【深度学习实战—6】:基于Pytorch的血细胞图像分类(通用型图像分类程序)
✨博客主页:米开朗琪罗~🎈
✨博主爱好:羽毛球🏸
✨年轻人要:Living for the moment(活在当下)!💪
🏆推荐专栏:【图像处理】【千锤百炼Python】【深度学习】【排序算法】
目录
- 😺一、数据集介绍
- 😺二、工程文件夹目录
- 😺三、option.py
- 😺四、getdata.py
- 😺五、utils.py
- 😺六、model.py
- 😺七、train.py
- 😺八、evaluate.py
- 😺九、pth2onnx.py
- 😺十、onnx_inference.py
图像分类是搞深度学习一定要掌握的一个视觉任务,本文章将基于血细胞数据集实现图像分类!
本文程序已解耦,可当做通用型图像分类框架使用。
数据集下载地址:Blood Cell Images
😺一、数据集介绍
从 kaggle 上下载到数据集后解压可以得到两个文件夹,分别是dataset-master和dataset2-master。
其中dataset-master的 JPEGImages 中包含了血细胞的原始图像,而且没有对血细胞进行分类,在 Annotations 文件夹内包含了对应 JPEGImages 中的每张图像血细胞的.xml格式的定位标签,也就是说,该文件夹是用来做目标检测的。
而在dataset2-master中的 images 文件夹中,包含了TRAIN、TEST、TEST_SIMPLE三种文件夹,且这三种文件夹下包含了血细胞的四种类别,分别是:EOSINOPHIL、LYMPHOCYTE、MONOCYTE、NEUTROPHIL。
但需要注意的是,在TRAIN和TEST文件夹下的图像,是已经经过数据增强之后的了,而TEST_SIMPLE文件夹下的图像并没有经过数据增强,因此我们将TRAIN、TEST、TEST_SIMPLE三种文件夹分别用作训练集、验证集和测试集。即:
- TRAIN——train(训练集)
- TEST——val(验证集)
- TEST_SIMPLE——test(测试集)
😺二、工程文件夹目录
我的工程文件夹目录如下,可以看到有很多的py文件,每个py文件具有不同的功能,这么写的好处是未来修改程序更加方便,而且每个py程序都没有很长。如果全部写到一个py程序里,则会显得很臃肿,修改起来也不轻松。
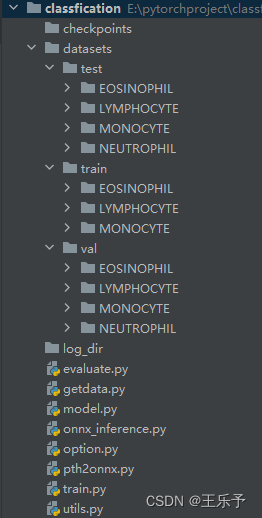
对每个文件的解释如下:
- checkpoints:存放训练的模型权重;
- datasets:存放数据集。并对数据集划分;
- log_dir:存放训练日志。包括训练、验证时候的损失与精度情况;
- option.py:存放整个工程下需要用到的所有参数;
- utils.py:存放各种函数。包括文件夹创建、绘制精度与损失变化情况、结果预测等;
- getdata.py:构建数据管道。其中定义了计算数据集中所有图形的均值和方差函数;
- model.py:构建神经网络模型;
- train.py:训练模型;
- evaluate.py:评估训练模型。有三种预测方式可以选择,分别是:对单张图像进行预测,对多张图像进行预测,对整个目录下的图片进行预测;
- pth2onnx:将pth模型转换到onnx模型;
- onnx_inference.py:使用.onnx模型对数据进行推理。
😺三、option.py
为了方便了解这些参数代表什么意思,在help中,全部使用了中文解释。
import argparsedef get_args():parser = argparse.ArgumentParser(description='all argument')parser.add_argument('--device', type=str, default='cuda', help='可以选择cuda或者cpu训练,苹果电脑m1芯片也可以选择mps加速训练')parser.add_argument('--loadsize', type=int, default=224, help='统一图像尺寸')parser.add_argument('--epochs', type=int, default=3, help='总的训练次数')parser.add_argument('--batch_size', type=int, default=16, help='每次喂多少数据给到网络')parser.add_argument('--lr', type=float, default=1e-2, help='初始学习率')parser.add_argument('--dataset_train', type=str, default='./datasets/train', help='训练集路径')parser.add_argument('--dataset_val', type=str, default="./datasets/val", help='验证集路径')parser.add_argument('--dataset_test', type=str, default="./datasets/test", help='测试集路径')parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='模型存放路径')parser.add_argument('--log_dir', type=str, default='./log_dir', help='训练日志保存的路径')parser.add_argument('--logging_txt', type=str, default='./log_dir/logging.txt', help='训练日志位置')parser.add_argument('--pretrained', type=bool, default=False, help='是否要继续上次的训练')parser.add_argument('--which_epoch', type=str, default='best.pth', help='如果继续训练,需要加载哪一个模型')parser.add_argument('--test_model_path', type=str, default='./checkpoints/best.pth', help='选择一个模型用于测试')parser.add_argument('--onnx_path', type=str, default='./checkpoints/best.onnx', help='.onnx模型的存放路径')parser.add_argument('--test_img_path', type=str, default='./datasets/test/EOSINOPHIL/_0_5239.jpeg', help='选择一张测试图像')parser.add_argument('--test_dir_path', type=str, default='./datasets/test', help='选择一个测试路径')return parser.parse_args()
😺四、getdata.py
对getdata.py中各函数的解释:
data_augmentation:该函数用作数据增强,最常使用的是transforms.Resize()、transforms.ToTensor()、transforms.Normalize()。由于数据集中已经对原始图像进行了数据增强,因此部分参数在下面注释掉了。transforms.Resize():将图像统一尺寸。transforms.ToTensor():维度变换。从 HWC 到 CWH 。transforms.Normalize():图像归一化。归一化的参数需要从get_mean_and_std函数计算得到。
MyData:构建数据管道。返回一个字典。imshow:图像可视化。可在构建数据管道后,可视化部分数据。get_mean_and_std:计算图像均值和方差。计算结果放到transforms.Normalize()中。
import torch
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision.utils import make_grid
import numpy as np
import matplotlib.pyplot as plt
from option import get_args
opt = get_args()def data_augmentation():data_transform = {'train': transforms.Compose([# transforms.RandomRotation(45), # 随机旋转,角度在-45到45度之间# transforms.RandomHorizontalFlip(p=0.5), # 以0.5的概率水平翻转# transforms.RandomVerticalFlip(p=0.5), # 以0.5的概率垂直翻转# transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1), # 参数依次为亮度、对比度、饱和度、色相# transforms.RandomGrayscale(p=0.025), # 以0.025的概率变为灰度图像,3通道即R=G=Btransforms.Resize((opt.loadsize, opt.loadsize)),transforms.ToTensor(), # HWC -> CHWtransforms.Normalize([0.6786, 0.6413, 0.6605], [0.2599, 0.2595, 0.2569]) # 使用均值和标准差标准化三个通道的数据]),'val': transforms.Compose([transforms.Resize((opt.loadsize, opt.loadsize)),transforms.ToTensor(),transforms.Normalize([0.6786, 0.6413, 0.6605], [0.2599, 0.2595, 0.2569])]),'test': transforms.Compose([transforms.Resize((opt.loadsize, opt.loadsize)),transforms.ToTensor(),transforms.Normalize([0.6786, 0.6413, 0.6605], [0.2599, 0.2595, 0.2569])])}return data_transformdef MyData():data_transform = data_augmentation()# 读取数据集image_datasets = {'train': ImageFolder(opt.dataset_train, data_transform['train']),'val': ImageFolder(opt.dataset_test, data_transform['val']),'test': ImageFolder(opt.dataset_test, data_transform['test'])}# 构建管道dataloaders = {'train': DataLoader(image_datasets['train'], batch_size=opt.batch_size, shuffle=True),'val': DataLoader(image_datasets['val'], batch_size=opt.batch_size, shuffle=True),'test': DataLoader(image_datasets['test'], batch_size=opt.batch_size, shuffle=True)}return dataloaders"""
图像可视化
"""
def imshow(inp, title=None):inp = inp.numpy().transpose((1, 2, 0))mean = np.array([0.6786, 0.6413, 0.6605])std = np.array([0.2599, 0.2595, 0.2569])inp = inp * std + meaninp = np.clip(inp, 0, 1)plt.imshow(inp)if title is not None:plt.title(title)plt.show()# 计算数据集所有图像的均值和方差
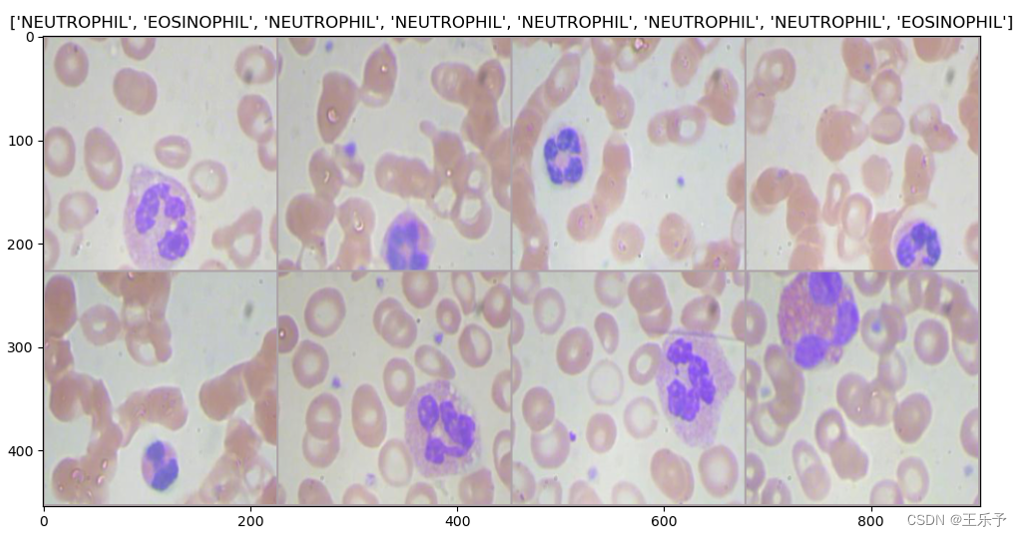
