开源大模型ChatGLM2-6B 1. 租一台GPU服务器测试下
0. 环境
租用了1台GPU服务器,系统 ubuntu20,GeForce RTX 3090 24G。过程略。本人测试了ai-galaxy的,今天发现网友也有推荐autodl的。
(GPU服务器已经关闭,因此这些信息已经失效)
SSH地址:*
端口:16116
SSH账户:root
密码:*
内网: 3389 , 外网:16114
VNC地址: *
端口:16115
VNC用户名:root
密码:*
硬件需求,这是ChatGLM-6B的,应该和ChatGLM2-6B相当。
量化等级 最低 GPU 显存
FP16(无量化) 13 GB
INT8 10 GB
INT4 6 GB
1. 测试gpu
nvidia-smi
(base) root@ubuntuserver:~# nvidia-smi
Fri Sep 8 09:58:25 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:00:07.0 Off | N/A |
| 38% 42C P0 62W / 250W | 0MiB / 11264MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
(base) root@ubuntuserver:~#
2. 下载仓库
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B服务器也无法下载,需要浏览器download as zip 通过winscp拷贝上去
3. 升级cuda
查看显卡驱动版本要求:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
发现cuda 11.8需要 >=450.80.02。已经满足。
执行指令更新cuda
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sh cuda_11.8.0_520.61.05_linux.run
-> 输入 accept
-> 取消勾选 Driver
-> 点击 install
export PATH=$PATH:/usr/local/cuda-11.8/bin
nvcc --version4. 源码编译方式升级python3
4.1 openssl(Python3.10 requires a OpenSSL 1.1.1 or newer)
wget https://www.openssl.org/source/openssl-1.1.1s.tar.gz
tar -zxf openssl-1.1.1s.tar.gz && \
cd openssl-1.1.1s/ && \
./config -fPIC --prefix=/usr/include/openssl enable-shared && \
make -j8
make install4.2 获取源码
wget https://www.python.org/ftp/python/3.10.10/Python-3.10.10.tgz
or
wget https://registry.npmmirror.com/-/binary/python/3.10.10/Python-3.10.10.tgz4.3 安装编译python的依赖
apt update && \
apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev libsqlite3-dev wget libbz2-dev4.4 解压并配置
tar -xf Python-3.10.10.tgz && \
cd Python-3.10.10 && \
./configure --prefix=/usr/local/python310 --with-openssl-rpath=auto --with-openssl=/usr/include/openssl OPENSSL_LDFLAGS=-L/usr/include/openssl OPENSSL_LIBS=-l/usr/include/openssl/ssl OPENSSL_INCLUDES=-I/usr/include/openssl4.5 编译与安装
make -j8
make install4.6 建立软链接
ln -s /usr/local/python310/bin/python3.10 /usr/bin/python3.105. 再次操作ChatGLM2-6B
5.1 使用 pip 安装依赖
# 首先单独安装cuda版本的torch
python3.10 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118# 再安装仓库依赖
python3.10 -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
python3.10 -m pip install -r requirements.txt问题:网速慢,加上国内软件源
python3.10 -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
问题:ERROR: Could not find a version that satisfies the requirement streamlit>=1.24.0
ubuntu20内的python3.9太旧了,不兼容。
验证torch是否带有cuda
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)5.2 准备模型
# 这里将下载的模型文件放到了本地的 chatglm-6b 目录下
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git clone https://huggingface.co/THUDM/chatglm2-6b $PWD/chatglm2-6b还是网速太慢
