离线数仓同步数据3
业务数据_增量表数据同步
- 1)Flume配置概述
- 2)Flume配置实操
- 3)通道测试
- 4)编写Flume启停脚本
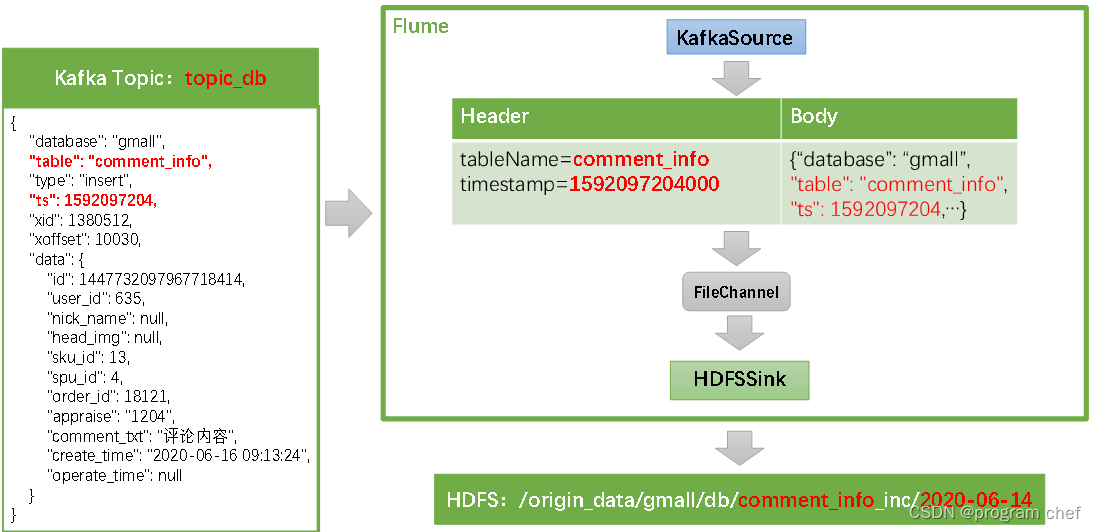
1)Flume配置概述
Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSink,Channel选用FileChannel。
需要注意的是, HDFSSink需要将不同mysql业务表的数据写到不同的路径,并且路径中应当包含一层日期,用于区分每天的数据。关键配置如下:
2)Flume配置实操
(1)创建Flume配置文件
在hadoop104节点的Flume的job目录下创建kafka_to_hdfs_db.conf
[atguigu@hadoop104 flume]$ mkdir job
[atguigu@hadoop104 flume]$ vim job/kafka_to_hdfs_db.conf
(2)配置文件内容如下
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampAndTableNameInterceptor$Buildera1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1(3)编写Flume拦截器
新建一个Maven项目,并在pom.xml文件中加入如下配置
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency>
</dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>在com.atguigu.gmall.flume.interceptor包下创建TimestampAndTableNameInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class TimestampAndTableNameInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);JSONObject jsonObject = JSONObject.parseObject(log);Long ts = jsonObject.getLong("ts");//Maxwell输出的数据中的ts字段时间戳单位为秒,Flume HDFSSink要求单位为毫秒String timeMills = String.valueOf(ts * 1000);String tableName = jsonObject.getString("table");headers.put("timestamp", timeMills);headers.put("tableName", tableName);return event;}@Overridepublic List<Event> intercept(List<Event> events) {for (Event event : events) {intercept(event);}return events;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new TimestampAndTableNameInterceptor ();}@Overridepublic void configure(Context context) {}}
}重新打包
将打好的包放入到hadoop104的/opt/module/flume/lib文件夹下
[atguigu@hadoop102 lib]$ ls | grep interceptor
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar3)通道测试
(1)启动Zookeeper、Kafka集群
(2)启动hadoop104的Flume
[atguigu@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_db.conf -Dflume.root.logger=info,console
(3)生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
(4)观察HDFS上的目标路径是否有数据出现
若HDFS上的目标路径已有增量表的数据出现了,就证明数据通道已经打通。
(5)数据目标路径的日期说明
仔细观察,会发现目标路径中的日期,并非模拟数据的业务日期,而是当前日期。这是由于Maxwell输出的JSON字符串中的ts字段的值,是数据的变动日期。而真实场景下,数据的业务日期与变动日期应当是一致的。4)编写Flume启停脚本
为方便使用,此处编写一个Flume的启停脚本
(1)在hadoop102节点的/home/atguigu/bin目录下创建脚本f3.sh
[atguigu@hadoop102 bin]$ vim f3.sh在脚本中填写如下内容
#!/bin/bashcase $1 in
"start")echo " --------启动 hadoop104 业务数据flume-------"ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")echo " --------停止 hadoop104 业务数据flume-------"ssh hadoop104 "ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f3.sh
(3)f3启动
[atguigu@hadoop102 module]$ f3.sh start
(4)f3停止
[atguigu@hadoop102 module]$ f3.sh stop2.2.6.3 Maxwell配置
1)Maxwell时间戳问题此处为了模拟真实环境,对Maxwell源码进行了改动,增加了一个参数mock_date,该参数的作用就是指定Maxwell输出JSON字符串的ts时间戳的日期,接下来进行测试。
修改Maxwell配置文件config.properties,增加mock_date参数,如下
log_level=infoproducer=kafka
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092#kafka topic配置
kafka_topic=topic_db#注:该参数仅在maxwell教学版中存在,修改该参数后重启Maxwell才可生效
mock_date=2020-06-14# mysql login info
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
注:该参数仅供学习使用,修改该参数后重启Maxwell才可生效。
重启Maxwell
[atguigu@hadoop102 bin]$ mxw.sh restart
重新生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
观察HDFS目标路径日期是否正常2.2.6.4 增量表首日全量同步
通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起见,下面编写一个增量表首日全量同步脚本。
1)在~/bin目录创建mysql_to_kafka_inc_init.sh
[atguigu@hadoop102 bin]$ vim mysql_to_kafka_inc_init.sh
脚本内容如下
#!/bin/bash# 该脚本的作用是初始化所有的增量表,只需执行一次MAXWELL_HOME=/opt/module/maxwellimport_data() {$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}case $1 in
"cart_info")import_data cart_info;;
"comment_info")import_data comment_info;;
"coupon_use")import_data coupon_use;;
"favor_info")import_data favor_info;;
"order_detail")import_data order_detail;;
"order_detail_activity")import_data order_detail_activity;;
"order_detail_coupon")import_data order_detail_coupon;;
"order_info")import_data order_info;;
"order_refund_info")import_data order_refund_info;;
"order_status_log")import_data order_status_log;;
"payment_info")import_data payment_info;;
"refund_payment")import_data refund_payment;;
"user_info")import_data user_info;;
"all")import_data cart_infoimport_data comment_infoimport_data coupon_useimport_data favor_infoimport_data order_detailimport_data order_detail_activityimport_data order_detail_couponimport_data order_infoimport_data order_refund_infoimport_data order_status_logimport_data payment_infoimport_data refund_paymentimport_data user_info;;
esac
2)为mysql_to_kafka_inc_init.sh增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/mysql_to_kafka_inc_init.sh3)测试同步脚本
(1)清理历史数据
为方便查看结果,现将HDFS上之前同步的增量表数据删除
[atguigu@hadoop102 ~]$ hadoop fs -ls /origin_data/gmall/db | grep _inc | awk '{print KaTeX parse error: Expected 'EOF', got '}' at position 2: 8}̲' | xargs hadoo… mysql_to_kafka_inc_init.sh all
4)检查同步结果
观察HDFS上是否重新出现增量表数据。
2.3 采集通道启动/停止脚本
1)在/home/atguigu/bin目录下创建脚本cluster.sh
[atguigu@hadoop102 bin]$ vim cluster.sh在脚本中填写如下内容
#!/bin/bashcase $1 in
"start"){echo ================== 启动 集群 ==================#启动 Zookeeper集群zk.sh start#启动 Hadoop集群hdp.sh start#启动 Kafka采集集群kf.sh start#启动采集 Flumef1.sh start#启动日志消费 Flumef2.sh start#启动业务消费 Flumef3.sh start#启动 maxwellmxw.sh start};;
"stop"){echo ================== 停止 集群 ==================#停止 Maxwellmxw.sh stop#停止 业务消费Flumef3.sh stop#停止 日志消费Flumef2.sh stop#停止 日志采集Flumef1.sh stop#停止 Kafka采集集群kf.sh stop#停止 Hadoop集群hdp.sh stop#停止 Zookeeper集群zk.sh stop};;
esac2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 cluster.sh
3)cluster集群启动脚本
[atguigu@hadoop102 module]$ cluster.sh start
4)cluster集群停止脚本
[atguigu@hadoop102 module]$ cluster.sh stop
相关文章:
离线数仓同步数据3
业务数据_增量表数据同步 1)Flume配置概述2)Flume配置实操3)通道测试4)编写Flume启停脚本 1)Flume配置概述 Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSinkÿ…...
Prometheus+Grafana 搭建应用监控系统
一、背景 完善的监控系统可以提高应用的可用性和可靠性,在提供更优质服务的前提下,降低运维的投入和工作量,为用户带来更多的商业利益和客户体验。下面就带大家彻底搞懂监控系统,使用Prometheus Grafana搭建完整的应用监控系统。 …...

