【C++】哈希——哈希的概念,应用以及闭散列和哈希桶的模拟实现
前言:
前面我们一同学习了二叉搜索树,以及特殊版本的平衡二叉搜索树,这些容器让我们查找数据的效率提高到了O(log^2 N)。虽然效率提高了很多,但是有没有一种理想的方法使得我们能提高到O(1)呢?其实在C语言数据结构中,我们接触过哈希表,他可以使效率提高到O(1)。
哈希表作为STL中我们所必须学习和了解的容器,是一种一一映射的存储方式,其次它在日常生活中的应用范围也是很广的,例如位图,海量数据筛选中用到的布隆过滤器等等……
下面我们就来先学习一下STL中的应用哈希表的两个容器,再了解一下底层结构 (两个关联式容器unordered_map和unordered_set,unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构),最后再来模拟实现一下。
目录
(一)STL中底层应用哈希的两个容器
1、unordered_set
2、unordered_map
(二)常见的查找性能对比
(三)哈希表的概念及模拟实现
1、哈希的概念
2、哈希函数
3、哈希冲突
4、闭散列——开放定址法
5、开散列——链地址法(开链法),哈希桶
(四)详细代码
(一)STL中底层应用哈希的两个容器
在STL中对应的容器分别是unordered_map和unordered_set这两个关联式容器。、
我们会用map和set,其实就会用unordered_map和unordered_set这两个容器,但是这两类容器是有区别的!
我们一一分析:
1、unordered_set
文档链接->unordered_set文档
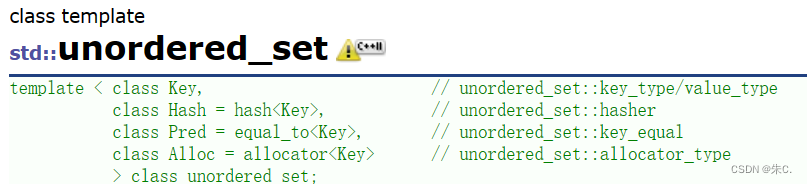
我们使用一下unordered_set的接口函数:
void test_unordered_set1()
{unordered_set<int> s1;s1.insert(1);s1.insert(2);s1.insert(9);s1.insert(2);s1.insert(3);s1.insert(3);s1.insert(4);s1.insert(5);unordered_set<int>::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";++it;}cout << endl;for (auto e : s1){cout << e << " ";}
} 
结果是实现了存储+去重,但是是无序的。
由上图和查阅资料得知:
- map和set: 去重 + 排序
- unordered_map和unordered_set: 只有去重
这里主要原因是底层实现不同,map和set底层是红黑树,unordered_set和unordered_map底层是红黑树。
其余函数接口和之前所学的容器使用起来大致相同,不再一一赘述。
unordered_map和unordered_set都是单向迭代器:
值得注意的是unordered_map和unordered_set的迭代器都是单向迭代器,而我们之前学的map和set则是双向迭代器(所以迭代器可以++也可以--)。
unordered_set和set的性能对比:
int main()
{const size_t N = 100000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; i++){v.push_back(rand());//v.push_back(rand()+i);//v.push_back(i);}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl << endl;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;
}数据随机但有重复: 数据随机但重复少


数据连续无重复:

总结:
总的来说unordered_map和unordered_set要比map和set的性能要好的,但是也并不是一定的,当数据量很大的时候,扩容重新哈希是有消耗的。
2、unordered_map
文档链接->unordered_map文档
我们使用unordered1_map的接口函数:
void test_unordered_map()
{string arr[] = { "梨","梨","苹果","梨","西瓜","西瓜" };unordered_map<string, int> m;for (auto& e : arr){m[e]++;}for (auto& kv : m){cout << kv.first << ":" << kv.second << endl;}
}
int main()
{test_unordered_map();return 0;
}
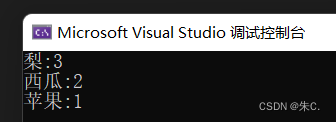
总体来说,unordered_map和map的用法差不多,但是他们的效率有所不同。
(二)常见的查找性能对比
- 暴力查找: 时间复杂度〇(N)
- 二分查找: 时间复杂度〇(logN) ,缺点 — 有序、数组结构
- 搜索二叉树: 时间复杂度〇(N),缺点 — 极端场景退化成单支
- 平衡二叉搜索树: 时间复杂度〇(logN)
- AVLTree: 左右子树高度差不超过1
- 红黑树:最长路径不超过最短路径的2倍
- 哈希
- B树系列: 多叉平衡搜索树 — 数据库原理
- 跳表
ps:
红黑树高度略高一些,但是跟AVL树是同一数量级,对于现代计算机没有差别但是红黑树相对而言近似平衡,旋转少。

