【kafka】kafka单节点/集群搭建
概述
本章节将分享不同版本的kafka单节点模式和集群模式搭建。
在kafka2.8版本之前,需要依赖zookeeper服务,而在kafka2.8版本(包括)之后,可以不在依赖zookeeper服务。本章节将分kafka2.8版本之前的版本和之后的版本分别搭建单节点模式和集群模式。
服务器环境规划
实际的生产使用中,我们一般推荐搭建奇数多节点的kafka集群,如3/5/7。在本次测试中,我分别使用了1台和3台Centos7 三台服务器搭建,复用了我搭建之前k8s集群的环境,如下表。
| IP | hostname |
|---|---|
| 192.168.2.140 | k8s-m1 |
| 192.168.2.141 | k8s-m2 |
| 192.168.2.142 | k8s-m3 |
java环境搭建
参考https://blog.csdn.net/margu_168/article/details/132598962
2.8版本
安装包下载
直接在服务器用wget下载或者用迅雷下载好了上传也行。下载地址https://kafka.apache.org/downloads
[root@k8s-m1 ~]# wget https://archive.apache.org/dist/kafka/2.8.0/kafka_2.13-2.8.0.tgz
单节点模式
#解压
[root@k8s-m1 ~]# tar -xvf kafka_2.13-2.8.0.tgz
#进入解压后的目录
[root@k8s-m1 ~]# cd kafka_2.13-2.8.0/
#生成uuid
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-storage.sh random-uuid
MJufIDcZRMmG0-brb3nRhg
# 将uuid写入配置文件中,注意要使用上一步骤中生产的uuid
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-storage.sh format -t MJufIDcZRMmG0-brb3nRhg -c ./config/kraft/server.properties
Formatting /root/kraft-combined-logs
#启动命令
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-server-start.sh ./config/kraft/server.properties
#后台启动
./bin/kafka-server-start.sh ./config/kraft/server.properties &
或者
./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
测试使用
#创建topic
[root@k8s-m1 kafka_2.13-2.8.0]#./bin/kafka-topics.sh --create --topic testkafka --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092
Created topic testkafka.
#创建生产者
[root@k8s-m1 kafka_2.13-2.8.0]#./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testkafka
#创建消费者
[root@k8s-m1 kafka_2.13-2.8.0]#./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testkafka --from-beginning
#查看topic列表
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-topics.sh --list --bootstrap-server localhost:9092
testkafka
#查看topic状态
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-topics.sh --describe --bootstrap-server localhost:9092
Topic: testkafka TopicId: vtjXyJpVRIWPMkSgWm6uOA PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824Topic: testkafka Partition: 0 Leader: 1 Replicas: 1 Isr: 1
集群模式
规划的三个节点上都需要相应的安装包。
解压
[root@k8s-m1 ~]# tar -xvf kafka_2.13-2.8.0.tgz
修改配置,并生产uuid进行格式
进入解压后的conf/kraft目录,修改server.properties中的nodeid,注意每个节点上的nodeid不一样,我们分别规划为1/2/3。修改controller.quorum.voters为以下格式,注意我们规划的投票端口为9093。其他Broker进行通信,传递Topic的消息端口都设置为9092。如果服务器不够,将3个broker部署在一台服务器上,需要注意端口不能冲突。
[root@k8s-m1 ~]# cd kafka_2.13-2.8.0/conf/kraft
#修改k8s-m1
[root@k8s-m1 kafka_2.13-2.8.0]# vim config/kraft/server.properties
node.id=1
controller.quorum.voters=1@192.168.2.140:9093,2@192.168.2.141:9093,3@192.168.2.142:9093
listeners=PLAINTEXT://192.168.2.140:9092,CONTROLLER://192.168.2.140:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.2.140:9092
其次生成uuid,并使用生成的uuid格式化存储目录时使用的uuid(集群id)只需要一个。依次使用相同命令格式化另外两个节点。
#生成uuid
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-storage.sh random-uuid
HXJpfi94Q8avP4wkBVRdfw
# 将uuid写入配置文件中,注意要使用上一步骤中生产的uuid
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-storage.sh format -t HXJpfi94Q8avP4wkBVRdfw -c ./config/kraft/server.properties
Formatting /tmp/kraft-combined-logs#k8s-m2
[root@k8s-m2 kafka_2.13-2.8.0]# ./bin/kafka-storage.sh format -t HXJpfi94Q8avP4wkBVRdfw -c ./config/kraft/server.properties
Formatting /tmp/kraft-combined-logs#k8s-m3
[root@k8s-m2 kafka_2.13-2.8.0]# ./bin/kafka-storage.sh format -t HXJpfi94Q8avP4wkBVRdfw -c ./config/kraft/server.properties
Formatting /tmp/kraft-combined-logs
启动并进行检查
三台服务都使用以下命令在守护程序模式下启动kafka服务。同样的命令启动另外两条服务器上的kafka。
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
使用jps检查kafka是否启动
#k8s-m1
[root@k8s-m1 kafka_2.13-2.8.0]# jps
28206 Kafka
28415 Jps
#k8s-m2
[root@k8s-m2 kafka_2.13-2.8.0]# jps
20794 Kafka
3548 Jps
#k8s-m3
[root@k8s-m3 kafka_2.13-2.8.0]# jps
2034 Jps
21935 Kafka
测试使用
#创建topic
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-topics.sh --create --topic testkafka1 --partitions 3 --replication-factor 3 --bootstrap-server 192.168.2.140:9092,192.168.2.141:9092,192.168.2.142:9092
Created topic testkafka1.
#查看topic