def get_mean_and_std(dataset):dataloader = DataLoader(dataset, batch_size=1, shuffle=True)mean = torch.zeros(3)std = torch.zeros(3)print('==> Computing mean and std..')for inputs, targets in dataloader:for i in range(3):mean[i] += inputs[:, i, :, :].mean()std[i] += inputs[:, i, :, :].std()mean.div_(len(dataset))std.div_(len(dataset))return mean, stdif __name__ == '__main__':mena_std_transform = transforms.Compose([transforms.ToTensor()])dataset = ImageFolder(opt.dataset_train, transform=mena_std_transform)print(dataset.class_to_idx) # 每个类别的索引mean, std = get_mean_and_std(dataset)print(mean)print(std)dataloader = MyData()inputs, classes = next(iter(dataloader['train']))out = make_grid(inputs, nrow=4) # nrow参数可以选择显示的列数class_names = ['EOSINOPHIL', 'LYMPHOCYTE', 'MONOCYTE', 'NEUTROPHIL']imshow(out, title=[class_names[x] for x in classes])
运行main函数可以得到:
类别索引: {'EOSINOPHIL': 0, 'LYMPHOCYTE': 1, 'MONOCYTE': 2, 'NEUTROPHIL': 3}
==> Computing mean and std..
tensor([0.6786, 0.6413, 0.6605])
tensor([0.2599, 0.2595, 0.2569])
将 opt.batchsize 设为8后,可以得到下图:
😺五、utils.py
对utils.py中各函数的解释:
make_dir:创建文件夹。draw_number:绘制损失与精度的变化情况。visual_image_single:单张图像可视化预测。visual_image_multi:多张图像可视化预测。get_confusion_matrix:输出混淆矩阵。用于对整个文件夹进行预测的情况。plot_confusion_matrix:混淆矩阵可视化。get_roc_auc:绘制ROC曲线。visual_img_dir:对整个文件夹进行预测。并得到分类报告、准确率、精确率、召回率、F1得分
import matplotlib.pyplot as plt
import numpy as np
import torch
import os
from PIL import Image
import torch.nn.functional as F
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report, confusion_matrix, roc_curve, auc
from sklearn.preprocessing import label_binarize
from scipy import interp
from itertools import cycle
from option import get_args
opt = get_args()"""
创建文件夹
"""
def make_dir():if os.path.exists(opt.log_dir) == True:passelse:os.mkdir(opt.log_dir)if os.path.exists(opt.checkpoints) == True:passelse:os.mkdir(opt.checkpoints)"""
绘制损失与精度的变化情况
"""
def draw_number(epochs, train_loss_plt, train_acc_plt, val_loss_plt, val_acc_plt):color = ['red', 'blue', 'green', 'orange']marker = ['o', '*', 'p', '+']linestyle = ['-', '--', '-.', ':']plt.plot(epochs, train_loss_plt, color=color[0], marker=marker[0], linestyle=linestyle[0], label="trainingsets-loss")plt.plot(epochs, train_acc_plt, color=color[1], marker=marker[1], linestyle=linestyle[1], label="trainingsets-acc")plt.plot(epochs, val_loss_plt, color=color[2], marker=marker[2], linestyle=linestyle[2], label="validationsets-loss")plt.plot(epochs, val_acc_plt, color=color[3], marker=marker[3], linestyle=linestyle[3], label="validationsets-acc")plt.legend()plt.xlabel("epochs")plt.ylabel("value")plt.title("Loss and accuracy changes in training and validation sets")plt.savefig("Loss_Accuracy.jpg")plt.show()"""
单张图像可视化预测
"""
def visual_image_single(img_path, transform_test, model, class_names):image = Image.open(img_path).convert('RGB')img = transform_test(image)img = img.unsqueeze_(0)out = model(img)pred_softmax = F.softmax(out, dim=1) # 对 logit 分数做 softmax 运算top_n = torch.topk(pred_softmax, len(class_names))confs = top_n[0].cpu().detach().numpy().squeeze().tolist() # 所有类别的预测概率confs_max = max(confs) # 最大概率值confs_max_position = confs.index(confs_max) # 最大概率值所在的位置print('Pre:{} Conf:{:.3f}'.format(class_names[confs_max_position], confs_max))plt.axis('off')plt.title('Pre:{} Conf:{:.3f}'.format(class_names[confs_max_position], confs_max))plt.imshow(image)plt.show()"""
多张图像可视化预测
"""
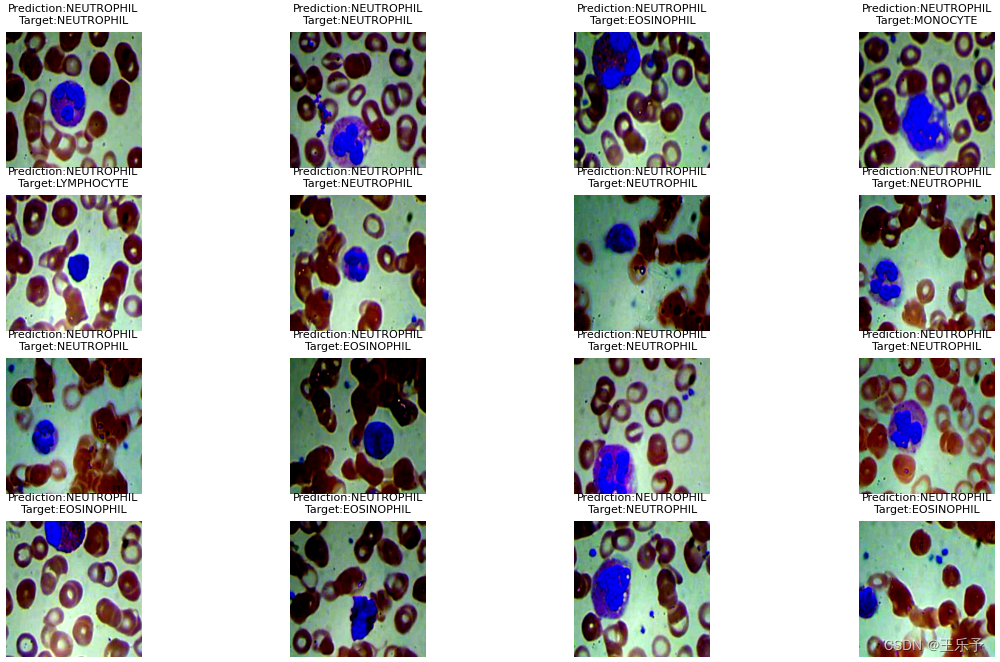
def visual_image_multi(dataloader, model, class_names):with torch.no_grad():for images, labels in dataloader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)for i in range(len(images)):plt.subplot(4, 4, i + 1)plt.title("Prediction:{}\nTarget:{}".format(class_names[predicted[i]], class_names[labels[i]]), fontsize=8)img = images[i].swapaxes(0, 1)img = img.swapaxes(1, 2)plt.imshow(img)plt.axis('off')plt.show()"""
对整个文件夹进行预测, 并输出混淆矩阵
"""
def get_confusion_matrix(trues, preds, labels):conf_matrix = confusion_matrix(trues, preds, labels=[i for i in range(len(labels))])return conf_matrixdef plot_confusion_matrix(conf_matrix, labels):plt.imshow(conf_matrix, cmap=plt.cm.Blues)plt.title('Confusion Matrix')indices = range(conf_matrix.shape[0])plt.xticks(indices, labels)plt.yticks(indices, labels)plt.colorbar()plt.xlabel('Predicted Label')plt.ylabel('True Label')# 显示数据for first_index in range(conf_matrix.shape[0]):for second_index in range(conf_matrix.shape[1]):plt.text(first_index, second_index, conf_matrix[first_index, second_index])plt.savefig('heatmap_confusion_matrix.jpg')plt.show()def get_roc_auc(trues, preds, labels):nb_classes = len(labels)fpr = dict()tpr = dict()roc_auc = dict()for i in range(nb_classes):fpr[i], tpr[i], _ = roc_curve(trues[:, i], preds[:, i])roc_auc[i] = auc(fpr[i], tpr[i])fpr["micro"], tpr["micro"], _ = roc_curve(trues.ravel(), preds.ravel())roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])all_fpr = np.unique(np.concatenate([fpr[i] for i in range(nb_classes)])) mean_tpr = np.zeros_like(all_fpr)for i in range(nb_classes):mean_tpr += interp(all_fpr, fpr[i], tpr[i])mean_tpr /= nb_classesfpr["macro"] = all_fprtpr["macro"] = mean_tprroc_auc["macro"] = auc(fpr["macro"], tpr["macro"])lw = 2plt.figure()plt.plot(fpr["micro"], tpr["micro"],label='micro-average ROC curve (area = {0:0.2f})'.format(roc_auc["micro"]),color='deeppink', linestyle=':', linewidth=4)plt.plot(fpr["macro"], tpr["macro"],label='macro-average ROC curve (area = {0:0.2f})'.format(roc_auc["macro"]),color='navy', linestyle=':', linewidth=4)colors = cycle(['aqua', 'darkorange', 'cornflowerblue', 'green'])for i, color in zip(range(nb_classes), colors):plt.plot(fpr[i], tpr[i], color=color, lw=lw, label='ROC curve of class {0} (area = {1:0.2f})'.format(i, roc_auc[i]))plt.plot([0, 1], [0, 1], 'k--', lw=lw)plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Some extension of Receiver operating characteristic to multi-class')plt.legend(loc="lower right")plt.savefig("ROC_多分类.jpg")plt.show()def visual_img_dir(dataloader, model, class_names):"""normalize: True:显示百分比, False: 显示个数"""y_pred = []y_true = []with torch.no_grad():for images, labels in dataloader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)y_pred.extend(predicted.cpu().numpy())y_true.extend(labels.cpu().numpy())accuracy = accuracy_score(y_true, y_pred) # 准确率 值所有判断正确的数据(TP+TN)占总量的比例。