Speech | 语音处理,分割一段音频(python)
本文主要是关于语音数据在处理过程中的一些脚本文件以及实例,所有代码只需要更改所需处理的文件路径,输出路径等,全部可运行。
目录
所需环境
方法1:将一整段音频按时间批量切成一个一个音频
方法2:将一整段音频按语句停顿批量切成一个一个音频
方法3:将一个文件夹内的几整段音频批量切成一个一个音频
3.1.数据格式:一个文件夹下的长几分多的音频(wav文件)按固定秒数切割
3.2.数据格式:一个文件夹下的长几分多的音频(mp3文件)按固定秒数切割
3.3.数据格式:一个文件夹下的长几分多的音频(wav文件)按语句停顿切割
扩展
将pcm文件批量处理成wav文件
Linux下查询文件夹中文件数量的方法
使用ls命令和wc命令
WAV格式文件详解
所需环境
本文环境:Linux
pydub(安装:pip3 install pydub)
ffmpeg(apt install ffmpeg)
方法1:将一整段音频按时间批量切成一个一个音频
数据格式:一个长三分五十秒的音频

# split_wav_time.py
from pydub import AudioSegment
from pydub.utils import make_chunksaudio = AudioSegment.from_file("his_one/1.wav", "wav")#size = 10000 #切割的毫秒数 10s=10000
size = 60000 #切割的毫秒数 60s=60000chunks = make_chunks(audio, size) #将文件切割为60s一个for i, chunk in enumerate(chunks):chunk_name = "new-{0}.wav".format(i)print(chunk_name)chunk.export(chunk_name, format="wav")运行命令:
python split_wav_time.py结果:
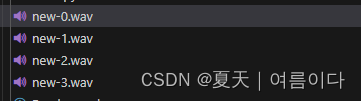
方法2:将一整段音频按语句停顿批量切成一个一个音频
数据格式:一个长几分多的音频
利用split_on_silence(sound,min_silence_len, silence_thresh, keep_silence=400)函数
第一个参数为待分割音频,第二个为多少秒“没声”代表沉默,第三个为分贝小于多少dBFS时代表沉默,第四个为为截出的每个音频添加多少ms无声
from pydub import AudioSegment
from pydub.silence import split_on_silencesound = AudioSegment.from_mp3("his_one/1.wav")
loudness = sound.dBFS
#print(loudness)chunks = split_on_silence(sound,# must be silent for at least half a second,沉默半秒min_silence_len=430,# consider it silent if quieter than -16 dBFSsilence_thresh=-45,keep_silence=400)
print('Len:', len(chunks))# 放弃长度小于2秒的录音片段
for i in list(range(len(chunks)))[::-1]:if len(chunks[i]) <= 2000 or len(chunks[i]) >= 10000:chunks.pop(i)
print('取有效分段(大于2s小于10s):', len(chunks))'''
for x in range(0,int(len(sound)/1000)):print(x,sound[x*1000:(x+1)*1000].max_dBFS)
'''for i, chunk in enumerate(chunks):chunk.export("cutwav_{0}.wav".format(i), format="wav")#print(i)结果:
方法3:将一个文件夹内的几整段音频批量切成一个一个音频
3.1.数据格式:一个文件夹下的长几分多的音频(wav文件)按固定秒数切割

from pydub import AudioSegment
from pydub.utils import make_chunks
import os, re# # 循环目录下所有文件
for each in os.listdir("/workspace/tts/PolyLangVITS/history"): #循环目录filename = re.findall(r"(.*?)\.wav", each) # 取出.wav后缀的文件名print(each)if each:# filename[0] += '.wav'# print(filename[0])mp3 = AudioSegment.from_file('/workspace/tts/PolyLangVITS/history/{}'.format(each), "wav") # 打开mp3文件
# # # mp3[17*1000+500:].export(filename[0], format="mp3") #size = 15000 # 切割的毫秒数 10s=10000chunks = make_chunks(mp3, size) # 将文件切割为15s一块for i, chunk in enumerate(chunks):chunk_name = "{}-{}.wav".format(each.split(".")[0],i)print(chunk_name)chunk.export('/workspace/tts/PolyLangVITS/preprodata/his_out/{}'.format(chunk_name), format="wav")结果

