Kafka3.0.0版本——消费者(Range分区分配策略以及再平衡)
目录
- 一、Range分区分配策略原理
- 1.1、Range分区分配策略原理的示例一
- 1.2、Range分区分配策略原理的示例二
- 1.3、Range分区分配策略原理的示例注意事项
- 二、Range 分区分配策略代码案例
- 2.1、创建带有4个分区的fiveTopic主题
- 2.2、创建三个消费者 组成 消费者组
- 2.3、创建生产者
- 2.4、测试
- 2.5、Range 分区分配策略代码案例说明
- 三、Range 分区分配再平衡案例
- 3.1、停止某一个消费者后,(45s 以内)重新发送消息示例
- 3.2、停止某一个消费者后,(45s 以后)重新发送消息示例
- 3.3、Range 分区分配再平衡案例说明
一、Range分区分配策略原理
- Range 是对每个 topic 而言的。首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
1.1、Range分区分配策略原理的示例一
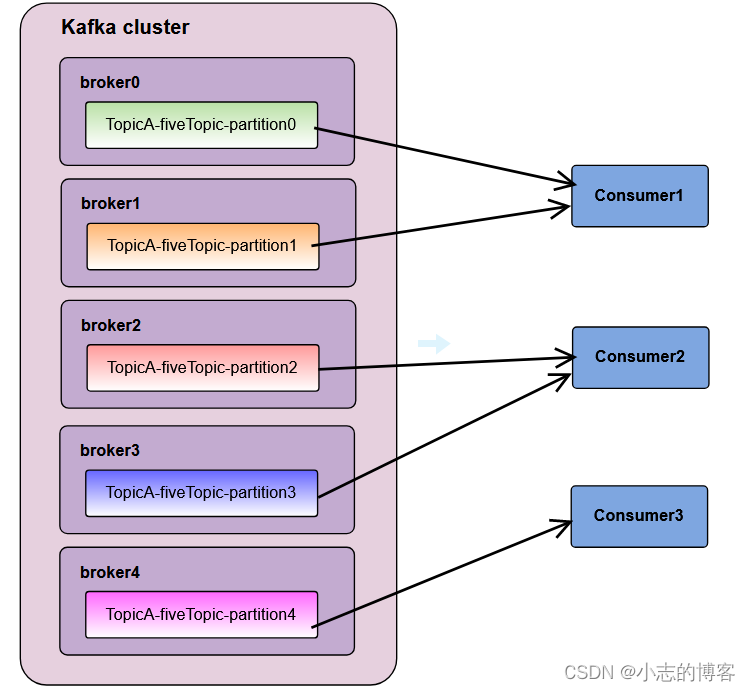
假如现在有 4 个分区,3 个消费者,排序后的分区将会是0,1,2,3;消费者排序完之后将会是C0,C1,C2。
- 通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。 如果除不尽,那么前面几个消费者将会多消费 1 个分区。
- 例如:4/3 = 1 余 1 ,除不尽,那么消费者C0便会多消费1个分区。
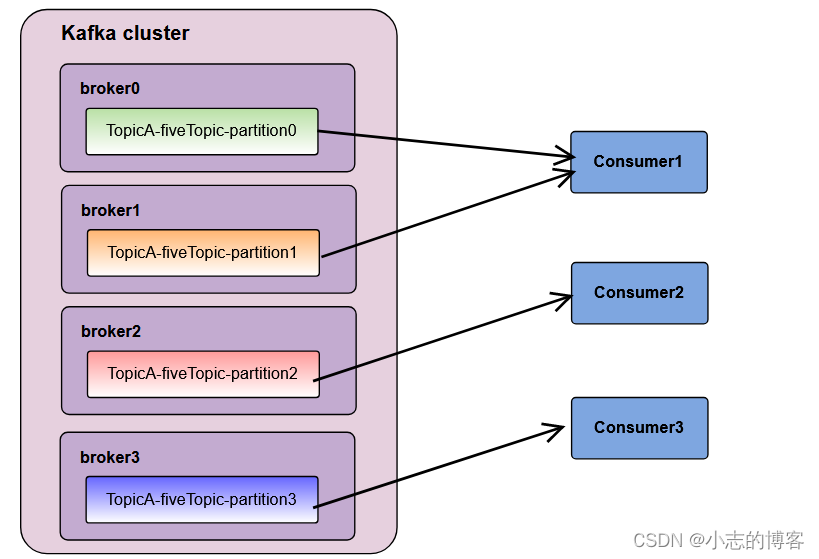
1.2、Range分区分配策略原理的示例二
假如现在有 5 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4;消费者排序完之后将会是C0,C1,C2。
- 通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。 如果除不尽,那么前面几个消费者将会多消费 1 个分区。
- 例如:5/3 = 1 余 2 ,除不尽,那么消费者么C0和C1分别多消费一个分区。
1.3、Range分区分配策略原理的示例注意事项
- 如果只是针对 1 个 topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有N多个topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费 N 个分区。 容易产生数据倾斜!
二、Range 分区分配策略代码案例
2.1、创建带有4个分区的fiveTopic主题
-
在 Kafka 集群控制台,创建带有4个分区的fiveTopic主题
bin/kafka-topics.sh --bootstrap-server 192.168.136.27:9092 --create --partitions 4 --replication-factor 1 --topic fiveTopic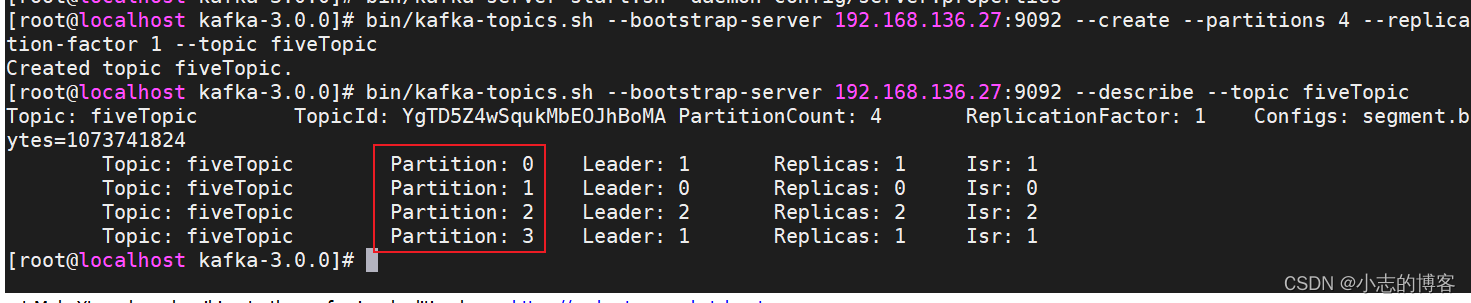
2.2、创建三个消费者 组成 消费者组
-
复制 CustomConsumer1类,创建 CustomConsumer2和CustomConsumer3。这样可以由三个消费者组成消费者组,组名都为“test”。
