interview3-微服务与MQ
一、SpringCloud篇


(1)服务注册
常见的注册中心:eureka、nacos、zookeeper
-
eureka做服务注册中心:
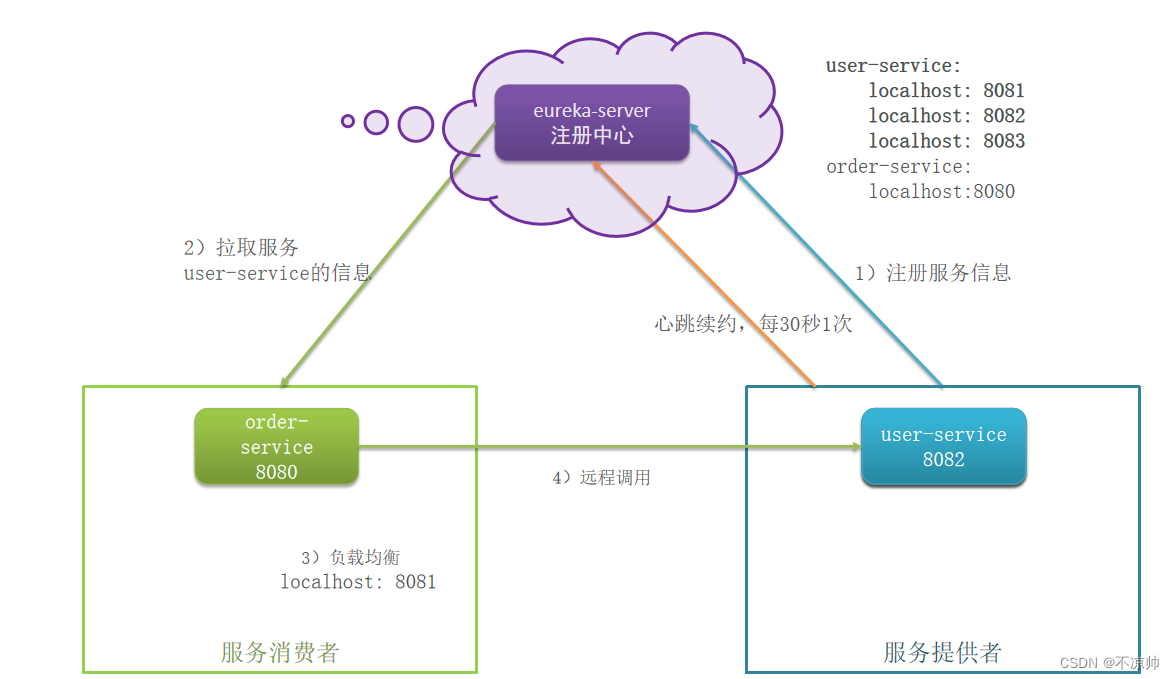
-
服务注册:服务提供者需要把自己的信息注册到eureka,由eureka来保存这些信息,比如服务名称、ip、端口等等
-
服务发现:消费者向eureka拉取服务列表信息,如果服务提供者有集群,则消费者会利用负载均衡算法,选择一个发起调用
-
服务监控:服务提供者会每隔30秒向eureka发送心跳,报告健康状态,如果eureka服务90秒没接收到心跳,从eureka中剔除
-
Nacos与eureka的共同点(注册中心)
-
都支持服务注册和服务拉取
-
都支持服务提供者心跳方式做健康检测
-
Nacos与Eureka的区别(注册中心)
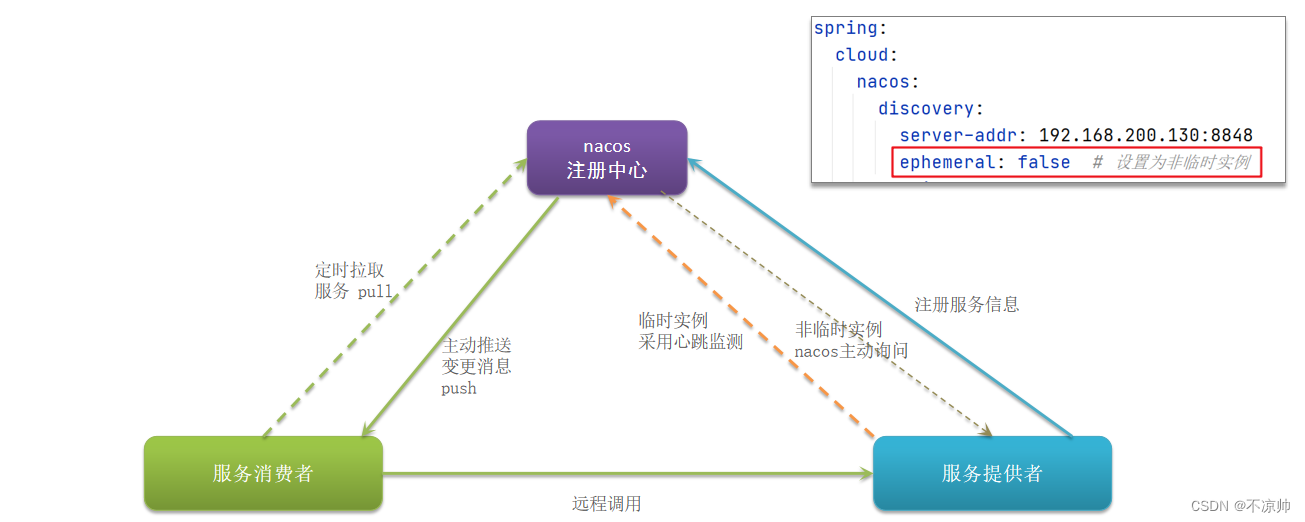
-
Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
-
临时实例心跳不正常会被剔除,非临时实例则不会被剔除
-
Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
-
Nacos集群默认采用AP(高可用)方式,当集群中存在非临时实例时,采用CP(强一致)模式;Eureka采用AP方式
-
Nacos还支持了配置中心,eureka则只有注册中心,也是选择使用nacos的一个重要原因
(2)负载均衡
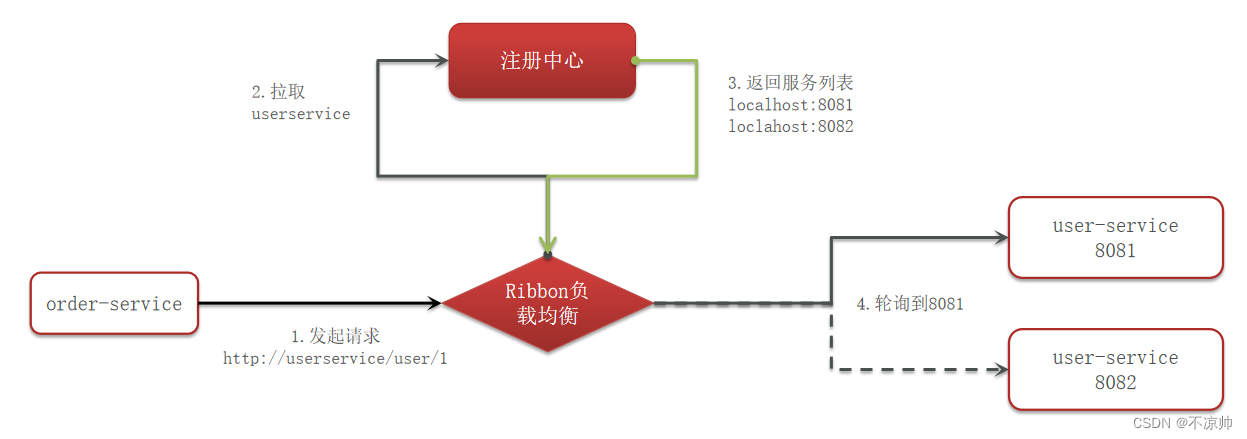
Ribbon负载均衡策略:
-
RoundRobinRule:简单轮询服务列表来选择服务器
-
WeightedResponseTimeRule:按照权重来选择服务器,响应时间越长,权重越小
-
RandomRule:随机选择一个可用的服务器
-
BestAvailableRule:忽略那些短路的服务器,并选择并发数较低的服务器
-
RetryRule:重试机制的选择逻辑
-
AvailabilityFilteringRule:可用性敏感策略,先过滤非健康的,再选择连接数较小的实例
-
ZoneAvoidanceRule:以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询
自定义负载均衡策略:
可以自己创建类实现IRule接口 , 然后再通过配置类或者配置文件配置即可 ,通过定义IRule实现可以修改负载均衡规则,有两种方式:
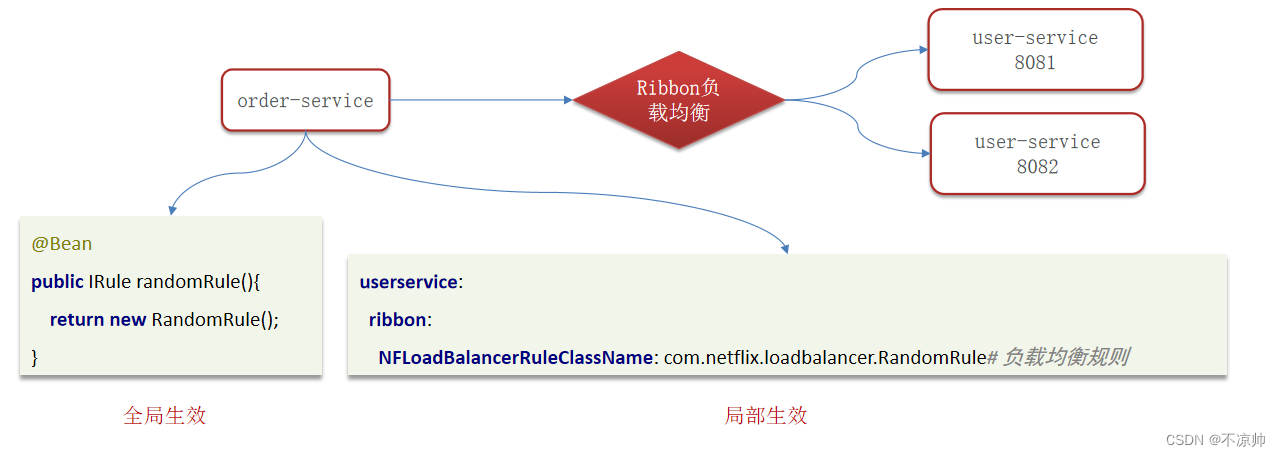
提供了两种方式:
-
创建类实现IRule接口,可以指定负载均衡策略(全局)
-
在客户端的配置文件中,可以配置某一个服务调用的负载均衡策略(局部)
(3)熔断、降级
雪崩问题指的是一个服务失败,导致整条链路的服务都失败的情形。一般使用服务熔断降级解决。
服务降级是服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃。
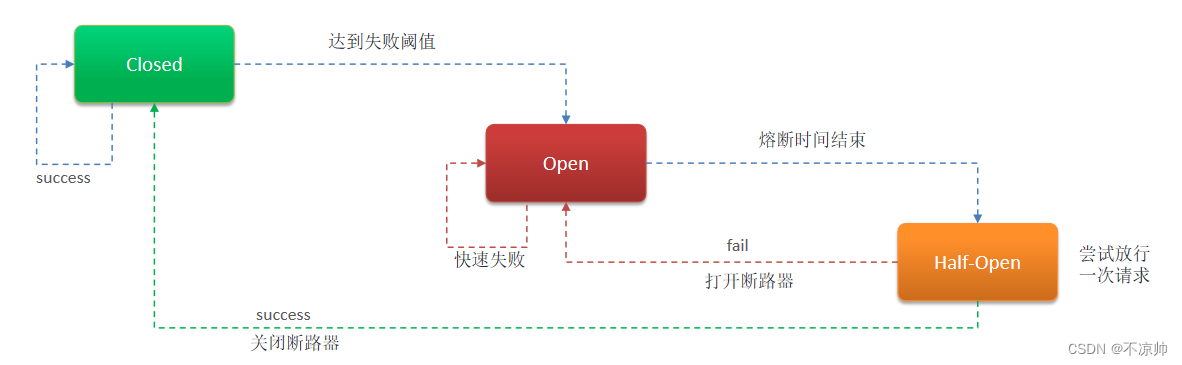
Hystrix 熔断机制,用于监控微服务调用情况, 默认是关闭的,如果需要开启需要在引导类上添加注解:@EnableCircuitBreaker如果检测到 10 秒内请求的失败率超过 50%,就触发熔断机制。之后每隔 5 秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求。
(4)监控
skywalking是一个分布式系统的应用程序性能监控工具( Application Performance Managment ),提供了完善的链路追踪能力, apache的顶级项目(前华为产品经理吴晟主导开源)
-
服务(service):业务资源应用系统(微服务)
-
端点(endpoint):应用系统对外暴露的功能接口(接口)
-
实例(instance):物理机
我们项目中采用的skywalking进行监控的
-
skywalking主要可以监控接口、服务、物理实例的一些状态。特别是在压测的时候可以看到众多服务中哪些服务和接口比较慢,我们可以针对性的分析和优化。
-
我们还在skywalking设置了告警规则,特别是在项目上线以后,如果报错,我们分别设置了可以给相关负责人发短信和发邮件,第一时间知道项目的bug情况,第一时间修复。
二、cloud业务相关处理
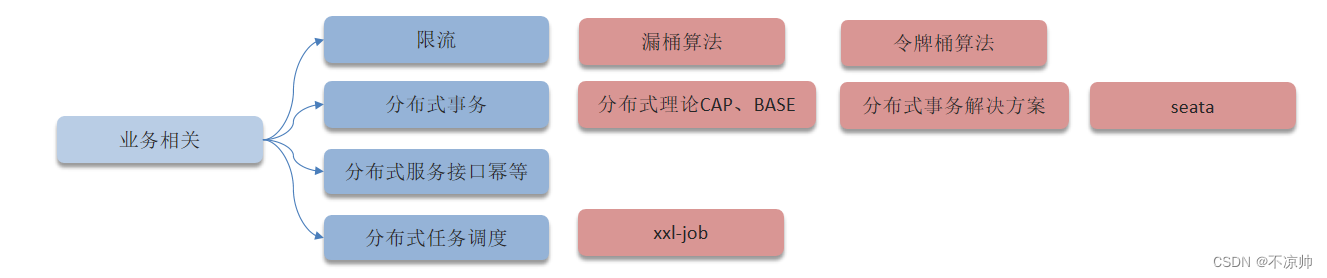
(1)限流
为什么要限流?1.并发的确大(突发流量)2.防止用户恶意刷接口
限流的实现方式:
-
Tomcat:可以设置最大连接数
-
Nginx:漏桶算法
-
网关:令牌桶算法
-
自定义拦截器
-
sentinel哨兵
1、nginx漏桶算法