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-topics.sh --describe --topic testkafka1 --bootstrap-server 192.168.2.140:9092Topic: testkafka1 TopicId: s_AFGUSfRHWb8FSQjdwaCw PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824Topic: testkafka1 Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1Topic: testkafka1 Partition: 1 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1Topic: testkafka1 Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
[root@k8s-m1 kafka_2.13-2.8.0]#
模拟producer
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-console-producer.sh --bootstrap-server 192.168.2.140:9092,192.168.2.141:9092,192.168.2.142:9092 --topic testkafka1
>hello
>kafka
>123
>abc
>
模拟consumer
[root@k8s-m1 kafka_2.13-2.8.0]# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.2.140:9092,192.168.2.141:9092,192.168.2.142:9092 --topic testkafka1 --from-beginning
hello
kafka
123
abc
2.2.1版本
在kafka2.8版本之前的版本,kakfa依赖zookeeper。此次测试使用kakfa 2.2.1版本。
安装包下载
直接在服务器用wget下载或者用迅雷下载好了上传也行。下载地址https://kafka.apache.org/downloads
[root@k8s-m1 ~]# wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
单节点模式
zookeeper服务启动
Kafka 使用 ZooKeeper 如果你还没有ZooKeeper服务器,你需要先启动一个ZooKeeper服务器。 可以通过与kafka打包在一起的便捷脚本来快速简单地创建一个单节点ZooKeeper实例,当然也可单独下载zookeeper的安装包进行安装。
[root@k8s-m1 opt]# tar -xvf /root/kafka_2.12-2.2.1.tgz -C /tmp/
[root@k8s-m1 tmp]# cd /tmp/kafka_2.12-2.2.1/
[root@k8s-m1 kafka_2.12-2.2.1]# ./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
[root@k8s-m1 kafka_2.12-2.2.1]# jps
1573 QuorumPeerMain
1638 Jps
kafka服务启动和检查
[root@k8s-m1 kafka_2.12-2.2.1]# ./bin/kafka-server-start.sh -daemon config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# jps
1573 QuorumPeerMain
4618 Kafka
4700 Jps
测试使用
#创建一个topic
[root@k8s-m1 kafka_2.12-2.2.1]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic test.
#查看topic列表
[root@k8s-m1 kafka_2.12-2.2.1]# ./bin/kafka-topics.sh --list --zookeeper localhost:2181
test
#查看topic详情
[root@k8s-m1 kafka_2.12-2.2.1]# ./bin/kafka-topics.sh --describe --zookeeper localhost:2181
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
#发送消息
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
>This is a message
>This is kafka #接收消息
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
This is a message
This is kafka
集群模式
zookeeper服务
为保证zookeeper的高可用,还是选择部署了3节点的zookeeper。
参考https://blog.csdn.net/margu_168/article/details/132598962,版本选择,可以通过查看解压后的kafka包中zookeeper的jar包。
[root@k8s-m1 libs]# ll /tmp/kafka_2.12-2.2.1/libs/zookeeper-3.4.13.jar
一般zookeeper后面的数字就代表可以使用的版本。
kafka集群部署
以下操作需要在3个节点都执行。注意在添加broker.id和advertised.listerners时每台服务器上的值不一样。
[root@k8s-m1 ~]# tar -xvf kafka_2.12-2.2.1.tgz -C /tmp/
[root@k8s-m1 ~]# mkdir /kafkalogs
[root@k8s-m1 ~]# sed -i '/^log.dirs=/d' /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 ~]# sed -i '/^broker.id/d' /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 ~]# sed -i '/^zookeeper.connect=/d' /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 ~]# sed -i '/^offsets.topic.replication.factor=1/d' /tmp/kafka_2.12-2.2.1/config/server.properties[root@k8s-m1 kafka_2.12-2.2.1]# echo -e "\nbroker.id=1" >> /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# echo -e "zookeeper.connect=192.168.2.140:2181,192.168.2.141:2181,192.168.2.142:2181" >> /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# echo -e "offsets.topic.replication.factor=3" >> /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# echo -e "advertised.listeners=PLAINTEXT://192.168.2.140:9092" >> /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# echo -e "log.dirs=/kafkalogs" >> /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# echo -e "auto.create.topics.enable=true" >> /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# echo -e "delete.topic.enable=true" >> /tmp/kafka_2.12-2.2.1/config/server.properties
#最后的效果如下,注意不同节点的区别
#k8s-m1
[root@k8s-m1 kafka_2.12-2.2.1]# vim config/server.properties
......
broker.id=1
zookeeper.connect=192.168.2.140:2181,192.168.2.141:2181,192.168.2.142:2181
offsets.topic.replication.factor=3