Spring Boot整合Log4j2.xml的问题
文章目录 问题解决参考 问题 Spring Boot整合Log4j2.xml的时候返回以下错误: Caused by: org.apache.logging.log4j.LoggingException: log4j-slf4j-impl cannot be present with log4j-to-slf4j 进行了解决。 解决 Spring Boot整合Log4j2.xml经过以下操作&#…...
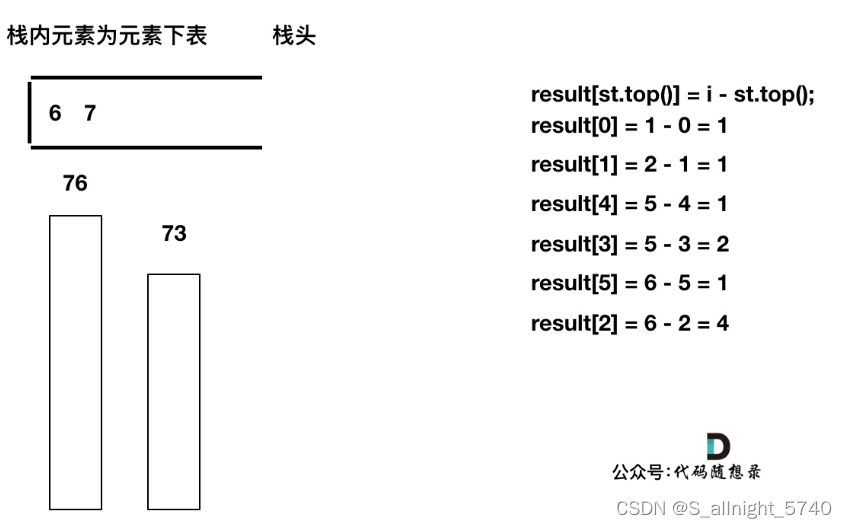
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I
代码随想录算法训练营第五十八天 | 739. 每日温度,496.下一个更大元素 I 739. 每日温度496.下一个更大元素 I 739. 每日温度 题目链接 视频讲解 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answe…...

