代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I
- 739. 每日温度
- 496.下一个更大元素 I
739. 每日温度
题目链接
视频讲解
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后,如果气温在这之后都不会升高,请在该位置用 0 来代替
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]
怎么能想到用单调栈呢? 什么时候用单调栈呢?
通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了,时间复杂度为O(n)
例如本题其实就是找找到一个元素右边第一个比自己大的元素,此时就应该想到用单调栈了
那么单调栈的原理是什么呢?为什么时间复杂度是O(n)就可以找到每一个元素的右边第一个比它大的元素位置呢?
单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素高的元素,优点是整个数组只需要遍历一次
更直白来说,就是用一个栈来记录我们遍历过的元素,因为我们遍历数组的时候,我们不知道之前都遍历了哪些元素,以至于遍历一个元素找不到是不是之前遍历过一个更小的,所以我们需要用一个容器(这里用单调栈)来记录我们遍历过的元素
在使用单调栈的时候首先要明确如下几点:
单调栈里存放的元素是什么?
单调栈里只需要存放元素的下标i就可以了,如果需要使用对应的元素,直接T[i]就可以获取
单调栈里元素是递增呢? 还是递减呢?
注意以下讲解中,顺序的描述为 从栈头到栈底的顺序,因为单纯的说从左到右或者从前到后,不说栈头朝哪个方向的话,一定比较懵
这里我们要使用递增循序(再强调一下是指从栈头到栈底的顺序),因为只有递增的时候,栈里要加入一个元素i的时候,才知道栈顶元素在数组中右面第一个比栈顶元素大的元素是i
即:如果求一个元素右边第一个更大元素,单调栈就是递增的,如果求一个元素右边第一个更小元素,单调栈就是递减的
文字描述理解起来有点费劲,接下来用一系列的图,来讲解单调栈的工作过程,再去思考,本题为什么是递增栈
使用单调栈主要有三个判断条件
当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
把这三种情况分析清楚了,也就理解透彻了
接下来用temperatures = [73, 74, 75, 71, 71, 72, 76, 73]为例来逐步分析,输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]