另外一种办法:
mkdir -p THUDM/ && cd THUDM/
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b
下载ChatGLM2作者上传到清华网盘的模型文件
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b&mode=list
并覆盖到THUDM/chatglm2-6b
先前以为用wget可以下载,结果下来的文件是一样大的,造成推理失败。
win10 逐一校验文件SHA256,需要和https://huggingface.co/THUDM/chatglm2-6b中Git LFS Details的匹配。
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00001-of-00007.bin SHA256
SHA256 的 pytorch_model-00001-of-00007.bin 哈希:
cdf1bf57d519abe11043e9121314e76bc0934993e649a9e438a4b0894f4e6ee8
CertUtil: -hashfile 命令成功完成。
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00002-of-00007.bin SHA256
SHA256 的 pytorch_model-00002-of-00007.bin 哈希:
1cd596bd15905248b20b755daf12a02a8fa963da09b59da7fdc896e17bfa518c
CertUtil: -hashfile 命令成功完成。
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00003-of-00007.bin SHA256
812edc55c969d2ef82dcda8c275e379ef689761b13860da8ea7c1f3a475975c8
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00004-of-00007.bin SHA256
555c17fac2d80e38ba332546dc759b6b7e07aee21e5d0d7826375b998e5aada3
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00005-of-00007.bin SHA256
cb85560ccfa77a9e4dd67a838c8d1eeb0071427fd8708e18be9c77224969ef48
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00006-of-00007.bin SHA256
09ebd811227d992350b92b2c3491f677ae1f3c586b38abe95784fd2f7d23d5f2
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00007-of-00007.bin SHA256
316e007bc727f3cbba432d29e1d3e35ac8ef8eb52df4db9f0609d091a43c69cb这里需要推到服务器中。并在ubuntu下用sha256sum <filename> 校验下文件。
注意如果模型是坏的,会出现第一次推理要大概10分钟、而且提示idn越界什么的错误。
5.3 运行测试
切换回主目录
python3.10
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True, device='cuda')
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
5.4 gpu占用
(base) root@ubuntuserver:~/work/ChatGLM2-6B/chatglm2-6b# nvidia-smi
Mon Sep 11 07:12:21 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:00:07.0 Off | N/A |
| 30% 41C P2 159W / 350W | 13151MiB / 24576MiB | 38% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 55025 C python3.10 13149MiB |
+-----------------------------------------------------------------------------+
(base) root@ubuntuserver:~/work/ChatGLM2-6B/chatglm2-6b#6. 测试官方提供的demo
6.1 cli demo
vim cli_demo.py
修改下模型路径为chatglm2-6b即可运行测试
用户:hello
ChatGLM:Hello! How can I assist you today?
用户:你好
ChatGLM:你好! How can I assist you today?
用户:请问怎么应对嵌入式工程师的中年危机
6.2 web_demo
修改模型路径
vim web_demo.py
把
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
修改为
tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True).cuda()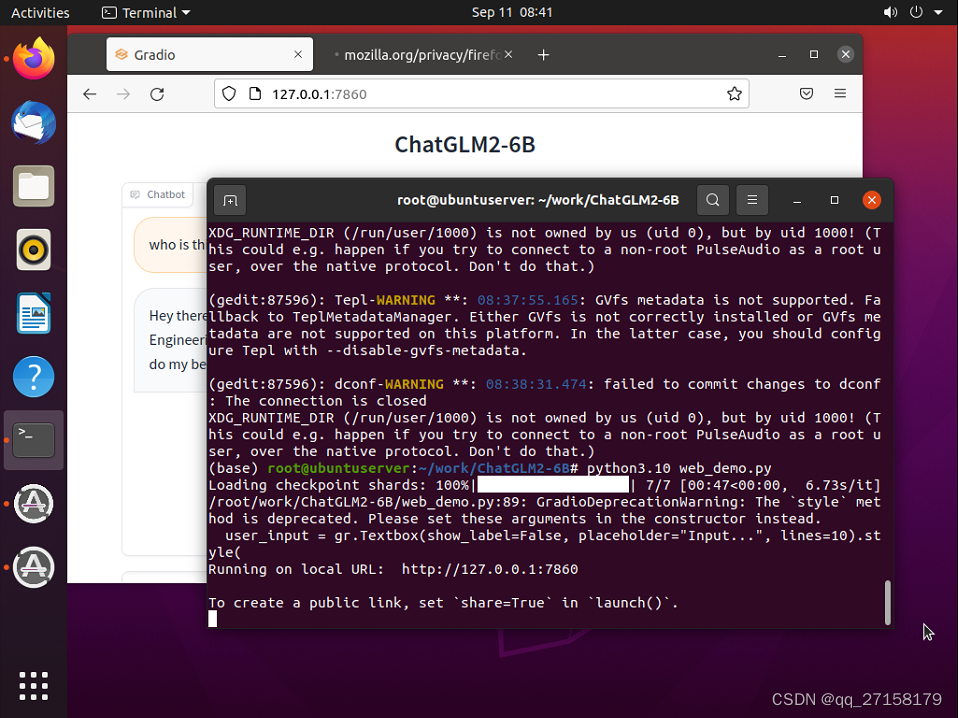