(三)哈希表的概念及模拟实现
1、哈希的概念
我们已学过的查找 :
理想的查找方法:
- 该中存储结构可以实现:
-
- 插入元素时:
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放。
- 插入元素时:
-
- 查找元素时:
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功。
- 查找元素时:
2、哈希函数
我们如何一一将键值转换为对应的关键码值,并映射到对应序号的存储位置呢?
直接建立映射关系问题:
- 1、数据范围分布很广、不集中(可能存在空间浪费严重的问题)
- 2、key的数据不是整数,是字符串怎么办?是自定义类型对象怎么办?
此时我们就需要一个函数对特殊非整数类型的数据进行处理,使其返回一个特定的整数,这个函数我们叫做 —— 哈希函数。
常见的哈希函数:
1、直接定址法(常用)
- 取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
- 优点:简单、均匀
- 缺点:需要事先知道关键字的分布情况
- 使用场景:适合查找比较小且连续的情况
2、除留余数法(常用)
3、其余常见但不常用的还有 平方取中法、折叠法、随机数法、数学分析法等。
字符串也有自己类型的哈希函数----->参考文献(了解即可)
3、哈希冲突
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
按照上述哈希函数计算出键值对应的关键码值,但是算出来的这些码值当中,有很大的可能会出现关键码值相同的情况,这种情况就叫作:哈希冲突。
- 哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
- 解决哈希冲突两种常见的方法是:闭散列和开散列
4、闭散列——开放定址法

线性探测:
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
插入:
- 通过哈希函数获取待插入元素在哈希表中的位置
- 线性探测找到空位置将值插入
查找:
- 挨个遍历哈希表,直到找到空为止
删除:
- 过关键码值再用线性探测找到该值直接删除
- 注意:
- 删除要是直接删除的话有可能会影响查找的准确性
- 如图删除了4,要去找44就会找不到。
那怎么办呢?
- 所以我们给每个键值提供一个状态,采取伪删除的方法
即通过对每一个数据加上一个标识状态即可:

线性探测的缺点:
- 一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。
所以我们引入了二次探测:跳跃着找空位置,是相对上面方法的优化,使得数据可能不那么拥堵。
所以经过上面的介绍,我们想自己实现一个闭散列需要注意以下的几点:
- 哈希函数的选择
- 哈希冲突的应对
- 如何应对“堆积”导致效率低下的情况
- 如何扩容表
第一点和第二点我们已经在上文介绍过了,这里我们应用的就是开放定址法和线性探测。
- 第三点:如何应对“堆积”导致效率低下的情况?
查询资料:

首先根据上文我们知道闭散列哈希表并不能太满:
- 太满就会导致线性探测时,找不到位置
- 更不能放满,那样探测就会陷入死循环
- 所以要控制一下存储的数据
- 我们引入了一个变量
n来记录存储数据的个数
散列表的载荷因子定义为: a = 填入表中的元素个数 / 散列表的长度
所以我们要控制一下负载因子:

- 第四点:负载因子超了如何扩容?
有人会说直接resize扩容就行了啊。但是,你没注意到一个问题:

我在刚刚那个表中又插入了13,这时按理说应该扩容了防止效率变低。
假如我扩容到20格,我想找13的时候根据哈希函数,13不应该在编号是13的格子中吗?但是我是存储在3中啊,这就矛盾了...
所以扩容时我们不能直接将原来的数据拷贝过去:
- 因为哈希是映射的关系,关键码值是通过数据和表的大小计算出来的
- 如果直接拷贝的话全都乱套了
- 这时我们需要重新映射

如图所示,也不是特别麻烦
直接建立一个新表,然后遍历旧表一次映射到新表中
不过扩容时会有不少的消耗
补充:
- 映射的时候取模
- 应该是对表的size()取模,而不是capacity()
- 因为对capacity取模的话,可能取到超出size的位置
- operator[]会对超出size的检查(不过有的也不检查,根据不同版本的库里定)
5、开散列——链地址法(开链法),哈希桶

从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
很显然,哈希桶中每个元素是个地址,所以哈希桶的底层原理就是一个指针数组,每个结点再挂着一个单链表,这样冲突就很容易解决了。
还是老问题,
- 如何应对“堆积”导致效率低下的情况
- 如何扩容
- 如何应对“堆积”导致效率低下的情况?
这里我们还是选择适时扩容,那什么情况扩容呢?
- 如何扩容?