首先先将第一个遍历元素加入单调栈
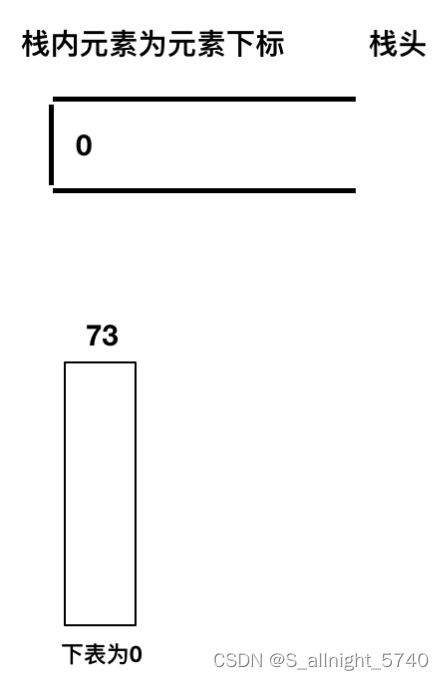
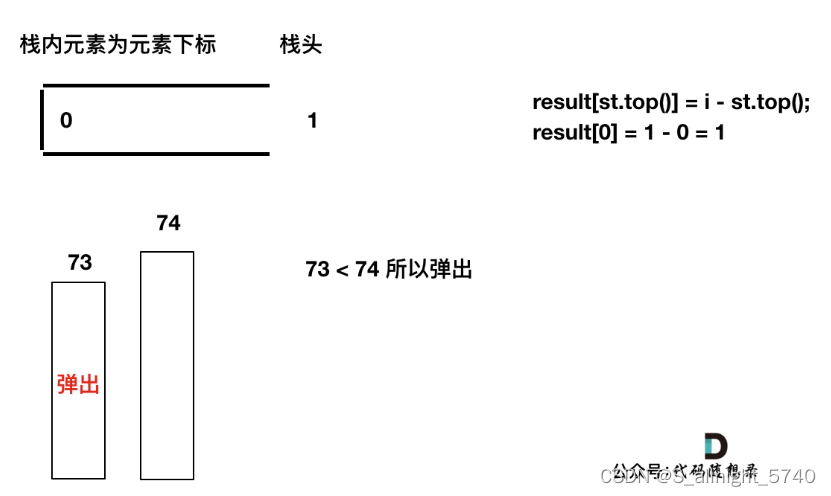
加入T[1] = 74,因为T[1] > T[0](当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况)
要保持一个递增单调栈(从栈头到栈底),所以将T[0]弹出,T[1]加入,此时result数组可以记录了,result[0] = 1,即T[0]右面第一个比T[0]大的元素是T[1]
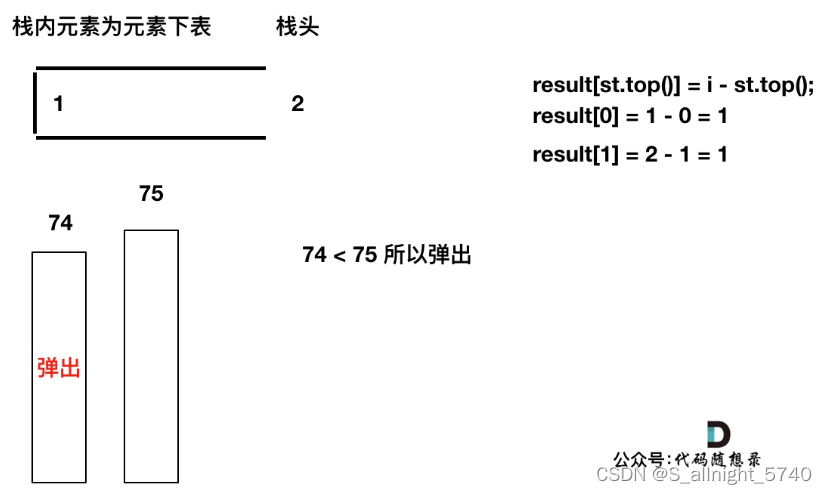
加入T[2],同理,T[1]弹出
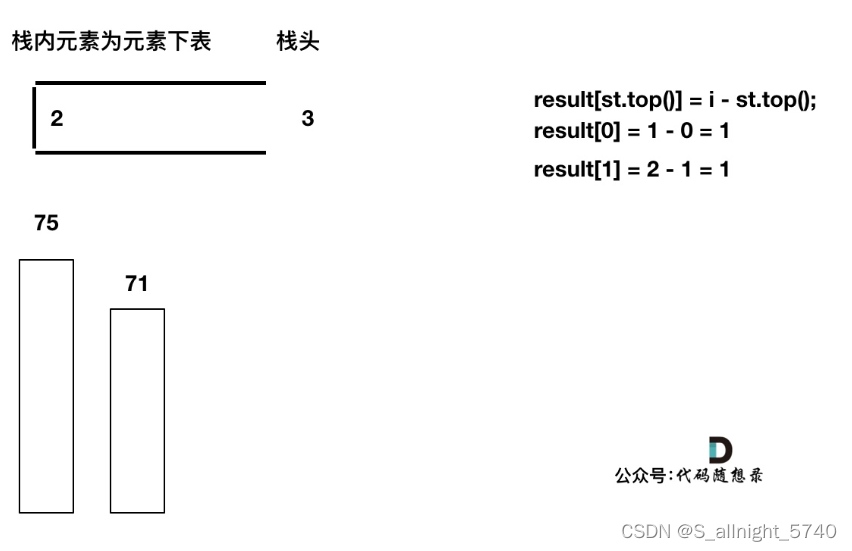
加入T[3],T[3] < T[2] (当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况),加T[3]加入单调栈
