Kafka/Spark-01消费topic到写出到topic
1 Kafka的工具类
1.1 从kafka消费数据的方法
- 消费者代码
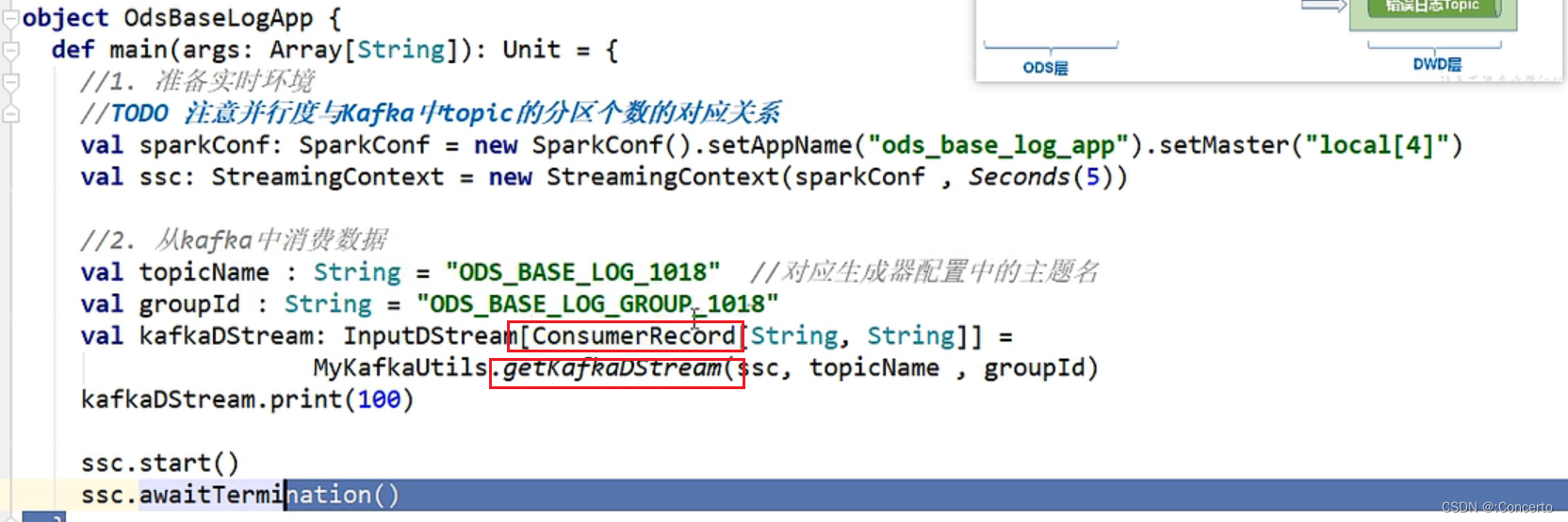
def getKafkaDStream(ssc : StreamingContext , topic: String , groupId:String ) ={consumerConfigs.put(ConsumerConfig.GROUP_ID_CONFIG , groupId)val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Array(topic), consumerConfigs))kafkaDStream}
- 注意点
- consumerConfigs是定义的可变的map的类型的,具体如下
private val consumerConfigs: mutable.Map[String, Object] = mutable.Map[String,Object](// kafka集群位置ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> MyPropsUtils(MyConfig.KAFKA_BOOTSTRAP_SERVERS),// kv反序列化器ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",// groupId// offset提交 自动 手动ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> "true",//自动提交的时间间隔//ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG// offset重置 "latest" "earliest"ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest"// .....)
