Shazam音乐检索算法原理及实现

算法基本流程如下:
1. 采集音乐库
2. 音乐指纹采集
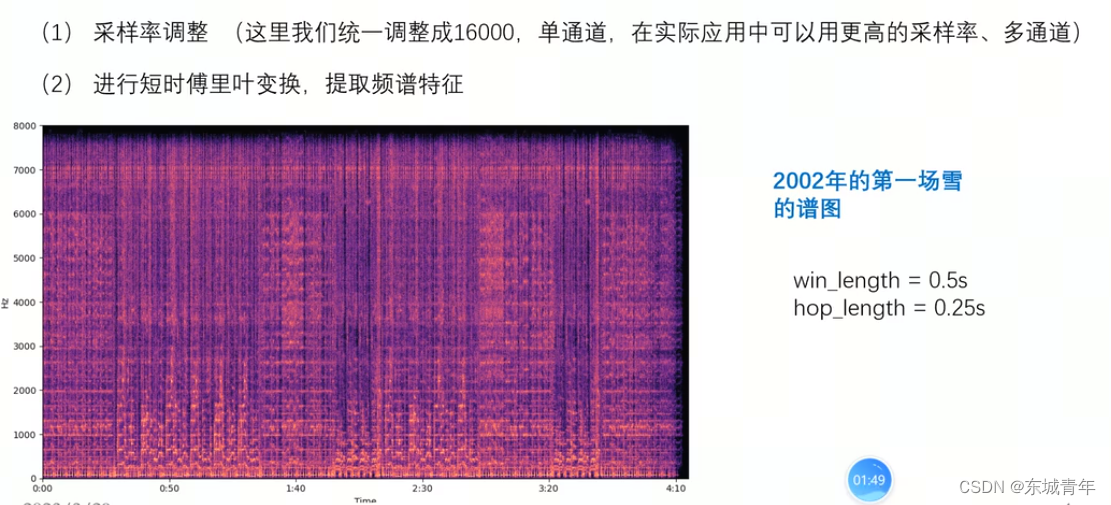
3. 采用局部最大值作为特征点
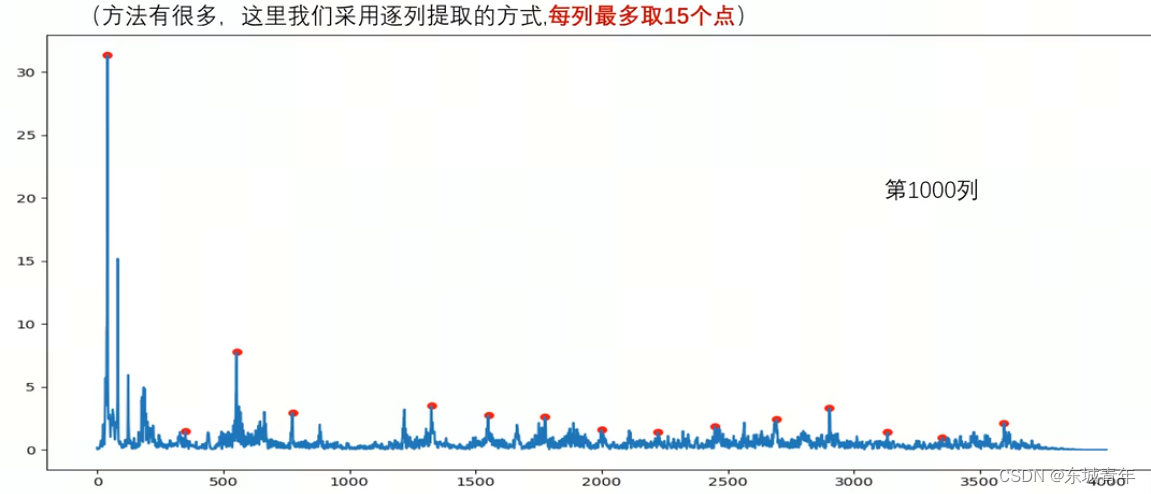
4. 将临近的特征点进行组合形成特征点对
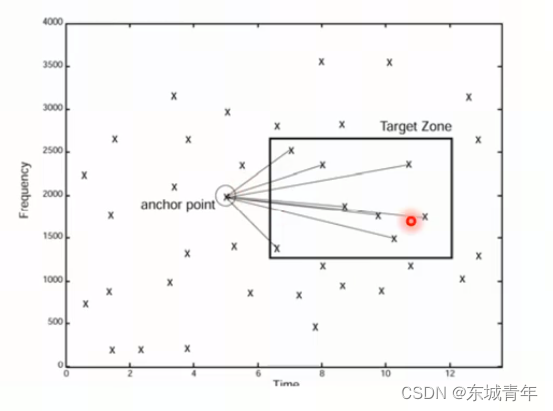
5. 对每个特征点对进行hash编码
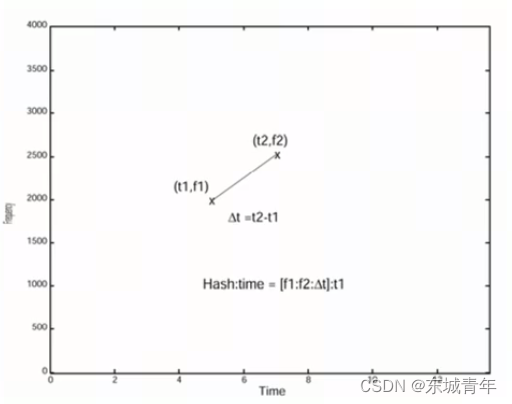
编码过程:将f1和f2进行10bit量化,其余bit用来存储时间偏移合集形成32bit的hash码
Hash = f1|f2<<10|diff_t<<20,存储信息(t1,Hash)
实现:
import numpy as np
import librosa
from scipy import signal
import pickle
import osfix_rate = 16000
win_length_seconds = 0.5
frequency_bits = 10
num_peaks = 15# 构造歌曲名与歌曲id之间的映射字典
def song_collect(base_path):index = 0dic_idx2song = {}for roots, dirs, files in os.walk(base_path):for file in files:if file.endswith(('.mp3', '.wav')):file_song = os.path.join(roots, file)dic_idx2song[index] = file_songindex += 1return dic_idx2song# 提取局部最大特征点
def collect_map(y, fs, win_length_seconds=0.5, num_peaks=15):win_length = int(win_length_seconds * fs)hop_length = int(win_length // 2)S = librosa.stft(y, n_fft=win_length, win_length=win_length, hop_length=hop_length)S = np.abs(S) # 获取频谱图D, T = np.shape(S)constellation_map = [] for i in range(T):spectrum = S[:, i]peaks_index, props = signal.find_peaks(spectrum, prominence=0, distance=200)# 根据显著性进行排序n_peaks= min(num_peaks, len(peaks_index))largest_peaks_index = np.argpartition(props['prominences'], -n_peaks)[-n_peaks:]for peak_index in peaks_index[largest_peaks_index]:frequency = fs / win_length * peak_index# 保存局部最大值点的时-频信息constellation_map.append([i, frequency])return constellation_map# 进行Hash编码
