Kubernetes(k8s)安装NFS动态供给存储类并安装KubeSphere
Kubernetes安装NFS动态供给存储类并安装KubeSphere
- KubeSphere介绍
- 环境准备
- KubeSphere
- NFS动态供给
- 安装NFS动态供给
- 搭建NFS
- 下载动态供给驱动
- 修改驱动文件
- 安装动态供给
- 安装KubeSphere
- 下载KubeSphere的yaml资源清单文件
- 安装KubeSphere
- 使用KubeSphere部署应用
- 创建项目
- 部署MySQL
KubeSphere介绍
它是一款全栈的 Kubernetes 容器云 PaaS 解决方案(来源于官网),而我觉得它是一款强大的Kubernetes图形界面,它继承了如下组件 (下面这段内容来自官网):
- Kubernetes DevOps 系统
- 基于 Jenkins 为引擎打造的 CI/CD,内置 Source-to-Image 和 Binary-to-Image 自动化打包部署工具
- 基于 Istio 的微服务治理
- 提供细粒度的流量管理、流量监控、灰度发布、分布式追踪,支持可视化的流量拓扑
- 丰富的云原生可观测性
- 提供多维度与多租户的监控、日志、事件、审计搜索,支持多种告警策略与通知渠道,支持日志转发
- 云原生应用商店
- 提供基于 Helm 的应用商店与应用仓库,内置多个应用模板,支持应用生命周期管理
- Kubernetes 多集群管理
- 跨多云与多集群统一分发应用,提供集群高可用与灾备的最佳实践,支持跨级群的可观测性
- Kubernetes 边缘节点管理
- 基于 KubeEdge 实现应用与工作负载在云端与边缘节点的统一分发与管理,解决在海量边、端设备上完成应用交付、运维、管控的需求
当然他的功能远不止这些,欢迎各位来到KubeSphere的官网了解更多内容:https://www.kubesphere.io/zh/
环境准备
KubeSphere
(摘自官网)
- 您的 Kubernetes 版本必须为:v1.20.x、v1.21.x、* v1.22.x、* v1.23.x、* v1.24.x、* v1.25.x 和 * v1.26.x。带星号的版本可能出现边缘节点部分功能不可用的情况。因此,如需使用边缘节点,推荐安装 v1.21.x。
- 确保您的机器满足最低硬件要求:CPU > 1 核,内存 > 2 GB。
- 在安装之前,需要配置 Kubernetes 集群中的默认存储类型(这篇文章会介绍安装)。
我已经准备好了一个Kubernetes集群,如图:

符合KubeSphere的支持边缘节点的最高版本要求,但建议你版本号不要超过 v1.26.x 。
NFS动态供给
首先你需要准备一台NFS服务器,为了方便,我这次就以我的主服务器 k8s-master 来担任这个NFS服务器了。
安装NFS动态供给
搭建NFS
首先我们需要在NFS服务器(我的NFS服务器和master是同一台)和所有k8s节点当中安装 nfs-utils 软件包(master和node都需要安装),可执行下面这行命令:
yum install -y nfs-utils
安装如图:

然后确定一个nfs共享的目录,这次我就使用 /data/nfs/dynamic-provisioner 这个目录作为nfs的共享目录了。所以我们来执行下面命令创建并共享这个目录:
# 创建这个目录
mkdir -p /data/nfs/dynamic-provisioner
# 执行这行命令将这个目录写到写到 /etc/exports 文件当中去,这样NFS会对局域网暴露这个目录
cat >> /etc/exports << EOF
/data/nfs/dynamic-provisioner *(rw,sync,no_root_squash)
EOF
# 启动NFS服务
systemctl enable --now nfs-server
执行后如图:

检查是否暴露成功:
showmount -e {nfs服务器地址}
可以看到是暴露成功的:

下载动态供给驱动
因为Kubernetes自己不自带NFS动态供给的驱动,所以我们需要下载第三方的NFS动态供给驱动。Kubernetes官方推荐了两个第三方的驱动可供选择,如图:

个人觉得这个 NFS subdir 驱动比较好用,这次就用这个驱动来搭建动态供给了。我们可以来到它的官网:https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner,并找到最新的release:

目前最新的发行版是 4.0.18 我们就下载这个版本:

也可直接通过命令下载:
wget https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner/archive/refs/tags/nfs-subdir-external-provisioner-4.0.18.tar.gz
下载成功如图:

我们直接解压它:
tar -zxvf nfs-subdir-external-provisioner-4.0.18.tar.gz
解压之后会获得一个特别长的文件夹:

修改驱动文件
我们来到这个文件夹下的deploy目录:
cd nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.18/deploy/
可以看到这里面有一些yaml,我们需要修改一部分:

首先我们需要修改的就是 deployment.yaml ,我们直接用vim修改:
vim deployment.yaml
首先就是这个镜像是在谷歌的k8s官方镜像仓库拉取的,国内拉取不到,所以我们要修改一下:

我已经通过一些方法将它拉取下来并且上传到了国内的阿里云镜像仓库,我们可以直接用下面这个镜像来替换:
# 这个镜像是在谷歌上的,国内拉取不到
# image: registry.k8s.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
# 使用这个我先在谷歌上拉取下来再上传到阿里云上的镜像
image: registry.cn-shenzhen.aliyuncs.com/xiaohh-docker/nfs-subdir-external-provisioner:v4.0.2
修改后如图:

然后我们还需要修改一下下面的nfs服务器地址和nfs服务器内共享的目录:

我的nfs服务器地址为 172.18.0.2 ,且按照上面的安装步骤,我nfs服务器暴露的共享目录为 /data/nfs/dynamic-provisioner ,所以我修改文件为(你的有可能和我不一样,根据自己设置的共享目录和nfs服务器地址修改此文件):

执行下面这一段脚本我们可以看到还是有很多资源是存放在默认命名空间下:
yamls=$(grep -rl 'namespace: default' ./)
for yaml in ${yamls}; doecho ${yaml}cat ${yaml} | grep 'namespace: default'
done
执行结果:

我们可以新创建一个命名空间专门装这个驱动,也方便以后管理,所以我决定创建一个名为 nfs-provisioner 命名空间,为了方便就不用yaml文件了,直接通过命令创建:
kubectl create namespace nfs-provisioner
执行后可以看到这个命名空间创建成功:

涉及命名空间这个配置的文件还挺多的,所以我们干脆通过一行脚本更改所有:
sed -i 's/namespace: default/namespace: nfs-provisioner/g' `grep -rl 'namespace: default' ./`
这行批量替换脚本直接将所有文件的命名空间都改过来了:

安装动态供给
之前我们已经修改好了所有的yaml资源清单文件,接下来我们直接执行安装。安装也是非常简单,直接通过下面一行命令就可以安装完成:
kubectl apply -k .
执行结果如图:

可以执行下面这个行命令查看是否部署完成:
kubectl get all -o wide -n nfs-provisioner
看到READY为 1/1 并且STATUS状态为 Running 那么动态供给就已经部署完毕:

可以执行下面命令查询安装的动态供应存储类的名字:
kubectl get storageclass
可以看到动态供应类的名字为 nfs-client :

nfs动态供应就已经安装完毕了
如果你只打算安装动态供给的存储类,那么到这里就结束了哦,接下来是KubeSphere相关的内容
安装KubeSphere
下载KubeSphere的yaml资源清单文件
此次安装的是最新的 v3.4.0 的 KubeSphere,可以通过以下命令下载资源清单文件(共两个):
wget \
https://github.com/kubesphere/ks-installer/releases/download/v3.4.0/kubesphere-installer.yaml \
https://github.com/kubesphere/ks-installer/releases/download/v3.4.0/cluster-configuration.yaml
可以看到一共下载了两个文件:

其中这两个文件的作用:
- kubesphere-installer.yaml: KubeSphere的安装器
- cluster-configuration.yaml: KubeSphere的集群配置文件
我们需要修改一下 cluster-configuration.yaml 文件,还记得我们之前的那个存储类吗?我们记住这个名字:

然后我们开始修改这个文件:
vim cluster-configuration.yaml
可以看到后面注释的说明,所以我们将 nfs-client 这个存储类的名字写在后面:

安装KubeSphere
然后我们先创建 kubesphere-installer.yaml 里面的资源:
kubectl apply -f kubesphere-installer.yaml
可以看到创建了一些资源:

然后我们检查这个资源是否创建成功:
kubectl get pod -o wide -n kubesphere-system
同样当READY为 1/1 并且STATUS状态为 Running 的时候这个文件就执行完毕了:

接下来我们来执行 cluster-configuration.yaml 文件:
kubectl apply -f cluster-configuration.yaml
它虽然只有一个资源,但是里面还是要做很多事的:

执行下面命令检查KubeSphere的执行日志:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
一段时间之后看到这个就是安装成功了:

因为我使用的是云服务器,所以我使用任何一个云服务器的公网IP地址+端口就能访问KubeSphere了,默认的用户名/密码是 admin/P@88w0rd:

初次登陆需要修改admin用户的密码:

随后即可以登录到KubeSphere的首页了:

同时我们来到NFS服务器共享的目录,可以看到KubeSphere的持久化数据存储在这:

使用KubeSphere部署应用
创建项目
因为KubeSphere的管理是基于项目的,所以我们先要创建一个项目,先点击企业空间:

选择这个默认企业(一般是新建一个企业,这里就简化了):

然后点击项目->创建:

创建一个测试项目:

创建一个项目其实就是创建了一个命名空间:

部署MySQL
现在我们开始部署MySQL了,点击这个刚创建的项目:

然后依次点击 工作负载->有状态副本集->创建:

填写部署一个测试的数据库然后点击下一步:

点击添加容器:

搜索指定的镜像并填写要创建的容器名字:

网下面拉可以设置CPU和内存限制还有需要使用的端口:

然后我们往下拉勾选环境变量,然后点击创建保密字典:

我们来设置mysql的密码,这个名字可以随便写,但是自己要记住:

类型选择默认后点击添加数据:

在这里设置mysql的root用户密码:

然后点击创建:

最后创建的Secret会自动填充,但是注意MySQL设置root用户密码的环境变量名不能自定义,是由Docker规定死的 MYSQL_ROOT_PASSWORD:

点击勾选同步主机时区:

点击下面的对勾✅:

最后点击下一步:

到了下一步点击添加持久卷声明模版:

然后按照提示输入内容:

最后点击下一步:

点击创建:

点击部署的这个mysql进来:

可以看到容器状态并且可以快速伸缩容器:

当这个变绿了就代表创建好了:

然后点击容器右边的向下的小箭头,最后点击终端:

最后在终端中即可运行mysql相关的命令了:

这篇文章就先写到这里,更多的KubeSphere操作,可以登录KubeSphere的官网了解,关注我,我以后一会写更多相关知识的哦!
KubeSphere官网:https://www.kubesphere.io/zh/
相关文章:
Kubernetes(k8s)安装NFS动态供给存储类并安装KubeSphere
Kubernetes安装NFS动态供给存储类并安装KubeSphere KubeSphere介绍环境准备KubeSphereNFS动态供给 安装NFS动态供给搭建NFS下载动态供给驱动修改驱动文件安装动态供给 安装KubeSphere下载KubeSphere的yaml资源清单文件安装KubeSphere 使用KubeSphere部署应用创建项目部署MySQL …...

机器学习笔记 - 【机器学习案例】基于KerasCV的预训练模型自定义多头+多标签预测
一、KerasCV KerasCV 是一个模块化计算机视觉组件库,可与 TensorFlow、JAX 或 PyTorch 原生配合使用。这些模型、层、指标、回调等基于Keras Core构建,可以在任何框架中进行训练和序列化,并在另一个框架中重复使用,而无需进行昂贵的迁 KerasCV 可以理解为 Keras API 的水平…...

