学习 BeautifulSoup 库从入门到精通
可以按照以下步骤进行:
1. 安装 BeautifulSoup:
首先,确保你已经安装了 Python。然后可以使用 pip 命令来安装 BeautifulSoup 库。在命令行中输入以下命令:
pip install beautifulsoup4
2. 导入 BeautifulSoup:
在 Python 脚本中,导入 BeautifulSoup 库以便使用其功能。可以使用以下代码导入 BeautifulSoup:
from bs4 import BeautifulSoup
3. 创建解析树:
使用 BeautifulSoup,可以将 HTML 或 XML 字符串传递给构造函数,创建一个解析树对象。例如,可以使用以下方式创建一个解析树对象:
soup = BeautifulSoup(html_string, 'html.parser')
4. 遍历解析树:
掌握遍历解析树的方法是非常重要的。可以使用以下方式来定位节点:
- 通过标签名:使用
find或find_all方法来定位单个或多个标签节点。 - 通过 CSS 选择器:使用
select方法来使用 CSS 选择器定位节点。 - 通过正则表达式:使用
find或find_all方法的string参数来使用正则表达式定位节点。
5. 提取信息:
一旦定位到所需的节点,可以使用 BeautifulSoup 提供的各种方法来提取节点的文本内容、属性值等信息。例如:
- 使用
text属性来获取节点的文本内容。 - 使用
get方法来获取节点的属性值。 - 使用
parent、next_sibling、previous_sibling等属性来获取节点的父节点、兄弟节点等。
6. 修改解析树:
BeautifulSoup 也支持对解析树进行修改。可以添加、删除、修改节点等操作,以满足特定的需求。例如:
- 使用
append、insert等方法来添加节点。 - 使用
extract方法来删除节点。
7. 异常处理:
在使用 BeautifulSoup 进行解析时,可能会遇到一些异常情况,如标签不完整、编码问题等。了解如何处理这些异常情况是很重要的。可以使用 try-except 语句来捕获并处理异常。
8. 进阶用法:
在第8点中,提到了一些进阶的用法,可以进一步学习和掌握 BeautifulSoup 库的高级功能。以下是一些有关进阶用法的更详细说明:
8.1. 使用不同的解析器:
BeautifulSoup 默认使用 Python 内置的解析器 html.parser,但也支持其他解析器,如 lxml、html5lib 等。这些解析器在处理某些复杂的 HTML 或 XML 文档时可能更可靠或更快速。可以使用解析器的名称作为第二个参数传递给 BeautifulSoup 的构造函数来选择特定的解析器。
例如,使用 lxml 解析器可以这样创建解析树对象:
soup = BeautifulSoup(html_string, 'lxml')
需要注意的是,使用不同的解析器可能需要额外安装相关的库。
8.2. 使用 CSS 选择器:
BeautifulSoup 提供了 select 方法来使用 CSS 选择器定位节点。使用 CSS 选择器可以更方便地定位节点,特别是对于复杂的文档结构。
例如,使用 CSS 选择器定位所有带有 class 属性为 my-class 的 div 标签可以这样写:
divs = soup.select('div.my-class')
这将返回一个列表,包含所有符合条件的 div 标签。
8.3. 使用正则表达式:
BeautifulSoup 的 find 和 find_all 方法的 string 参数支持正则表达式,可以用来定位节点文本内容符合特定模式的节点。
例如,使用正则表达式定位所有文本内容为数字的节点可以这样写:
import re
pattern = re.compile(r'\d+')
nodes = soup.find_all(string=pattern)
这将返回一个列表,包含所有符合条件的节点。
通过学习和实践这些进阶用法,你可以更加灵活地使用 BeautifulSoup 库,处理更复杂的 HTML 或 XML 文档,并提取出所需的信息。阅读官方文档和参考示例代码也是掌握这些用法的好方法。
9. 练习和实践:
最好的学习方式是通过实践。尝试使用 BeautifulSoup 库解析不同的网页,并提取出所需的信息。通过实践,你可以更好地理解和掌握 BeautifulSoup 的各种功能和技巧。
9.1. 修改节点内容:
BeautifulSoup 提供了 replace_with 方法来替换节点的内容。可以使用该方法修改节点的文本内容或标签。
例如,将一个节点的文本内容替换为新的内容可以这样写:
node = soup.find('p')
node.string.replace_with('New Content')
这将把该节点的文本内容替换为 'New Content'。
9.2. 遍历节点树:
使用 BeautifulSoup,可以通过遍历节点树的方式来访问和处理文档中的节点。可以使用 children、descendants、next_sibling、previous_sibling 等方法来访问不同层级和关系的节点。
例如,遍历并打印所有子节点的文本内容可以这样写:
for child in soup.body.children:print(child.string)
9.3. 处理 XML 文档:
BeautifulSoup 不仅可以用于解析 HTML 文档,也可以用于解析 XML 文档。可以使用相同的方法和属性来处理 XML 文档。
例如,解析 XML 文档可以这样写:
soup = BeautifulSoup(xml_string, 'xml')
然后就可以使用 BeautifulSoup 提供的方法和属性来访问和处理 XML 文档。
以上是一些关于 BeautifulSoup 库的其他功能和扩展的说明。通过学习和实践这些功能,你可以更加灵活地处理和操作文档中的节点,完成更复杂的任务和需求。阅读官方文档和参考示例代码也是掌握这些功能的好方法。
10. 案例
案例1: 修改节点内容
假设我们有一个 HTML 文档,其中一个 <p> 标签包含了一段旧的文本内容。我们想要将这段文本内容替换为新的内容。