advertised.listeners=PLAINTEXT://192.168.2.140:9092
log.dirs=/kafkalogs
auto.create.topics.enable=true
delete.topic.enable=true#k8s-m2
[root@k8s-m2 ~]# vim /tmp/kafka_2.12-2.2.1/config/server.properties
......
broker.id=2
zookeeper.connect=192.168.2.140:2181,192.168.2.141:2181,192.168.2.142:2181
offsets.topic.replication.factor=3
advertised.listeners=PLAINTEXT://192.168.2.141:9092
log.dirs=/kafkalogs
auto.create.topics.enable=true
delete.topic.enable=true#k8s-m3
......
broker.id=3
zookeeper.connect=192.168.2.140:2181,192.168.2.141:2181,192.168.2.142:2181
offsets.topic.replication.factor=3
advertised.listeners=PLAINTEXT://192.168.2.142:9092
log.dirs=/kafkalogs
auto.create.topics.enable=true
delete.topic.enable=true
kafka服务启动和检查
三个节点依次启动kafka。检查结果中QuorumPeerMain为zookeeper的进程。一定要确保三个节点的进程都正常启动,如果不正常启动可以查看日志,目录为logs/server.log
[root@k8s-m1 kafka_2.12-2.2.1]# /tmp/kafka_2.12-2.2.1/bin/kafka-server-start.sh -daemon /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# jps
15633 Jps
22170 QuorumPeerMain
13979 Kafka
测试使用
主题创建
#创建一个3副本,2分区的topic
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic my-replicated-topic
Created topic my-replicated-topic.
#查看创建好的topic
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-topics.sh --list --zookeeper localhost:2181 --topic my-replicated-topic
my-replicated-topic
#查看某个topic的具体情况
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:2 ReplicationFactor:3 Configs:Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3Topic: my-replicated-topic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
以下是对输出信息的解释。第一行给出了所有分区的摘要,下面的每行都给出了一个分区的信息。因为我们有两个分区,所以有两行。
- “leader”是负责给定分区所有读写操作的节点。每个节点都是随机选择的部分分区的领导者。
- “replicas”是复制分区日志的节点列表,不管这些节点是leader还是仅仅活着。
- “isr”是一组“同步”replicas,是replicas列表的子集,它活着并被指到leader。
生产信息
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
>hello world
>hello kafka
>
消费信息
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
hello world
hello kafka
容错性测试
从上面的describe可以看到,对于my-replicated-topic这个topic的分区0,它的leader是broker1,可以先将其杀死进行测试。
[root@k8s-m1 kafka_2.12-2.2.1]# jps
15633 Jps
22170 QuorumPeerMain
13979 Kafka
[root@k8s-m1 kafka_2.12-2.2.1]# kill -9 13979#再次查看该topic
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:2 ReplicationFactor:3 Configs:Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,3 Isr: 2,3Topic: my-replicated-topic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 2,3
[root@k8s-m1 kafka_2.12-2.2.1]#
可以看到,对于my-replicated-topic这个topic的分区0,它的leader已经从broker1变成了broker2(Leader2)
不过,即便原先写入消息的leader已经不在,这些消息仍可用于消费,注意–bootstrap-server我们改成了的第二台服务器的IP,其实这个地方可以将3个IP地址全部写上。
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.2.141:9092 --from-beginning --topic my-replicated-topichello world
hello world
hello kafka
使用Kafka Connect来导入/导出数据
创建测试数据
#先进之前停掉的broker节点启动起来
[root@k8s-m1 kafka_2.12-2.2.1]# /tmp/kafka_2.12-2.2.1/bin/kafka-server-start.sh -daemon /tmp/kafka_2.12-2.2.1/config/server.properties
[root@k8s-m1 kafka_2.12-2.2.1]# echo -e "foo\nbar" > test.txt
[root@k8s-m1 kafka_2.12-2.2.1]# bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
这些包含在Kafka中的示例配置文件使用您之前启动的默认本地群集配置,并创建两个连接器: 第一个是源连接器,用于从输入文件读取行,并将其输入到 Kafka topic。 第二个是接收器连接器,它从Kafka topic中读取消息,并在输出文件中生成一行。
在启动过程中,你会看到一些日志消息,包括一些连接器正在实例化的指示。 一旦Kafka Connect进程启动,源连接器就开始从 test.txt 读取行并且 将它们生产到主题 connect-test 中,同时接收器连接器也开始从主题 connect-test 中读取消息, 并将它们写入文件 test.sink.txt 中。我们可以通过检查输出文件的内容来验证数据是否已通过整个pipeline进行交付。
#查看,注意路径
[root@k8s-m1 kafka_2.12-2.2.1]# more test.sink.txt
foo
bar
大家可以自行查看创建连接器过程中使用的配置文件,里面有定义各输入输出文件的名字。
注意,导入的数据存储在Kafka topic connect-test 中,因此我们也可以运行一个console consumer(控制台消费者)来查看 topic 中的数据(或使用custom consumer(自定义消费者)代码进行处理):
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
而如果没有将连接器断开,连接器将一直处理数据,所以我们可以将数据添加到文件中,并看到它在pipeline 中移动
[root@k8s-m1 kafka_2.12-2.2.1]# echo "hello world" >> test.txt
我们可以看到这一行出现在控制台用户输出和接收器文件中。
[root@k8s-m1 kafka_2.12-2.2.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
{"schema":{"type":"string","optional":false},"payload":"hello world"}
更多关于kafka的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出
相关文章:

【kafka】kafka单节点/集群搭建
概述 本章节将分享不同版本的kafka单节点模式和集群模式搭建。 在kafka2.8版本之前,需要依赖zookeeper服务,而在kafka2.8版本(包括)之后,可以不在依赖zookeeper服务。本章节将分kafka2.8版本之前的版本和之后的版本分…...

如何进行机器学习
进行机器学习主要包含以下步骤: 获取数据:首先需要获取用于学习的数据,数据的质量和数量都会影响机器学习的效果。如果自己的数据量较少,可以尝试在网上寻找公开数据集进行训练,然后使用自己的数据进行微调。另一种方…...

Vue项目使用axios配置请求拦截和响应拦截以及判断请求超时处理提示
哈喽大家好啊,最近做Vue项目看到axios axios官网:起步 | Axios 中文文档 | Axios 中文网 (axios-http.cn) 重要点: axios是基于Promise封装的 axios能拦截请求和响应 axios能自动转换成json数据 等等 安装: $ npm i…...
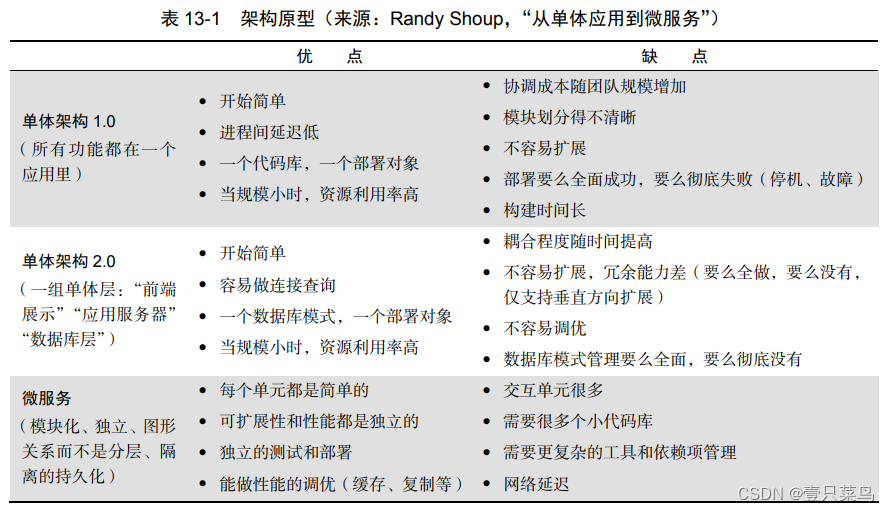
《DevOps实践指南》- 读书笔记(四)
