一种高效且节约内存的聚合数据结构的实现
一种高效且节约内存的聚合数据结构的实现
在特定的场景中,特殊定制数据结构能够得到更加好的性能且更节约内存。
聚合函数GroupArray的问题
GroupArray聚合函数是将分组内容组成一个个数组,例如下面的例子:
SELECT groupArray(concat('ABC-', toString(number))) from numbers(20) group by number % 5;
------------------------------------------------------
Output:
------------------------------------------------------
['ABC-0','ABC-5','ABC-10','ABC-15']
['ABC-1','ABC-6','ABC-11','ABC-16']
['ABC-2','ABC-7','ABC-12','ABC-17']
['ABC-3','ABC-8','ABC-13','ABC-18']
['ABC-4','ABC-9','ABC-14','ABC-19']
原始的实现中使用顺序表存放每个字符串,每个字符串由size和data两部分组成,如以下简化代码所示:
// 内存排布:
// [8 字节]size, [不定字节数]data...
// 例如字符串"ABC"的表示如下:
// 0x0000000000000003, 'A', 'B', 'C'
struct StringNode
{size_t size;// 实例尾部存放实际数据。
};
using AggregateData = PODArray<StringNode*>
在聚合过程中,不断创建StringNode实例并将其指针放入表示聚合数据的AggregateData实例中。这个实现方法会存在几个问题:
- 在聚合过程中,由
AggregateData表示的聚合数据不断增长,会引发多次因PODArray的内存空间不够而引发的重新申请内存的动作,还会附加复制数据到新内存空间操作的消耗。 - PODArray的初始大小也很难确定:初始大小如果过大,浪费空间;初始大小如果过小,重新申请新的内存空间后,原先的初始的内存就浪费了,且新的内存空间可能又过大了。举个例子,如果
AggregateData初始大小是32字节,实际聚合数据有48字节,需要重新分配内存空间,重新分配的内存是64字节,这样浪费的内存是:原来的32字节+新空间装完48字节的数据之后空余的16字节,总共浪费了48个字节。 StringNode的size字段并不需要8个字节,因为我们知道在我们的实际使用场景中,字符串最大不会超过65535,用2个字节表示长度就够了,浪费了6个字节。
用链表替代顺序表的解决方案
用链表替代顺序表,似乎第一感觉是不可行的,因为两个根深蒂固(可能来自于教科书)的观点:
- 链表的内存分散,局部性不好;
- 链表每新增一个节点都需要分配内存,内存分配动作过多影响效率;
- 链表访问较慢,需要通过next指针找下一个。
在使用Arena的内存分配器和当前GroupArray的聚合数据结构的前提条件,以上两个观点都不是绝对正确的。
先说第一个问题,在一般内存分配器中,可能每次分配的内存都是不连续的,这是链表的内存分散的原因。但是Arena内存分配器在不切换内存块的前提下分配的内存是连续的。每个聚合线程有独立的Arena内存分配器。因此这种情况下链表的内存是基本连续的,保证了相对的局部性。
第二个问题也是跟Arena内存分配器相关。Arena内存分配器是一次调用系统接口(jemalloc或者mmap或者其他)分配一大块内存,然后每次调用Arena内存分配器分配内存时只要返回当前指向内存块中空余内存的指针的值,然后更新这个指针的值使其指向剩下的空余内存的开头即可。这是一个非常轻量的函数调用而且极有可能被内联了。
第三个问题,聚合数据是StringNode的指针的数组,虽然PODArray是顺序表但是每次访问也是要通过指针才能访问到StringNode实例的,这样跟链表中通过next指针访问的代价是一样的。但我们此时能够直接访问真实数据了,不需要再次通过链表节点的指针去访问真实数据,这样指针取值操作的次数是不变的。
综上所述,链表替代顺序表在这个特定场景下是更好的方案。
节约6个字节
原先的size_t size需要8个字节,但实际两个字节就够了。虽然只是6个字节,但是在数据的行数很大的情况下总共节约下来的内存是很客观的。例如对于十亿条数据,就会节约8GiB左右(8 x 10亿)的内存。
实现方式如下:
struct StringNode
{UInt16 size;char data[6];
}// string_size是字符串的实际大小。sizeof(StringNode::data)等于6。
arena.alignedAlloc(std::max(sizeof(Node), sizeof(Node) - sizeof(StringNode::data) + string_size), alignof(Node));
通过把size改成UInt16并加入一个6个字节的data字段,省出6个字节出来。
根据需要定义count字段
教科书上的链表不需要count字段,因为可以通过遍历next指针获得。但是实际上我们可能需要快速获取一个链表的节点个数,但也有可能不需要。
通过模板参数,来控制是否需要count字段。在不需要获取节点数量(例如本例中的GroupArray聚合函数)的场景下,就可以省下count字段的8个字节。积少成多。
struct EmptyState{};template <bool is_empty, typename T>
using TypeOrEmpty = std::conditional_t<is_empty, EmptyState, T>;template <...,bool require_count,...>
struct ...
{... ...[[no_unique_address]] TypeOrEmpty<!require_count, UInt64> node_count {};... ...
};当模板参数require_count等于false的时候, node_count不占空间。
具体实现
代码结构
实现由以下几个模板类组成:
- struct ArenaLinkedNodeList
表示整一个链表数据结构。 - concept UnfixedSized
判定数据类型是否为变长的,规定凡是有char * data和size_t size的就是变长数据类型。 - struct ArenaMemoryNodeBase
表示链表中的一个节点的数据结构基类。派生类使用CRTP模式继承此基类。 - struct ArenaMemoryUnfixedSizedNode
表示变长数据的链表节点,通常是字符串、数组。 - struct ArenaMemoryFixedSizedNode
表示固定长度数据的链表节点,通常是数值、日期。
