18--Elasticsearch
一 Elasticsearch介绍
1 全文检索

Elasticsearch是一个全文检索服务器
全文检索是一种非结构化数据的搜索方式
- 结构化数据:指具有固定格式固定长度的数据,如数据库中的字段。

- 非结构化数据:指格式和长度不固定的数据,如电商网站的商品详情。



结构化数据一般存入数据库,使用sql语句即可快速查询。但由于非结构化数据的数据量大且格式不固定,我们需要采用全文检索的方式进行搜索。全文检索通过建立倒排索引加快搜索效率。
2 倒排索引

索引
将数据中的一部分信息提取出来,重新组织成一定的数据结构,我们可以根据该结构进行快速搜索,这样的结构称之为索引。
索引即目录,例如字典会将字的拼音提取出来做成目录,通过目录即可快速找到字的位置。
索引分为正排索引和倒排索引。
正排索引(正向索引)
将文档id建立为索引,通过id快速可以快速查找数据。如数据库中的主键就会创建正排索引。

倒排索引(反向索引)
非结构化数据中我们往往会根据关键词查询数据。此时我们将数据中的关键词建立为索引,指向文档数据,这样的索引称为倒排索引。

创建倒排索引流程:

3 Elasticsearch数据结构

文档(Document):文档是可被查询的最小数据单元,一个 Document 就是一条数据。类似于关系型数据库中的记录的概念。
类型(Type):具有一组共同字段的文档定义成一个类型,类似于关系型数据库中的数据表的概念。
索引(Index):索引是多种类型文档的集合,类似于关系型数据库中的库的概念。
域(Fied):文档由多个域组成,类似于关系型数据库中的字段的概念。
Elasticsearch跟关系型数据库中概念的对比:
| JAVA | 项目 | 实体类 | 对象 | 属性 |
|---|---|---|---|---|
| ES | Index | Type | Document | Filed |
| Mysql | Database | Table | Row | Column |
注:ES7.X之后删除了type的概念,一个索引不会代表一个库, 而是代表一张表。本文中使用ES7.17,所以目前的ES中概念对比为:
| JAVA | 项目 | 实体类 | 对象 | 属性 |
|---|---|---|---|---|
| ES | Index | Document | Filed | |
| Mysql | Database | Table | Row | Column |
二 Elasticsearch安装
1 安装ES服务
准备工作
- 准备一台搭载有CentOS7系统的虚拟机,使用XShell连接虚拟机
- 关闭防火墙,方便访问ES
#关闭防火墙:
systemctl stop firewalld.service#禁止防火墙自启动:
systemctl disable firewalld.service
- 配置最大可创建文件数大小
#打开系统文件:
vim /etc/sysctl.conf#添加以下配置:
vm.max_map_count=655360#配置生效:
sysctl -p
- 由于ES不能以root用户运行,我们需要创建一个非root用户,此 处创建一个名为es的用户:
#创建用户:
useradd es
安装服务
- 使用xftp将linux版的ES上传至虚拟机
- 解压ES
#解压:
tar -zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz#重命名:
mv elasticsearch-7.17.0 elasticsearch1#移动文件夹:
mv elasticsearch1 /usr/local/#es用户取得该文件夹权限:
chown -R es:es /usr/local/elasticsearch1
改变文件拥有者chown
语法:
chown [-R] 属主名:属组名 文件名
- 启动ES服务:
#切换为es用户:
su es#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/#启动ES服务:
./elasticsearch#查询ES服务是否启动成功
curl 127.0.0.1:9200
2 安装kibana

Kibana是一款开源的数据分析和可视化平台,设计用于和 Elasticsearch协作。我们可以使用Kibana对Elasticsearch索引中的数据进行搜索、查看、交互操作。
- 使用xftp将将Kibana压缩文件上传到Linux虚拟机
- 解压
tar -zxvf kibana-7.17.0-linux-x86_64.tar.gz -C /usr/local/
- 修改配置
# 进入Kibana解压路径
cd /usr/local/kibana-7.17.0-linux-x86_64/config# 修改配置文件
vim kibana.yml# 加入以下内容
# kibana主机IP
server.host: "虚拟机IP"
# Elasticsearch路径
elasticsearch.hosts: ["http://127.0.0.1:9200"]
- 启动:
kibana不能以root用户运行,我们给es用户设置kibana目录的权限,并使用es用户运行kibana
# 给es用户设置kibana目录权限
chown -R es:es /usr/local/kibana-7.17.0-linux-x86_64/# 切换为es用户
su es# 启动kibana
cd /usr/local/kibana-7.17.0-linux-x86_64/bin/
./kibana
- 访问kibana:http://虚拟机IP:5601
- 点击 Management =>Stack Management => Index Management 可以查看es索引信息。
3 Docker安装
安装Elasticsearch
拉取镜像
docker pull elasticsearch:7.17.0
启动容器
# docker容器间建立通信
docker network create elastic
# 创建es容器
docker run --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=singlenode" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --name='elasticsearch' --net elastic --cpuset-cpus="1" -m 1G -d elasticsearch:7.17.0
安装Kibana
拉取镜像
docker pull kibana:7.17.0
启动容器
docker run --name kibana --net elastic --link elasticsearch:elasticsearch -p 5601:5601 -d kibana:7.17.0
访问kibana:http://虚拟机IP:5601
三 Elasticsearch常用操作
1 索引操作

Elasticsearch是使用RESTful风格的http请求访问操作的,请求参数和返回值都是Json格式的,我们可以使用kibana发送http请求操作ES。
创建没有结构的索引
路径:ip地址:端口号/索引名
注:在kibana中所有的请求都会省略 ip地址:端口号 ,之后的路径我 们省略写 ip地址:端口号
请求方式:PUT
举例:
PUT /student
为索引添加结构
POST /索引名/_mapping
{"properties":{"域名1":{"type":域的类型,"store":是否存储,"index":是否创建索引,"analyzer":分词器},"域名2":{...}}
}举例:
POST /student/_mapping
{"properties": {"id":{"type":"integer"},"name": {"type": "text"},"age": {"type": "integer"}}
}
创建有结构的索引

PUT /索引名
{"mappings":{"properties":{"域名1":{"type":域的类型,"store":是否单独存储,"index":是否创建索引,"analyzer":分词器},"域名2":{...}}}
}举例:
PUT /student1
{"mappings": {"properties": {"name": {"type": "text"},"age": {"type": "integer"}}}
}删除索引
DELETE /索引名
举例:
DELETE /student1
2 文档操作

新增/修改文档
POST /索引/_doc/[id值]
{"field名":field值
}
注:id值不写时自动生成文档id,id和已有id重复时修改文档
举例:
POST /student/_doc/1
{"name": "lxx","age": 18
}
根据id查询文档
GET /索引/_doc/id值
举例:
GET /student/_doc/1
删除文档
DELETE /索引/_doc/id值
举例:
DELETE /student/_doc/1
根据id批量查询文档
GET /索引/_mget
{"docs":[{"_id":id值},{"_id":id值}]
}
举例:
GET /student/_mget
{"docs": [{"_id": 1},{"_id": 2}]
}
查询所有文档
GET /索引/_search
{"query": {"match_all": {}}
}
举例:
GET /student/_search
{"query": {"match_all": {}}
}
修改文档部分字段
POST /索引/_doc/id值/_update
{"doc":{域名:值}
}
注:
Elasticsearch执行删除操作时,ES先标记文档为deleted状态, 而不是直接物理删除。当ES存储空间不足或工作空闲时,才会执行物理删除操作。
Elasticsearch执行修改操作时,ES不会真的修改Document中 的数据,而是标记ES中原有的文档为deleted状态,再创建一个 新的文档来存储数据。
举例:
POST /student/_doc/1/_update
{"doc": {"name": "newLxx"}
}
3 域的属性
index
该域是否创建索引。只有值设置为true,才能根据该域的关键词查询文档。
// 根据关键词查询文档
GET /索引名/_search
{"query":{"term":{搜索字段: 关键字}}
}
案例:
PUT /student1
{"mappings": {"properties": {"name": {"type": "text","index": true}}}
}PUT /student2
{"mappings": {"properties": {"name": {"type": "text","index": false}}}
}POST /student1/_doc/1
{"name":"I love you"
}POST /student2/_doc/1
{"name":"I love you"
}GET /student1/_search
{"query":{"term":{"name":"love"}}
}
// 可以查询到结果GET /student2/_search
{"query":{"term":{"name":"love"}}
}
// 查询不到结果
type
域的类型
| 核心类型 | 具体类型 |
|---|---|
| 字符串类型 | text |
| 整数类型 | long, integer, short, byte |
| 浮点类型 | double, float |
| 日期类型 | date |
| 布尔类型 | boolean |
| 数组类型 | array |
| 对象类型 | object |
| 不分词的字符串 | keyword |
store
是否单独存储。如果设置为true,则该域能够单独查询。
// 单独查询某个域:
GET /索引名/_search
{"stored_fields": ["域名"]
}
举例:
PUT /student3
{"mappings": {"properties": {"name": {"type": "text","store": true}}}
}POST /student3/_doc/1
{"name":"I love you1"
}POST /student3/_doc/2
{"name":"I love you2"
}GET /student3/_search
{"stored_fields": ["name"]
}四 分词器
1 默认分词器