def create_hash(constellation_map, fs, frequency_bits=10, song_id=None):upper_frequency = fs / 2hashes = {}for idx, (time, freq) in enumerate(constellation_map):for other_time, other_freq in constellation_map[idx: idx + 100]: # 从邻近的100个点中找点对diff = int(other_time - time)if diff <= 1 or diff > 10: # 在一定时间范围内找点对continuefreq_binned = int(freq / upper_frequency * (2 ** frequency_bits))other_freq_binned = int(other_freq / upper_frequency * (2 ** frequency_bits))hash = int(freq_binned) | (int(other_freq) << 10) | (int(diff) << 20)hashes[hash] = (time, song_id)return hashes特征提取:feature_collect.py
# 获取数据库中所有音乐
path_music = 'data'
current_path = os.getcwd()
path_songs = os.path.join(current_path, path_music)
dic_idx2song = song_collect(path_songs)# 对每条音乐进行特征提取
database = {}
for song_id in dic_idx2song.keys():file = dic_idx2song[song_id]print("collect info of file", file)# 读取音乐y, fs = librosa.load(file, sr=fix_rate)# 提取特征对constellation_map = collect_map(y, fs, win_length_seconds=win_length_seconds, num_peaks=num_peaks)# 获取hash值hashes = create_hash(constellation_map, fs, frequency_bits=frequency_bits, song_id=song_id)# 把hash信息填充入数据库for hash, time_index_pair in hashes.items():if hash not in database:database[hash] = []database[hash].append(time_index_pair)# 对数据进行保存
with open('database.pickle', 'wb') as db:pickle.dump(database, db, pickle.HIGHEST_PROTOCOL)
with open('song_index.pickle', 'wb') as songs:pickle.dump(dic_idx2song, songs, pickle.HIGHEST_PROTOCOL)# 加载数据库
database = pickle.load(open('database.pickle', 'rb'))
dic_idx2song = pickle.load(open('song_index.pickle', 'rb'))
print(len(database))# 检索过程