具体代码
以下是具体代码。
struct EmptyState { }; // 表示空类型。template <bool use_type, typename T>
using MaybeEmptyState = std::conditional_t<use_type, T, EmptyState>; // 可能是空类型,也可能是T,由use_type控制。template <typename T>
concept UnfixedSized = requires(T v)
{{v.size} -> std::convertible_to<size_t>;{v.data} -> std::convertible_to<const char *>;
};template <typename T>
concept FixedSized = !UnfixedSized<T>;template <typename Derived, typename ValueType>
struct ArenaMemoryNodeBase
{Derived * next;Derived * asDerived(){return static_cast<Derived*>(this);}const Derived * asDerived() const{return static_cast<const Derived*>(this);}template <bool is_plain_column>ALWAYS_INLINE static Derived * allocate(const IColumn & column, size_t row_num, Arena & arena){return Derived::allocate(Derived::template getValueFromColumn<is_plain_column>(column, row_num, arena), arena);}ALWAYS_INLINE Derived * clone(Arena & arena) const{size_t copy_size = Derived::realMemorySizeOfNode(static_cast<const Derived &>(*this));Derived * new_node = reinterpret_cast<Derived*>(arena.alignedAlloc(copy_size, alignof(Derived)));memcpy(new_node, this, copy_size);new_node->next = nullptr;return new_node;}ALWAYS_INLINE ValueType value() const{return Derived::getValueFromNode(static_cast<const Derived&>(*this));}ALWAYS_INLINE void serialize(WriteBuffer & buf) const{writeBinary(value(), buf);}
};template <UnfixedSized ValueType>
struct ArenaMemoryUnfixedSizedNode : ArenaMemoryNodeBase<ArenaMemoryUnfixedSizedNode<ValueType>, ValueType>
{using Derived = ArenaMemoryUnfixedSizedNode<ValueType>;static constexpr UInt16 unfixed_sized_len_limit = -1;UInt16 size;char data[6];template <bool is_plain_column>ALWAYS_INLINE static ValueType getValueFromColumn(const IColumn & column, size_t row_num, Arena & arena){if (is_plain_column){const char * begin{};auto serialized = column.serializeValueIntoArena(row_num, arena, begin);return allocate(arena, {serialized.data, serialized.size});}else{return allocate(arena, column.getDataAt(row_num));}}ALWAYS_INLINE static ValueType getValueFromNode(const Derived & node){return {node.data, node.size};}ALWAYS_INLINE static Derived * allocate(ValueType value, Arena & arena){if (value.size > unfixed_sized_len_limit){throw Exception();}Derived * node = reinterpret_cast<Derived*>(arena.alignedAlloc(Derived::realUnfixedSizedDataMemorySizeForPayload(value.size), alignof(Derived)));node->next = nullptr;node->size = value.size;memcpy(node->data, value.data, value.size);return node;}ALWAYS_INLINE static size_t realMemorySizeOfNode(const Derived & node){return realUnfixedSizedDataMemorySizeForPayload(node.size);}ALWAYS_INLINE static size_t realUnfixedSizedDataMemorySizeForPayload(size_t payload_size){return std::max(sizeof(Derived), sizeof(Derived) + payload_size - sizeof(Derived::data));}ALWAYS_INLINE static Derived * deserialize(ReadBuffer & buf, Arena & arena){// Treat all unfixed sized data as String and StringRef.String data;readBinary(data, buf);return allocate(arena, StringRef(data));}};template <FixedSized ValueType>
