Pytorch intermediate(三) RNN分类
使用RNN对MNIST手写数字进行分类。RNN和LSTM模型结构
pytorch中的LSTM的使用让人有点头晕,这里讲述的是LSTM的模型参数的意义。
1、加载数据集
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import torch.utils.data as Data device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')sequence_length = 28
input_size = 28
hidden_size = 128
num_layers = 2
num_classes = 10
batch_size = 128
num_epochs = 2
learning_rate = 0.01 train_dataset = torchvision.datasets.MNIST(root='./data/',train=True,transform=transforms.ToTensor(),download=True)
test_dataset = torchvision.datasets.MNIST(root='./data/',train=False,transform=transforms.ToTensor())train_loader = Data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = Data.DataLoader(dataset=test_dataset,batch_size=batch_size)2、构建RNN模型
-
input_size – 输入的特征维度
-
hidden_size – 隐状态的特征维度
-
num_layers – 层数(和时序展开要区分开)
-
bias – 如果为
False,那么LSTM将不会使用,默认为True。 -
batch_first – 如果为
True,那么输入和输出Tensor的形状为(batch, seq, feature) -
dropout – 如果非零的话,将会在
RNN的输出上加个dropout,最后一层除外。 -
bidirectional – 如果为
True,将会变成一个双向RNN,默认为False
1、上面的参数来自于文档,最基本的参数是input_size, hidden_size, num_layer三个。input_size:输入数据向量维度,在这里为28;hidden_size:隐藏层特征维度,也是输出的特征维度,这里是128;num_layers:lstm模块个数,这里是2。
2、h0和c0的初始化维度为(num_layer,batch_size, hidden_size)
3、lstm的输出有out和(hn,cn),其中out.shape = torch.Size([128, 28, 128]),对应(batch_size,时序数,隐藏特征维度),也就是保存了28个时序的输出特征,因为做的分类,所以只需要最后的输出特征。所以取出最后的输出特征,进行全连接计算,全连接计算的输出维度为10(10分类)。
4、batch_first这个参数比较特殊:如果为true,那么输入数据的维度为(batch, seq, feature),否则为(seq, batch, feature)
5、num_layers:lstm模块个数,如果有两个,那么第一个模块的输出会变成第二个模块的输入。
总结:构建一个LSTM模型要用到的参数,(输入数据的特征维度,隐藏层的特征维度,lstm模块个数);时序的个数体现在X中, X.shape = (batch_size, 时序长度, 数据向量维度)。
可以理解为LSTM可以根据我们的输入来实现自动的时序匹配,从而达到输入长短不同的功能。
class RNN(nn.Module):def __init__(self, input_size,hidden_size,num_layers, num_classes):super(RNN, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layers#input_size - 输入特征维度#hidden_size - 隐藏状态特征维度#num_layers - 层数(和时序展开要区分开),lstm模块的个数#batch_first为true,输入和输出的形状为(batch, seq, feature),true意为将batch_size放在第一维度,否则放在第二维度self.lstm = nn.LSTM(input_size,hidden_size,num_layers,batch_first = True) self.fc = nn.Linear(hidden_size, num_classes)def forward(self,x):#参数:LSTM单元个数, batch_size, 隐藏层单元个数 h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) #h0.shape = (2, 128, 128)c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)#输出output : (seq_len, batch, hidden_size * num_directions)#(h_n, c_n):最后一个时间步的隐藏状态和细胞状态#对out的理解:维度batch, eq_len, hidden_size,其中保存着每个时序对应的输出,所以全连接部分只取最后一个时序的#out第一维batch_size,第二维时序的个数,第三维隐藏层个数,所以和lstm单元的个数是无关的out,_ = self.lstm(x, (h0, c0)) #shape = torch.Size([128, 28, 128])out = self.fc(out[:,-1,:]) #因为batch_first = true,所以维度顺序batch, eq_len, hidden_sizereturn out训练部分
model = RNN(input_size,hidden_size, num_layers, num_classes).to(device)
print(model)#RNN(
# (lstm): LSTM(28, 128, num_layers=2, batch_first=True)
# (fc): Linear(in_features=128, out_features=10, bias=True)
#)criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)total_step = len(train_loader)
for epoch in range(num_epochs):for i,(images, labels) in enumerate(train_loader):#batch_size = -1, 序列长度 = 28, 数据向量维度 = 28images = images.reshape(-1, sequence_length, input_size).to(device)labels = labels.to(device)# Forward passoutputs = model(images)loss = criterion(outputs, labels)# Backward and optimizeoptimizer.zero_grad()loss.backward() optimizer.step()if (i+1) % 100 == 0:print(outputs.shape)print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, total_step, loss.item()))# Test the model
with torch.no_grad():correct = 0total = 0for images, labels in test_loader:images = images.reshape(-1, sequence_length, input_size).to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Test Accuracy of the model on the 10000 test images: {} %'.format(100 * correct / total)) 相关文章:
 RNN分类)
Pytorch intermediate(三) RNN分类
使用RNN对MNIST手写数字进行分类。RNN和LSTM模型结构 pytorch中的LSTM的使用让人有点头晕,这里讲述的是LSTM的模型参数的意义。 1、加载数据集 import torch import torchvision import torch.nn as nn import torchvision.transforms as transforms import torc…...

