李宏毅-机器学习hw4-self-attention结构-辨别600个speaker的身份
一、慢慢分析+学习pytorch中的各个模块的参数含义、使用方法、功能:
1.encoder编码器中的nhead参数:
self.encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, dim_feedforward=256, nhead=2)

所以说,这个nhead的意思,就是有window窗口的大小,也就是一个b由几个a得到
2.tensor.permute改变维度的用法示例:
#尝试使用permute函数进行测试:可以通过tensor张量直接调用
import torch
import numpy as np
x = np.array([[[1,1,1],[2,2,2]],[[3,3,3],[4,4,4]]])
y = torch.tensor(x)
#y.shape
z=y.permute(2,1,0)
z.shape
print(z) #permute之后变成了3*2*2的维度
print(y) #本来是一个2*2*3从外到内的维度3.tensor.mean求均值:从1个向量 到 1个数值:

4.python中字典(映射)的使用:
二、model的neural network设计部分:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Classifier(nn.Module):def __init__(self, d_model=80, n_spks=600, dropout=0.1):super().__init__()# Project the dimension of features from that of input into d_model.self.prenet = nn.Linear(40, d_model) #通过一个线性的输入层,从40个维度,变成d_model个#展示不需要使用这个conformer进行实验# TODO:# Change Transformer to Conformer. # https://arxiv.org/abs/2005.08100#这里是不需要自己设计 self-attention层的,因为transformer的encoder层用到self-attention层self.encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, dim_feedforward=256, nhead=2 #输入维度是上面的d_model,输出维度是256,这2个nhead是啥?一个b由几个a得到)#下面这个暂时用不到# self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)# Project the the dimension of features from d_model into speaker nums.#predict_layerself.pred_layer = nn.Sequential( #这里其实就相当于是一个线性输出层了,最终输出的是一个n_soks维度600的向量nn.Linear(d_model, d_model),nn.ReLU(),nn.Linear(d_model, n_spks),)def forward(self, mels):"""args:mels: (batch size, length, 40) #我来试图解释一下这个东西,反正就是一段声音信号处理后得到的3维tensor,最里面那一维是40return:out: (batch size, n_spks) #最后只要输出每个batch中的行数 + 每一行中的n_spks的数值"""# out: (batch size, length, d_model) #原来out设置的3个维度的数据分别是batchsize , out = self.prenet(mels) #通过一个prenet层之后,最里面的那一维空间 就变成了一个d_model维度# out: (length, batch size, d_model)out = out.permute(1, 0, 2) #利用permute将0维和1维进行交换# The encoder layer expect features in the shape of (length, batch size, d_model).out = self.encoder_layer(out)# out: (batch size, length, d_model)out = out.transpose(0, 1) #重新得到原来的维度,这次用transpose和上一次用permute没有区别# mean poolingstats = out.mean(dim=1) #对维度1(第二个维度)计算均值,也就是将整个向量空间-->转成1个数值#得到的是batch,d_model (len就是一行的数据,从这一行中取均值,就是所谓的均值池化)# out: (batch, n_spks)out = self.pred_layer(stats) #这里得到n_spks还不是one-hot vecreturn out三、warming up 的设计过程:
import mathimport torch
from torch.optim import Optimizer
from torch.optim.lr_scheduler import LambdaLR#这部分的代码感觉有一点诡异,好像是设计了一个learning rate的warmup过程,算了,之后再回来阅读好了def get_cosine_schedule_with_warmup(optimizer: Optimizer,num_warmup_steps: int,num_training_steps: int,num_cycles: float = 0.5,last_epoch: int = -1,
):"""Create a schedule with a learning rate that decreases following the values of the cosine function between theinitial lr set in the optimizer to 0, after a warmup period during which it increases linearly between 0 and theinitial lr set in the optimizer.Args:optimizer (:class:`~torch.optim.Optimizer`):The optimizer for which to schedule the learning rate.num_warmup_steps (:obj:`int`):The number of steps for the warmup phase.num_training_steps (:obj:`int`):The total number of training steps.num_cycles (:obj:`float`, `optional`, defaults to 0.5):The number of waves in the cosine schedule (the defaults is to just decrease from the max value to 0following a half-cosine).last_epoch (:obj:`int`, `optional`, defaults to -1):The index of the last epoch when resuming training.Return::obj:`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule."""def lr_lambda(current_step):# Warmupif current_step < num_warmup_steps:return float(current_step) / float(max(1, num_warmup_steps))# decadenceprogress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))return LambdaLR(optimizer, lr_lambda, last_epoch)四、train中每个batch进行的处理:
import torch#这里面其实就是原来train部分的代码处理一个batch的操作def model_fn(batch, model, criterion, device): #这个函数的参数是batch数据,model,loss_func,设备"""Forward a batch through the model."""mels, labels = batch #获取mels参数 和 labels参数mels = mels.to(device)labels = labels.to(device)outs = model(mels) #得到的输出结果loss = criterion(outs, labels) #通过和labels进行比较得到loss# Get the speaker id with highest probability.preds = outs.argmax(1) #按照列的方向 计算出最大的索引位置# Compute accuracy.accuracy = torch.mean((preds == labels).float()) #通过将preds和labels进行比较得到acc的数值return loss, accuracy五、validation的处理函数:
from tqdm import tqdm
import torchdef valid(dataloader, model, criterion, device): #感觉就是整个validationset中的数据都进行了操作"""Validate on validation set."""model.eval() #开启evaluation模式running_loss = 0.0running_accuracy = 0.0pbar = tqdm(total=len(dataloader.dataset), ncols=0, desc="Valid", unit=" uttr") #创建进度条,实现可视化process_barfor i, batch in enumerate(dataloader): #下标i,batch数据存到batch中with torch.no_grad(): #先说明不会使用SGDloss, accuracy = model_fn(batch, model, criterion, device) #调用上面定义的batch处理函数得到loss 和 accrunning_loss += loss.item()running_accuracy += accuracy.item()pbar.update(dataloader.batch_size) #这些处理进度条的内容可以暂时不用管 pbar.set_postfix(loss=f"{running_loss / (i+1):.2f}",accuracy=f"{running_accuracy / (i+1):.2f}",)pbar.close()model.train()return running_accuracy / len(dataloader) #返回正确率六、train的main调用:
from tqdm import tqdmimport torch
import torch.nn as nn
from torch.optim import AdamW
from torch.utils.data import DataLoader, random_splitdef parse_args(): #定义一个给config赋值的函数"""arguments"""config = {"data_dir": "./Dataset","save_path": "model.ckpt","batch_size": 32,"n_workers": 1, #这个参数太大的时候,我的这个会error"valid_steps": 2000,"warmup_steps": 1000,"save_steps": 10000,"total_steps": 70000,}return configdef main( #可以直接用上面定义那些参数作为这个main里面的参数data_dir,save_path,batch_size,n_workers,valid_steps,warmup_steps,total_steps,save_steps,
):"""Main function."""device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"[Info]: Use {device} now!")train_loader, valid_loader, speaker_num = get_dataloader(data_dir, batch_size, n_workers) #获取所需的data,调用get_dataloader函数train_iterator = iter(train_loader) #定义一个train_data的迭代器print(f"[Info]: Finish loading data!",flush = True)model = Classifier(n_spks=speaker_num).to(device) #构造一个model的实例criterion = nn.CrossEntropyLoss() #分别构造loss_func 和 optimizer的实例optimizer = AdamW(model.parameters(), lr=1e-3)scheduler = get_cosine_schedule_with_warmup(optimizer, warmup_steps, total_steps) #构造warmup的实例print(f"[Info]: Finish creating model!",flush = True)best_accuracy = -1.0best_state_dict = Nonepbar = tqdm(total=valid_steps, ncols=0, desc="Train", unit=" step") #process_bar相关的东西,不用管它for step in range(total_steps): #一共需要的步数进行for循环# Get datatry:batch = next(train_iterator) #从train_data中获取到下一个batch的数据except StopIteration:train_iterator = iter(train_loader)batch = next(train_iterator)loss, accuracy = model_fn(batch, model, criterion, device) #传递对应的数据、模型参数,得到这个batch的loss和accbatch_loss = loss.item()batch_accuracy = accuracy.item()# Updata modelloss.backward()optimizer.step()scheduler.step()optimizer.zero_grad() #更新进行Gradient descend 更新模型,并且将grad清空# Logpbar.update() #process_bar的东西先不管pbar.set_postfix(loss=f"{batch_loss:.2f}",accuracy=f"{batch_accuracy:.2f}",step=step + 1,)# Do validationif (step + 1) % valid_steps == 0:pbar.close()valid_accuracy = valid(valid_loader, model, criterion, device) #调用valid函数计算这一次validation的正确率# keep the best modelif valid_accuracy > best_accuracy: #总是保持最好的valid_accbest_accuracy = valid_accuracybest_state_dict = model.state_dict()pbar = tqdm(total=valid_steps, ncols=0, desc="Train", unit=" step")# Save the best model so far.if (step + 1) % save_steps == 0 and best_state_dict is not None:torch.save(best_state_dict, save_path) #保存最好的model参数pbar.write(f"Step {step + 1}, best model saved. (accuracy={best_accuracy:.4f})")pbar.close()if __name__ == "__main__": #调用这个main函数main(**parse_args())七、inference部分的test内容:
import os
import json
import torch
from pathlib import Path