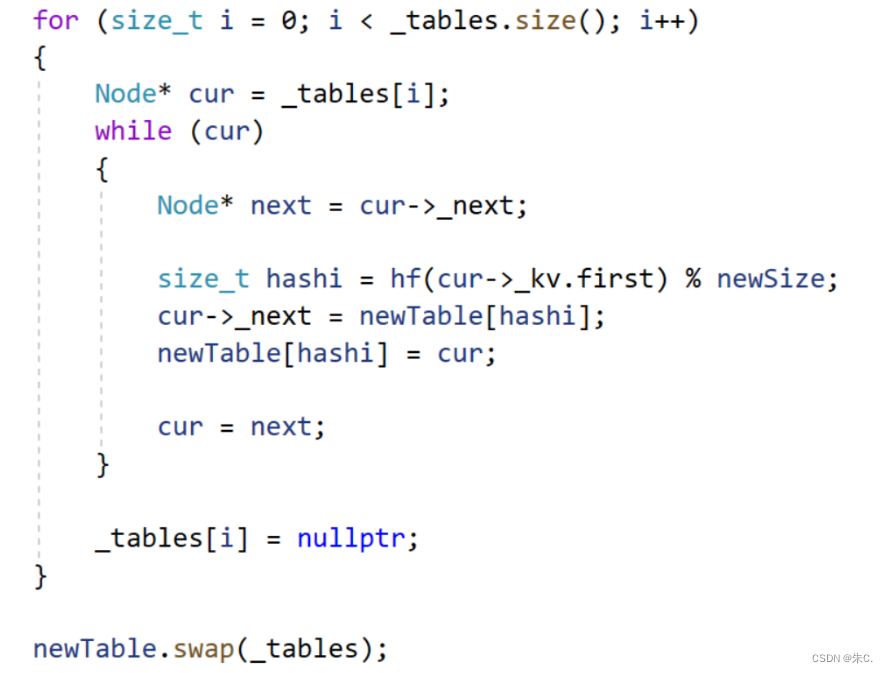
很显然我们更倾向于方案二:
方案一写法更简单,但是不断递归开销更大。
注:哈希桶结点插入,我们一般采用头插的方法,因为对于每一个链表,如果尾插,需要先找到尾,增加了时间消耗,头插的话消耗更低。
因为开散列是一个指针数组,涉及到空间的开辟,所以析构函数我们要自己完善:
~HashTable(){for (auto& cur : _tables){while (cur){Node* next = cur->_next;delete cur;cur = next;}cur = nullptr;}}
(四)详细代码
namespace OpenAddress
{enum State{EMPTY,EXIST,DELETE};template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};template<class K, class V>class HashTable{public:HashData<K, V>* Find(const K& key){if (_tables.size() == 0){return nullptr;}size_t hashi = key % _tables.size();//线性探测size_t i = 1;size_t index = hashi;while (_tables[index]._state != EMPTY){if (_tables[index]._state == EXIST&& _tables[index]._kv.first == key){return &_tables[index];}index = hashi + i;index %= _tables.size();++i;if (index == hashi){break;}}return nullptr;}bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}else{return false;}}bool Insert(const pair<K, V>& kv){if (Find(kv.first)){return false;}if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7){size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;HashTable<K, V> newht;newht._tables.resize(newsize);for (auto& data : _tables){if (data._state == EXIST){newht.Insert(data._kv);}}_tables.swap(newht._tables);}size_t hashi = kv.first % _tables.size();//线性探测size_t i = 1;size_t index = hashi;while (_tables[index]._state == EXIST){index = hashi + i;index %= _tables.size();++i;}_tables[index]._kv = kv;_tables[index]._state = EXIST;_n++;return true;}private:vector<HashData<K, V>> _tables;size_t _n = 0;//存储的数据个数};void TestHashTable2(){HashTable<int, int> ht;int arr[] = { 1,2,2,3,3,3,4,4,4,4,5,9,2,3 };for (auto& e : arr){ht.Insert(make_pair(e, e));}}void TestHashTable1(){int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(15, 15));if (ht.Find(13)){cout << "13在" << endl;}else{cout << "13不在" << endl;}ht.Erase(13);if (ht.Find(13)){cout << "13在" << endl;}else{cout << "13不在" << endl;}}
}namespace HashBacket
{template<class K,class V>struct HashNode{HashNode<K, V>* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_next(nullptr), _kv(kv){}};template<class K,class V>class HashTable{typedef HashNode<K, V> Node;public:~HashTable(){for (auto& cur : _tables){while (cur){Node* next = cur->_next;delete cur;cur = next;}cur = nullptr;}}Node* Find(const K& key){if (_tables.size() == 0){return nullptr;}size_t hashi = key % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key){size_t hashi = key % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if(prev==nullptr){ _tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}else{prev = cur;cur = cur->_next;}}return false;}bool Insert(const pair<K, V>& kv){if (Find(kv.first)){return false;}if (_n == _tables.size()){size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;vector<Node*> newtables(newsize, nullptr);for (auto& cur : _tables){while (cur){Node* next = cur->_next;size_t hashi = cur->_kv.first % newtables.size();//头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}}_tables.swap(newtables);}size_t hashi = kv.first % _tables.size();// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}private:vector<Node*> _tables;size_t _n = 0;};void TestHashTable1(){int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(15, 15));ht.Insert(make_pair(25, 25));ht.Insert(make_pair(35, 35));ht.Insert(make_pair(45, 45));}void TestHashTable2(){int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}ht.Erase(12);ht.Erase(3);ht.Erase(33);}
}感谢你的阅读!
相关文章:
【C++】哈希——哈希的概念,应用以及闭散列和哈希桶的模拟实现
前言: 前面我们一同学习了二叉搜索树,以及特殊版本的平衡二叉搜索树,这些容器让我们查找数据的效率提高到了O(log^2 N)。虽然效率提高了很多,但是有没有一种理想的方法使得我们能提高到O(1)呢?其实在C语言数据结构中&a…...

