掌握MySQL分库分表(七)广播表、绑定表实战,水平分库+分表实现及之后的查询和删除操作
文章目录
- 什么是广播表
- 广播表实战
- 数据库配置表
- Java配置实体类
- 配置文件
- 测试广播表
- 水平分库+分表
- 配置文件
- 运行测试
- 什么是绑定表?
- 绑定表实战
- 配置数据库
- 配置Java实体类
- 配置文件
- 运行测试
- 水平分库+分表后的查询和删除操作
- 查询操作
什么是广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全⼀致
适用于数据量不⼤且需要与海量数据的表进行关联查询的场景,例如:字典表、配置表
需求:在任意一个库中插入一条数据,另一个库中的相同表也插入这条数据
广播表实战
数据库配置表
脚本
CREATE TABLE `ad_config` (`id` BIGINT UNSIGNED NOT NULL COMMENT '主键id',`config_key` VARCHAR ( 1024 ) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置key',`config_value` VARCHAR ( 1024 ) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置value',`type` VARCHAR ( 128 ) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '类型',PRIMARY KEY ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin;
Java配置实体类
model层
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("ad_config")
public class AdConfigDO {private Long id;private String configKey;private String configValue;private String type;
}
mapper层
public interface AdConfigMapper extends BaseMapper<AdConfigDO> {
}
配置文件
增加配置规则
#配置⼴播表
spring.shardingsphere.sharding.broadcasttables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
配置文件完整
spring.application.name=xdclass-sharding-jdbc
server.port=8080# 打印执行的数据库以及语句
spring.shardingsphere.props.sql.show=true# 数据源 db0
spring.shardingsphere.datasource.names=ds0,ds1# 第一个数据库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://10.24.201.232:3306/xdclass_shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root# 第二个数据库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://10.24.201.232:3306/xdclass_shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root#配置workId
spring.shardingsphere.sharding.tables.product_order.key-generator.props.worker.id=1#配置广播表
spring.shardingsphere.sharding.broadcast-tables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE#id生成策略
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds0.product_order_$->{0..1}# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{user_id % 2}
测试广播表
测试类
@Testpublic void testSaveAdConfig(){AdConfigDO adConfigDO = new AdConfigDO();adConfigDO.setConfigKey("banner");adConfigDO.setConfigValue("xdclass.net");adConfigDO.setType("ad");adConfigMapper.insert(adConfigDO);}
运行结果:


水平分库+分表
需求:插入订单数据,分布在2个数据库和每个库的2张表中
分库规则:根据 user_id 进行分库
分表规则:根据 product_order_id 订单号(id字段)进行分表
配置文件
增加分库配置规则
# 配置分库规则
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2 }
修改数据节点配置规则
# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{id % 2}
运行测试
测试类
@Test
public void testSaveProductOrder(){Random random = new Random();for(int i=0; i<20;i++){ProductOrderDO productOrderDO = new ProductOrderDO();productOrderDO.setCreateTime(new Date());productOrderDO.setNickname("我是i"+i+"号");productOrderDO.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));productOrderDO.setPayAmount(100.00);productOrderDO.setState("PAY");productOrderDO.setUserId(Long.valueOf(random.nextInt(50)));productOrderMapper.insert(productOrderDO);
}




什么是绑定表?