【动手学深度学习】--文本预处理
文章目录 文本预处理1.读取数据集2.词元化3.词表4.整合所有功能 文本预处理 学习视频:文本预处理【动手学深度学习v2】 官方笔记:文本预处理 对于序列数据处理问题,在【序列模型】中评估了所需的统计工具和预测时面临的挑战,这…...

2023年最佳研发管理平台评选:哪家表现出色?
“研发管理平台哪家好?以下是一些知名的研发管理软件品牌:Zoho Projects、JIRA、Trello、Microsoft Teams、GitLab。’” 企业需要不断创新以保持竞争力。研发是企业创新的核心,而研发管理平台则为企业提供了一个有效的工具来支持和管理其研发…...

轻量容器引擎Docker基础使用
轻量容器引擎Docker Docker是什么 Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。 它基于 Google 公司推出的 Go 语言实现,项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,…...

questions
1.JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境 JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需…...
MojoTween:使用「Burst、Jobs、Collections、Mathematics」优化实现的Unity顶级「Tween动画引擎」
MojoTween是一个令人惊叹的Tween动画引擎,针对C#和Unity进行了高度优化,使用了Burst、Jobs、Collections、Mathematics等新技术编码。 MojoTween提供了一套完整的解决方案,将Tween动画应用于Unity Objects的各个方面,并可以通过E…...