Kubernetes (K8s) 解读:微服务与容器编排的未来
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🐅🐾猫头虎建议程序员必备技术栈一览表📖: 🛠️ 全栈技术 Full Stack: 📚…...
JavaScript学习--Day04
元字符 边界符: /^/:以什么开头 /$/:以什么结尾 量词: 预定义类:...
)
HCS 基本概念(三)
一、定义 HCS采用FusionSphere OpenStack作为云平台,对各个物理数据中心资源做整合,采用ManageOne作为数据中心管理软件对多个数据中心提供统一管理,通过云平台和数据中心管理软件协同运作,达到多数据中心融合、提升企业整体IT效率…...
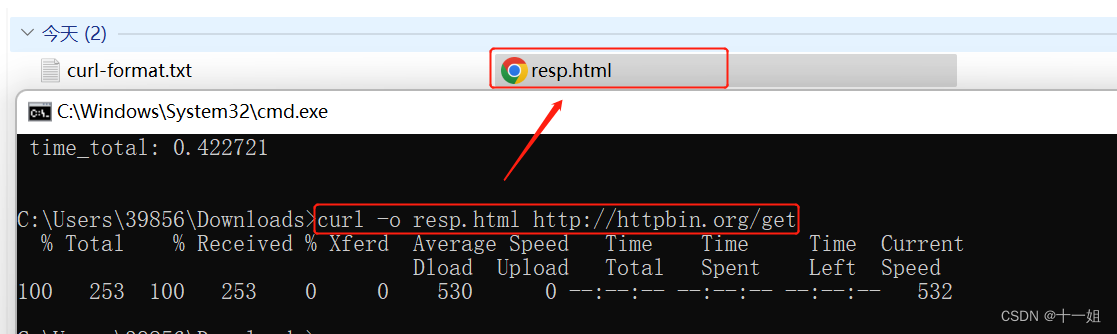
通过curl命令分析http接口请求各阶段的耗时等
目录 一、介绍二、功能1、-v 输出请求 响应头状态码 响应文本等信息2、-x 测试代理ip是否能在该网站使用3、-w 额外输出查看接口请求响应的消耗时间4、-o 将响应结果存储到文件里面5、-X post请求测试 (没测成功用的不多) 一、介绍 Curl是一个用于发送和接收请求的命令行工具和…...