ES文档的数据拆分成一个个有完整含义的关键词,并将关键词与文档对应,这样就可以通过关键词查询文档。要想正确的分词,需要选择合适的分词器。
analyzer:插入文档时,将text类型的字段做分词然后插入倒排索引。
search_analyzer:查询时,先对要查询的text类型的输入做分词,再去倒排索引中搜索。
如果想要让’索引’和’查询’时使用不同的分词器,ElasticSearch也是能支持的,只需要在字段上加上search_analyzer参数。插入时,只会去看字段有没有定义analyzer,有定义的话就用定义的,没定义就用es预设的。查询时,会先去看字段有没有定义search_analyzer,如果没有定义,就去看有没有analyzer,再没有定义,才会去使用es预设的
standard analyzer:Elasticsearch默认分词器,根据空格和标点符号对英文进行分词,会进行单词的大小写转换。
默认分词器是英文分词器,对中文的分词是一字一词。
- 查看分词效果
GET /_analyze
{"text":"测试语句","analyzer":"分词器"
}
- 举例
GET /_analyze
{"text": "I love you","analyzer": "standard"
}
2 IK分词器

IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。提供了两种分词算法:
- ik_smart:最少切分
- ik_max_word:最细粒度划分
安装IK分词器
- 关闭es服务
- 使用xftp将ik分词器上传至虚拟机
注:ik分词器的版本要和es版本保持一致。
- 解压ik分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis-ik
- 启动ES服务
su es#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/#启动ES服务:
./elasticsearch -d
测试分词器效果
GET /_analyze
{"text":"测试语句","analyzer":"ik_smart/ik_max_word"
}举例:
GET /_analyze
{"text": "湖人总冠军","analyzer": "ik_smart"
}
IK分词器词典
IK分词器根据词典进行分词,词典文件在IK分词器的config目录中。(/usr/local/elasticsearch1/plugins/analysis-ik/config)
- main.dic:IK中内置的词典。记录了IK统计的所有中文单词。
- IKAnalyzer.cfg.xml:用于配置自定义词库。
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext_dict.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">ext_stopwords.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3 拼音分词器

拼音分词器可以将中文分成对应的全拼,全拼首字母等。
安装拼音分词器
- 关闭es服务
- 使用xftp将拼音分词器上传至虚拟机
注:ik分词器的版本要和es版本保持一致。
- 解压拼音分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis-pinyin
- 启动ES服务
su es#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/#启动ES服务:
./elasticsearch
测试分词器效果
GET /_analyze
{"text":"测试语句","analyzer":"pinyin"
}举例:
GET /_analyze
{"text": "湖人总冠军","analyzer": "pinyin"
}
4 自定义分词器

真实开发中我们往往需要对一段内容既进行文字分词,又进行拼音分词,此时我们需要自定义ik+pinyin分词器。
创建自定义分词器
- 在创建索引时自定义分词器
PUT /索引名
{"settings" : {"analysis" : {"analyzer" : {"ik_pinyin" : { //自定义分词器名"tokenizer":"ik_max_word", // 基本分词器"filter":"pinyin_filter" // 配置分词器过滤}},"filter" : { // 分词器过滤时配置另一个分词器,相当于同时使用两个分词器"pinyin_filter" : {"type" : "pinyin", // 另一个分词器// 拼音分词器的配置"keep_separate_first_letter" : false, // 是否分词每个字的首字母"keep_full_pinyin" :true, // 是否分词全拼"keep_original" : true,// 是否保留原始输入"remove_duplicated_term": true // 是否删除重复项}}}},"mappings":{"properties":{"域名1":{"type":域的类型,"store":是否单独存储,"index":是否创建索引,"analyzer":分词器},"域名2":{...}}}
}
- 举例:
PUT /student4
{"settings": {"analysis": {"analyzer": {"ik_pinyin": {"tokenizer": "ik_max_word","filter": "pinyin_filter"}},"filter": {"pinyin_filter": {"type": "pinyin","keep_separate_first_letter": false,"keep_full_pinyin": true,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"name": {"type": "text","store": true,"index": true,"analyzer": "ik_pinyin"},"age": {"type": "integer"}}}
}测试自定义分词器
GET /索引/_analyze
{"text": "测试语句","analyzer": "ik_pinyin"
}
举例:
GET /student4/_analyze
{"text": "湖人总冠军","analyzer": "ik_pinyin"
}
五 Elasticsearch搜索文档
1 准备工作

Elasticsearch提供了全面的文档搜索方式,在学习前我们添加一些文档数据
PUT /students
{"mappings": {"properties": {"id": {"type": "integer","index": true},"name": {"type": "text","store": true,"index": true,"analyzer": "ik_smart"},"info": {"type": "text","store": true,"index": true,"analyzer": "ik_smart"}}}
}
POST /students/_doc/
{"id": 1,"name": "百战程序员","info": "I love baizhan"
}
POST /students/_doc/
{"id": 2,"name": "美羊羊","info": "美羊羊是羊村最漂亮的人"
}
POST /students/_doc/
{"id": 3,"name": "懒羊羊","info": "懒羊羊的成绩不是很好"
}
POST /students/_doc/
{"id": 4,"name": "小灰灰","info": "小灰灰的年纪比较小"
}
POST /students/_doc/
{"id": 5,"name": "沸羊羊","info": "沸羊羊喜欢美羊羊"
}
POST /students/_doc/
{"id": 6,"name": "灰太狼","info": "灰太狼是小灰灰的父亲,每次都会说我一定会回来的"
}
- 文档搜索
GET /索引/_search
{"query":{搜索方式:搜索参数}
}2 搜索方式

- match_all:查询所有文档
{"query":{"match_all":{}}
}
举例:
GET /students/_search
{"query": {"match_all": {}}
}
- match:全文检索。将查询条件分词后再进行搜索。
{"query":{"match":{"搜索字段":"搜索条件"}}
}
注:在搜索时关键词有可能会输入错误,ES搜索提供了自动纠错功能,即ES的模糊查询。使用match方式可以实现模糊查询。模糊查询对中文的支持效果一般,我们使用英文数据测试模糊查询。
{"query":{"match":{"域名":{"query":"搜索条件","fuzziness":"最多错误字符数,不能超过2"}}} }
举例:
GET /students/_search
{"query": {"match": {"info": "我喜欢成绩好的"}}
}
GET /students/_search
{"query": {"match": {"info": {"query": "lovr","fuzziness": 1}}}
}
- range:范围搜索。对数字类型的字段进行范围搜索
{"query":{"range":{搜索字段:{"gte":最小值,"lte":最大值}}}
}
gt/lt:大于/小于
gte/lte:大于等于/小于等于
举例:
GET /students/_search
{"query": {"range": {"id": {"gte": 2,"lte": 4}}}
}
- match_phrase:短语检索。搜索条件不做任何分词解析,在搜索字段对应的倒排索引中精确匹配。
{"query":{"match_phrase":{搜索字段:搜索条件}}
}
举例:
GET /students/_search
{"query": {"match_phrase": {"info": "喜欢"}}
}
- term/terms:单词/词组搜索。搜索条件不做任何分词解析,在搜索字段对应的倒排索引中精确匹配
{"query":{"term":{ 搜索字段: 搜索条件}}
}
{"query":{"terms":{ 搜索字段: [搜索条件1,搜索条件2]}}
}
举例:
GET /students/_search
{"query": {"term": {"info": "喜欢"}}
}GET /students/_search
{"query": {"terms": {"info": ["喜欢","漂亮"]}}
}
3 复合搜索

GET /索引/_search
{"query": {"bool": {// 必须满足的条件"must": [搜索方式:搜索参数,搜索方式:搜索参数],// 多个条件有任意一个满足即可"should": [搜索方式:搜索参数,搜索方式:搜索参数],// 必须不满足的条件"must_not":[搜索方式:搜索参数,搜索方式:搜索参数]}}
}
举例:
GET /students/_search
{"query": {"bool": {"must": [{"match": {"info": "美羊羊喜欢成绩好的同学"}}],"must_not": [{"range": {"id": {"gte": 1,"lte": 3}}}]}}
}
4 结果排序

