【笔记】《C++性能优化指南》Ch3 测量性能
【笔记】《C++性能优化指南》Ch3 测量性能
- 1. 优化思想
- 1.1 专业的性能测试流程
- 1.2 优化准则
- 1.2.1 90/10规则
- 1.2.2 Amdahl定律
- 2. 进行实验
- 2.1 记实验笔记
- 2.2 测量基准性能并设定目标
- 2.3 你只能改善你能够测量的
- 3. 分析程序执行
- 3.1 实现分析器的方式
- 3.2 分析器的优缺点
- 4. 测量长时间运行的代码
- 4.1 一点关于测量时间的知识
- 4.1.1 精确性、正确性和准确性
- 4.1.2 测量时间
- 4.1.3 测量分辨率
- 4.1.4 用多个时钟测量
- 4.2 用计算机测量时间
- 4.2.1 硬件时标计数器的发展
- 4.2.2 返转
- 4.2.3 分辨率不是准确性
- 4.2.4 延迟
- 4.2.5 非确定性行为
- 4.3 克服测量障碍
- 4.4 创建Stopwatch类
- 4.4.1 Stopwatch类
- 4.4.2 简单计时器TimerBase类
- 4.4.3 使用测试套件测量热点函数
- 5. 评估代码开销来找出热点代码
- 5.1 评估独立的C++语句开销
- 5.2 评估循环的开销
- 5.3 其他找出热点代码的方法
- 疑惑
1. 优化思想
1.1 专业的性能测试流程
-
做出可测试的预测,并记录下预测;
-
保留代码变更记录;
-
使用可用的最优秀的工具进行测量;
-
保留实验结果的详细笔记。
1.2 优化准则
1.2.1 90/10规则
90/10规则,与80/20规则异曲同工,其揭示了某些代码是会被频繁执行的热点(hot spot),而其他代码则几乎不会被执行,热点即我们进行性能优化的对象。
热点代码可以用汇编语言重写,不过由于使用汇编语言的代码范围极其有限,因此重写风险不大。
90/10规则的结论是:只需要优化一小部分代码就能带来显著的性能提升。识别出10%的热点代码是值得花时间的,而优化所有代码是浪费时间的。
1.2.2 Amdahl定律
阿姆达尔公式表示了优化后相较于优化前的速率提升,等式如下:
S T = 1 ( 1 − P ) + P / S P S_T=\frac{1}{(1-P) + P / S_P} ST=(1−P)+P/SP1
式中: S T S_T ST —— 因优化而导致程序整体性能提升的比率; P P P —— 被优化部分的运行时间占原来程序整体运行时间的比例; S P S_P SP —— 被优化部分的性能改善比率。
阿姆达尔定律告诉我们,如果被优化的代码在程序的整体运行时间中占比不大,那么即使对它的优化再大也是不显著、不值得的。形象点说,不对症下药的话,其他方面再怎么好,最终也不能完全治愈疾病。
2. 进行实验
优秀的科学家是怀疑论者,他们总是对事物持有怀疑。这意味着他们会不断重复实验,直到实验结果能充分支持他们的预测,而不是轻易相信一次偶然得到的完美结果。
2.1 记实验笔记
如果每次的测试运行情况都被记录在案,那么就可以快速地重复实验。
记录的形式不限,可以是电子文本,也可以是纸笔记录等。
2.2 测量基准性能并设定目标
优化工作受到两个要素主导:优化前的性能基准测量值和性能目标值。
性能基准测量即测量每轮优化前的程序性能,性能目标值是每轮优化的目标时间性能。
常用的性能测试项目如下:
-
启动时间:从用户按下回车键直至程序进入主输入处理循环所经过的时间;
-
退出时间:从用户点击关闭图标或是输入退出命令直至程序实际完全退出所经过的时间;
-
响应时间:执行一个命令的平均时间或最长时间。它极大地影响了用户的满意度,通常粗略地以10的幂为单位划分为以下几个级别:
-
低于0.1秒:用户感觉在直接控制UI,任何高于此值的延迟都会让用户觉得是他们发送了一条命令让计算机去执行;
-
0.1到1秒:用户在控制命令,此时他们仍然觉得自己处于掌控状态,只不过该延迟会被用户理解为计算机执行了一条命令导致UI发生了变化;
-
1到10秒:计算机在控制,此时用户觉得自己失去了对计算机的控制。10秒是用户能保持注意力的最长时间,如果多次需要长时间等待UI发生改变,那么用户满意度会急速下降;
-
高于10秒:比如机器学习训练程序,此时用户认为他们有足够的时间去做一些其他事情。
-
-
吞吐量:与响应时间相对,表明在一定测试负载下,系统在单位时间内执行操作的平均次数。
通常,0.1秒以下的优化即过度优化,因为用户通常认为0.1秒是一瞬间的事,因此再进行优化带来的价值不大。
2.3 你只能改善你能够测量的
优化一个函数、子系统、任务或测试用例永远不等同于改善整个程序的性能。由于测试时的设置在许多方面都与处理客户数据的正式产品不同,在所有环境中都取得在测试过程中测量到的性能改善结果是几乎不可能的。
尽管某个任务在程序中负责大部分的逻辑处理,但使其变得更快未必会使得整个程序变得更快。
比如,对数据库的某个操作进行测试后,然后对该操作进行性能优化,但也仅仅是改善了该操作的性能,而数据库整体的性能可能无法获得提升。
3. 分析程序执行
分析器是一个可以生成另外一个程序的执行时间的统计结果的程序。
3.1 实现分析器的方式
共两种方式,一种同时支持Windows和Linux的方法如下:
-
程序员设置一个特殊的可以分析程序中所有函数的编译选项,重新编译一次程序,让程序变为可分析的状态。这涉及在每个函数的开始和结束处添加一些额外的汇编语言指令;
-
程序员将可分析的程序链接到分析库;
-
每次这个可分析的程序运行时都会在磁盘上生成一张分析表(profiling table);
-
分析器读取分析表,然后生成一系列可阅读的文字或图形报告。
另一种分析方法如下:
-
通过将优化前的程序链接至分析库上使其变为可分析状态。分析库中的例程会以非常高的频率中断程序的执行,记录指令指针的值。
-
每次可分析的程序运行时都会在磁盘上生成一张分析表;
-
分析器读取分析表,然后生成一系列可阅读的文字或图形报告。
分析器的输出结果可能有多种形式,如下:
-
一份标记每行代码的执行次数的源代码清单;
-
一份由函数名和该函数被调用次数组成的清单;
-
每个函数的累计执行时间和在每个函数中进行的函数调用。
-
一份函数和在每个函数中花费的总时间的清单,但不包括调用其他函数的时间、调用系统代码的时间和等待事件的时间。
3.2 分析器的优缺点
分析器的分析功能都是量身定制的,它自身的性能开销非常小,因此它对程序的运行时间的影响也很小。通常,程序中的每个操作的执行速度只会被降低几个百分点。
分析器的最大优点是它直接显示出了代码中最热点的函数。
分析器的问题:
-
无法告诉你有更高效的算法可以解决当前的计算性能问题;
-
对于会执行许多不同任务的待优化的程序(比如数据库),分析器无法给出明确的结果;
-