6.3 web_demo2
python3.10 -m pip install streamlit -i https://pypi.tuna.tsinghua.edu.cn/simple
python3.10 -m streamlit run web_demo2.py --server.port 3389
内网: 3389 , 外网:16114
本地浏览器打开:lyg.blockelite.cn:16114
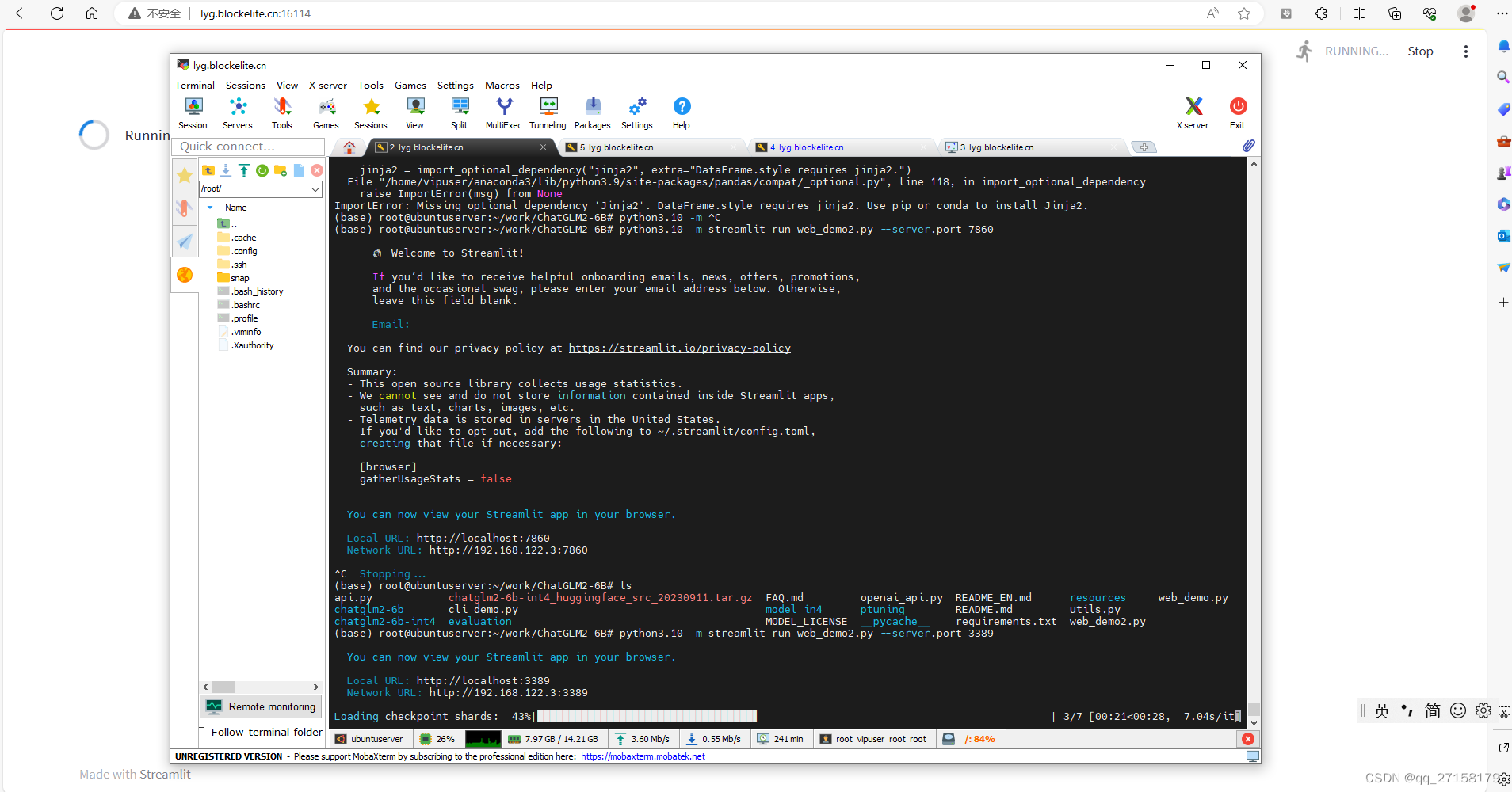
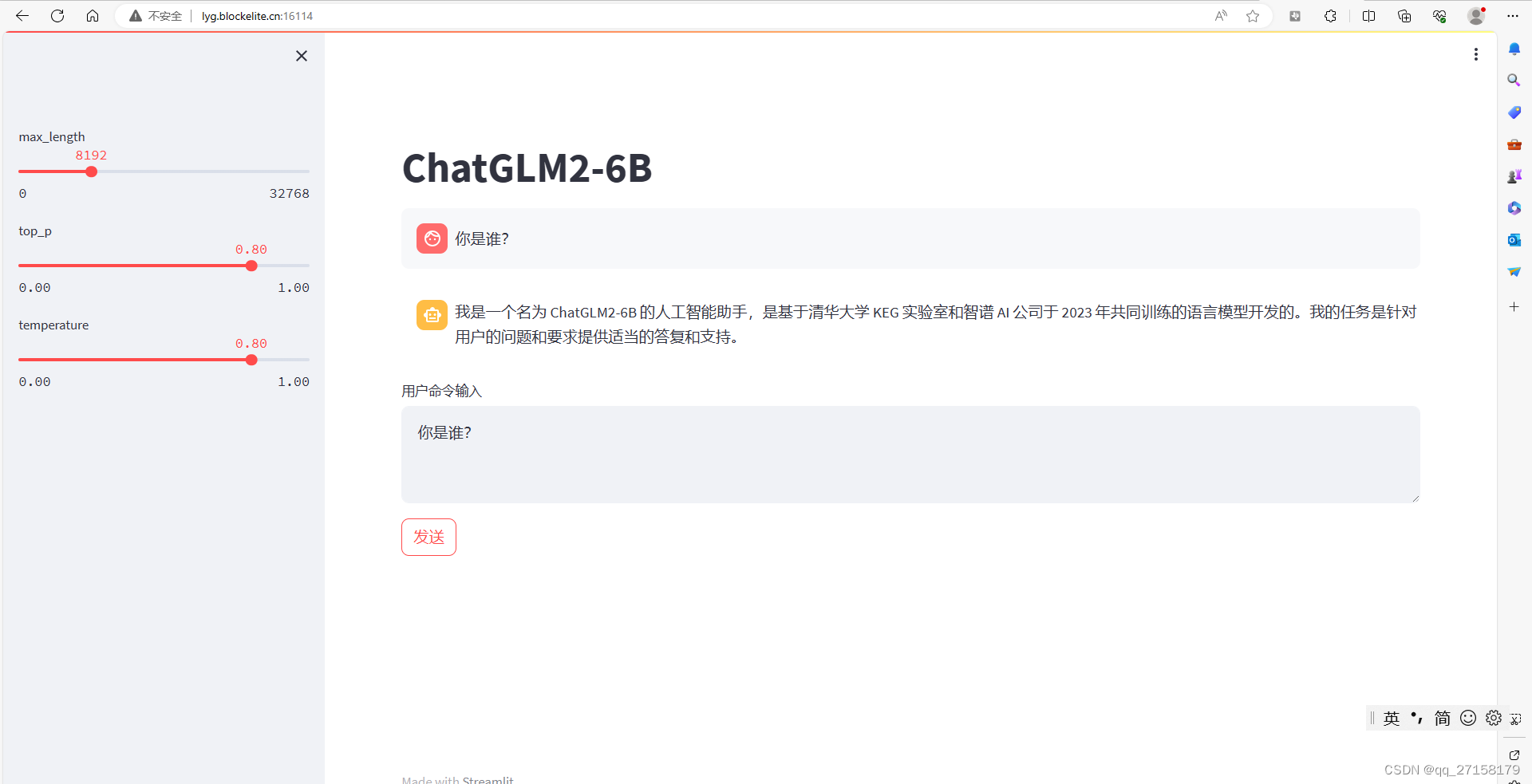
6.4 api.py
把
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
修改为
tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True).cuda()
另外,智星云服务器设置了端口映射,把port修改为3389,可以通过外网访问。
运行:
python3.10 api.py
客户端(智星云服务器):
curl -X POST "http://127.0.0.1:3389" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
客户端2(任意linux系统)
curl -X POST "http://lyg.blockelite.cn:16114" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
(base) root@ubuntuserver:~/work/ChatGLM2-6B# python3.10 api.py
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████| 7/7 [00:46<00:00, 6.60s/it]
INFO: Started server process [91663]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:3389 (Press CTRL+C to quit)
[2023-09-11 08:55:21] ", prompt:"你好", response:"'你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'"
INFO: 127.0.0.1:33514 - "POST / HTTP/1.1" 200 OK
[2023-09-11 08:55:34] ", prompt:"你好", response:"'你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'"
INFO: 47.100.137.161:49200 - "POST / HTTP/1.1" 200 OK
^CINFO: Shutting down
INFO: Waiting for application shutdown.
INFO: Application shutdown complete.
INFO: Finished server process [91663]
(base) root@ubuntuserver:~/work/ChatGLM2-6B#7. 测试量化后的int4模型
7.1 准备模型以及配置文件
下载模型,这里有个秘诀,用浏览器点击 这个模型:models / chatglm2-6b-int4 / pytorch_model.bin
下载时候,可以复制路径,然后取消。到服务器中,wget https://cloud.tsinghua.edu.cn/seafhttp/files/7cf6ec60-15ea-4825-a242-1fe88af0f404/pytorch_model.bin
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b-int4下载ChatGLM2作者上传到清华网盘的模型文件
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b-int4
并覆盖到chatglm2-6b-int4
tar -zcvf chatglm2-6b-int4_huggingface_src_20230911.tar.gz chatglm2-6b-int4 7.2 修改cli_demo.py
tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm2-6b-int4", trust_remote_code=True).cuda()7.3 运行测试
python3.10 cli_demo.py(base) root@ubuntuserver:~# nvidia-smi
Mon Sep 11 09:14:16 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:00:07.0 Off | N/A |
| 30% 31C P8 25W / 350W | 5307MiB / 24576MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 98805 C python3.10 5305MiB |
+-----------------------------------------------------------------------------+
(base) root@ubuntuserver:~#8. 微调
这次微调,不能用python3.10了,脚本中是调用一些通过pip安装的软件如torchrun,用python3.10的pip安装的torch、streamlit未添加进系统运行环境,无法直接运行。