控制速率(突发流量)
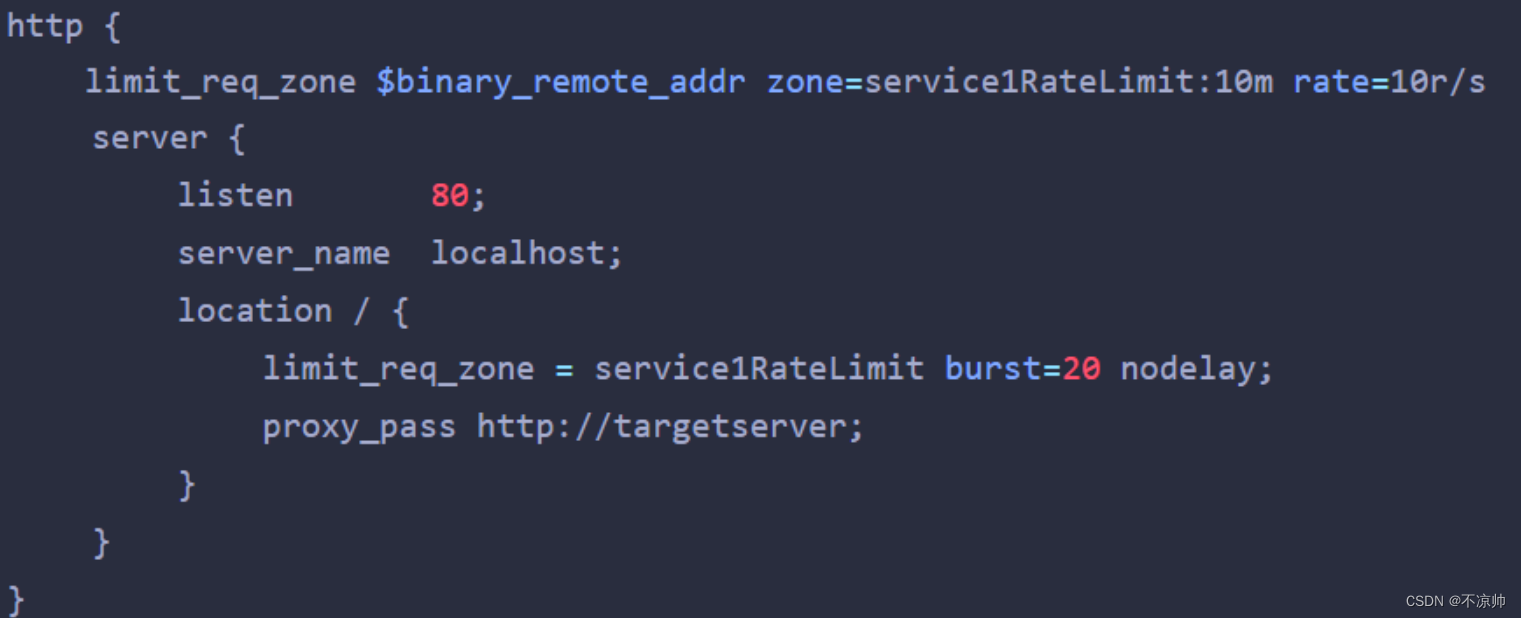
-
key:定义限流对象,binary_remote_addr就是一种key,基于客户端ip限流
-
Zone:定义共享存储区来存储访问信息,10m可以存储16wip地址访问信息
-
Rate:最大访问速率,rate=10r/s 表示每秒最多请求10个请求
-
burst=20:相当于桶的大小
-
Nodelay:快速处理
控制并发连接数
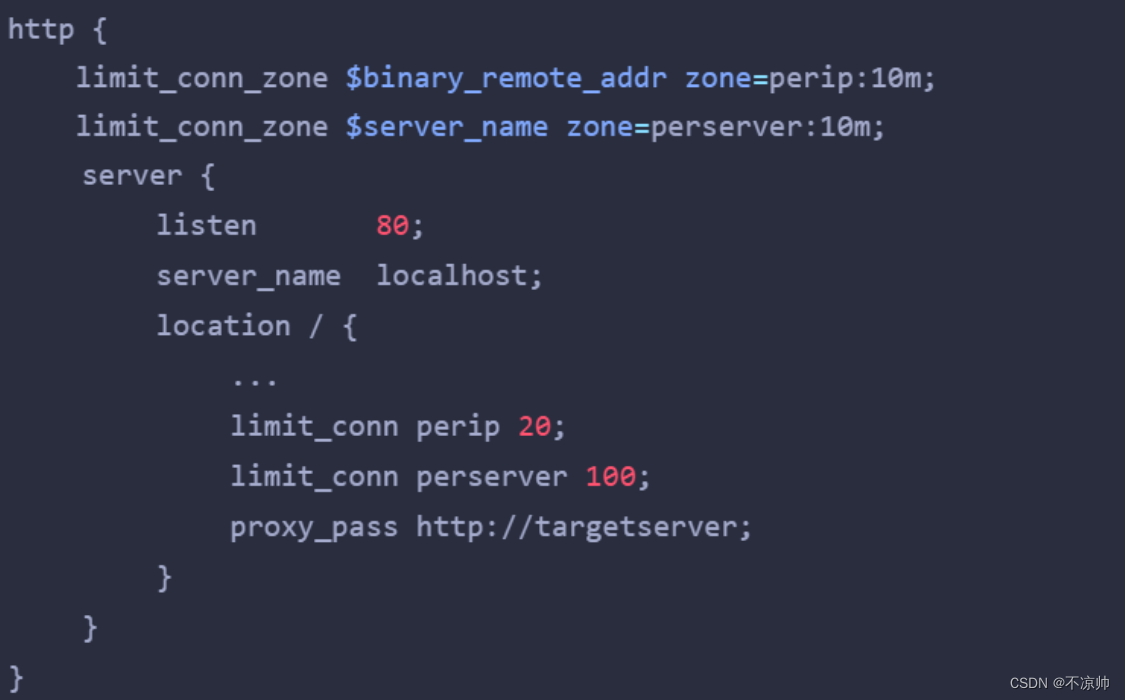
-
limit_conn perip 20:对应的key是 $binary_remote_addr,表示限制单个IP同时最多能持有20个连接。
-
limit_conn perserver 100:对应的key是 $server_name,表示虚拟主机(server) 同时能处理并发连接的总数。
2、gateway令牌桶算法