DevOps实践指南 Part 3 第一步 :流动的技术实践11. 应用和实践持续集成11.1 小批量开发与大批量合并11.2 应用基于主干的开发实践11.3 小结 12. 自动化和低风险发布12.1 自动化部署流程12.1.1 应用自动化的自助式部署12.1.2 在部署流水线中集成代码部署 12.2 将部署…...
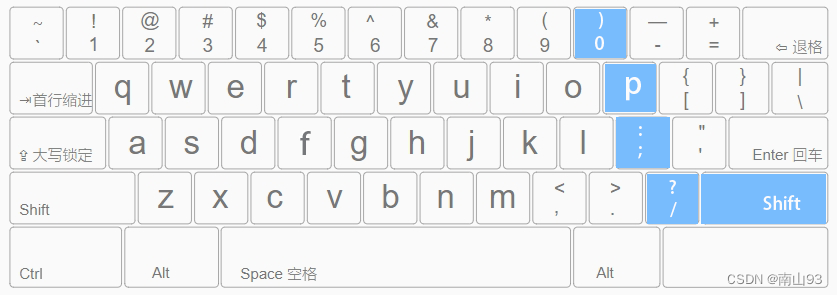
盲打键盘的正确指法指南
简介 很多打字初学者,并不了解打字的正确指法规范,很容易出现只用两根手指交替按压键盘的“二指禅”情况。虽然这样也能实现打字,但是效率极低。本文将简单介绍盲打键盘的正确指法,以便大家在后续的学习和工作中能够提高工作效率…...
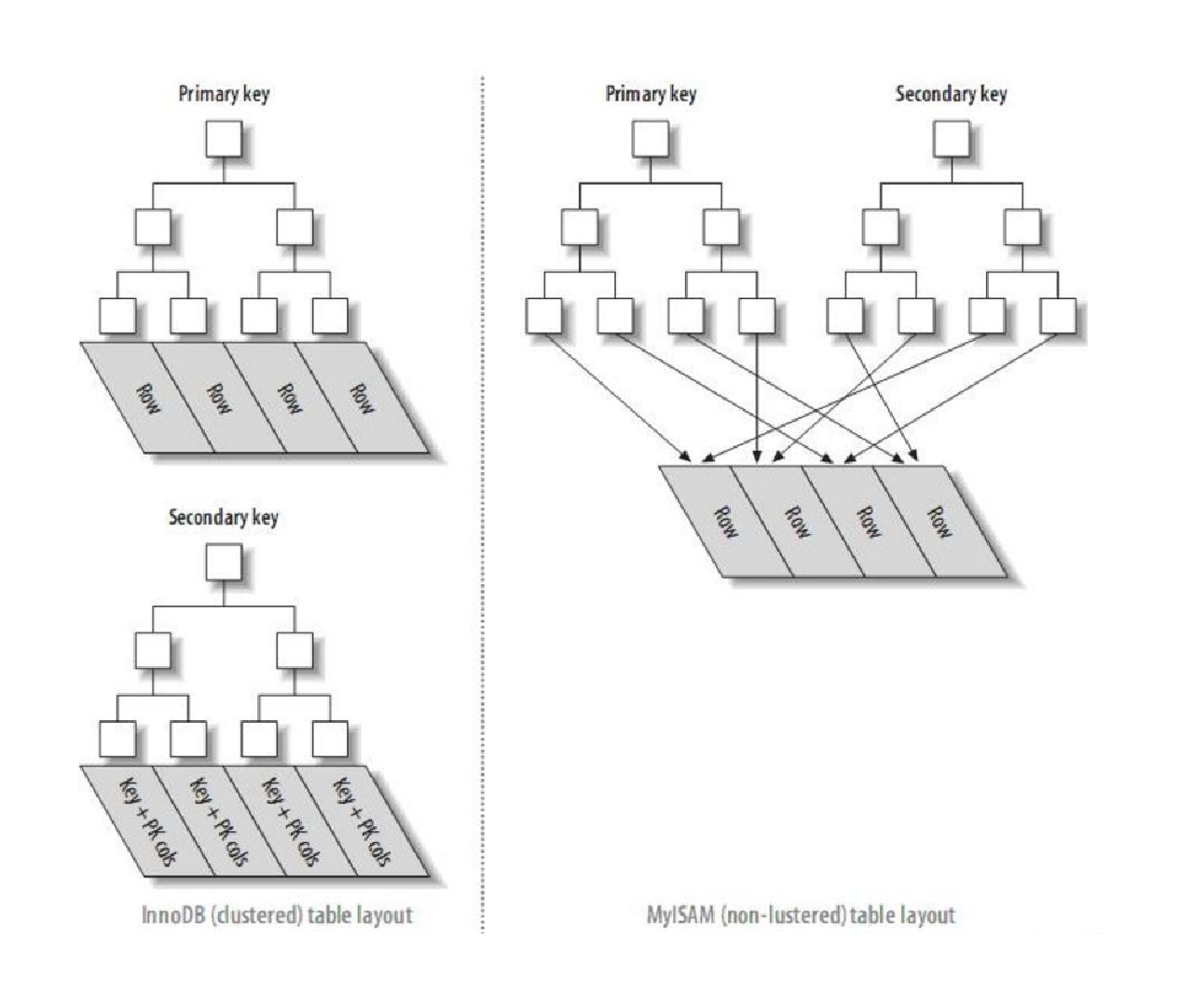
【MySQL】索引 详解
索引 详解 一. 概念二. 作用三. 使用场景四. 操作五. 索引背后的数据结构B-树B树聚簇索引与非聚簇索引 一. 概念 索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各…...