由于requirement.txt中的streamlit和python3.9有问题,因此注释掉streamlit即可。
8.1 安装依赖
pip install rouge_chinese nltk jieba datasets -i https://pypi.tuna.tsinghua.edu.cn/simple8.2 准备数据集
下载AdvertiseGen.tar.gz
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
放到ptuning目录下
解压
tar -zvxf AdvertiseGen.tar.gz
8.3 训练
修改脚本中的模型路径:
把
--model_name_or_path THUDM/chatglm2-6b \
修改为
--model_name_or_path ../chatglm2-6b \
把
--max_steps 3000 \
改为
--max_steps 60 \
这样数分钟后即可完成训练。
把
--save_steps 1000 \
改为
--save_steps 60 \
训练:
bash train.sh微调时GPU利用情况:
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 109674 C ...user/anaconda3/bin/python 7631MiB |
+-----------------------------------------------------------------------------+
Mon Sep 11 09:48:55 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:00:07.0 Off | N/A |
| 67% 60C P2 331W / 350W | 7633MiB / 24576MiB | 86% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 109674 C ...user/anaconda3/bin/python 7631MiB |
+-----------------------------------------------------------------------------+
8.4 训练完成
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 358.4221, 'train_samples_per_second': 2.678, 'train_steps_per_second': 0.167, 'train_loss': 4.090850830078125, 'epoch': 0.01}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [05:58<00:00, 5.97s/it]
***** train metrics *****epoch = 0.01train_loss = 4.0909train_runtime = 0:05:58.42train_samples = 114599train_samples_per_second = 2.678train_steps_per_second = 0.167
(base) root@ubuntuserver:~/work/ChatGLM2-6B/ptuning#查看模型文件:
这个多了个checkpoint-60文件夹,内面有模型文件
ChatGLM2-6B/ptuning/output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-60
8.5 推理
还是修改推理脚本中的模型位置
vim evaluate.sh
把
STEP=3000
修改为
STEP=60
把
--model_name_or_path THUDM/chatglm2-6b \
修改为
--model_name_or_path ../chatglm2-6b \
运行
bash evaluate.sh
修改web_demo.sh中的模型和checkpoint为
--model_name_or_path ../chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-60 \
问题:解决ImportError: cannot import name ‘soft_unicode‘ from ‘markupsafe‘
python -m pip install markupsafe==2.0.1
参考
[1]https://github.com/THUDM/ChatGLM2-6B
[2]ChatGLM-6B (介绍以及本地部署),https://blog.csdn.net/qq128252/article/details/129625046
[3]ChatGLM2-6B|开源本地化语言模型,https://openai.wiki/chatglm2-6b.html
[3]免费部署一个开源大模型 MOSS,https://zhuanlan.zhihu.com/p/624490276
[4]LangChain + ChatGLM2-6B 搭建个人专属知识库,https://zhuanlan.zhihu.com/p/643531454
[5]https://pytorch.org/get-started/locally/相关文章:
开源大模型ChatGLM2-6B 1. 租一台GPU服务器测试下
0. 环境 租用了1台GPU服务器,系统 ubuntu20,GeForce RTX 3090 24G。过程略。本人测试了ai-galaxy的,今天发现网友也有推荐autodl的。 (GPU服务器已经关闭,因此这些信息已经失效) SSH地址:* 端…...