package com.xz.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration; import java.util.ArrayList; import java.util.Properties;public class CustomConsumer1 {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.27:9092,192.168.136.28:9092,192.168.136.29:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");// 1 创建一个消费者 "", "hello"KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("fiveTopic");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}} }
2.3、创建生产者
-
创建CustomProducer生产者。
package com.xz.kafka.producer;import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties;public class CustomProducerCallback {public static void main(String[] args) throws InterruptedException {//1、创建 kafka 生产者的配置对象Properties properties = new Properties();//2、给 kafka 配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.27:9092,192.168.136.28:9092,192.168.136.29:9092");//3、指定对应的key和value的序列化类型 key.serializer value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());//4、创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);//5、调用 send 方法,发送消息for (int i = 0; i < 200; i++) {kafkaProducer.send(new ProducerRecord<>("fiveTopic", "hello kafka" + i), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null){System.out.println("主题: "+metadata.topic() + " 分区: "+ metadata.partition());}}});Thread.sleep(2);}// 3 关闭资源kafkaProducer.close();} }
2.4、测试
-
首先,在 IDEA中分别启动消费者1、消费者2和消费者3代码
-
然后,在 IDEA中分别启动生产者代码
-
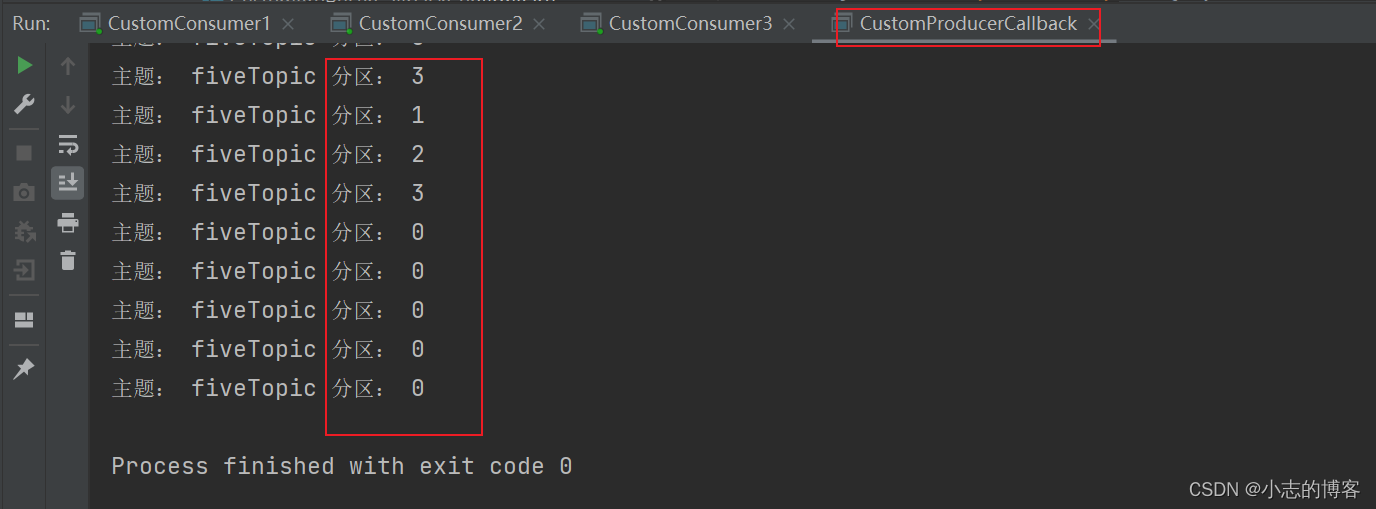
在 IDEA 控制台观察消费者1、消费者2和消费者3控制台接收到的数据,如下图所示:



2.5、Range 分区分配策略代码案例说明
- 由上述测试输出结果截图可知: 消费者1消费2分区的数据;消费者2消费0和3分区的数据;消费者3消费2分区的数据。
- 说明:Kafka 默认的分区分配策略就是 Range + CooperativeSticky,所以不需要修改策略。
三、Range 分区分配再平衡案例
3.1、停止某一个消费者后,(45s 以内)重新发送消息示例
- 由下图控制台输出可知:2号消费者 消费到 0、3号分区数据。

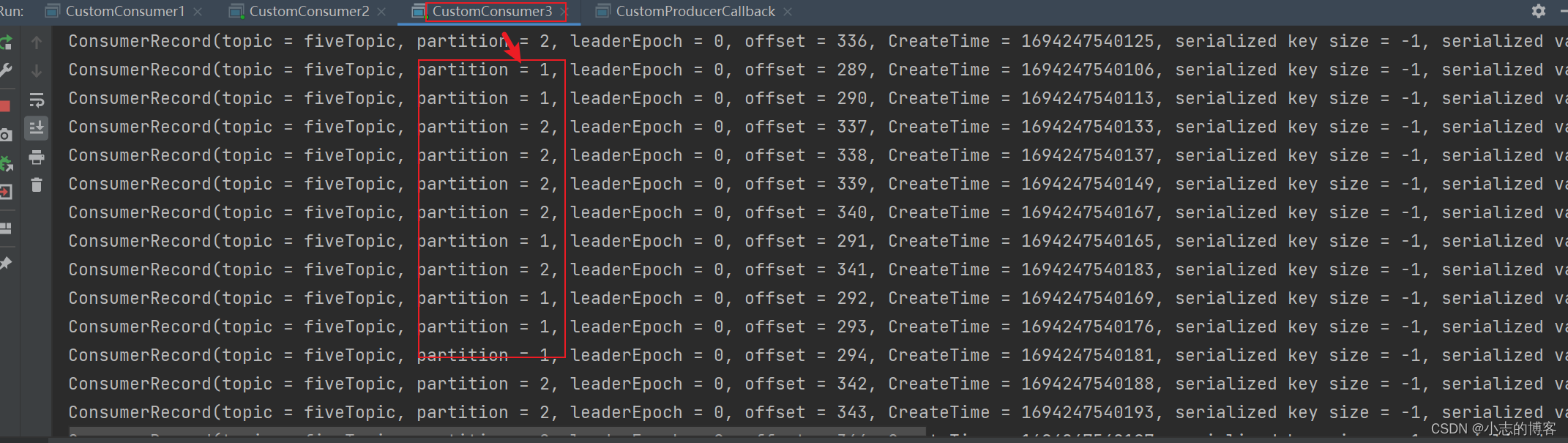
- 由下图控制台输出可知:3号消费者 消费到 1号分区数据。

3.2、停止某一个消费者后,(45s 以后)重新发送消息示例
- 由下图控制台输出可知:2号消费者 消费到 0、3号分区数据。