ES中默认使用相关度分数实现排序,可以通过搜索语法定制化排序。
GET /索引/_search
{"query": "搜索条件","sort": [{"字段1": {"order": "asc"}},{"字段2": {"order": "desc"}}]
}
由于ES对text类型字段数据会做分词处理,使用哪一个单词做排序都是不合理的,所以ES中默认不允许对text类型的字段做排序。如果需要使用字符串做结果排序,可以使用 keyword类型 的字段作为排序依据,因为keyword字段不做分词处理。
举例:
GET /students/_search
{"query": {"match": {"name": "羊"}},"sort": [{"id": {"order": "desc"}}]
}
5 分页查询

GET /索引/_search
{"query": 搜索条件,"from": 起始下标,"size": 查询记录数
}
举例:
GET /students/_search
{"query": {"match_all": {}},"from": 0,"size": 2
}GET /students/_search
{"query": {"match_all": {}},"from": 2,"size": 2
}
6 高亮查询

在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。
为什么在网页中关键字会显示不同的颜色,我们通过开发者工具查看网页源码:

我们可以在关键字左右加入标签字符串,数据传入前端即可完成高亮显示,ES可以对查询出的内容中关键字部分进行标签和样式的设置。
GET /索引/_search
{"query":搜索条件,"highlight":{"fields": {"高亮显示的字段名": {// 返回高亮数据的最大长度"fragment_size":100,// 返回结果最多可以包含几段不连续的文字"number_of_fragments":5}},"pre_tags":["前缀"],"post_tags":["后缀"]}}
}
举例:
GET /students/_search
{"query": {"match": {"info": "我喜欢成绩好的"}},"highlight": {"fields": {"info": {"fragment_size": 20,"number_of_fragments": 5}},"pre_tags": ["<em>"],"post_tags": ["</em>"]}
}
7 SQL查询
在ES7之后,支持SQL语句查询文档:
GET /_sql?format=txt
{"query": SQL语句
}
开源版本的ES并不支持通过Java操作SQL进行查询,如果需要操 作 SQL查询,则需要氪金(购买白金版)
六 原生JAVA操作ES
1 搭建项目

原生JAVA可以对ES的索引和文档进行操作,但操作较复杂,我们了解即可。
- 创建maven项目
- maven项目引入以下依赖:
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.17.0</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.17.0</version></dependency>
2 索引操作
创建空索引
//索引操作
public class IndexTest {// 创建空索引@Testpublic void createIndex() throws IOException {// 1.创建客户端对象,连接ESRestHighLevelClient client = newRestHighLevelClient(RestClient.builder(newHttpHost("192.168.66.113", 9200, "http")));// 2.创建请求对象CreateIndexRequest request = new CreateIndexRequest("student");// 3.发送请求CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);// 4.操作响应结果System.out.println(response.index());// 5.关闭客户端client.close();}
外部无法访问ES的解决方案:
打开Elasticsearch安装路径下config目录下的elasticsearch.yml 文件,加入如下配置:
discovery.seed_hosts: ["host1"] network.host: 0.0.0.0重新启动ES即可。
PS:如果修改配置文件后,启动报错:
1、max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
每个进程最大同时打开文件数太小
修改/etc/security/limits.conf文件,增加配置,用户退出后重新登录生效
* soft nofile 65536 * hard nofile 655362、max number of threads [3818] for user [hadoop] is too low, increase to at least [4096]
问题同上,最大线程个数太低。
修改/etc/security/limits.conf文件,增加配置,用户退出后重新登录生效
* soft nproc 4096 * hard nproc 4096
给索引添加结构
//给索引添加结构@Testpublic void mappingIndex() throws IOException {// 1.创建客户端对象,连接ESRestHighLevelClient client = newRestHighLevelClient(RestClient.builder(newHttpHost("192.168.66.113", 9200, "http")));// 2.创建请求对象PutMappingRequest request = new PutMappingRequest("student");request.source("{\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\":\"integer\"\n" +" },\n" +" \"name\": {\n" +" \"type\": \"text\"\n" +" },\n" +" \"age\": {\n" +" \"type\": \"integer\"\n" +" }\n" +" }\n" +"}", XContentType.JSON);// 3.发送请求AcknowledgedResponse response = client.indices().putMapping(request, RequestOptions.DEFAULT);// 4.操作响应结果System.out.println(response.isAcknowledged());// 5.关闭客户端client.close();}
删除索引
// 删除索引@Testpublic void deleteIndex() throws IOException {// 1.创建客户端对象,连接ESRestHighLevelClient client = newRestHighLevelClient(RestClient.builder(newHttpHost("192.168.66.113", 9200, "http")));// 2.创建请求对象DeleteIndexRequest request = new DeleteIndexRequest("student");// 3.发送请求AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);// 4.操作响应结果System.out.println(response.isAcknowledged());// 5.关闭客户端client.close();}
3 文档操作
新增&修改文档
//新增&修改文档@Testpublic void addDocument() throws IOException {// 1.创建客户端对象,连接ESRestHighLevelClient client = newRestHighLevelClient(RestClient.builder(newHttpHost("192.168.66.113", 9200, "http")));// 2.创建请求对象IndexRequest request = new IndexRequest("student").id("1");request.source(XContentFactory.jsonBuilder().startObject().field("id", 1).field("name", "i love lxx").field("age", 20).endObject());// 3.发送请求IndexResponse response = client.index(request, RequestOptions.DEFAULT);// 4.操作响应结果System.out.println(response.status());// 5.关闭客户端client.close();}
根据id查询文档
// 根据id查询文档@Testpublic void findByIdDocument() throws IOException {// 1.创建客户端对象,连接ESRestHighLevelClient client = newRestHighLevelClient(RestClient.builder(newHttpHost("192.168.66.113", 9200, "http")));// 2.创建请求对象GetRequest request = new GetRequest("student", "1");// 3.发送请求GetResponse response = client.get(request, RequestOptions.DEFAULT);// 4.操作响应结果System.out.println(response.getSourceAsString());// 5.关闭客户端client.close();}
删除文档
// 删除文档@Testpublic void DeleteDocument() throwsIOException {// 1.创建客户端对象,连接ESRestHighLevelClient client = newRestHighLevelClient(RestClient.builder(newHttpHost("192.168.66.113", 9200, "http")));// 2.创建请求对象DeleteRequest request = new DeleteRequest("student", "1");// 3.发送请求DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);// 4.操作响应结果System.out.println(response.status());// 5.关闭客户端client.close();}
3 搜索操作
搜索所有文档
//搜索所有文档@Testpublic void queryAllDocument() throws IOException {// 1.创建客户端对象,连接ESRestHighLevelClient client = newRestHighLevelClient(RestClient.builder(newHttpHost("192.168.66.113", 9200, "http")));// 创建搜索条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 创建请求对象SearchRequest request = new SearchRequest("student").source(searchSourceBuilder);// 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 输出返回结果for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString());}// 关闭客户端client.close();}根据关键词搜索文档
//根据关键词搜索文档@Testpublic void queryTermDocument() throwsIOException {// 创建客户端对象,链接ESRestHighLevelClient client = newRestHighLevelClient(RestClient.builder(newHttpHost("192.168.66.113", 9200, "http")));// 创建请求条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.termQuery("name", "lxx"));// 创建请求对象SearchRequest request = new SearchRequest("student").source(searchSourceBuilder);// 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 输出返回结果for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString());}// 关闭客户端client.close();}
七 SpringDataES
1 入门案例

项目搭建
Spring Data ElasticSearch是Spring对原生JAVA操作Elasticsearch 封装之后的产物。它通过对原生API的封装,使得JAVA程序员可以简单的对Elasticsearch进行操作。
- 创建SpringBoot项目,加入Spring Data Elasticsearch起步依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
- 编写配置文件:
spring:elasticsearch:uris: http://192.168.66.113:9200
此时Spring Data ElasticSearch项目已经搭建完成。
创建实体类
一个实体类的所有对象都会存入ES的一个索引中,所以我们在创建实体类时关联ES索引
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "product", createIndex = true)
public class Product {@Id@Field(type = FieldType.Integer, store = true, index = true)private Integer id;@Field(type = FieldType.Text, store = true, index = true,analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")private String productName;@Field(type = FieldType.Text, store = true, index = true,analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")private String productDesc;}
@Document:标记在类上,标记实体类为文档对象,一般有如下属性:
indexName:对应索引的名称
createIndex:是否自动创建索引
@Id:标记在成员变量上,标记一个字段为主键,该字段的值会同步到ES该文档的id值。
@Field:标记在成员变量上,标记为文档中的域,一般有如下属性:
type:域的类型
index:是否创建索引,默认是 true
store:是否单独存储,默认是 false
analyzer:分词器
searchAnalyzer:搜索时的分词器
创建Repository接口