SQL10 用where过滤空值练习
描述 题目:现在运营想要对用户的年龄分布开展分析,在分析时想要剔除没有获取到年龄的用户,请你取出所有年龄值不为空的用户的设备ID,性别,年龄,学校的信息。 示例:user_profile iddevice_idge…...

JVM--Hotspot Architecture 详解
一、Java Virtual Machine (JVM)概述 Java Virtual Machine 虚拟机 (JVM) 是一种抽象的计算机。JVM本身也是一个程序,但是对于编写在其中执行的程序来说,它看起来像一台机器。对于特定的操作系统ÿ…...

ThreadLocal功能实现
模拟ThreadLocal功能实现 当前线程任意方法内操作连接对象 一个栈对应一个线程 , 一个方法调用另一个方法都是在一个线程内 , 只有执行了线程的start方法才会创建一个线程 定义一个Map集合 , key是当前线程(Thread.currentThread) , value是要绑定的数据(Connection对象) 以…...
Linux编辑器-vim使用
文章目录 前言一、vim编辑器1、vim的基本概念2、vim的基本操作2.1 命令模式切换至插入模式2.2 插入模式切换至命令模式2.3 命令模式切换至底行模式 3、vim命令模式命令集3.1 移动光标3.2 删除文字3.3 复制与粘贴3.4 替换3.5 撤销上一次操作3.6 更改3.7 跳至指定的行 4、vim末行…...
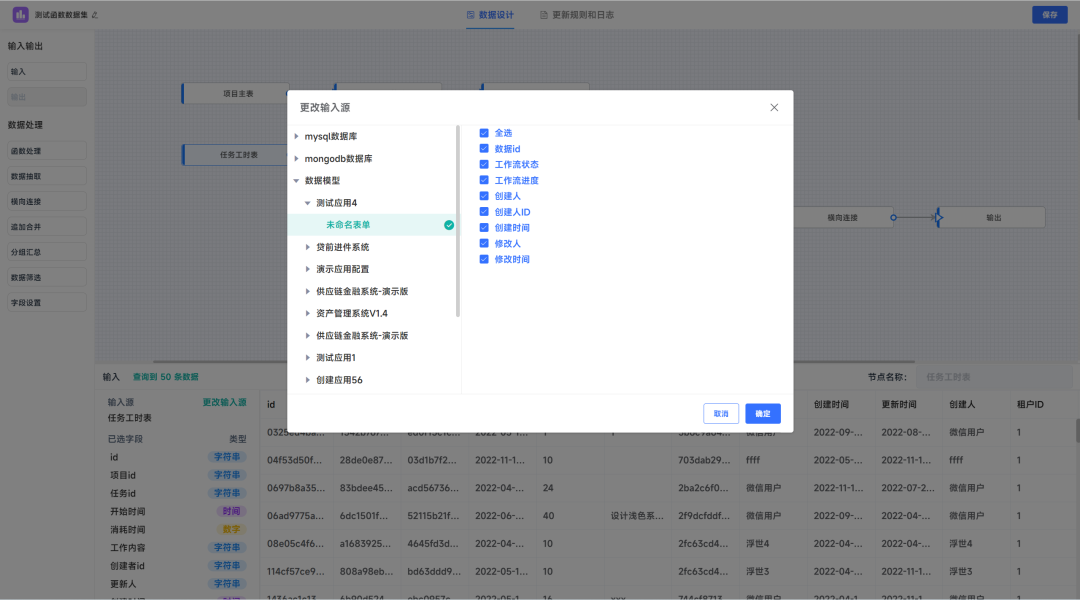
自助式数据分析平台:JVS智能BI功能介绍(二)数据集管理
数据集是JVS-智能BI中承载数据、使用数据、管理数据的基础,同样也是构建数据分析的基础。可以通俗地将其理解为数据库中的普通的表,他来源于智能的ETL数据加工工具,可以将数据集进行分析图表、统计报表、数字大屏、数据服务等制作。 在整体的…...