def getscores(y, fs, database):# 对检索语音提取hashconstellation_map = collect_map(y, fs)hashes = create_hash(constellation_map, fs, frequency_bits=10, song_id=None)# 获取与数据库中每首歌的hash匹配matches_per_song = {}for hash, (sample_time, _) in hashes.items():if hash in database:maching_occurences = database[hash]for source_time, song_index in maching_occurences:if song_index not in matches_per_song:matches_per_song[song_index] = []matches_per_song[song_index].append((hash, sample_time, source_time))scores = {}# 对于匹配的hash,计算测试样本时间和数据库中样本时间的偏差for song_index, matches in matches_per_song.items():
# scores[song_index] = len(matches)song_scores_by_offset = {}# 对相同的时间偏差进行累计for hash, sample_time, source_time in matches:delta = source_time - sample_timeif delta not in song_scores_by_offset:song_scores_by_offset[delta] = 0song_scores_by_offset[delta] += 1# 计算每条歌曲的最大累计偏差max = (0, 0)for offset, score in song_scores_by_offset.items():if score > max[1]:max = (offset, score)scores[song_index] = maxscores = sorted(scores.items(), key=lambda x:x[1][1], reverse=True)return scores音乐检索:music_research.py
import threading
from playsound import playsounddef cycle(path):while 1:playsound(path)
def play(path, cyc=False):if cyc:cycle(path)else:playsound(path)path = 'test_music/record4.wav'
y, fs = librosa.load(path, sr=fix_rate)
# 播放待检索音频
music = threading.Thread(target=play, args=(path,))
music.start()# 检索打分
scores = getscores(y, fs, database)# 打印检索信息
for k, v in scores:file = dic_idx2song[k]name = os.path.split(file)[-1]# print("%s :%d"%(name, v))print("%s: %d: %d"%(name, v[0], v[1]))# 打印结果