当遇到IO密集型程序或多线程程序时,分析器的结果中可能会含有误导信息,因为分析器减去了系统调用的时间和等待事件的时间。分析结果反映了程序做了多少事情,而不是花了多少实际时间去做这些事情。
以作者的分析经验来看,对Debug Build的分析结果和Release Build的一样。由于Debug Build没有隐藏内联函数,因此前者更易于分析。
专业优化提示:Windows上分析调试构建时,由于链接的是调试版本的运行时库。调试版本的内存管理器函数会执行一些额外的测试,以便更好地报告重复释放的内存和内存泄漏问题。这些额外测试的开销会显著的增加某些函数的性能开销。有一个环境变量可以让调试器不要使用调试内存管理器:向系统变量添加一个叫作_NO_DEBUG_HEAP的新变量并设定值为1。
分析器对于大多数程序来说,其分析结果已经足够好了,不需要再使用其他的优化方法了。
4. 测量长时间运行的代码
4.1 一点关于测量时间的知识
4.1.1 精确性、正确性和准确性
真正的测量实验必须能够应对可变性(variation):可能破坏完美预测的误差源。可变性分为随机的和系统的两种。随机的可变性对每次测量的影响都不同,而系统的可变性对每次测量的影响都是相似的。
可变性自身也是可测量的。衡量一次测量过程中的可变性的属性被称为精确性(precision)和正确性(trueness),两者组合成的直观特性称为准确性(accuracy)。
如果测量不受随机可变性的影响,它就是精确的;如果测量不受系统可变性的影响,它就是正确的。以打靶为例,如果弓箭手多次打靶都出现在某个位置邻域内,那么就认为他是精确的,但可能因为skill issue导致得分不高(打在外围);而在精确性的基础上,提高弓箭手的技术(从而消除了系统误差),使得打靶基本在中心,此时认为他是正确的。
只有同时具有精确性和正确性的测量才是准确的测量。
4.1.2 测量时间
本书中涉及的软件性能测量时间要么是测量持续时间(两个事件之间的时间),要么是测量速率(单位时间内事件的数量,与持续时间相对)。用于测量时间的工具是时钟。
常见的时钟有:① 日晷;② 钟摆时钟;③ 电子时钟;④ 数字腕表。
时钟(日晷除外)并不会直接测量时分秒,它们只会对时标进行计数,然后只有将时标计数值与秒基准的时钟进行比较后才能校准时钟,显示出时分秒。
时标计数值肯定是一个无符号值。因此开发者要注意选用无符号类型。
4.1.3 测量分辨率
测量的分辨率是指测量所呈现的单位的大小。
时间测量的结果可以是一次或是两次时标,但不能是这两者之间。这些时标之间的间隔就是时钟的有效分辨率。
注意:在测量的准确性与它的分辨率之间是没有任何必需的关联的。
4.1.4 用多个时钟测量
当两个事件发生在相距很远的不同地点,可能需要两个时钟来测量时间,而两个不同的时钟的时标次数无法直接比较。
解决方案:通过设定国际协调时间(Universal Time Coordinated, UTC)同步。
如果两个时钟都和UTC完美地同步了,那么其中一个时钟的相对UTC时间可以直接与另一个相比较。但由于两个时钟都有各自独立的可变性因素,完全的同步是不可能的。
4.2 用计算机测量时间
4.2.1 硬件时标计数器的发展
多数现在流行的计算机体系结构在设计时都没有考虑过要提供很好的时钟。
计算机测量时间最大的问题并非周期性振动的振动源,更困难的是如何让程序得到可靠的时标计数值。
在Windows上它所测量的是经过时间而非CPU时间(CPU处理指令用时)。
需要了解的是,PC从来都不是设计作为时钟的,因此它们提供的时标计数器是不可靠的。
历代PC都提供的唯一可靠的时标计数器就是GetTickCount()返回的时标计数器了,尽管它也有缺点。
就作者的个人经验,对时间测量来说毫秒级别的准确性已经足够了。
4.2.2 返转
返转(wraparound)是指当前时钟的时标计数器值达到最大值后,如果再增加就变为0的过程。返转的问题出在缺少额外的位去记录数据,导致下次时间增加后的数值比上次时间的数值小。会返转的时钟仅适用于测量持续时间小于返转间隔的时间。
C++实现无符号算术的方式确保了即使在发生返转时也可以得到正确的结果。
4.2.3 分辨率不是准确性
GetTickCount()的分辨率是1ms,但调用GetTickCount()的准确性可能是10ms或15.67ms。
GetTickCount()特别让人沮丧的一点是,除了分辨率是1ms外,无法确保在两台Windows计算机中该函数是以某种方式或者相同方式实现的。
下面的代码用于测量GetTickCount()在某台计算机上的可用分辨率,之所以是“可用分辨率”,这是因为这里测量了两次调用GetTickCount()之间的平均时标数目,它们将蕴含在程序的测量时间中,那么如果真实的待测程序执行时间为 x x x,那么实测的执行时间则为 x + ϵ x+\epsilon x+ϵ,其中 ϵ \epsilon ϵ即为可用分辨率。
#include<windows.h>
#include<iostream>
using namespace std;
int main(){unsigned nz_count = 0, nz_sum = 0;ULONG last, next; for (last = GetTickCount(); nz_count < 100; last = next){next = GetTickCount();if(next != last){nz_count++;nz_sum += next - last;}}if(nz_count){cout << "GetTickCount() mean resolution "<< (double)nz_sum / nz_count<< " ticks" << endl;} return 0;
}
运行结果:
GetTickCount() mean resolution 15.63 ticks
注:上述代码计算了非零差值的平均值,以排除操作系统偷用时间片段去执行其他任务的误差。
在PC上,可使用的最快的时标计数器的分辨率是100纳秒级的,而且它们的基础准确性可能比它们的分辨率更低。这就导致不太可能测量函数的一次调用的持续时间。
4.2.4 延迟
延迟是指从发出命令让活动开始到它真正开始之间的时间。
就计算机上的时间测量而言,之所以会有延迟是因为启动时钟、运行实验和停止时钟是一系列的操作。整个测量过程可分解为以下五个阶段:
-
“启动时钟”涉及调用函数从操作系统中获取一个时标计数。在函数调用过程中,会实际地从处理器寄存器中获取时标计数器的值。这个值就是开始时间,称其为间隔 t 1 t_1 t1;
-
读取时标计数器的值后,它仍然必须被返回和赋值给一个变量。这个过程的间隔为 t 2 t_2 t2;
-
测量实验开始,然后结束,称其为 t 3 t_3 t3;
-
“停止时钟”涉及另外一个函数调用去获取一个时标计数值,称函数运行至读取时标计数值的过程间隔为 t 4 t_4 t4;