struct ArenaMemoryFixedSizedNode : ArenaMemoryNodeBase<ArenaMemoryFixedSizedNode<ValueType>, ValueType>
{using Derived = ArenaMemoryFixedSizedNode<ValueType>;ValueType data;template <bool is_plain_column>ALWAYS_INLINE static ValueType getValueFromColumn(const IColumn & column, size_t row_num, Arena & arena){static_assert(!is_plain_column);return allocate(arena, assert_cast<const ColumnVector<ValueType>&>(column).getData()[row_num]);}ALWAYS_INLINE static ValueType getValueFromNode(const Derived & node){return node.data;}ALWAYS_INLINE static Derived * allocate(ValueType value, Arena & arena){Derived * node = reinterpret_cast<Derived*>(arena.alignedAlloc(sizeof(Derived), alignof(Derived)));node->next = nullptr;node->data = value;return node;}ALWAYS_INLINE size_t realMemorySizeOfNode() const{return sizeof(Derived);}ALWAYS_INLINE static Derived * deserialize(ReadBuffer & buf, Arena & arena){Derived * new_node = reinterpret_cast<Derived*>(arena.alignedAlloc(sizeof(Derived), alignof(Derived)));new_node->next = nullptr;readBinary(new_node->data, buf);return new_node;}
};template <typename ValueType, bool has_count_field = false>
struct ArenaLinkedList
{template <typename T>struct NodeTraits{using NodeType = ArenaMemoryFixedSizedNode<T>;};template <UnfixedSized T>struct NodeTraits<T>{using NodeType = ArenaMemoryUnfixedSizedNode<T>;};using Node = typename NodeTraits<ValueType>::NodeType;Node * head{};Node * tail{};[[no_unique_address]] std::conditional_t<has_count_field, size_t, EmptyState> count{};struct Iterator{using iterator_category = std::forward_iterator_tag;using difference_type = std::ptrdiff_t;using value_type = ValueType;using pointer = value_type *;using reference = value_type &;value_type operator * (){return p->value();}Iterator & operator ++ (){p = p->next;return *this;}Iterator operator ++ (int){auto retvalue = *this;++(*this);return retvalue;}friend bool operator == (const Iterator & left, const Iterator & right) = default;friend bool operator != (const Iterator & left, const Iterator & right) = default;Node * p{};};Iterator begin() const { return {head}; }Iterator end() const { return {nullptr}; }template <bool is_plain_column>ALWAYS_INLINE void add(const IColumn & column, size_t row_num, Arena & arena){Node * new_node = Node::template allocate<is_plain_column>(arena, column, row_num);add(new_node);}ALWAYS_INLINE void add(ValueType value, Arena & arena){Node * new_node = Node::allocate(value, arena);add(new_node);}ALWAYS_INLINE void add(Node * new_node){new_node->next = nullptr;if (head == nullptr) [[unlikely]]{head = new_node;}if (tail != nullptr) [[likely]]{tail->next = new_node;}tail = new_node;if constexpr (has_count_field){++ count;}}ALWAYS_INLINE size_t size() const{if constexpr (has_count_field){return count;}else{return std::distance(begin(), end());}}ALWAYS_INLINE bool empty() const{return begin() == end();}void merge(const ArenaLinkedList & rhs, Arena & arena){auto rhs_iter = rhs.head;while (rhs_iter){auto new_node = rhs_iter->clone(arena);add(new_node);rhs_iter = rhs_iter->next;}}void mergeLink(const ArenaLinkedList & rhs, Arena &){if (!head) [[unlikely]]{head = rhs.head;}if (tail) [[likely]]{tail->next = rhs.head;}if (rhs.tail) [[likely]]{tail = rhs.tail;}if constexpr (has_count_field){count += rhs.count;}}