指分片规则⼀致的主表和子表
需求:product_order表和product_order_item表,均按照order_id分片,则此两张表互为绑定表关系
绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
绑定表实战
配置数据库
脚本
CREATE TABLE `product_order_item_0` (`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,`product_order_id` BIGINT DEFAULT NULL COMMENT '订单号',`product_id` BIGINT DEFAULT NULL COMMENT '产品id',`product_name` VARCHAR ( 128 ) DEFAULT NULL COMMENT '商品名称',`buy_num` INT DEFAULT NULL COMMENT '购买数量',`user_id` BIGINT DEFAULT NULL,PRIMARY KEY ( `id` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin;
配置Java实体类
model层
@Data
@TableName("product_order_item")
@EqualsAndHashCode(callSuper = false)
public class ProductOrderItemDO {private Long id;private Long productOrderId;private Long productId;private String productName;private Integer buyNum;private Long userId;
}
mapper层
public interface ProductOrderMapper extends BaseMapper<ProductOrderDO> {@Select("select * from product_order o left join product_order_item i on o.id=i.product_order_id")List<Object> listProductOrderDetail();
}public interface ProductOrderItemMapper extends BaseMapper<ProductOrderItemDO> {
}
配置文件
添加配置:默认分库策略
#配置【默认分库策略】
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2 }
添加配置:配置绑定表
#配置绑定表
spring.shardingsphere.sharding.binding‐tables[0] = product_order,product_order_item
添加配置:分片键、分片策略
# 指定product_order_item表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order_item.actual-data-nodes=ds$->{0..1}.product_order_item_$->{0..1}
spring.shardingsphere.sharding.tables.product_order_item.table-strategy.inline.sharding-column=product_order_id
spring.shardingsphere.sharding.tables.product_order_item.table-strategy.inline.algorithm-expression=product_order_item_$->{product_order_id % 2}
运行测试
测试类
@Testpublic void testBingding(){List<Object> list = productOrderMapper.listProductOrderDetail();System.out.println(list);}
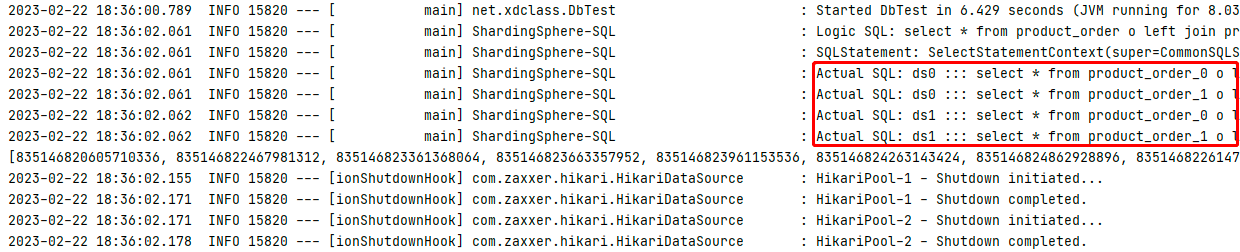
配置绑定表时SQL数量(性能):4条SQL
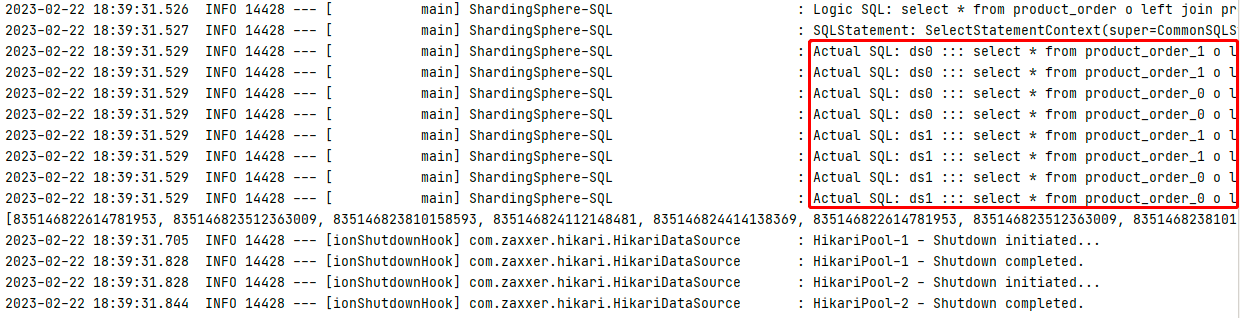
不配置绑定表时SQL数量(性能):8条SQL(注释掉绑定表的配置文件配置)
水平分库+分表后的查询和删除操作
查询操作
有分片键(标准路由)=、in
测试类
/*** 有分片键*/
@Test
public void testPartitionKeySelect(){productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().eq("id",835146820605710336L));//productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().in("id",Arrays.asList(1464129579089227778L,1464129582369173506L,1464129583140925441L)));}
相关文章:
掌握MySQL分库分表(七)广播表、绑定表实战,水平分库+分表实现及之后的查询和删除操作
文章目录什么是广播表广播表实战数据库配置表Java配置实体类配置文件测试广播表水平分库分表配置文件运行测试什么是绑定表?绑定表实战配置数据库配置Java实体类配置文件运行测试水平分库分表后的查询和删除操作查询操作什么是广播表 指所有的分片数据源中都存在的…...