3.2.数据格式:一个文件夹下的长几分多的音频(mp3文件)按固定秒数切割
from pydub import AudioSegment
from pydub.utils import make_chunks
import os, re
# #
# # 循环目录下所有文件
for each in os.listdir("D:/纯音乐"): #循环目录filename = re.findall(r"(.*?)\.mp3", each) # 取出.mp3后缀的文件名print(each)if each:# filename[0] += '.wav'# print(filename[0])mp3 = AudioSegment.from_file('D:/纯音乐/{}'.format(each), "mp3") # 打开mp3文件
# # # mp3[17*1000+500:].export(filename[0], format="mp3") #size = 15000 # 切割的毫秒数 10s=10000chunks = make_chunks(mp3, size) # 将文件切割为15s一块for i, chunk in enumerate(chunks):chunk_name = "{}-{}.mp3".format(each.split(".")[0],i)print(chunk_name)chunk.export('D:/纯音乐分解/{}'.format(chunk_name), format="mp3")```3.3.数据格式:一个文件夹下的长几分多的音频(wav文件)按语句停顿切割
# @ Elena
# @ Date : 23.9.4import os, re
from pydub import AudioSegment
from pydub.silence import split_on_silence# # 循环目录下所有文件
for each in os.listdir("/workspace/tts/PolyLangVITS/history"): filename = re.findall(r"(.*?)\.wav", each) # 取出.wav后缀的文件名print(each)if each:sound = AudioSegment.from_file('/workspace/tts/PolyLangVITS/history/{}'.format(each), "wav")loudness = sound.dBFS#print(loudness)chunks = split_on_silence(sound,# must be silent for at least half a second,沉默半秒min_silence_len=430,# consider it silent if quieter than -16 dBFSsilence_thresh=-45,keep_silence=400)print('Len:', len(chunks))# 放弃长度小于1秒的录音片段for i in list(range(len(chunks)))[::-1]:if len(chunks[i]) <= 1000 or len(chunks[i]) >= 10000:chunks.pop(i)print('Len (1s~10s wav file):', len(chunks))'''for x in range(0,int(len(sound)/1000)):print(x,sound[x*1000:(x+1)*1000].max_dBFS)'''for i, chunk in enumerate(chunks):chunk_name = "{}-{}.wav".format(each.split(".")[0],i) chunk.export("/workspace/tts/PolyLangVITS/preprodata/his_out/{}".format(chunk_name), format="wav")#print(i)
结果

使用 file 查询 wav
(WAV文件格式是Microsoft的RIFF规范的一个子集,用于存储多媒体文件。WAV(RIFF)文件由若干个Chunk组成,分别为: RIFF WAVE Chunk,Format Chunk,Fact Chunk(可选),Data Chunk。具体格式如下:)

扩展
将pcm文件批量处理成wav文件
import wave
import osfilepath = "data/" # 添加路径
filename = os.listdir(filepath) # 得到文件夹下的所有文件名称
#f = wave.open(filepath + filename[1], 'rb')
#print(filename)
for i in range(len(filename)):with open("data/"+failename[i], 'rb') as pcmfile:pcmdata = pcmfile.read()with wave.open("data/"+filename[i][:-3] + '.wav', 'wb') as wavfile:wavfile.setparams((1, 2, 16000, 0, 'NONE', 'NONE'))wavfile.writeframes(pcmdata)Linux下查询文件夹中文件数量的方法
使用ls命令和wc命令
使用ls命令的-l选项和管道操作符|结合wc命令来统计文件数量:
查询当前文件夹下带有“wav”的文件数量
ls -l | grep "wav" | wc -l 
WAV格式文件详解
WAV文件格式是Microsoft的RIFF规范的一个子集,用于存储多媒体文件。WAV(RIFF)文件由若干个Chunk组成,分别为: RIFF WAVE Chunk,Format Chunk,Fact Chunk(可选),Data Chunk。具体格式如下:
音频文件参数简介
对于形如44100HZ 16bit stereo 或者 22050HZ 8bit mono参数描述的音频文件,其蕴含的文件参数包括:
采样率:声音信号在“模→数”转换过程中单位时间内采样的次数。
采样值(采样精度):每一次采样周期内声音模拟信号的积分值。
同时,每个采样数据记录的是振幅, 而采样精度取决于储存空间的大小。
对于单声道(mono)文件,采样数据为8位的短整数,同时其采样精度有:
1 字节(8bit) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
2 字节(16bit) 可以细到 65536 个数, 即为 CD 标准;
4 字节(32bit) 能把振幅细分到 4294967296 个等级, 实在是没必要了。
对于双声道立体声(stereo)文件,每次采样数据为一个16位的整数(int),且采样是双份的,也为单声道文件的两倍。采样数据中高八位(左声道)和低八位(右声道)分别代表两个声道。
由于wav格式文件本质上为音频文件,即可根据文件的大小、采样频率和采样大小估算文件的播放长度。
更多可查看Microsoft WAVE soundfile format (sapp.org)
相关文章:
Speech | 语音处理,分割一段音频(python)
本文主要是关于语音数据在处理过程中的一些脚本文件以及实例,所有代码只需要更改所需处理的文件路径,输出路径等,全部可运行。 目录 所需环境 方法1:将一整段音频按时间批量切成一个一个音频 方法2:将一整段音频按…...