};测试
测试代码是基于gtest写的。
#include <ArenaLinkedNodeList.h>#include <gtest/gtest.h>TEST(ArenaLinkedList, StringList)
{Arena arena;ArenaLinkedList<StringRef> list;String s1{"Activity1"}, s2{"Activity2"}, s3{"ActivityActivity3"};list.add(StringRef(s1), arena);list.add(StringRef(s2), arena);list.add(StringRef(s3), arena);ASSERT_EQ(list.size(), 3);auto iter = list.begin();ASSERT_EQ(*iter, s1);++iter;ASSERT_EQ(*iter, s2);++iter;ASSERT_EQ(*iter, s3);
}TEST(ArenaLinkedList, NumberList)
{Arena arena;ArenaLinkedList<Int64, true> list;std::array<Int64, 10> expected {1, 4, 2, 1024, 10231024, 102310241025, 888, 99999999, -102310241025, -99999999};for (auto x : expected)list.add(x, arena);ASSERT_EQ(list.size(), 10);auto iter = list.begin();for (size_t i = 0; i < expected.size(); ++i, ++iter)ASSERT_EQ(*iter, expected[i]);
}TEST(ArenaLinkedList, MergeList)
{Arena arena;ArenaLinkedList<StringRef> list1, list2;String s1{"Activity1"}, s2{"Activity2"}, s3{"ActivityActivity3"}, s4{"ABCDEFGHIJKLMN"};Strings expected{s1, s2, s3, s4};list1.add(StringRef(s1), arena);list1.add(StringRef(s2), arena);list1.add(StringRef(s3), arena);list2.add(StringRef(s4), arena);list1.merge(list2, arena);auto iter = list1.begin();ASSERT_EQ(list1.size(), expected.size());for (auto x : expected){ASSERT_EQ(*iter, x);++iter;}
}TEST(ArenaLinkedList, MergeEmptyList)
{Arena arena;ArenaLinkedList<StringRef> list1, list2;String s1{"Activity1"}, s2{"Activity2"}, s3{"ActivityActivity3"};Strings expected{s1, s2, s3};list1.add(StringRef(s1), arena);list1.add(StringRef(s2), arena);list1.add(StringRef(s3), arena);// list2 is an empty list.list1.merge(list2, arena);auto iter = list1.begin();ASSERT_EQ(list1.size(), expected.size());for (auto x : expected){ASSERT_EQ(*iter, x);++iter;}
}TEST(ArenaLinkedList, MergeLinkEmptyList)
{Arena arena;ArenaLinkedList<StringRef> list1, list2;String s1{"Activity1"}, s2{"Activity2"}, s3{"ActivityActivity3"};Strings expected{s1, s2, s3};list1.add(StringRef(s1), arena);list1.add(StringRef(s2), arena);list1.add(StringRef(s3), arena);// list2 is an empty list.list1.mergeLink(list2, arena);auto iter = list1.begin();ASSERT_EQ(list1.size(), expected.size());for (auto x : expected){ASSERT_EQ(*iter, x);++iter;}
}TEST(ArenaLinkedList, MergeLinkEmptyListAndAddNew)
{Arena arena;ArenaLinkedList<StringRef> list1, list2;String s1{"Activity1"}, s2{"Activity2"}, s3{"ActivityActivity3"}, s4{"ABCDEFGHIJKLMN"}, s5{"abcdefg"};Strings expected{s1, s2, s3, s4, s5};list1.add(StringRef(s1), arena);list1.add(StringRef(s2), arena);list1.add(StringRef(s3), arena);// list2 is an empty list.list1.mergeLink(list2, arena);list1.add(StringRef(s4), arena);list1.add(s5, arena);auto iter = list1.begin();ASSERT_EQ(list1.size(), expected.size());for (auto x : expected){ASSERT_EQ(*iter, x);++iter;}
}测试全部通过。
相关文章:

一种高效且节约内存的聚合数据结构的实现
一种高效且节约内存的聚合数据结构的实现 在特定的场景中,特殊定制数据结构能够得到更加好的性能且更节约内存。 聚合函数GroupArray的问题 GroupArray聚合函数是将分组内容组成一个个数组,例如下面的例子: SELECT groupArray(concat(ABC…...

机器学习(10)---特征选择
文章目录 一、概述二、Filter过滤法2.1 过滤法说明2.2 方差过滤2.3 方差过滤对模型影响 三、相关性过滤3.1 卡方过滤3.2 F检验3.3 互信息法3.4 过滤法总结 四、Embedded嵌入法4.1 嵌入法说明4.2 以随机森林为例的嵌入法 五、Wrapper包装法5.1 包装法说明5.2 以随机森林为例的包…...

Python之数据库(MYSQL)连接
一)数据库SQL语言基础 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database…...
【建站教程】使用阿里云服务器怎么搭建网站?
使用阿里云服务器快速搭建网站教程,先为云服务器安装宝塔面板,然后在宝塔面板上新建站点,阿里云服务器网以搭建WordPress网站博客为例,阿小云来详细说下从阿里云服务器CPU内存配置选择、Web环境、域名解析到网站上线全流程&#x…...

【自然语言处理】关系抽取 —— MPDD 讲解
MPDD 论文信息 标题:MPDD: A Multi-Party Dialogue Dataset for Analysis of Emotions and Interpersonal Relationships 作者:Yi-Ting Chen, Hen-Hsen Huang, Hsin-Hsi Chen 期刊:LREC 2020 发布时间与更新时间:2020 主题:自然语言处理、关系抽取、对话场景、情感预测 数…...

深入理解JVM虚拟机第三篇:JVM的指令集架构模型和JVM的生命周期
文章目录 一:JVM的指令集架构模型 1:基于栈式架构的特点...

[小尾巴 UI 组件库] 组件库配置与使用
文章归档于:https://www.yuque.com/u27599042/row3c6 组件库地址 npm:https://www.npmjs.com/package/xwb-ui?activeTabreadme小尾巴 UI 组件库源码 gitee:https://gitee.com/tongchaowei/xwb-ui小尾巴 UI 组件库测试代码 gitee:…...
函数的理解)
Linux系统中fork()函数的理解
fork() 函数是一个在Unix和类Unix操作系统中常见的系统调用,用于创建一个新的进程,该进程是调用进程(父进程)的副本。fork() 函数的工作原理如下: 1. 当父进程调用 fork() 时,操作系统会创建一个新的进程&a…...
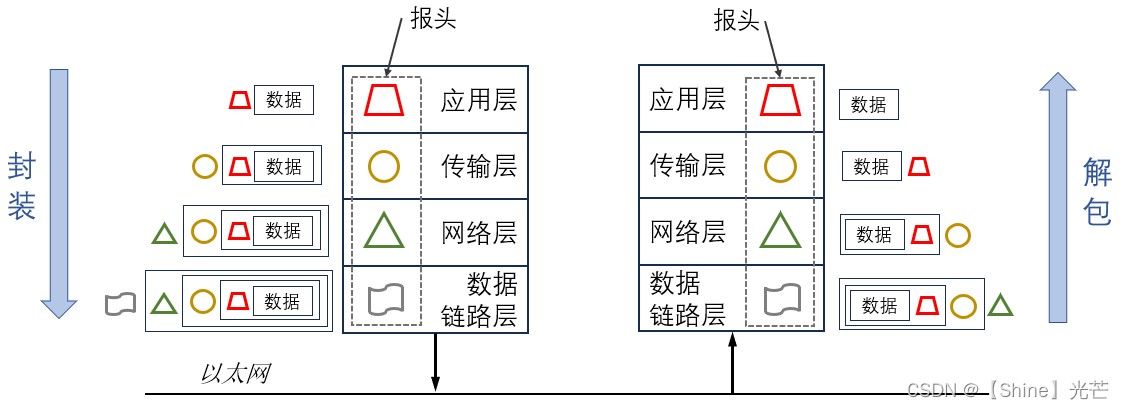
Linux网络编程:网络协议及网络传输的基本流程
目录 一. 计算机网络的发展 二. 网络协议的认识 2.1 对于协议分层的理解 2.2 TCP/IP五层协议模型 2.3 OSI七层模型 三. 网络传输的流程 3.1 同一网段中计算机通信的流程 3.2 不同网段中计算机设备的通信 3.3 对于IP地址和MAC地址的理解 3.4 数据的封装和解包 四. 总结…...