Linux工具——gcc
目录 一,gcc简介 二,C语言源文件的编译过程 1.预处理 2.编译 3.汇编 4.链接 5.动静态库 一,gcc简介 相信有不少的小白和我一样在学习Linux之前只听说过visual studio。其实这个gcc这个编译器实现的功能便是和visual studio一样的功能&…...

uni-app 使用uCharts-进行图表展示(折线图带单位)
前言 在uni-app经常是需要进行数据展示,针对这个情况也是有人开发好了第三方包,来兼容不同平台展示 uCharts和pc端的Echarts使用差不多,甚至会感觉在uni-app使用uCharts更轻便,更舒服 但是这个第三方包有优点就会有缺点…...
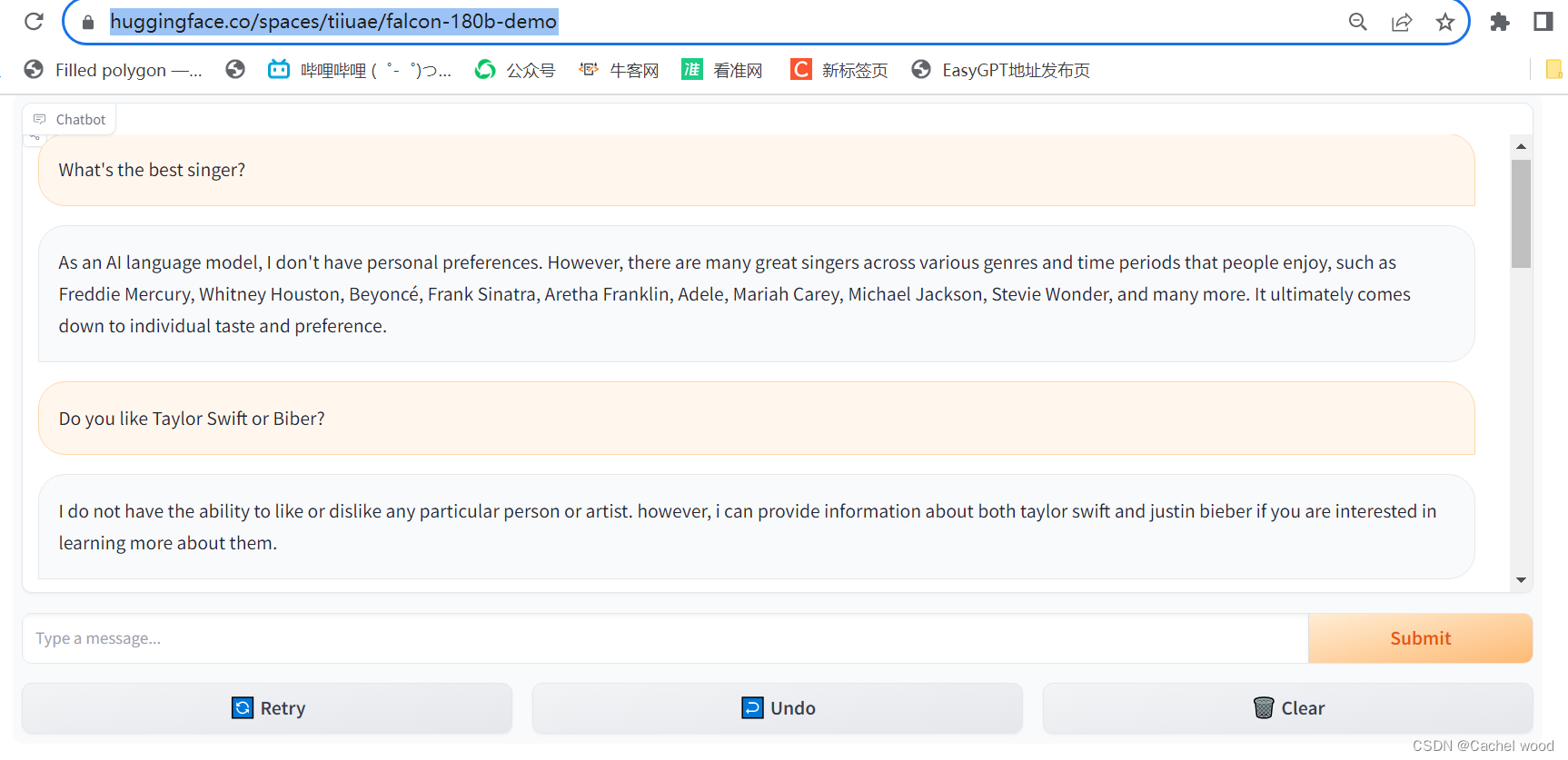
180B参数的Falcon登顶Hugging Face,vs chatGPT 最好开源大模型使用体验
文章目录 使用地址使用体验test1:简单喜好类问题test2:知识性问题test3:开放性问题test4:中文支持test5:问题时效性test6:学术问题使用地址 https://huggingface.co/spaces/tiiuae/falcon-180b-demo 使用体验 相比Falcon-7b,Falcon-180b拥有1800亿的参数量...
服务器数据恢复-EMC存储磁盘损坏的RAID5数据恢复案例
服务器数据恢复环境: 北京某单位有一台EMC某型号存储,有一组由10块STAT硬盘组建的RAID5阵列,另外2块磁盘作为热备盘使用。RAID5阵列上层只划分了一个LUN,分配给SUN小机使用,上层文件系统为ZFS。 服务器故障࿱…...