企业为什么需要数据可视化报表
数据可视化报表是在商业环境、市场环境已经改变之后,发展出来为当前企业提供替代解决办法的重要方案。而且信息化、数字化时代,很多企业已经进行了初步的信息化建设,沉淀了大量业务数据,这些数据作为企业的资产,是需要…...
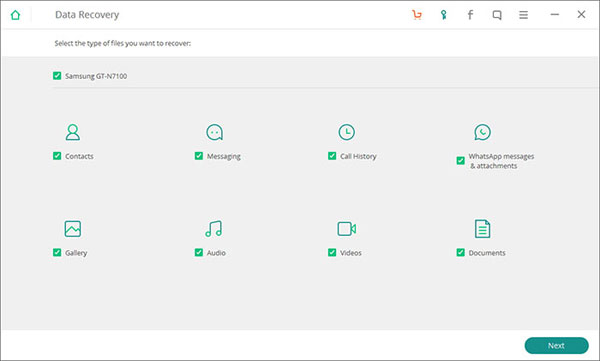
5个有效的华为(HUAWEI)手机数据恢复方法
5个有效的手机数据恢复方法 华为智能手机中的数据丢失比许多人认为的更为普遍。发生这种类型的丢失有多种不同的原因,因此数据恢复软件的重要性。您永远不知道您的智能手机何时会在这方面垮台;因此,预防总比哀叹好,这就是为什么众…...
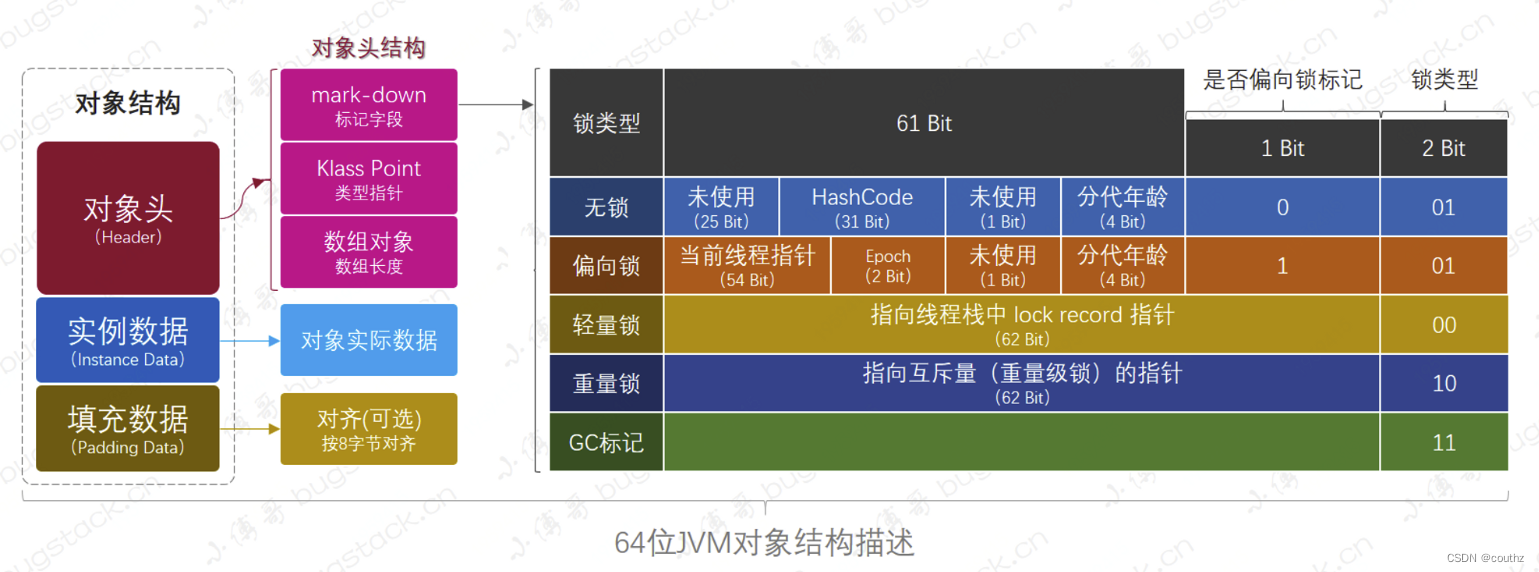
【Java并发编程】线程安全(一)Synchronized原理
Synchronized底层实现 简单来说,Synchronized关键字的执行主体是线程对象,加锁是通过一个锁对象来完成的是,而锁对象底层关联了一个c源码的monitor的对象,monitor对象底层又对应了操作系统级别的互斥锁,同一时刻只有一…...