【大数据之Kafka】十、Kafka消费者工作流程
1 Kafka消费方式 (1)pull(拉)模式:消费者从broker中主动拉取数据。(Kafka中使用) 不足:如果Kafka中没有数据,消费者可能会陷入循环,一直返回空数据。 &#…...

如何确保ChatGPT的文本生成对特定行业术语的正确使用?
确保ChatGPT在特定行业术语的正确使用是一个重要而复杂的任务。这涉及到许多方面,包括数据预处理、模型训练、微调、评估和监控。下面我将详细介绍如何确保ChatGPT的文本生成对特定行业术语的正确使用,并探讨这一过程中的关键考虑因素。 ### 1. 数据预处…...
行业追踪,2023-09-11
自动复盘 2023-09-11 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...
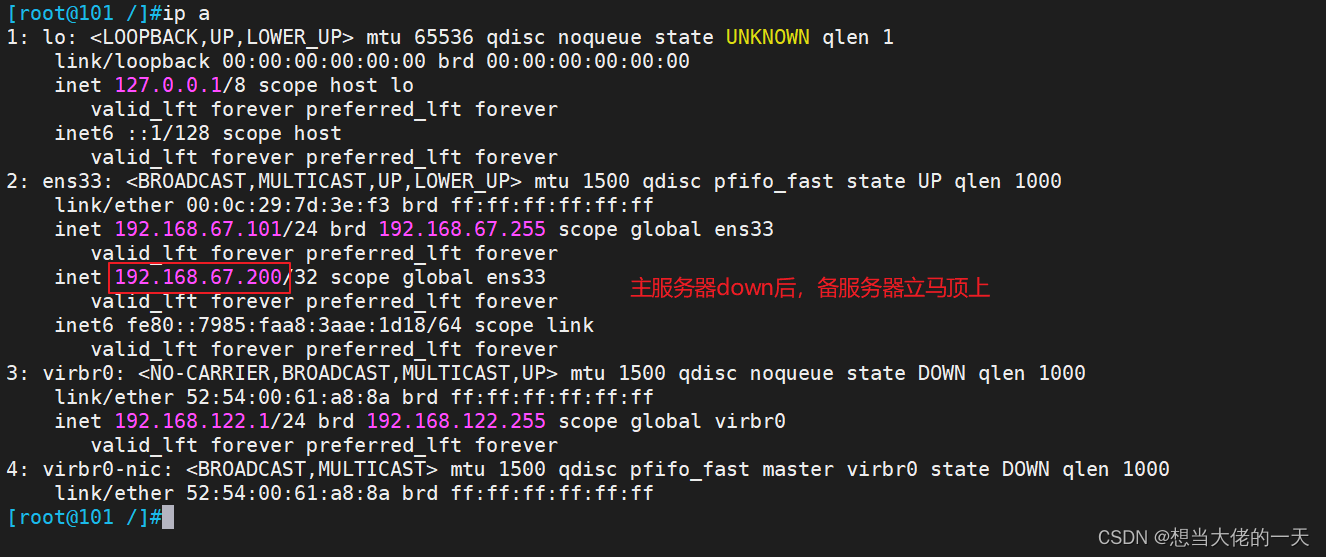
LVS + Keepalived群集
文章目录 1. Keepalived工具概述1.1 什么是Keepalived1.2 工作原理1.3 Keepailved实现原理1.4 Keepalived体系主要模块及其作用1.5 keepalived的抢占与非抢占模式 2. 脑裂现象 (拓展)2.1 什么是脑裂2.2 脑裂的产生原因2.3 如何解决脑裂2.4 如何预防脑裂 …...

springboot将jar改成war
一、maven项目 1、修改pom文件 <packaging>war</packaging>2、添加Servlet API依赖,Spring Boot的Starter依赖通常会包含这个依赖,所以你可能已经有了,没有就需要添加 <dependency><groupId>javax.servlet</gr…...