precision = precision_score(y_true, y_pred, average='macro') # 精确率 所有被判定为正类(TP+FP)中,真实的正类(TP)占的比例。recall = recall_score(y_true, y_pred, average='macro') # 召回率 所有真实为正类(TP+FN)中,被判定为正类(TP)占的比例。f1 = f1_score(y_true, y_pred, average='macro') # f1-score 它赋予Precision score和Recall Score相同的权重,以衡量其准确性方面的性能,使其成为准确性指标的替代方案(它不需要我们知道样本总数)。conf_matrix = get_confusion_matrix(y_true, y_pred, labels=class_names)print('分类报告:\n', classification_report(y_true, y_pred)) # 分类报告print("[accuracy:{:.4f}] [precision:{:.4f}] [recall:{:.4f}] [f1:{:.4f}]".format(accuracy, precision, recall, f1))plot_confusion_matrix(conf_matrix, labels=class_names)test_trues = label_binarize(y_true, classes=[i for i in range(len(class_names))])test_preds = label_binarize(y_pred, classes=[i for i in range(len(class_names))])get_roc_auc(test_trues, test_preds, class_names)
😺六、model.py
我们可以自定义一个分类网络,也可以使用现有的经典分类网络,如resnet50,在使用resnet50时,可以选择冻结部分网络层,即冻结的网络层不可再被训练,仅使用其网络结构,网络参数是早已学习好的;也可以选择冻结所有层;也可以选择不冻结任何层。在迁移学习的时候,需要注意最后的分类层。血细胞分类共有4类,而resnet50最后的全连接层有1000个神经元输出,所以需要修改最后一层全连接层,将其输出改为4。
import torch
import torch.nn as nn
from torchvision.models import resnet50, ResNet50_Weights
from torchsummary import summary
from option import get_args
opt = get_args()class My_CNN(nn.Module):def __init__(self):super(My_CNN, self).__init__()self.conv1_1 = nn.Sequential(nn.Conv2d(3, 16, (3, 3), 1, 1),nn.ReLU(),nn.BatchNorm2d(16))self.conv1_2 = nn.Sequential(nn.Conv2d(16, 32, (3, 3), 2, 1),nn.ReLU(),nn.BatchNorm2d(32))self.conv2_1 = nn.Sequential(nn.Conv2d(32, 32, (3, 3), 1, 1),nn.ReLU(),nn.BatchNorm2d(32))self.conv2_2 = nn.Sequential(nn.Conv2d(32, 64, (3, 3), 2, 1),nn.ReLU(),nn.BatchNorm2d(64))self.conv3_1 = nn.Sequential(nn.Conv2d(64, 64, (3, 3), 1, 1),nn.ReLU(),nn.BatchNorm2d(64))self.conv3_2 = nn.Sequential(nn.Conv2d(64, 128, (3, 3), 2, 1),nn.ReLU(),nn.BatchNorm2d(128))self.linear_1 = nn.Linear(28 * 28 * 128, 80)self.linear_2 = nn.Linear(80, 4)def forward(self, x):in_size = x.size(0)x = self.conv1_1(x)x = self.conv1_2(x)x = self.conv2_1(x)x = self.conv2_2(x)x = self.conv3_1(x)x = self.conv3_2(x)x = x.view(in_size, -1)x = self.linear_1(x)out = self.linear_2(x)return out"""
使用预训练模型 1 ————微调模型
使用预训练的模型来初始化网络,而非随机初始化网络,并且权重可以随着训练的进行而发生改变,步骤如下:
--(1)替换输出层。将模型的最后一个全连接层替换为新的全连接层;
--(2)训练输出层。新的输出层会将前面的层所提取出的低级特征映射到我们所期望的类别的概率;
--(3)训练输出层之前的层。也就是将这些层的权重标记为需要求导。固定模型的参数 2 ————微调模型
固定预训练模型的参数,将模型除了输出层之外的所有层看作一个特征提取器。在训练模型的时候,这些层的权重不参与训练,不可优化。
"""
def ResNet():model = resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)"""可选择仅冻结某一层或者全部冻结"""# for name, layer in model.named_children(): # 仅冻结layer1层# if name == "layer1":# for param in layer.parameters():# param.requires_grad = False## for param in model.parameters(): # 冻结所有层,锁定模型所有参数,所有层设置为不可训练的模式。# param.requires_grad = Falsenum_ftrs = model.fc.in_featuresmodel.fc = nn.Linear(num_ftrs, 4)return modelif __name__ == '__main__':model = ResNet()print(summary(model.to(opt.device), (3, opt.loadsize, opt.loadsize), opt.batch_size))
😺七、train.py
对train.py解释如下:
make_dir():从 utils 中调用函数,目的是如果当前工程目录下不存在相应的文件夹(log_dir和checkpoints),则主动创建,如果已经存在,则不做处理。file = open(opt.logging_txt, 'w'):创建.txt文件,后续将写入训练过程的相关信息,包括损失与精度的变化情况。writer = SummaryWriter():SummaryWriter 类将条目直接写入指定文件夹中的事件文件,以供 TensorBoard 使用。在程序运行时,会在工程目录下自动新建一个 run 文件夹,用于存储训练过程。在 run 文件夹下使用终端,输入tensorboard –logdir=run可以在网页中查看网络训练过程。train_best:定义训练过程的函数。
import numpy as np
from tqdm import tqdm
from torch.utils.tensorboard import SummaryWriter
import torch
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.nn as nn
from model import My_CNN, ResNet
from getdata import MyData
from utils import draw_number, EarlyStopping, make_dir
from option import get_args
opt = get_args()make_dir()
file = open(opt.logging_txt, 'w')
writer = SummaryWriter()def train_best(model, num_epoch, dataloaders, optimizer, loss_function):model.to(opt.device)train_loss_plt, train_acc_plt, val_loss_plt, val_acc_plt = [], [], [], [] # 将训练和验证过程的损失和精度保留下来,用于绘制折线图for epoch in range(start_epoch, opt.epochs):print("---------开始第{}/{}轮训练---------".format(epoch, opt.epochs))for phase in ['train', 'val']:loss_sum, acc_sum = 0, 0step = 0 # 将数据全部取完, 记录每一个batchall_step = 0 # 记录取了多少个数据for (inputs, labels) in tqdm(dataloaders[phase], position=0):if phase == 'train':model.train()if phase == 'val':model.eval()inputs = inputs.to(opt.device)labels = labels.to(opt.device)optimizer.zero_grad() # 梯度清零,防止累加a = inputs.size(0) # 每一批次拿了多少张图像outputs = model(inputs)loss = loss_function(outputs, labels)_, pred = torch.max(outputs, 1) # 返回每一行的最大值和其索引loss.backward()optimizer.step()loss_sum += loss.item() * inputs.size(0) # 损失acc_sum += torch.sum(pred == labels.data)step += 1all_step += aprint("[Epoch: {}/{}] [step = {}] [{}_loss = {:.3f}, {}_acc = {:.3f}]".format(epoch, opt.epochs, all_step, phase, loss_sum / all_step, phase, acc_sum.double() / all_step))# 保留每一个epoch后的训练损失与精度if phase == 'train':train_loss = loss_sum / len(dataloaders[phase].dataset)train_acc = acc_sum.double() / len(dataloaders[phase].dataset)train_acc = np.float32(train_acc.cpu().numpy())train_loss_plt.append(train_loss)train_acc_plt.append(train_acc)else:val_loss = loss_sum / len(dataloaders[phase].dataset)val_acc = acc_sum.double() / len(dataloaders[phase].dataset)val_acc = np.float32(val_acc.cpu().numpy())val_loss_plt.append(val_loss)val_acc_plt.append(val_acc)writer.add_scalars('loss', {'train': train_loss, 'val': val_loss}, global_step=epoch + 1 - start_epoch)writer.add_scalars('acc', {'train': train_acc, 'val': val_acc}, global_step=epoch + 1 - start_epoch)writer.close()print("EPOCH = {}/{} train_loss = {:.3f}, train_acc = {:.3f}, val_loss = {:.3f}, val_acc = {:.3f} \n".format(epoch, num_epoch, train_loss, train_acc, val_loss, val_acc))file.write("EPOCH = {}/{} train_loss = {:.3f}, train_acc = {:.3f}, val_loss = {:.3f}, val_acc = {:.3f} \n".format(epoch, num_epoch, train_loss, train_acc, val_loss, val_acc))state = {'model': model.state_dict(), 'optimizer': optimizer.state_dict(), 'epoch': epoch}if epoch % 2 == 0:torch.save(state, opt.checkpoints + 'model_{}.pth'.format(epoch))draw_number(np.arange(0, opt.epoch-start_epoch, 1), train_loss_plt, train_acc_plt, val_loss_plt, val_acc_plt)if __name__ == '__main__':model = ResNet()# model = nn.DataParallel(model) # 多卡并行训练解开这句注释model.to(opt.device)loss_function = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr)if opt.pretrained:checkpoint = torch.load(opt.checkpoints + opt.which_epoch)model.load_state_dict(checkpoint['model'])optimizer.load_state_dict(checkpoint['optimizer'])start_epoch = checkpoint['epoch']print('加载 epoch {} 成功!'.format(start_epoch))else:start_epoch = 0print('无保存模型,将从头开始训练!')dataloaders = MyData()train_best(model, opt.epochs, dataloaders, optimizer, loss_function)
😺八、evaluate.py
对evaluate.py需要注意:
-
class_names:必须要和数据管道的标签对应。也就是getdata.py运行得到的类别索引。
类别索引: {'EOSINOPHIL': 0, 'LYMPHOCYTE': 1, 'MONOCYTE': 2, 'NEUTROPHIL': 3} -
main 函数内的
visual_image_single:将每次弹出一张预测结果 -
main 函数内的
visual_image_multi:将每次弹出opt.batch_size张预测结果,可以通过修改opt.batch_size改变预测数量,同时可以跳转到utils.py里的visual_image_multi函数中,通过修改plt.subplot()中的参数,可以控制预测结果的排列分布,例如 4 行 4 列 或者 2 行 8 列 等。 -
main 函数内的
visual_img_dir:将得到ROC曲线图,混淆矩阵图、各种评估指标等。
from model import My_CNN, ResNet
from getdata import MyData, data_augmentation
import torch.utils.data
from option import get_args
from utils import visual_image_single, visual_image_multi, visual_img_diropt = get_args()model = ResNet()
ckpt = torch.load(opt.test_model_path, map_location='cpu')
model.load_state_dict(ckpt, strict=False)
model.eval()data_transform = data_augmentation() # 测试单张图像使用
transform_test = data_transform['test']dataloaders = MyData() # 测试多张图像和文件夹使用
dataloader = dataloaders['test']class_names = ['EOSINOPHIL', 'LYMPHOCYTE', 'MONOCYTE', 'NEUTROPHIL']if __name__ == '__main__':# visual_image_single(opt.test_img_path, transform_test, model, class_names)# visual_image_multi(dataloader, model, class_names)visual_img_dir(dataloader, model, class_names=class_names)
程序运行结果如下所示:
visual_image_single:
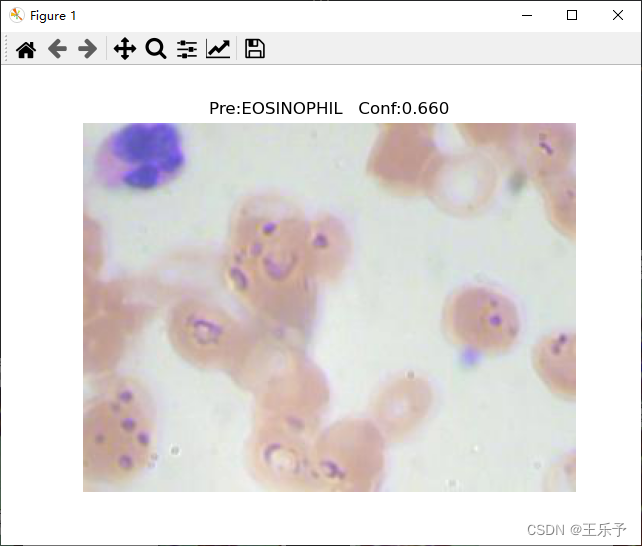
visual_image_multi:
visual_img_dir:
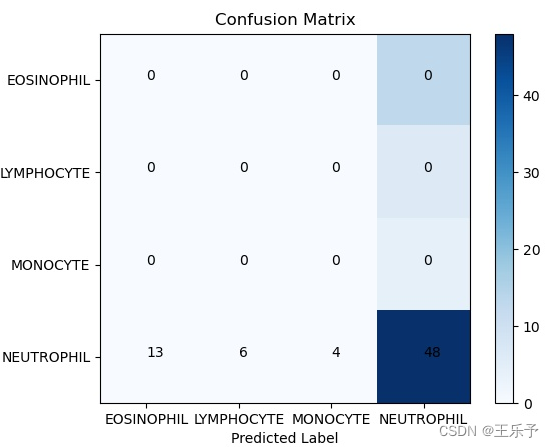
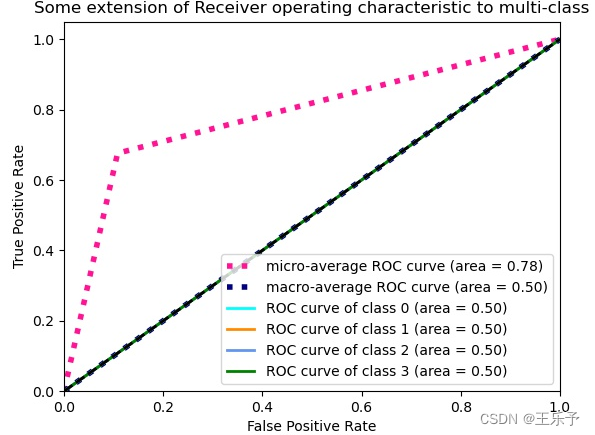
分类报告:precision recall f1-score support0 0.00 0.00 0.00 131 0.00 0.00 0.00 62 0.00 0.00 0.00 43 0.68 1.00 0.81 48accuracy 0.68 71macro avg 0.17 0.25 0.20 71
weighted avg 0.46 0.68 0.55 71[accuracy:0.6761] [precision:0.1690] [recall:0.2500] [f1:0.2017]
😺九、pth2onnx.py
对evaluate.py需要注意:
模型转换时,需要指定模型的输入大小,即input变量。
import torch
from torch.autograd import Variable
import onnx
from model import My_CNN, ResNet
from option import get_args
opt = get_args()model = ResNet()
ckpt = torch.load(opt.test_model_path, map_location='cpu')
model.load_state_dict(ckpt, strict=False)
model.eval()
input_name = ['input']
output_name = ['output']
input = Variable(torch.randn(1, 3, opt.loadsize, opt.loadsize))torch.onnx.export(model, input, opt.onnx_path, input_names=input_name, output_names=output_name, verbose=True)# check .onnx model
onnx_model = onnx.load(opt.onnx_path)
onnx.checker.check_model(onnx_model)
print(onnx.helper.printable_graph(onnx_model.graph))
程序运行后就可以在checkpoints文件夹下发现.onnx文件。
😺十、onnx_inference.py
使用onnx模型进行推理。
注意在推理前,要把opt.batch_size改为 1。
import numpy as np
import onnxruntime
import time
from getdata import MyData
from option import get_args
opt = get_args()def infer_test(model_path, data_loader, device):if device == 'cpu':print("using CPUExecutionProvider")session = onnxruntime.InferenceSession(model_path, providers=['CPUExecutionProvider'])else:print("using CUDAExecutionProvider")session = onnxruntime.InferenceSession(model_path, providers=['CUDAExecutionProvider'])input_name = session.get_inputs()[0].nameoutput_name = session.get_outputs()[0].nametotal = 0.0correct = 0start_time = time.time()for batch, data in enumerate(data_loader):X, y = dataX = X.numpy()y = y.numpy()output = session.run([output_name], {input_name: X})[0]y_pred = np.argmax(output, axis=1)if y[0] == y_pred[0]:correct += 1total += 1end_time = time.time()print(end_time - start_time)print("accuracy is {}%".format(correct / total * 100.0))def main():input_model_path = opt.onnx_pathdevice = input("cpu or gpu?")dataloaders = MyData()infer_test(input_model_path, dataloaders['test'], device)if __name__ == "__main__":main()
推理结果如下所示:
cpu or gpu?cpu
using CPUExecutionProvider
1.8580236434936523
accuracy is 67.6056338028169%
相关文章:
【深度学习实战—6】:基于Pytorch的血细胞图像分类(通用型图像分类程序)
✨博客主页:米开朗琪罗~🎈 ✨博主爱好:羽毛球🏸 ✨年轻人要:Living for the moment(活在当下)!💪 🏆推荐专栏:【图像处理】【千锤百炼Python】【深…...