from bs4 import BeautifulSouphtml = '''
<html>
<body><p>旧的文本内容</p>
</body>
</html>
'''soup = BeautifulSoup(html, 'html.parser')
node = soup.find('p')
node.string.replace_with('新的文本内容')print(soup)
输出:
<html>
<body><p>新的文本内容</p>
</body>
</html>
在这个案例中,我们使用 find 方法找到了 <p> 标签的节点,然后使用 replace_with 方法将节点的文本内容替换为 '新的文本内容'。
案例2: 遍历节点树
假设我们有一个 HTML 文档,其中包含了一些嵌套的标签,我们想要遍历并打印所有的文本内容。
from bs4 import BeautifulSouphtml = '''
<html>
<body><div><p>第一个段落</p><p>第二个段落</p></div>
</body>
</html>
'''soup = BeautifulSoup(html, 'html.parser')for child in soup.body.children:if child.string:print(child.string)
输出:
第一个段落
第二个段落
在这个案例中,我们使用了 children 方法来访问 body 标签下的子节点。然后我们使用了 string 属性来获取节点的文本内容,并进行打印。
案例3: 处理 XML 文档
除了解析 HTML 文档,BeautifulSoup 也可以用于解析 XML 文档。我们可以使用相同的方法和属性来处理 XML 文档。
from bs4 import BeautifulSoupxml = '''
<root><person><name>John</name><age>30</age></person><person><name>Jane</name><age>25</age></person>
</root>
'''soup = BeautifulSoup(xml, 'xml')persons = soup.find_all('person')
for person in persons:name = person.find('name').stringage = person.find('age').stringprint(f"Name: {name}, Age: {age}")
输出:
Name: John, Age: 30
Name: Jane, Age: 25
在这个案例中,我们使用了 'xml' 参数来指定解析器,告诉 BeautifulSoup 这是一个 XML 文档。然后我们使用了 find_all 方法来找到所有的 person 标签,进而获取每个 person 标签下的 name 和 age 的文本内容,并进行打印。
这些案例展示了 BeautifulSoup 库的其他功能和扩展的用法。你可以根据自己的需求和任务,使用这些功能来解析、处理和操作文档中的节点。
11. 练习题
练习题1: 获取所有链接
给定一个 HTML 文档,编写一个程序来获取所有的链接,并打印出链接的文本内容和对应的 URL。
from bs4 import BeautifulSouphtml = '''
<html>
<body><a href="https://www.example1.com">Link 1</a><a href="https://www.example2.com">Link 2</a><a href="https://www.example3.com">Link 3</a>
</body>
</html>
'''soup = BeautifulSoup(html, 'html.parser')links = soup.find_all('a')
for link in links:text = link.stringurl = link['href']print(f"Text: {text}, URL: {url}")
练习题2: 提取图片链接
给定一个 HTML 文档,编写一个程序来提取所有图片的链接,并打印出链接的 URL。
from bs4 import BeautifulSouphtml = '''
<html>
<body><img src="https://www.example.com/image1.jpg"><img src="https://www.example.com/image2.jpg"><img src="https://www.example.com/image3.jpg">
</body>
</html>
'''soup = BeautifulSoup(html, 'html.parser')images = soup.find_all('img')
for image in images:url = image['src']print(f"URL: {url}")
练习题3: 计算总字数
给定一个 HTML 文档,编写一个程序来计算文档中所有节点的文本内容的总字数。
from bs4 import BeautifulSouphtml = '''
<html>
<body><h1>标题</h1><p>第一段文本</p><p>第二段文本</p>
</body>
</html>
'''soup = BeautifulSoup(html, 'html.parser')total_words = 0
for node in soup.find_all():if node.string:words = len(node.string.split())total_words += wordsprint(f"Total words: {total_words}")
这些练习题可以帮助你练习使用 BeautifulSoup 来解析和操作文档中的节点。你可以根据这些练习题的要求进行编程,并查看结果来验证你的代码是否正确。
不断练习和实践是掌握 BeautifulSoup 库的关键。阅读官方文档、参考教程和示例代码,也能够帮助你更好地理解和使用 BeautifulSoup。
相关文章:

学习 BeautifulSoup 库从入门到精通
可以按照以下步骤进行: 1. 安装 BeautifulSoup: 首先,确保你已经安装了 Python。然后可以使用 pip 命令来安装 BeautifulSoup 库。在命令行中输入以下命令: pip install beautifulsoup42. 导入 BeautifulSoup: 在 …...

JavaScript基础知识总结
目录 一、js代码位置 二、变量与数据类型 1、声明变量 2、基本类型(7种基本类型) 1、undefined和null 2、String ⭐ 模板字符串(Template strings) 3、number和bigint ⭐ 4、boolean ⭐ 5、symbol 3、对象类型 1、Fun…...

技术面试与HR面:两者之间的关联与区别
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

【Redis】为什么要学 Redis
文章目录 前言一、Redis 为什么快二、Redis 的特性2.1 将数据储存到内存中2.2 可编程性2.3 可扩展性2.4 持久性2.5 支持集群2.6 高可用性 三、Redis 的应用场景四、不能使用 Redis 的场景 前言 关于为什么要学 Redis 这个问题,一个字就可以回答,那就是&…...
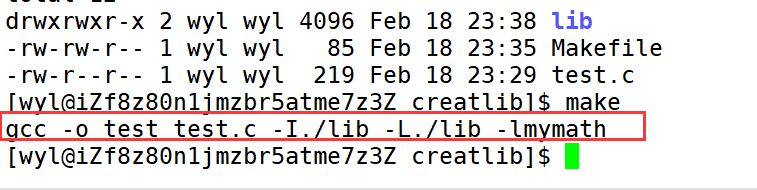
动静态库生成使用
🔥🔥 欢迎来到小林的博客!! 🛰️博客主页:✈️林 子 🛰️博客专栏:✈️ Linux 🛰️社区 :✈️ 进步学堂 🛰…...

LLVM编译安装
LLVM编译安装 #全量下载 git clone https://github.com/llvm/llvm-project.git #只下载最新commit版本 git clone --depth 1 https://github.com/llvm/llvm-project.git#配置 #!/bin/bash set -ex cmake -S llvm -B build -DCMAKE_INSTALL_PREFIX/data0/huozai/software/insta…...