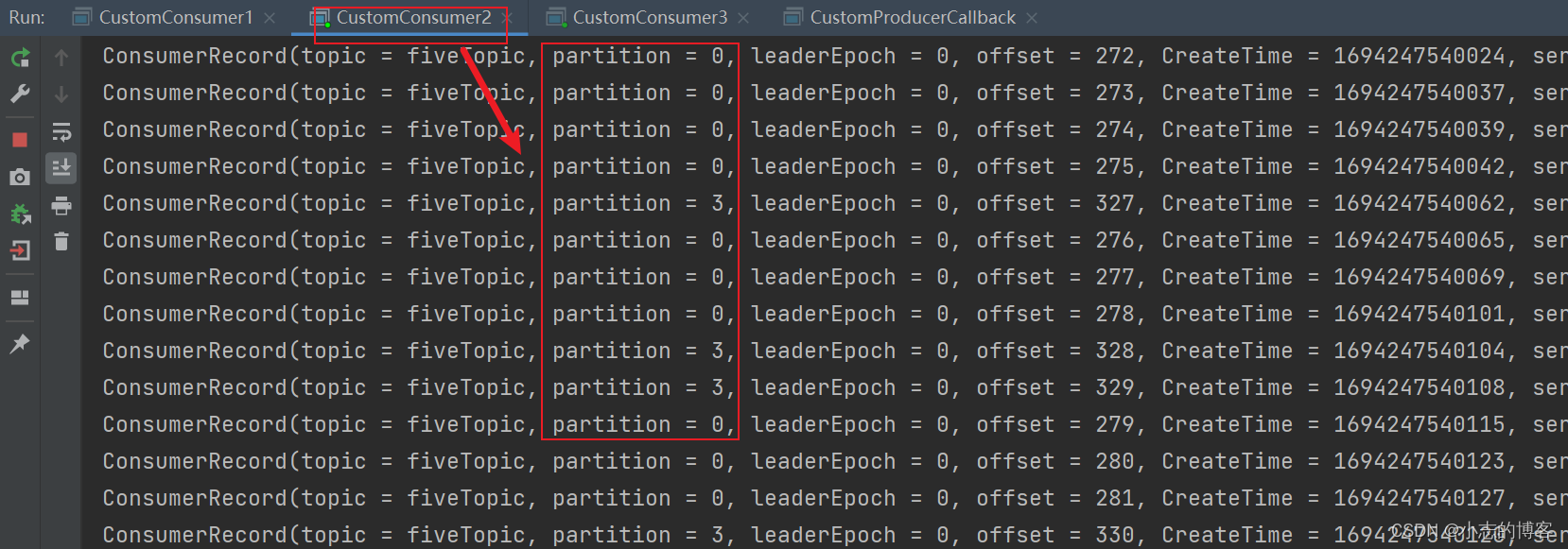
- 由下图控制台输出可知:3号消费者 消费到 1、2号分区数据。
3.3、Range 分区分配再平衡案例说明
- 1号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
- 消费者1 已经被踢出消费者组,所以重新按照 range 方式分配。
相关文章:
Kafka3.0.0版本——消费者(Range分区分配策略以及再平衡)
目录 一、Range分区分配策略原理1.1、Range分区分配策略原理的示例一1.2、Range分区分配策略原理的示例二1.3、Range分区分配策略原理的示例注意事项 二、Range 分区分配策略代码案例2.1、创建带有4个分区的fiveTopic主题2.2、创建三个消费者 组成 消费者组2.3、创建生产者2.4、…...