Vue3响应式源码实现
Vue3响应式源码实现 初始化项目结构 vue-proxy ├── effect.js ├── effect.ts ├── index.html ├── index.js ├── package.json ├── reactive.js ├── reactive.ts └── webpack.config.jsreactive.ts import { track, trigger } from "./effect&q…...

【RapidAI】P1 中文文本切割程序
中文文本切割程序 基本信息代码解析相关包获取 yaml 关键文件类的构造函数切分语句部分特殊处理 PDF重点切分去除数组中空字符串再度切分后长度 附录附录一:完整代码附录二:可继续思考问题 基本信息 文件名: chinese_text_splitter.py 文件地…...

4、QT中的网络编程
一、Linux中的网络编程 1、子网和公网的概念 子网网络:局域网,只能进行内网的通信公网网络:因特网,服务器等可以进行远程的通信 2、网络分层模型 4层模型:应用层、传输层、网络层、物理层 应用层:用户自…...
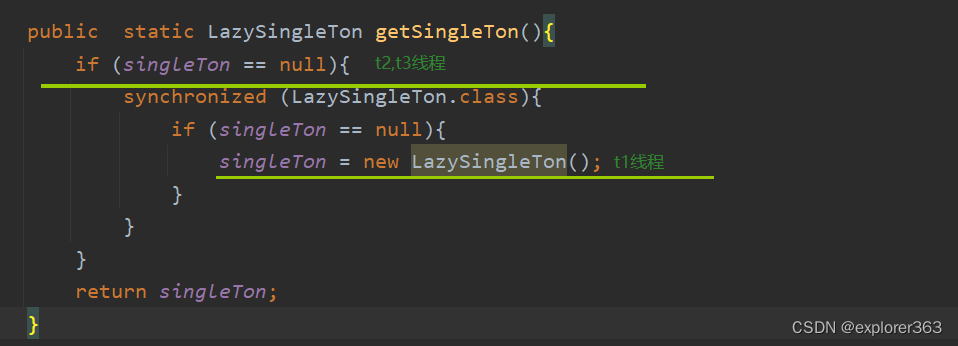
单例模式(饿汉式单例 VS 懒汉式单例)
所谓的单例模式就是保证某个类在程序中只有一个对象 一、如何控制只产生一个对象? 1.构造方法私有化(保证对象的产生个数) 创建类的对象,要通过构造方法产生对象 构造方法若是public权限,对于类的外部,可…...

Oracle数据库连接之TNS-12541异常
在进行数据库开发的时候,通常需要使用PLSQL Developer开发工具连接Oralce数据库,在进行连接时,经常性的会提示TNS-12541:TNS:no listener(没有监听),从而导致PLSQL Developer 无法连接到数据库实例…...
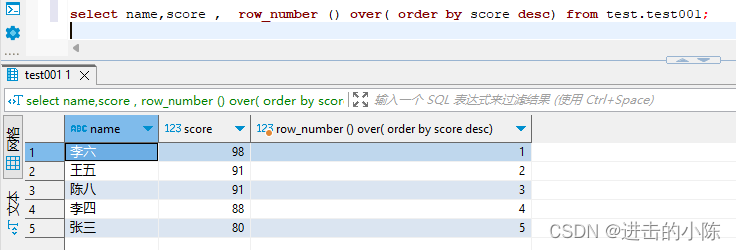
sql中的排序函数dense_rank(),RANK()和row_number()
dense_rank(),RANK()和row_number()是SQL中的排序函数。 为方便后面的函数差异比对清晰直观,准备数据表如下: 1.dense_rank() 函数语法:dense_rank() over( order by 列名 【desc/asc】) DENSE_RANK()是连续排序,比如…...

Flask狼书笔记 | 05_数据库
文章目录 5 数据库5.1 数据库的分类5.2 ORM5.3 使用Flask_SQLAlchemy5.4 数据库操作5.5 定义关系5.6 更新数据库表5.7 数据库进阶小结 5 数据库 这一章学习如何在Python中使用DBMS(数据库管理系统),来对数据库进行管理和操作。本书使用SQLit…...