Linux Debian常用70条经典运维命令和使用案例
一、前言 今天分享一些Linux Debian运维方法以及常用命令 二、运维方法 Linux Debian系统的运维涉及到各种任务,包括系统安装、配置、更新和维护,以及故障排查和性能优化等。下面是一些常用的运维命令: 1、以下是部分命令注释 1. apt-ge…...

【涵子来信】——步入中学,日积跬步,以致千里
大家好: 我是涵子,好久没有发文,今天发个文。 如果说,给你一次再入中学的机会,你会怎么想?对于刚刚步入中学的我,目前状况尚好,洛谷最近刷得紧,看看我的洛谷。 好的&…...
【sgCreateAPI】自定义小工具:敏捷开发→自动化生成API接口脚本(接口代码生成工具)
<template><div :class"$options.name"><div class"sg-head">接口代码生成工具</div><div class"sg-container"><div class"sg-start "><div style"margin-bottom: 10px;">接口地…...

数据库相关基础知识
第一章 概念 1、数据:描述事物的符号记录称为数据。特点:数据和关于数据的解释不可分。 2、数据库:长期存储在计算机内、有组织、可共享的大量的数据的集合。数据库中的数据按照一定的数据模型组织、描述和存储,具有较小的冗余度、…...

LeetCode刷题笔记【23】:贪心算法专题-1(分发饼干、摆动序列、最大子序和)
文章目录 前置知识贪心算法的本质什么时候用贪心算法?什么时候不能用贪心?贪心算法的解题步骤 455.分发饼干题目描述解题思路代码 376. 摆动序列题目描述解题思路代码 53. 最大子序和题目描述暴力解法动态规划贪心算法 总结 前置知识 贪心算法的本质 贪心的本质是选择每一阶…...
C++算法 —— 分治(2)归并
文章目录 1、排序数组2、数组中的逆序对3、计算右侧小于当前元素的个数4、翻转对 本篇前提条件是已学会归并排序 1、排序数组 912. 排序数组 排序数组也可以用归并排序来做。 vector<int> tmp;//写成全局是因为如果在每一次小的排序中都创建一次,更消耗时间和…...

Hadoop YARN HA 集群安装部署详细图文教程
目录 一、YARN 集群角色、部署规划 1.1 集群角色--概述 1.2 集群角色--ResourceManager(RM) 1.3 集群角色--NodeManager(NM) 1.4 HA 集群部署规划 二、YARN RM 重启机制 2.1 概述 2.2 演示 2.2.1 不开启 RM 重启机制…...

BBS+商城项目的数据库表设计
本文章是对于BBS商城项目的数据库的初步设计,仅供参考! -- 创建用户表 CREATE TABLE Users (id bigint(20) PRIMARY KEY COMMENT 用户ID,username varchar(255) NOT NULL COMMENT 用户名,password varchar(255) NOT NULL COMMENT 密码,status int(1) DE…...