华清远见第六课程day4作业
仿照string类,完成myString 类 #include <iostream> #include <cstring>using namespace std;class myString{ private:char *str;int size; public:myString():size(10){str new char[size];strcpy(str,"");}myString(const char*s){size …...

【广州华锐互动】AR远程智慧巡检在化工行业中的应用
AR远程智慧巡检是一种基于增强现实技术的新型巡检方式,它可以利用虚拟信息和现实场景的结合,实现对设备、工艺流程等方面的实时监测和识别。在化工行业中,AR远程智慧巡检具有广泛的应用前景,可以提高生产效率和安全性。 一、设备巡…...

easyui-sidemenu 菜单 后台加载
前言 一个项目的功能较齐全,而齐全就预示着功能菜单比较长,但是现实中在不同的甲方使用中往往只需要摘取其中几项功能,所以就想到用配置菜单以满足其需求,且无需变更原始代码,查找一些资料总是似是而非或是誊抄别的什…...

Python总结上传图片到服务器并保存的两种方式
一、前言 图片保存到服务器的两种方法: 1、根据图片的 URL 将其保存到服务器的固定位置 2、根据 request.FILES.get("file") 方式从请求中获取上传的图片文件,并将其保存到服务器的固定位置 二、方法 1、图片的 URL 要根据图片的 URL 将…...

