Prometheus+Grafana 搭建应用监控系统
一、背景
完善的监控系统可以提高应用的可用性和可靠性,在提供更优质服务的前提下,降低运维的投入和工作量,为用户带来更多的商业利益和客户体验。下面就带大家彻底搞懂监控系统,使用Prometheus +Grafana搭建完整的应用监控系统。
二、监控系统简介
1.1 什么是监控系统?
监控系统顾名思义就是监控服务器、应用系统以及其他第三方组件运行状态的系统。对于平台系统而言,监控系统就是我们第三只眼,监控系统会实时跟踪应用平台的运行状态,如果有应用系统出现问题或是服务器内存爆满,我们通过监控系统就可以快速定位问题所在,甚至可以设置预警,对一些将要出现的问题进行提前预防处理,及时避免问题的发生。
1.2 监控系统的作用
监控是运维系统的基础,我们衡量一个公司/部门的运维水平,看他们的监控系统就可以了。监控系统的作用不言而喻,能帮我们快速定位问题,减少故障,容量规划,性能优化等。
1)定位故障:在发生故障时,我们可以通过查看监控系统的各项指标数据,辅助故障分析和定位。
2)减少故障率:对于即将可能产生的故障能够及时发出预警信息,做好提前预防处理。
3)容量规划:为服务器、中间件以及应用集群的容量规划提供数据支撑。
4)性能调优:JVM垃圾回收次数、接口响应时间、慢SQL等等都可以监控优化。
总而言之,一个完善的监控系统可以提高应用的可用性和可靠性,在提供更优质服务的前提下,降低运维的投入和工作量,为用户带来更多的商业利益和客户体验。
1.3 常见的监控对象和指标都有哪些?
应用系统的监控主要分为指标监控和日志监控两大部分:
(1)指标监控主要是对一定时间段内性能指标进行测量,然后再通过时间序列的方式,进行处理、存储和告警。
(2)日志监控则可以提供更详细的上下文信息,通常通过 ELK 技术栈来进行收集、索引和图形化展示。
指标监控可以说是系统监控最核心的功能。主要有服务器资源、应用监控、数据库中间件等。
- 服务器资源监控:CPU使用率、内存使用率、磁盘使用率、磁盘读写的吞吐量、网络出入流量等等。
- 数据库监控:TPS、QPS、数据库连接数、慢SQL、InnoDB缓冲池命中率等。
- Redis监控:内存使用率、缓存命中率、key值总数、Redis响应请求时间、客户端连接数、持久性指标等。
- MQ消息监控:连接数、队列数、生产速率、消费速率、消息堆积量等等。
- 应用监控:包括HTTP请求,JVM,线程池等。
日志监控则更能清楚的记录系统运行时的详细状态,虽然指标监控,可以帮助迅速定位发生瓶颈的位置,不过只有指标的话往往还不够。比如,同样的一个接口,当请求传入的参数不同时,就可能会导致完全不同的性能问题。所以,除了指标外,我们还需要对这些指标的上下文信息进行监控,而日志正是这些上下文的最佳来源。
1.4 监控系统的架构
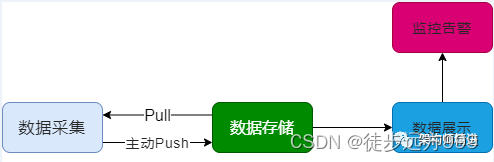
一个完整的监控系统通常由数据采集、数据传输、数据存储、数据展示、监控告警等多个模块组成。
- 数据采集,采集的方式有很多种,包括日志埋点进行采集,JMX标准接口输出监控指标,被监控对象提供REST API进行数据采集(如Hadoop、ES),系统命令行,统一的SDK进行侵入式的埋点和上报等。
- 数据传输,将采集的数据以TCP、UDP或者HTTP协议的形式上报给监控系统,有主动Push模式,也有被动Pull模式。
- 数据存储,有使用MySQL、Oracle等关系数据库存储的,也有使用时序数据库RRDTool、OpentTSDB、InfluxDB存储的,还有使用HBase存储的。
- 数据展示,数据指标的图形化展示。
- 监控告警,灵活的告警设置,以及支持邮件、短信、IM等多种通知通道。
三、当前流行的监控系统
目前大部分厂商都采用自研或是基于开源组件的方式搭建自己的监控平台。当然也有很多非常流行的开源监控系统,其中,最流行的莫过于Zabbix和Prometheus。下面就对这两个监控系统进行介绍,同时总结下各自的优劣势。
2.1 Zabbix
Zabbix 1998年诞生,核心组件采用C语言开发,Web端采用PHP开发。它属于老牌监控系统中的优秀代表,功能全面,使用广泛,是最优秀的监控解决方案之一。
2.1.1 Zabbix的优势
产品成熟:由于诞生时间长且使用广泛,拥有丰富的文档资料以及各种开源的数据采集插件,能覆盖绝大部分监控场景。
采集方式丰富:支持Agent、SNMP、JMX、SSH等多种采集方式,以及主动和被动的数据传输方式。
2.1.2 Zabbix的劣势
Zabbix需要在被监控主机上安装Agent,所有的数据都存在数据库里,产生的数据很大,瓶颈主要在数据库。
2.2 Prometheus
随着微服务架构和容器的兴起,Zabbix对容器监控显得力不从心。为解决监控容器的问题 Prometheus 应运而生。
Prometheus 是一套开源的系统监控报警框架,采用Go语言开发。得益于Google与k8s的强力支持,自带云原生的光环,天然能够友好协作,使得Prometheus 在开源社区异常火爆。
2.2.1 Prometheus优点
(1)提供多维度数据模型和灵活的查询方式
通过将监控指标关联多个 tag,来将监控数据进行任意维度的组合,并且提供简单的 PromQL 查询方式,还提供 HTTP 查询接口,可以很方便地结合 Grafana 等 GUI 组件展示数据。
(2)基于时序数据库,支持服务器节点的本地存储
通过 Prometheus 自带的时序数据库,可以完成每秒千万级的数据存储;不仅如此,在保存大量历史数据的场景中,Prometheus 可以对接第三方时序数据库和 OpenTSDB 等。
(3)定义了开放指标数据标准
以基于 HTTP 的 Pull 方式采集时序数据,只有实现了Prometheus监控数据才可以被 Prometheus 采集、汇总、并支持 Push 方式向中间网关推送时序列数据,能更加灵活地应对多种监控场景。
(4)支持通过静态文件配置和动态发现机制发现监控对象
自动完成数据采集。Prometheus 目前已经支持 Kubernetes、etcd、Consul 等多种服务发现机制。
(5)易于维护
可以通过二进制文件直接启动,并且提供了容器化部署镜像。
(6)集群支持
支持数据的分区采样和集群部署,支持大规模集群监控。
2.2.2 Prometheus缺点
Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。
由于Prometheus采用的是Pull模型拉取数据,意味着所有被监控的endpoint必须是可达的,需要合理规划网络的安全配置。
指标众多,需进行适当裁剪。
2.3 综合对比
下表通过多维度展现了各自监控系统的优缺点:
综合来看,Zabbix 的成熟度更高,上手更快,但灵活性较差。而且,监控数据的复杂度增加后,Zabbix 做进一步定制难度很高,即使做好了定制,也没法利用之前收集到的数据了(关系型数据库造成的问题)。
Prometheus 基本上是正相反,上手难度大一些,但由于定制灵活度高,数据也有更多的聚合可能,起步后的使用难度远小于 Zabbix。