Nginx优化文件上传大小限制
Nginx默认配置 Nginx 默认情况下,上传文件的大小为1M,超过1M就会返回413错误。只用对Nginx进行简单配置即可解决问题。 优化Nginx文件上传大小限制 可以在Nginx配置文件中配置 client_max_body_size 配置项。 设置客户端请求正文允许的最大大小。如果…...
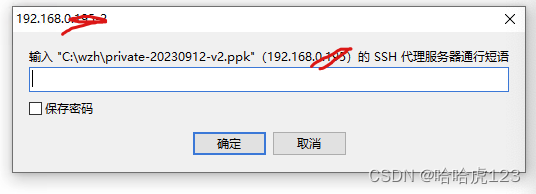
navicat SSH连接数据库报错: Putty key format too new
问题 下载 Putty 0.79 生成了密钥,但是在navicat 15 使用SSH通道连接数据库报错: Putty key format too new 错误原因和处理 原来是因为生成的私钥格式是 V3 , navicat 15 只能识别 V2 所以,在 PuTTYgen Load 私钥,重新保存为 …...
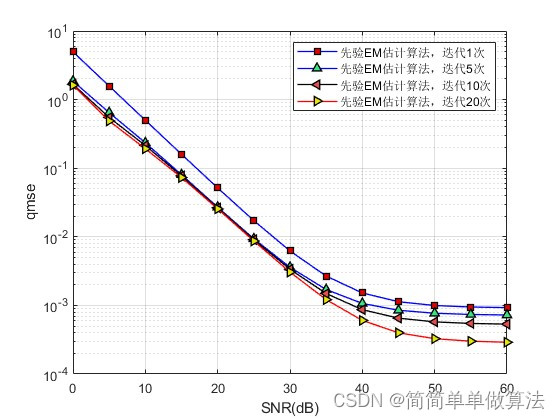
基于大规模MIMO通信系统的半盲信道估计算法matlab性能仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 %EM算法收敛所需的迭代 nIter 1; Yp Y(:,1:L_polit,:); %与导频序列相对应的部分 q…...
———— OVV Recall Rate与 IV Recall Rate)
自然语言处理学习笔记(九)———— OVV Recall Rate与 IV Recall Rate
目录 1.OVV Recall Rate 2. IV Recall Rate 1.OVV Recall Rate OOV指的是“未登录词”(Out Of Vocabulary),或者俗称的“新词”,也即词典未收录的词汇。如何准确切分00V,乃至识别其语义,是整个NLP领域的核…...

区块链正在开启一场回归商业,融合商业的新发展
对于区块链来讲,它其实同样在延续着这样一种发展路径。 正如上文所说,区块链正在开启一场回归商业,融合商业的新发展。 而欲要实现这一点,区块链就是要从底层算法,底层数据传输,底层体系的打造着手…...

【软考】系统集成项目管理工程师(三)信息系统集成专业技术知识③
一、云计算 1、定义 通过互联网来提供大型计算能力和动态易扩展的虚拟化资源;云是网络、互联网的一种比喻说法。是一种大集中的服务模式。 2、特点 (1)超大规模(2)虚拟化(3)高可扩展性&…...

js中如何判断一个对象是否为空对象?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 使用 Object.keys()⭐ 使用 for...in 循环⭐ 使用 JSON.stringify()⭐ 使用 ES6 的 Object.getOwnPropertyNames()⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带…...