WeiTools
目录 1.1 WeiTools 1.2 getTime 1.3 getImageView 1.4 StringEncode 1.4.1 // TODO Auto-generated catch block WeiTools package com.shrimp.xiaoweirobot.tools;...
)
目标检测数据集:医学图像检测数据集(自己标注)
1.专栏介绍 ✨✨✨✨✨✨目标检测数据集✨✨✨✨✨✨ 本专栏提供各种场景的数据集,主要聚焦:工业缺陷检测数据集、小目标数据集、遥感数据集、红外小目标数据集,该专栏的数据集会在多个专栏进行验证,在多个数据集进行验证mAP涨点明显,尤其是小目标、遮挡物精度提升明显的…...
【系统设计系列】数据库
系统设计系列初衷 System Design Primer: 英文文档 GitHub - donnemartin/system-design-primer: Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards. 中文版: https://github.com/donnemarti…...
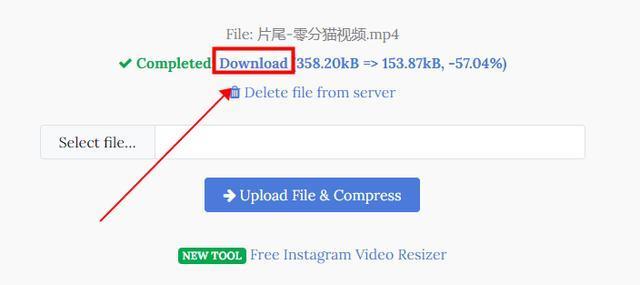
mp4压缩视频不改变画质?跟我这样压缩视频大小
在当今数字化时代,视频文件变得越来越普遍,然而,这些文件通常都很大,给存储和传输带来了困难,为了解决这个问题,许多人都希望将视频压缩得更小,而又不牺牲画质,下面就来看看具体应该…...

AQS同步队列和等待队列的同步机制
理解AQS必须要理解同步队列和等待队列之间的同步机制,简单来说流程是: 获取锁失败的线程进入同步队列,成功的占用锁,占锁线程调用await方法进入条件等待队列,其他占锁线程调用signal方法,条件等待队列线程进…...

vue3实现无限循环滚动的方法;el-table内容无限循环滚动的实现
需求:vue3实现一个div内的内容无限循环滚动 方法一: <template><div idcontainer><div class"item" v-foritem in 5>测试内容{{{ item }}</div></div> </template><script setup> //封装一个方法…...

Windows 安装 MariaDB 数据库
之前一直使用 MySQL,使用 MySQL8.0 时候,占用内存比较大,储存空间好像也稍微有点大,看到 MariaDB 是用来代替 MySQL 的方案,之前用着也挺得劲,MySQL8.0 以上好像不能去导入低版本的 sql,或者需要…...
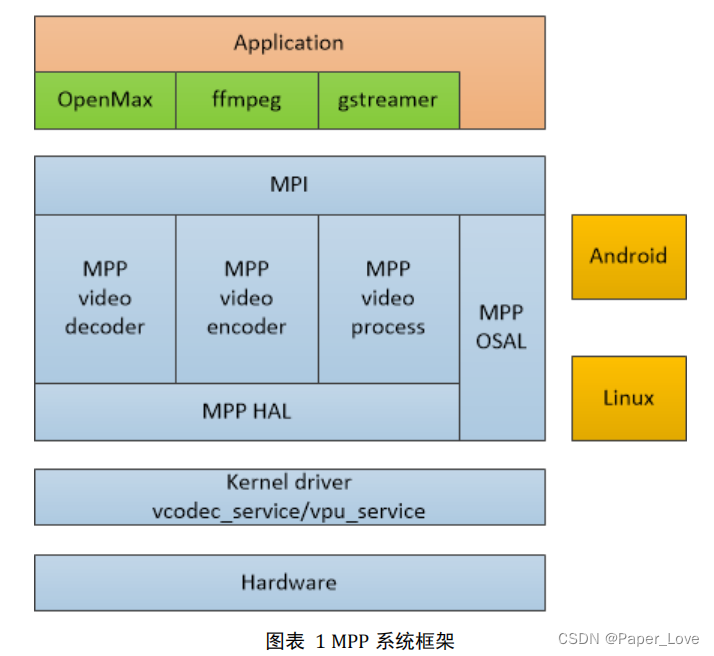
RK3568-mpp(Media Process Platform)媒体处理软件平台
第一章 MPP 介绍 1.1 概述 瑞芯微提供的媒体处理软件平台(Media Process Platform,简称 MPP)是适用于瑞芯微芯片系列的通用媒体处理软件平台。 该平台对应用软件屏蔽了芯片相关的复杂底层处理,其目的是为了屏蔽不同芯片的差异,为使用者提供统一的视频媒体处理接口(Medi…...