if len(scores) > 0 and scores[0][1][1] > 50:print("检索结果为:", os.path.split(dic_idx2song[scores[0][0]])[-1])
else:print("没有搜索到该音乐")麦克风录音识别音乐:
import pyaudio
import waveRATE = 48000 # 采样率
CHUNK = 1024 # 帧大小
record_seconds = 10 # 录音时长s
CHANNWLS = 2 # 通道数# 创建pyaudio流
audio = pyaudio.PyAudio()stream = audio.open(format=pyaudio.paInt16, # 使用量化位数16位channels=CHANNWLS, # 输入声道数目rate=RATE, # 采样率input=True, # 打开输入流frames_per_buffer=CHUNK) # 缓冲区大小frames = [] # 存放录制的数据
# 开始录音
print('录音中。。。')
for i in range(0, int(RATE / CHUNK * record_seconds)):# 从麦克风读取数据流data = stream.read(CHUNK)# 将数据追加到列表中frames.append(data)# 停止录音,关闭输入流
stream.stop_stream()
stream.close()
audio.terminate()# 将录音数据写入wav文件中
with wave.open('test_music/test.wav', 'wb') as wf:wf.setnchannels(CHANNWLS)wf.setsampwidth(audio.get_sample_size(pyaudio.paInt16))wf.setframerate(RATE)wf.writeframes(b''.join(frames))# 打开录音文件
path = 'test_music/test.wav'
y, fs = librosa.load(path, sr=fix_rate)# 线程播放待检索音频
# music = threading.Thread(target=play, args=(path,))
# music.start()# 音乐检索
print('检索中。。。')
scores = getscores(y, fix_rate, database)# 打印检索信息
# for k, v in scores:
# file = dic_idx2song[k]
# name = os.path.split(file)[-1]
# # print("%s :%d"%(name, v))
# print("%s: %d: %d"%(name, v[0], v[1]))# 打印结果
if len(scores) > 0 and scores[0][1][1] > 50:print("检索结果为:", os.path.split(dic_idx2song[scores[0][0]])[-1])
else:print("没有搜索到该音乐")
参考:音乐检索-Shazam算法原理_哔哩哔哩_bilibili
相关文章:
Shazam音乐检索算法原理及实现
算法基本流程如下: 1. 采集音乐库 2. 音乐指纹采集 3. 采用局部最大值作为特征点 4. 将临近的特征点进行组合形成特征点对 5. 对每个特征点对进行hash编码 编码过程:将f1和f2进行10bit量化,其余bit用来存储时间偏移合集形成32bit的hash码 …...