创建Repository接口继承ElasticsearchRepository,该接口提供了文档的增删改查方法
public interface ProductRepository extends ElasticsearchRepository<Product, Integer> {
}
测试方法
编写测试类,注入Repository接口并测试Repository接口的增删改 查方法
@SpringBootTest
public class ProductRepositoryTest {@Autowiredprivate ProductRepository repository;@Testpublic void addDocument() {Product product = new Product(1, "iphone30", "iphone30是苹果最新手机");repository.save(product);}@Testpublic void updateDocument() {Product product = new Product(1, "iphone31", "iphone31是苹果最新手机");repository.save(product);}@Testpublic void findAllDocument() {Iterable<Product> all = repository.findAll();for (Product product : all) {System.out.println(product);}}@Testpublic void findDocumentById() {Optional<Product> product = repository.findById(1);System.out.println(product.get());}
}
2 查询方式

接下来我们讲解SpringDataES支持的查询方式,首先准备一些文档数据:
// 添加一些数据repository.save(new Product(2, "三体1", "三体1 是优秀的科幻小说"));repository.save(new Product(3, "三体2", "三体2 是优秀的科幻小说"));repository.save(new Product(4, "三体3", "三体3 是优秀的科幻小说"));repository.save(new Product(5, "elasticsearch", "elasticsearch是基于lucene开发的优秀的搜索引擎"));
使用Repository继承的方法查询文档
该方式我们之前已经讲解过了
使用DSL语句查询文档
ES通过json类型的请求体查询文档,方法如下:
GET /索引/_search
{"query":{搜索方式:搜索参数}
}
query后的json对象称为DSL语句,我们可以在接口方法上使用 @Query注解自定义DSL语句查询
@Query("{\n" +" \"match\": {\n" +" \"productDesc\": \"?0\"\n" +" }\n" +" }")List<Product> findByProductDescMatch(String keyword);@Query("{\n" +" \"match\": {\n" +" \"productDesc\": {\n" +" \"query\": \"?0\",\n" +" \"fuzziness\": 1\n" +" }\n" +" }\n" +" }")List<Product> findByProductDescFuzzy(String keyword);
按照规则命名方法进行查询
- 只需在Repository接口中按照SpringDataES的规则命名方法,该方法就能完成相应的查询。
- 规则:查询方法以findBy开头,涉及查询条件时,条件的属性用条件关键字连接。
| 关键字 | 命名规则 | 解释 | 示例 |
|---|---|---|---|
| and | findByField1AndField2 | 根据Field1和Field2 获得数据 | findByTitleAndContent |
| or | findByField1OrField2 根 | 据Field1或Field2 获得数据 | findByTitleOrContent |
| is | findByField | 根据Field获得数据 | findByTitle |
| not | findByFieldNot | 根据Field获得补集数据 | findByTitleNot |
| between | findByFieldBetween | 获得指定范围的数据 | findByPriceBetween |
List<Product> findByProductName(String productName);List<Product> findByProductNameOrProductDesc(String productName, String productDesc);List<Product> findByIdBetween(Integer startId, Integer endId);
3 分页查询

使用继承或自定义的方法时,在方法中添加Pageable类型的参数, 返回值为Page类型即可进行分页查询。
// 测试继承的方法:@Testpublic void testFindPage() {// 参数1:页数,参数2:每页条数Pageable pageable = PageRequest.of(1, 3);Page<Product> page = repository.findAll(pageable);System.out.println("总条数" + page.getTotalElements());System.out.println("总页数" + page.getTotalPages());System.out.println("数据" + page.getContent());}
// 自定义方法Page<Product> findByProductDesc(String productDesc, Pageable pageable);// 测试自定义方法@Testpublic void testFindPage2() {Pageable pageable = PageRequest.of(0, 2);Page<Product> page = repository.findByProductDesc("三体", pageable);System.out.println("总条数" + page.getTotalElements());System.out.println("总页数" + page.getTotalPages());System.out.println("数据" + page.getContent());}
4 结果排序

使用继承或自定义的方法时,在方法中添加Sort类型的参数即可进行结果排序。
// 结果排序@Testpublic void testFindSort() {Sort sort = Sort.by(Sort.Direction.DESC, "id");Iterable<Product> all = repository.findAll(sort);for (Product product : all) {System.out.println(product);}}// 测试分页加排序@Testpublic void testFindPage3() {Sort sort = Sort.by(Sort.Direction.DESC, "id");Pageable pageable = PageRequest.of(0, 2, sort);Page<Product> page = repository.findByProductDesc("三体", pageable);System.out.println("总条数" + page.getTotalElements());System.out.println("总页数" + page.getTotalPages());System.out.println("数据" + page.getContent());}
5 template工具类

SpringDataElasticsearch提供了一个工具类
ElasticsearchRestTemplate,我们使用该类对象也能对ES进行操作。
操作索引
@Autowiredprivate ElasticsearchRestTemplate template;// 新增索引@Testpublic void addIndex() {// 获得索引操作对象IndexOperations indexOperations = template.indexOps(Product.class);// 创建索引,注:该方法无法设置索引结构,不推荐使用indexOperations.create();}// 删除索引@Testpublic void delIndex() {// 获得索引操作对象IndexOperations indexOperations = template.indexOps(Product.class);// 删除索引indexOperations.delete();}
增删改文档
template操作文档的常用方法:
- save():新增/修改文档
- delete():删除文档
// 新增/修改文档@Testpublic void addDocument() {Product product = new Product(7, "es1", "es是一款优秀的搜索引擎");template.save(product);}// 删除文档@Testpublic void delDocument() {template.delete("7", Product.class);}
查询文档
template的search方法可以查询文档:
SearchHits<T> search(Query query, Class<T> clazz):查询文档,query是查询条件对象,clazz是结果
类型。
用法如下:
// 查询文档@Testpublic void searchDocument() {// 1.确定查询方式// MatchAllQueryBuilder builder = QueryBuilders.matchAllQuery();// TermQueryBuilder builder =QueryBuilders.termQuery("productDesc", "手机");MatchQueryBuilder builder =QueryBuilders.matchQuery("productDesc", "我喜欢看科幻小说");// 2.构建查询条件NativeSearchQuery query = newNativeSearchQueryBuilder().withQuery(builder).build();// 3.查询SearchHits<Product> result = template.search(query, Product.class);// 4.处理查询结果for (SearchHit<Product> productSearchHit : result) {Product product = productSearchHit.getContent();System.out.println(product);}}
复杂条件查询
@Testpublic void searchDocument2() {
// String productName ="三体";
// String productDesc = "小说";String productName = null;String productDesc = null;// 1.确定查询方式BoolQueryBuilder builder = QueryBuilders.boolQuery();// 如果没有传入参数,查询所有if (productName == null && productDesc == null) {MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();builder.must(matchAllQueryBuilder);} else {if (productName != null && productName.length() > 0) {MatchQueryBuilder queryBuilder1 =QueryBuilders.matchQuery("productName", productName);builder.must(queryBuilder1);}if (productDesc != null && productDesc.length() > 0) {MatchQueryBuilder queryBuilder2= QueryBuilders.matchQuery("productDesc", productDesc);builder.must(queryBuilder2);}}// 2.构建查询条件NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(builder).build();// 3.查询SearchHits<Product> result = template.search(query, Product.class);// 4.处理查询结果for (SearchHit<Product> productSearchHit : result) {Product product = productSearchHit.getContent();System.out.println(product);}}分页查询
// 分页查询文档@Testpublic void searchDocumentPage() {// 1.确定查询方式MatchAllQueryBuilder builder = QueryBuilders.matchAllQuery();// 2.构建查询条件// 分页条件Pageable pageable = PageRequest.of(0, 3);NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(builder).withPageable(pageable).build();// 3.查询SearchHits<Product> result = template.search(query, Product.class);// 4.将查询结果封装为Page对象List<Product> content = new ArrayList();for (SearchHit<Product> productSearchHit : result) {Product product = productSearchHit.getContent();content.add(product);}/*** 封装Page对象,参数1:具体数据,参数2:分页条件对象,参数3:总条数*/Page<Product> page = new PageImpl(content, pageable, result.getTotalHits());System.out.println(page.getTotalElements());System.out.println(page.getTotalPages());System.out.println(page.getContent());}
结果排序
@Testpublic void searchDocumentSort() {// 1.确定查询方式MatchAllQueryBuilder builder = QueryBuilders.matchAllQuery();// 2.构建查询条件// 排序条件SortBuilder sortBuilder = SortBuilders.fieldSort("id").order(SortOrder.DESC);NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(builder).withSorts(sortBuilder).build();// 3.查询SearchHits<Product> result = template.search(query, Product.class);// 4.处理查询结果for (SearchHit<Product> productSearchHit : result) {Product product = productSearchHit.getContent();System.out.println(product);}}八 Elasticsearch集群
1 概念