-
consumerConfigs.put(ConsumerConfig.GROUP_ID_CONFIG , groupId)是为了不限制groupId特意写的传参
-
是使用自带的kafka工具类createDirectStream方法去消费kafak 的数据,详细参数解释如下
在`KafkaUtils.createDirectStream`方法中,后续传递的参数的含义如下:1. `ssc`:这是一个`StreamingContext`对象,用于指定Spark Streaming的上下文。
2. `LocationStrategies.PreferConsistent`:这是一个位置策略,用于指定Kafka消费者的位置策略。`PreferConsistent`表示优先选择分区分布均匀的消费者。
3. `ConsumerStrategies.Subscribe[String, String]`:这是一个消费者策略,用于指定Kafka消费者的订阅策略。`Subscribe[String, String]`表示按照指定的泛型主题字符串数组订阅消息,键和值的类型都为`String`。
4. `Array(topic)`:这是一个字符串数组,用于指定要订阅的Kafka主题。
5. `consumerConfigs`:这是一个`java.util.Properties`类型的对象,其中配置了一些Kafka消费者的属性。总之,在`KafkaUtils.createDirectStream`方法中,这些参数组合被用于创建一个Kafka直连流(Direct Stream),该流可以直接从Kafka主题中消费消息,并将其转换为`InputDStream[ConsumerRecord[String, String]]`类型的DStream。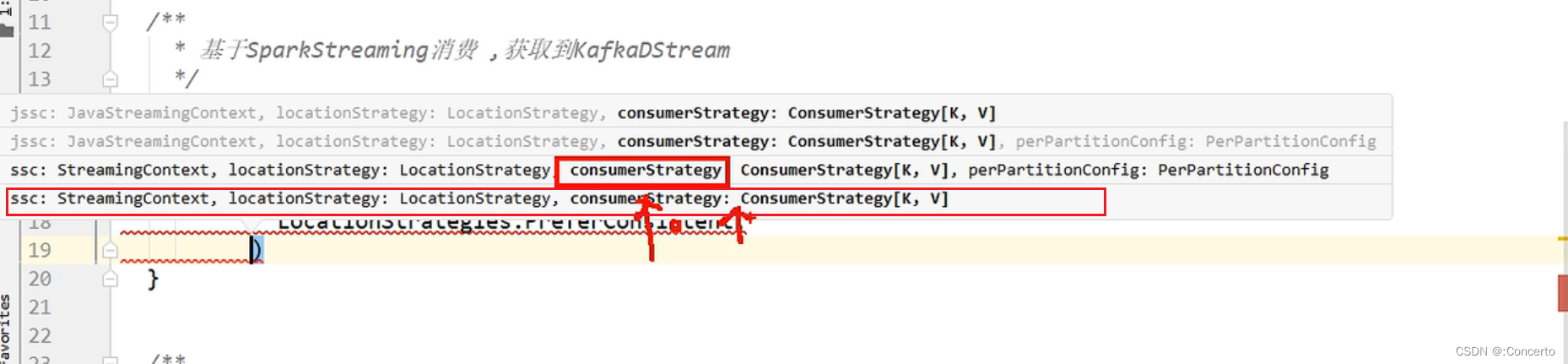
- Subscribe传参需要指定泛型,这边指定string,表示指定主题的键和值的类型,即Array(topic), consumerConfigs传参是string