如何使用Savitzky-Golay滤波器进行轨迹平滑
一、Savitzky-Golay滤波器介绍 Savitzky-Golay滤波器是一种数字滤波器,用于平滑数据,特别是在信号处理中。它基于最小二乘法的思想,通过拟合数据到一个滑动窗口内的低阶多项式来实现平滑。这种滤波器的优点是它可以保留数据的高频信息&#…...
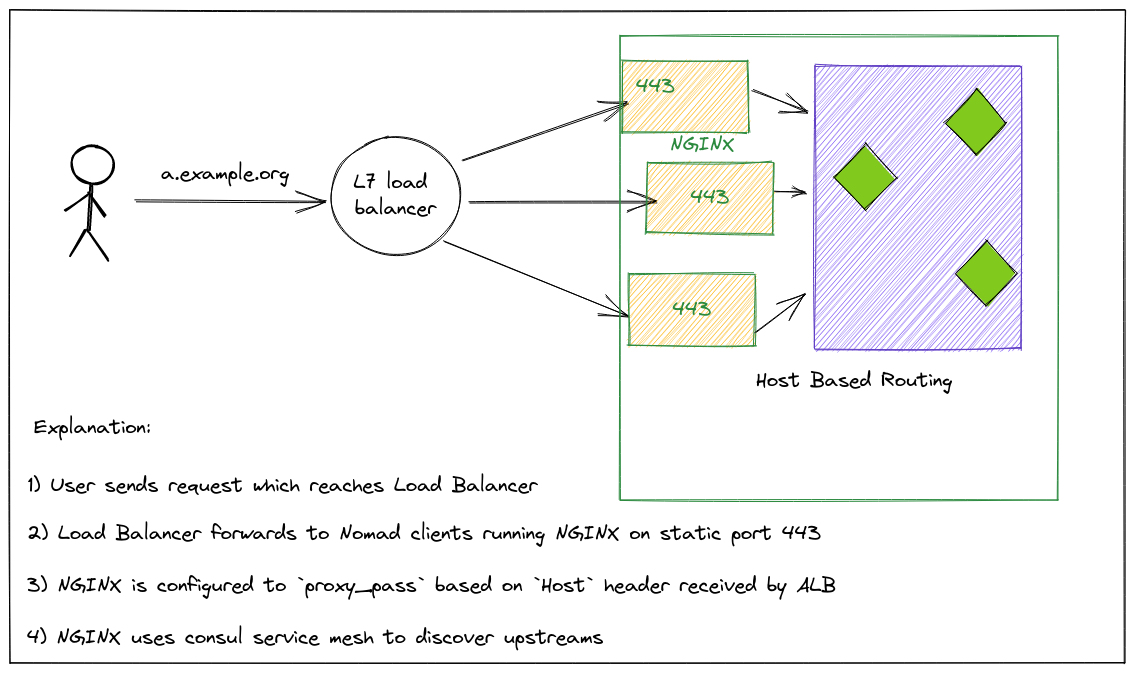
Nomad系列-Nomad网络模式
系列文章 Nomad 系列文章 概述 Nomad 的网络和 Docker 的也有很大不同, 和 K8s 的有很大不同. 另外, Nomad 不同版本(Nomad 1.3 版本前后)或是否集成 Consul 及 CNI 等不同组件也会导致网络模式各不相同. 本文详细梳理一下 Nomad 的主要几种网络模式 在Nomad 1.3发布之前&a…...

OpenCV项目开发实战--实现面部情绪识别对情绪进行识别和分类及详细讲解及完整代码实现
文末提供免费的完整代码下载链接 面部情绪识别(FER)是指根据面部表情对人类情绪进行识别和分类的过程。通过分析面部特征和模式,机器可以对一个人的情绪状态做出有根据的猜测。面部识别的这个子领域是高度跨学科的,借鉴了计算机视觉、机器学习和心理学的见解。 在这篇研究…...

Validate表单组件的封装
之前一直是直接去使用别人现成的组件库,也没有具体去了解人家的组件是怎么封装的,造轮子才会更好地提高自己,所以尝试开始从封装Form表单组件开始 一:组件需求分析 本次封装组件,主要是摸索封装组件的流程,…...

企业架构LNMP学习笔记32
企业架构LB-服务器的负载均衡之LVS实现: 学习目标和内容 1)能够了解LVS的工作方式; 2)能够安装和配置LVS负载均衡; 3)能够了解LVS-NAT的配置方式; 4)能够了解LVS-DR的配置方式&…...

基于Jetty9的Geoserver配置https证书
1.环境准备 由于Geoserver自带的jetty版本不具备https模块,所以需要下载完整版本jetty。这里需要先查看本地geoserver对应的jetty版本,进入geoserver安装目录,执行如下命令。 java -jar start.jar --version Jetty Server Classpath: -----…...