vue递归组件
父组件: <template><div><treeVue :treeData"treeData"></treeVue></div> </template><script setup lang"ts"> import { reactive } from "vue"; import treeVue from "./tree.vue…...
软件测试/测试开发丨测试用例自动录入 学习笔记
点此获取更多相关资料 本文为霍格沃兹测试开发学社学员学习笔记分享 原文链接:https://ceshiren.com/t/topic/27139 测试用例自动录入 测试用例自动录入的价值 省略人工同步的步骤,节省时间 兼容代码版本的自动化测试用例 用例的执行与调度统一化管理…...

来学Python啦,大话字符串
To be a happy man, reading, travel, hard work, care for the body and mind。做一个幸福的人,读书,旅行,努力工作,关心身体和心境。 前面我们讲解过关于用Python写温度转换器&…...

pyqt5设置背景图片
PyQt5设置背景图片 1、打开QTDesigner 创建一个UI,camera.ui。 2、创建一个pictures.qrc文件 在ui文件同级目录下先创建一个pictures.txt,填写内容: <RCC><qresource prefix"media"><file>1.jpg</file>…...
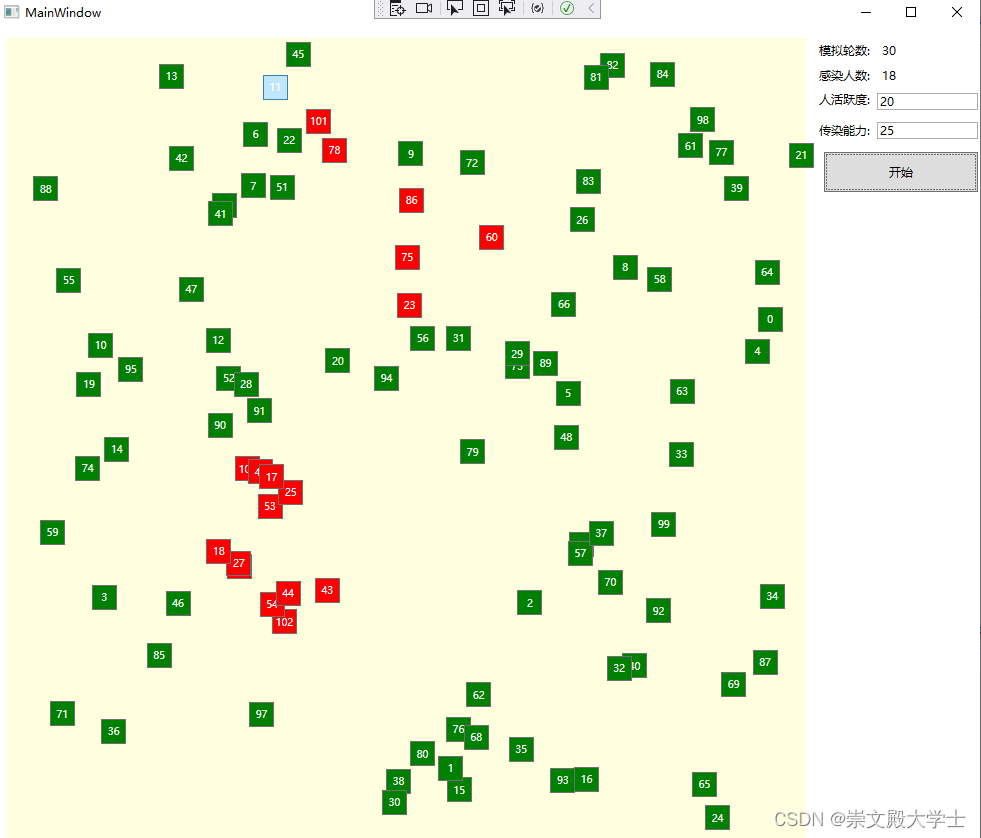
C# WPF 自己写的一个模拟病毒传播的程序,有可视化
源代码: https://github.com/t39q/VirusSpread 主要代码 using System; using System.Collections.Concurrent; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading; using System.Threading.Tasks;namespace VirusSpread.Bu…...

stable diffusion实践操作-大模型介绍-SDXL1大模型
系列文章目录 大家移步下面链接中,里面详细介绍了stable diffusion的原理,操作等(本文只是下面系列文章的一个写作模板)。 stable diffusion实践操作 提示:写完文章后,目录可以自动生成,如何生…...

软考高级系统架构设计师系列案例考点专题四:嵌入式系统
软考高级系统架构设计师系列案例考点专题四:嵌入式系统 一、相关概念二、软件可靠性和硬件可靠性的区别三、可靠性指标四、可靠性设计五、冗余技术六、软件容错七、双机容错技术八、集群技术九、负载均衡十、可维护性的评价指标十一、软件维护的分类嵌入式每年必考一题,但是属…...
Django Form实现表单使用及应用场景
首先需要定义一个使用场景: 音乐网站的前端部分可以添加上传歌手的单曲, 这个添加页面就使用django form表单来实现。 目录 数据表内容 歌手表及表模型 单曲表及表模型 演示表单使用 设置路由 创建form.py 视图实例化表单类 模板使用表单对象 表…...

golang面试题:json包变量不加tag会怎么样?
问题 json包里使用的时候,结构体里的变量不加tag能不能正常转成json里的字段? 怎么答 如果变量首字母小写,则为private。无论如何不能转,因为取不到反射信息。如果变量首字母大写,则为public。 不加tag,…...

