9B参数规模&…...

【OpenClaw】测试工程师如何使用 OpenClaw 参与测试流程
测试工程师如何使用 OpenClaw 参与测试流程1.OpenClaw 能帮测试工程师做什么?2.核心能力:Skill 让 AI 具备测试执行能力2.1 API 测试 Skill2.2 浏览器自动化 Skill2.3 数据库操作 Skill3.实战工作流:让 OpenClaw 跑通你的测试流程3.1 工作流 …...

告别手动备份!用Power Automate Desktop自动备份桌面重要文件并生成日志
告别手动备份!用Power Automate Desktop打造智能文件备份系统 每天下班前,你是否会习惯性地将桌面上的重要文件拖拽到U盘或移动硬盘?这种重复性操作不仅耗时耗力,还容易因疏忽导致文件遗漏。更糟糕的是,当系统崩溃或误…...