【ModelSim】使用终端命令行来编译、运行Verilog程序,创建脚本教程
▚ 01 ModelSim命令解说 📢 这些命令是 ModelSim 中常用的命令,用于创建库、编译源代码和启动仿真。 🔔 在使用这些命令之前,你需要在 ModelSim 的命令行界面或脚本中执行 vlib 命令来创建一个库,然后使用 vlog 命令…...
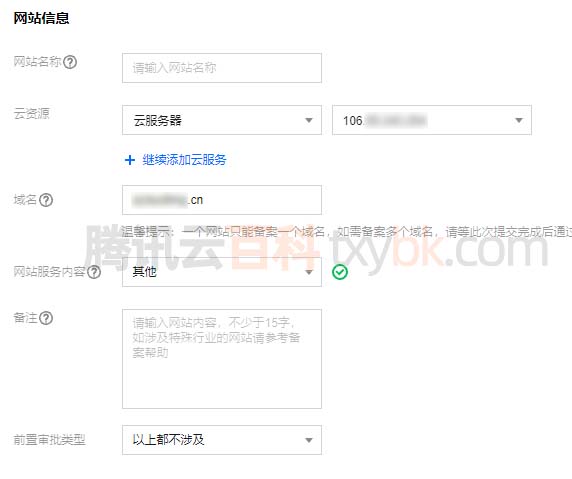
腾讯云网站备案详细流程_审核时间说明
腾讯云网站备案流程先填写基础信息、主体信息和网站信息,然后提交备案后等待腾讯云初审,初审通过后进行短信核验,最后等待各省管局审核,前面腾讯云初审时间1到2天左右,最长时间是等待管局审核时间,网站备案…...

HTTP介绍:一文了解什么是HTTP
前言: 在当今数字时代,互联网已经成为人们生活中不可或缺的一部分。无论是浏览网页、发送电子邮件还是在线购物,我们都离不开超文本传输协议(HTTP)。HTTP作为一种通信协议,扮演着连接客户端和服务器的重要角…...
动态规划之子数组系列
子数组系列 1. 环形⼦数组的最⼤和2. 乘积最大子数组3. 等差数列划分4. 最长湍流子数组5. 单词拆分6. 环绕字符串中唯⼀的子字符串 1. 环形⼦数组的最⼤和 1.题目链接:环形⼦数组的最⼤和 2.题目描述:给定一个长度为 n 的环形整数数组 nums ,…...
LeetCode(力扣)332.重新安排行程Python
LeetCode332.重新安排行程 题目链接代码 题目链接 https://leetcode.cn/problems/reconstruct-itinerary/ 代码 class Solution:def backtracking(self, tickets, used, cur, result, path):if len(path) len(tickets) 1:result.append(path[:])return Truefor i, ticket…...
的问题))
Pytho 从列表中创建字典 (dict.fromkeys()的问题)
问题起因:想在代码中通过已有的列表创建一个字典,但是又不想写循环,更不想手动填,所以用到了字典对象的fromkeys()方法 。 先以一个简单的例子介绍一下该方法: a ["A", "B", "C", &qu…...

第14节-PhotoShop基础课程-图框工具
文章目录 前言1.矩形画框2.椭圆画框 前言 图框 上面两张图,生成下面一幅图,这个就是图框工具的作用 图框工具ICON 1.矩形画框 2.椭圆画框...