【深度学习】 Python 和 NumPy 系列教程(三):Python容器:1、列表List详解(初始化、索引、切片、更新、删除、常用函数、拆包、遍历)
目录 一、前言 二、实验环境 三、Python容器(Containers) 0、容器介绍 1、列表(List) 1. 初始化 a. 创建空列表 b. 使用现有元素初始化列表 c. 使用列表生成式 d. 复制列表 2. 索引和切片 a. 索引 b. 负数索引 c. 切…...

【C++笔记】C++string类模拟实现
【C笔记】Cstring类模拟实现 一、实现模型和基本接口1.1、各种构造和析构1.2、迭代器 二、各种插入和删除接口2.1、插入接口2.2、删除接口2.3、resize接口 三、各种运算符重载3.1、方括号运算符重载3.2、各种比较运算符重载 四、查找接口4.1、查找字符4.2、查找子串 五、流插入…...
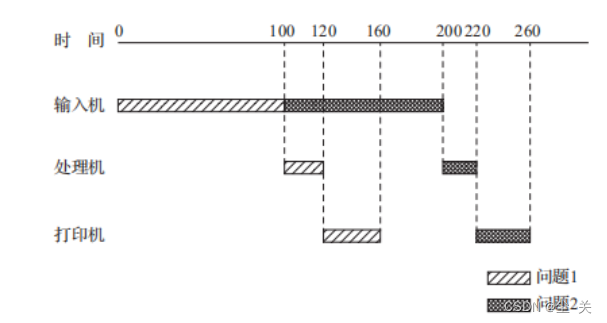
操作系统之课后习题——引论
(一)简答题 1.在计算机系统上配置OS的目标是什么?作用主要表现在哪几个方面? 答: 在计算机系统上配置OS,主要目标是实现:方便性、有效性、可扩充性和开放性; OS的作用主要表现在以下…...
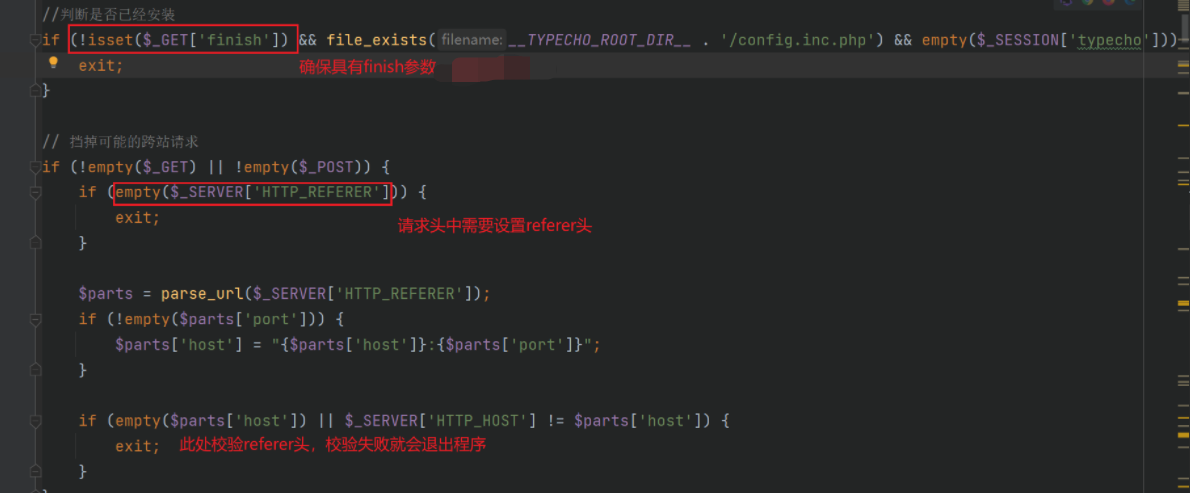
【PHP代码审计】反序列化漏洞实战
文章目录 概述资源下载地址Typecho代码审计-漏洞原理call_user_func()_applyFilter()、get()与__get__toString()__construct()install.php POC利用漏洞利用复现利用链执行phpinfo()GET利用POST利用 getshell生成payload漏洞利用蚁剑连接 总结 概述 序列化,“将对象…...
Socks5 与 HTTP 代理在网络安全中的应用
目录 Socks5和HTTP代理在网络安全中的应用。 Socks5代理和HTTP代理的优点和缺点。 选择合适的代理IP需要考虑的因素: 总结 在网络安全领域中,Socks5和HTTP代理都扮演着重要的角色。作为两种不同的代理技术,它们在网络安全中的应用各有特点…...