在单台ES服务器上,随着一个索引内数据的增多,会产生存储、效率、安全等问题。
- 假设项目中有一个500G大小的索引,但我们只有几台200G硬盘的服务器,此时是不可能将索引放入其中某一台服务器中的。

- 此时我们需要将索引拆分成多份,分别放入不同的服务器中,此时这几台服务器维护了同一个索引,我们称这几台服务器为一个集群,其中的每一台服务器为一个节点,每一台服务器中的数据称为一个分片。

- 此时如果某个节点故障,则会造成集群崩溃,所以每个节点的分片往往还会创建副本,存放在其他节点中,此时一个节点的崩溃就不会影响整个集群的正常运行。

节点(node):一个节点是集群中的一台服务器,是集群的一部分。它存储数据,参与集群的索引和搜索功能。集群中有一个为主节点,主节点通过ES内部选举产生。
集群(cluster):一组节点组织在一起称为一个集群,它们共同持有整个的数据,并一起提供索引和搜索功能。
分片(shards):ES可以把完整的索引分成多个分片,分别存储在不同的节点上。
副本(replicas):ES可以为每个分片创建副本,提高查询效率, 保证在分片数据丢失后的恢复。

注:
分片的数量只能在索引创建时指定,索引创建后不能再更改分片数量,但可以改变副本的数量。
为保证节点发生故障后集群的正常运行,ES不会将某个分片和它的副本存在同一台节点上。
2 搭建集群

安装第一个ES节点
- 安装
#解压:
tar -zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz#重命名:
mv elasticsearch-7.17.0 myes1#移动文件夹:
mv myes1 /usr/local/#安装ik分词器
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/myes1/plugins/analysis-ik#安装拼音分词器
unzip elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/myes1/plugins/analysis-pinyin#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes1
- 修改配置文件
#打开节点一配置文件:
vim /usr/local/myes1/config/elasticsearch.yml
配置如下信息:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node1
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9200
#集群间通信端口号
transport.tcp.port: 9300
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes: ["node1","node2","node3"]
- 启动
#切换为es用户:
su es
#后台启动第一个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes1/bin/elasticsearch -d
安装第二个ES节点
- 安装
#解压:
tar -zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz#重命名:
mv elasticsearch-7.17.0 myes2#移动文件夹:
mv myes2 /usr/local/#安装ik分词器
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/myes2/plugins/analysis-ik#安装拼音分词器
unzip elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/myes2/plugins/analysis-pinyin#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes2
- 修改配置文件
#打开节点二配置文件:
vim /usr/local/myes2/config/elasticsearch.yml
配置如下信息:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node2
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9201
#集群间通信端口号
transport.tcp.port: 9301
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes: ["node1","node2","node3"]
- 启动
#切换为es用户:
su es#后台启动第二个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes2/bin/elasticsearch -d
安装第三个ES节点
- 安装
#解压:
tar -zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz#重命名:
mv elasticsearch-7.17.0 myes3#移动文件夹:
mv myes3 /usr/local/#安装ik分词器
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/myes3/plugins/analysis-ik#安装拼音分词器
unzip elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/myes3/plugins/analysis-pinyin#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes3
- 修改配置文件
#打开节点三配置文件:
vim /usr/local/myes3/config/elasticsearch.yml
配置如下信息:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node3
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9202
#集群间通信端口号
transport.tcp.port: 9302
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes: ["node1","node2","node3"]
- 启动
#切换为es用户:
su es#后台启动第三个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes3/bin/elasticsearch -d
测试集群
访问 http://虚拟机IP:9200/_cat/nodes 查看是否集群搭建成功。
kibana连接es集群
- 在kibana中访问集群
# 打开kibana配置文件
vim /usr/local/kibana-7.17.0-linux-x86_64/config/kibana.yml
添加如下配置
# 该集群的所有节点
elasticsearch.hosts: ["http://虚拟机IP:9200","http://虚拟机IP:9201","http://虚拟机IP:9202"]
- 启动kibana
#切换为es用户:
su es#启动kibana:
/usr/local/kibana-7.17.0-linux-x86_64/bin/kibana
- 访问kibana: http://虚拟机IP:5601
3 测试集群状态
- 在集群中创建一个索引
PUT /product1
{"settings": {"number_of_shards": 5,// 分片数"number_of_replicas": 1// 每个分片的副本数},"mappings": {"properties": {"id": {"type": "integer","store": true,"index": true},"productName": {"type": "text","store": true,"index": true},"productDesc": {"type": "text","store": true,"index": true}}}
}
- 查看集群状态
# 查看集群健康状态
GET /_cat/health?v# 查看索引状态
GET /_cat/indices?v# 查看分片状态
GET /_cat/shards?v
4 故障应对&水平扩容
- 关闭一个节点,可以发现ES集群可以自动进行故障应对。
- 重新打开该节点,可以发现ES集群可以自动进行水平扩容。
- 分片数不能改变,但是可以改变每个分片的副本数:
PUT /索引/_settings
{"number_of_replicas": 副本数
}
九 Elasticsearch优化
1 磁盘选择
ES的优化即通过调整参数使得读写性能更快
磁盘通常是服务器的瓶颈。Elasticsearch重度使用磁盘,磁盘的效 率越高,Elasticsearch的执行效率就越高。这里有一些优化磁盘的技巧:
- 使用SSD(固态硬盘),它比机械磁盘优秀多了。
- 使用RAID0模式(将连续的数据分散到多个硬盘存储,这样可以并行进行IO操作),代价是一块硬盘发生故障就会引发系统故障。
- 不要使用远程挂载的存储。
2 内存设置
ES默认占用内存是4GB,我们可以修改config/jvm.option设置ES的 堆内存大小,Xms表示堆内存的初始大小,Xmx表示可分配的最大内存。
- Xmx和Xms的大小设置为相同的,可以减轻伸缩堆大小带来的压力。
- Xmx和Xms不要超过物理内存的50%,因为ES内部的Lucene也要占据一部分物理内存。
- Xmx和Xms不要超过32GB,由于Java语言的特性,堆内存超过32G会浪费大量系统资源,所以在内 存足够的情况下,最终我们都会采用设置为31G:
-Xms 31g
-Xmx 31g
例如:在一台128GB内存的机器中,我们可以创建两个节点,每个节点分配31GB内存。
3 分片策略
分片和副本数并不是越多越好。每个分片的底层都是一个Lucene索引,会消耗一定的系统资源。且搜索请求需要命中索引中的所有分片,分片数过多会降低搜索性能。索引的分片数需要架构师和技术人员对业务的增长有预先的判断,一般来说我们遵循以下原则:
- 每个分片占用的硬盘容量不超过ES的最大JVM的堆空间设置(一 般设置不超过32G)。比如:如果索引的总容量在500G左右, 那分片数量在16个左右即可。
- 分片数一般不超过节点数的3倍。比如:如果集群内有10个节点,则分片数不超过30个。
- 推迟分片分配:节点中断后集群会重新分配分片。但默认集群会等待一分钟来查看节点是否重新加入。我们可以设置等待的时长,减少重新分配的次数:
PUT /索引/_settings
{"settings":{"index.unassianed.node_left.delayed_timeout":"5m"}
}
- 减少副本数量:进行写入操作时,需要把写入的数据都同步到副本,副本越多写入的效率就越慢。我们进行大批量进行写入操作时可以先设置副本数为0,写入完成后再修改回正常的状态。
十 Elasticsearch案例
1 需求说明
接下来我们使用ES模仿百度搜索,即自动补全+搜索引擎效果:

2 ES自动补全
es为我们提供了关键词的自动补全功能:
GET /索引/_search
{"suggest": {"prefix_suggestion": {// 自定义推荐名"prefix": "elastic",// 被补全的关键字"completion": {"field": "productName",// 查询的域"skip_duplicates": true, //忽略重复结果"size": 10 //最多查询到的结果数}}}
}
注:自动补全对性能要求极高,ES不是通过倒排索引来实现的,所以需要将对应的查询字段类型设置为completion。
PUT /product2
{"mappings": {"properties": {"id": {"type": "integer","store": true,"index": true},"productName": {"type": "completion"},"productDesc": {"type": "text","store": true,"index": true}}}
}POST /product2/_doc
{"id":1,"productName":"elasticsearch1","productDesc":"elasticsearch1 is a good search engine"
}
POST /product2/_doc
{"id":2,"productName":"elasticsearch2","productDesc":"elasticsearch2 is a good search engine"
}
POST /product2/_doc
{"id":3,"productName":"elasticsearch3","productDesc":"elasticsearch3 is a good search engine"
}
测试自动补全功能:
GET /product2/_search
{"suggest": {"prefix_suggestion": {"prefix": "elastic","completion": {"field": "productName","skip_duplicates": true,"size": 10}}}
}
3 创建索引
PUT /news
{"settings": {"analysis": {"analyzer": {"ik_pinyin": {"tokenizer": "ik_smart","filter": "pinyin_filter"},"tag_pinyin": {"tokenizer": "keyword","filter": "pinyin_filter"}},"filter": {"pinyin_filter": {"type": "pinyin","keep_joined_full_pinyin": true,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"id": {"type": "integer","index": true},"title": {"type": "text","index": true,"analyzer": "ik_pinyin","search_analyzer": "ik_smart"},"content": {"type": "text","index": true,"analyzer": "ik_pinyin","search_analyzer": "ik_smart"},"url": {"type": "keyword","index": true},"tags": {"type": "completion","analyzer": "tag_pinyin","search_analyzer": "tag_pinyin"}}}
}
4 准备数据
将提前准备好的sql导入数据库:
/*
SQLyog Ultimate v12.09 (64 bit)
MySQL - 5.5.40-log : Database - news
*********************************************************************
*//*!40101 SET NAMES utf8 */;/*!40101 SET SQL_MODE=''*/;/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`news` /*!40100 DEFAULT CHARACTER SET utf8 */;USE `news`;/*Table structure for table `news` */DROP TABLE IF EXISTS `news`;CREATE TABLE `news` (`id` int(11) NOT NULL AUTO_INCREMENT,`title` varchar(255) NOT NULL,`url` varchar(255) DEFAULT NULL,`content` text,`tags` varchar(1000) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=92 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;/*Data for the table `news` */insert into `news`(`id`,`title`,`url`,`content`,`tags`) values (1,'略...','略...','略...','略...';/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;使用logstash工具可以将mysql数据同步到es中:
- 解压logstash-7.17.0-windows-x86_64.zip
logstash要和elastisearch版本一致
- 在解压路径下的/config中创建mysql.conf文件,文件写入以下脚本内容:
input {jdbc {jdbc_driver_library => "F:\001-after-end\笔记\14-全文检索与日志管理\Elasticsearch\软件\案例\mysql-connector-java-5.1.37-bin.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql:///news"jdbc_user => "root"jdbc_password => "123456"schedule => "* * * * *"jdbc_default_timezone => "Asia/Shanghai"statement => "SELECT * FROM news;"}
}filter {mutate {split => {"tags" => ","}}
}output {elasticsearch {hosts => ["192.168.66.113:9200"]index => "news"document_id => "%{id}"}
}- 在解压路径下打开cmd黑窗口,运行命令:
bin\logstash -f config\mysql.conf
注意:
logstash解压路径不能有中文;
mysql.conf的编码必须为utf-8;
配置es可以远程访问(参照第六章配置)。
- 测试自动补齐
GET /news/_search
{"suggest": {"my_suggest": {"prefix": "li","completion": {"field": "tags","skip_duplicates": true,"size": 10}}}
}
5 项目搭建
创建Springboot项目,加入SpringDataElasticsearch和SpringMVC 的起步依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency><dependency> <groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency>写配置文件:
spring:elasticsearch:uris: 192.168.66.113:9200logging:pattern:console: '%d{HH:mm:ss.SSS} %clr(%-5level) --- [%-15thread]%cyan(%-50logger{50}):%msg%n'
6 创建实体类
//索引已经提前创建好了,下面的实体类则不用添加那些和创建索引有关的属性了
@Document(indexName = "news")
@Data
public class News {@Id@Fieldprivate Integer id;@Fieldprivate String title;@Fieldprivate String content;@Fieldprivate String url;@CompletionField@Transientprivate Completion tags;
}7 创建Repository接口
public interface NewsRepository extends ElasticsearchRepository<News, Integer> {
}
8 自动补全功能
@Service
public class NewsService {@Autowiredprivate ElasticsearchRestTemplate template;// 自动补齐public List<String> autoSuggest(String keyword) {// 1.创建补全请求SuggestBuilder suggestBuilder = new SuggestBuilder();// 2.构建补全条件SuggestionBuilder suggestionBuilder = SuggestBuilders.completionSuggestion("tags").prefix(keyword).skipDuplicates(true).size(10);suggestBuilder.addSuggestion("prefix_suggestion", suggestionBuilder);// 3.发送请求SearchResponse response = template.suggest(suggestBuilder, IndexCoordinates.of("news"));// 4.处理结果List<String> result = response.getSuggest().getSuggestion("prefix_suggestion").getEntries().get(0).getOptions().stream().map(Suggest.Suggestion.Entry.Option::getText).map(Text::toString).collect(Collectors.toList());return result;}
}对应的原生es搜索为:
GET /news/_search
{"suggest": {"prefix_suggestion": {"prefix": "li","completion": {"field": "tags","skip_duplicates": true,"size": 10}}}
}
结果为:
{"took" : 33,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"suggest" : {"prefix_suggestion" : [{"text" : "li","offset" : 0,"length" : 2,"options" : [{"text" : "利哈伊谷","_index" : "news","_type" : "_doc","_id" : "18","_score" : 1.0,"_source" : {"@timestamp" : "2023-05-06T08:39:01.668Z","tags" : ["美国","美国黑五","利哈伊谷","购物中心","视频","脸书","保安","塞缪尔·萨法迪","海军陆战队","现役海军陆战队员","退役海军陆战队员","礼品店","礼品","打斗","安全人员","安全"],"content" : "海外网12月1日电 近日,一年一度的“黑色星期五”购物节拉开帷幕,热情的购物者涌向百货商店,都希望能买到打折商品。然而,美国各地也因此发生了几起暴力事件。美媒甚至感慨,“如果一年有一天会失去对人性的希望,那就是‘黑五’。”福克斯新闻网报道了本周内美国各个州因“黑五”引发的冲突事件,目击者拍下视频,画面在社交平台上疯传。当地时间11月29日晚上,在宾夕法尼亚州利哈伊谷购物中心的Forever 21商店外,发生了一场打斗事件。有网友将视频拍摄下来,略......","id" : 18,"url" : "https://news.sina.com.cn/w/2019-12-01/doc-iihnzhfz2885717.shtml","title" : """美国"黑五"冲突不断多地发生斗殴 有人鼻子被打断""","@version" : "1"}},.......略]}]}
}9 搜索关键字功能
在repository接口中添加高亮搜索关键字方法
// 高亮搜索关键字
@Highlight(fields = {@HighlightField(name = "title"), @HighlightField(name = "content")})
List<SearchHit<News>> findByTitleMatchesOrContentMatches(String title, String content);
service类中调用该方法
@AutowiredNewsRepository repository;// 查询关键字public List<News> highLightSearch(String keyword) {List<SearchHit<News>> result = repository.findByTitleMatchesOrContentMatches(keyword, keyword);// 处理结果,封装为News类型的集合List<News> newsList = new ArrayList();for (SearchHit<News> newsSearchHit : result) {News news = newsSearchHit.getContent();// 高亮字段Map<String, List<String>> highlightFields = newsSearchHit.getHighlightFields();if (highlightFields.get("title") != null) {news.setTitle(highlightFields.get("title").get(0));}if (highlightFields.get("content") != null) {news.setContent(highlightFields.get("content").get(0));}newsList.add(news);}return newsList;}
对应的原生es搜索为:
GET /news/_search
{"query": {"bool": {"should": [{"match": {"title": "江西"}},{"match": {"content": "江西"}}]}},"highlight": {"fields": [{"content": {"fragment_size": 20,"number_of_fragments": 5}},{"title": {"fragment_size": 20,"number_of_fragments": 5}}],"pre_tags": ["<em>"],"post_tags": ["</em>"]}
}
结果为:
{"took" : 15,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 11.891368,"hits" : [{"_index" : "news","_type" : "_doc","_id" : "91","_score" : 11.891368,"_source" : {"@timestamp" : "2023-05-06T08:39:01.686Z","tags" : ["江西九江","江西","九江","吴城","吴城水上公路","老鼠","江西暴雨","暴雨","鄱阳湖","洪水","长江","三峡"],"content" : "7月4日,江西九江,吴城水上公路因暴雨被洪水淹没,有一辆车在水中熄火动弹不了,一市民和她老公去现场救援时发现公路旁有个亭子,发现里面竟有七八十只老鼠在亭内躲避洪水,并表示第一次看到这么多老鼠。该市民称,每年雨季这条公路都会被淹没,在此呼吁广大市民,雨季行车注意安全。江西省继续发布洪水预警,鄱阳湖防洪对长江流域相当重要今日10时,江西省继续发布洪水红色预警,鄱阳湖水位超警戒3.60米,形势严峻。鄱阳湖是江西的“集水盆”,江西境内五大河流经,略......","id" : 91,"url" : "https://baijiahao.baidu.com/s?id=1672108752181366032&wfr=spider&for=pc","title" : """江西暴雨近百只老鼠凉亭内躲洪水:密密麻麻紧贴石墩江西暴雨近百只老鼠凉亭内躲洪水:密密麻麻紧贴石墩""","@version" : "1"},"highlight" : {"title" : ["<em>江西</em>暴雨近百只老鼠凉亭内躲洪水:密密麻麻紧贴石墩","<em>江西</em>暴雨近百只老鼠凉亭内躲洪水:密密麻麻紧贴石墩"],"content" : ["7月4日,<em>江西</em>九江,吴城水上公路因暴雨被洪水淹没","鄱阳湖是<em>江西</em>的“集水盆”,<em>江西</em>境内五大河流经鄱阳湖集纳后进入长江"]}},略......]}
}10 创建Controller类
@RestController
public class NewsController {@Autowiredprivate NewsService newsService;@GetMapping("/autoSuggest")public List<String> autoSuggest(String term) { // 前端使用jqueryUI,发送的参数默认名为termreturn newsService.autoSuggest(term);}@GetMapping("/highLightSearch")public List<News> highLightSearch(String term) {return newsService.highLightSearch(term);}
}
11 前端页面
我们使用jqueryUI中的autocomplete插件完成项目的前端实现
略。。。
相关文章:
18--Elasticsearch
一 Elasticsearch介绍 1 全文检索 Elasticsearch是一个全文检索服务器 全文检索是一种非结构化数据的搜索方式 结构化数据:指具有固定格式固定长度的数据,如数据库中的字段。 非结构化数据:指格式和长度不固定的数据,如电商网站…...