使用 Nacos 在 Spring Boot 项目中实现服务注册与配置管理
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

package.json中workspaces详解与monorepo
参考package.json配置详解,让你一看就会(下) - 掘金...

Spring Boot + Vue的网上商城之商品信息展示
Spring Boot Vue的网上商城之商品信息展示 当实现一个Spring Boot Vue的网上商城的商品信息展示时,可以按照以下步骤进行: 后端实现: 创建一个Spring Boot项目,并添加所需的依赖,包括Spring Web和Spring Data JPA。…...
深度优先搜索遍历与广度优先搜索遍历
目录 一.深度优先搜索遍历 1.深度优先遍历的方法 2.采用邻接矩阵表示图的深度优先搜索遍历 3.非连通图的遍历 二.广度优先搜索遍历 1.广度优先搜索遍历的方法 2.非连通图的广度遍历 3.广度优先搜索遍历的实现 4.按广度优先非递归遍历连通图 一.深度优先搜索遍历 1.深…...

我花三天实测了DeepSeek V4,发现它根本不是来跟GPT-4o打架的
2026年4月24号,DeepSeek V4发布。 同一天,GPT-5.5也发布了。 这不是巧合,这是宣战。 但测了三天之后,我发现一个反直觉的结论,DeepSeek V4的真正对手根本不是GPT-4o,也不是Claude 3.5。 它要干掉的…...

如何使用日志实现业务全链路追踪
在现代分布式系统架构中,一个业务请求往往需要经过多个服务节点的协同处理,涉及网关、微服务、数据库、缓存、消息队列等多个组件。传统的日志记录方式通常局限于单个服务或模块,难以还原一个完整请求的流转路径,给问题排查、性能…...

在Windows上直接安装Android应用的革命性方案:APK安装器完全指南
在Windows上直接安装Android应用的革命性方案:APK安装器完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经希望在Windows电脑上直接运行手…...

美国通信业去监管趋势下的技术生态变革与产业应对策略
1. 从“去监管”信号看美国通信业格局重塑 2017年初,当阿吉特派伊(Ajit Pai)正式接任美国联邦通信委员会(FCC)主席时,他的一项早期举措——为广播公司和有线电视运营商削减文书工作规定——几乎在所有人的预…...

5 款实用漏洞扫描工具,网安从业者必备收藏
漏洞扫描是指基于漏洞数据库,通过扫描等手段对指定的远程或者本地计算机系统的安全脆弱性进行检测,发现可利用漏洞的一种安全检测的行为。 在漏洞扫描过程中,我们经常会借助一些漏扫工具,市面上漏扫工具众多,其中有一…...
)
用C8051F单片机自带的12位ADC,实现16位精度的温度测量(附完整代码)
基于C8051F单片机12位ADC实现16位温度测量的工程实践 在嵌入式系统开发中,高精度温度测量往往需要昂贵的16位ADC芯片,但通过合理的算法设计,我们可以利用C8051F系列单片机内置的12位ADC实现等效16位的测量精度。本文将深入探讨过采样技术的实…...

【人生底稿 23】新疆出差记・上篇:初入边疆,三个半小时的漫长飞行
2024 年的 6 月,刚在赣州、河北、湖南的项目里连轴转完,手里的需求设计还没完全收尾,一通临时电话,打破了我短暂的节奏 —— 任务突然下达:陪客户前往新疆乌鲁木齐的甲方现场。这不是我第一次出差,却是第一…...

QFN测试插座技术解析与应用实践
1. QFN测试插座的技术挑战与解决方案在半导体测试领域,QFN封装器件的测试一直是个棘手问题。这种无引线四方扁平封装虽然节省空间、散热优异,但恰恰因为缺少传统引脚,使得测试接触变得异常困难。我经手过不少QFN测试项目,最头疼的…...

告别重复点击!淘金币自动化脚本让你每天多出20分钟自由时间
告别重复点击!淘金币自动化脚本让你每天多出20分钟自由时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi …...

Windows安卓开发环境一键配置:告别繁琐驱动的终极解决方案
Windows安卓开发环境一键配置:告别繁琐驱动的终极解决方案 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/l…...