加入T[4],T[4] == T[3] (当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况),此时依然要加入栈,不用计算距离,因为我们要求的是右面第一个大于本元素的位置,而不是大于等于!
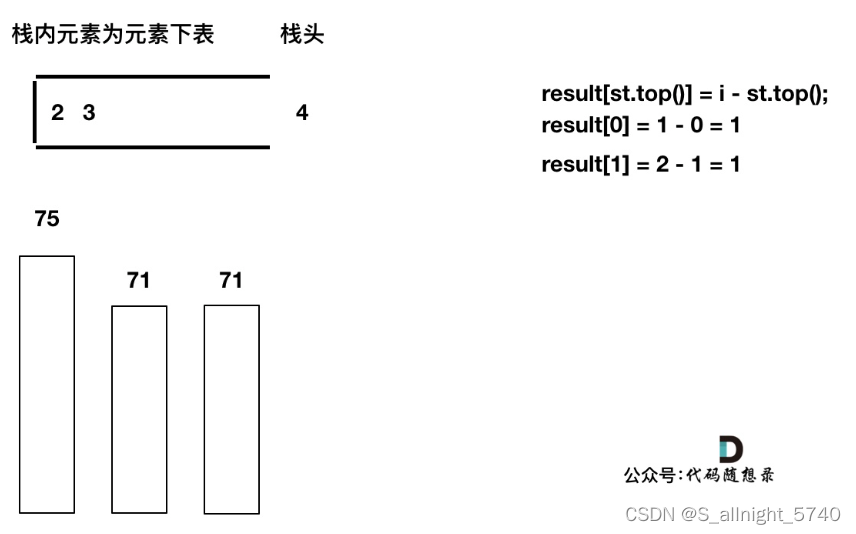
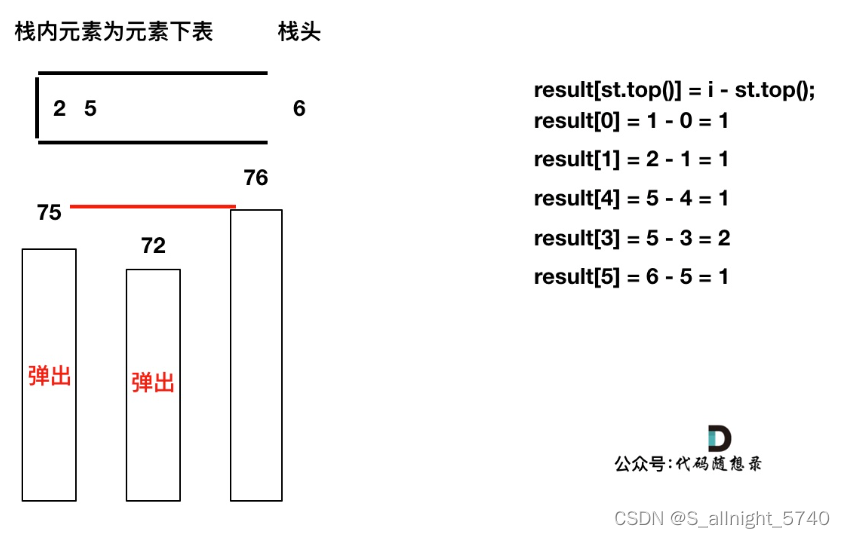
加入T[5],T[5] > T[4] (当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况),将T[4]弹出,同时计算距离,更新result
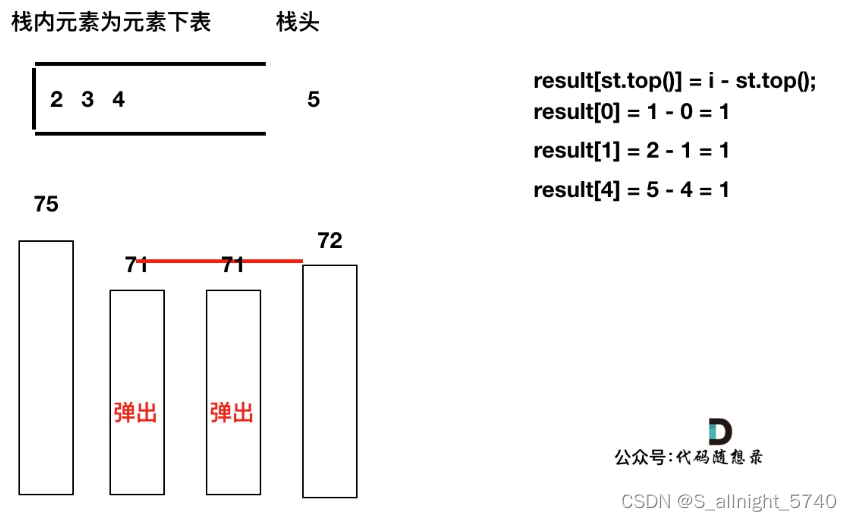
T[4]弹出之后, T[5] > T[3] (当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况),将T[3]继续弹出,同时计算距离,更新result
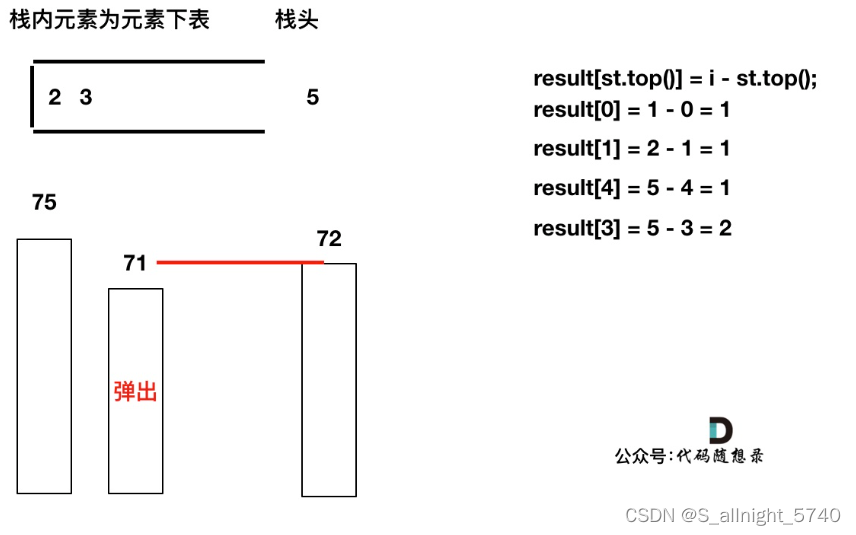
直到发现T[5]小于T[st.top()],终止弹出,将T[5]加入单调栈
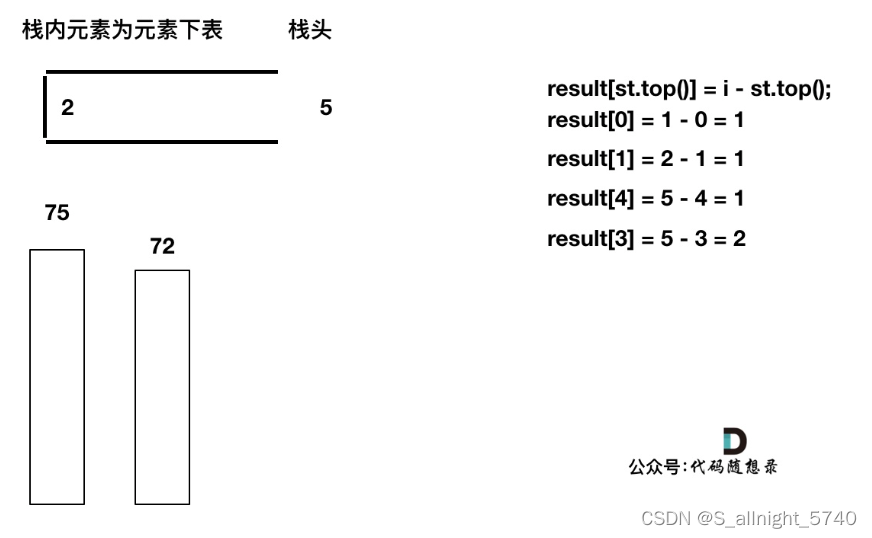
加入T[6],同理,需要将栈里的T[5],T[2]弹出
同理,继续弹出