vue2+webpack升级vue3+vite,修改插件兼容性bug
同学们可以私信我加入学习群! 前言 在前面使用electronvue3的过程中,已经验证了历史vue2代码vue3混合开发的模式。 本次旧项目vue框架整体升级中,同事已经完成了vue3、pinia、router等基础框架工具的升级。所以我此次记录的主要是vite打包工…...
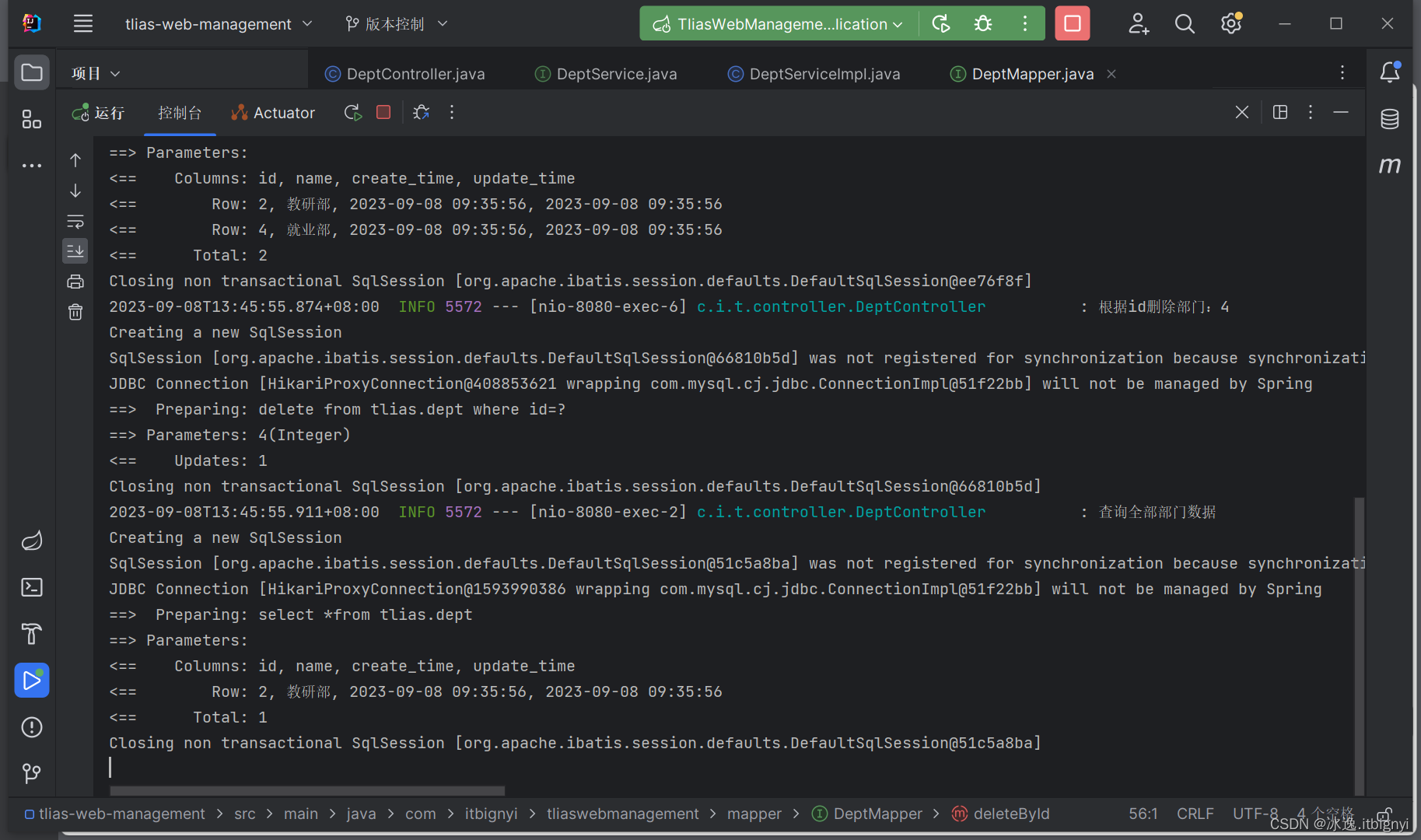
案例实战-Spring boot Web
准备工作 需求&环境搭建 需求: 部门管理: 查询部门列表 删除部门 新增部门 修改部门 员工管理 查询员工列表(分页、条件) 删除员工 新增员工 修改员工 环境搭建 准备数据库表(dept、emp) -- 部门管理…...