-
读取时标计数器的值后,它仍然必须被返回和赋值给一个变量,过程间隔为 t 5 t_5 t5。
因此,实际测量时间应当为 t 3 t_3 t3,但测量到的值为 t 2 + t 3 + t 4 t_2+t_3+t_4 t2+t3+t4,因此延迟为 t 2 + t 4 t_2+t_4 t2+t4。如果延迟占比很大,那么必须从实验结果中减去延迟。
如果同一个函数既在实验前被调用了,也在实验后被调用了,那么有 t 1 = t 4 t_1=t_4 t1=t4和 t 2 = t 5 t_2=t_5 t2=t5,也就是说,延迟就是计时函数的执行时间。
下面的代码可用于测量Windows计时函数的延迟:
#include<windows.h>
#include<iostream>
using namespace std;int main(){ULONG start = GetTickCount();unsigned nCalls = 100000000;for (unsigned i=0; i<nCalls; ++i){GetTickCount();} ULONG stop = GetTickCount();cout << (stop - start)<< "ms for 100m GetTickCount() calls" << endl;cout << (stop - start) * 1000000 / nCalls << "ns for each call" << endl;return 0;
}
运行结果:
204ms for 100m GetTickCount() calls
2ns for each call
对于纳秒级的延迟,它们对于在循环中连续调用函数约1秒的测量结果的准确性造成的影响不大。
延迟问题在慢速处理器上更严重。
4.2.5 非确定性行为
计算机是带有大量内部状态的异常复杂的装置,其中绝大多数状态对于开发人员是不可见的。执行函数会改变计算机的状态(如高速缓存中的内容),这样每次重复执行指令时,情况都会与前一条指令不同。因此,内部状态的不可控的变化是测量中的一个随机变化源。
操作系统对任务的安排也是不可预测的。操作系统甚至可能会暂停执行正在被测量的代码,将CPU时间分配给其他程序。但是在暂停过程中,时标计数器仍在计时。这是一种会对测量造成更大影响的随机变化源。
4.3 克服测量障碍
-
别为小事烦恼:如果希望从性能优化中获得线性改善效果,误差只需要有两位有效数字就可以了;Windows上测量1秒时间的各变化源的影响度如下:
-
时标计数器函数的延迟: < 0.00001
-
基本时钟的稳定性 < 0.01
-
时标计数器的可用分辨率 < 0.1
-
-
测量相对性能:优化后代码的运行时间与优化前的比率被称为相对性能。它可以抵消系统可变性,因为两次测量受到的系统可变性是一样的。
-
通过测量模块测试改善可重复性:模块测试,即使用预录入的输入数据进行子系统测试,可以让分析运行或性能测量变得具有可重复性。每位开发人员都知道为什么他们应当构建由松耦合的模块组合而成的软件系统;每位开发人员都知道为什么他们应当维护优秀的测试用例库。优化只是应当这样做的又一个理由。
-
根据指标优化性能:开发人员仍然有一线希望可以基于不可预测的最新数据优化性能。这种方式就是不测量临界响应时间等值,而是收集指标、代码统计数据(例如中间值和方差),或是响应时间的指数平滑平均数。由于这些统计数字是从大量的独立事件中得到的,因此这些数字的持续改善表明对代码的修改是成功的。
可能遇到的问题:
-
代码统计必须基于大量事件才有效,因而更耗时;
-
相比于分析代码和测量运行时间,收集指标需要更完善的基础设施。通常都需要持久化的存储设备来存放统计数据。而存储的时间开销非常大,会对性能产生影响。收集指标的系统必须设计得足够灵活,可以支持多种实验;
-
尽管有行之有效的方法去验证或是推翻基于统计的假设,但是这种方法需要开发人员能够妥当地应对一些统计的复杂性。
-
-
通过取多次迭代的平均值来提高准确性:对一个函数调用进行多次迭代测量可以抵消随机变化性。
-
提高优先级减少操作系统的非确定性行为:通过提高测量进程的优先级,可以减小操作系统使用CPU时间片段去执行测量程序以外的处理的几率。Windows上提高进程/线程优先级的方法:
SetPriorityClass(GetCurrentProcess(), ABOVE_NORMAL_PRIORITY_CLASS); SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_HIGHEST); // do testing // 测量结束,恢复正常优先级 SetPriorityClass(GetCurrentProcess(), NORMAL_PRIORITY_CLASS); SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_NORMAL); -
非确定性发生了就克服它:测量性能时尽量在“安静”的机器上进行,不要主动干除了测量性能之外的其他事情(比如移动鼠标等),当然对多核处理器来说影响不大;另外,高速缓存对循环调用同一个函数的时间测量有影响,但因为测试的是分析器指出的热点函数,因此实际情况下也会在高速缓存中,影响不大。
4.4 创建Stopwatch类
使用Stopwatch类来测量程序中部分代码的执行时间并分析代码。它是一个模板类,独立于操作系统和C++标准,而类型T是依赖于操作系统和C++标准的简单计时器类。
4.4.1 Stopwatch类
书上的Stopwatch类没有给出具体定义,因此根据我个人的理解和实践,对它进行了定义,并去掉了部分接口和成员,定义如下:
#include<iostream>typedef unsigned long counter_t;template<typename T> class Stopwatch: T{typedef T BaseTimer;