此时栈里只剩下了T[6]

加入T[7], T[7] < T[6] 直接入栈,这就是最后的情况,result数组也更新完了
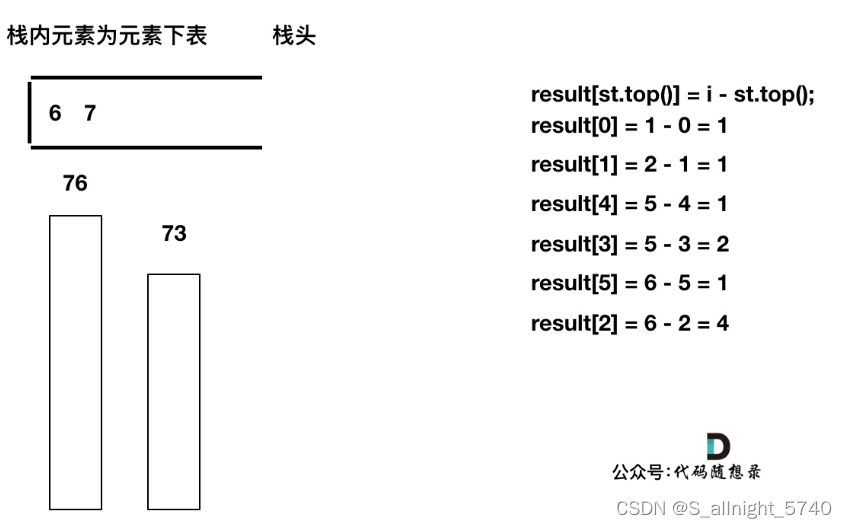
此时有可能就疑惑了,那result[6] , result[7]怎么没更新啊,元素也一直在栈里
其实定义result数组的时候,就应该直接初始化为0,如果result没有更新,说明这个元素右面没有更大的了,也就是为0
以上在图解的时候,已经把,这三种情况都做了详细的分析
情况一:当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
情况二:当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
情况三:当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
通过以上过程,大家可以自己再模拟一遍,就会发现:只有单调栈递增(从栈口到栈底顺序),就是求右边第一个比自己大的,单调栈递减的话,就是求右边第一个比自己小的
class Solution {
public:vector<int> dailyTemperatures(vector<int>& T) {// 递增栈stack<int> st;vector<int> result(T.size(), 0);st.push(0);for (int i = 1; i < T.size(); i++) {if (T[i] < T[st.top()]) { // 情况一st.push(i);} else if (T[i] == T[st.top()]) { // 情况二st.push(i);} else {while (!st.empty() && T[i] > T[st.top()]) { // 情况三result[st.top()] = i - st.top();st.pop();}st.push(i);}}return result;}
};
496.下一个更大元素 I
题目链接
视频讲解
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素,给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集,对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1,返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素
输入:nums1 = [4,1,2], nums2 = [1,3,4,2].
输出:[-1,3,-1]
在739. 每日温度中是求每个元素下一个比当前元素大的元素的位置
本题则是说nums1 是 nums2的子集,找nums1中的元素在nums2中下一个比当前元素大的元素
看上去和739. 每日温度就如出一辙了
几乎是一样的,但是这么绕了一下,其实还上升了一点难度
需要对单调栈使用的更熟练一些,才能顺利的把本题写出来
从题目示例中我们可以看出最后是要求nums1的每个元素在nums2中下一个比当前元素大的元素,那么就要定义一个和nums1一样大小的数组result来存放结果
一些人可能看到两个数组都已经懵了,不知道要定一个一个多大的result数组来存放结果了
这么定义这个result数组初始化应该为多少呢?
题目说如果不存在对应位置就输出 -1 ,所以result数组如果某位置没有被赋值,那么就应该是是-1,所以就初始化为-1
在遍历nums2的过程中,我们要判断nums2[i]是否在nums1中出现过,因为最后是要根据nums1元素的下标来更新result数组
注意题目中说是两个没有重复元素 的数组 nums1 和 nums2
没有重复元素,我们就可以用map来做映射了。根据数值快速找到下标,还可以判断nums2[i]是否在nums1中出现过
C++中,当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的
那么预处理代码如下:
unordered_map<int, int> umap; // key:下标元素,value:下标
for (int i = 0; i < nums1.size(); i++) {umap[nums1[i]] = i;
}
使用单调栈,首先要想单调栈是从大到小还是从小到大
本题和739. 每日温度是一样的
栈头到栈底的顺序,要从小到大,也就是保持栈里的元素为递增顺序。只要保持递增,才能找到右边第一个比自己大的元素
可能这里有一些人不理解,那么可以自己尝试一下用递减栈,能不能求出来。其实递减栈就是求右边第一个比自己小的元素了
接下来就要分析如下三种情况,一定要分析清楚
情况一:当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
此时满足递增栈(栈头到栈底的顺序),所以直接入栈
情况二:当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
如果相等的话,依然直接入栈,因为我们要求的是右边第一个比自己大的元素,而不是大于等于!
情况三:当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
此时如果入栈就不满足递增栈了,这也是找到右边第一个比自己大的元素的时候
判断栈顶元素是否在nums1里出现过,(注意栈里的元素是nums2的元素),如果出现过,开始记录结果
记录结果这块逻辑有一点小绕,要清楚,此时栈顶元素在nums2数组中右面第一个大的元素是nums2[i](即当前遍历元素)
代码如下:
while (!st.empty() && nums2[i] > nums2[st.top()]) {if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标result[index] = nums2[i];}st.pop();
}
st.push(i);
class Solution {
public:vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {stack<int> st;vector<int> result(nums1.size(), -1);if (nums1.size() == 0) return result;unordered_map<int, int> umap; // key:下标元素,value:下标for (int i = 0; i < nums1.size(); i++) {umap[nums1[i]] = i;}st.push(0);for (int i = 1; i < nums2.size(); i++) {if (nums2[i] < nums2[st.top()]) { // 情况一st.push(i);} else if (nums2[i] == nums2[st.top()]) { // 情况二st.push(i);} else { // 情况三while (!st.empty() && nums2[i] > nums2[st.top()]) {if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标result[index] = nums2[i];}st.pop();}st.push(i);}}return result;}
};
相关文章:
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I 739. 每日温度496.下一个更大元素 I 739. 每日温度 题目链接 视频讲解 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answe…...