国内项目管理中级证书CSPM-3正在报名!
CSPM-3中级项目管理专业人员认证,是中国标准化协会(全国项目管理标准化技术委员会秘书处),面向社会开展项目管理专业人员能力的等级证书。旨在构建多层次从业人员培养培训体系,建立健全人才职业能力评价和激励机制的要…...
vue表格不显示列号123456
我在网上找了半天,都是如何添加列号123456的,没有找到不显示列号的参考,现在把这个解决了,特此记录一下。 没有加右边的就会显示,加上右边的就隐藏了...
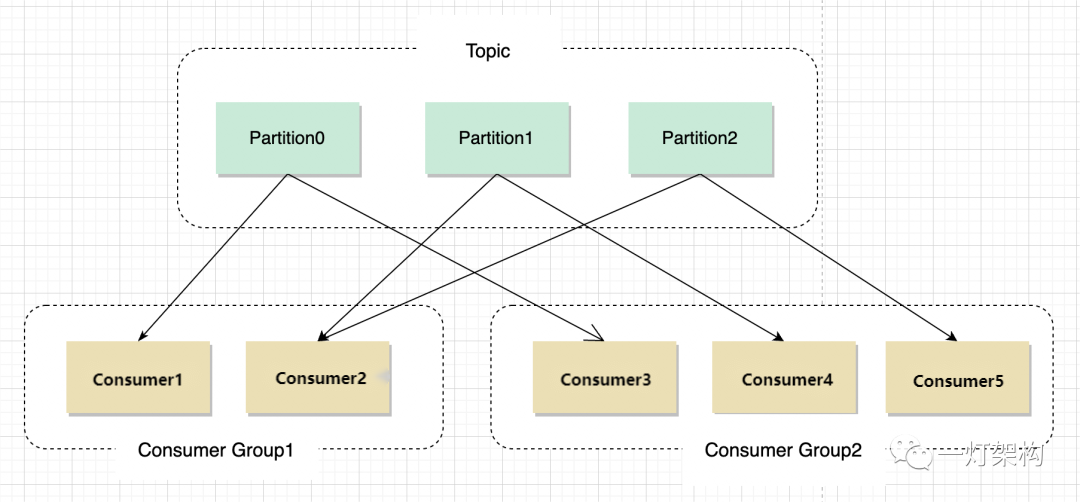
【大数据】Kafka 入门指南
Kafka 入门指南 1.Kafka 简介2.Kafka 架构3.分区与副本4.偏移量5.消费者组6.总结 1.Kafka 简介 Apache Kafka 是一种高吞吐、分布式的流处理平台,由 LinkedIn 开发并于 2011 年开源。它具有 高伸缩性、高可靠性 和 低延迟 等特点,因此在大型数据处理场景…...

Qt 5.15集成Crypto++ 8.8.0(MSVC 2019)笔记
一、背景 笔者已介绍过在Qt 5.15.x中使用MinGW(8.10版本)编译并集成Crypto 8.8.0。 但是该编译出来的库(.a和.dll)不适用MSVC(2019版本)构建环境,需要重新编译(.lib或和.dll…...
)
前端面试的话术集锦第 9 篇:高频考点(webpack性能优化)
这是记录前端面试的话术集锦第九篇博文——高频考点(webpack性能优化),我会不断更新该博文。❗❗❗ 在此章节中,我不会浪费篇幅给大家讲如何写配置文件。如果你想学习这方面的内容,那么完全可以去官网学习。在这部分的内容中,我们会聚焦于以下两个知识点,并且每一个知识…...

程序员,你真热爱编程吗?
程序员的热爱与演变 我发现,程序员这个行业不像其他行业那样,很多人是因为热爱编程才去做程序员,不会被逼无奈去做程序员(要是真有就太惨了)。 热爱编程的漫长过程 热爱过、⼜不爱了、⼜爱了,这是个过程…...

算法通关村-----海量数据的处理方法
从40亿中产生一个不存在的数 问题描述 给定一个文件,包含40亿个非负整数,请你设计一个算法,产生一个不在该文件中的数字。假设你只有1GB内存。 问题分析 40亿整数,在java中,用int存储的话,大概需要40亿✖️4B,大约…...

Pytorch 多卡并行(1)—— 原理简介和 DDP 并行实践
近年来,深度学习模型的规模越来越大,需要处理的数据也越来越多,单卡训练的显存空间和计算效率都越来越难以满足需求。因此,多卡并行训练成为了一个必要的解决方案本文主要介绍使用 Pytorch 的 DistributedDataParallel(…...