from torch.utils.data import Datasetclass InferenceDataset(Dataset):def __init__(self, data_dir):testdata_path = Path(data_dir) / "testdata.json"metadata = json.load(testdata_path.open())self.data_dir = data_dirself.data = metadata["utterances"]def __len__(self):return len(self.data)def __getitem__(self, index):utterance = self.data[index]feat_path = utterance["feature_path"]mel = torch.load(os.path.join(self.data_dir, feat_path))return feat_path, meldef inference_collate_batch(batch):"""Collate a batch of data."""feat_paths, mels = zip(*batch)return feat_paths, torch.stack(mels)import json
import csv
from pathlib import Path
from tqdm.notebook import tqdmimport torch
from torch.utils.data import DataLoaderdef parse_args():"""arguments"""config = {"data_dir": "./Dataset","model_path": "./model.ckpt","output_path": "./output.csv",}return configdef main(data_dir,model_path,output_path,
):"""Main function."""device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"[Info]: Use {device} now!")mapping_path = Path(data_dir) / "mapping.json"mapping = json.load(mapping_path.open())dataset = InferenceDataset(data_dir)dataloader = DataLoader(dataset,batch_size=1,shuffle=False,drop_last=False,num_workers=8,collate_fn=inference_collate_batch,)print(f"[Info]: Finish loading data!",flush = True)speaker_num = len(mapping["id2speaker"])model = Classifier(n_spks=speaker_num).to(device)model.load_state_dict(torch.load(model_path))model.eval()print(f"[Info]: Finish creating model!",flush = True)results = [["Id", "Category"]]for feat_paths, mels in tqdm(dataloader):with torch.no_grad():mels = mels.to(device)outs = model(mels) #调用model计算得到outspreds = outs.argmax(1).cpu().numpy() #对outs进行argmax,得到的索引存储到preds中for feat_path, pred in zip(feat_paths, preds):results.append([feat_path, mapping["id2speaker"][str(pred)]]) #将每一次的结果存放的到results中with open(output_path, 'w', newline='') as csvfile:writer = csv.writer(csvfile)writer.writerows(results)if __name__ == "__main__":main(**parse_args())inference部分的代码暂时就看看好了,这个2022版本的数据在github上404了。。。
七、Dataset的处理过程:
import os
import json
import torch
import random
from pathlib import Path
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequenceclass myDataset(Dataset):def __init__(self, data_dir, segment_len=128):self.data_dir = data_dirself.segment_len = segment_len# Load the mapping from speaker neme to their corresponding id. mapping_path = Path(data_dir) / "mapping.json"mapping = json.load(mapping_path.open()) #将这个json文件load到变量mapping中self.speaker2id = mapping["speaker2id"] #其实speaker2id这个变量就是mapping里面的内容#其实也就是原来数据集中的"id00464"变成我们这里的600个人的数据集的0-599的id# Load metadata of training data.metadata_path = Path(data_dir) / "metadata.json"metadata = json.load(open(metadata_path))["speakers"]#和上面类似的操作,这里的metadata就是打开那个json文件中的内容#我觉得按照他上课的说法,这里的n_mels的意思就是每个特征音频长度取出40就好了,?对吗#然后,这个json文件里面的内容就是不同speakerid所发声的音频文件的路径和mel_len# Get the total number of speaker.self.speaker_num = len(metadata.keys())self.data = [] #data就是这个class中的数据for speaker in metadata.keys(): #逐个遍历每个speakerfor utterances in metadata[speaker]: #遍历每个speaker的每一段录音self.data.append([utterances["feature_path"], self.speaker2id[speaker]])#将每一段录音按照 (路径,新id)存入data变量中def __len__(self):return len(self.data) #返回总共的data数量def __getitem__(self, index):feat_path, speaker = self.data[index] #从下标位置获取到该段录音的路径 和 speakerid# Load preprocessed mel-spectrogram.mel = torch.load(os.path.join(self.data_dir, feat_path)) #从路径中获取到该mel录音文件# Segmemt mel-spectrogram into "segment_len" frames.if len(mel) > self.segment_len: #如果大于128这个seg , 一些处理....# Randomly get the starting point of the segment.start = random.randint(0, len(mel) - self.segment_len)# Get a segment with "segment_len" frames.mel = torch.FloatTensor(mel[start:start+self.segment_len])else:mel = torch.FloatTensor(mel)# Turn the speaker id into long for computing loss later.speaker = torch.FloatTensor([speaker]).long() #将speakerid转换为long类型 return mel, speaker #返回这个录音mel文件和对应的speakeriddef get_speaker_number(self):return self.speaker_num这里附带我下载的文件资源路径:
ML2022Spring-hw4 | Kaggle
下面dropbox的链接是可以使用的