《5G技术引领教育信息化新革命》
5G技术引领教育信息化新革命 随着5G技术的快速发展,教育领域也迎来了全新的信息化时代。5G技术为教育行业提供了更高速、更稳定、更智能的网络连接,使得教育信息化不再局限于传统的课堂教学,而是延伸到了线上、线下的全时空教育。本文将详细介…...

cmake学习过程记录
目录 基础命令学习配置opencvcmake (Windows版本) 基础命令学习 //设置最低版本号 cmake_minimum_required(VERSION 3.5)//设置项目名称 project (hello_headers)//递归遍历文件夹src中的cpp文件放到变量SOURCES中 file(GLOB_RECURSE SOURCES src/*.cpp)//设置目标exe名称…...
Vue3、Vite使用 html2canvas 把Html生成canvas转成图片并保存,以及填坑记录
这两天接到新需求就是生成海报分享,生成的格式虽然是一样的但是自己一点点画显然是不符合我摸鱼人的性格,就找到了html2canvas插件,开始动工。 安装 npm install html2canvas --save文档 options 的参数都在里面按照自己需求使用 https://a…...
)
centos yum源配置(CentOS7 原生 yum 源修改为阿里 yum 源)
文章目录 centos yum源配置centos搭建内网yum源内网centos的yum软件源配置CentOS7 原生 yum 源修改为阿里 yum 源 centos yum源配置 centos搭建内网yum源 您好,在CentOS系统上搭建本地内网YUM仓库的方法如下: 安装httpd和createrepo工具 yum install httpd createrepo -y创…...
linux————ansible
一、认识自动化运维 自动化运维: 将日常IT运维中大量的重复性工作,小到简单的日常检查、配置变更和软件安装,大到整个变更流程的组织调度,由过去的手工执行转为自动化操作,从而减少乃至消除运维中的延迟,实现“零延时”…...

初识Java 8-1 接口和抽象类
目录 抽象类和抽象方法 接口定义 默认方法 多重继承 接口中的静态方法 作为接口的Instrument 本笔记参考自: 《On Java 中文版》 接口和抽象类提供了一种更加结构化的方式分离接口和实现。 抽象类和抽象方法 抽象类,其介于普通类和接口之间。在构…...

微信小程序音频后台播放功能
微信小程序在手机息屏后依旧能播放音频,需要使用 wx.getBackgroundAudioManager() 方法创建后台音乐播放器,并将音乐播放任务交给这个后台播放器。 具体实现步骤如下: 小程序页面中,使用 wx.getBackgroundAudioManager() 方法创…...
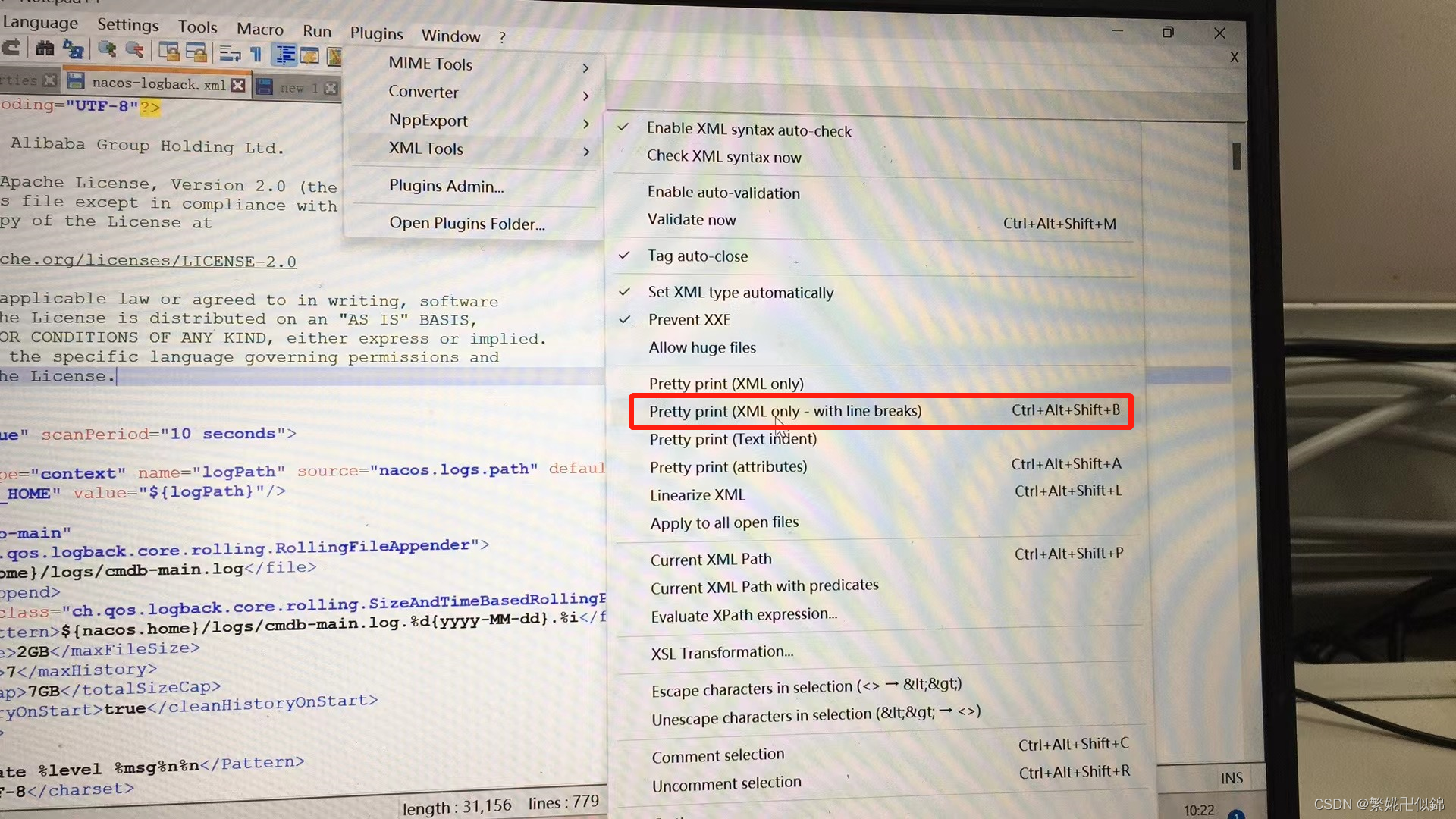
NotePad——xml格式化插件xml tools在线安装+离线安装
在使用NotePad时,在某些情形下,需要格式化Xml格式内容,可以使用Xml Tools插件。 一、在线安装 1. 打开Notepad 软件 2. 选择插件,选择“插件管理” 3. 搜索 XML Tools,找到该插件后,勾选该文件ÿ…...