快速排序(重点)
前言 快排是一种比较重要的排序算法,他的思想有时候会作用到个别算法提上,公司招聘的笔试上有时候也有他的过程推导题,所以搞懂快排势在必行!!! 快速排序 基本思想: 根据基准,将数…...

python高级内置函数介绍及应用举例
目录 1. 概述2. 举例 1. 概述 Python中有许多高级内置函数,它们提供了丰富的功能和便利性,可以大大简化代码并提高效率。以下是一些常用的高级内置函数: map(): 用于将一个函数应用于一个可迭代对象的所有项,返回一…...
:实测TTS自然度MOS分≥4.2、API响应<380ms的4个隐秘优选)
AI配音演员平替革命(2024企业级落地白皮书):实测TTS自然度MOS分≥4.2、API响应<380ms的4个隐秘优选
更多请点击: https://intelliparadigm.com 第一章:AI配音演员平替革命的产业拐点与ElevenLabs替代必要性 过去两年,AI语音合成已从“可听”跃迁至“拟人化沉浸”,催生了影视本地化、有声书量产、短视频口播自动化等新赛道。但Ele…...

声音与视觉环境优化:提升工程师与知识工作者生产力的科学方法
1. 项目概述:声音与视觉如何重塑我们的生产力你有没有过这样的体验:在图书馆的绝对安静里,反而一个字也写不出来;但在咖啡馆那恰到好处的嘈杂声中,思绪却如泉涌?或者,当你戴上耳机,播…...

终极指南:免费解锁WeMod高级功能的完整方案
终极指南:免费解锁WeMod高级功能的完整方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod Pro的订阅费用而犹豫吗?…...

扣图操作方法完全指南:一键去背景,从小白到高手只需3步
每次看到朋友圈里别人的证件照、商品图、头像背景都换得很专业,你是不是也想试试?但一提到"扣图",很多人的第一反应就是打开Photoshop,结果被复杂的工具栏劝退了。其实,现在扣图已经不是什么高技术门槛的事儿…...

当计算机视觉模型开始“打架”:对抗性攻击与鲁棒性研究
摘要随着计算机视觉模型在安全敏感场景(如自动驾驶、人脸识别、安防监控)中的广泛应用,模型的脆弱性问题日益凸显。“打架”在这里并非字面意义的冲突,而是指对抗性攻击(Adversarial Attacks)与防御机制&am…...

Sveltos:多集群Kubernetes应用分发与配置管理的核心利器
1. 项目概述:Sveltos,一个被低估的集群应用管理利器如果你和我一样,长期在多集群的Kubernetes环境中摸爬滚打,那你一定对“应用分发”这件事的复杂性深有体会。想象一下,你手头有几十甚至上百个集群,有的在…...

三步轻松上手:BilldDesk Pro开源远程桌面控制工具完整指南
三步轻松上手:BilldDesk Pro开源远程桌面控制工具完整指南 【免费下载链接】billd-desk 基于Vue3 WebRTC Nodejs Flutter搭建的远程桌面控制、游戏串流 项目地址: https://gitcode.com/gh_mirrors/bi/billd-desk 如果你正在寻找一款功能强大且完全免费的跨…...

2026一氧化碳监测仪选型避坑指南:康高特等厂家深度对比评测
引言一氧化碳(CO),这种无色、无味、无刺激性的气体,因其与血红蛋白的极高亲和力,在工业生产、公共安全及环境监测领域构成了严峻的“隐形威胁”。随着全球工业化进程的加速和安全生产标准的日益提升,对一氧…...

3分钟掌握AMD Ryzen调试神器:SMUDebugTool终极使用指南
3分钟掌握AMD Ryzen调试神器:SMUDebugTool终极使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://g…...

基于NestJS的上下文管理:从AsyncLocalStorage到微服务架构实践
1. 项目概述:从“Nest Hub”到“contextzero/nest_hub”的深度解构最近在逛一些开发者社区和开源项目托管平台时,我注意到一个挺有意思的现象:一个名为“contextzero/nest_hub”的项目开始在一些技术讨论中被提及。乍一看标题,很多…...