代码随想录算法训练营 day59|503.下一个更大元素II、42. 接雨水
一、503.下一个更大元素II 力扣题目链接 可以不扩充nums,在遍历的过程中模拟走两边nums class Solution { public:vector<int> nextGreaterElements(vector<int>& nums) {vector<int> result(nums.size(), -1);if (nums.size() 0) return…...

MyBatis数据库操作
文章目录 前言一、MyBatis的各种查询功能1.查询一个实体类对象2.查询一个List集合3.查询单个数据4.查询一条数据为map集合5.查询多条数据为map集合方法一方法二 6.测试类 二、特殊SQL的执行1.模糊查询2.批量删除3.动态设置表名5.添加功能获取自增的主键6.测试类 三、自定义映射…...

python flask框架 debug功能
从今天开始,准备整理一些基础知识,分享给需要的人吧 先整理个flask的debug功能,首先列举一下debug加与不加的区别,然后再上代码和图看看差异 区别: (1)加了debug后,修改js…...

《深入浅出OCR》第六章:OCR数据集与评价指标
一、OCR技术流程 在介绍OCR数据集开始,我将带领大家和回顾下OCR技术流程,典型的OCR技术pipline如下图所示,其中,文本检测和识别是OCR技术的两个重要核心技术。 1.1 图像预处理: 图像预处理是OCR流程的第一步…...
15. 线性代数 - 克拉默法则
文章目录 克拉默法则矩阵运算Hi,大家好。我是茶桁。 上节课我们在最后提到了一个概念「克拉默法则」,本节课,我们就来看看到底什么是克拉默法则。 克拉默法则 之前的课程我们一直在强调,矩阵是线性方程组抽象的来的。那么既然我们抽象出来了,有没有一种比较好的办法高效…...
【LeetCode】剑指 Offer <二刷>(6)
目录 题目:剑指 Offer 12. 矩阵中的路径 - 力扣(LeetCode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 13. 机器人的运动范围 - 力扣&#…...
jsp页面出现“String cannot be resolved to a type”错误解决办法
篇首语:小编为大家整理,主要介绍了jsp页面出现“String cannot be resolved to a type”错误解决办法相关的知识,希望对你有一定的参考价值。 jsp页面出现“String cannot be resolved to a type”错误解决办法 解决办法: 右键项目…...

【go-zero】使用自带Redis方法
yaml配置文件 RedisS:Host: Type: Pass: config增加 RedisS struct {Host stringType stringPass string}svc文件 type * struct {RedisClient *redis.Redis } func *(c config.Config) * {sqlConn : sqlx.NewMysql(c.DB.DataSource)return &*{RedisClient: redis.New(c…...
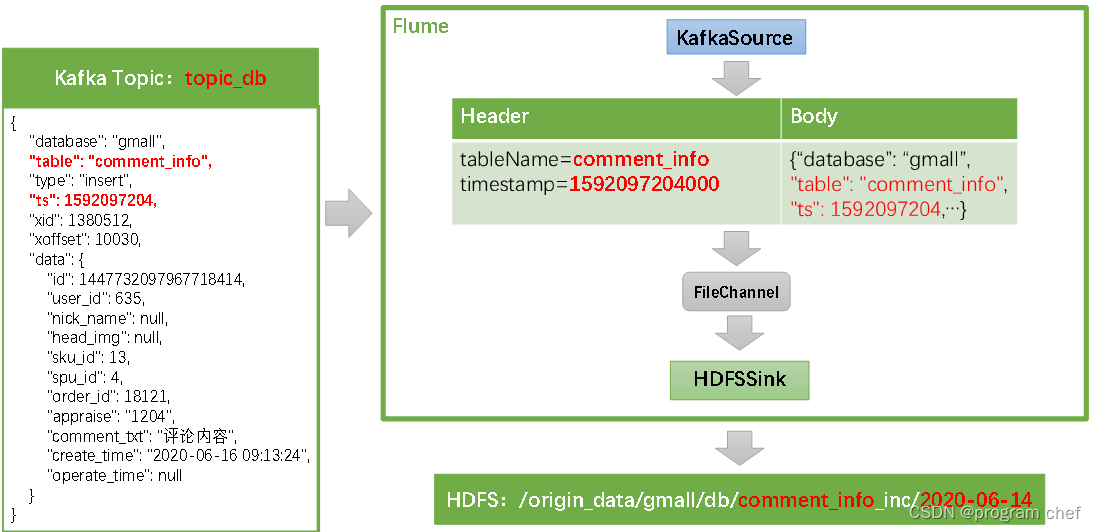
离线数仓同步数据3
业务数据_增量表数据同步 1)Flume配置概述2)Flume配置实操3)通道测试4)编写Flume启停脚本 1)Flume配置概述 Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSinkÿ…...
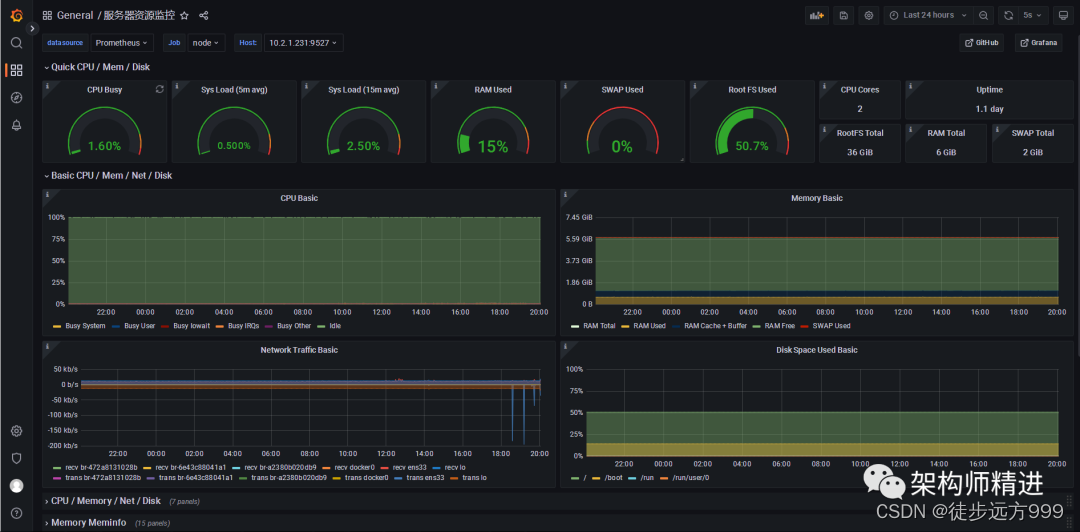
Prometheus+Grafana 搭建应用监控系统
一、背景 完善的监控系统可以提高应用的可用性和可靠性,在提供更优质服务的前提下,降低运维的投入和工作量,为用户带来更多的商业利益和客户体验。下面就带大家彻底搞懂监控系统,使用Prometheus Grafana搭建完整的应用监控系统。 …...