【ETH】以太坊合约智能合约逆向方案
技术角度了解区块链 区块链技术逆袭专栏 文章目录 区块链技术逆袭专栏获取合约代码逆向工具方案1方案2实操演示:获取合约代码 在反编译之前,你需要先知道如果获取编译后的字节码。 这里以 USDT 举例 eth.getCode(0xdAC17F958D2ee523a2206206994597C13D831ec7)字节码: 0x…...
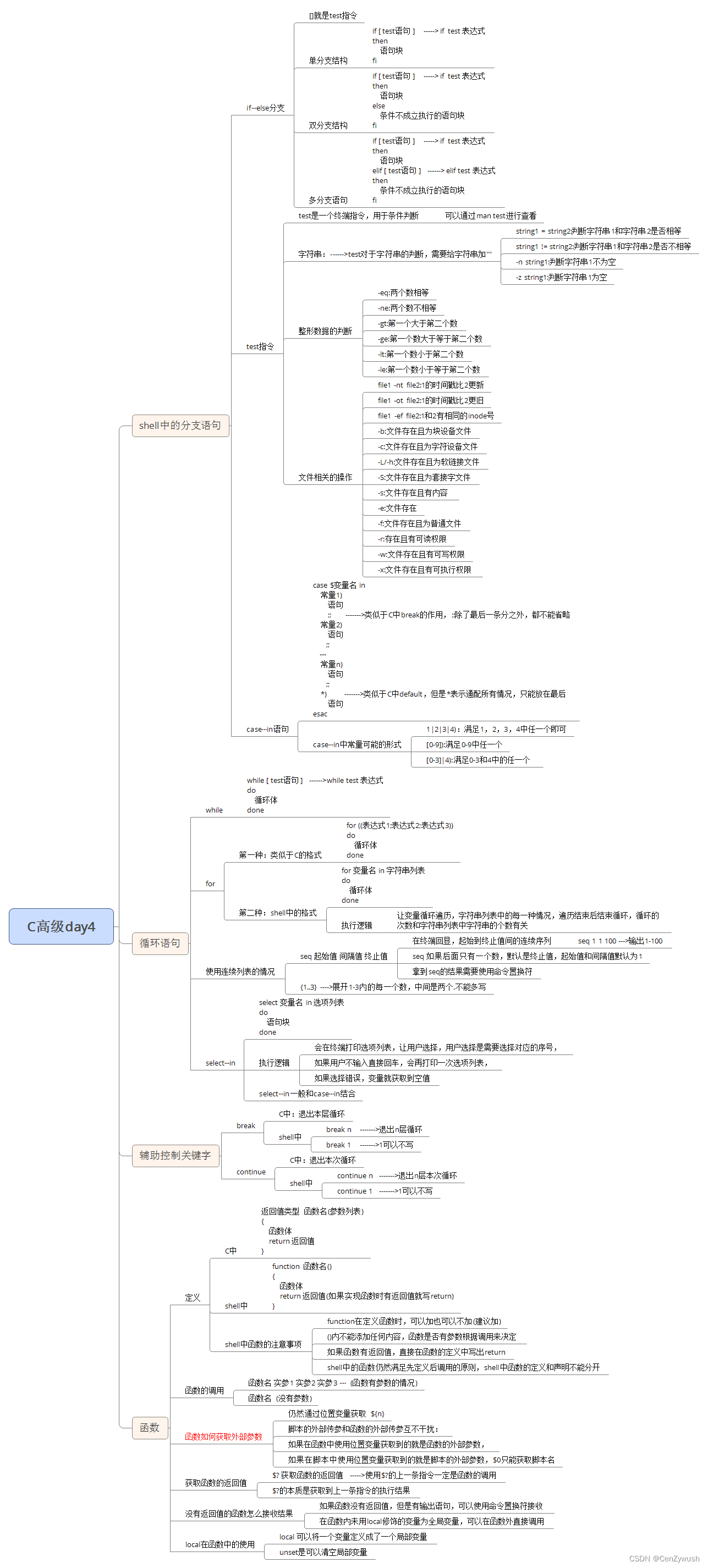
C高级Day5
课后作业: rootlinux:~/shell# cat qh.sh #!/bin/bash function sum_array() {local brr($*) local sum0for i in ${brr[*]} dosum$((sum i))doneecho $sum } arr(1 2 3 4 5) result$(sum_array ${arr[*]}) echo "数组的和为: $result"#!/bin/bash fun…...

AI绘画:Midjourney超详细教程Al表情包超简单制作,内附关键词和变现方式
大家好,本篇文章主要介绍AI绘画完成表情包的制作和变现方式分享。 你还不会AI表情包制作吗?下面我们详细的拆解制作过程。跟着这个教程做出一套属于自己的表情包。 核心工具Midjourney PS,你就可以得到一套自己的专属表情包啦~ 整体制作…...

Linux dup dup2函数
/*#include <unistd.h>int dup2(int oldfd, int newfd);作用:重定向文件描述符oldfd 指向 a.txt, newfd 指向b.txt,调用函数之后,newfd和b.txt close,newfd指向a.txtoldfd必须是一个有效的文件描述符 */ #include <unistd.h> #i…...
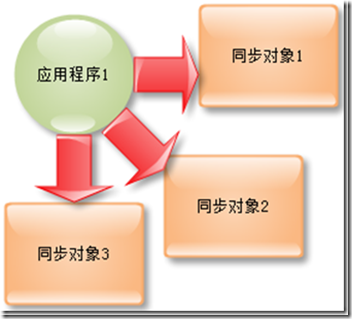
设计模式系列-外观模式
一、上篇回顾 上篇我们主要讲述了创建型模式中的最后一个模式-原型模式,我们主要讲述了原型模式的几类实现方案,和原型模式的应用的场景和特点,原型模式 适合在哪些场景下使用呢?我们先来回顾一下我们上篇讲述的3个常用的场景。 1…...
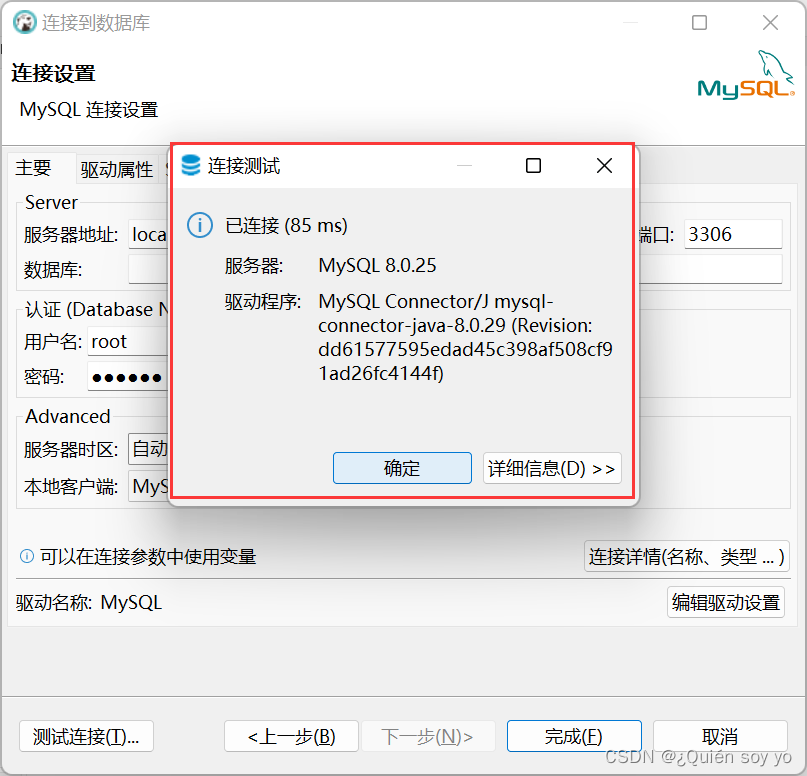
DBeaver 下载、安装与数据库连接(MySQL)详细教程【超详细,保姆级教程!!!】
本文介绍DBeaver 下载、安装与数据库连接(MySQL)的详细教程 一、DBeaver 下载 官网下载地址:https://dbeaver.io/download/ 二、安装 1、双击下载的安装包,选择中文 2、点击下一步 3、点击我接受 4、如下勾选,…...