怎么通过ip地址连接共享打印机
在现代办公环境中,共享打印机已成为一种常见的需求。通过共享打印机,多个用户可以在网络上共享同一台打印机,从而提高工作效率并减少设备成本。下面虎观代理小二二将介绍如何通过IP地址连接共享打印机。 确定打印机的IP地址 首先࿰…...
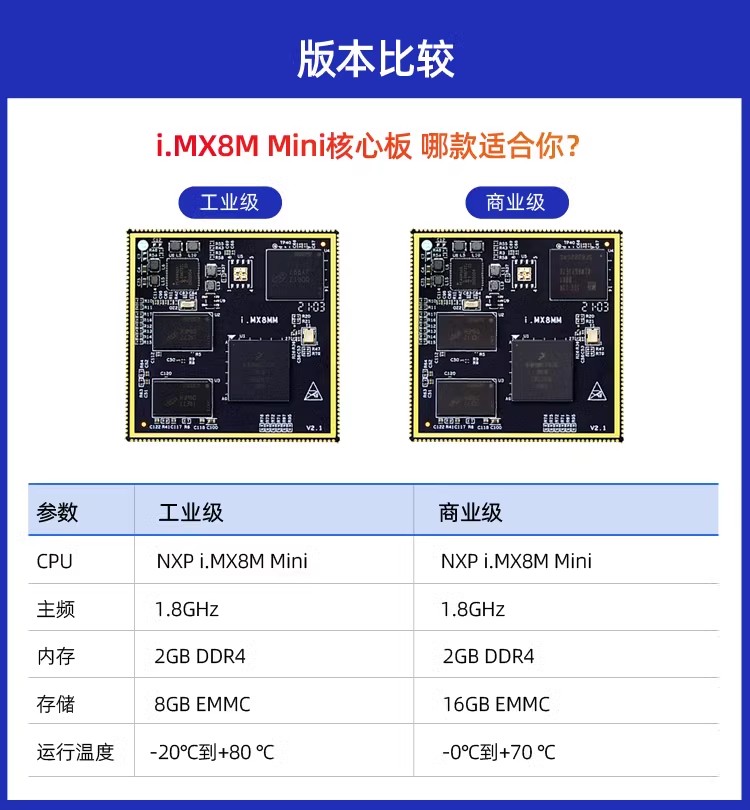
迅为i.MX8mm小尺寸商业级/工业级核心板
尺寸: 50mm*50mm CPU: NXP i.MX8M Mini 主频: 1.8GHz 架构: 四核Cortex-A53,单核Cortex-M4 PMIC: PCA9450A电源管理PCA9450A电源管理NXP全新研制配,iMX8M的电源管理芯片有六个降压稳压器、五…...
vue中v-for循环数组使用方法中splice删除数组元素(错误:每次都删掉点击的下面的一项)
总结:平常使用v-for的key都是使用index,这里vue官方文档也不推荐,这个时候就出问题了,我们需要key为唯一标识,这里我使用了时间戳(new Date().getTime())处理比较复杂的情况, 本文章…...