企业互联网暴露面未知资产梳理
一、互联网暴露面梳理的重要性 当前,互联网新技术的产生推动着各种网络应用的蓬勃发展,网络安全威胁逐渐蔓延到各种新兴场景中,揭示着网络安全威胁不断加速泛化。当前网络存在着许多资产,这些资产关系到企业内部的安全情况&#…...
【动态规划刷题 12】等差数列划分 最长湍流子数组
139. 单词拆分 链接: 139. 单词拆分 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。 示例 1: 输入: …...

react-redux 的使用
react-redux React Redux 是 Redux 的官方 React UI 绑定库。它使得你的 React 组件能够从 Redux store 中读取到数据,并且你可以通过dispatch actions去更新 store 中的 state 安装 npm install --save react-reduxProvider React Redux 包含一个 <Provider…...

77 # koa 中间件的应用
调用 next() 表示执行下一个中间件 const Koa require("koa");const app new Koa();app.use(async (ctx, next) > {console.log(1);next();console.log(2); });app.use(async (ctx, next) > {console.log(3);next();console.log(4); });app.use(async (ctx,…...

win2xcur:Windows光标主题完美移植Linux的格式转换指南
1. 项目概述:从Windows光标到Linux的“翻译官”如果你和我一样,是个在Linux桌面和Windows之间反复横跳的用户,或者你为团队维护着跨平台的开发环境,那你一定遇到过这个不大不小但很恼人的问题:Windows系统上那些精心设…...

6541616
56465651...

GitHub仓库自动化同步工具xpull:原理、配置与实战应用
1. 项目概述:一个被低估的GitHub数据同步利器 如果你经常在GitHub上管理多个仓库,或者需要将某个仓库的特定分支、标签甚至整个提交历史同步到另一个仓库,那么你很可能经历过手动操作的繁琐。无论是为了备份、镜像、还是将上游的更新合并到自…...
之Java自动化不同类型环境的配置浅析)
自动化(二)之Java自动化不同类型环境的配置浅析
小编本文主要是关于Java自动化环境的配置搭建与大家进行分享。 本篇内容包含(基于上篇的基础上根据不同端汇总环境配置):单元测试(JUnit5) 接口自动化(RestAssured) UI自动化(Selenium) 测试报告(Allure)。 前置必备软件&#x…...

基于Claude API的视频转录技能开发:从语音识别到AI集成实战
1. 项目概述:一个为Claude设计的视频转录技能最近在折腾AI应用开发,特别是围绕Claude API构建一些实用工具。我发现一个挺有意思的项目,叫Johncli7941/claude-skill-video-transcribe。从名字就能看出来,这是一个为Claude设计的“…...

PointLLM:让大语言模型看懂三维点云,实现具身智能与机器人交互
1. 项目概述:当大语言模型“睁开双眼”看世界最近在机器人感知与交互领域,一个名为 PointLLM 的项目引起了我的注意。它来自 InternRobotics,核心目标直指一个非常前沿且有趣的问题:如何让大语言模型(LLM)直…...

自建轻量级Web监控信标:前端性能与错误数据采集实践
1. 项目概述:一个轻量级、可扩展的Web应用监控信标最近在梳理个人项目和团队内部工具链时,我重新审视了一个名为“beacon”的小工具。这个项目源自一个非常具体的痛点:在开发和运维Web应用时,我们常常需要一种简单、无侵入的方式来…...

METSO A413150输出模块
METSO A413150 是美卓(Metso Automation)BIU 8 分布式控制系统中的一款输出模块,主要用于向现场执行机构输出模拟量控制信号。中间15个特点METSO A413150 提供8通道模拟量输出,适用于多路控制信号输出。该模块分辨率为16位&#x…...

【无人机控制】一维环境下LQR与PID控制在无人机悬停控制中的对比分析附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室🍊个人信条:格物致知,完整Matlab代码及仿真咨询…...

CSS如何实现固定页脚布局_利用calc计算高度差
最可靠的页脚固定方案是Flexbox:外层容器设min-height: 100vh和display: flex、flex-direction: column,main加flex: 1,footer保持自然高度,并重置body { margin: 0 }。页脚卡在底部但内容少时被顶上去这是 position: fixed 最常见…...