如果监控的是物理机,用 Zabbix 没毛病,Zabbix 在传统监控系统中,尤其是在服务器相关监控方面,占据绝对优势;但如果是云环境的话,除非是 Zabbix 玩的非常溜,可以做各种定制,否则还是 Prometheus 吧,毕竟人家就是干这个的。
Prometheus 号称下一代监控系统,已经成为主导及容器监控方面的标配,并且在未来可见的时间内被广泛应用。
四、使用Prometheus+grafana搭建监控系统
4.1 下载
Prometheus需要下载prometheus(Prometheus主服务)、node_exporter(服务器监控)、mysqld_exporter(Mysql数据库监控-可选)、pushgateway(数据网关-可选)、alertmanager(告警组件-可选)
下载地址:https://prometheus.io/download/
Grafana为数据展示界面,下载地址:https://grafana.com/grafana/download
4.2 架构图
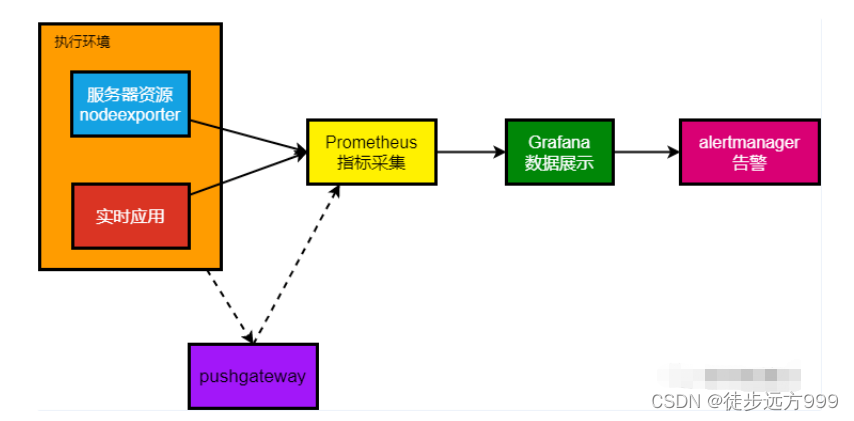
4.3 安装 Prometheus Server
Prometheus 的架构设计中,Prometheus Server 主要负责数据的收集,存储并且对外提供数据查询支持。下面开始安装Prometheus Server。
step1:首先,下载prometheus,并上传到服务器
解压到/usr/local/prometheus目录下:tar -zxvf prometheus-2.37.0.linux-amd64.tar.gz -C /usr/local/prometheus# 修改目录名:cd /usr/local/prometheusmv prometheus-2.37.0.linux-amd64 prometheus-2.37.0
setp2:启动prometheus Server 服务。prometheus启动非常简单,只需要一个命令即可,进入到/usr/local/prometheus/prometheus-2.37.0后执行如下命令:
#进入prometheus目录cd /usr/local/prometheus/prometheus-2.37.0#执行启动脚本./prometheus --web.enable-admin-api --config.file=prometheus.yml
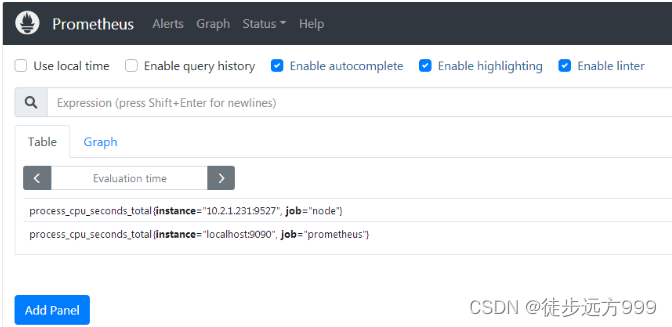
step3:验证prometheus是否启动成功,prometheus默认端口为:9090,我们在浏览器中输入:http://10.2.1.231:9090/graph,进入prometheus数据展示页面,说明prometheus启动成功。
4.4 安装 Node Exporter
实际的监控样本数据的由 Exporter 负责收集,如node_exporter 就是负责服务器的资源信息,同时提供了对外访问的HTTP服务地址(通常是/metrics)给prometheus拉取监控样本数据。下面开始安装node_exporter。
step1:首先,下载node_exporter,并上传到服务器
# 解压到/usr/local/prometheus目录下:tar -zxvf node_exporter-1.3.1.linux-amd64.tar.gz -C /usr/local/prometheus# 修改目录名:cd /usr/local/prometheusmv node_exporter-1.3.1.linux-amd64 node_exporter-1.3.1
step2:启动node_exporler,输入如下命令启动:
#node_exportercd /usr/local/prometheus/node_exporter-1.3.1#执行启动命令,指定数据访问的url./node_exporter --web.listen-address 10.2.1.231:9527
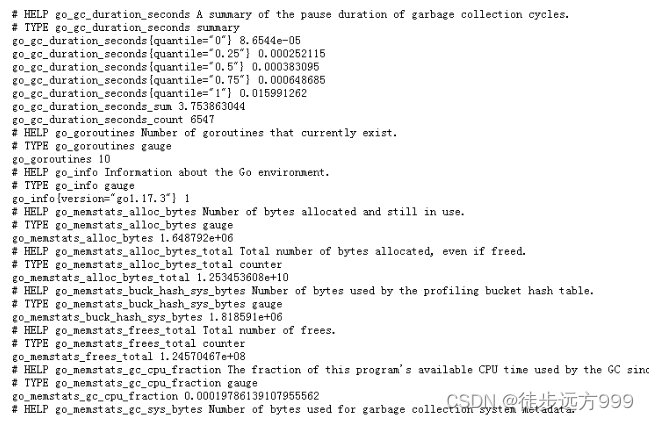
step3:验证node_exporler是否启动成功,我们在浏览器中输入上面指定的地址:http://10.2.1.231:9527/metrics,可以看到当前 node_exporter 获取到的当前主机的所有监控数据。说明node_exporler启动成功。
step4:最后,配置prometheus,将新增加的node配置到prometheus。
修改prometheus-2.37.0 文件夹下的prometheus.yml文件。增加新的node配置,具体配置如下:
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] # 采集node exporter监控数据 - job_name: 'node' static_configs: - targets: ['10.2.1.231:9527']
修改完prometheus.yml 文件后,重新启动prometheus。再次访问prometheus数据展示页面,选择status | target,可以看到新的node已经添加进来了。
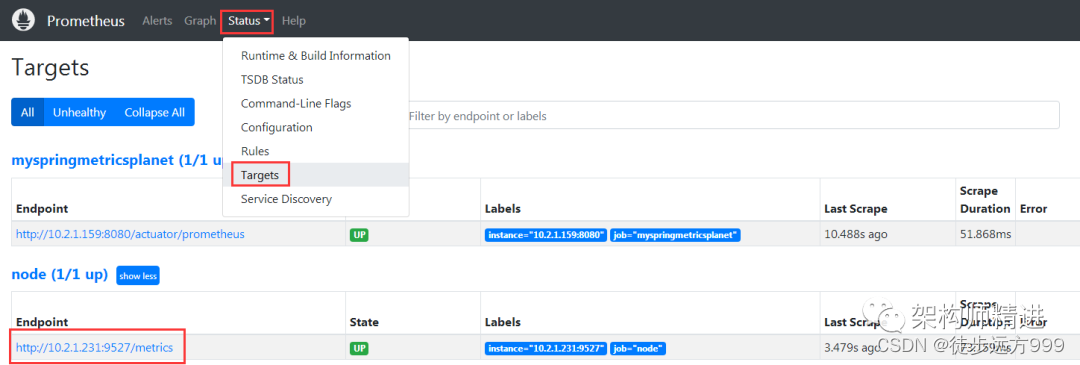
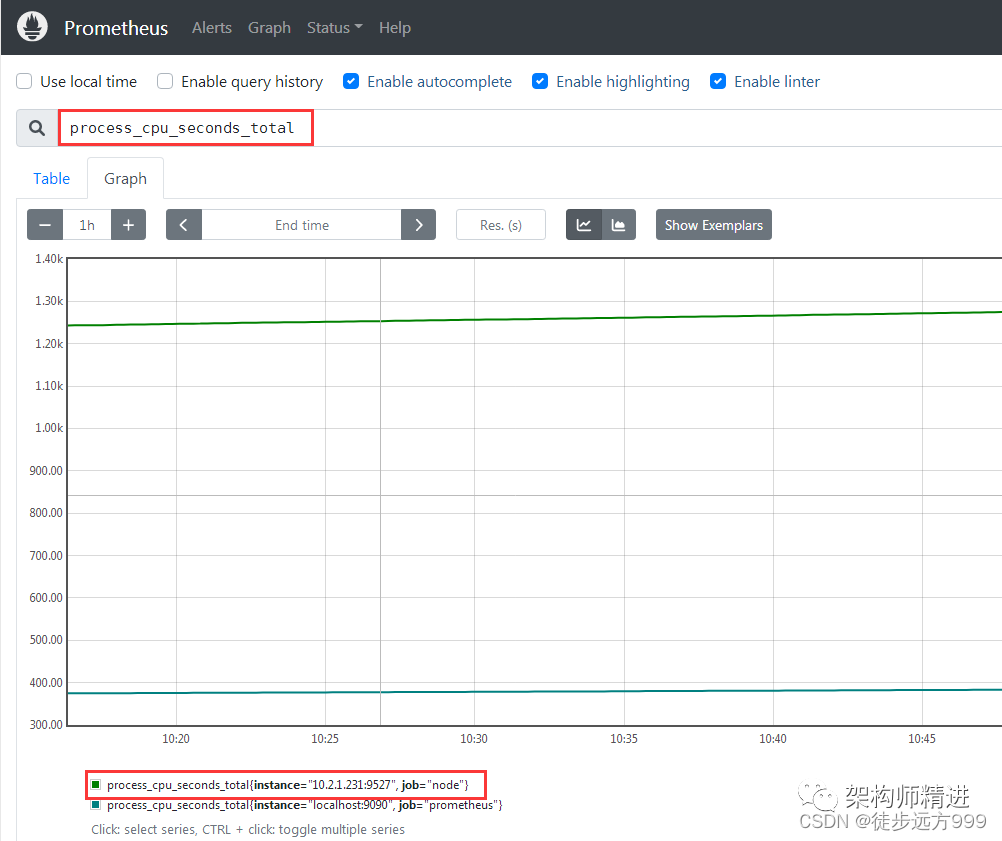
在Graph 页面,在查询框中输入: process_cpu_seconds_total
3.5 安装grafana
前面已经把prometheus和node exporter 安装并集成成功。prometheus虽然有自带的数据展示界面,但是不够全面也不直观。接下来集成grafana 完成数据展示。
下载地址:https://grafana.com/grafana/download
step1:首先,下载Grafana,并上传到服务器。
# 下载grafanawget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.0.3.linux-amd64.tar.gz# 解压到tar -zxvf grafana-enterprise-9.0.3.linux-amd64.tar.gz -C /usr/local/prometheus# 修改目录名:cd /usr/local/prometheusmv ngrafana-enterprise-9.0.3.linux-amd64 grafana-9.0.3
step2:启动Grafana,输入如下命令:
#grafanacd /usr/local/prometheus/grafana-9.0.3/bin#执行启动命令,指定数据访问的url./grafana-server --homepath /usr/local/prometheus/grafana-9.0.3 web
step3:验证是否安装成功,Grafana默认端口:3000。在浏览器中输入:http://10.2.1.231:3000/ 输入默认账号密码:admin\admin。能正常进入Grafana,说明Grafana安装成功。