[apollo]vue3.x中apollo的使用
[apollo]vue3.x中apollo的使用通过客户端获取Apollo配置环境工具的安装获取Apollo配置相关代码错误提示Uncaught (in promise) Error: Apollo client with id default not found. Use provideApolloClient() if you are outside of a component setup通过开放接口获取Apollo配置…...
函数启用新进程占有原进程的文件描述符表的问题)
system()函数启用新进程占有原进程的文件描述符表的问题
我在A程序中占用了/dev/video0这个独占模式的设备文件,在A中用system函数启用了B程序,B程序的代码中并不包含对/dev/video0的访问,但是我发现B程序也占用了/dev/video0,并且我在A程序中关闭了/dev/video0后,A程序不再占…...
nignx(安装,正反代理,安装tomcat设置反向代理,ip透传)
1安装nginx 安装wget Yum install -y wget 下载(链接从官网找到右键获取) 以下过程root 安装gcc Yum -y install gcc c 安装pcre Yum install -y pcre pcre-devel Openssl Yum install -y openssl openssl-devel 安装zlib Yum install -y zlib zlib-devel 安装make Yum inst…...

sklearn模块常用内容解析笔记
文章目录 回归模型评价指标R2_score预备知识R2_score计算公式r2_score使用方法注意事项参考文献回归模型评价指标R2_score 回归模型的性能的评价指标主要有:RMSE(平方根误差)、MAE(平均绝对误差)、MSE(平均平方误差)、R2_score。但是当量纲不同时,RMSE、MAE、MSE难以衡量模…...
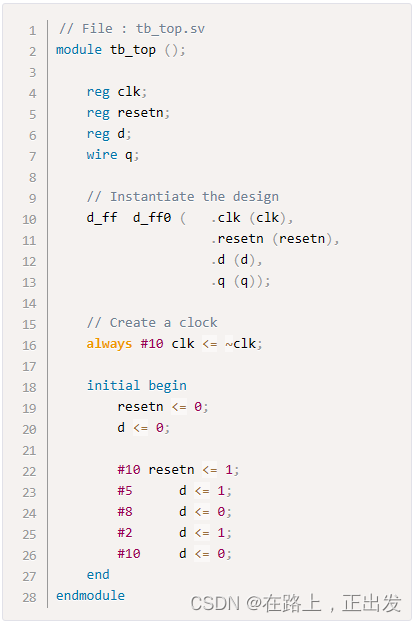
我的 System Verilog 学习记录(2)
引言 从本文开始,就开始系统学习 System Verilog ,不只是语法,还有结合 Questa Sim 的实际编程练习、Debug。 本文简单介绍 System Verilog 语言的用途以及学习的必要性。 前文链接: 我的 System Verilog 学习记录(…...