- 最后方法返回一个kafkaDStream
1.2 kafka的生产数据的方法
- 生产者代码
- 创建与配置
/*** 生产者对象*/val producer : KafkaProducer[String,String] = createProducer()/*** 创建生产者对象*/def createProducer():KafkaProducer[String,String] = {val producerConfigs: util.HashMap[String, AnyRef] = new util.HashMap[String,AnyRef]//生产者配置类 ProducerConfig//kafka集群位置//producerConfigs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092,hadoop104:9092")//producerConfigs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,MyPropsUtils("kafka.bootstrap-servers"))producerConfigs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,MyPropsUtils(MyConfig.KAFKA_BOOTSTRAP_SERVERS))//kv序列化器producerConfigs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG , "org.apache.kafka.common.serialization.StringSerializer")producerConfigs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG , "org.apache.kafka.common.serialization.StringSerializer")//acksproducerConfigs.put(ProducerConfig.ACKS_CONFIG , "all")//batch.size 16kb//linger.ms 0//retries//幂等配置producerConfigs.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG , "true")val producer: KafkaProducer[String, String] = new KafkaProducer[String,String](producerConfigs)producer}
- 生产方法
/*** 生产(按照默认的黏性分区策略)*/def send(topic : String , msg : String ):Unit = {producer.send(new ProducerRecord[String,String](topic , msg ))}/**或者!* 生产(按照key进行分区)*/def send(topic : String , key : String , msg : String ):Unit = {producer.send(new ProducerRecord[String,String](topic , key , msg ))}
- 关闭生产
/*** 关闭生产者对象*/def close():Unit = {if(producer != null ) producer.close()}/*** 刷写 ,将缓冲区的数据刷写到磁盘**/def flush(): Unit ={producer.flush()}
2 消费数据
2.1 消费到数据
单纯的使用返回的ConsumerRecord不支持序列化,没有实现序列化接口
因此需要转换成通用的jsonobject对象
//3. 处理数据//3.1 转换数据结构val jsonObjDStream: DStream[JSONObject] = offsetRangesDStream.map(consumerRecord => {//获取ConsumerRecord中的value,value就是日志数据val log: String = consumerRecord.value()//转换成Json对象val jsonObj: JSONObject = JSON.parseObject(log)//返回jsonObj})
2.2 数据分流发送到对应topic
- 提取错误数据并发送到对应的topic中
jsonObjDStream.foreachRDD(rdd => {rdd.foreachPartition(jsonObjIter => {for (jsonObj <- jsonObjIter) {//分流过程//分流错误数据val errObj: JSONObject = jsonObj.getJSONObject("err")if(errObj != null){//将错误数据发送到 DWD_ERROR_LOG_TOPICMyKafkaUtils.send(DWD_ERROR_LOG_TOPIC , jsonObj.toJSONString )}else{}}}}
- 将公共字段和页面数据发送到DWD_PAGE_DISPLAY_TOPIC
else{// 提取公共字段val commonObj: JSONObject = jsonObj.getJSONObject("common")val ar: String = commonObj.getString("ar")val uid: String = commonObj.getString("uid")val os: String = commonObj.getString("os")val ch: String = commonObj.getString("ch")val isNew: String = commonObj.getString("is_new")val md: String = commonObj.getString("md")val mid: String = commonObj.getString("mid")val vc: String = commonObj.getString("vc")val ba: String = commonObj.getString("ba")//提取时间戳val ts: Long = jsonObj.getLong("ts")// 页面数据val pageObj: JSONObject = jsonObj.getJSONObject("page")if(pageObj != null ){//提取page字段val pageId: String = pageObj.getString("page_id")val pageItem: String = pageObj.getString("item")val pageItemType: String = pageObj.getString("item_type")val duringTime: Long = pageObj.getLong("during_time")val lastPageId: String = pageObj.getString("last_page_id")val sourceType: String = pageObj.getString("source_type")//封装成PageLog,这边还写了bean实体类去接收var pageLog =PageLog(mid,uid,ar,ch,isNew,md,os,vc,ba,pageId,lastPageId,pageItem,pageItemType,duringTime,sourceType,ts)//发送到DWD_PAGE_LOG_TOPICMyKafkaUtils.send(DWD_PAGE_LOG_TOPIC , JSON.toJSONString(pageLog , new SerializeConfig(true)))//scala中bean没有set和get方法,这边是直接操作字段}相关文章:
Kafka/Spark-01消费topic到写出到topic
1 Kafka的工具类 1.1 从kafka消费数据的方法 消费者代码 def getKafkaDStream(ssc : StreamingContext , topic: String , groupId:String ) {consumerConfigs.put(ConsumerConfig.GROUP_ID_CONFIG , groupId)val kafkaDStream: InputDStream[ConsumerRecord[String, Strin…...
【算法与数据结构】98、LeetCode验证二叉搜索树
文章目录 一、题目二、解法三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、解法 思路分析:注意不要落入下面你的陷阱,笔者本来想左节点键值<中间节点键值<右节点键值即可&…...
关于GitHub Desktop中的“Open in Git Bash”无法使用的问题
问题描述 在GitHub Desktop中选择Repository--Open in Git Bash(如图1),出现如图2所示结果。 图1 图2 解决办法(Windows10) 这个问题是由于Git的环境变量没有得到正确配置所导致的,所以需要正确设置环境变量…...