进阶C语言-指针的进阶(中)
指针的进阶 📖5.函数指针📖6.函数指针数组📖7.指向函数指针数组的指针📖8.回调函数 📖5.函数指针 数组指针 - 指向数组的指针 - 存放的是数组的地址 - &数组名就是数组的地址。 函数指针 - 指向函数的指针 - 存放的…...

保姆级-微信小程序开发教程
一,注册微信小程序 如果你还没有微信公众平台的账号,请先进入微信公众平台首页,点击 “立即注册” 按钮进行注册。注册的账号类型可以是订阅号、服务号、小程序以及企业微信,我们选择 “小程序” 即可。 接着填写账号信息&#x…...
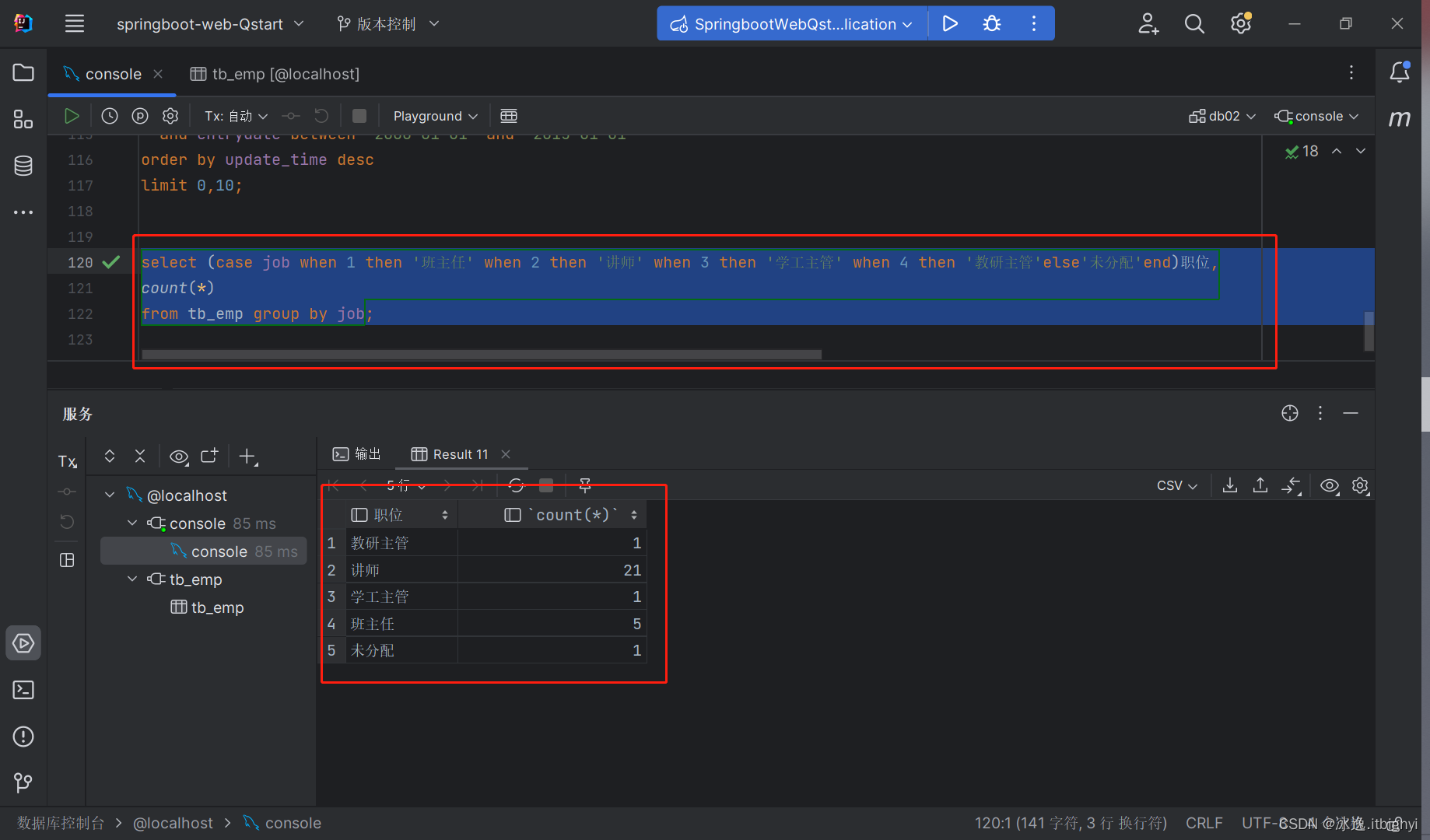
数据库-DQL
DQL:用来查询数据库表中的记录 关键字:SELECT 语法: select:字段列表 from:表名列表 where:条件列表 group by:分组列表 having:分组后条件列表 order by:排序字段列表…...