HJ70 矩阵乘法计算量估算
Powered by:NEFU AB-IN Link 文章目录 HJ70 矩阵乘法计算量估算题意思路代码 HJ70 矩阵乘法计算量估算 题意 矩阵乘法的运算量与矩阵乘法的顺序强相关。 例如: A是一个5010的矩阵,B是1020的矩阵,C是205的矩阵 计算ABC有两种顺序:…...

Doris数据库使用记录
新建表 create table tonly_attendance(vin varchar(64),diggings_name varchar(256),area varchar(64),diggings_type varchar(256),work_time decimal(20,2),engine_run_time decimal(20,2),upload_time varchar(64))DUPLICATE KEY (vin)distributed by hash (vin)删除之…...

华为OD机试真题【篮球比赛】
1、题目描述 【篮球比赛】 一个有N个选手参加比赛,选手编号为1~N(3<N<100),有M(3<M<10)个评委对选手进行打分。 打分规则为每个评委对选手打分,最高分10分,最低分1分。…...
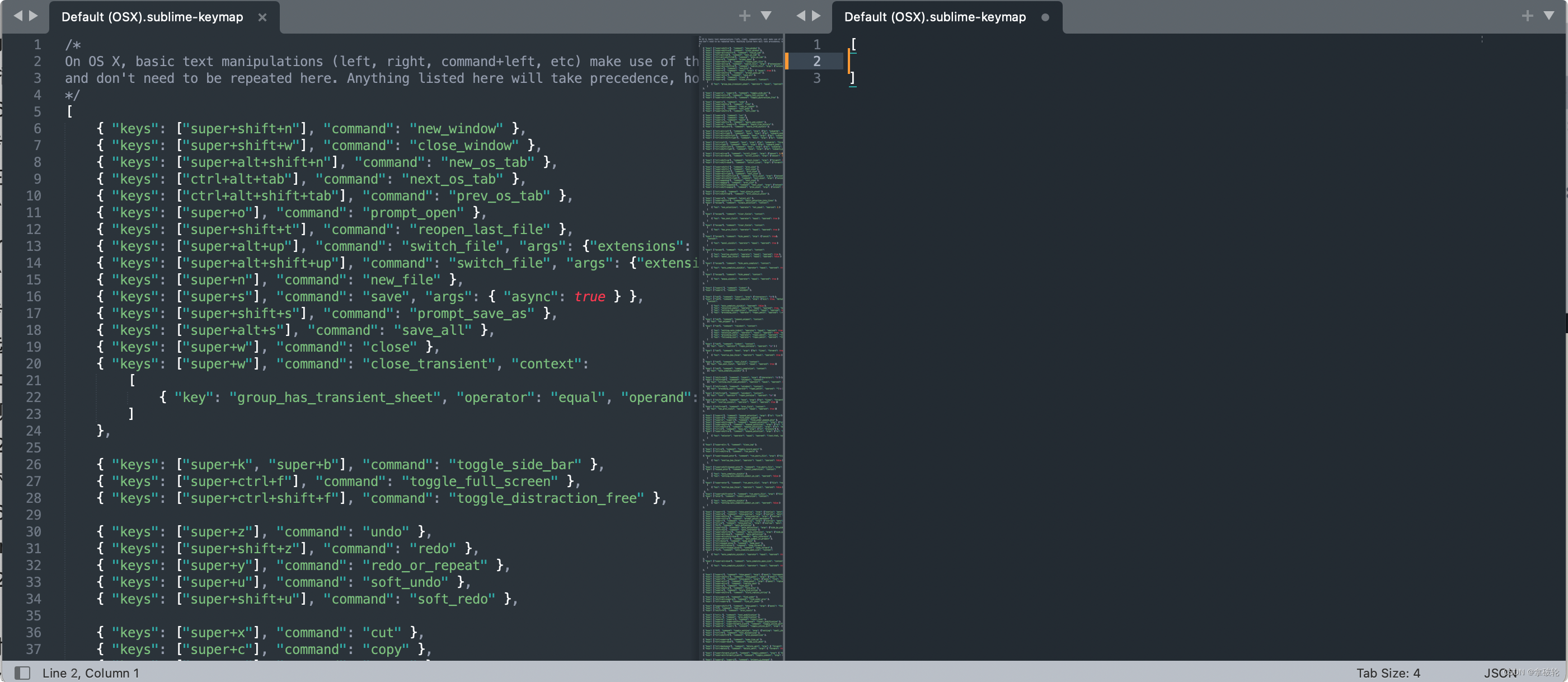
sublime text 格式化json快捷键配置
以 controlcommandj 为例。 打开Sublime Text,依次点击左上角菜单Sublime Text->Preferences->Key Bindings,出现以下文件: 左边的是Sublime Text默认的快捷键,不可编辑。右边是我们自定义快捷键的地方,在中括号…...

