【动手学深度学习】--文本预处理
文章目录
- 文本预处理
- 1.读取数据集
- 2.词元化
- 3.词表
- 4.整合所有功能
文本预处理
学习视频:文本预处理【动手学深度学习v2】
官方笔记:文本预处理
对于序列数据处理问题,在【序列模型】中评估了所需的统计工具和预测时面临的挑战,这样的数据存在许多种形式,文本是最常见例子之一,例如,一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 本节中,我们将解析文本的常见预处理步骤。 这些步骤通常包括:
1.将文本作为字符串加载到内存中
2.将字符串拆分为词元(如单词和字符)
3.建立一个词表,将拆分的词元映射到数字索引
4.将文本转换为数字索引序列,方便模型操作
1.读取数据集
import collections
import re
from d2l import torch as d2l
首先,从时光机器中加载文本,这是一个相当小的语料库,只有30000多个单词,但足够我们小试牛刀, 而现实中的文档集合可能会包含数十亿个单词。 下面的函数将数据集读取到由多条文本行组成的列表中,其中每条文本行都是一个字符串。 为简单起见,我们在这里忽略了标点符号和字母大写。
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')def read_time_machine(): #@save"""将时间机器数据集加载到文本行的列表中"""with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])

2.词元化
下面的tokenize函数将文本行列表(lines)作为输入, 列表中的每个元素是一个文本序列(如一条文本行)。 每个文本序列又被拆分成一个词元列表,词元(token)是文本的基本单位。 最后,返回一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
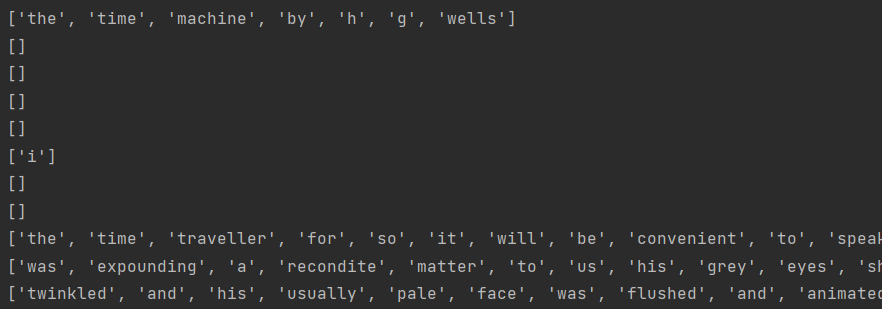
def tokenize(lines, token='word'): #@save"""将文本行拆分为单词或字符词元"""if token == 'word':return [line.split() for line in lines]elif token == 'char':return [list(line) for line in lines]else:print('错误:未知词元类型:' + token)tokens = tokenize(lines)
for i in range(11):print(tokens[i])
3.词表
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。 现在,让我们构建一个字典,通常也叫做词表(vocabulary), 用来将字符串类型的词元映射到从0开始的数字索引中。 我们先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus)。 然后根据每个唯一词元的出现频率,为其分配一个数字索引。 很少出现的词元通常被移除,这可以降低复杂性。 另外,语料库中不存在或已删除的任何词元都将映射到一个特定的未知词元“<unk>”。 我们可以选择增加一个列表,用于保存那些被保留的词元, 例如:填充词元(“<pad>”); 序列开始词元(“<bos>”); 序列结束词元(“<eos>”)。
class Vocab: #@save"""文本词表"""def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):if tokens is None:tokens = []if reserved_tokens is None:reserved_tokens = []# 按出现频率排序counter = count_corpus(tokens)self._token_freqs = sorted(counter.items(), key=lambda x: x[1],reverse=True)# 未知词元的索引为0self.idx_to_token = ['<unk>'] + reserved_tokensself.token_to_idx = {token: idxfor idx, token in enumerate(self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:breakif token not in self.token_to_idx:self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1def __len__(self):return len(self.idx_to_token)def __getitem__(self, tokens):if not isinstance(tokens, (list, tuple)):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):if not isinstance(indices, (list, tuple)):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices]@propertydef unk(self): # 未知词元的索引为0return 0@propertydef token_freqs(self):return self._token_freqsdef count_corpus(tokens): #@save"""统计词元的频率"""# 这里的tokens是1D列表或2D列表if len(tokens) == 0 or isinstance(tokens[0], list):# 将词元列表展平成一个列表tokens = [token for line in tokens for token in line]return collections.Counter(tokens)
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])for i in [0, 10]:print('文本:', tokens[i])print('索引:', vocab[tokens[i]])