!wget https://www.dropbox.com/s/vw324newiku0sz0/Dataset.tar.gz.aa?d1=0
!wget https://www.dropbox.com/s/vw324newiku0sz0/Dataset.tar.gz.aa?d1=0
!wget https://www.dropbox.com/s/z840g69e71nkayo/Dataset.tar.gz.ab?d1=0
!wget https://www.dropbox.com/s/h1081e1ggonio81/Dataset.tar.gz.ac?d1=0
!wget https://www.dropbox.com/s/fh3zd8ow668c4th/Dataset.tar.gz.ad?d1=0
!wget https://www.dropbox.com/s/ydzygoy2pv6gw9d/Dataset.tar.gz.ae?d1=0
!cat Dataset.tar.gz.* | tar zxvf -这样才能下载到你需要的数据
怎么说呢?最后的最后,还是这个dropbox中下载的内容不全,少了一些文件
有一个解决的方法是,直接在kaggle上面下载那个5.2GB的压缩包,不过解压之后可能有70GB,文件似乎太大了,而且下载之后,只要全部解压导入到Dataset文件夹就可以运行了
方法三:尝试一下那个GoogleDrive上面的文件 :
失败了,算了还是自己老老实实下载然后上传吧
!gdown --id '1CtHZhJ-mTpNsO-MqvAPIi4Yrt3oSBXYV' --output Dataset.zip
!gdown --id '14hmoMgB1fe6v50biIceKyndyeYABGrRq' --output Dataset.zip
!gdown --id '1e9x-Pj13n7-9tK9LS_WjiMo21ru4UBH9' --output Dataset.zip
!gdown --id '10TC0g46bcAz_jkiM165zNmwttT4RiRgY' --output Dataset.zip
!gdown --id '1MUGBvG_Jjq00C2JYHuyV3B01vaf1kWIm' --output Dataset.zip
!gdown --id '18M91P5DHwILNy01ssZ57AiPOR0OwutOM' --output Dataset.zip
!unzip Dataset.zip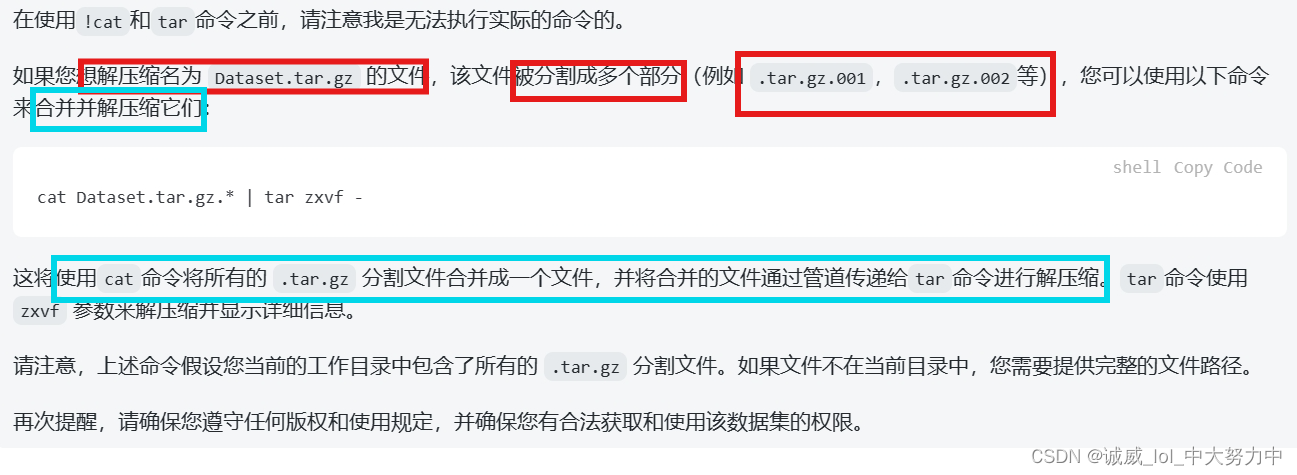
相关文章:
李宏毅-机器学习hw4-self-attention结构-辨别600个speaker的身份
一、慢慢分析学习pytorch中的各个模块的参数含义、使用方法、功能: 1.encoder编码器中的nhead参数: self.encoder_layer nn.TransformerEncoderLayer( d_modeld_model, dim_feedforward256, nhead2) 所以说,这个nhead的意思,就…...