使用DeepSpeed加速大型模型训练(二)
使用DeepSpeed加速大型模型训练 在这篇文章中,我们将了解如何利用Accelerate库来训练大型模型,从而使用户能够利用DeeSpeed的 ZeRO 功能。 简介 尝试训练大型模型时是否厌倦了内存不足 (OOM) 错误?我们已经为您提供了保障。大型模型性能非…...

ASP.net web应用 GridView控件常用方法
GridView 控件是 ASP.NET Web Forms 中常用的数据展示控件之一。它提供了一个网格形式的表格,用于显示和编辑数据。GridView 控件对于包含大量数据、需要进行分页、排序和筛选的情况非常有用。 GridView 控件的主要特性包括: 数据绑定:GridV…...

MATLAB入门一基础知识
MATLAB入门一基础知识 此篇为课程学习笔记 链接: link 什么是MATLAB 平时所说的MATLAB既是一款软件又是一种编程语言,只是这种高级解释性语言是在配套的软件下进行开发的 MATLAB的一个特性 MATLAB的一个特性,如果一条语句以英文分号‘;’结尾&…...

SpringMVC实现文件上传和下载功能
文件下载 ResponseEntity用于控制器方法的返回值类型,该控制器方法的返回值就是响应到浏览器的响应报文。具体步骤如下: 获取下载文件的位置;创建流,读取文件;设置响应信息,包括响应头,响应体以…...
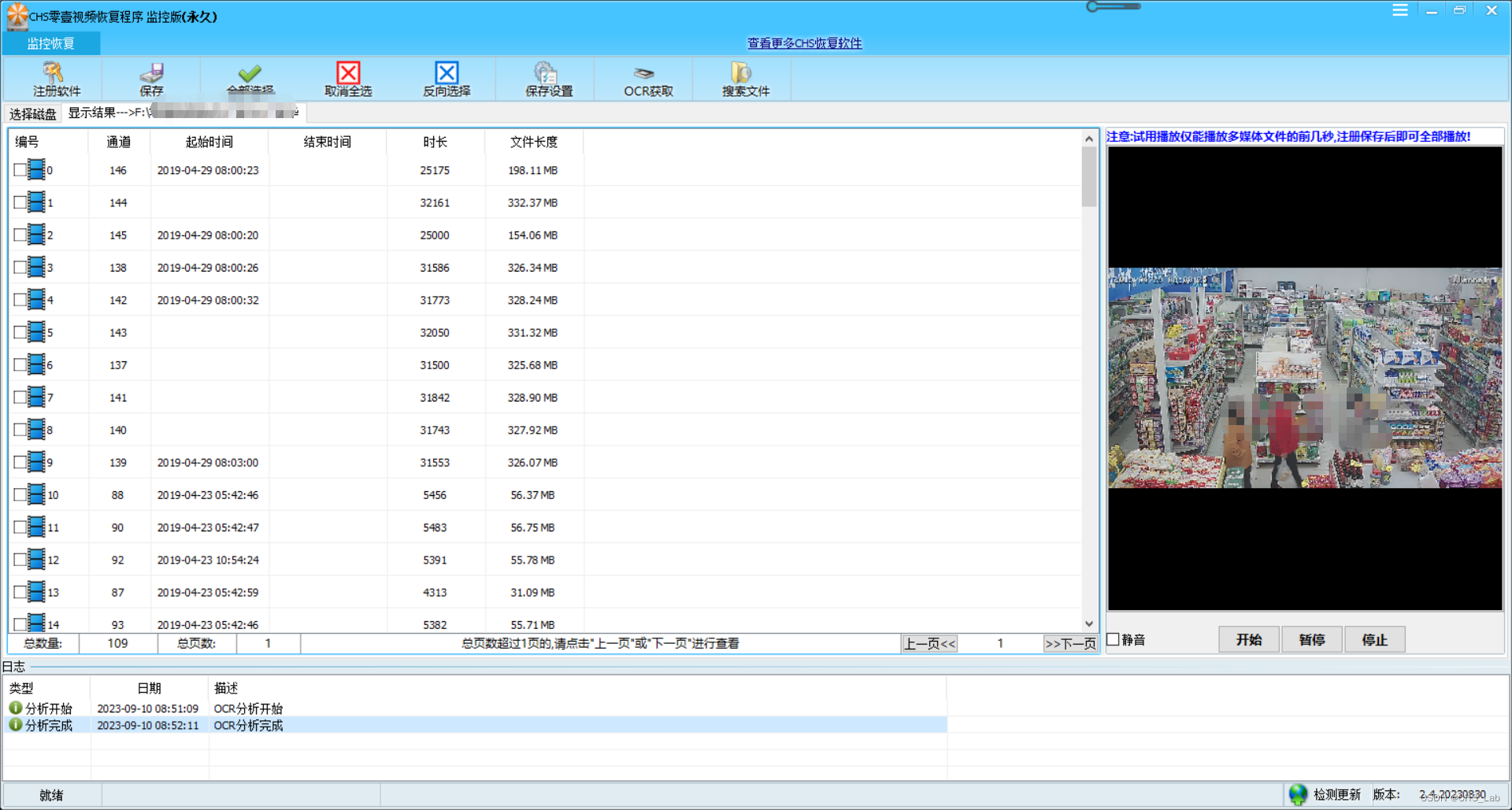
CHS零壹视频恢复程序OCR使用方法
目前CHS零壹视频恢复程序监控版、专业版、高级版已经支持了OCR,OCR是一种光学识别系统,通俗说就和扫描仪带的OCR软件一样的原理: 分析照片->OCR获取字符串->整理字符串->输出 使用方法如下(以CHS零壹视频恢复程序监控版…...