yml配置文件中,微服务路由设置添加局部过滤器RequestRateLimiter
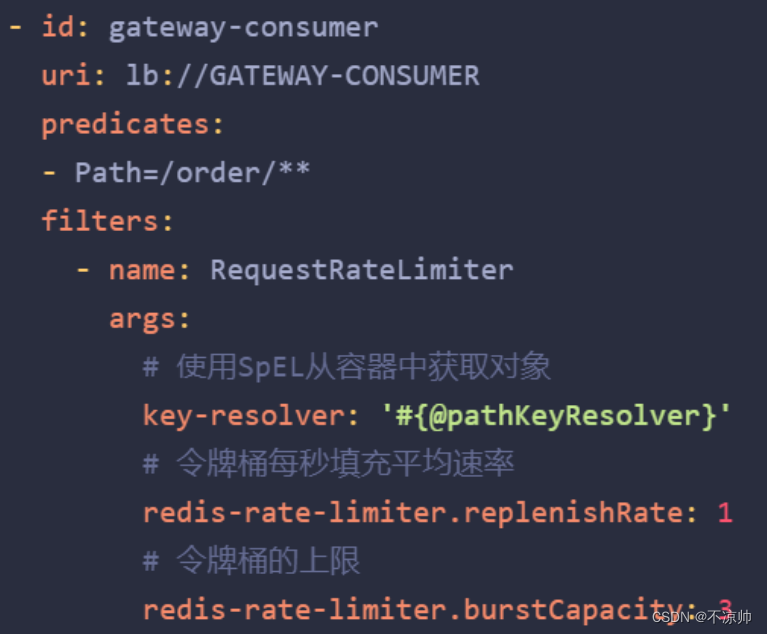
-
key-resolver :定义限流对象( ip 、路径、参数),需代码实现,使用spel表达式获取。
-
replenishRate :令牌桶每秒填充平均速率。
-
urstCapacity :令牌桶总容量。
(2)分布式事务
1、分布式理论CAP、BASE
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标:
-
Consistency(一致性): 用户访问分布式系统中的任意节点,得到的数据必须一致。
-
Availability(可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝。
-
Partition tolerance (分区容错性):因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区,在集群出现分区时,整个系统也要持续对外提供服务。
Eric Brewer 说,分布式系统无法同时满足这三个指标。这个结论就叫做 CAP 定理。
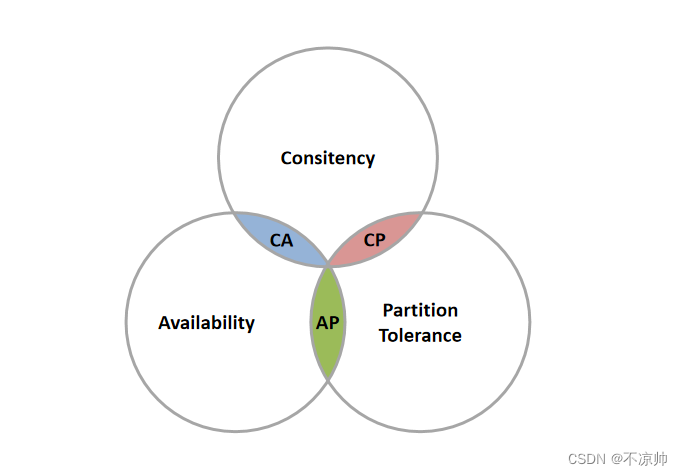
结论:
-
分布式系统节点之间肯定是需要网络连接的,分区(P)是必然存在的
-
如果保证访问的高可用性(A),可以持续对外提供服务,但不能保证数据的强一致性 --> AP
-
如果保证访问的数据强一致性(C),就要放弃高可用性 --> CP
BASE理论是对CAP的一种解决思路,包含三个思想:
-
Basically Available (基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
-
Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
-
Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
解决分布式事务的思想和模型:
-
最终一致思想:各分支事务分别执行并提交,如果有不一致的情况,再想办法恢复数据(AP)
-
强一致思想:各分支事务执行完业务不要提交,等待彼此结果。而后统一提交或回滚(CP)
2、分布式事务解决方案Seata
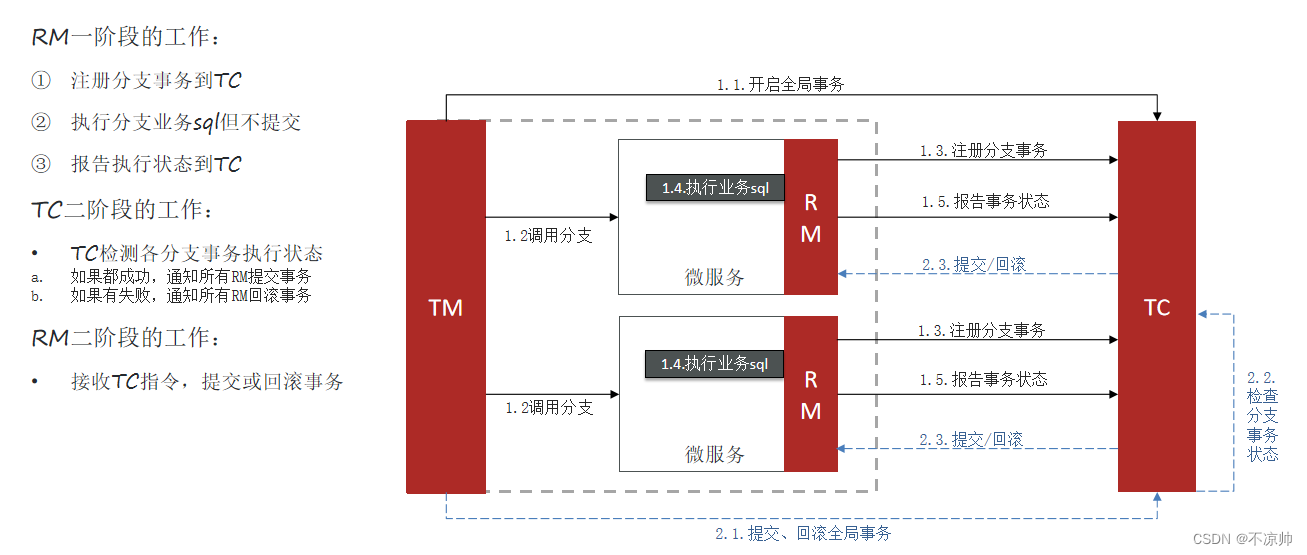
Seata事务管理中有三个重要的角色:
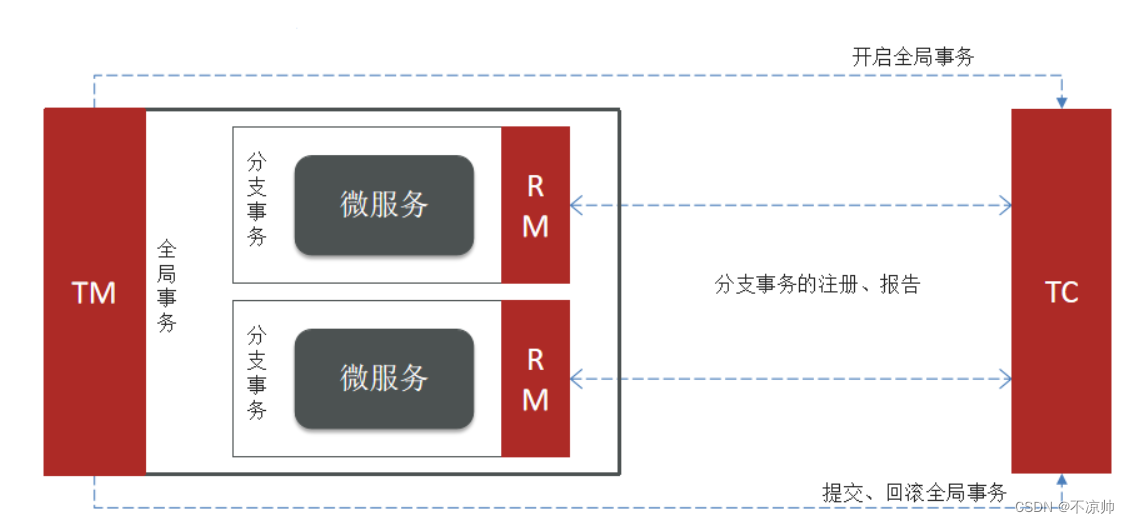
-
TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
-
TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
-
RM (Resource Manager) - 资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
简历上写的微服务,只要是发生了多个服务之间的写操作,都需要进行分布式事务控制。
描述项目中采用的哪种方案(seata | MQ)
-
seata的XA模式,CP,需要互相等待各个分支事务提交,可以保证强一致性,性能差
-
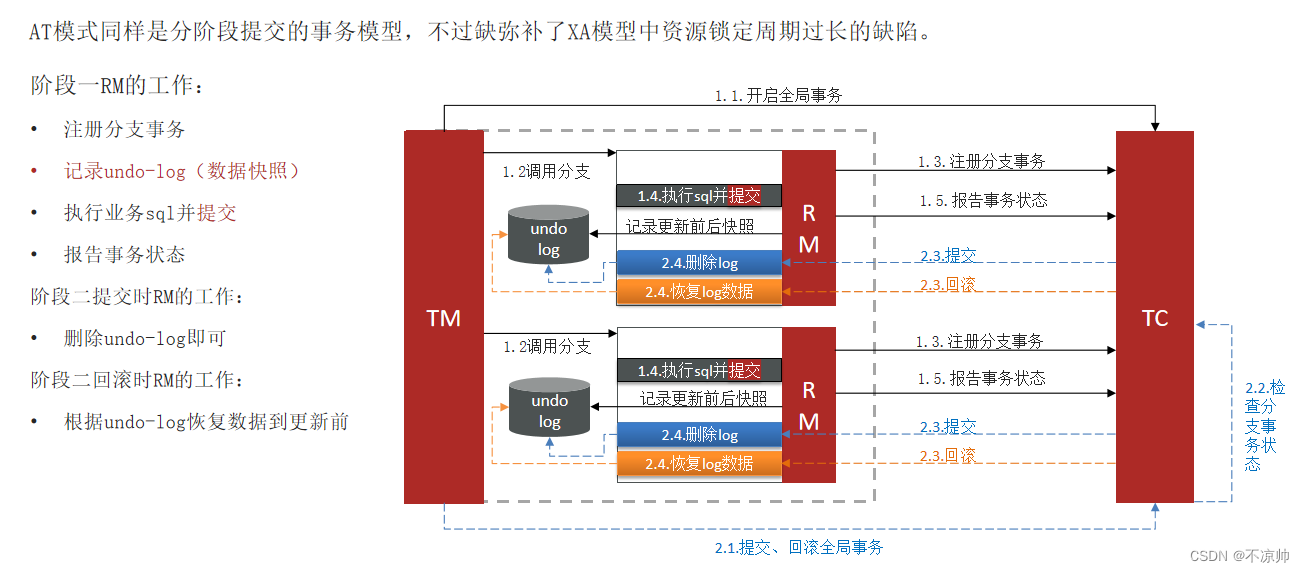
seata的AT模式,AP,底层使用undo log 实现,性能好
-
seata的TCC模式,AP,性能较好,不过需要人工编码实现