19 螺旋矩阵
螺旋矩阵 题解1 循环(4个标志——根据顺时针)题解2 方向 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 提示: - m matrix.length - n matrix[i].length - 1 < m, n <…...
数据结构与算法:概述
目录 算法 评价标准 时间的复杂度 概念 推导原则 举例 空间的复杂度 定义 情形 运用场景 数据结构 组成方式 算法 在数学领域,算法是解决某一类问题的公式和思想; 计算机科学领域,是指一系列程序指令,用于解决特定的…...
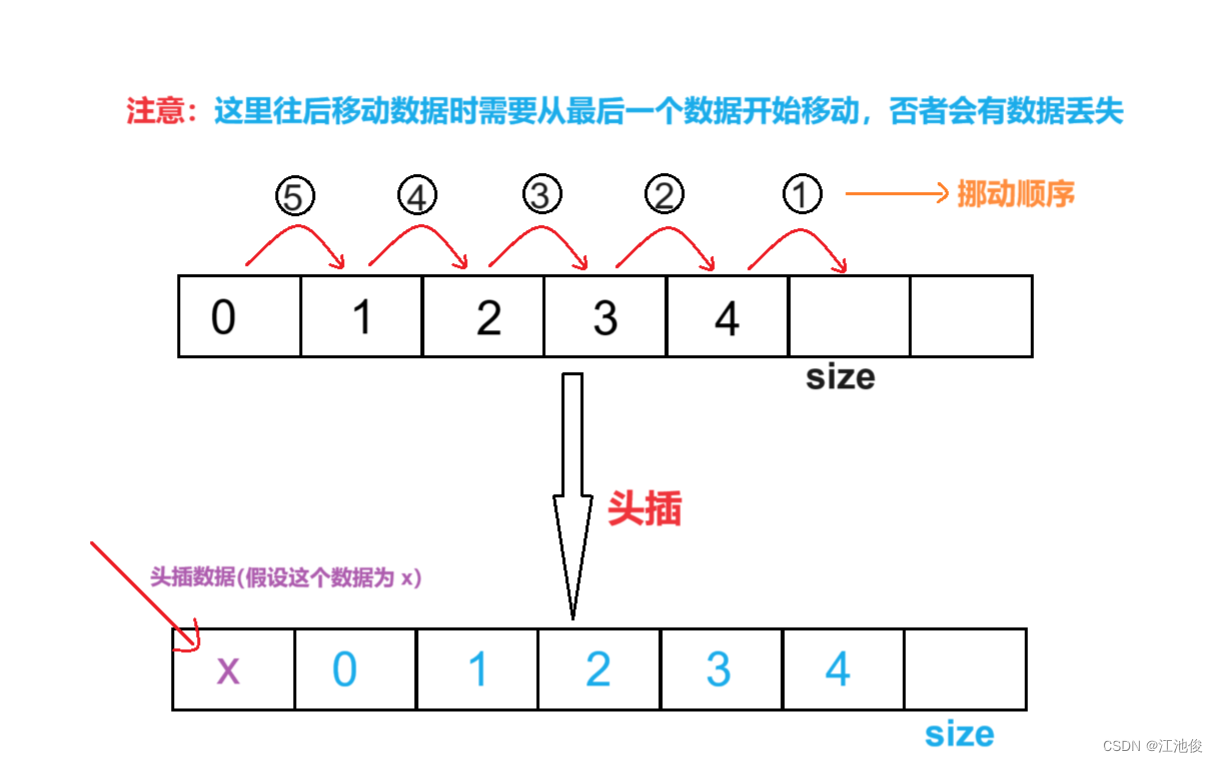
顺序表详解