从9.10拼多多笔试第四题产生的01背包感悟
文章目录 题面基本的01背包问题本题变式 本文参考: 9.10拼多多笔试ak_牛客网 (nowcoder.com) 拼多多 秋招 2023.09.10 编程题目与题解 (xiaohongshu.com) 题面 拼多多9.10笔试的最后一题,是一道比较好的01背包变式问题,可以学习其解法加深对…...
搭建自己的OCR服务,第一步:选择合适的开源OCR项目
一、OCR是什么? 光学字符识别(Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。 亦即将图像中的文字进行识别,并以文本的形式返回。 二、OCR的基本流程 1…...

【C++】VScode配置C/C++语言环境(简洁易懂版)
目录 一、下载VScode(装好直接跳第五步)二、安装VScode三、VScode设置语言为中文四、VScode切换主题(个人爱好)五、下载C语言编译器(MinGW-W64 GCC)六、配置编译器环境变量七、配置VScode八、使用单独窗口…...

【hive】—原有分区表新增加列(alter table xxx add columns (xxx string) cascade;)
项目场景: 需求:需要在之前上线的分区报表中新增加一列。 实现方案: 1、创建分区测试表并插入测试数据 drop table test_1; create table test_1 (id string, score int, name string ) partitioned by (class string) row format delimit…...
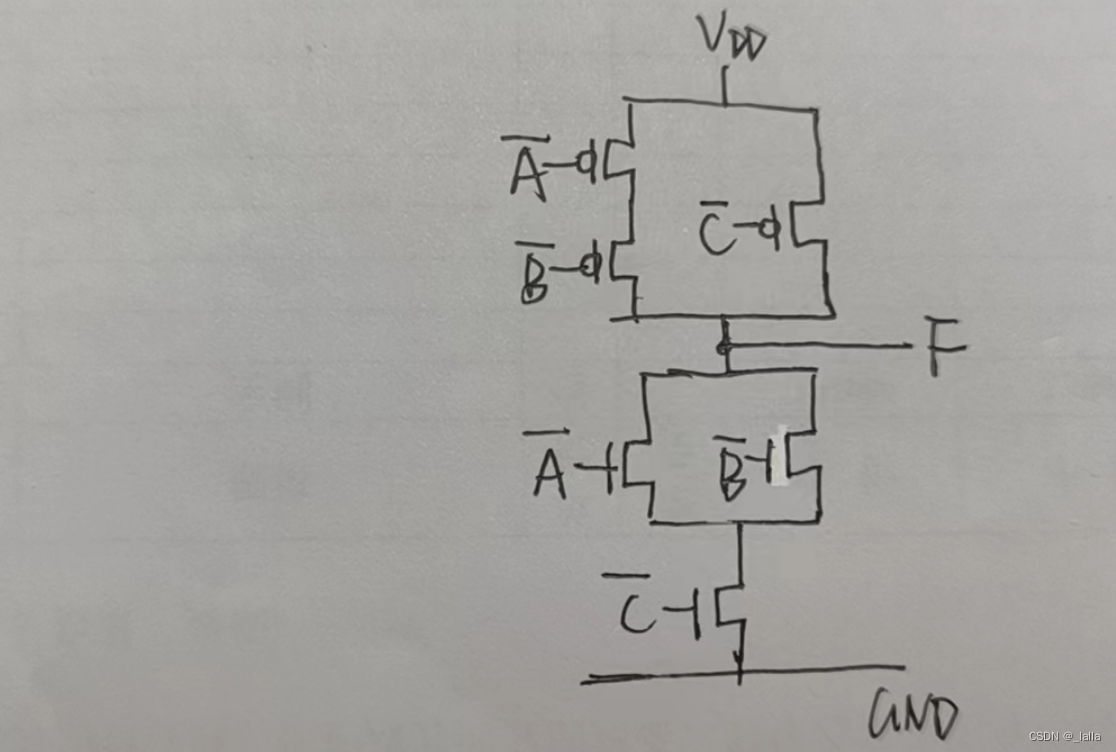
verilog学习笔记7——PMOS和NMOS、TTL电路和CMOS电路
文章目录 前言一、PMOS和NMOS1、NMOS2、PMOS3、增强型和耗尽型4、两者面积大小 二、CMOS门电路1、非门2、与非门3、或非门4、线与逻辑5、CMOS传输门6、三态门 三、TTL电路四、TTL电路 VS CMOS电路五、数字电平六、使用CMOS电路实现逻辑函数1、上拉网络 PUN2、下拉网络 PDN3、实…...