Spring6.1之RestClient分析
文章目录 1 RestClient1.1 介绍1.2 准备项目1.2.1 pom.xml1.2.2 创建全局 RestClient1.2.3 Get接收数据 retrieve1.2.4 结果转换 Bean1.2.5 Post发布数据1.2.6 Delete删除数据1.2.7 处理错误1.2.8 Exchange 方法 1 RestClient 1.1 介绍 Spring 框架一直提供了两种不同的客户端…...

冒泡排序、选择排序、插入排序、希尔排序
冒泡排序 基本思想 代码实现 # 冒泡排序 def bubble_sort(arr):length len(arr) - 1for i in range(length):flag Truefor j in range(length - i):if arr[j] > arr[j 1]:temp arr[j]arr[j] arr[j 1]arr[j 1] tempflag Falseprint(f第{i 1}趟的排序结果为&#…...

OpenCV(二十三):中值滤波
1.中值滤波的原理 中值滤波(Median Filter)是一种常用的非线性图像滤波方法,用于去除图像中的椒盐噪声等离群点。它的原理是基于邻域像素值的排序,并将中间值作为当前像素的新值。 2.中值滤波函数 medianBlur() void cv::medianBl…...

Prompt Tuning训练过程
目录 0. 入门 0.1. NLP发展的四个阶段: Prompt工程如此强大,我们还需要模型训练吗? - 知乎 Prompt learning系列之prompt engineering(二) 离散型prompt自动构建 Prompt learning系列之训练策略篇 - 知乎 ptuning v2 的 chatglm垂直领域训练记…...

装备制造企业是否要转型智能装备后服务型公司?
一、从制造到服务:装备制造企业的转型之路 装备制造企业作为国家经济发展的重要支柱,面临着日益激烈的市场竞争。在这样的背景下,越来越多的装备制造企业开始意识到,通过转型为智能装备后服务型公司,可以更好地满足客…...
 动态规划 part 10)
day-49 代码随想录算法训练营(19) 动态规划 part 10
121.买卖股票的最佳时机 思路一:贪心 不断更新最小买入值不断更新当前值和最小买入值的差值最大值 思路二:动态规划(今天自己写出来了哈哈哈哈哈哈哈) 1.dp存储:dp[i][0] 表示当前持有 dp[i][1]表示当前不持有2.状…...

检查文件名是否含不可打印字符的C++代码源码
本篇文章属于《518抽奖软件开发日志》系列文章的一部分。 我在开发《518抽奖软件》(www.518cj.net)的时候,有时候需要检查输入的是否是合法的文件名,文件名是否含不可打印字符等。代码如下: //----------------------…...

学习笔记-正则表达式
https://www.runoob.com/regexp/regexp-tutorial.html 正则表达式re(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),可以用来描…...

Wireshark TS | 网络路径不一致传输丢包问题
问题背景 网络路径不一致,或者说是网络路径来回不一致,再专业点可以说是网络路径不对称,以上种种说法,做网络方向的工程师肯定会更清楚些,用简单的描述就是: A 与 B 通讯场景,C 和 D 代表中间…...