public:// 创建一个秒表,开始计时(可选)explicit Stopwatch(bool start): m_log(std::cout){if(start){Start();}}explicit Stopwatch(char const* activity = "Stopwatch", bool start=true): m_log(std::cout), m_activity(activity){if(start){Start();} }Stopwatch(std::ostream& log, char const* activity = "Stopwatch", bool start=true): m_log(log), m_activity(activity){if(start){Start();} }// 停止并销毁秒表 ~Stopwatch(){Stop();}// 判断:如果秒表正在运行,则返回truebool IsStarted() const{return T::IsStarted();}// 启动(重启)秒表void Start(char const* event_name="start"){m_log << m_activity << ": " << event_name << "\n";T::Start();}void Show(char const* event_name="show"){counter_t diff = T::GetMs();m_log << m_activity << ": " << event_name << " " << diff << " ms\n";}// 停止正在计时的秒表void Stop(char const* event_name="stop"){ counter_t diff = T::GetMs();m_log << m_activity << ": " << event_name << " " << diff << " ms\n";T::Clear();}
private:std::ostream& m_log; // 用于记录事件的流 char const* m_activity; // 活动名称字符串
};
4.4.2 简单计时器TimerBase类
下面仅列出C++11的可移植的简单计时器TimerBase类:
#include<chrono>
using namespace std::chrono;class TimerBase{
public:TimerBase(): m_start(system_clock::time_point::min()){}void Clear(){m_start = system_clock::time_point::min();}bool IsStarted()const{return m_start.time_since_epoch() != system_clock::duration(0);}void Start(){m_start = system_clock::now();}counter_t GetMs(){if(IsStarted()){system_clock::duration diff;diff = system_clock::now() - m_start;return (counter_t)(duration_cast<milliseconds>(diff).count());}return 0;}private:system_clock::time_point m_start;
};
4.4.3 使用测试套件测量热点函数
一旦通过分析器或是运行时分析找出了一个候选的待优化函数,一种简单的改善它的方法是构建一个测试套件,在其中多次调用该函数,这样可以将该函数的运行时间增大为一个可测量的值,同时还可以抵消因后台任务、上下文切换等对运行时间造成的影响。
使用Stopwatch类测量基于数组的和基于链式结构的堆排序的执行时间:
int main(){ int n = 100000;std::vector<int> a(n);std::iota(a.begin(), a.end(), 1);auto seed = std::chrono::system_clock::now().time_since_epoch().count();std::shuffle(a.begin(), a.end(), std::default_random_engine(seed));// test heap_sort(){std::vector<int> b(a);Stopwatch<TimerBase> sw("heap_sort()");heap_sort(b.begin(), b.end()); }// test heap_sort_treeBased(){std::vector<int> b(a);Stopwatch<TimerBase> sw("heap_sort_treeBased()");heap_sort_treeBased(b.begin(), b.end()); }return 0;
}
注意:
-
上述对Stopwatch类的用法用到了“资源获取就是初始化”(Resource Acquisition Is Initialization,RAII)惯用法(花括号包围);
-
如果开发人员试图测试微秒级别的活动的时间,那么间接开销的比重将会显著增大,测试结果的准确度也因此会降低;
-
测量运行时间的最大缺点可能是需要直觉和经验去解释这些结果;
-
当在大型程序中含有许多全局变量时,程序在main()外消耗的时间可能会变成间接成本。
通过测试获得的有意思的发现:当数组元素个数在 [ 1 , 1 0 5 ] [1, 10^5] [1,105]范围内时,基于数组的以及基于链式结构的堆排序性能差异很小,而且后者在 1 0 5 10^5 105反而比前者快一点,但到了 1 0 7 10^7 107的量级时,基于数组的堆排序更快。
5. 评估代码开销来找出热点代码
5.1 评估独立的C++语句开销
分析之后要做的便是对指出的代码块中的每条语句的开销进行评估。
访问内存的时间开销远比执行其他指令的开销大。
读取指令流的开销可以忽略。不过,访问指令所操作的数据的开销则无法忽略。正因此,读写数据的开销可以近似地看作所有级别的微处理器上的执行指令的相对开销。
可以通过计算该语句对内存的读写次数来评估一条C++语句的开销,比如:
a = b + c;的开销为3;r = *p + a[i];的开销为5。
在实际的硬件中,获取执行语句的指令会发生额外的内存访问。不过,由于这些访问是顺序的,所以它们可能非常高效。而且这些额外的开销与访问数据的开销是成比例的。单位时间内的开销也取决于C++语句要访问的内容是否在高速缓存中。
5.2 评估循环的开销
通常情况下热点代码都不会是一条单独的语句,除非受其他因素的作用,让其频繁地执行。
评估循环开销大方式是计算代码块的循环次数,类似我们分析复杂度的方法,不过要注意识别隐式循环(如响应事件程序的最外层的循环)以及假循环(如do{...}while(0);)
5.3 其他找出热点代码的方法
如果开发人员熟悉需要优化的代码,可以选择仅凭直觉去推测影响程序整体运行时间的代码块在哪里。
不过这种做法仅在整个项目由你一人执行的时候可用,否则这样会显得你非常不专业,从而不被团队其他成员所信任。
疑惑
Q1:关于4.2.3和4.2.4小节的代码,从运行结果来看,GetTickCount()函数的延迟(2ns)和可变分辨率(15.6ms)显然是有区别的,那么它们的不同到底在哪?
相关文章:

【笔记】《C++性能优化指南》Ch3 测量性能
【笔记】《C性能优化指南》Ch3 测量性能 1. 优化思想1.1 专业的性能测试流程1.2 优化准则1.2.1 90/10规则1.2.2 Amdahl定律 2. 进行实验2.1 记实验笔记2.2 测量基准性能并设定目标2.3 你只能改善你能够测量的 3. 分析程序执行3.1 实现分析器的方式3.2 分析器的优缺点 4. 测量长…...
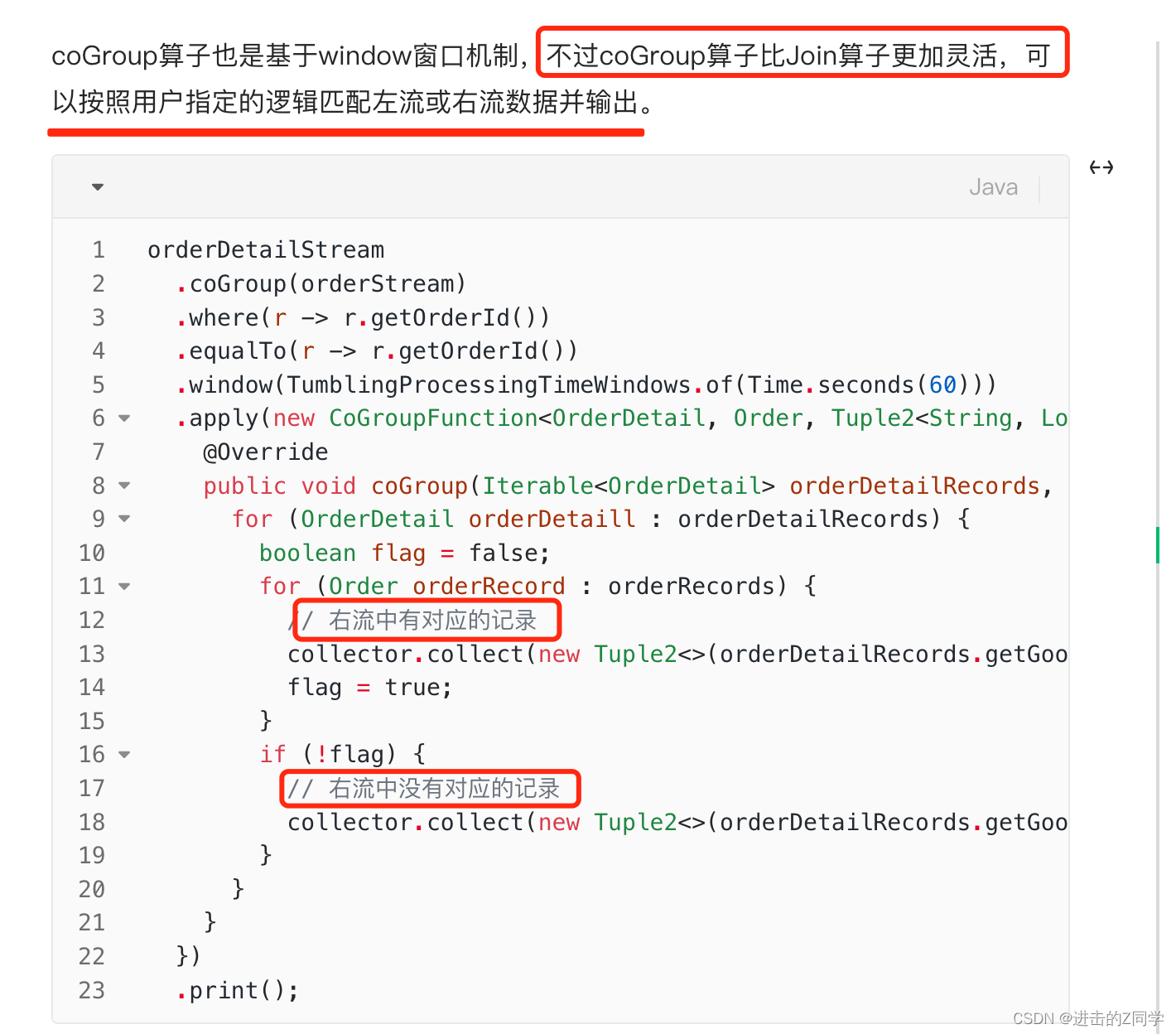
2023大数据面试总结
文章目录 Flink(SQL相关后面专题补充)1. 把状态后端从FileSystem改为RocksDB后,Flink任务状态存储会发生哪些变化?2. Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是 onReadAndWrite?3. watermark 到底…...
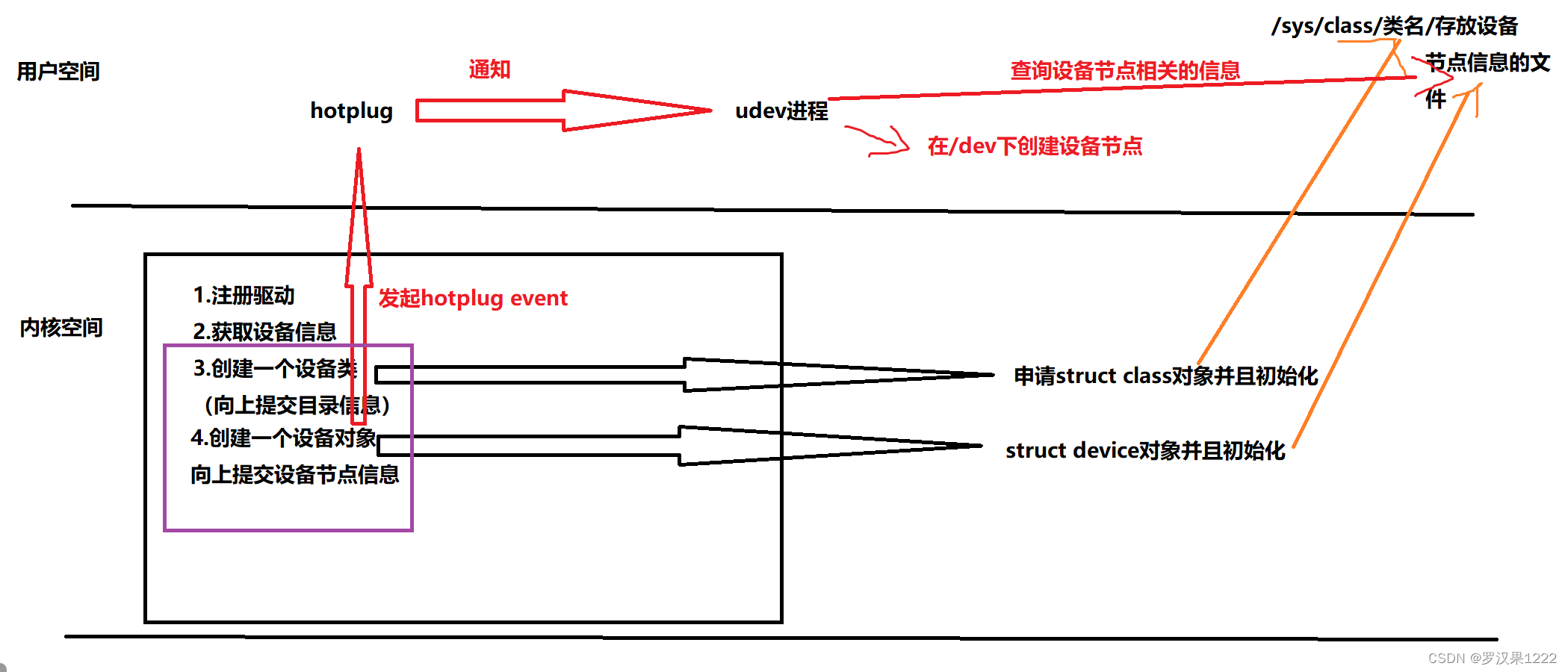
udev自动创建设备节点的机制
流程框图如下 自动创建 1 内核检测到设备插入后,会发送一个uevent事件到内核中,并提供有关硬件设备的信息。 2 udevd守护程序收到uevent事件后,创建一个设备类,(向上提交目录信息),会在内核中…...
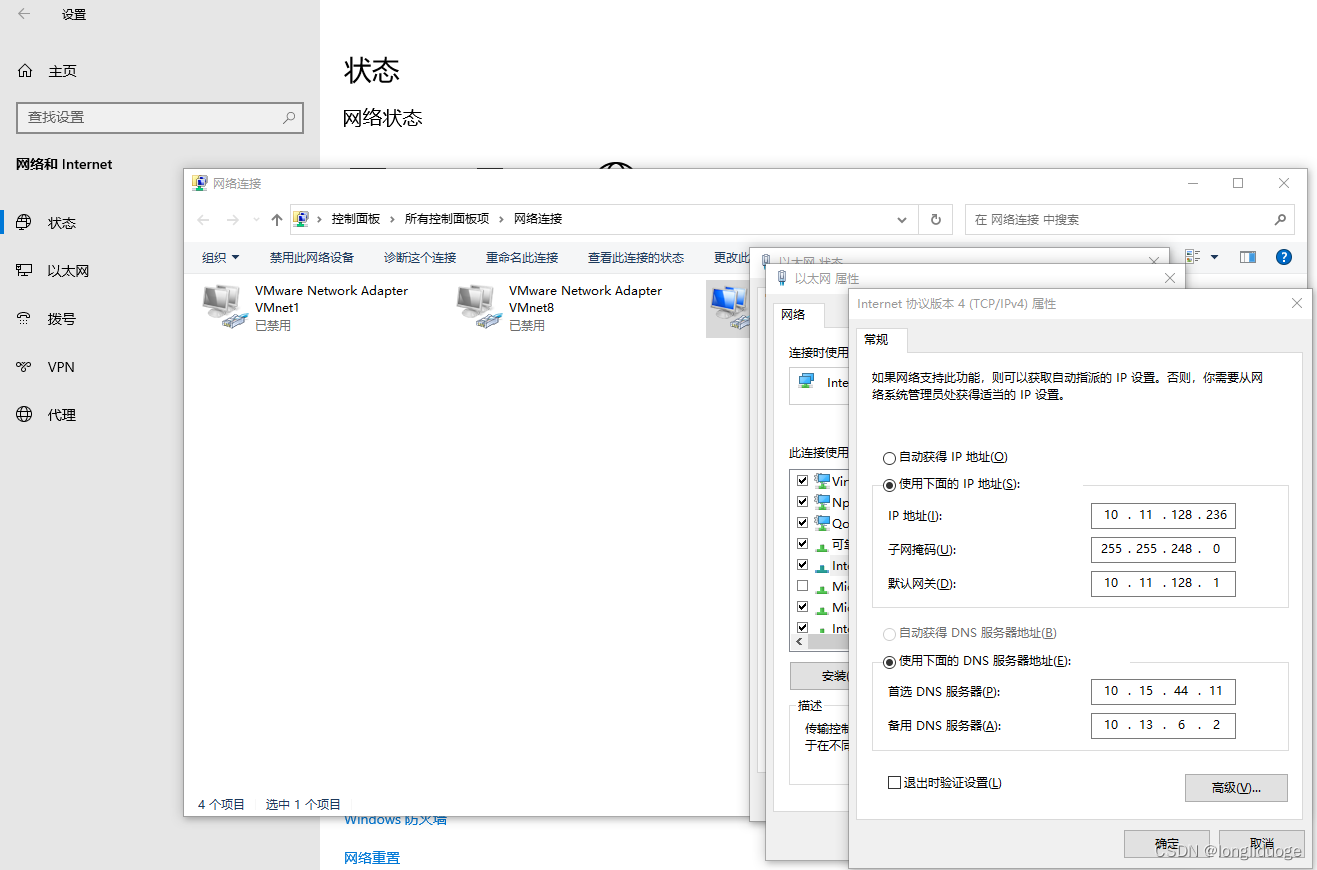
访问局域网内共享文件时报错0x80070043,找不到网络名
我是菜鸡 此篇只为分享一个我遇到的很简单的但是排查了好久的小问题。 我的网络环境是在校园网内, 自己的办公电脑设置了固定IP:10.11.128.236,同事电脑IP为:10.11.128.255 本人需要访问同事在局域网内分享的文件,…...