Python用GAN生成对抗性神经网络判别模型拟合多维数组、分类识别手写数字图像可视化...
全文链接:https://tecdat.cn/?p33566 生成对抗网络(GAN)是一种神经网络,可以生成类似于人类产生的材料,如图像、音乐、语音或文本(点击文末“阅读原文”获取完整代码数据)。 相关视频 最近我们…...

嵌入式Linux驱动开发(LCD屏幕专题)(一)
一、LCD简介 总的分辨率是 yres*xres。 1.1、像素颜色的表示 以下三种方式表示颜色 1.2、如何将颜色数据发送给屏幕 每个屏幕都有一个内存(framebuffer)如下图,内存中每块数据对用屏幕上的一个像素点,设置好LCD后ÿ…...

uniapp搜索功能
假设下方数据是我们从接口中获取到的,我们需要通过name来搜索,好我们看下一步。 data: [{"id": 30,"category_id": 3,"name": "日常家居名称","goods_num": 20,"integral_num": 20,&q…...

iframe 实现跨域,两页面之间的通信
一、 背景 一个项目为vue2,一个项目为vue3,两个不同的项目实现iframe嵌入,并实现通信 二、方案 iframe跨域时,iframe组件之间常用的通信,主要是H5的possmessage方法 三、案例代码 父页面-vue2(端口号为…...
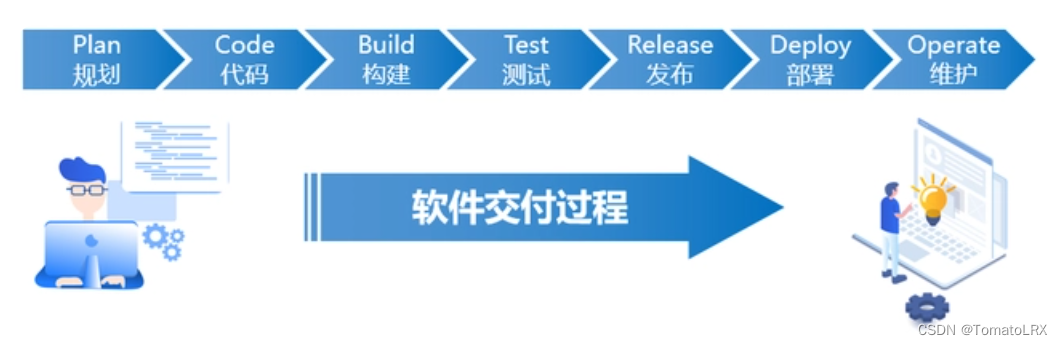
DevOps到底是什么意思?
前言: 当我们谈到 DevOps 时,可能讨论的是:流程和管理,运维和自动化,架构和服务,以及文化和组织等等概念。那么,到底什么是"DevOps"呢? 那么,DevOps是什么呢? 有人说它是一种方法,也有人说它是一种工具,还有人说它是一种思想。更有甚者,说它是一种哲学…...
03JVM_类加载
一、类加载与字节码技术 1.类文件结构 2.字节码指令 3.编译期处理 4.类加载阶段 5.类加载器 6.运行期优化 1.类文件结构 类文件结构 1.1 魔数magic 介绍 每个java class文件的前4个字节是魔数:0x CAFEBABE。魔数作用在于分辨出java class文件和非java clas…...
)
Mysql如何对null进行排序(mysql中null排序)
来源:Mysql如何对null进行排序(mysql中null排序) Mysql如何对null进行排序 Mysql是一种开源的关系型数据库管理系统,经常被用于Web开发和应用程序中。在使用Mysql进行数据处理的过程中,很多时候都会遇到需要对null进行…...
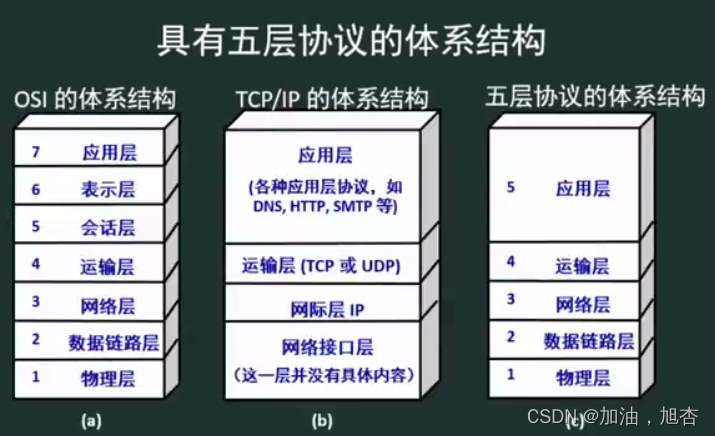
【基础计算机网络1】认识计算机网络体系结构,了解计算机网络的大致模型(下)
前言 在上一篇我们主要介绍了有关计算机网络概述的内容,下面这一篇我们将来介绍有关计算机网络体系结构与参考模型的内容。这一篇博客紧紧联系上一篇博客。 这一篇博客主要内容是:计算机网络体系结构与参考模型,主要是计算机网络分层结构、协…...

vscode 画流程图
文章目录 1、安装插件 draw2、新建文件3、开始画图4、另存为图片 vscode可以画流程图了,只需要安装插件就可以了。 1、安装插件 draw 2、新建文件 3、开始画图 4、另存为图片...