云备份——服务端客户端联合测试
一,准备工作 服务端清空备份文件信息、备份文件夹、压缩文件夹 客户端清空备份文件夹 二,开始测试 服务端配置文件 先启动服务端和客户端 向客户端指定文件夹放入稍微大点的文件,方便后续测试断点重传 2.1 上传功能测试 客户端自动上传成功…...
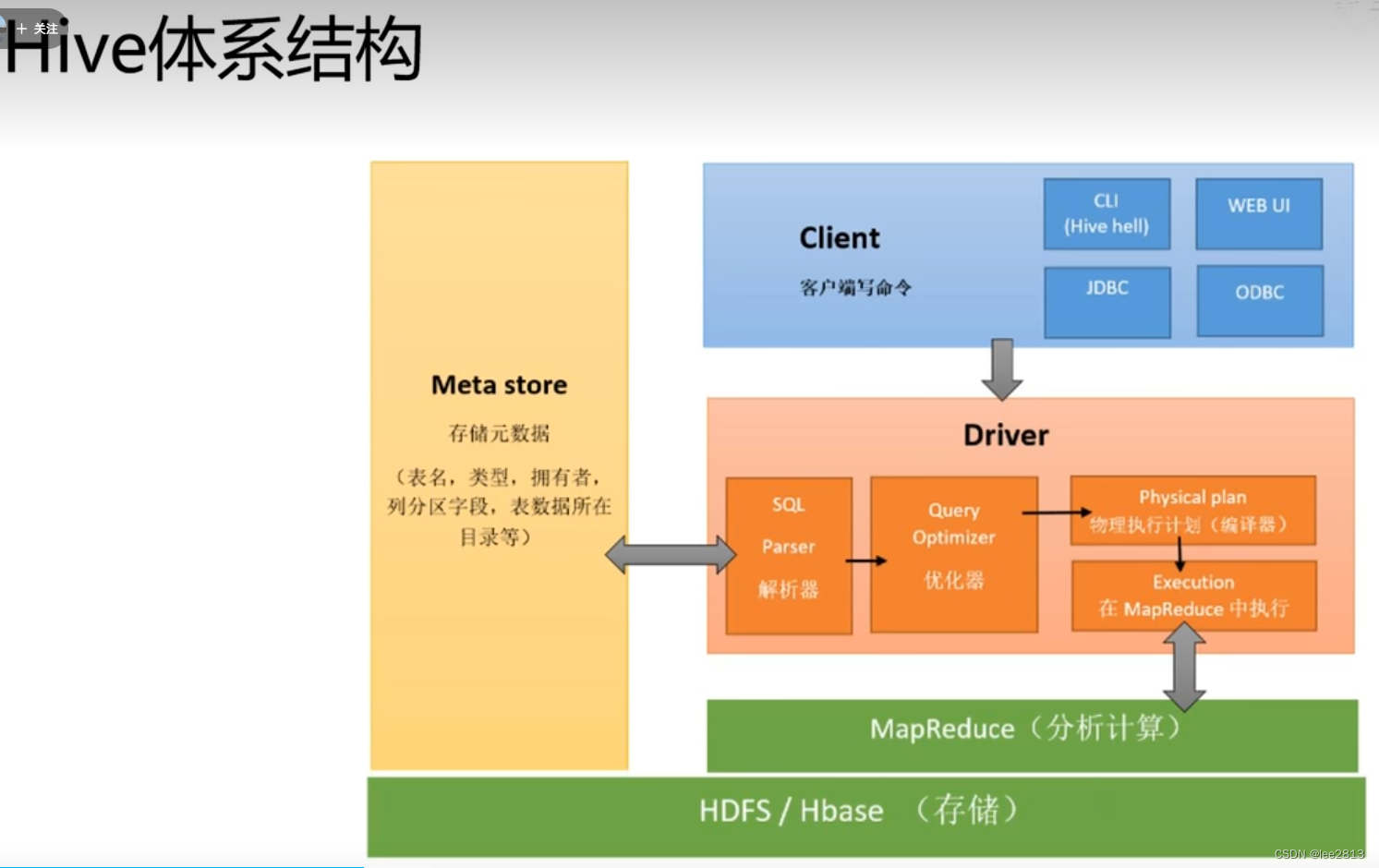
L2 数据仓库和Hive环境配置
1.数据仓库架构 数据仓库DW主要是一个用于存储,分析,报告的数据系统。数据仓库的目的是面向分析的集成化数据环境,分析结果为企业提供决策支持。-DW不产生和消耗数据 结构数据:数据库中数据,CSV文件 直接导入DW非结构…...
【iOS】MVC
文章目录 前言一、MVC各层职责1.1、controller层1.2、model层1.3、view层 二、总结三、优缺点3.1、优点3.2、缺点 四、代码示例 前言 MVC模式的目的是实现一种动态的程序设计,使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。除此…...