记一次使用NetworkManager管理Ubuntu网络无效问题分析
我们都知道CentOS、Redhat系列网络配置比较连贯,要么在/etc/sysconfig/network-scripts/ifcfg-网络设备名,文件中编辑后,重启网络服务;要么使用nmtui或者nmcli进行配置。但是,Ubuntu变动就比较大: 早期版本…...
Nginx重写功能
Nginx重写功能 一、Nginx常见模块二、访问路由location2.1location常用正则表达式2.2、location的分类2.3、location常用的匹配规则2.4、location优先级排列说明2.5、location示例2.6、location优先级总结2.7、实例2.7.1、location/{}与location/{}2.7.2、location/index.html{…...
王道考研计算机网络
文章目录 计算机网络体系结构计算机网络概述计算机网络的性能指标 计算机网络体系结构与参考模型错题 物理层通信基础基础概念奈奎斯特定理和香农定理编码与调制电路交换、报文交换和分组交换数据报与虚电路 传输介质物理层设备错题 数据链路层数据链路层的功能组帧差错控制检错…...
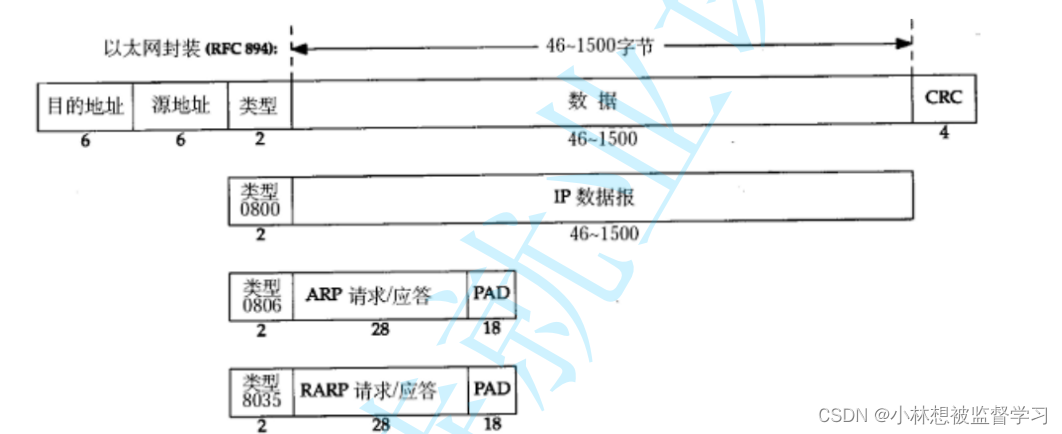
数据链路层重点协议-以太网
以太网简介 "以太网" 不是一种具体的网络,而是一种技术标准;既包含了数据链路层的内容,也包含了 一些物理层的内容。例如:规定了网络拓扑结构,访问控制方式,传输速率等; 以太网数据帧…...