-
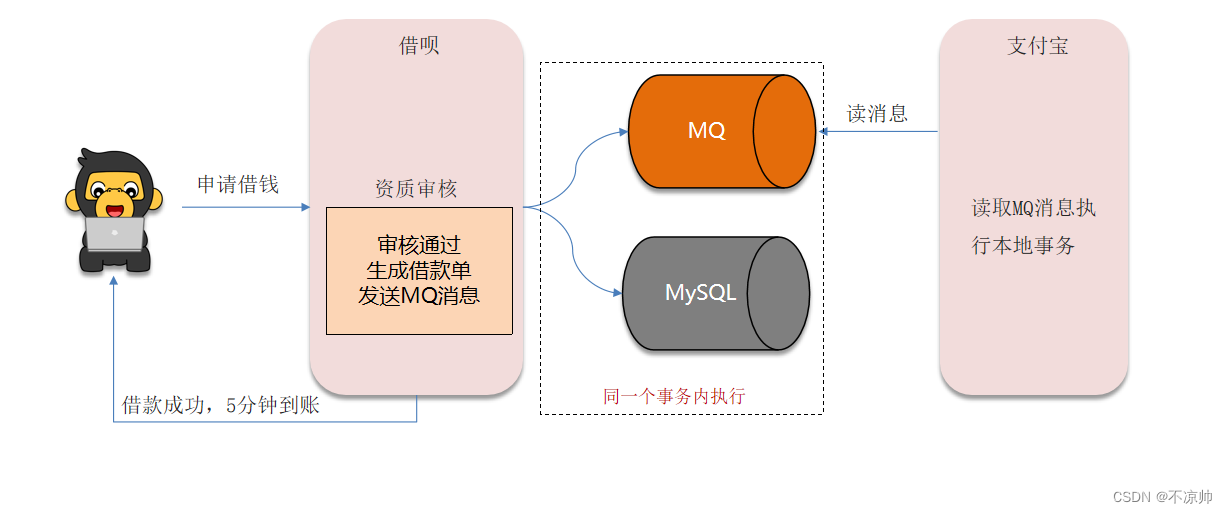
MQ模式实现分布式事务,在A服务写数据的时候,需要在同一个事务内发送消息到另外一个事务,异步,性能最好
(3)分布式服务接口幂等
幂等: 多次调用方法或者接口不会改变业务状态,可以保证重复调用的结果和单次调用的结果一致。
需要幂等场景:用户重复点击(网络波动)、MQ消息重复、应用使用失败或超时重试机制。
-
基于RESTful API的角度对部分常见类型请求的幂等性特点进行分析:

分布式服务的接口幂等性如何设计?
-
如果是新增数据,可以使用数据库的唯一索引
-
如果是新增或修改数据
1. 分布式锁,性能较低使用。
2. token+redis来实现,性能较好。第一次请求,生成一个唯一token存入redis,返回给前端。第二次请求,业务处理,携带之前的token,到redis进行验证,如果存在,可以执行业务,删除token;如果不存在,则直接返回,不处理业务。
(4)分布式事务任务调度
xxl-job提供了很多的路由策略,我们平时用的较多就是:轮询、故障转移、分片广播…
xxl-job任务执行失败怎么解决?
-
路由策略选择故障转移,使用健康的实例来执行任务
-
设置重试次数
-
查看日志+邮件告警来通知相关负责人解决
如果有大数据量的任务同时都需要执行,怎么解决?
-
让多个实例一块去执行(部署集群),路由策略分片广播
-
在任务执行的代码中可以获取分片总数和当前分片,按照取模的方式分摊到各个实例执行
三、MQ篇
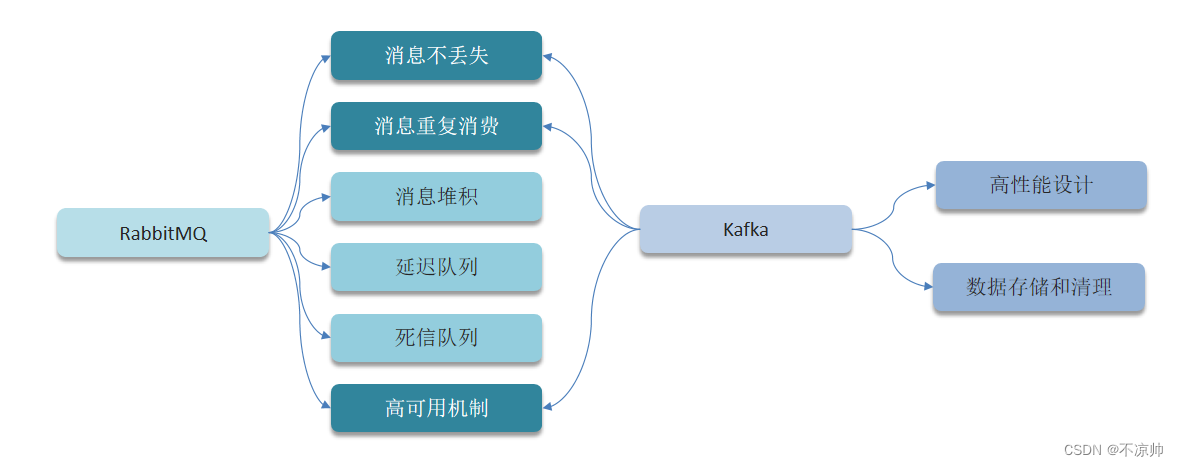
多个MQ如何选型?
-
RabbitMQ:erlang开发,对消息堆积的支持并不好,当大量消息积压的时候,会导致RabbitMQ的性能急剧下降,每秒可以处理几万到几十万条消息。
-
RocketMQ:java开发,面向互联网集群化,功能丰富,对在线业务的响应延迟做了很多优化,大多数情况下可以做到毫秒级的响应,每秒钟大概能处理几十万条消息。
-
kafka:scala开发,面向日志,功能丰富,性能最高,当你的业务中,每秒钟消息数量没那么多的时候,Kafka的延时反而会比较高,所以kafka不太适合在线业务场景。
-
ActiveMQ:java开发,简单,稳定,性能不如其他的,小型系统用也可以,但不推荐使用。
为什么要使用MQ?
解耦:降低系统之间的耦合度。 异步。 流量削峰:请求达到峰值后,后端service开可以用固定消费速率消费,不会被压垮。
(1)RabbitMQ
1、消息不丢失
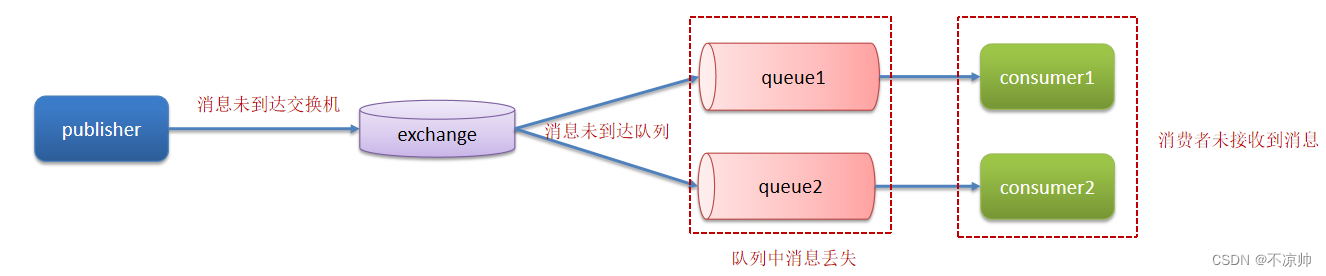
主要从三个层面考虑:
第一层:开启生产者确认机制,确保生产者的消息能到达队列。
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。
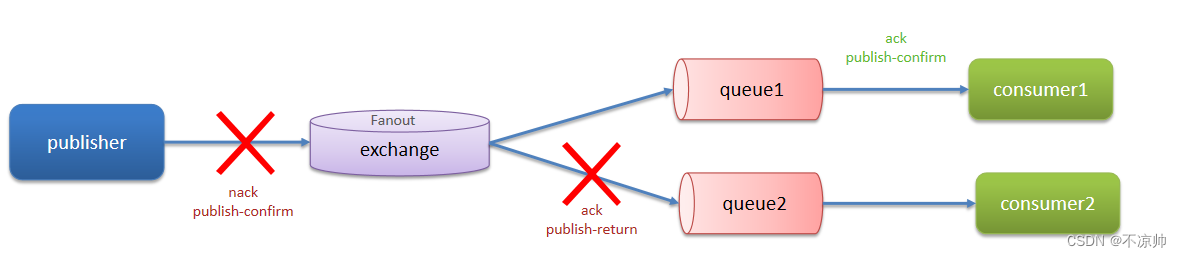
消息失败之后如何处理呢?
-
回调方法即时重发
-
记录日志
-
保存到数据库然后定时重发,成功发送后即刻删除表中的数据
第二层:开启持久化功能,确保消息未消费前在队列中不会丢失。
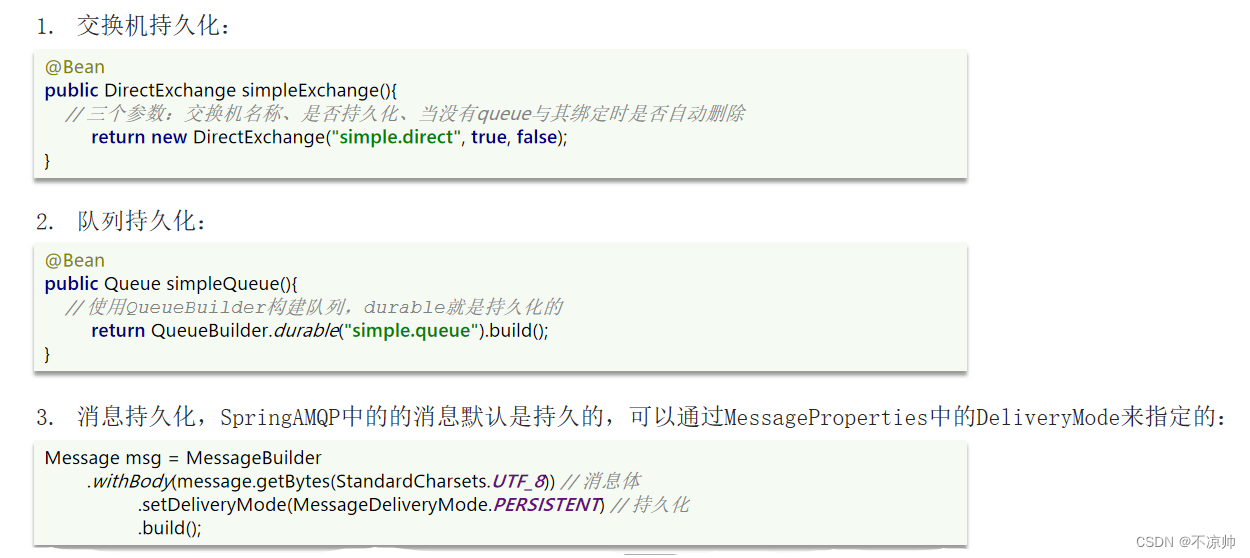
确保消息未消费前在队列中不会丢失,其中的交换机、队列、和消息都要做持久化
第三层:开启消费者确认机制为auto,由spring确认消息处理成功后完成ack(应答信号)。
SpringAMQP则允许配置三种确认模式:
-
manual:手动ack,需要在业务代码结束后,调用api发送ack。
-
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
-
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
开启消费者失败重试机制,多次重试失败后将消息投递到异常交换机,交由人工处理。
2、消息重复消费
网络抖动或者是消费者挂了,都有可能导致消息重复消费。
解决方案:
-
每条消息设置一个唯一的标识id
-
幂等方案:【 分布式锁、数据库锁(悲观锁、乐观锁) 】
3、消息堆积
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
解决消息堆积有三种种思路:
-
增加更多消费者,提高消费速度
-
在消费者内开启线程池加快消息处理速度
-
扩大队列容积,提高堆积上限
4、延迟队列
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
-
消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为false
-
消息是一个过期消息,超时无人消费
-
要投递的队列消息堆积满了,最早的消息可能成为死信

如果该队列配置了dead-letter-exchange属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机(Dead Letter Exchange,简称DLX)。
-
我们当时一个什么业务使用到了延迟队列(超时订单、限时优惠、定时发布…)
-
其中延迟队列就用到了死信交换机和TTL(消息存活时间)实现的
-
消息超时未消费就会变成死信(死信的其他情况:拒绝被消费,队列满了)
延迟队列插件实现延迟队列DelayExchange
-
声明一个交换机,添加delayed属性为true
-
发送消息时,添加x-delay头,值为超时时间
5、惰性队列
惰性队列的特征如下:

-
接收到消息后直接存入磁盘而非内存
-
消费者要消费消息时才会从磁盘中读取并加载到内存
-
支持数百万条的消息存储
如果有100万消息堆积在MQ , 如何解决 ?
-
提高消费者的消费能力 ,可以使用多线程消费任务。
-
增加更多消费者,提高消费速度。使用工作队列模式, 设置多个消费者消费消费同一个队列中的消息
-
扩大队列容积,提高堆积上限。可以使用RabbitMQ惰性队列,惰性队列的好处主要是:
①接收到消息后直接存入磁盘而非内存
②消费者要消费消息时才会从磁盘中读取并加载到内存
③支持数百万条的消息存储
6、高可用机制
一般有的方案有普通集群、镜像集群、仲裁队列。
普通集群,或者叫标准集群(classic cluster),具备下列特征:
-
会在集群的各个节点间共享部分数据,包括:交换机、队列元信息。不包含队列中的消息。
-
当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
-
队列所在节点宕机,队列中的消息就会丢失
镜像集群:一般用得最多,本质是主从模式,具备下面的特征:
-
交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份。
-
创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
-
一个队列的主节点可能是另一个队列的镜像节点
-
所有操作都是主节点完成,然后同步给镜像节点
-
主宕机后,镜像节点会替代成新的主节点
仲裁队列:仲裁队列是3.8版本以后才有的新功能,用来替代镜像队列。