使用adjustText解决标签文字遮挡问题python
使用adjustText解决文字遮挡问题 1、一个例子2、adjust_text的用法使用pip install adjustText或conda install -c conda-forge adjusttext来安装adjustText。安装成功之后,首先生成随机示例数据以方便之后的演示: 1、一个例子 我们先不使用adjustText调整图像,直接绘制出原…...
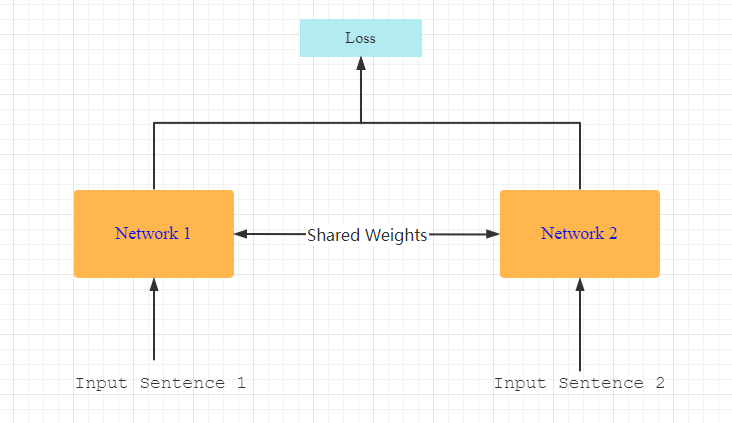
[论文笔记]SiameseNet
引言 这是Learning Text Similarity with Siamese Recurrent Networks的论文笔记。 论文标题意思是利用孪生循环神经网络学习文本相似性。 什么是孪生神经网络呢?满足以下两个条件即可: 输入是成对的网络结构和参数共享(即同一个网络)如下图所示: 看到这种图要知道可能代…...
只有个体户执照,可以用来在抖音开店吗?抖店开通问题解答
我是王路飞。 在抖音开店的门槛,本身就是需要有营业执照的。 至于执照的类型,其实主要看商家自己。 如果你是新手商家,之前也没有怎么接触过电商行业,那么用个体执照在抖音开店足够用了,毕竟你要先入门,…...
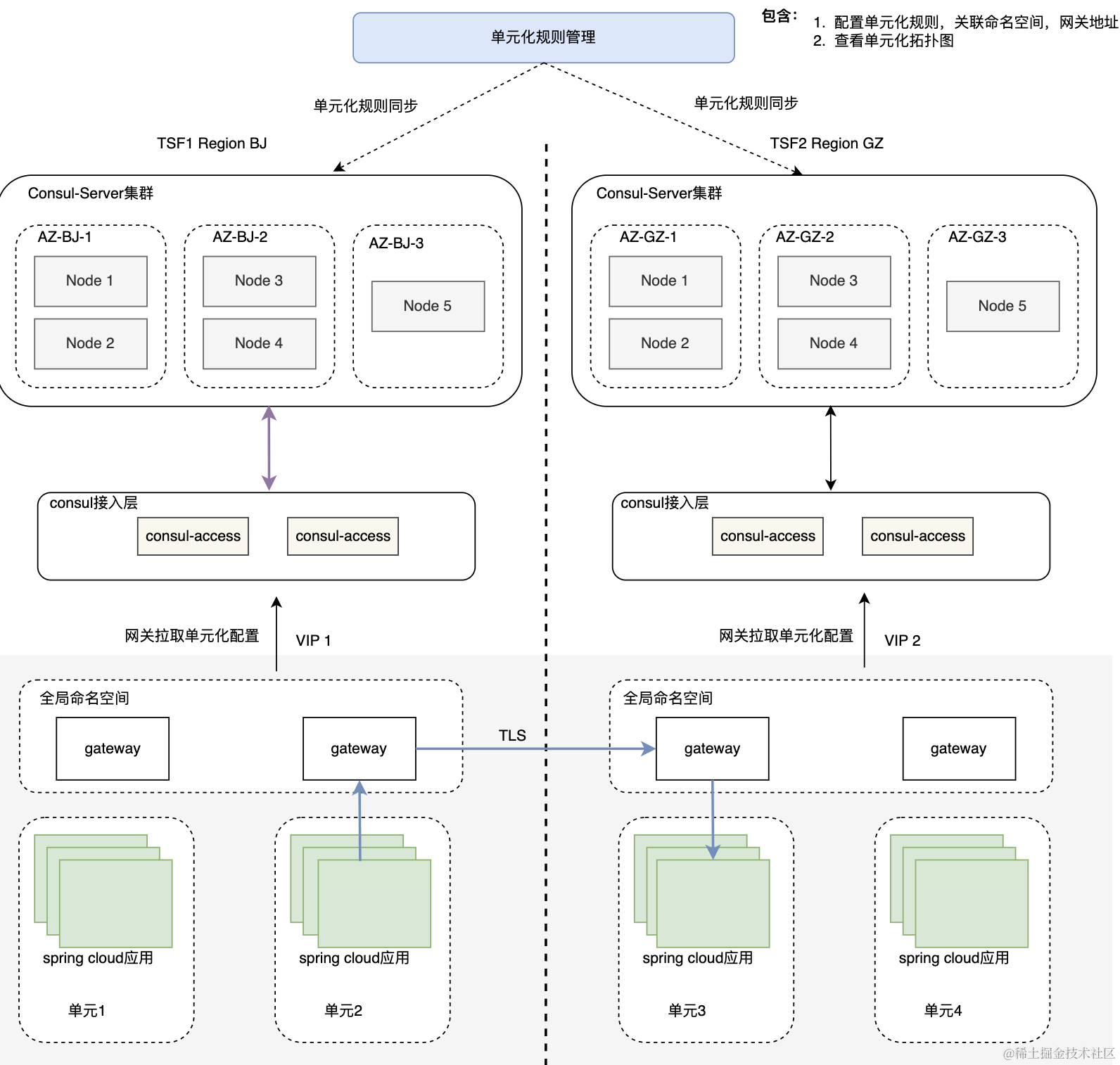
微服务高可用容灾架构设计
导语 相对于过去单体或 SOA 架构,建设微服务架构所依赖的组件发生了改变,因此分析与设计高可用容灾架构方案的思路也随之改变,本文对微服务架构落地过程中的几种常见容灾高可用方案展开分析。 作者介绍 刘冠军 腾讯云中间件中心架构组负责…...