CMake高级用法实例分析(学习paddle官方的CMakeLists)
cmake基础学习教程 https://juejin.cn/post/6844903557183832078 官方完整CMakeLists cmake_minimum_required(VERSION 3.0) project(PaddleObjectDetector CXX C)option(WITH_MKL "Compile demo with MKL/OpenBlas support,defaultuseMKL." ON) o…...

数据采集: selenium 自动翻页接口调用时的验证码处理
写在前面 工作中遇到,简单整理理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大…...
IDEA安装翻译插件
IDEA安装翻译插件 File->Settings->Plugins 在Marketplace中,找到Translation,点击Install 更换翻译引擎 勾选自动翻译文档 翻译 鼠标右击->点击Translate...

DBeaver使用
一、导出表结构 二、导出数据CSV 导出数据时DBeaver并没有导出表结构,所以表结构需要额外保存; 导入数据CSV 导入数据时会因外键、字段长度导致失败;...

Nougat:一种用于科学文档OCR的Transformer 模型
随着人工智能领域的不断进步,其子领域,包括自然语言处理,自然语言生成,计算机视觉等,由于其广泛的用例而迅速获得了大量的普及。光学字符识别(OCR)是计算机视觉中一个成熟且被广泛研究的领域。它有许多用途,…...

redis八股1
参考Redis连环60问(八股文背诵版) - 知乎 (zhihu.com) 1.是什么 本质上是一个key-val数据库,把整个数据库加载到内存中操作,定期通过异步操作把数据flush到硬盘持久化。因为纯内存操作,所以性能很出色,每秒可以超过10…...

人工智能基础-趋势-架构
在过去的几周里,我花了一些时间来了解生成式人工智能基础设施的前景。在这篇文章中,我的目标是清晰概述关键组成部分、新兴趋势,并重点介绍推动创新的早期行业参与者。我将解释基础模型、计算、框架、计算、编排和矢量数据库、微调、标签、合…...
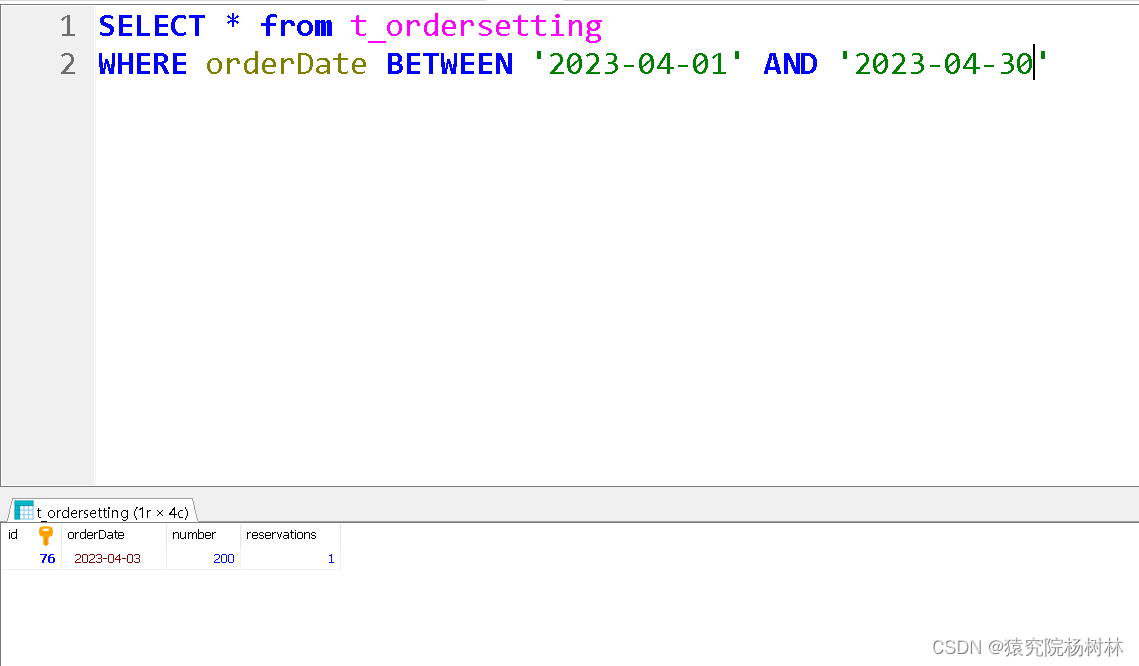
Date日期工具类(数据库日期区间问题)
文章目录 前言DateUtils日期工具类总结 前言 在我们日常开发过程中,当涉及到处理日期和时间的操作时,字符串与Date日期类往往要经过相互转换,且在SQL语句的动态查询中,往往月份的格式不正确,SQL语句执行的效果是不同的…...