JavaScript-----jQuery
目录 前言: 1. jQuery介绍 2. 工厂函数 - $() jQuery通过选择器获取元素,$("选择器") 过滤选择器,需要结合其他选择器使用。 3.操作元素内容 4. 操作标签属性 5. 操作标签样式 6. 元素的创建,添加,删除 7.数据与对象遍历…...

Stream流
Stream操作流 在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。 1.1 集合的迭代 几乎所有的集合(如 Collection 接口或 Map 接口等)都支持直接或间接的迭代…...

javaee spring 声明式事务管理方式2 注解方式
spring配置文件 <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema/beans"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xmlns:context"http://www.springframewo…...
基于SpringBoot+微信小程序的智慧医疗线上预约问诊小程序
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 近年来,随…...

注意力机制讲解与代码解析
一、SEBlock(通道注意力机制) 先在H*W维度进行压缩,全局平均池化将每个通道平均为一个值。 (B, C, H, W)---- (B, C, 1, 1) 利用各channel维度的相关性计算权重 (B, C, 1, 1) --- (B, C//K, 1, 1) --- (B, C, 1, 1) --- sigmoid 与原特征相…...

微调 TrOCR – 训练 TrOCR 识别弯曲文本
TrOCR(基于 Transformer 的光学字符识别)模型是性能最佳的 OCR 模型之一。在我们之前的文章中,我们分析了它们在单行打印和手写文本上的表现。然而,与任何其他深度学习模型一样,它们也有其局限性。TrOCR 在处理开箱即用的弯曲文本时表现不佳。本文将通过在弯曲文本数据集上…...
Jetsonnano B01 笔记7:Mediapipe与人脸手势识别
今日继续我的Jetsonnano学习之路,今日学习安装使用的是:MediaPipe 一款开源的多媒体机器学习模型应用框架。可在移动设备、工作站和服务 器上跨平台运行,并支持移动 GPU 加速。 介绍与程序搬运官方,只是自己的学习记录笔记&am…...
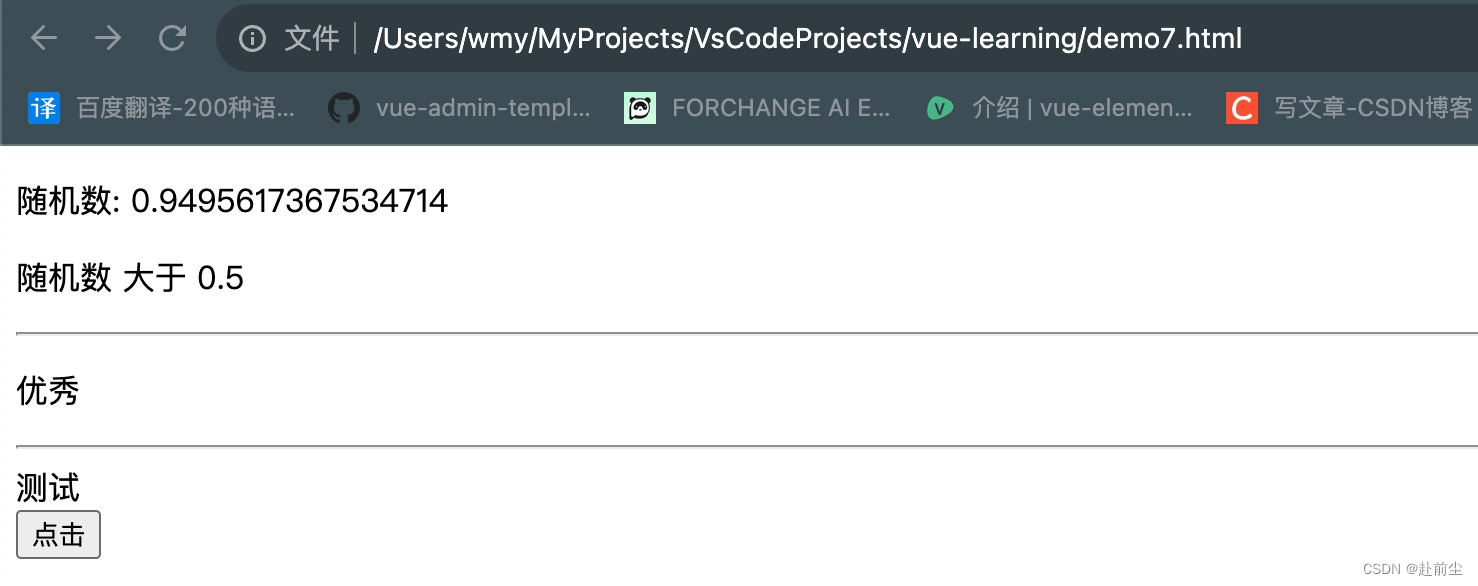
vue学习之v-if/v-else/v-else-if
v-else/v-else-if 创建 demo7.html,内容如下 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Docum…...
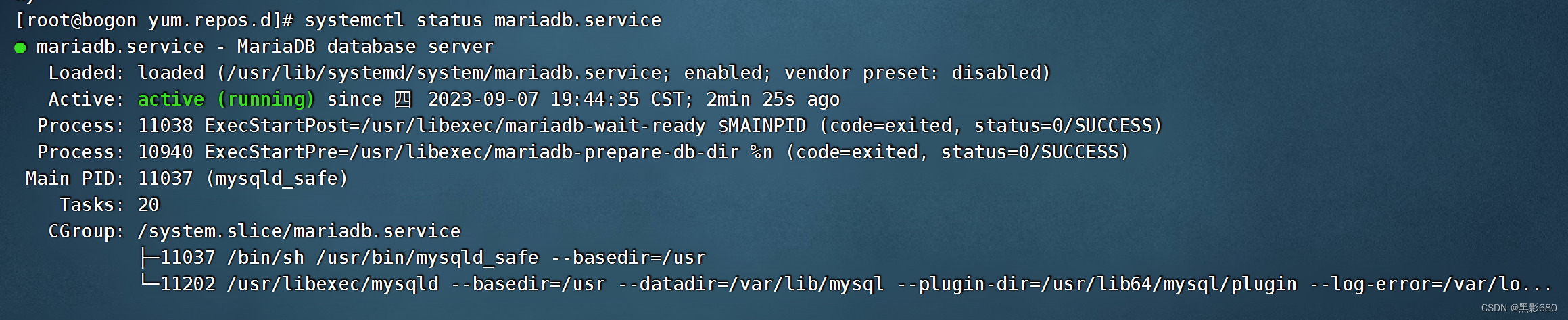
ansible的安装和简单的块使用
目录 一、概述 二、安装 1、选择源 2、安装ansible 3、模块查看 三、实验 1、拓扑编辑 2、设置组、ping模块 3、hostname模块 4、file模块 编辑 5、stat模块 6、copy模块(本地拷贝到远程) 7、fetch模块与copy模块类似,但作用…...