具备下列特征:
-
与镜像队列一样,都是主从模式,支持主从数据同步
-
使用非常简单,没有复杂的配置
-
主从同步基于Raft协议,强一致
(2)Kafka
1、消息不丢失
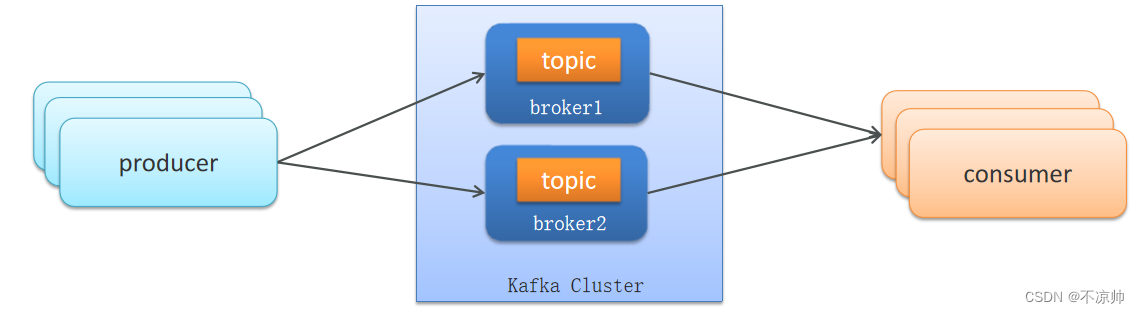
使用Kafka在消息的收发过程都会出现消息丢失 , Kafka分别给出了解决方案:
生产者发送消息到Brocker丢失时:
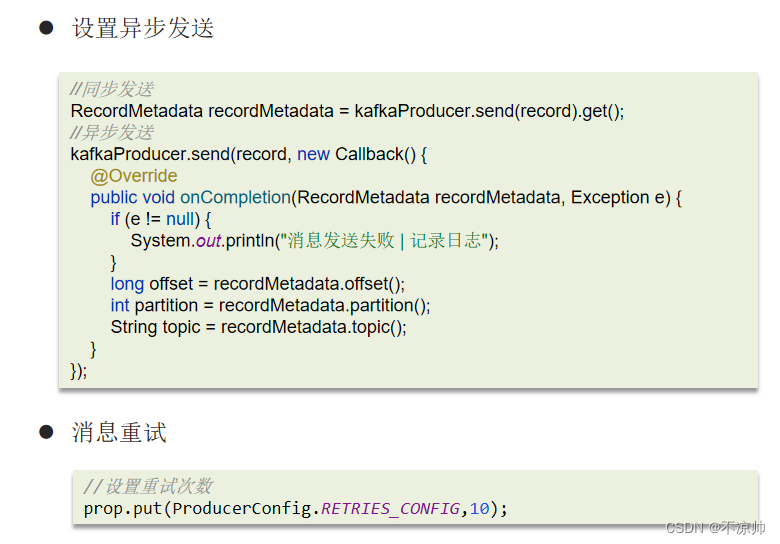
消息在Brocker中存储丢失时:

消费者从Brocker接收消息丢失时:

-
关闭自动提交偏移量,开启手动提交偏移量
-
提交方式,最好是同步+异步提交
2、消息重复消费
解决方案:
-
关闭自动提交偏移量,开启手动提交偏移量
-
提交方式,最好是同步+异步提交
-
幂等方案(对于同一操作多次执行的结果与一次执行的结果相同)
Kafka是如何保证消费的顺序性?一个topic的数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序性解决方案:
-
发送消息时指定分区号
-
发送消息时按照相同的业务设置相同的key
3、高可用机制
集群模式
一个kafka集群由多个broker实例组成,即使某一台宕机,也不耽误其他broker继续对外提供服务。
分区备份机制
-
一个topic有多个分区,每个分区有多个副本,有一个leader,其余的是follower,副本存储在不同的broker中
-
所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader,保证了系统的容错性、高可用性。ISR(in-sync replica)需要同步复制保存的follower分区副本分为了两类,一个是ISR,与leader副本同步保存数据,另外一个普通的副本,是异步同步数据,当leader挂掉之后,会优先从ISR副本列表中选取一个作为leader。
4、数据存储和清理
Kafka存储结构:
-
Kafka存储结构Kafka中topic的数据存储在分区上,分区如果文件过大会分段存储segment
-
每个分段都在磁盘上以索引(xxxx.index)和日志文件(xxxx.log)的形式存储
-
分段的好处是,第一能够减少单个文件内容的大小,查找数据方便,第二方便kafka进行日志清理。
日志的清理策略有两个:
-
根据消息的保留时间,当消息保存的时间超过了指定的时间,就会触发清理,默认是168小时( 7天)
-
根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。(默认关闭)
5、高性能设计
-
消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
-
顺序读写:磁盘顺序读写,提升读写效率
-
页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
-
零拷贝:减少上下文切换及数据拷贝
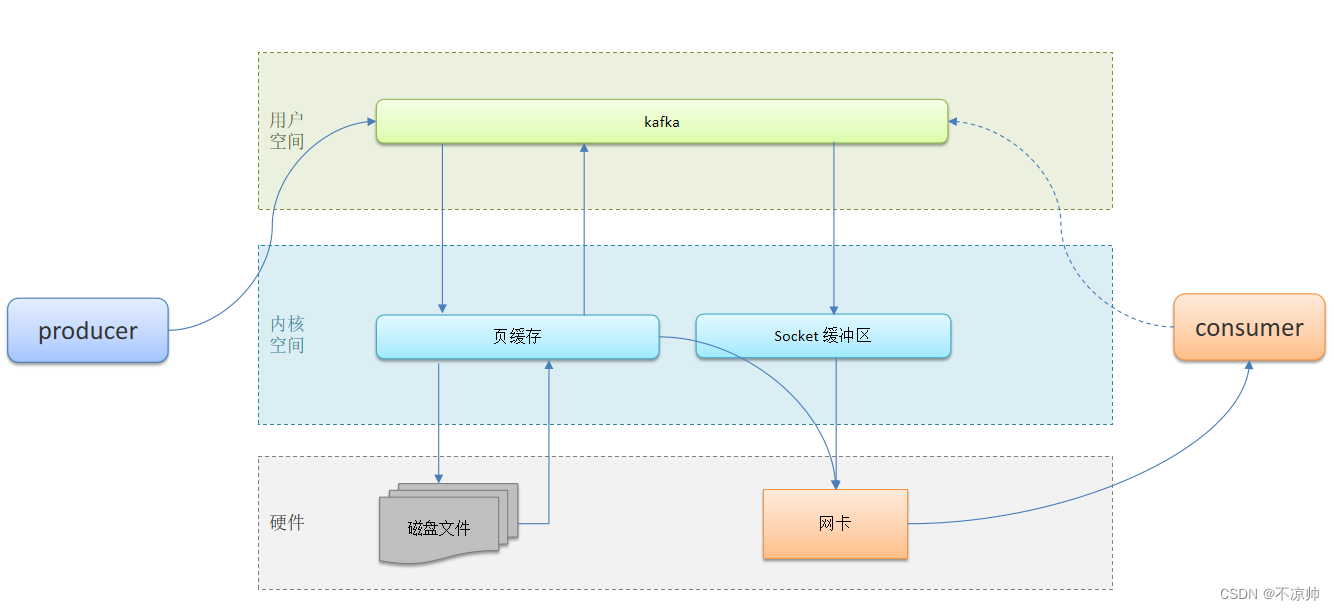
-
消息压缩:减少磁盘IO和网络IO
-
分批发送:将消息打包批量发送,减少网络开销
(3)RocketMQ
1、工作流程
RocketMQ的角色组成:
-
nameServer:无状态,动态列表。
-
producer:消息生产者,负责发送消息到broker。
-
broker:就是MQ本身,负责收发消息,持久化消息等。
-
consumer:消息消费者,负责从broker上拉取消息进行消费,消费完进行ack。
RockerMQ的工作流程:
-
启动nameServer,nameServer启动后开始监听端口,等待Broker Producer,Consumer连接。
-
启动Broker时,Broker会与所有nameServer建立并保持长连接,然后每30秒向nameServer定时发送心跳包
-
发送消息前,可以先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,当然,在创建Topic时也会将Topic与Broker的关系写入到NameServer中,不过这步时可选的,也可以在发送消息时自动创建topic。
-
Produce发送消息,启动共时先跟nameServer集群中的其中一台建立长连接,并从nameServer中获取路由信息,即当前发送的Topic消息的queue与broleer的地址的映射关系,然后根据算法策略从队列选择一个queue,与队列所在的Broker建立长连接,从而向broker发送消息,当然,在获取到路由信息后,producer会首先将路由信息缓存到本地,再每30秒从nameServer更新一次路由信息。
-
Consumer跟Producer类似,跟其中一台NameServer建立连接,获取其所订阅Topic的路由信息,然后根据算法策略从路由信息中获取到其所要消费的Queue,然后直接跟broker建立长连接,开始消费其中的消息,Consumer在获取到路由信息后,同样也会每30秒从nameService更新一次路由信息,不过不同与producer的是,Consumer还会向broker发送心跳,以确保broker的存活状态。
2、消费模式
RocketMQ有几种消费模式:
-
集群消费:一条消息指挥被同group的一个consumer消费,多个group同时消费一个topic时,每个group都会有一个consumer消费到数据。
-
广播消费:消息将对一个consumer group下的各个consumer实例都消费一遍。
消费消息是push 还是 pull?
-
RockerMQ没有真正意义上的push,都是pull,虽然有push类,但实际上底层实现采用的都是长轮询机制。
为什么要主动要拉取消息, 而不是使用事件监听方式?
-
事件驱动方式时建立好长连接,由事件(发送数据)的方式来实时推送。
-
如果Broker主动推送消息的话,有可能push速度快,消费速度慢,那么就会造成消息再consumer端堆积过多,同时又不能被其他consumer消费的情况,而pull的方式可以根据当前自身情况来pull,不会造成过多的压力而造成瓶颈,所以采取了pull方式。
相关文章:
interview3-微服务与MQ
一、SpringCloud篇 (1)服务注册 常见的注册中心:eureka、nacos、zookeeper eureka做服务注册中心: 服务注册:服务提供者需要把自己的信息注册到eureka,由eureka来保存这些信息,比如服务名称、…...
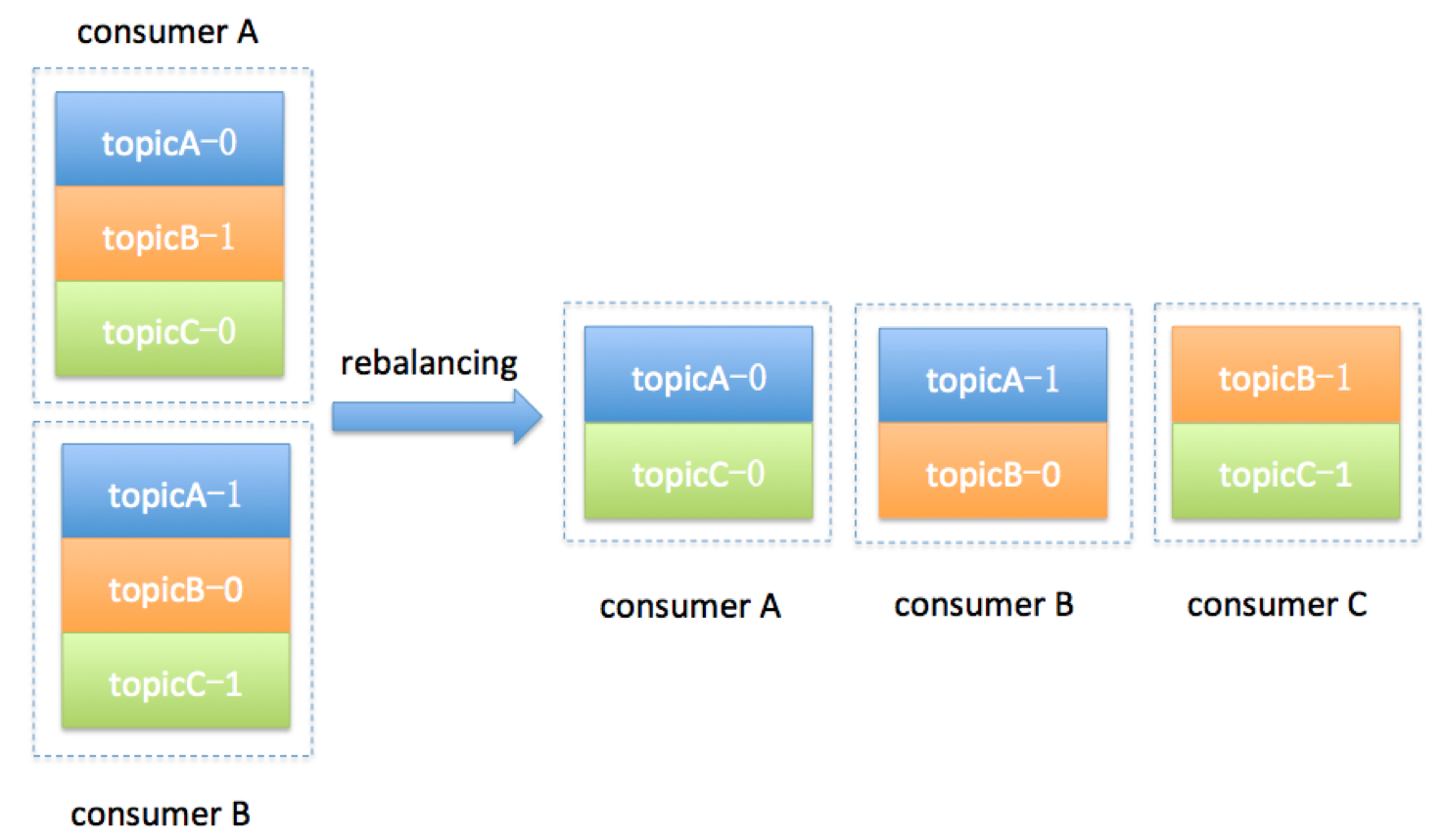
kafka详解一
kafka详解一 1、消息引擎背景 根据维基百科的定义,消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递. 即:系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A…...