编写程序统计行业招聘薪资行情数据,智能比对企业薪资标准,优化薪资体系,减少企业人才流失问题。
一、实际应用场景描述在中型及以上企业的人力资源管理中,经常出现:- 企业需制定或调整岗位薪资标准(Salary Band)- 市场上同岗位薪资随城市、行业、经验年限波动明显- 企业内部薪资数据分散在 HR 系统 / Excel 中,缺乏…...
:API调用失败率<0.8%的私有化部署方案首次公开)
Sora 2国内可用性深度测评(2024Q2最新版):API调用失败率<0.8%的私有化部署方案首次公开
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Sora 2视频生成怎么用 Sora 2 并非 OpenAI 官方发布的模型——截至目前(2024年中),OpenAI 仅公开了 Sora(初代)的演示能力࿰…...

2026年主流地图API AI功能开发与零代码工具横评
核心观点摘要 行业趋势判断:AI与零代码正深度融合地图API开发,推动位置智能从专业编码向业务自助快速演进,2026年主流平台将在多模态数据融合与行业化场景能力上形成分水岭。选型关键维度:需综合考量数据覆盖广度、模型智能水平、…...
)
别再对着乱码发愁了!手把手教你用Python解码AIS VDM暗码(附完整代码)
从AIS暗码到可读数据:Python实战解析指南 当你第一次看到类似!AIVDM,1,1,,A,169DvlgP1R8KPtvFBfOCt3?h0RT,0*03这样的字符串时,可能会感到一头雾水。这串看似随机的字符实际上是AIS(船舶自动识别系统)传输的VDM(VHF Data-link Message)报文,…...

ARM HCR_EL2寄存器解析与虚拟化控制
1. ARM HCR_EL2寄存器架构解析HCR_EL2(Hypervisor Configuration Register)是ARMv8/v9架构中用于控制虚拟化行为的关键系统寄存器。作为Hypervisor的主要控制接口,它定义了EL2对低特权级(EL1/EL0)执行环境的监控策略。…...

从微信小程序转战uniapp,我总结的路由跳转对照表与迁移心得
从微信小程序到Uniapp:路由跳转深度迁移指南与实战避坑 第一次在Uniapp项目里看到uni.navigateTo这个API时,我下意识地以为它和微信小程序的wx.navigateTo完全一样——直到某个深夜,测试同学突然报告说iOS设备上连续跳转7个页面后应用直接闪退…...

为什么92%的AI团队误用DeepSeek Serverless?——基于37家客户架构审计报告的5大认知断层与重构路径
更多请点击: https://intelliparadigm.com 第一章:为什么92%的AI团队误用DeepSeek Serverless? DeepSeek Serverless 本为轻量推理与函数即服务(FaaS)场景设计,但大量团队将其当作通用模型托管平台使用&am…...
)
Docker Compose 镜像检测脚本(支持自动扫描 + 手动输入 YAML)
在日常运维中,经常会遇到这样一个问题: docker-compose 文件里定义了很多镜像,但本地是否已经存在不清楚 如果一个个 docker pull 或 docker images 去对比,会非常低效。 因此我们可以写一个脚本,自动解析 docker-com…...

WaveTools:鸣潮玩家的终极优化工具箱,轻松解锁120FPS流畅体验
WaveTools:鸣潮玩家的终极优化工具箱,轻松解锁120FPS流畅体验 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 你是否曾经在《鸣潮》的激烈战斗中感受到画面卡顿?是否因为…...

Docker 部署 XiuXianGame 文字修仙游戏:极空间 NAS 上随时挂机刷资源
前言 挂机刷资源,躺平修成仙。 这类文字修仙游戏,说白了就是佛系养成为主,不用时刻盯着,挂着就行。但问题是——大多数要么得在本地电脑跑,要么依赖第三方平台,体验受限。把这套东西跑在自己的 NAS 上&am…...