表的内连接和外连接
表的连接是SQL中的一种操作,用于将两个或多个表中的数据按照某个条件进行关联。 内连接 使用内连接将两个表(Table1 和 Table2)进行连接: select * from Table1 inner join Table2 on Table1.id Table2.id;举例: -- 用普通的写法 select…...
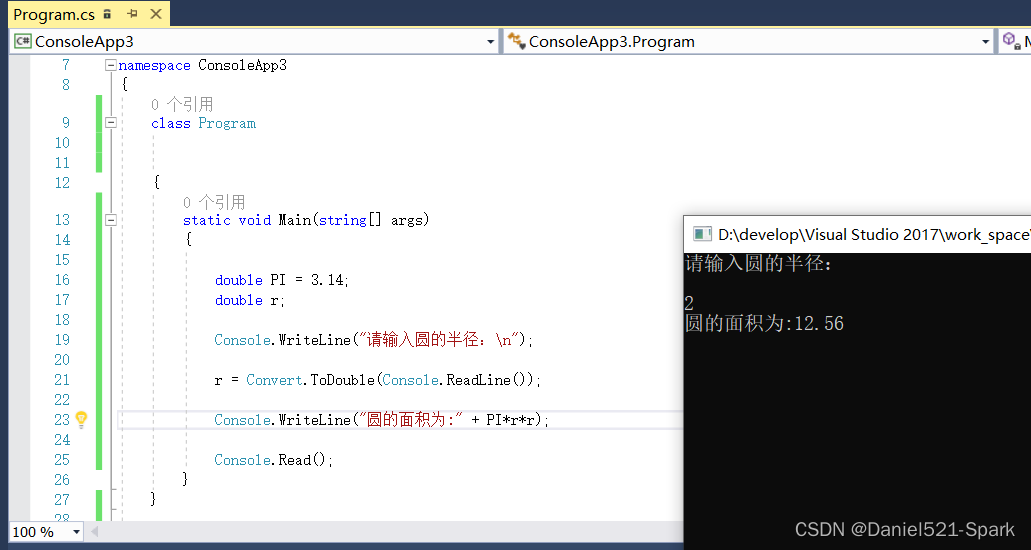
三、C#—变量,表达式,运算符(3)
🌻🌻 目录 一、变量1.1 变量1.2 使用变量的步骤1.3 变量的声明1.4 变量的命名规则1.5 变量的初始化1.6 变量初始化的三种方法1.7 变量的作用域1.8 变量使用实例1.9 变量常见错误 二、C#数据类型2.1 数据类型2.2 值类型2.2.1 值类型直接存储值2.2.2 简单类…...

纷享销客受邀出席CDIE2023数字化创新博览会 助力大中型企业增长
2023年,穿越周期,用数字化的力量重塑企业经营与增长的逻辑,再次成为企业数字化技术应用思考的主旋律,以数字经济为主线,数字技术融入产业发展与企业增长为依据,推动中国企业数字化升级。 9月5日,…...

linux下qt交叉编译 tslib 库
在 Linux 下进行 Qt 的交叉编译,并包含 tslib 库,可以按照以下步骤进行操作:1. 准备交叉编译工具链:首先,你需要准备适用于目标平台的交叉编译工具链。这个工具链包括交叉编译器、 2. 链接器和其他相关的工具ÿ…...
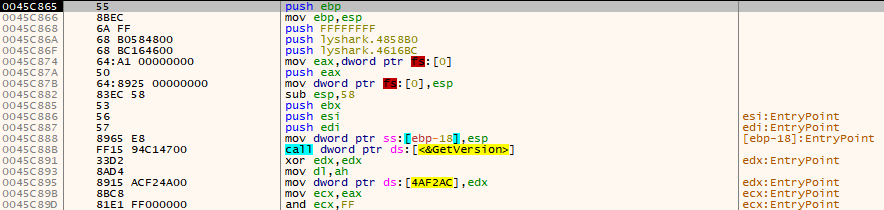
2.13 PE结构:实现PE代码段加密
代码加密功能的实现原理,首先通过创建一个新的.hack区段,并对该区段进行初始化,接着我们向此区段内写入一段具有动态解密功能的ShellCode汇编指令集,并将程序入口地址修正为ShellCode地址位置处,当解密功能被运行后则可…...