4.整合所有功能
在使用上述函数时,我们将所有功能打包到load_corpus_time_machine函数中, 该函数返回corpus(词元索引列表)和vocab(时光机器语料库的词表)。 我们在这里所做的改变是:
- 为了简化后面章节中的训练,我们使用字符(而不是单词)实现文本词元化;
- 时光机器数据集中的每个文本行不一定是一个句子或一个段落,还可能是一个单词,因此返回的
corpus仅处理为单个列表,而不是使用多词元列表构成的一个列表。
def load_corpus_time_machine(max_tokens=-1): #@save"""返回时光机器数据集的词元索引列表和词表"""lines = read_time_machine()tokens = tokenize(lines, 'char')vocab = Vocab(tokens)# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,# 所以将所有文本行展平到一个列表中corpus = [vocab[token] for line in tokens for token in line]if max_tokens > 0:corpus = corpus[:max_tokens]return corpus, vocabcorpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)
相关文章:
【动手学深度学习】--文本预处理
文章目录 文本预处理1.读取数据集2.词元化3.词表4.整合所有功能 文本预处理 学习视频:文本预处理【动手学深度学习v2】 官方笔记:文本预处理 对于序列数据处理问题,在【序列模型】中评估了所需的统计工具和预测时面临的挑战,这…...

2023年最佳研发管理平台评选:哪家表现出色?
“研发管理平台哪家好?以下是一些知名的研发管理软件品牌:Zoho Projects、JIRA、Trello、Microsoft Teams、GitLab。’” 企业需要不断创新以保持竞争力。研发是企业创新的核心,而研发管理平台则为企业提供了一个有效的工具来支持和管理其研发…...

轻量容器引擎Docker基础使用
轻量容器引擎Docker Docker是什么 Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。 它基于 Google 公司推出的 Go 语言实现,项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,…...

questions
1.JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境 JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需…...
MojoTween:使用「Burst、Jobs、Collections、Mathematics」优化实现的Unity顶级「Tween动画引擎」
MojoTween是一个令人惊叹的Tween动画引擎,针对C#和Unity进行了高度优化,使用了Burst、Jobs、Collections、Mathematics等新技术编码。 MojoTween提供了一套完整的解决方案,将Tween动画应用于Unity Objects的各个方面,并可以通过E…...

Vue3响应式源码实现
Vue3响应式源码实现 初始化项目结构 vue-proxy ├── effect.js ├── effect.ts ├── index.html ├── index.js ├── package.json ├── reactive.js ├── reactive.ts └── webpack.config.jsreactive.ts import { track, trigger } from "./effect&q…...

【RapidAI】P1 中文文本切割程序
中文文本切割程序 基本信息代码解析相关包获取 yaml 关键文件类的构造函数切分语句部分特殊处理 PDF重点切分去除数组中空字符串再度切分后长度 附录附录一:完整代码附录二:可继续思考问题 基本信息 文件名: chinese_text_splitter.py 文件地…...

4、QT中的网络编程
一、Linux中的网络编程 1、子网和公网的概念 子网网络:局域网,只能进行内网的通信公网网络:因特网,服务器等可以进行远程的通信 2、网络分层模型 4层模型:应用层、传输层、网络层、物理层 应用层:用户自…...
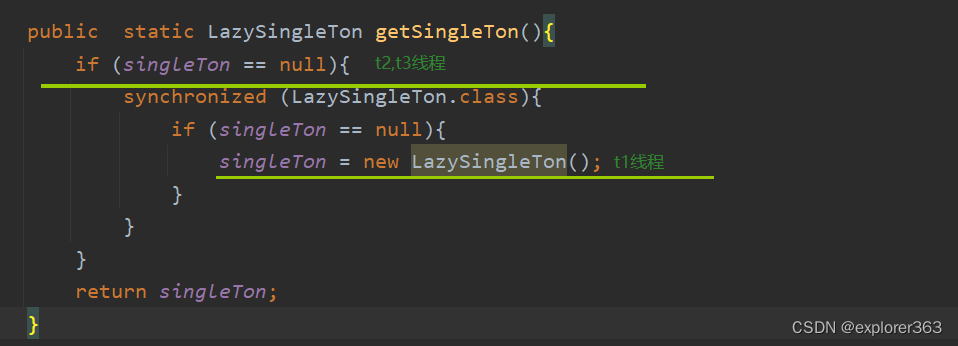
单例模式(饿汉式单例 VS 懒汉式单例)
所谓的单例模式就是保证某个类在程序中只有一个对象 一、如何控制只产生一个对象? 1.构造方法私有化(保证对象的产生个数) 创建类的对象,要通过构造方法产生对象 构造方法若是public权限,对于类的外部,可…...