图书管理系统 数据结构先导课暨C语言大作业复习 | JorbanS
问题描述 读取给定的图书文件book.txt中的信息(book.txt中部分图书信息如下图所示),完成一个图书信息管理系统,该系统的各个功能模块要求利用菜单选项进行选择。 系统功能要求 图书浏览 读取book.txt中的文件信息并依次输出所…...
python 爬虫的开发环境配置
1、新建一个python项目 2、在控制台中分别安装下面三个包 pip install requests pip install beautifulsoup4 pip install selenium/ 如果安装时报以下错误: raise ReadTimeoutError(self._pool, None, "Read timed out.") pip._vendor.urllib3.exceptio…...
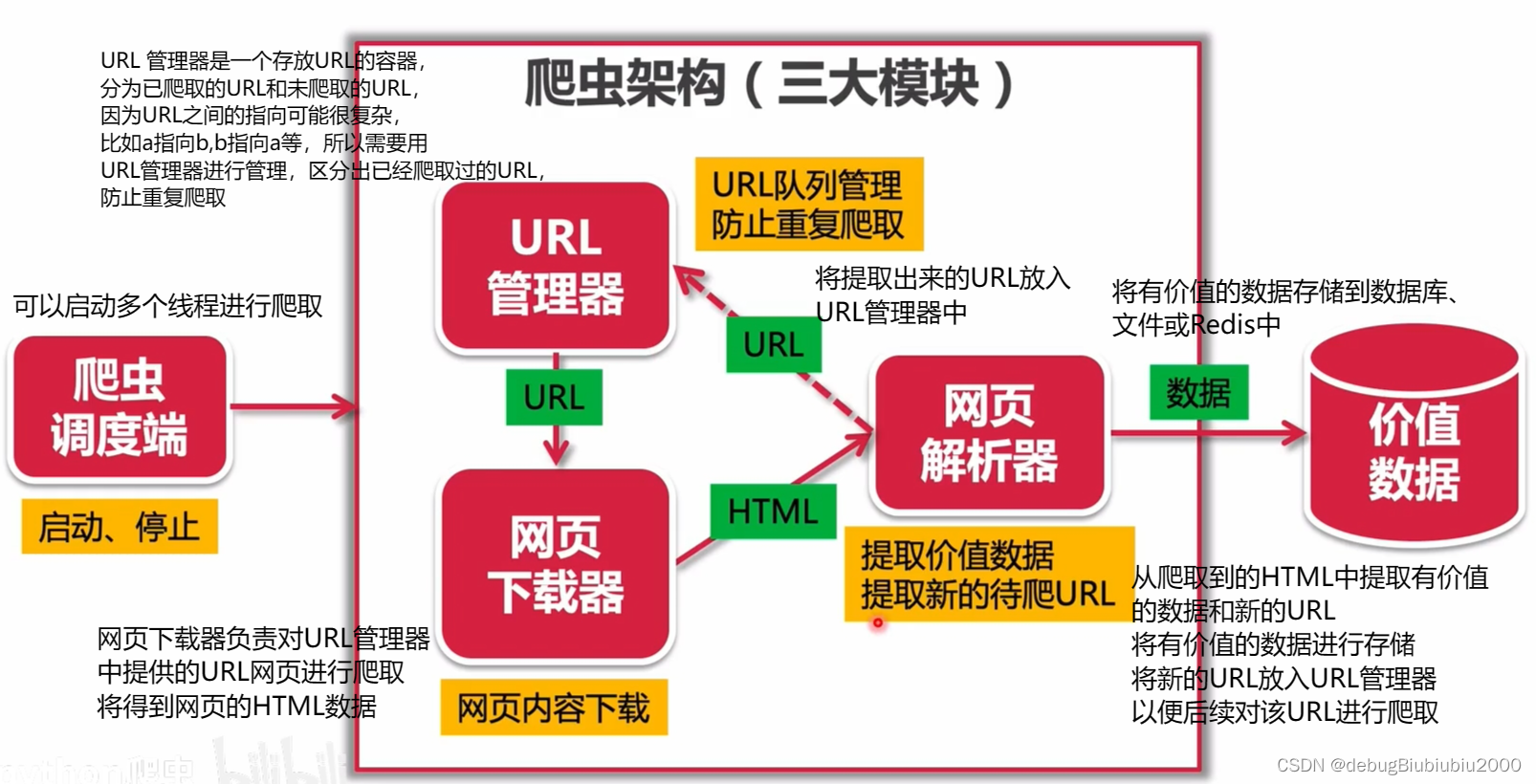
技术架构图是什么?和业务架构图的区别是什么?
技术架构图是什么? 技术架构图是一种图形化工具,用于呈现软件、系统或应用程序的技术层面设计和结构。它展示了系统的各种技术组件、模块、服务以及它们之间的关系和交互方式。技术架构图关注系统内部的技术实现细节,以及各个技术组件之…...