Flutter yuv 转 rgb
1、引用yuv_converter库 yuv_converter: ^0.0.1 2、导入头文件: import package:yuv_converter/yuv_converter.dart;3、yuv转rgb YuvConverter.yuv420NV21ToRgba8888(yuvRawData, 512, 512) 根据yuv格式选择不同的api。 举个例子: void initState() …...

MySQL——子查询
2023.9.8 相关学习笔记: #子查询 /* 含义: 出现在其他语句中的select语句,称为子查询或内查询 外部的查询语句,称为主查询或外查询分类: 按子查询出现的位置:select后面:仅仅支持标量子查询fro…...
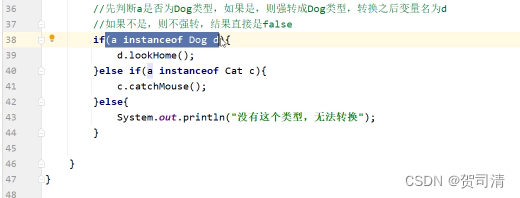
Java学习笔记---多态
面向对象三大特征之一(继承,封装,多态) 多态的应用场景:根据传递对象的不同,调用不同的show方法 一、多态的定义 同类型的对象,表现出的不同形态(对象的多种形态) 二…...

2023-09-10 LeetCode每日一题(课程表 II)
2023-09-10每日一题 一、题目编号 210. 课程表 II二、题目链接 点击跳转到题目位置 三、题目描述 现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] [ai, bi] ,表示在…...

合并区间【贪心算法】
合并区间 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 class Solution {public int[][] merge(int[…...
2023,软件测试人的未来在哪里?
2023年,IT行业出现空前的萧条,首先是年初一开始各大厂像着了魔似的不约而同的纷纷裁员、降薪、奖金包缩水,随之而来的是需求萎缩,HC减少或封锁等等。 而有幸未被列入裁员名单的在职人员,庆幸之余也心有余悸࿰…...
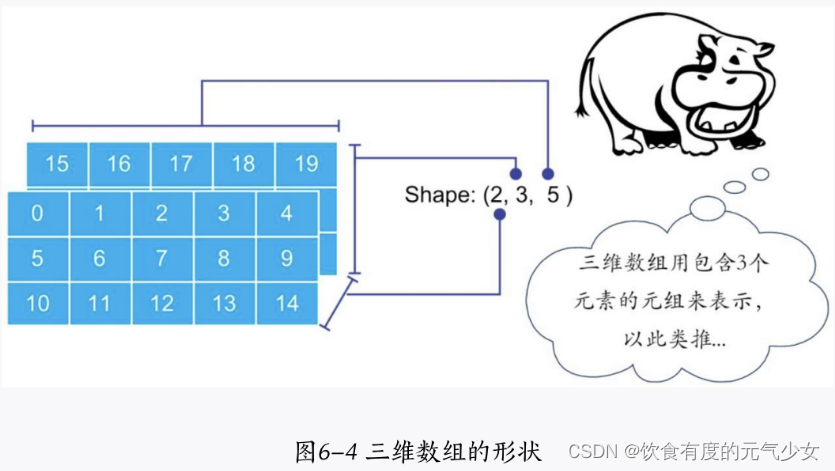
Python中的Numpy向量计算(R与Python系列第三篇)
目录 一、什么是Numpy? 二、如何导入NumPy? 三、生成NumPy数组 3.1利用序列生成 3.2使用特定函数生成NumPy数组 (1)使用np.arange() (2)使用np.linspace() 四、NumPy数组的其他常用函数 (1)np.z…...
LeetCode刷题笔记【27】:贪心算法专题-5(无重叠区间、划分字母区间、合并区间)
文章目录 前置知识435. 无重叠区间题目描述参考<452. 用最少数量的箭引爆气球>, 间接求解直接求"重叠区间数量" 763.划分字母区间题目描述贪心 - 建立"最后一个当前字母"数组优化marker创建的过程 56. 合并区间题目描述解题思路代码① 如果有重合就合…...

nvidia-smi 命令详解
nvidia-smi 命令详解 1. nvidia-smi 面板解析2. 显存与GPU的区别 Reference: nvidia-smi命令详解 相关文章: nvidia-smi nvcc -V 及 CUDA、cuDNN 安装 nvidia-smi(NVIDIA System Management Interface) 是一种命令行实用程序,用于监控和管理 NVIDIA G…...
函数的返回值)
fork()函数的返回值
在程序中,int pd fork() 是一个典型的 fork() 调用。fork() 函数会创建一个新的进程,然后在父进程中返回子进程的进程ID(PID),在子进程中返回0。所以 pd 的值会根据当前进程是父进程还是子进程而有所不同:…...
)
Stable Diffusion WebUI挂VPN不能跑图解决办法(Windows)
如何解决SD在打开VPN的状态不能运行的问题 在我们开VPN的时候会出现无法生成图片,也无法做其他任何事,这个时候是不是很着急呢? 别急,我这里会说明如何解决。 就像这样,运行半天生成不了图,有时还会出现…...

Android的本地数据
何为本地,即写完之后除非手动修改,否像嘎了一样在那固定死了 有些需求可能也会要求我们去写死数据,因为这需求是一成不变的,那么你通常会用什么方法写死呢? 1. 本地存储-SharedPreferences 此方法可以长时间保存于手…...

android NDK 开发包,网盘下载,不限速
记录下ndk 开发包的地址,分享给大家。 另外有Android studio的下载包, 在另一篇文章 链接:http://t.csdn.cn/JSr9x Android Studio.exe 下载 2023 最新更新,网盘下载_hsj-obj的博客-CSDN博客 主要是19-25,其他的没有…...