学习计划
白驹过隙,转眼已是大二。新学期,新气象,新计划。 一、专业学习方面 学习vue、spring boot、redis、MybatisPlus、Elasticsearch、ssm框架,完成项目的编写,思考复盘。 二、读书方面 因为我大概率会走前端方向࿰…...

RabbitMQ的RPM包安装和Python读写操作
下载地址 ## erlang 下载地址 https://packagecloud.io/rabbitmq/erlang?page6## rabbitmq 下载地址 https://packagecloud.io/rabbitmq/rabbitmq-server/packages/el/7/rabbitmq-server-3.8.29-1.el7.noarch.rpm?distro_version_id140 Rabbitmq的RPM包安装 ## 下载 wget -…...
文件上传漏洞案例
目录 1.案例一 1)案例源码 2)创建web.php文件 3)使用抓包软件 2.案例二 1)案例代码 2) 案例分析 3)copy命令生成图片马 4)上传图片马到服务器 5)解析 文件图片 3.案例三 …...

Office365 Excel中使用宏将汉字转拼音
Office365 Excel中开启宏 文件 - 选项 - 信任中心 - 信任中心设值 - 宏设值 启用VBA宏启用VBA宏时启用Excel 4.0宏信任对VBA工程对象模型的访问 创建宏 视图 - 查看宏 填写名字创建宏:getpy填入下面代码保存,点击否,另存类型为“excel启…...

baichuan2(百川2)本地部署的实战方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…...
)
PostgreSQL配置主从备份(docker)
一、服务器规划 序号 IP 备注 1192.168.1.110主数据库2192.168.1.120从数据库 二、服务器部署 2.1、主服务器部署(192.168.1.110) 1)、于/opt/postgresql目录下,编辑docker-compose.yml version: "3" services:po…...

qt作业day4
//clock_exercise.cpp#include "clock_timer.h" #include "ui_clock_timer.h"//时间事件处理函数 void Clock_Timer::timerEvent(QTimerEvent *event) {if(event->timerId() time_id){sys_tm QDateTime :: currentDateTime(); // int year sy…...

js如何实现字符串反转?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 使用 split() 和 reverse() 方法⭐ 使用循环⭐ 使用递归⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专…...
Nmap 7.94 发布:新功能!
Nmap 的最新版本 7.94 在其 26 岁生日之际发布。 最重要的升级是在所有平台上将 Zenmap 和 Ndiff 从 Python 2 迁移到 Python 3。 这个新版本的 Nmap 7.94 进行了升级,进行了多项改进,修复了一些关键错误,并添加了新的 Npcap、操作系统指纹…...

【深入解析spring cloud gateway】08 Reactor 知识扫盲
一、响应式编程概述 1.1 背景知识 为了应对高并发服务器端开发场景,在2009 年,微软提出了一个更优雅地实现异步编程的方式——Reactive Programming,我们称之为响应式编程。随后,Netflix 和LightBend 公司提供了RxJava 和Akka S…...

常用ADB指令
ADB指令 1.查看版本 adb shell getprop|findstr fingerprint 2.查看应用包名 adb shell pm list packages 3.查看系统关键字 adb shell getprop|findstr oem/sn/user… 4.查看进程id adb shell ps -ef |grep appstore 5.启动服务 adb shell am startservice -n com.a…...