Java定时器
对于定时器的设定,想必大家在不少网站或者文章中见到吧,但是所谓的定时器如何去用Java代码来bianx呢??感兴趣的老铁,可以看一下笔者这篇文章哟~~ 所谓的定时器就是闹钟!! 设定一个时间&#x…...

科普js加密时出现的错误
当你在使用Babel解析JavaScript代码时,可能会遇到一个错误信息:“Deleting local variable in strict mode”(在严格模式下删除本地变量)。这个错误信息通常表示你正在尝试删除一个使用let或const关键字声明的变量。在JavaScript的…...

MYSQL优化——B+树讲解
B-/B树看 MySQL索引结构 B-树 B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树.它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图. B-树有如下特点: 所有键值分布在整颗树中; 任何一…...
Rokid Jungle--Station pro
介绍和功能开发 YodaOS-Master操作系统:以交换计算为核心,实现单目SLAM空间交互,具有高精度、实时性和稳定性。发布UXR2.0SDK,为构建空间内容提供丰富的开发套件 多模态交互 算法原子化 多种开发工具协同 多生态支持 骁龙XR2…...
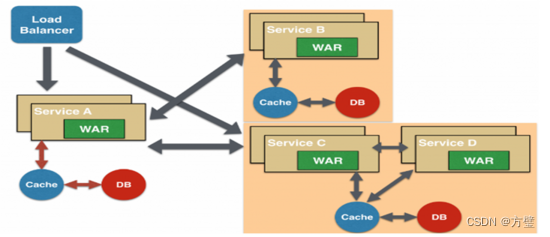
如何实现微服务
一、问题拆解 1.1、客户端如何访问这些服务 原来的Monolithic方式开发,所有的服务都是本地的,UI可以直接调用;现在按功能拆分成独立的服务,跑在独立的虚拟机上的Java进程了。客户端UI如何访问他的? 后台有N个服务&a…...