【每日一题Day320】LC2651计算列车到站时间 | 数学
计算列车到站时间【LC2651】](https://leetcode.cn/problems/calculate-delayed-arrival-time/) 给你一个正整数 arrivalTime 表示列车正点到站的时间(单位:小时),另给你一个正整数 delayedTime 表示列车延误的小时数。 返回列车实…...
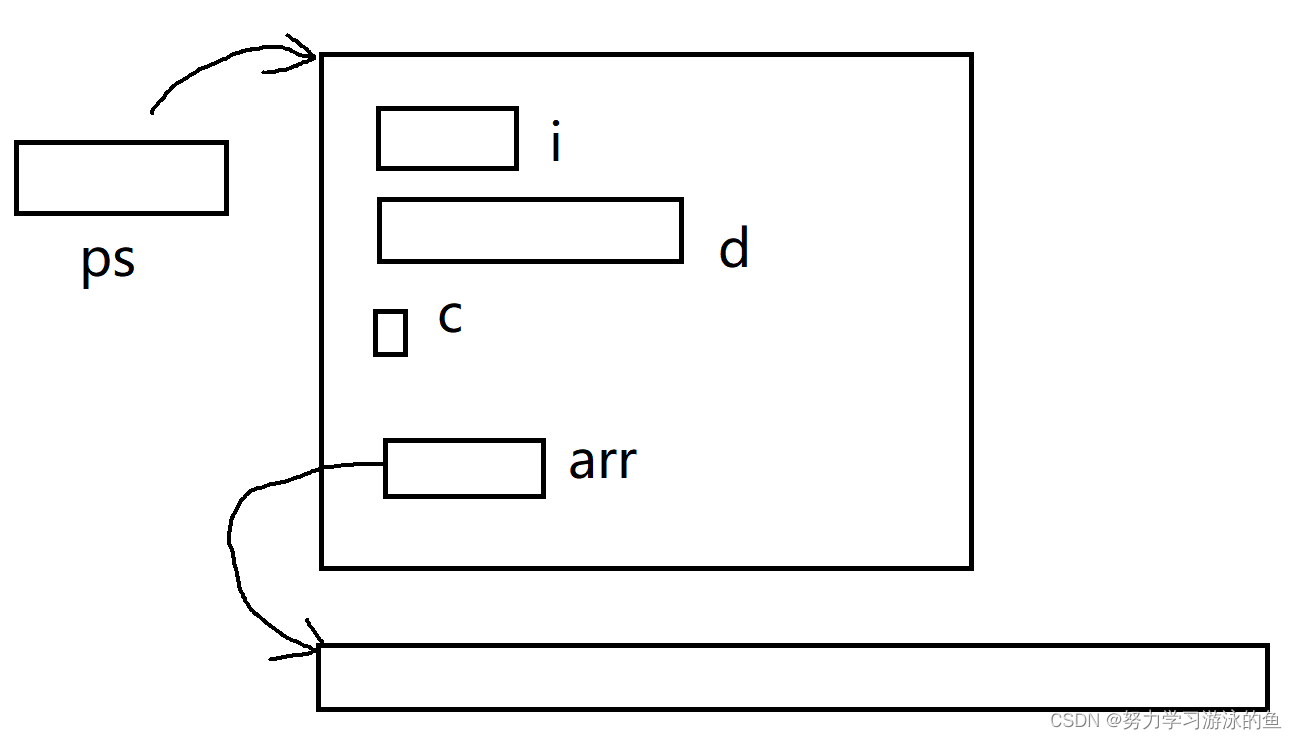
C语言柔性数组详解:让你的程序更灵活
柔性数组 一、前言二、柔性数组的用法三、柔性数组的内存分布四、柔性数组的优势五、总结 一、前言 仔细观察下面的代码,有没有看出哪里不对劲? struct S {int i;double d;char c;int arr[]; };还有另外一种写法: struct S {int i;double …...
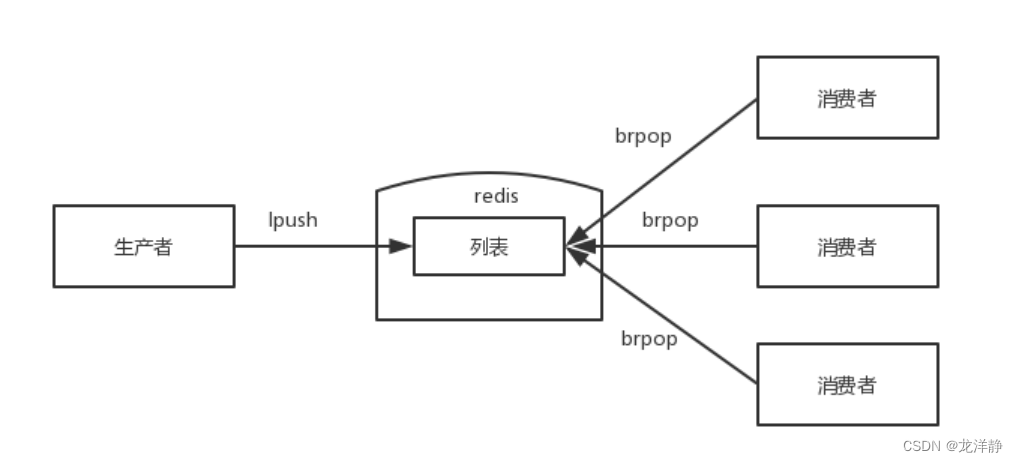
Redis-带你深入学习数据类型list
目录 1、list列表 2、list相关命令 2.1、添加相关命令:rpush、lpush、linsert 2.2、查找相关命令:lrange、lindex、llen 2.3、删除相关命令:lpop、rpop、lrem、ltrim 2.4、修改相关命令:lset 2.5、阻塞相关命令:…...

react拖拽依赖库react-dnd
注:对于表格自定义行可以拖拽和树自定义节点可以拖拽等比较适用,其余的拖拽处理可以使用dragstart,drop等js原生事件来实现 react-dnd使用方法很简单,直接上干货 第一步安装依赖并引入 import { DndProvider } from react-dnd;…...
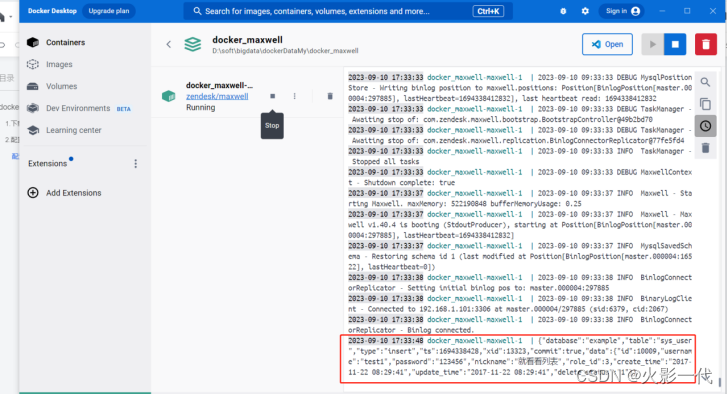
win10环境安装使用docker-maxwell
目的:maxwell可以监控mysql数据变化,并同步到kafka、mq或tcp等。 maxwell和canal区别: maxwell更轻量,canal把表结构也输出了 docker bootstrap可导出历史数据,canal不能 环境 :win10,mysql5…...

从科幻到现实:波色量子18.4亿融资背后,量子计算在多领域应用大突破!
【导语:科幻电影《流浪地球2》中智能量子计算机“MOSS”令人印象深刻,如今量子计算已从实验室走向商业化。波色量子成立三年获11轮融资共18.4亿,其量子计算在多领域展现出巨大应用潜力。】波色量子:资本竞逐中的宠儿按照“十五五规…...

如何用3分钟搞定视频字幕提取?揭秘这款本地化硬字幕提取神器
如何用3分钟搞定视频字幕提取?揭秘这款本地化硬字幕提取神器 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字…...

汽车存储技术演进:从边缘计算到车规级设计的核心挑战与选型指南
1. 汽车存储需求变迁:从机械心脏到数字大脑二十年前,我们选车看的是发动机的轰鸣、变速箱的平顺和底盘的扎实。如今,走进4S店,销售顾问会先带你坐进驾驶舱,点亮那块巨大的中控屏,演示语音助手、在线导航、高…...
:API调用失败率<0.8%的私有化部署方案首次公开)
Sora 2国内可用性深度测评(2024Q2最新版):API调用失败率<0.8%的私有化部署方案首次公开
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Sora 2视频生成怎么用 Sora 2 并非 OpenAI 官方发布的模型——截至目前(2024年中),OpenAI 仅公开了 Sora(初代)的演示能力࿰…...

终极指南:如何免费使用Umi-OCR实现高效离线文字识别
终极指南:如何免费使用Umi-OCR实现高效离线文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库…...

【Kanzi 资源系统完全笔记】
一、Resource 的类层次结构Kanzi 中所有资源(Resource)都继承自 Object 基类。下图是常见的资源继承体系(根据图片整理):Object└── Resource├── GPUResource # 位于 GPU 显存中的资源(纹理、…...

Python开发进阶之路:探索异步编程与高性能应用
在当今快节奏的软件开发环境中,构建高性能、可扩展的应用程序已成为开发者的首要任务。随着互联网应用的普及,用户对响应速度和并发处理能力的要求越来越高。Python,作为一种广泛使用的高级编程语言,凭借其简洁的语法和强大的生态…...

LangChain集成MCP协议:构建模块化AI应用的新范式
1. 项目概述:当LangChain遇见MCP,构建下一代AI应用的新范式如果你最近在捣鼓LangChain,想给AI应用加点“料”,比如让它能实时查询数据库、调用外部API,甚至控制智能家居,那你大概率会遇到一个核心痛点&…...

MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案
MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科芯片设备设计的开源逆向工程与刷机工具&am…...
)
Nature论文检索正在失效,Perplexity底层检索逻辑重构预警(仅限科研骨干内部流通的3条技术简报)
更多请点击: https://intelliparadigm.com 第一章:Nature论文检索正在失效,Perplexity底层检索逻辑重构预警(仅限科研骨干内部流通的3条技术简报) 检索信号衰减的实证观测 近期对Nature、Science主站及PubMed Centra…...