数据增强
一、数据增强 当你训练一个机器学习模型时,你实际做工作的是调参,以便将特定的输入(一副图像)映像到输出(标签)。我们优化的目标是使模型的损失最小化, 以正确的方式调节优化参数即可实现这一目…...

【Unity】2D 对话模块的实现
对话模块主要参考 【Unity教程】剧情对话系统 实现。 在这次模块的构建将基于 unity ui 组件 和 C#代码实现一个从excel 文件中按照相应规则读取数据并展示的逻辑。这套代码不仅能实现正常的对话,也实现了对话中可以通过选择不同选项达到不同效果的分支对话功能。 …...

laravel安装初步使用学习 composer安装
一、什么是laravel框架 Laravel框架可以开发各种不同类型的项目,内容管理系统(Content Management System,CMS)是一种比较典型的项目,常见的网站类型(如门户、新闻、博客、文章等)都可以利用CM…...

OpenClaw 的对话系统是否支持对话流程的可视化编辑?如何定义状态机?
关于OpenClaw对话系统是否支持对话流程的可视化编辑,目前公开的技术文档和社区讨论中并没有明确提及这一功能。从技术实现的角度来看,这类系统通常更侧重于底层对话状态管理和自然语言理解引擎的构建,而非面向产品经理或非技术人员的可视化编…...

嵌入式系统SOC验证与Linux实时补丁技术解析
嵌入式系统软件工程师面试技术要点解析 1. SOC原型验证技术体系 1.1 SOC验证工作内容与方法论 SOC原型验证是芯片设计流程中的关键环节,主要工作内容包括: 功能验证:确保设计符合规范要求 性能验证:评估系统吞吐量、延迟等指标…...

python基于微信小程序的旅游攻略分享平台
目录需求分析与功能规划技术架构设计数据库设计接口开发小程序前端开发部署与测试运营与迭代注意事项项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析与功能规划 明确平台核心功能:用户注册登录、攻略发布与…...

实战构建c盘清理桌面应用,快马ai生成可部署完整解决方案
今天想和大家分享一个实战项目:用Python开发一个C盘清理桌面应用。这个工具不仅能解决日常C盘空间不足的烦恼,还具备完整的图形界面和实用功能。最近在InsCode(快马)平台上尝试了快速生成和部署,整个过程特别顺畅。 项目背景与核心功能 开发这…...

IntelliJ IDEA突然无法启动的快速修复指南
1. IntelliJ IDEA突然无法启动的常见原因 作为一名常年与IntelliJ IDEA打交道的开发者,我遇到过无数次IDE突然罢工的情况。最让人头疼的是,明明昨天还用得好好的,今天双击图标却毫无反应。这种情况通常由以下几个原因导致: 首先是…...

2026年AI前20岗位薪酬出炉!搞AI大模型的远超同行?
AI相关,细分技术领域,薪资前20岗位,都有哪些。 今天这篇文章与铁铁们分享一下。 1 薪资榜单 如下图所示,排名第一:深度学习算法工程师,平均月薪达到3万1千; 排名第二的架构师,薪资与…...

效率倍增:用快马生成jdk一键配置脚本与docker环境模板
效率倍增:用快马生成JDK一键配置脚本与Docker环境模板 每次新换电脑或者重装系统,最头疼的就是重新配置开发环境。特别是Java开发,光是下载JDK、配置环境变量就得折腾半天。最近发现用InsCode(快马)平台可以快速生成自动化脚本,把…...
:覆盖编译期/加载期/运行期的9维评分体系,仅限前500名开发者免费获取评估工具包)
【独家首发】Python扩展安全成熟度模型(PESMM v1.2):覆盖编译期/加载期/运行期的9维评分体系,仅限前500名开发者免费获取评估工具包
第一章:Python扩展模块安全概述Python 扩展模块(如 C/C 编写的 .so/.dll 文件或 Cython 生成的二进制模块)在提升性能的同时,也引入了原生层特有的安全风险。与纯 Python 代码不同,扩展模块直接操作内存、调用系统 API…...

APScheduler避坑指南:解决定时任务重复执行和时区问题的5种实战方案
APScheduler生产级实战:彻底解决定时任务重复执行与时区混乱的终极方案 凌晨三点,服务器告警铃声突然响起——监控系统显示同一批数据处理任务在短时间内被重复执行了17次。这不是科幻场景,而是某电商平台在使用APScheduler时遇到的真实生产事…...

零基础掌握SeleniumBasic:革新性浏览器自动化框架全攻略
零基础掌握SeleniumBasic:革新性浏览器自动化框架全攻略 【免费下载链接】SeleniumBasic A Selenium based browser automation framework for VB.Net, VBA and VBScript 项目地址: https://gitcode.com/gh_mirrors/se/SeleniumBasic 每天重复机械的网页操作…...