Rust更换Cargo国内源,镜像了寂寞
换皮不换身 换了国内源,构建时该卡还会卡。因为它所谓的换源,只是更换crates.io“索引”的源,而不是package“内容”的源。换了国内源后,在国内编译时访问 crates.io-index 自然会快很多,可是crates.io-index里面的信…...
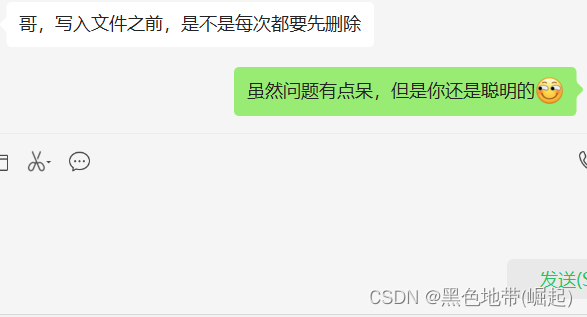
【网络安全带你练爬虫-100练】第23练:文件内容的删除+写入
目录 0x00 前言: 0x02 解决: 0x00 前言: 本篇博文可能会有一点点的超级呆 0x02 解决: 你是不是也会想: 使用pyrhon将指定文件夹位置里面的1.txt中数据全部删除以后---->然后再将参数req_text的值写入到1.txt …...

ESP32蓝牙实例-BLE服务器与客户端通信
BLE服务器与客户端通信 文章目录 BLE服务器与客户端通信1、软件准备2、硬件准备3、代码实现3.1 BLE服务器实现3.2 Android手机测试BLE服务器3.3 ESP32 BLE客户端在本文中,我们将介绍如何使用低功耗蓝牙在两个 ESP32 开发板之间执行 BLE 服务器客户端通信。 换句话说,将介绍如…...

第11章_瑞萨MCU零基础入门系列教程之SysTick
本教程基于韦东山百问网出的 DShanMCU-RA6M5开发板 进行编写,需要的同学可以在这里获取: https://item.taobao.com/item.htm?id728461040949 配套资料获取:https://renesas-docs.100ask.net 瑞萨MCU零基础入门系列教程汇总: ht…...

【面试题精讲】如何使用Stream的聚合功能
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 首发博客地址 系列文章地址 求和(Sum): List<Integer> numbers Arrays.asList(1, 2, 3, 4, 5);int sum n…...

Linux 中的 chmod 命令及示例
在 Unix 操作系统中,chmod命令用于更改文件的访问模式。该名称是change mode的缩写。其中规定每个文件和目录都有一组权限来控制权限,例如谁可以读取、写入或执行该文件。其中权限分为三类:同时读、写和执行,用“r”、“w”和“x”表示。这些字母组合在一起形成一组用户的特…...

sannaing i14 pro max使用体验
体验了一把山寨机,不明真相的人会以为这是三星的英文标志,又是pro又是max的,价格600,进系统去看了配置,cpu写的是snapdragon 888,运存12g,内存500g。下了个安兔兔也是被忽悠了,它也以…...

Shazam音乐检索算法原理及实现
算法基本流程如下: 1. 采集音乐库 2. 音乐指纹采集 3. 采用局部最大值作为特征点 4. 将临近的特征点进行组合形成特征点对 5. 对每个特征点对进行hash编码 编码过程:将f1和f2进行10bit量化,其余bit用来存储时间偏移合集形成32bit的hash码 …...

vue递归组件
父组件: <template><div><treeVue :treeData"treeData"></treeVue></div> </template><script setup lang"ts"> import { reactive } from "vue"; import treeVue from "./tree.vue…...