【动手学深度学习】--文本预处理
文章目录 文本预处理1.读取数据集2.词元化3.词表4.整合所有功能 文本预处理 学习视频:文本预处理【动手学深度学习v2】 官方笔记:文本预处理 对于序列数据处理问题,在【序列模型】中评估了所需的统计工具和预测时面临的挑战,这…...

2023年最佳研发管理平台评选:哪家表现出色?
“研发管理平台哪家好?以下是一些知名的研发管理软件品牌:Zoho Projects、JIRA、Trello、Microsoft Teams、GitLab。’” 企业需要不断创新以保持竞争力。研发是企业创新的核心,而研发管理平台则为企业提供了一个有效的工具来支持和管理其研发…...

轻量容器引擎Docker基础使用
轻量容器引擎Docker Docker是什么 Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。 它基于 Google 公司推出的 Go 语言实现,项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,…...

questions
1.JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境 JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需…...
MojoTween:使用「Burst、Jobs、Collections、Mathematics」优化实现的Unity顶级「Tween动画引擎」
MojoTween是一个令人惊叹的Tween动画引擎,针对C#和Unity进行了高度优化,使用了Burst、Jobs、Collections、Mathematics等新技术编码。 MojoTween提供了一套完整的解决方案,将Tween动画应用于Unity Objects的各个方面,并可以通过E…...

Vue3响应式源码实现
Vue3响应式源码实现 初始化项目结构 vue-proxy ├── effect.js ├── effect.ts ├── index.html ├── index.js ├── package.json ├── reactive.js ├── reactive.ts └── webpack.config.jsreactive.ts import { track, trigger } from "./effect&q…...

【RapidAI】P1 中文文本切割程序
中文文本切割程序 基本信息代码解析相关包获取 yaml 关键文件类的构造函数切分语句部分特殊处理 PDF重点切分去除数组中空字符串再度切分后长度 附录附录一:完整代码附录二:可继续思考问题 基本信息 文件名: chinese_text_splitter.py 文件地…...

4、QT中的网络编程
一、Linux中的网络编程 1、子网和公网的概念 子网网络:局域网,只能进行内网的通信公网网络:因特网,服务器等可以进行远程的通信 2、网络分层模型 4层模型:应用层、传输层、网络层、物理层 应用层:用户自…...
单例模式(饿汉式单例 VS 懒汉式单例)
所谓的单例模式就是保证某个类在程序中只有一个对象 一、如何控制只产生一个对象? 1.构造方法私有化(保证对象的产生个数) 创建类的对象,要通过构造方法产生对象 构造方法若是public权限,对于类的外部,可…...

Oracle数据库连接之TNS-12541异常
在进行数据库开发的时候,通常需要使用PLSQL Developer开发工具连接Oralce数据库,在进行连接时,经常性的会提示TNS-12541:TNS:no listener(没有监听),从而导致PLSQL Developer 无法连接到数据库实例…...
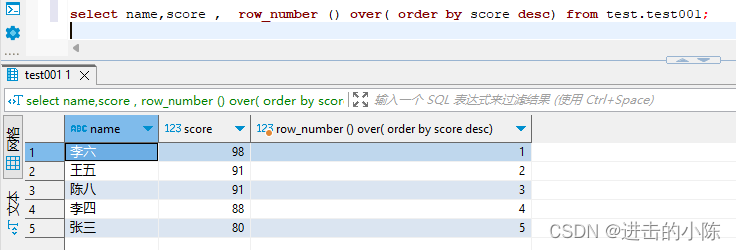
sql中的排序函数dense_rank(),RANK()和row_number()
dense_rank(),RANK()和row_number()是SQL中的排序函数。 为方便后面的函数差异比对清晰直观,准备数据表如下: 1.dense_rank() 函数语法:dense_rank() over( order by 列名 【desc/asc】) DENSE_RANK()是连续排序,比如…...

Flask狼书笔记 | 05_数据库
文章目录 5 数据库5.1 数据库的分类5.2 ORM5.3 使用Flask_SQLAlchemy5.4 数据库操作5.5 定义关系5.6 更新数据库表5.7 数据库进阶小结 5 数据库 这一章学习如何在Python中使用DBMS(数据库管理系统),来对数据库进行管理和操作。本书使用SQLit…...

HJ70 矩阵乘法计算量估算
Powered by:NEFU AB-IN Link 文章目录 HJ70 矩阵乘法计算量估算题意思路代码 HJ70 矩阵乘法计算量估算 题意 矩阵乘法的运算量与矩阵乘法的顺序强相关。 例如: A是一个5010的矩阵,B是1020的矩阵,C是205的矩阵 计算ABC有两种顺序:…...