Linux SysRq 简介
文章目录 1. 前言2. 背景3. Linux SysRq3.1 SysRq 简介3.1.1 SysRq 初始化 3.2 通过 procfs 发起 SysRq 请求3.2.1 修改内核日志等级3.2.1.1 触发3.2.1.2 实现简析 3.2.2 手动触发内核 panic3.2.2.1 触发3.2.2.2 实现简析3.2.2.3 应用场景 3.2.3 其它 SysRq 请求 3.3 通过 特殊…...
Mac版本破解Typora,解决Mac安装软件的“已损坏,无法打开。 您应该将它移到废纸篓”问题
一、修改配置文件 首先去官网选择mac版本下载安装 typora下载 然后打开typora包内容找到 /Applications/Typora.app/Contents/Resources/TypeMark/ 编辑器打开上面文件夹,这里我拉到vscode 找到page-dist/static/js/Licen..如下图 输入 hasActivated"…...
elementui el-dialog 动态生成多个,点击按钮打开对应的 dialog
业务场景: 根据后端返回的数据,动态生成表单,返回的数据中会有表单字段的类型,如果单选、多选、富文本,其它的属性还好说,重点说在富文本,因为我想通过 dialog 弹窗的方式,进行富文…...
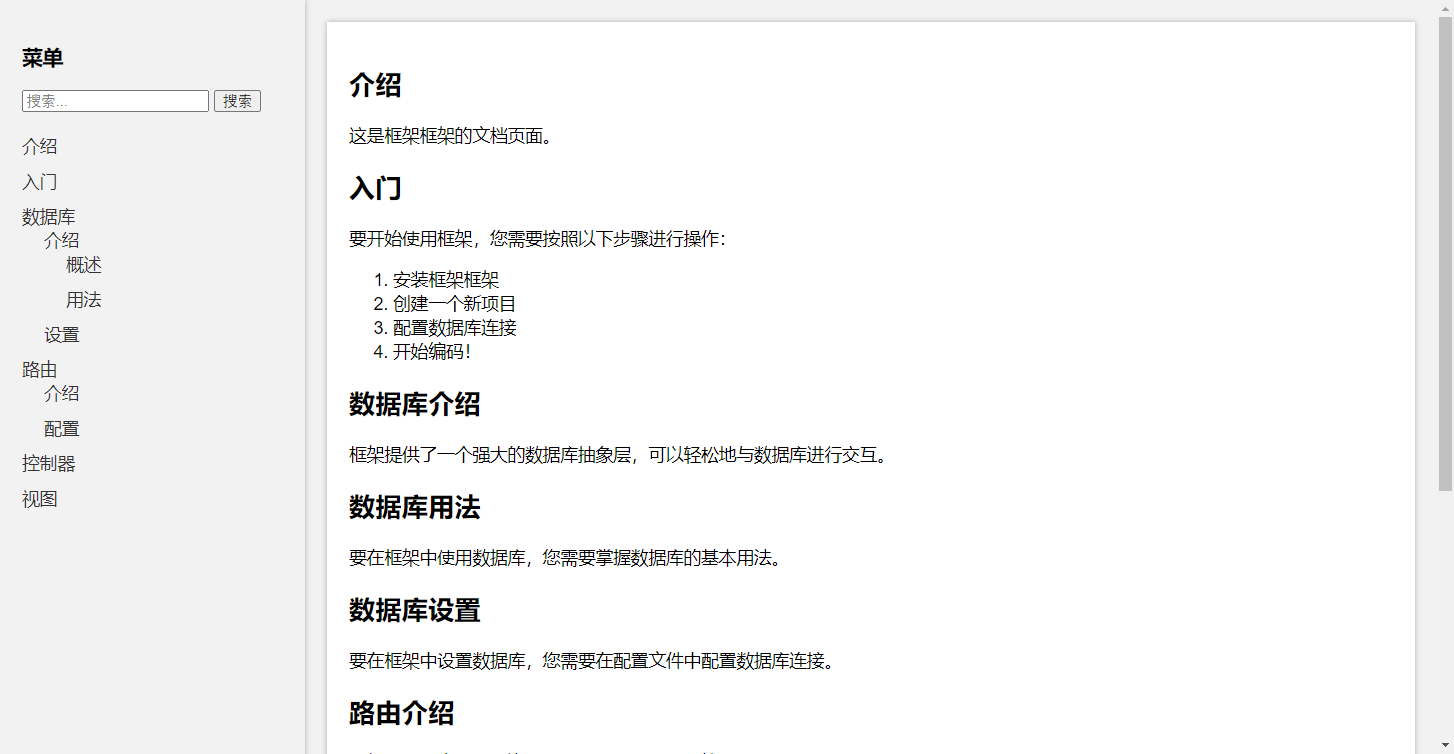
自己开发一个接口文档页面html
演示效果 具体代码如下 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>框架框架文档页面</…...