【HTML5高级第二篇】WebWorker多线程、EventSource事件推送、History历史操作
文章目录 一、多线程1.1 概述1.2 体会多线程1.3 多线程中数据传递和接收 二、事件推送2.1 概述2.2 onmessage 事件 三、history 一、多线程 1.1 概述 前端JS默认按照单线程去执行,一段时间内只能执行一件事情。举个栗子:比方说古代攻城游戏,…...

CentOS云服务器部署配置
1. 安装Mysql 1.1.确保服务器系统处于最新状态 [rootlocalhost ~]# yum -y update如果显示内容中含有 [rootlocalhost ~]# Complete! 说明更新完成 1.2.下载MySql安装包 rootlocalhost ~]# rpm -ivh http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm…...

深入解析Java中的数组复制:System.arraycopy、Arrays.copyOf和Arrays.copyOfRange
当涉及到在Java中处理数组时,有许多方法可供选择,其中一些包括System.arraycopy()、Arrays.copyOf()和Arrays.copyOfRange()。这些方法允许您在不同的数组之间复制数据,但它们之间有一些细微的差异。在本篇博客文章中,我们将深入探…...

libc和glibc有什么区别
libc(C Library)是一个常见的术语,指的是C语言的标准函数库,提供了许多函数和常量供C语言程序使用。在不同的操作系统中,libc可能是不同的,但是它们都实现了C语言的标准库函数。 glibc(GNU C L…...

从规范到验证:构建企业级环境变量与密钥安全管理体系
1. 项目概述:从“裸奔”到“装甲车”的密钥管理进化在开发一个现代应用时,我们几乎不可避免地要和一堆敏感信息打交道:数据库密码、API密钥、第三方服务的访问令牌、加密盐值……这些信息,我们通常称之为“环境变量”或“密钥”。…...

如何实现微信聊天记录永久保存:WeChatMsg完整备份终极指南
如何实现微信聊天记录永久保存:WeChatMsg完整备份终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

基于官方API的WhatsApp AI助手集成:规避封号风险与实战部署指南
1. 项目概述:为你的AI助手开通一个安全的WhatsApp专线 如果你正在使用OpenClaw构建自己的AI助手,并且希望它能通过WhatsApp与用户自然交流,那么你很可能已经研究过各种方案了。市面上常见的方案,比如基于 whatsapp-web.js 或 …...

Taotoken用量看板与成本管理功能的实际使用体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本管理功能的实际使用体验 对于需要持续调用大模型API的项目而言,成本的可观测与可控性是管理中的…...

粒子群灰狼优化算法稀疏码设计【附代码】
✨ 长期致力于稀疏码多址接入、星型正交振幅调制、功率不平衡码本、粒子群算法、混合粒子群灰狼优化算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1ÿ…...

从零到一:在STM32F103上构建FatFs文件系统并驱动W25Q64 Flash
1. 硬件准备与环境搭建 在开始构建FatFs文件系统之前,我们需要先准备好硬件环境。我手头用的是STM32F103C8T6最小系统板,搭配一块W25Q64 Flash芯片。这块Flash芯片容量为8MB,通过SPI接口通信,正好适合用来做文件存储介质。 首先得…...

JPlag代码抄袭检测:17种编程语言的智能原创守护者
JPlag代码抄袭检测:17种编程语言的智能原创守护者 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 在数字化教…...

通用汽车IT部门裁员600人,为AI人才腾空间,软件团队变革进行时
通用汽车IT部门裁员600人,AI人才成新宠 通用汽车证实已对其IT部门进行裁员,约600名领薪员工(占比10%以上)被裁,目的是清除专业知识不再适用的员工,为具有AI背景的人员腾出空间。公司表示这是面向未来做好准…...

纯Java实现Gemma大模型推理:在JVM中部署轻量级AI的工程实践
1. 项目概述:当Gemma遇上Java,一个轻量级AI推理的新选择最近在开源社区里,一个名为mukel/gemma4.java的项目引起了我的注意。作为一名长期在Java生态和机器学习边缘部署领域摸爬滚打的开发者,看到这个标题的第一反应是:…...

4 生成器模式
生成器模式 的核心是:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。简单说:像搭积木一样,用相同的步骤可以搭出不同样式的房子。建造房子的步骤是固定的:打地基建墙体安装屋顶装修内部但…...