💓 博客主页:江池俊的博客⏩ 收录专栏:数据结构探索👉专栏推荐:✅C语言初阶之路 ✅C语言进阶之路💻代码仓库:江池俊的代码仓库🔥编译环境:Visual Studio 2022Ἰ…...
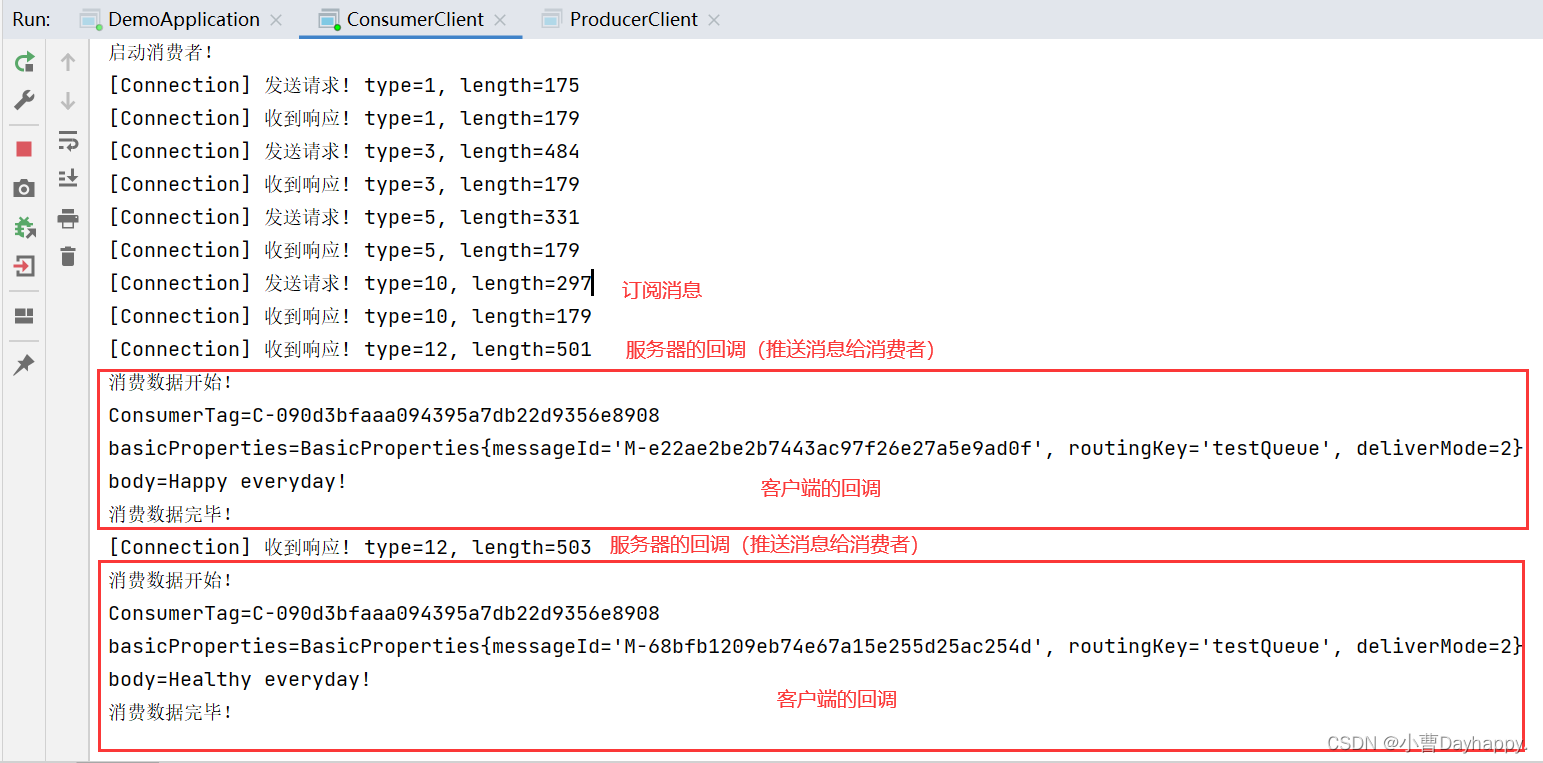
基于RabbitMQ的模拟消息队列之六——网络通信设计
自定义基于TCP的应用层通信协议。实现客户端对服务器的远程调用 编写服务器及客户端代码 文章目录 基于TCP的自定义应用层协议一、请求1.请求格式2.创建Request类 二、响应1.响应格式2.创建Response类 三、客户端-服务器交互四、type五、请求payload1.BasicAruguments(方法公共…...