记录docker 部署nessus
1、开启容器 docker run -itd --nameramisec_nessus -p 8834:8834 ramisec/nessus 2、登录 :注意是https https://ip8843 3、修改admin密码 #进入容器 docker exec -it ramisec_nessus /bin/bash#列出用户名 /opt/nessus/sbin/nessuscli lsuser#修改密码&a…...
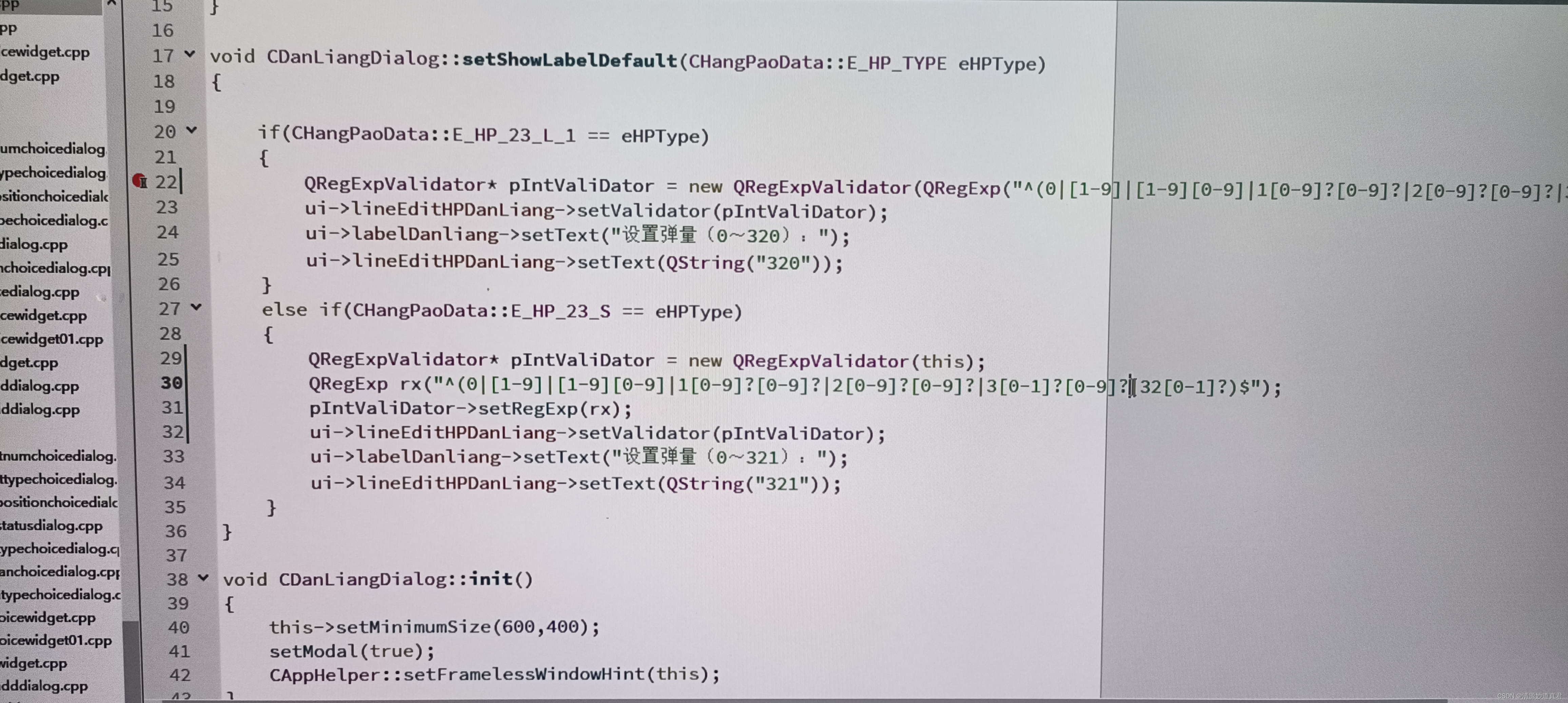
qt 正则表达式
以上是正则表达式的格式说明 以下是自己写的正则表达式 22-25行 是一种设置正则表达式的方式, 29-34行 : 29行 new一个正则表达式的过滤器对象 30行 正则表达式 的过滤格式 这个格式是0-321的任意数字都可以输入 31行 将过滤格式保存到过滤器对象里面 32行 将验…...

l8-d13 UNIX域套接字
一、UNIX 域流式套接字 本地地址 struct sockaddr_un { unsigned short sun_family; /* 协议类型 */ char sun_path[108]; /* 套接字文件路径 */ }; UNIX 域流式套接字的用法和 TCP 套接字基本一致,区别在于使用的协议和地址不同 UNIX 域流式套接字服务器…...
)是什么语法?)
@RequiredArgsConstructor(onConstructor=@_(@Autowired))是什么语法?
这是 Lombok 语法糖写法。 在我们写controller或者Service层的时候,需要注入很多的mapper接口或者另外的service接口,这时候就会写很多的AutoWired注解 lombok提供注解: RequiredArgsConstructor(onConstructor __(Autowired))写在类上可以…...

FL Studio Producer Edition 21.0.3.3713中文完整破解版功能特点及安装激活教程
FL Studio Producer Edition 21.0.3.3713中文完整破解版是一款由Image Line公司研发几近完美的虚拟音乐工作站,同时也是知名的音乐制作软件。它让你的计算机就像是全功能的录音室,漂亮的大混音盘,先进的创作工具,让你的音乐突破想象力的限制。…...

Clawforce:开源AI智能体团队基础设施,实现持久化与安全协作
1. 项目概述:Clawforce,一个为持久化AI智能体团队构建的基础设施最近在AI智能体领域,一个词被反复提及:“Agentic AI”,即智能体驱动的AI。这不再是让单个AI模型回答一个问题那么简单,而是构建一个能够自主…...
)
Excel数据同步ERP/CRM太麻烦?一个Python脚本搞定多系统自动填充(基于GoBot)
Excel数据同步ERP/CRM太麻烦?一个Python脚本搞定多系统自动填充(基于GoBot) 每次月底看着财务同事在ERP系统里逐条录入Excel数据,市场部同事又在CRM里重复同样的操作,这种低效场景你一定不陌生。数据在不同系统间的孤岛…...
)
从癌症研究到企业风控:用Python实战Cox比例风险模型(附完整代码与数据)
从医学到商业:Python实战Cox风险模型的企业级应用 在医疗领域,我们关心患者存活时间;在商业世界,我们关注客户生命周期。看似迥异的场景背后,都隐藏着同一个数学工具的身影——Cox比例风险模型。这个诞生于1972年的生存…...

国家级数据仓库构建:从爬取到应用的全流程实践指南
1. 项目概述与核心价值最近在整理一个数据项目时,我偶然发现了一个名为“national_data”的仓库,作者是Ddhjx。这个项目名听起来平平无奇,但点进去之后,我发现它远不止是一个简单的数据集合。它本质上是一个结构化的、持续更新的国…...

终极Moonlight TV游戏串流指南:3分钟实现电视大屏游戏体验
终极Moonlight TV游戏串流指南:3分钟实现电视大屏游戏体验 【免费下载链接】moonlight-tv Lightweight NVIDIA GameStream Client, for LG webOS TV and embedded devices like Raspberry Pi 项目地址: https://gitcode.com/gh_mirrors/mo/moonlight-tv 你是…...

使用Nodejs和Taotoken为前端应用构建AI聊天后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js和Taotoken为前端应用构建AI聊天后端 基础教程类,指导前端或全栈开发者使用Node.js环境接入Taotoken&#…...
)
华为eNSP模拟器实战:用VRRP+MSTP给公司网络做个高可用冗余(附完整配置命令)
华为eNSP企业级网络高可用架构实战:VRRP与MSTP深度协同设计 当一家中型企业的终端规模突破500台时,网络架构的脆弱性往往会突然暴露——某个交换机的意外宕机可能导致整个部门断网,核心链路的拥塞会让关键业务卡顿不已。这时仅靠基础的STP和…...

实战部署Funannotate基因组注释工具:3种高效配置方案指南
实战部署Funannotate基因组注释工具:3种高效配置方案指南 【免费下载链接】funannotate Eukaryotic Genome Annotation Pipeline 项目地址: https://gitcode.com/gh_mirrors/fu/funannotate Funannotate是一款专业的真核生物基因组注释工具,特别针…...

从‘咖啡环’到‘热点’富集:超疏水表面如何将SERS检测灵敏度提升几个数量级?
从“咖啡环效应”到分子富集革命:超疏水表面如何重塑痕量检测极限 清晨的咖啡杯边缘总留下一圈深色痕迹,这个看似普通的日常现象背后,隐藏着改变分子检测游戏规则的物理机制。当科研人员将这种被称为"咖啡环效应"的液滴蒸发现象与表…...

NodeMCU PyFlasher:让物联网开发变得简单的固件烧录神器
NodeMCU PyFlasher:让物联网开发变得简单的固件烧录神器 【免费下载链接】nodemcu-pyflasher Self-contained NodeMCU flasher with GUI based on esptool.py and wxPython. 项目地址: https://gitcode.com/gh_mirrors/no/nodemcu-pyflasher 还在为NodeMCU开…...