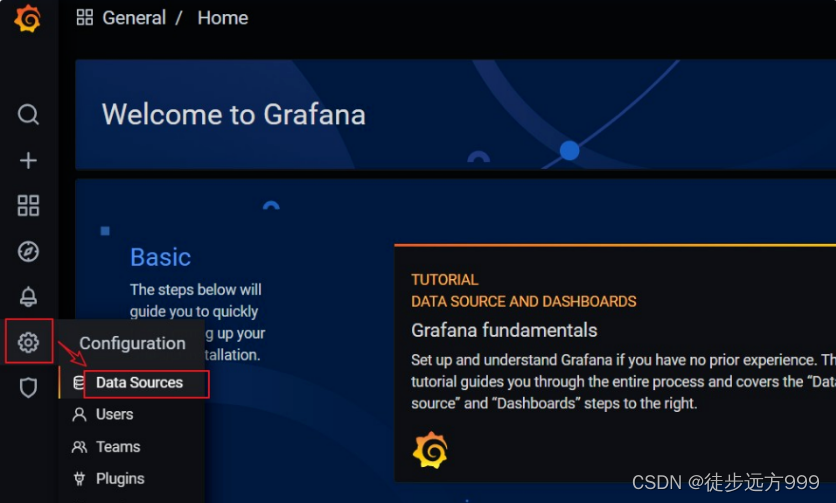
step4:配置prometheus数据源,点击 设置 | Data Source ,按照操作添加prometheus数据源。
点击add data source,后选择prometheus数据源。
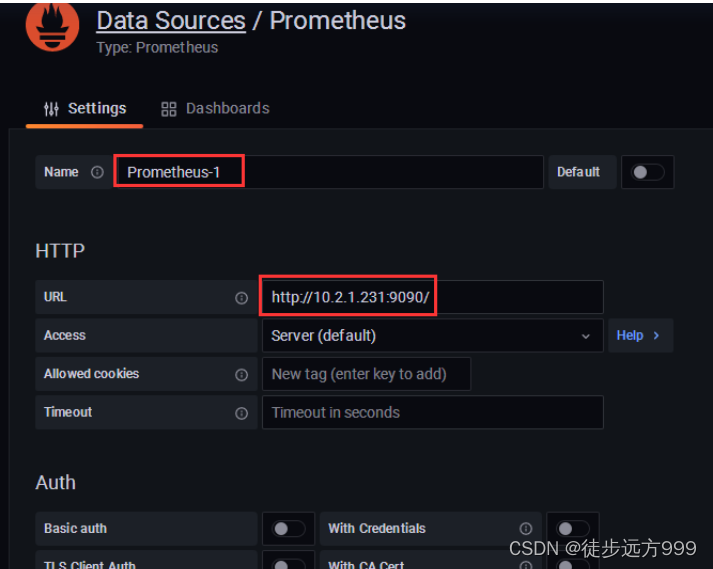
输入data source 的名字以及prometheus的地址:http://10.2.1.231:9090/ 后点击Save&Test 即可。
step5:创建仪表盘 Dashboard
Grafana 支持手动创建仪表盘 Dashboard 和自动导入Dashboard模板两种方式,手动一个个添加Dashboard 比较繁琐,Grafana 社区鼓励用户分享 Dashboard,通过https://grafana.com/dashboards 网站,可以找到大量可直接使用的Dashboard模板。
Grafana 中所有的Dashboard 通过 JSON 进行共享,下载并且导入这些 JSON 文件,就可以直接使用这些已经定义好的 Dashboard:
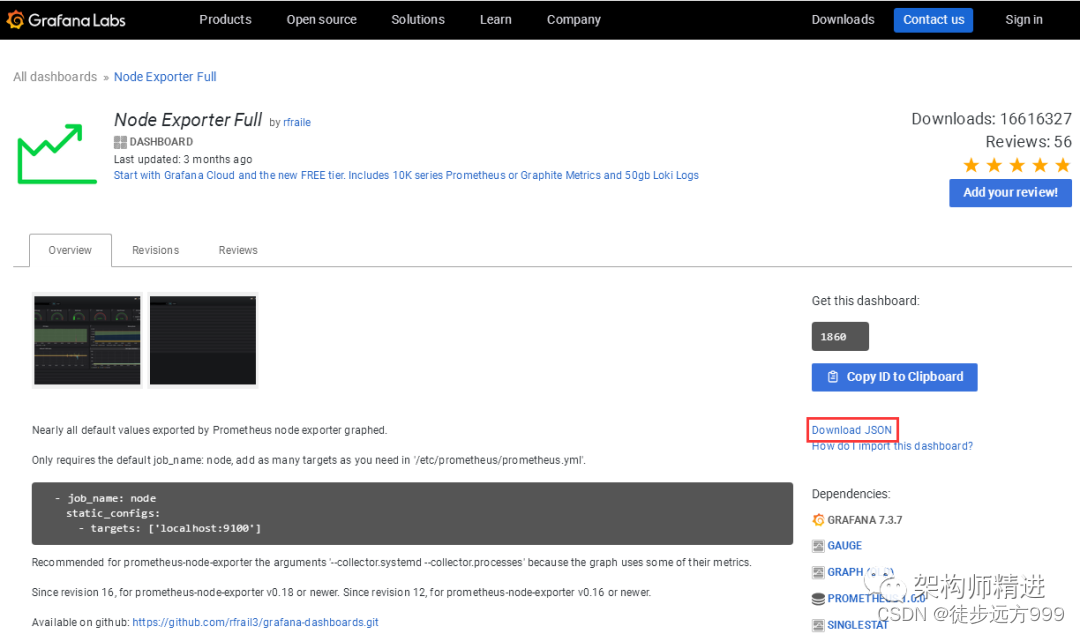
选择自己喜欢的模板后,点击 Download JSON下载对应的json 文件。然后在Grafana系统中导入相应的json即可。
接下来回到Grafana页面,点击DashBoards|Import
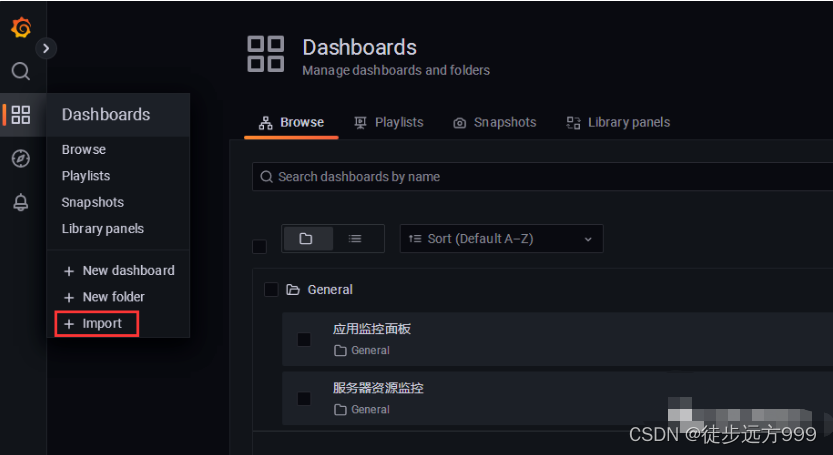
选择之前下载好的json文件,导入即可。
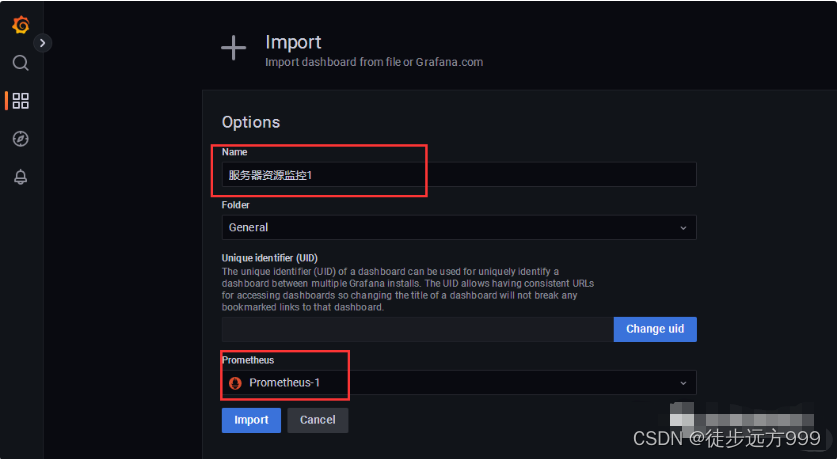
点击Import后,我们就可以看到详细的服务器资源监控数据。如下图所示:
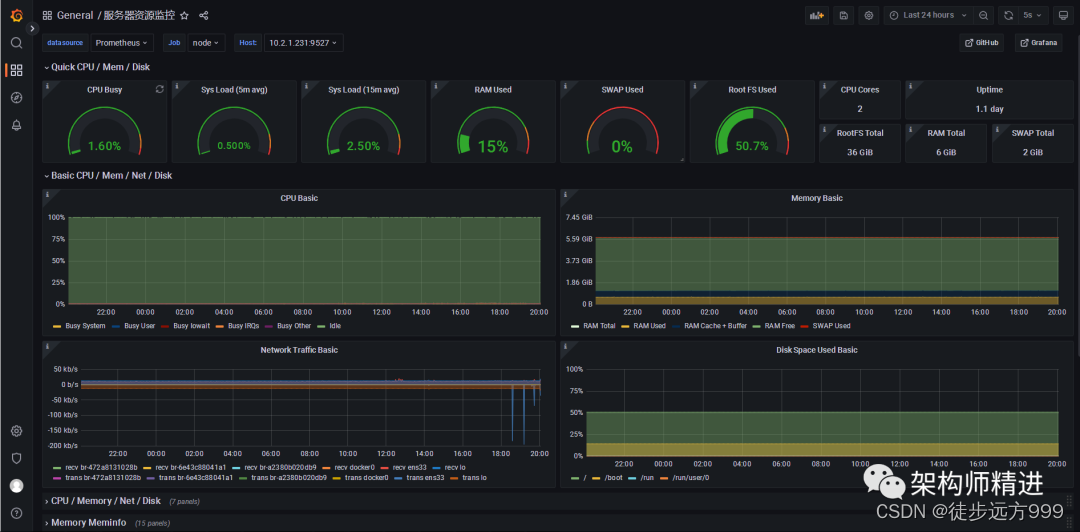
参考文章
五、Prometheus告警规则
1、与AlertManager关联
alerting:alertmanagers:- static_configs:- targets:- 192.168.94.71:9093
rule_files:# - "first_rules.yml"# - "second_rules.yml"- "/app/prometheus/rules/*.rules" #告警规则位置
2、添加监控Alertmanager,让Prometheus去收集Alertmanager的监控指标
- job_name: 'alertmanager'#覆盖全局配置,每15秒收集一次信息scrape_interval: 15sstatic_configs:- targets: ['192.168.94.71:9093']
3、配置告警规则,创建告警文件
cat /opt/prometheus/rules/temp.rules
cat /opt/prometheus/rules/temp.rules
groups:- name: test-rulesrules:#对任何实例超过1分钟无法联系的情况发出警报- alert: InstanceDown #告警规则的名称expr: up == 0 #基于PromQL表达式告警出发条件,用于计算是否有时间序列满足改条件for: 2m #评估等待时间,用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。labels: #自定义标签,允许用户指定要附加到告警上的一组附加标签status: warningannotations: #用于指定一组附加信息,比如用于描述告警详细信息,当中内容会在告警产生时作为参数一同发送到AlertManagersummary: "{{$labels.instance}}: has been down"description: "{{$labels.instance}}: job {{$labels.job}} has been down"- name: node-cpurules:- alert: NodeCpuUsageexpr: (100 - (avg by (instance) (rate(node_cpu_seconds_total{job=~".*",mode="idle"}[2m])) * 100)) > 90for: 15mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: CPU usage is above 90% (current value is: {{ $value }}"- alert: NodeMemUsageexpr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 90for: 15mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: MEM usage is above 90% (current value is: {{ $value }}"- alert: NodeDiskUsageexpr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev|snap).*"} / node_filesystem_size_bytes) * 100 > 90for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: Disk usage is above 80% (current value is: {{ $value }}"- alert: NodeFDUsageexpr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 80for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: File Descriptor usage is above 80% (current value is: {{ $value }}"- alert: NodeLoad15expr: avg by (instance) (node_load15{}) > 20for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: Load15 is above 100 (current value is: {{ $value }}"- alert: NodeAgentStatusexpr: avg by (instance) (up{}) == 0for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: Node Agent is down (current value is: {{ $value }}"- alert: NodeProcsBlockedexpr: avg by (instance) (node_procs_blocked{}) > 100for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: Node Blocked Procs detected!