算法:数组中的最大差值---“打擂台法“
文章来源: https://blog.csdn.net/weixin_45630258/article/details/132737088 欢迎各位大佬指点、三连 1、题目: 给定一个整数数组 nums,找出给定数组中两个数字之间的最大差值。要求,第二个数字必须大于第一个数字。 2、分析特…...

三种方式查看 JVM 垃圾收集器
一、引言 不同版本的 JVM 默认使用的垃圾收集器是不同的,目前的新生代和老年代的垃圾收集器如下图所示,新生代和老年代之间的连线表示这些垃圾收集器可以进行搭配使用 垃圾收集器的名字和 JVM 里面的参数对照表如下,即在 JVM 里面并不是存储的…...
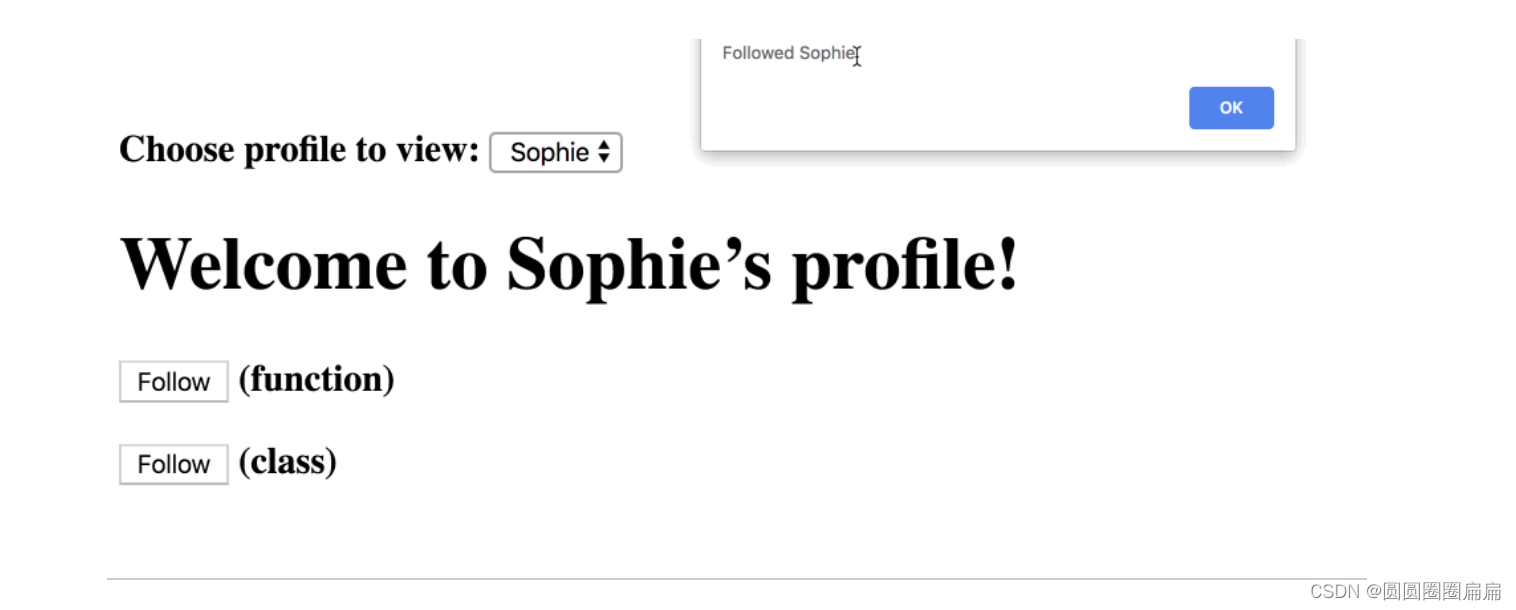
React中函数式组件与类组件有何不同?
Function Component 与 Class Component 有何不同 目录 Function Component 与 Class Component 有何不同 文章核心观点: 解释一下: 总结: 文章核心观点: Function components capture the rendered values.函数式组件捕获…...
windows11安装docker时,修改默认安装到C盘
1、修改默认安装到C盘 2、如果之前安装过docker,请删除如下目录:C:\Program Files\Docker 3、在D盘新建目录:D:\Program Files\Docker 4、winr,以管理员权限运行cmd 5、在cmd中执行如下命令,建立软联接: m…...

python模块之 aiomysql 异步mysql
mysql安装教程 mysql语法大全 python 模块pymysql模块,连接mysql数据库 一、介绍 aiomysql 是一个基于 asyncio 的异步 MySQL 客户端库,用于在 Python 中与 MySQL 数据库进行交互。它提供了异步的数据库连接和查询操作,适用于异步编程环境 …...