GPEN对戴口罩人脸的修复能力实测:遮挡场景适应性
GPEN对戴口罩人脸的修复能力实测:遮挡场景适应性 1. 引言:当人脸识别遇上口罩 最近几年,口罩成了我们生活中的常客。无论是进出公共场所,还是在一些特殊的工作环境中,遮住半张脸的情况越来越普遍。这带来了一个有趣的…...

数据架构现代化:AI应用落地的关键突破口
数据架构现代化:AI应用落地的关键突破口 一、引言:为什么你的AI项目总卡在“数据关”? 1. 一个扎心的真实场景 去年,我遇到一位零售企业的技术负责人,他的困惑让我印象深刻:“我们花了12个月、近500万预算&…...

2026年6月PMP考试:70天冲刺,这5个“备考误区”正在偷偷浪费你的时间
大家好,我是老陈。 今天这篇,我不想再写什么“每天学几小时、刷多少题”了。 前面写了好几篇,该说的都说了。今天咱们换个角度,聊聊那些看似正确、实则坑人的备考误区。 为什么聊这个?因为我发现一个规律࿱…...

OpenClaw跨平台脚本:Qwen3-32B生成的Python代码自动测试
OpenClaw跨平台脚本:Qwen3-32B生成的Python代码自动测试 1. 为什么需要AI全流程编程辅助 作为经常需要写脚本处理数据的开发者,我发现自己陷入了一个典型困境:每天要花大量时间编写重复性代码,而真正需要创造性思考的部分反而被…...

延时补偿预测器
Active flux基于扰动观测器补偿仿真模型: (1)1.5周期延时补偿 (2)相电压补偿 (2)扰动观测器补偿最近在调试电机控制项目的时候,总遇到Active Flux观测器输出波形抖动的问题。工程师们…...

构建自主海上防御系统:Mirai Robotics融资420万美元
Mirai Robotics已筹集420万美元的Pre-Seed轮资金,旨在构建自主和智能的海上系统。本轮融资由Primo Ventures、Techshop和40Jemz Ventures领投,并有来自意大利和国际的天使投资人参与。 海洋是地球上最关键的基础设施之一。全球超过80%的贸易通过海路运输…...

AtlasOS终极指南:专业解决Windows安装错误2502/2503的完整方案
AtlasOS终极指南:专业解决Windows安装错误2502/2503的完整方案 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and security. 项目地址: https://gitcode.com/GitHub_Trendi…...

Halcon角度计算双雄对比:orientation_region和smallest_rectangle2到底该用哪个?
Halcon角度计算双雄对比:orientation_region与smallest_rectangle2的实战抉择 在工业视觉检测中,区域角度计算是定位、对齐和测量的基础操作。Halcon作为机器视觉领域的标杆工具,提供了orientation_region和smallest_rectangle2两个核心算子来…...

嵌入式NTP客户端高精度时间同步实现
1. NTP客户端库深度解析:嵌入式系统中的高精度时间同步实现1.1 项目背景与工程痛点NTP(Network Time Protocol)是嵌入式设备实现网络时间同步的核心协议。在工业控制、数据采集、日志记录等场景中,毫秒级甚至亚毫秒级的时间精度直…...

丹青幻境部署案例:高校数字艺术实验室低成本GPU算力复用方案
丹青幻境部署案例:高校数字艺术实验室低成本GPU算力复用方案 1. 项目背景与挑战 很多高校的数字艺术、动画设计或新媒体专业,都面临一个共同的难题:教学和创作需要强大的AI绘图能力,但专门采购一批高性能GPU服务器,预…...