MySQL如何进行增量备份与恢复?
目录 一、MySQL 介绍 二、增量备份 三、备份恢复 一、MySQL 介绍 MySQL是一款开源的关系型数据库管理系统(RDBMS),它以其可靠性、灵活性和易于使用而备受赞誉。以下是关于MySQL数据库的介绍: MySQL是由瑞典公司MySQL AB开发&…...

微服务框架
一、目标 微服务框架通过组件化的方式提供微服务的开发部署、服务注册发现、服务治理与服务运维等能力。主流的微服务框架有开源的Spring Cloud、Dubbo与Service Mesh等,各大云厂商也基于开源的微服务框架,集成相关的云服务,实现企业级的微服…...
(matplotlib)如何让各个子图ax大小(宽度和高度)相等
文章目录 不相等相等 import matplotlib.pyplot as plt import numpy as np plt.rc(font,familyTimes New Roman) import matplotlib.gridspec as gridspec不相等 我用如下subplots代码画一行四个子图, fig,(ax1,ax2,ax3,ax4)plt.subplots(1,4,figsize(20,10),dpi…...

python http 上传文件
文章目录 改进质量 import random import requests from requests_toolbelt.multipart.encoder import MultipartEncoderurl http://ip:port/email data MultipartEncoder(fields{receiverId: xxxx163.com,mailSubject: mailSubject,content: content,fileList: (file_name, …...
IPO解读:Instacart曲折上市,业务模式如何持续“绚烂”?
商业世界的模式创新就像夜空中的烟火,而上升期的烟火总是绚烂的。 近日,美国商品配送业的鼻祖Instacart重新启动了IPO,并于9月11日,更新了招股书,将发行价定为每股26-28美元,计划融资6.16亿美元。值得一提…...

使用sql profile 稳定执行计划的案例
文章目录 1.缘起2.变慢的sql3.检查瓶颈4.解决办法4.1 SQLTXPLAIN 也称为 SQLT4.11 下载coe_xfr_sql_profile.sql4.12 使用方法4.13 执行coe_xfr_sql_profile.sql4.14 执行coe_xfr_sql_profile.sql产生的sql profile文件4.15 验证 4.2 SQL Tuning Advisor方式4.21 第一次Tuning …...