Doris数据库使用记录
新建表 create table tonly_attendance(vin varchar(64),diggings_name varchar(256),area varchar(64),diggings_type varchar(256),work_time decimal(20,2),engine_run_time decimal(20,2),upload_time varchar(64))DUPLICATE KEY (vin)distributed by hash (vin)删除之…...

华为OD机试真题【篮球比赛】
1、题目描述 【篮球比赛】 一个有N个选手参加比赛,选手编号为1~N(3<N<100),有M(3<M<10)个评委对选手进行打分。 打分规则为每个评委对选手打分,最高分10分,最低分1分。…...
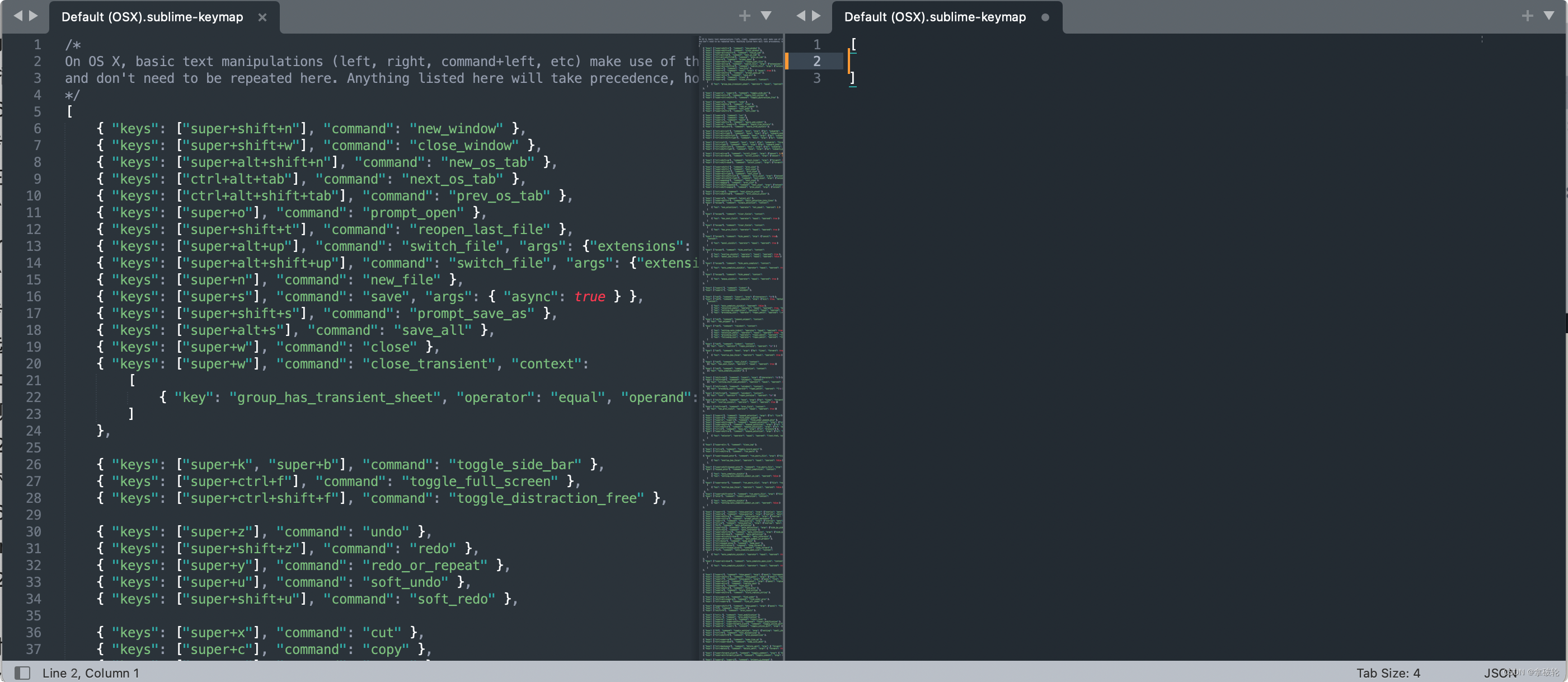
sublime text 格式化json快捷键配置
以 controlcommandj 为例。 打开Sublime Text,依次点击左上角菜单Sublime Text->Preferences->Key Bindings,出现以下文件: 左边的是Sublime Text默认的快捷键,不可编辑。右边是我们自定义快捷键的地方,在中括号…...