Oracle数据库连接之TNS-12541异常
在进行数据库开发的时候,通常需要使用PLSQL Developer开发工具连接Oralce数据库,在进行连接时,经常性的会提示TNS-12541:TNS:no listener(没有监听),从而导致PLSQL Developer 无法连接到数据库实例…...
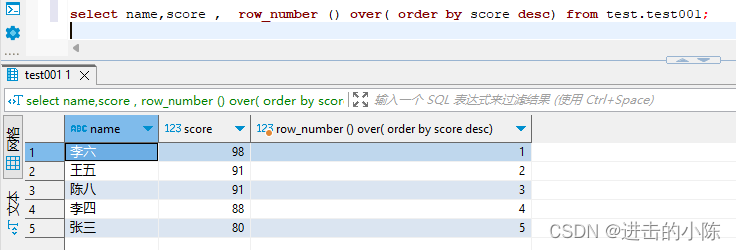
sql中的排序函数dense_rank(),RANK()和row_number()
dense_rank(),RANK()和row_number()是SQL中的排序函数。 为方便后面的函数差异比对清晰直观,准备数据表如下: 1.dense_rank() 函数语法:dense_rank() over( order by 列名 【desc/asc】) DENSE_RANK()是连续排序,比如…...

Flask狼书笔记 | 05_数据库
文章目录 5 数据库5.1 数据库的分类5.2 ORM5.3 使用Flask_SQLAlchemy5.4 数据库操作5.5 定义关系5.6 更新数据库表5.7 数据库进阶小结 5 数据库 这一章学习如何在Python中使用DBMS(数据库管理系统),来对数据库进行管理和操作。本书使用SQLit…...

HJ70 矩阵乘法计算量估算
Powered by:NEFU AB-IN Link 文章目录 HJ70 矩阵乘法计算量估算题意思路代码 HJ70 矩阵乘法计算量估算 题意 矩阵乘法的运算量与矩阵乘法的顺序强相关。 例如: A是一个5010的矩阵,B是1020的矩阵,C是205的矩阵 计算ABC有两种顺序:…...

Doris数据库使用记录
新建表 create table tonly_attendance(vin varchar(64),diggings_name varchar(256),area varchar(64),diggings_type varchar(256),work_time decimal(20,2),engine_run_time decimal(20,2),upload_time varchar(64))DUPLICATE KEY (vin)distributed by hash (vin)删除之…...

华为OD机试真题【篮球比赛】
1、题目描述 【篮球比赛】 一个有N个选手参加比赛,选手编号为1~N(3<N<100),有M(3<M<10)个评委对选手进行打分。 打分规则为每个评委对选手打分,最高分10分,最低分1分。…...
sublime text 格式化json快捷键配置
以 controlcommandj 为例。 打开Sublime Text,依次点击左上角菜单Sublime Text->Preferences->Key Bindings,出现以下文件: 左边的是Sublime Text默认的快捷键,不可编辑。右边是我们自定义快捷键的地方,在中括号…...

Spring Cloud 面试题总结
Spring Cloud和各子项目版本对应关系 Spring Cloud 是一个用于构建分布式系统的开发工具包,它基于Spring Boot提供了一组模块和功能,用于构建微服务架构中的分布式应用程序。Spring Cloud的不同子项目有各自的版本,下面是一些常见的Spring C…...

如何实现24/7客户服务自动化?
传统的客服制胜与否的法宝在于人,互联网时代,对于产品线广的大型企业来说:单靠人力,成本大且效率低,相对于产品相对单一的中小型企业来说:建设传统客服系统的成本难以承受,企业客户服务的转型已…...