(current value is: {{ $value }}"- alert: NodeTransmitRateexpr: avg by (instance)(floor(irate(node_network_transmit_bytes_total{device!="lo"}[2m])/ 1024 / 1024)) > 100for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: Node Transmit Rate is above 100MB/s (current value is: {{ $value }}"- alert: NodeReceiveRateexpr: avg by (instance) (floor(irate(node_network_receive_bytes_total{device="eth0"}[2m]) / 1024 / 1024)) > 100for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: Node Receive Rate is above 100MB/s (current value is: {{ $value }}"- alert: NodeDiskReadRateexpr: avg by (instance) (floor(irate(node_disk_bytes_read{}[2m]) / 1024 / 1024)) > 50for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: Node Disk Read Rate is above 50MB/s (current value is: {{ $value }}"- alert: NodeDiskWriteRateexpr: avg by (instance) (floor(irate(node_nfsd_disk_bytes_written_total{}[2m]) / 1024 / 1024)) > 50for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: Node Disk Write Rate is above 50MB/s (current value is: {{ $value }}"- alert: Domain expr: domain_expiry_days < 30for: 2mlabels:service_name: testlevel: warningannotations:description: "{{$labels.instance}}: 域名剩余时间小于三十天,请及时续费 (current value is: {{ $value }}"
4、重载配置文件
curl -X POST http://localhost:9090/-/reload
六、配置邮箱报警
1、使用配置文件定义告警
# cat alertmanager.yaml
global:resolve_timeout: 5msmtp_smarthost: 'xxx' #邮件服务器smtp_from: 'xxx' #发邮件的邮箱smtp_auth_username: 'xxx' #发邮件的邮箱用户名smtp_auth_password: 'xxx' #发邮件的邮箱密码 smtp_require_tls: false #进行tls验证smtp_hello: 'xxx'
route:group_by: ['alertname']# 当收到告警的时候,等待group_wait配置的时间,看是否还有告警,如果有就一起发出去group_wait: 5s# 上次告警信息发送成功,此时又来了一个新的告警数据,则需要等该 group_interval 配置的时间才可以发送出去group_interval: 5s# 如果上次告警信息发送成功,且问题没有解决,则等待 repeat_interval 配置的时间再次发送告警数据repeat_interval: 5m# 全局报警组,这个参数必选(定义告警接收器)receiver: 'email'
receivers:# 选择告警接收器
- name: 'email'email_configs:# 收邮件的邮箱- to: 'xxx, xxx'# 如果报警恢复,也发送邮件send_resolved: truewebhook_configs: - url: 'http://api.aiops.com/alert/api/event/prometheus/0a099b8d-49dd-403d-8c97-9878ed75fc39'send_resolved: true
inhibit_rules:- source_match:severity: 'critical'target_match:severity: 'warning'equal: ['alertname', 'dev', 'instance']
2、使用模板定义告警信息
创建告警信息模板
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
<h2>@告警通知</h2>
告警程序:prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情:{{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
<h2>@告警恢复</h2>
告警程序: prometheus_alert <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
告警时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- end }}
修改AlertManager配置文件
...
templates:- '/opt/alertmanager/template/*.temp'
receivers:# 选择告警接收器
- name: 'email'email_configs:# 收邮件的邮箱- to: 'xxx, xxx'html: '{{ template "email.heml" .}}'# 如果报警恢复,也发送邮件send_resolved: true
相关文章:
Prometheus+Grafana 搭建应用监控系统
一、背景 完善的监控系统可以提高应用的可用性和可靠性,在提供更优质服务的前提下,降低运维的投入和工作量,为用户带来更多的商业利益和客户体验。下面就带大家彻底搞懂监控系统,使用Prometheus Grafana搭建完整的应用监控系统。 …...