Spring Boot整合Log4j2.xml的问题
文章目录 问题解决参考 问题 Spring Boot整合Log4j2.xml的时候返回以下错误: Caused by: org.apache.logging.log4j.LoggingException: log4j-slf4j-impl cannot be present with log4j-to-slf4j 进行了解决。 解决 Spring Boot整合Log4j2.xml经过以下操作&#…...
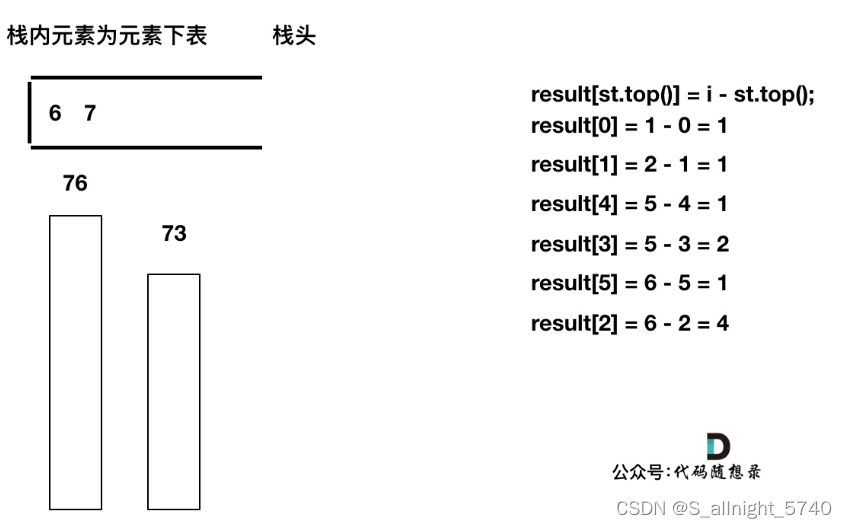
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I 739. 每日温度496.下一个更大元素 I 739. 每日温度 题目链接 视频讲解 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answe…...

【动手学深度学习】--文本预处理
文章目录 文本预处理1.读取数据集2.词元化3.词表4.整合所有功能 文本预处理 学习视频:文本预处理【动手学深度学习v2】 官方笔记:文本预处理 对于序列数据处理问题,在【序列模型】中评估了所需的统计工具和预测时面临的挑战,这…...

2023年最佳研发管理平台评选:哪家表现出色?
“研发管理平台哪家好?以下是一些知名的研发管理软件品牌:Zoho Projects、JIRA、Trello、Microsoft Teams、GitLab。’” 企业需要不断创新以保持竞争力。研发是企业创新的核心,而研发管理平台则为企业提供了一个有效的工具来支持和管理其研发…...

轻量容器引擎Docker基础使用
轻量容器引擎Docker Docker是什么 Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。 它基于 Google 公司推出的 Go 语言实现,项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,…...

questions
1.JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境 JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需…...
MojoTween:使用「Burst、Jobs、Collections、Mathematics」优化实现的Unity顶级「Tween动画引擎」
MojoTween是一个令人惊叹的Tween动画引擎,针对C#和Unity进行了高度优化,使用了Burst、Jobs、Collections、Mathematics等新技术编码。 MojoTween提供了一套完整的解决方案,将Tween动画应用于Unity Objects的各个方面,并可以通过E…...

Vue3响应式源码实现
Vue3响应式源码实现 初始化项目结构 vue-proxy ├── effect.js ├── effect.ts ├── index.html ├── index.js ├── package.json ├── reactive.js ├── reactive.ts └── webpack.config.jsreactive.ts import { track, trigger } from "./effect&q…...

【RapidAI】P1 中文文本切割程序
中文文本切割程序 基本信息代码解析相关包获取 yaml 关键文件类的构造函数切分语句部分特殊处理 PDF重点切分去除数组中空字符串再度切分后长度 附录附录一:完整代码附录二:可继续思考问题 基本信息 文件名: chinese_text_splitter.py 文件地…...

开箱即用:ANIMATEDIFF PRO预置镜像部署,快速开启AI视频创作
开箱即用:ANIMATEDIFF PRO预置镜像部署,快速开启AI视频创作 1. 为什么选择ANIMATEDIFF PRO镜像 如果你正在寻找一个能快速生成电影级AI视频的解决方案,ANIMATEDIFF PRO预置镜像可能是目前最省心的选择。这个基于AnimateDiff架构和Realistic…...

RexUniNLU新手入门指南:3步搞定智能家居、金融、医疗场景意图识别
RexUniNLU新手入门指南:3步搞定智能家居、金融、医疗场景意图识别 1. 认识RexUniNLU:零样本意图识别利器 RexUniNLU是一款基于Siamese-UIE架构的轻量级自然语言理解框架,它能让你无需准备标注数据,仅通过简单的标签定义就能完成…...

实战指南:如何用PyMC实现贝叶斯分位数回归解决业务预测难题
实战指南:如何用PyMC实现贝叶斯分位数回归解决业务预测难题 【免费下载链接】pymc Python 中的贝叶斯建模和概率编程。 项目地址: https://gitcode.com/GitHub_Trending/py/pymc 你是否曾面临这样的困境:使用传统线性回归预测客户流失率ÿ…...

CVPR 2025前瞻:计算机视觉三大技术革新与应用场景
1. 三维重建:从实验室走向真实世界 记得我第一次接触三维重建技术是在2015年,当时还在用传统的SFM(Structure from Motion)方法处理无人机航拍图像。十年后的今天,看着CVPR 2025上涌现的新技术,不得不感叹…...

Keil4 STC15浮点运算踩坑实录:如何避免数据类型转换导致的诡异错误
Keil4 STC15浮点运算避坑指南:从原理到实战的数据类型陷阱解析 在嵌入式开发领域,STC15系列单片机凭借其优异的性价比和丰富的功能接口,成为许多中小型项目的首选。然而当开发者使用Keil4这一经典但略显陈旧的开发环境时,常常会遇…...

解决数字记忆碎片化的创新方案:GetQzonehistory让社交数据成为可触摸的时光胶囊
解决数字记忆碎片化的创新方案:GetQzonehistory让社交数据成为可触摸的时光胶囊 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 副标题:重构QQ空间回忆的3大突破…...

QuickRecorder:革新性macOS轻量化录屏解决方案
QuickRecorder:革新性macOS轻量化录屏解决方案 【免费下载链接】QuickRecorder A lightweight screen recorder based on ScreenCapture Kit for macOS / 基于 ScreenCapture Kit 的轻量化多功能 macOS 录屏工具 项目地址: https://gitcode.com/GitHub_Trending/q…...
ROS1驱动融合与rviz点云同屏可视化)
Bunker_mini_dev实战:多雷达(AVIA MID360)ROS1驱动融合与rviz点云同屏可视化
1. 多雷达ROS1驱动融合实战背景 最近在Bunker_mini_dev机器人开发平台上折腾多激光雷达融合,发现不少开发者对Livox AVIA和MID360这两款雷达的ROS1驱动配置存在困惑。我自己踩过不少坑,今天就把从驱动安装到rviz同屏显示的全流程梳理一遍。这种配置在自动…...

Phi-3 Forest Lab实战案例:用128K上下文处理整本API文档并生成测试用例
Phi-3 Forest Lab实战案例:用128K上下文处理整本API文档并生成测试用例 1. 项目背景与价值 在现代软件开发中,API文档的处理和测试用例生成是两项耗时且容易出错的工作。传统方法需要工程师手动阅读大量文档并编写测试代码,效率低下且难以保…...

零配置部署Wan2.2-I2V-A14B:RTX4090D优化镜像实战,快速生成高质量视频
零配置部署Wan2.2-I2V-A14B:RTX4090D优化镜像实战,快速生成高质量视频 1. 开箱即用的视频生成解决方案 想象一下,你只需要一条简单的文本描述,就能在几分钟内生成一段高清视频——夕阳下的海浪拍打着沙滩,海鸥在低空…...