uniapp-一些实用的api接口
唤起导航 调用后可以跳转到地图页 uni.openLocation({latitude: res.data.data.latitude, //到达的纬度longitude: res.data.data.longitude, //到达的经度name: res.data.data.address, // 到达的名字scale: 12, // 缩放倍数success() { // 成功回调console.log(success) }…...
合宙Air724UG LuatOS-Air LVGL API控件-表格(Table)
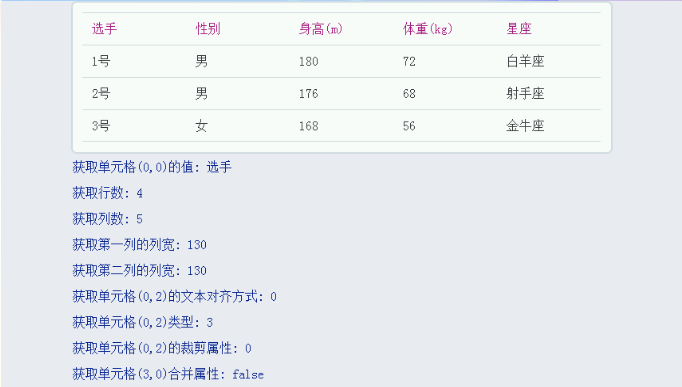
表格(Table) 示例代码 --创建表格Table1 lvgl.table_create(lvgl.scr_act(),nil)--设置表格为4行5列lvgl.table_set_row_cnt(Table1,4)lvgl.table_set_col_cnt(Table1,5)--给每个单元格赋值lvgl.table_set_cell_value(Table1, 0, 0, "选手")l…...

FPGA/CPLD项目隐性成本分析与设计陷阱规避实战指南
1. 项目概述:从一则电视购物广告引发的工程思考最近整理旧资料,翻到一篇十多年前EE Times上的老博客,作者Clive Maxfield聊了个挺有意思的事儿。他吐槽电视购物广告里那句经典的“只需支付单独的处理与手续费”,并敏锐地注意到&am…...

深度解析20辆电动汽车29个月真实充电数据:电池容量衰减评估与健康监测关键技术
深度解析20辆电动汽车29个月真实充电数据:电池容量衰减评估与健康监测关键技术 【免费下载链接】battery-charging-data-of-on-road-electric-vehicles This repository is transfered from the personal account of Dr. Zhognwei Deng (Michael Teng) 项目地址: …...

MATLAB程序打包成exe后,发给没有MATLAB的同事/客户怎么用?完整部署指南
MATLAB程序打包成EXE后的完整部署指南:让无MATLAB环境的用户也能顺畅运行 当你花费数周时间在MATLAB中打磨出一个完美的算法工具,最终通过mcc命令将其打包成.exe文件时,那种成就感无与伦比。但现实往往给你当头一棒——同事或客户双击这个exe…...

Java反编译终极指南:JD-GUI从入门到精通完整教程
Java反编译终极指南:JD-GUI从入门到精通完整教程 【免费下载链接】jd-gui A standalone Java Decompiler GUI 项目地址: https://gitcode.com/gh_mirrors/jd/jd-gui Java反编译是每个Java开发者必备的核心技能,而JD-GUI正是这一领域的终极利器。作…...

CentOS 8系统下EMQX 4.3.8安装避坑实录:解决crypto和libncurses依赖报错
CentOS 8系统下EMQX 4.3.8深度部署指南:从依赖解析到高可用架构 在物联网和边缘计算领域,MQTT协议凭借其轻量级和高效性已成为设备通信的事实标准。而EMQX作为基于Erlang/OTP平台开发的开源MQTT消息服务器,其单节点支持200万连接的能力使其成…...

构建AI信任层TrustLayer:开源插件化架构保障AI输出安全与可靠
1. 项目概述:为什么我们需要一个AI信任层?最近几个月,我几乎把所有主流的AI工具都试了个遍。从代码助手到文案生成,从图像创作到数据分析,每个工具都承诺能提升效率。但用着用着,我发现一个越来越明显的问题…...

2026年最值得投入的5款AI Agent工具:Gartner认证+生产环境压测数据全公开
更多请点击: https://intelliparadigm.com 第一章:2026年最佳AI Agent工具推荐 2026年,AI Agent 已从概念原型迈入企业级生产部署阶段。开发者不再满足于单任务自动化,而是追求具备长期记忆、跨平台协调与自主目标分解能力的智能…...

5分钟完全指南:roop-unleashed AI换脸神器从入门到精通
5分钟完全指南:roop-unleashed AI换脸神器从入门到精通 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要在几分钟内制作专业级的AI换脸视频吗…...

终极指南:如何用React JSON Schema Form快速构建专业表单设计语言
终极指南:如何用React JSON Schema Form快速构建专业表单设计语言 【免费下载链接】react-jsonschema-form A React component for building Web forms from JSON Schema. 项目地址: https://gitcode.com/gh_mirrors/re/react-jsonschema-form React JSON Sc…...

2026届学术党必备的五大AI科研神器实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 降 AI 指令,是一种合规优化工具,用于调试 AI 生成逻辑,以…...