【调研报告】Monorepo 和 Multirepo 的风格对比及使用示例
带有权重的Monorepo和Multirepo对比 功能/特性MonorepoMultirepoMonorepo权重值Multirepo权重值代码管理管理多个代码库更加复杂管理单个代码库更加简单37依赖管理可以简化依赖管理依赖冲突可能会更加困难73构建和部署构建和部署更加容易构建和部署可能需要更多的配置82团队协…...
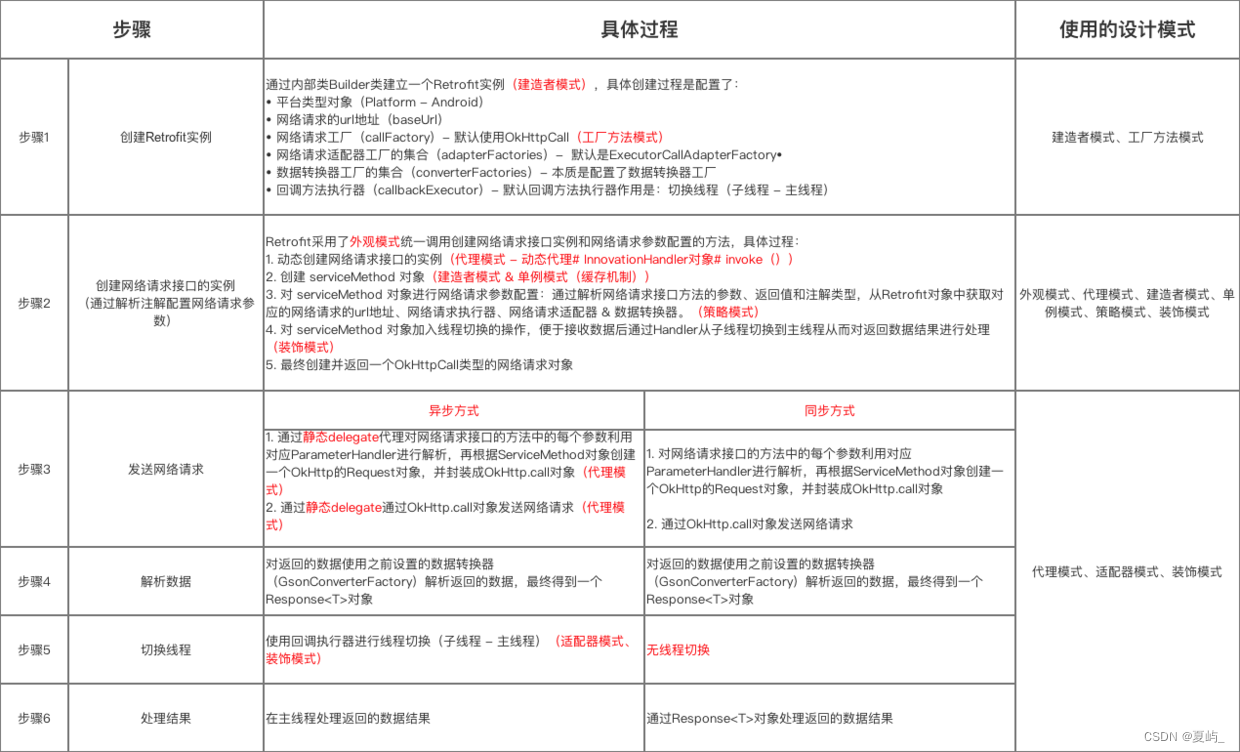
Retrofit源码分析
文章目录一、简介二、源码分析2.1Retrofit的本质流程2.2源码分析2.2.1 创建Retrofit实例步骤1步骤2步骤3步骤4步骤5总结2.2.2创建网络请求接口的实例外观模式 & 代理模式1.外观模式2. 代理模式步骤3步骤4总结2.2.3执行网络请求同步请求OkHttpCall.execute()1.发送请求过程2…...