开开心心带你学习MySQL数据库之第八篇
索引和事务 ~~ 数据库运行的原理知识 面试题 索引 索引(index) > 目录 索引存在的意义,就是为了加快查找速度!!(省略了遍历的过程) 查找速度是快了,但是付出了一定的代价!! 1.需要付出额外的空间代价来保存索引数据 2.索引可能会拖慢新增,删除,修改的速度 ~~ …...

yml配置动态数据源(数据库@DS)与引起(If you want an embedded database (H2, HSQL or Derby))类问题
1:yml 配置 spring:datasource:dynamic:datasource:master:url: jdbc:mysql://192.168.11.50:3306/dsdd?characterEncodingUTF-8&useUnicodetrue&useSSLfalse&tinyInt1isBitfalse&allowPublicKeyRetrievaltrue&serverTimezoneUTCusername: ro…...
)
别再混淆了!一文讲透W25Q128FV与JV的QSPI驱动差异(附STM32H743配置代码)
深入解析W25Q128FV与JV的QSPI驱动差异及STM32H743实战配置 在嵌入式存储解决方案中,W25Q128系列闪存芯片因其高性价比和稳定性能而广受欢迎。然而,许多工程师在实际项目中容易忽略FV与JV这两个子型号之间的关键差异,导致驱动开发过程中出现各…...

如何用BilibiliDown轻松提取B站无损音频:3步完成音乐下载
如何用BilibiliDown轻松提取B站无损音频:3步完成音乐下载 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirror…...

Cursor Pro功能无限试用:开源自动化工具原理与实战部署指南
1. 项目概述与核心思路拆解最近在开发者圈子里,Cursor 这款 AI 驱动的代码编辑器热度一直很高,它集成了强大的 AI 助手,能极大地提升编码效率。不过,其核心的 Pro 功能需要付费订阅才能持续使用。很多开发者,尤其是学生…...
)
从电机控制到无刷驱动:STM32高级定时器TIM1互补PWM带死区配置全流程(附逻辑分析仪实测)
STM32高级定时器TIM1互补PWM与死区控制实战指南 在工业电机驱动和电源逆变领域,精确的PWM信号控制是系统可靠运行的核心。许多工程师在初次接触STM32高级定时器的互补PWM功能时,往往会被其复杂的参数配置所困扰——特别是当涉及到H桥电路的安全驱动时&am…...

别再满世界找grep了!Windows上PowerShell自带的Select-String和findstr,5分钟上手教程
Windows高效文本搜索指南:Select-String与findstr实战解析 每次在Windows环境下需要搜索文本时,你是否会下意识地怀念Linux中的grep命令?作为开发者或运维人员,快速定位日志、配置文件或代码片段是日常高频操作。实际上Windows平台…...

告别第三方工具:手把手教你打造微软官方WinPE系统维护盘
1. 为什么你需要一个官方WinPE维护盘? 每次电脑系统崩溃时,你是不是也在各大论坛疯狂搜索"如何重装系统"?市面上确实有很多第三方PE工具,比如老毛桃、微PE之类的,用起来确实方便。但作为一个在IT行业摸爬滚…...

如何精准下载GitHub项目中的特定文件或文件夹
如何精准下载GitHub项目中的特定文件或文件夹 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 在GitHub上查找开源资源时,开发者常常面临一个现实问题:如何仅获取项目中的特定模块而非整…...

Windows 11 LTSC系统恢复微软商店:3分钟快速安装完整指南
Windows 11 LTSC系统恢复微软商店:3分钟快速安装完整指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 LTSC版本…...

UE5实战:从MediaPlayer到Media Texture,打通场景与UMG的视频播放全链路
1. 视频播放功能的基础准备 在UE5中实现视频播放功能,首先需要做好基础环境搭建。我强烈建议使用Electra Player插件,这是Epic官方推荐的视频解码方案,对DX12有良好支持。安装时只需在插件管理器中勾选"Electra Player"࿰…...

Aider:AI结对编程实战,从原理到项目级代码编辑
1. 项目概述:当AI成为你的结对编程伙伴如果你是一名开发者,大概率经历过这样的场景:面对一个需要修改的复杂函数,你清楚地知道要做什么,但就是不想动手去敲那一行行重复或繁琐的代码;或者,在深夜…...