RTKLIB2.4.3进阶:在VS2017中通过.conf与命令行参数高效驱动PPP数据处理
1. RTKLIB与PPP数据处理基础 RTKLIB作为开源GNSS数据处理工具链,在精密单点定位(PPP)领域有着广泛应用。2.4.3版本虽然发布较早,但其稳定性和功能完整性使其至今仍是许多高精度定位项目的首选。我在多个测绘项目中实测发现&#x…...

利用Taotoken的多模型能力为AIGC应用构建弹性后备方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken的多模型能力为AIGC应用构建弹性后备方案 对于开发图像生成、文案创作等AIGC应用的团队而言,服务连续性至…...

TrollInstallerX:iOS内核漏洞利用与TrollStore安装技术深度解析
TrollInstallerX:iOS内核漏洞利用与TrollStore安装技术深度解析 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款基于内核漏洞利用的iO…...

如何轻松备份微信聊天记录:iOS用户的终极解决方案
如何轻松备份微信聊天记录:iOS用户的终极解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经因为手机损坏或更换设备而丢失了珍贵的微信聊天记…...

第一份工作选大厂还是创业公司?5年后的差距令人深思
对于刚刚走出校门的软件测试工程师而言,第一份工作的选择,如同一场没有回头路的开局落子。它不仅仅关乎起薪的高低,更将深刻塑造你的技术视野、职业习惯和未来五年的成长曲线。五年,足以让一个初出茅庐的新人成长为独当一面的技术…...
:降级策略与熔断保护,保证高峰期服务不被大图请求拖垮)
Pytorch图像去噪实战(八十):降级策略与熔断保护,保证高峰期服务不被大图请求拖垮
Pytorch图像去噪实战(八十):降级策略与熔断保护,保证高峰期服务不被大图请求拖垮 一、问题场景:高峰期几个大图请求,把整个服务拖慢 图像去噪服务在高峰期最怕两类请求: 超大图片 高质量模型请求 它们会占用大量 CPU/GPU 时间,导致普通小图请求也变慢。 这时如果没有…...

我跟踪了100位测试工程师的5年成长轨迹,发现成功者都踩准了这三个节点
五年,对于软件测试工程师而言,是一道清晰的分水岭。有人依然困在重复的手工用例里,薪资徘徊在行业均线以下;有人却完成了从执行者到架构者、从成本中心到价值中心的跃迁,成为团队里不可替代的角色。过去五年࿰…...

AI模型评估资源精选:从标准基准到定制化实践指南
1. 项目概述:为什么我们需要一个AI评估资源精选集?如果你最近也在折腾大语言模型,无论是想自己微调一个,还是想评估市面上哪个模型更适合你的业务场景,大概率会遇到一个头疼的问题:评估标准太多了ÿ…...

贾子理论体系:公理化东方智慧与现代科学工程化的认知范式
贾子理论体系:公理化东方智慧与现代科学工程化的认知范式摘要 贾子(本名贾龙栋,笔名Kucius)于2025–2026年间构建以“1-2-3-4-5”公理架构为核心的跨学科认知体系,涵盖思想主权元公理、两大规律、三大定律、四大支柱与…...

AI 搜索重新重视来源:内容平台的新机会不是被点击,而是被正确引用
生成式搜索刚出现时,很多内容创作者最担心的问题是:如果答案直接出现在搜索页,用户还会不会点进原文?这个担心并不多余。AI Overviews、AI Mode 和各类答案引擎,确实改变了“搜索结果页到网页”的传统路径。但现在更值…...