2022年12月 C/C++(六级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:区间合并 给定 n 个闭区间 [ai; bi],其中i=1,2,…,n。任意两个相邻或相交的闭区间可以合并为一个闭区间。例如,[1;2] 和 [2;3] 可以合并为 [1;3],[1;3] 和 [2;4] 可以合并为 [1;4],但是[1;2] 和 [3;4] 不可以合并。 我们的任务是…...

【Spring Cloud系列】 雪花算法原理及实现
【Spring Cloud系列】 雪花算法原理及实现 文章目录 【Spring Cloud系列】 雪花算法原理及实现一、概述二、生成ID规则部分硬性要求三、ID号生成系统可用性要求四、解决分布式ID通用方案4.1 UUID4.2 数据库自增主键4.3 基于Redis生成全局id策略 五、SnowFlake(雪花算…...
彻底解放Windows 11任务栏:TranslucentTB透明化完全指南
彻底解放Windows 11任务栏:TranslucentTB透明化完全指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Windows…...

汽车存储技术演进:从边缘计算到车规级设计的核心挑战与选型指南
1. 汽车存储需求变迁:从机械心脏到数字大脑二十年前,我们选车看的是发动机的轰鸣、变速箱的平顺和底盘的扎实。如今,走进4S店,销售顾问会先带你坐进驾驶舱,点亮那块巨大的中控屏,演示语音助手、在线导航、高…...
:API调用失败率<0.8%的私有化部署方案首次公开)
Sora 2国内可用性深度测评(2024Q2最新版):API调用失败率<0.8%的私有化部署方案首次公开
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Sora 2视频生成怎么用 Sora 2 并非 OpenAI 官方发布的模型——截至目前(2024年中),OpenAI 仅公开了 Sora(初代)的演示能力࿰…...

IV测试仪选购避坑指南,这几点一定要提前了解
在光伏产业链中,IV测试仪应用广泛,覆盖组件分选、实验室检定、电站验收、运维排查等场景。市面上仪器品类繁杂,包含台式实验室款、生产线分选款、户外检测款,价格差距悬殊。不少采购人员不懂场景适配,盲目比价、堆砌参…...

Shell脚本工程化:great.sh框架解决运维脚本可维护性难题
1. 项目概述:一个被低估的Shell脚本构建框架如果你和我一样,常年混迹在运维、DevOps或者后端开发领域,那么对Shell脚本的感情一定是复杂的。一方面,它是我们最趁手的“瑞士军刀”,从服务器初始化、日志分析到自动化部署…...

React Native Expo样板项目:集成导航、状态管理与样式的最佳实践
1. 项目概述:一个为React Native开发者准备的“开箱即用”脚手架 如果你是一名React Native开发者,或者正打算踏入这个领域,那么你一定对项目启动初期那些繁琐的配置工作深有体会。从搭建开发环境、配置路由、集成状态管理,到设置…...

如何高效配置ClickHouse连接器:专业用户的完整指南
如何高效配置ClickHouse连接器:专业用户的完整指南 【免费下载链接】clickhouse-odbc ODBC driver for ClickHouse 项目地址: https://gitcode.com/gh_mirrors/cl/clickhouse-odbc ClickHouse ODBC驱动是连接ClickHouse数据库与各类数据分析工具的关键桥梁&a…...

GitHub企业版MCP服务器:为AI助手集成私有化GitHub工作流
1. 项目概述:一个为开发者定制的GitHub企业版MCP服务器如果你是一名重度依赖GitHub Enterprise进行团队协作的开发者,并且正在探索如何将AI助手(比如Claude、Cursor等)无缝集成到你的日常开发工作流中,那么你很可能已经…...

专业级macOS歌词同步方案:LyricsX核心功能深度解析
专业级macOS歌词同步方案:LyricsX核心功能深度解析 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的专业级歌词同步工具,通过智能歌词…...

网络安全入门:2026年转行网络安全完整路径图
网络安全入门:2026 年转行网络安全完整路径图 导语:2026 年,网络安全人才缺口达 150 万,平均薪资较传统 IT 岗位高出 30%。但 70% 的转行者因路径不清晰而失败。本文详解 2026 年转行网络安全的完整路径:学习路线、证…...