Spring Boot整合Log4j2.xml的问题
文章目录 问题解决参考 问题 Spring Boot整合Log4j2.xml的时候返回以下错误: Caused by: org.apache.logging.log4j.LoggingException: log4j-slf4j-impl cannot be present with log4j-to-slf4j 进行了解决。 解决 Spring Boot整合Log4j2.xml经过以下操作&#…...
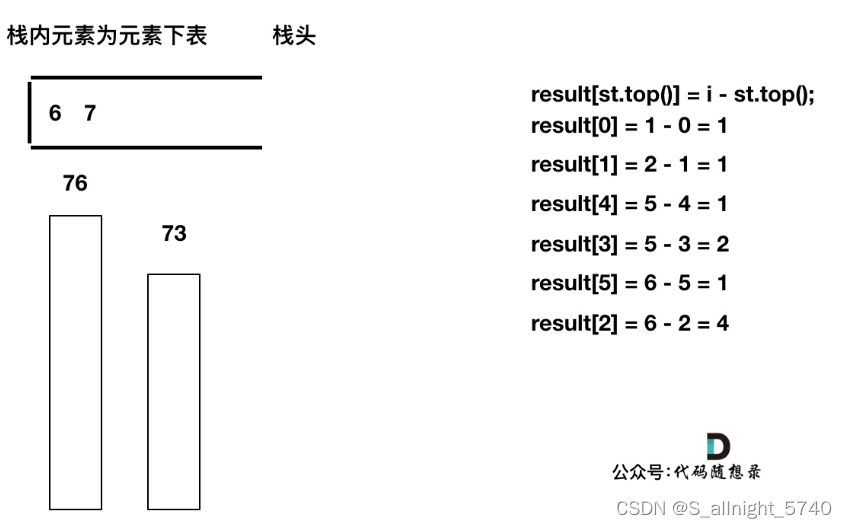
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I 739. 每日温度496.下一个更大元素 I 739. 每日温度 题目链接 视频讲解 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answe…...