图解CA注意力机制:用Keras一步步拆解‘宽高分离池化’,理解位置信息如何嵌入通道注意力
图解CA注意力机制:用Keras拆解‘宽高分离池化’的视觉密码 当我们谈论注意力机制时,脑海中往往会浮现SE(Squeeze-and-Excitation)模块的通道加权画面。但今天要探讨的CA(Coordinate Attention)机制…...
)
【限时解禁】Google I/O 2024未发布的Gemini Android Enterprise Integration白皮书核心章节(仅剩37份授权访问码)
更多请点击: https://intelliparadigm.com 第一章:Gemini Android深度整合的战略定位与演进脉络 Google 将 Gemini 模型深度嵌入 Android 生态,并非单纯叠加 AI 功能,而是重构操作系统级智能代理的交互范式。其战略内核在于将大模…...
原理与应用全解析)
时序电路的心脏:钟控触发器(RS/D/JK/T)原理与应用全解析
1. 时序电路的心脏:为什么需要钟控触发器? 第一次接触数字电路时,我被各种触发器绕得头晕。直到老师用"心脏"来比喻钟控触发器,才恍然大悟——就像心脏通过规律跳动为全身供血一样,钟控触发器通过时钟脉冲协…...

第一份工作选大厂还是创业公司?5年后的差距令人深思
对于刚刚走出校门的软件测试工程师而言,第一份工作的选择,如同一场没有回头路的开局落子。它不仅仅关乎起薪的高低,更将深刻塑造你的技术视野、职业习惯和未来五年的成长曲线。五年,足以让一个初出茅庐的新人成长为独当一面的技术…...

5种智能匹配模式:Illustrator脚本replaceItems.jsx如何让设计元素替换效率提升20倍
5种智能匹配模式:Illustrator脚本replaceItems.jsx如何让设计元素替换效率提升20倍 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在Adobe Illustrator设计工作中&…...

5个核心功能:彻底掌握Nexus Mods App模组管理技巧
5个核心功能:彻底掌握Nexus Mods App模组管理技巧 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App Nexus Mods App是一款革命性的游戏模组管理器,专为…...

从Hello-World到Nginx:5个真实案例详解如何让Docker容器在后台稳定运行
从Hello-World到Nginx:5个真实案例详解如何让Docker容器在后台稳定运行 当你在终端输入docker run后,容器却像一阵风一样消失无踪——这种"闪退"现象往往是Docker新手遭遇的第一个认知颠覆点。不同于传统虚拟机,容器本质上是隔离的…...

EdgeDB终极性能优化指南:5个关键磁盘IO配置大幅提升数据读写速度 [特殊字符]
EdgeDB终极性能优化指南:5个关键磁盘IO配置大幅提升数据读写速度 🚀 【免费下载链接】edgedb Gel supercharges Postgres with a modern data model, graph queries, Auth & AI solutions, and much more. 项目地址: https://gitcode.com/gh_mirro…...

36种阀体混线全自动智能分拣方案|3D视觉+机器人柔性制造实践
一、项目背景与行业痛点在高端流体控制设备制造领域,阀体、阀盖的精密分拣是保障产品质量的核心环节。随着工业设备向小型化、高精度方向发展,客户对阀体组件加工误差的控制要求持续提升,传统生产模式面临显著瓶颈:1. 人工分拣效率…...

从数学定义到代码实现:深度解析卷积与互相关的本质差异
1. 卷积与互相关的数学定义 很多人第一次接触卷积和互相关时,都会觉得它们长得太像了。确实,从表面上看,它们都是用一个滑动窗口在输入数据上移动,然后进行加权求和。但如果你仔细研究它们的数学定义,就会发现本质上的…...