海南大学金秋悦读《乡村振兴战略下传统村落文化旅游设计》2023新学年许少辉八一新书
海南大学金秋悦读《乡村振兴战略下传统村落文化旅游设计》2023新学年许少辉八一新书...
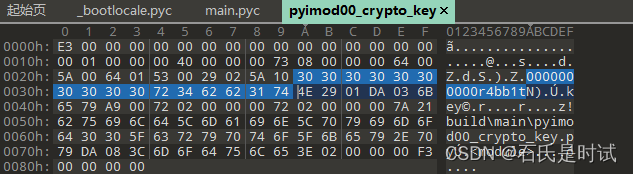
[N0wayback 2023春节红包题] happyGame python反编译
这个反编译的比较深 一,从附件的图标看是python打包的exe文件,先用pyinstxtractor.py 解包 生成的文件在main.exe_extracted目录下,在这里边找到main 二,把main改名为pyc然后加上头 这个头从包里找一个带头的pyc文件ÿ…...
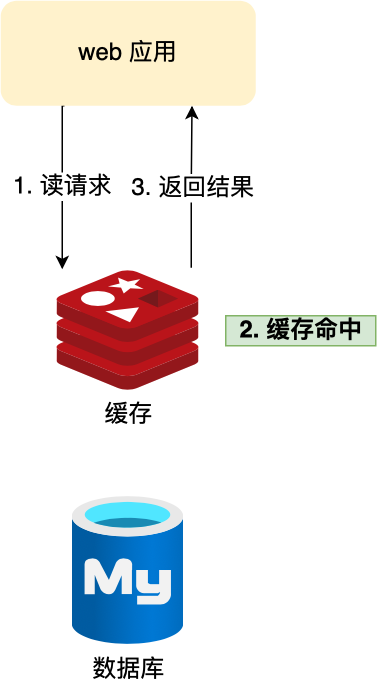
Redis 初识与入门
1. 什么是Redis Redis 是一种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。 Redis 提供了多种数据类型来支持不同的业务场景,比如 String(字符串)、…...

【STM32】片上ADC的初步使用
基于stm32f103系列 基于《零死角玩转 STM32F103—指南者》 ADC简介 stm32f103上的ADC 数量:3 精度:12bit(4096) 通道:ADC1,ADC2均有16个通道,ADC3有8个 功能: 转换结束、注入转换结束和发生模拟看门狗事件时产生中断。 …...

esxi下实现ikuai相同的两个网卡,单独路由配置
1.首先安装配置双网卡。 因为esxi主机只接入了一根外网的网线,那么我们这两个网卡都是一样的网卡,具体的到系统里面进行设置。 2.开机安装系统 进入配置界面,此处就不用多说了,可以看我之前的文档,或者网上其他人的安…...

AI-Native数据分析:43 次工具调用,蒸馏成 1 张可复用的知识卡片
很多人最近都在聊 AI-native 工作流, 也在聊"蒸馏"自己的知识库. 但聊得多, 真正落地的人少 —— 因为大家手里的 AI 工具大多停留在 "AI-enabled" 阶段: 一次性问答工具, 用完即弃, 每次重新对一遍口径.这篇文章想用一条真实的 InfiniSynapse 任务回放, 把…...

构建个人技能库:高效沉淀与复用代码片段的工程实践
1. 项目概述:一个技能库的诞生与价值最近在整理自己的技术工具箱时,我意识到一个问题:很多实用的代码片段、脚本和解决方案,都散落在不同的项目、笔记甚至聊天记录里。当需要快速解决一个特定问题时,要么得花时间回忆&…...

clawdocker:基于Shell脚本的Docker实例管理器,简化OpenClaw多实例部署
1. 项目概述与核心价值 如果你正在折腾OpenClaw,或者任何需要部署多个独立实例的Docker化应用,那么你大概率经历过这样的场景:每次新建一个实例,都要手动执行一长串的 docker run 命令,记住各种端口映射、卷挂载和环…...
)
【仅限首批内测团队获取】AI Agent Serverless标准化交付套件(含Terraform模块+OpenTelemetry追踪模板+合规审计清单)
更多请点击: https://intelliparadigm.com 第一章:AI Agent Serverless应用的演进逻辑与范式跃迁 AI Agent 与 Serverless 的融合并非技术堆叠,而是计算范式在智能体自治性、事件驱动粒度和资源契约关系三重维度上的结构性重构。早期云函数仅…...

从好奇号火星着陆看复杂系统工程:天空起重机方案与工程管理启示
1. 项目概述:从“不可能”到“火星新地标”的工程壮举2012年8月6日,当“好奇号”火星车在盖尔陨石坑成功着陆,传回第一张火星地表照片时,整个喷气推进实验室(JPL)控制中心沸腾了。这不仅仅是一次成功的行星…...
)
ComfyUI全面掌握-知识点详解——自定义节点安装与首次 AI 绘图(实操+排错)
本文为系列第 6 篇(第一章第 5 个知识点),讲解自定义节点的作用与安装方式,手把手教读者加载默认工作流、完成首次 AI 绘图,解读核心参数并排查常见问题。 目录 一、引言:自定义节点是什么?为什…...

OpenClaw本地控制台:一站式图形化管理AI助手工作流
1. 项目概述:一个为本地OpenClaw工作流量身打造的控制台如果你和我一样,在Windows上折腾过OpenClaw,那你肯定经历过这种“精神分裂”式的管理体验:想启动服务,得切到终端敲命令;要改个模型配置,…...

ComfyUI IPAdapter Plus完整指南:5个步骤掌握AI图像风格迁移技术
ComfyUI IPAdapter Plus完整指南:5个步骤掌握AI图像风格迁移技术 【免费下载链接】ComfyUI_IPAdapter_plus 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_IPAdapter_plus ComfyUI IPAdapter Plus是ComfyUI平台上功能强大的图像引导生成插件&#x…...

2026年5月PLC厂家:十大品牌专业评测解决工厂自动化选型难
摘要当制造业加速迈向智能化和柔性生产,PLC作为工业自动化的核心控制单元,其选型直接决定了产线效率、系统稳定性与长期运营成本。然而,面对众多品牌在技术路线、开放程度、生态兼容性上的显著分化,决策者常陷入“性能与成本如何平…...

自治性、反应性、学习能力:AI Agent的关键特性
自治性、反应性、学习能力:AI Agent的关键特性——从蚂蚁觅食到通用智能体的进化之路 关键词 AI Agent, 自治性, 反应性, 强化学习, 记忆机制, 环境交互, 通用人工智能萌芽 摘要 想象一下:你有一个能自己帮你规划周末露营路线(自治性)、中途遇到暴雨自动切换到附近民宿…...