Spring Cloud 面试题总结
Spring Cloud和各子项目版本对应关系 Spring Cloud 是一个用于构建分布式系统的开发工具包,它基于Spring Boot提供了一组模块和功能,用于构建微服务架构中的分布式应用程序。Spring Cloud的不同子项目有各自的版本,下面是一些常见的Spring C…...

如何实现24/7客户服务自动化?
传统的客服制胜与否的法宝在于人,互联网时代,对于产品线广的大型企业来说:单靠人力,成本大且效率低,相对于产品相对单一的中小型企业来说:建设传统客服系统的成本难以承受,企业客户服务的转型已…...

2022年12月 C/C++(六级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:区间合并 给定 n 个闭区间 [ai; bi],其中i=1,2,…,n。任意两个相邻或相交的闭区间可以合并为一个闭区间。例如,[1;2] 和 [2;3] 可以合并为 [1;3],[1;3] 和 [2;4] 可以合并为 [1;4],但是[1;2] 和 [3;4] 不可以合并。 我们的任务是…...

《jEasyUI 取得选中行数据》
《jEasyUI 取得选中行数据》 引言 jEasyUI 是一个基于 jQuery 的易于使用的开源 UI 库,它为网页开发者提供了丰富的 UI 组件,如表格、表单、菜单、对话框等。在 jEasyUI 的众多组件中,表格组件(Datagrid)是使用频率非常…...

Fulling框架:构建完整AI智能体的工程化实践指南
1. 项目概述:从“FullAgent”到“Fulling”的智能体进化之路最近在开源社区里,一个名为“Fulling”的项目引起了我的注意。它隶属于“FullAgent”这个组织,名字本身就很有意思。“Fulling”这个词,在英语里有“使…丰满、充实”的…...

终极iOS设备降级指南:使用Legacy-iOS-Kit让旧设备重获新生 [特殊字符]
终极iOS设备降级指南:使用Legacy-iOS-Kit让旧设备重获新生 🚀 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Le…...

5个场景告诉你:为什么你需要这款免费的窗口分辨率神器
5个场景告诉你:为什么你需要这款免费的窗口分辨率神器 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾遇到过这些困扰?游戏内分辨率选项有限,无法满足你对极致画质的…...

Cursor集成Trunk插件:AI编程与代码质量守护的完美融合
1. 项目概述:当AI编程助手遇上代码质量守护者最近在折腾Cursor编辑器,发现了一个挺有意思的插件项目——trunk-io/cursor-plugin。简单来说,这就是一个桥梁,把Trunk这个代码质量与安全平台的能力,直接集成到了Cursor这…...

Cortex-R52 MBIST与March算法在嵌入式存储测试中的应用
1. Cortex-R52 MBIST测试技术解析在嵌入式系统开发中,存储器可靠性直接影响整个系统的稳定性。作为Arm Cortex-R系列中的实时处理器,Cortex-R52集成了PMC-R52(Programmable Memory Controller)模块,专门用于执行存储器…...

FPGA频率测量实战:从原理到实现,三种方法深度解析与选型指南
1. FPGA频率测量的工程意义与挑战 在数字电路设计中,频率测量就像给信号"把脉",是评估系统健康状况的基础操作。想象你正在开发一款智能温控器,需要精确测量风扇转速信号;或者设计无线通信模块,要监控本振频…...

大模型压缩实战:量化、剪枝与蒸馏技术解析与AngelSlim应用
1. 项目概述:从“大”到“小”的模型压缩革命最近在模型部署和推理优化的圈子里,Tencent/AngelSlim 这个项目被讨论得挺多。简单来说,它不是一个全新的模型,而是一套由腾讯开源的、专门用于大语言模型(LLM)…...
:风险计算、工具应用)
信息安全工程师-网络安全风险评估(下篇):风险计算、工具应用
一、引言风险评估是软考信息安全工程师考试中风险管理模块的核心考点,分值占比约 8%-12%,涵盖客观题、案例分析题两类题型。从技术定位来看,风险评估是连接安全需求与安全建设的核心枢纽,其输出结果直接作为安全策略制定、安全措施…...

千万级用户购物车系统的架构设计
我们当时搞的购物车服务,其实还是有点庞大的,看似是一个简单的CRUD,但是当你真正去实现一个购物车的时候,发现压根不是那回事。 当商品类型从单一SKU扩展到普通商品、套餐组合、活动商品,拼单等混合的时候,…...