【动手学深度学习】--文本预处理
文章目录 文本预处理1.读取数据集2.词元化3.词表4.整合所有功能 文本预处理 学习视频:文本预处理【动手学深度学习v2】 官方笔记:文本预处理 对于序列数据处理问题,在【序列模型】中评估了所需的统计工具和预测时面临的挑战,这…...

2023年最佳研发管理平台评选:哪家表现出色?
“研发管理平台哪家好?以下是一些知名的研发管理软件品牌:Zoho Projects、JIRA、Trello、Microsoft Teams、GitLab。’” 企业需要不断创新以保持竞争力。研发是企业创新的核心,而研发管理平台则为企业提供了一个有效的工具来支持和管理其研发…...

轻量容器引擎Docker基础使用
轻量容器引擎Docker Docker是什么 Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。 它基于 Google 公司推出的 Go 语言实现,项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,…...

questions
1.JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境 JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需…...
MojoTween:使用「Burst、Jobs、Collections、Mathematics」优化实现的Unity顶级「Tween动画引擎」
MojoTween是一个令人惊叹的Tween动画引擎,针对C#和Unity进行了高度优化,使用了Burst、Jobs、Collections、Mathematics等新技术编码。 MojoTween提供了一套完整的解决方案,将Tween动画应用于Unity Objects的各个方面,并可以通过E…...