AI建站避坑指南:10个高频问题与风险防范全解析
用AI建站虽然快,但过程中隐藏的风险如果没到,轻则内容效果差,重则可能有版权或合规隐患。这份避坑指南,围绕大家最关心的10个核心问题,给出客观的分析和可操作的防范建议,帮你安心用好AI建站工具。\### 核心…...

OpenClaw+GLM-4.7-Flash:个人财务数据处理自动化方案
OpenClawGLM-4.7-Flash:个人财务数据处理自动化方案 1. 为什么需要自动化财务处理 每个月末,我都会面对一堆散乱的银行流水、电子发票和Excel表格。手动整理这些数据不仅耗时,还容易出错。直到我发现OpenClaw这个开源自动化框架,…...

VS Code+智谱AI+Cline 完整实战教程
对于习惯用VS Code做日常开发、偏爱国产大模型的开发者来说,Cline是一款轻量无广告、适配性极强的AI编程客户端插件,搭配智谱GLM-4系列、CodeGeeX 4编码专用模型,既能完美适配中文编程需求,又能无缝对接Vue、Python、Java、小程序…...

vLLM-v0.17.1在新闻聚合平台的应用:热点事件摘要生成服务
vLLM-v0.17.1在新闻聚合平台的应用:热点事件摘要生成服务 1. 技术背景与需求场景 新闻聚合平台每天需要处理海量新闻内容,如何快速生成准确、简洁的热点事件摘要成为关键挑战。传统方法依赖人工编辑或简单规则提取,效率低下且质量参差不齐。…...

CYBER-VISION零号协议SolidWorks设计文档智能解读与生成
CYBER-VISION零号协议:让AI读懂你的SolidWorks设计图 每次打开一个复杂的SolidWorks装配体文件,面对几十上百个零件,你是不是也头疼过整理物料清单、编写设计说明?或者,当同事发来一份设计文档,你需要花半…...

RTX4090D优化版Qwen3-32B+OpenClaw:3小时搞定AI办公自动化
RTX4090D优化版Qwen3-32BOpenClaw:3小时搞定AI办公自动化 1. 为什么选择本地部署方案 去年冬天,当我第17次被飞书机器人返回的"API配额不足"提示打断工作流时,终于下定决心寻找替代方案。作为一个小型技术团队的负责人࿰…...

造相-Z-Image效果对比:Z-Image在中文语义理解准确率上超越SDXL实测
造相-Z-Image效果对比:Z-Image在中文语义理解准确率上超越SDXL实测 最近在折腾本地文生图,发现了一个挺有意思的现象。我用的是基于通义千问官方Z-Image模型定制的“造相-Z-Image”引擎,专门为我的RTX 4090显卡做了优化。本来只是想试试它的…...
性能对比与应用场景)
Python实战:线性方程组求解的三大直接分解法(Doolittle、克劳特、追赶法)性能对比与应用场景
1. 线性方程组求解的三大直接分解法概述 遇到线性方程组求解问题时,很多开发者会直接调用现成的库函数。但了解底层算法原理,能帮助我们在特定场景下选择最优解法。就像开车时知道发动机原理,遇到故障时就能更快定位问题。今天要聊的Doolittl…...

终极指南:深入解析 Evcxr 模块系统如何实现 Rust 代码隔离和状态管理
终极指南:深入解析 Evcxr 模块系统如何实现 Rust 代码隔离和状态管理 【免费下载链接】evcxr 项目地址: https://gitcode.com/gh_mirrors/ev/evcxr Evcxr 是一个为 Rust 语言设计的 eval() 实现,提供了强大的代码隔离和状态管理功能。这个 Rust …...

语音控制扩展:让OpenClaw通过nanobot响应语音指令
语音控制扩展:让OpenClaw通过nanobot响应语音指令 1. 为什么需要语音控制OpenClaw 作为一个长期使用OpenClaw的开发者,我一直在思考如何让这个强大的自动化工具更加"人性化"。键盘鼠标操作固然精确,但在某些场景下——比如双手被…...