Java知识点二
Java知识点二 1、Comparable内部比较器,Comparator外部比较器2、源码结构的区别:1)Comparable接口:2)Comparator接口: 2、Java反射 1、Comparable内部比较器,Comparator外部比较器 我们一般把Comparable叫…...
:从模糊关键词到JCR一区论文PDF的全自动链路搭建)
Perplexity + Sage期刊深度协同方案(科研人私藏版):从模糊关键词到JCR一区论文PDF的全自动链路搭建
更多请点击: https://intelliparadigm.com 第一章:Perplexity Sage期刊深度协同方案(科研人私藏版):从模糊关键词到JCR一区论文PDF的全自动链路搭建 核心协同逻辑:语义增强型检索闭环 Perplexity 的实时…...

白嫖使用 Claude Opus 4.7 一个月,新手保姆级教程
挖槽,最近亚马逊做了一次大善人,为它自家的 Kiro 做拉新活动,新注册账号可以直接获得一个月的 Kiro Pro 会员,价值 20 美刀。 教程非常详细,所以有点长,想看最短流程版的可以直接划到文章末尾。 Kiro 是什…...
【Pixel专属Gemini Edge推理引擎】:本地运行LLM不联网、零延迟、功耗降低47%——实测数据首次公开
更多请点击: https://intelliparadigm.com 第一章:Gemini Edge推理引擎的Pixel专属定位与技术边界 Gemini Edge 是 Google 为 Pixel 系列设备深度定制的端侧推理引擎,其核心设计目标并非通用模型部署,而是围绕 Pixel 的硬件协同栈…...

【Midjourney提示词工程高阶实战】:20年AI图像生成专家亲授7大隐性权重控制法则,92%用户从未用过的构图锚点技术
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词工程高阶认知重构 提示词工程(Prompt Engineering)在 Midjourney 中远非关键词堆砌,而是一场语义结构、视觉语法与模型先验知识的三重对齐。高阶重构…...

Dev Containers实战:容器化开发环境配置与团队协作指南
1. 项目概述:一个容器化的开发环境定义仓库如果你和我一样,经常需要在不同的机器上切换工作,或者团队里有新成员加入,那么“环境配置”这件事,绝对能排进程序员最头疼问题的前三名。我经历过无数次这样的场景ÿ…...

终极指南:boardgame.io v0.50重大更新,打造更强大的回合制游戏框架
终极指南:boardgame.io v0.50重大更新,打造更强大的回合制游戏框架 【免费下载链接】boardgame.io State Management and Multiplayer Networking for Turn-Based Games 项目地址: https://gitcode.com/gh_mirrors/bo/boardgame.io boardgame.io是…...

AI编程助手Code-Buddy:本地优先、插件化架构与工程实践全解析
1. 项目概述:一个为开发者量身打造的智能代码伙伴 最近在逛GitHub的时候,发现了一个挺有意思的项目,叫 runkids/code-buddy 。光看名字,“代码伙伴”,就让人感觉这应该是个能帮我们写代码、解决开发问题的工具。点进…...

嵌入式开发中CHM文件的应用与优化
1. CHM文件在嵌入式开发中的核心价值CHM(Compiled HTML Help)作为微软推出的编译型帮助文档格式,在嵌入式开发领域已经服役超过20年。这种将HTML文档、索引和搜索功能打包成单一文件的格式,特别适合Keil MDK这类嵌入式开发环境的技…...

Origin 9 绘图避坑指南:7个高频问题解决,让你的科研图表一次成型
Origin 9 科研绘图实战:7个高频问题深度解析与优化方案 科研绘图是数据可视化的重要环节,而Origin 9作为经典的科学绘图软件,其功能强大但操作细节繁多。许多用户在初次接触或日常使用中常会遇到各种棘手问题,导致绘图效率低下、图…...

终极指南:5分钟快速修复Windows更新问题的完整解决方案
终极指南:5分钟快速修复Windows更新问题的完整解决方案 【免费下载链接】Script-Reset-Windows-Update-Tool This script reset the Windows Update Components. 项目地址: https://gitcode.com/gh_mirrors/sc/Script-Reset-Windows-Update-Tool 当Windows更…...