Vue3响应式源码实现
Vue3响应式源码实现 初始化项目结构 vue-proxy ├── effect.js ├── effect.ts ├── index.html ├── index.js ├── package.json ├── reactive.js ├── reactive.ts └── webpack.config.jsreactive.ts import { track, trigger } from "./effect&q…...

【RapidAI】P1 中文文本切割程序
中文文本切割程序 基本信息代码解析相关包获取 yaml 关键文件类的构造函数切分语句部分特殊处理 PDF重点切分去除数组中空字符串再度切分后长度 附录附录一:完整代码附录二:可继续思考问题 基本信息 文件名: chinese_text_splitter.py 文件地…...

4、QT中的网络编程
一、Linux中的网络编程 1、子网和公网的概念 子网网络:局域网,只能进行内网的通信公网网络:因特网,服务器等可以进行远程的通信 2、网络分层模型 4层模型:应用层、传输层、网络层、物理层 应用层:用户自…...
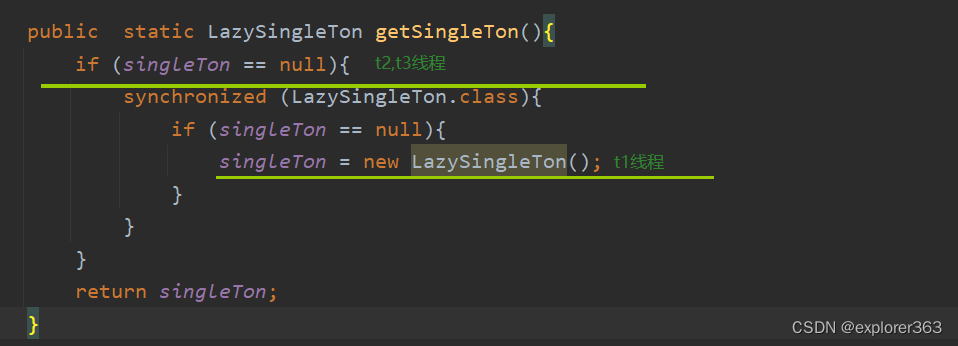
单例模式(饿汉式单例 VS 懒汉式单例)
所谓的单例模式就是保证某个类在程序中只有一个对象 一、如何控制只产生一个对象? 1.构造方法私有化(保证对象的产生个数) 创建类的对象,要通过构造方法产生对象 构造方法若是public权限,对于类的外部,可…...

Oracle数据库连接之TNS-12541异常
在进行数据库开发的时候,通常需要使用PLSQL Developer开发工具连接Oralce数据库,在进行连接时,经常性的会提示TNS-12541:TNS:no listener(没有监听),从而导致PLSQL Developer 无法连接到数据库实例…...
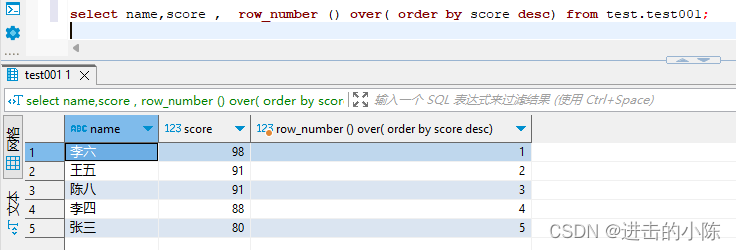
sql中的排序函数dense_rank(),RANK()和row_number()
dense_rank(),RANK()和row_number()是SQL中的排序函数。 为方便后面的函数差异比对清晰直观,准备数据表如下: 1.dense_rank() 函数语法:dense_rank() over( order by 列名 【desc/asc】) DENSE_RANK()是连续排序,比如…...

Flask狼书笔记 | 05_数据库
文章目录 5 数据库5.1 数据库的分类5.2 ORM5.3 使用Flask_SQLAlchemy5.4 数据库操作5.5 定义关系5.6 更新数据库表5.7 数据库进阶小结 5 数据库 这一章学习如何在Python中使用DBMS(数据库管理系统),来对数据库进行管理和操作。本书使用SQLit…...

HJ70 矩阵乘法计算量估算
Powered by:NEFU AB-IN Link 文章目录 HJ70 矩阵乘法计算量估算题意思路代码 HJ70 矩阵乘法计算量估算 题意 矩阵乘法的运算量与矩阵乘法的顺序强相关。 例如: A是一个5010的矩阵,B是1020的矩阵,C是205的矩阵 计算ABC有两种顺序:…...

Doris数据库使用记录
新建表 create table tonly_attendance(vin varchar(64),diggings_name varchar(256),area varchar(64),diggings_type varchar(256),work_time decimal(20,2),engine_run_time decimal(20,2),upload_time varchar(64))DUPLICATE KEY (vin)distributed by hash (vin)删除之…...

华为OD机试真题【篮球比赛】
1、题目描述 【篮球比赛】 一个有N个选手参加比赛,选手编号为1~N(3<N<100),有M(3<M<10)个评委对选手进行打分。 打分规则为每个评委对选手打分,最高分10分,最低分1分。…...
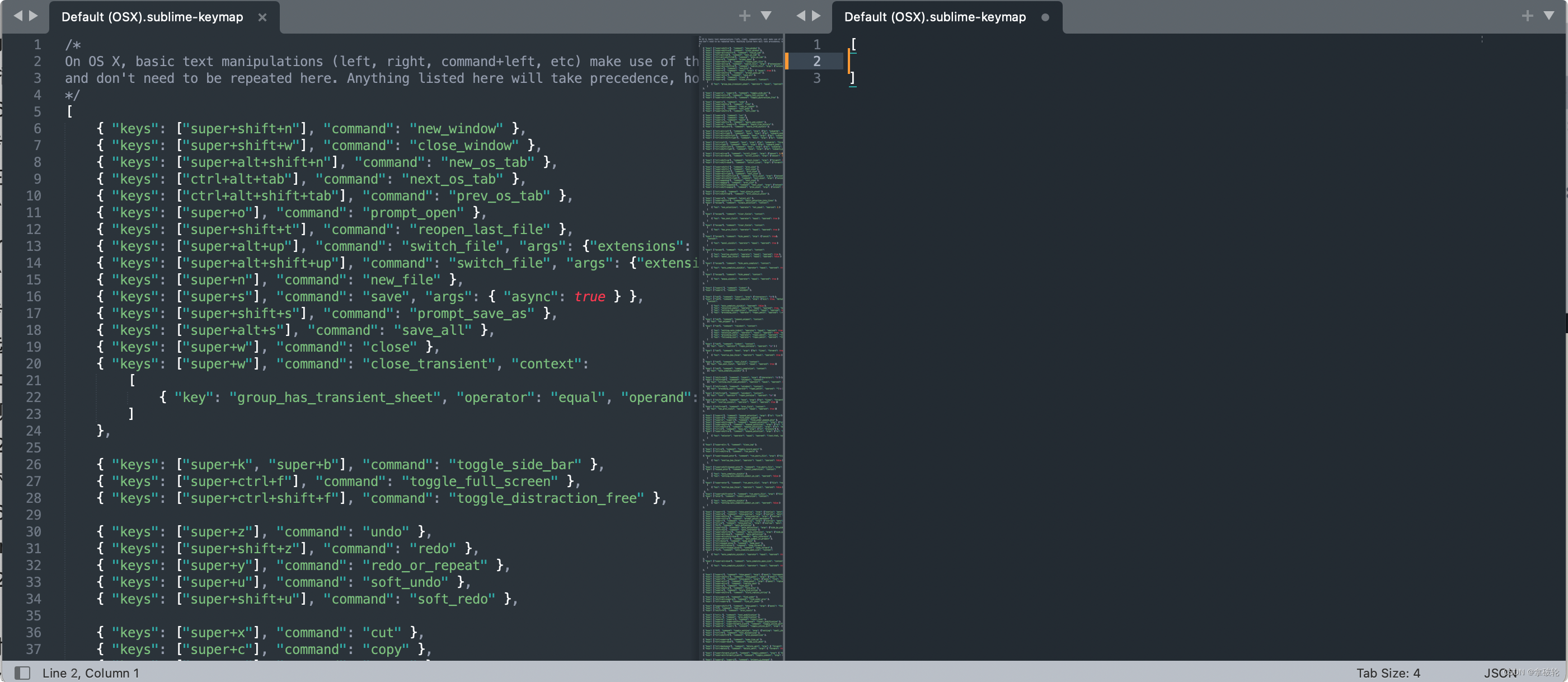
sublime text 格式化json快捷键配置
以 controlcommandj 为例。 打开Sublime Text,依次点击左上角菜单Sublime Text->Preferences->Key Bindings,出现以下文件: 左边的是Sublime Text默认的快捷键,不可编辑。右边是我们自定义快捷键的地方,在中括号…...

Spring Cloud 面试题总结
Spring Cloud和各子项目版本对应关系 Spring Cloud 是一个用于构建分布式系统的开发工具包,它基于Spring Boot提供了一组模块和功能,用于构建微服务架构中的分布式应用程序。Spring Cloud的不同子项目有各自的版本,下面是一些常见的Spring C…...

基于Azure SQL与Semantic Kernel的RAG应用实战:低成本实现向量搜索与智能问答
1. 项目概述:当SQL数据库遇上向量搜索如果你正在用.NET技术栈构建智能应用,并且数据已经躺在Azure SQL Database里,那么“如何低成本、高效率地实现语义搜索和RAG(检索增强生成)”很可能就是你当前最头疼的问题。传统的…...

AI智能体如何革新LaTeX写作:PaperDebugger深度集成Overleaf实践
1. 项目概述:当AI助手遇上LaTeX写作如果你是一名科研工作者、研究生,或者任何需要和LaTeX文档打交道的人,那么下面这个场景你一定不陌生:深夜,你对着Overleaf编辑器里密密麻麻的代码和公式,反复修改着论文的…...
)
ChatGPT Instagram内容策略失效真相(92%运营者忽略的算法适配层)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Instagram内容策略失效的底层归因 Instagram 的算法演进与用户行为迁移,正系统性瓦解基于通用大模型(如 ChatGPT)生成的“模板化内容策略”。其失效并非源于…...

【2024最严苛功能压力测试】:在金融合规文档生成、医疗术语推理、代码安全审计三大高危场景下,Claude与Gemini谁扛住了0误判红线?
更多请点击: https://intelliparadigm.com 第一章:【2024最严苛功能压力测试】:在金融合规文档生成、医疗术语推理、代码安全审计三大高危场景下,Claude与Gemini谁扛住了0误判红线? 测试设计原则 本测试采用“双盲对…...

ARM GICv4.1 GICD_TYPER2寄存器详解与虚拟化应用
1. GICD_TYPER2寄存器概述 GICD_TYPER2是ARM GICv4.1架构中引入的关键寄存器,属于中断控制器类型寄存器家族。作为GIC Distributor的一部分,它专门用于增强虚拟化场景下的中断管理能力。这个32位寄存器位于内存映射地址Dist_base 0x000C处,仅…...

基础模型全生命周期管理的混合架构实践与优化
1. 基础模型全生命周期管理的架构挑战基础模型(Foundation Models)正在重塑AI技术栈的每个环节,从预训练到推理部署的全生命周期管理面临前所未有的系统架构挑战。传统HPC(高性能计算)集群和云原生平台各自为政的局面&…...

DLP Pico技术与近眼显示系统设计解析
1. DLP Pico技术解析:微镜阵列如何重塑显示未来 在2014年,德州仪器(TI)推出了一项颠覆性的显示技术——基于DLP TRP架构的Pico芯片组。这项技术的核心是一块布满微小铝镜的芯片,每个微镜尺寸仅5.4微米,比人类头发直径的十分之一还…...

Perplexity无法解析Springer LaTeX公式?2024.06最新MathJax兼容补丁+3类数学文献精准摘要生成术
更多请点击: https://intelliparadigm.com 第一章:Perplexity解析Springer文献的底层机制与失效归因 Perplexity 作为衡量语言模型预测能力的关键指标,在学术文献解析场景中常被误用为“质量代理”,尤其在处理 Springer 出版集团…...

Nintendo Switch游戏安装终极指南:3种方法解决所有格式兼容问题
Nintendo Switch游戏安装终极指南:3种方法解决所有格式兼容问题 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Nintendo Switch…...

英雄联盟R3nzSkin换肤工具:5分钟快速上手免费皮肤解锁指南
英雄联盟R3nzSkin换肤工具:5分钟快速上手免费皮肤解锁指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 还在为英雄联盟国服昂贵的皮肤价…...