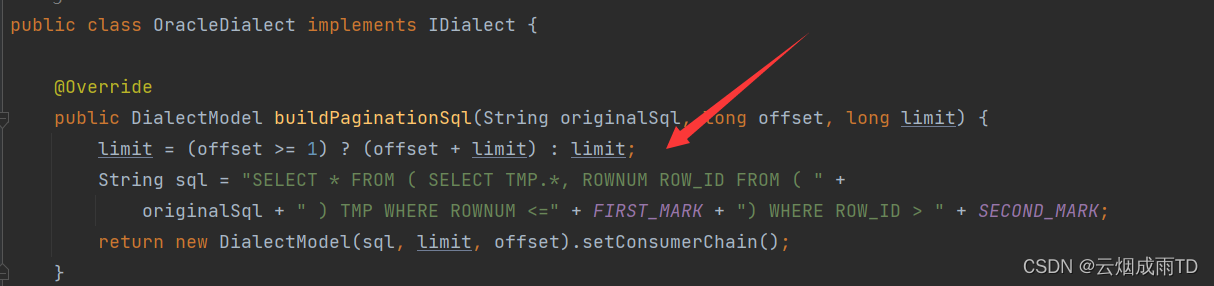
Mybatis-Plus入门系列(20) -兼容多种数据库
有道无术,术尚可求,有术无道,止于术。 文章目录前言方案分析1. 分页2. XML自定义SQL案例演示1. 配置2. 简单分页查询3. 带方言的分页查询参考前言 在我们实际开发软件产品过程中,数据库的类型可能不是确定的,也有客户…...
JetPack板块—Android X解析
Android Jetpack简述 AndroidX 是Android团队用于在Jetpack中开发,测试,打包,发布和版本管理的开源项目。相比于原来的Android Support库,AndroidX 可以称得上是一次重大的升级改进。 和Support库一样,AndroidX与Android 操作系…...

C++学习笔记-数字
当我们使用数字时,通常我们使用原始数据类型,例如 int,short,long,float 和 double 等。数字数据类型,它们的可能值和取值范围在讨论 C 数据类型时已经解释了。 C 定义数字 我们已经在之前笔记的各种实例…...
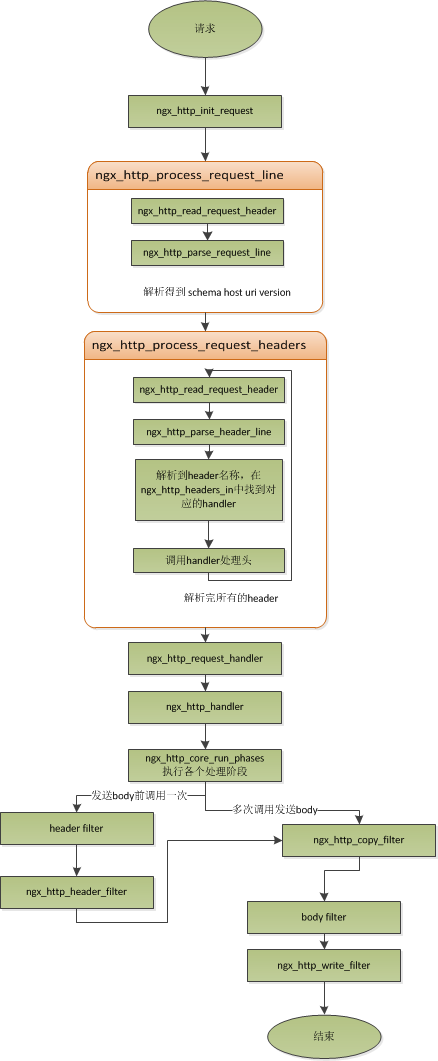
Nginx——Nginx的基础原理
摘要 Nginx 是俄罗斯人编写的十分轻量级的 HTTP 服务器,是一个高性能的HTTP和反向代理服务器,同时也是一个 IMAP/POP3/SMTP 代理服务器。Nginx 是由俄罗斯人 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,它已经在该站点运行超过两年半了。…...
服务端开发Java之备战秋招面试篇1
在这个面试造火箭工作拧螺丝的时代背景下,感觉不是很好,不过还好也是拿到了还行的offer,准备去实习了,接下来就是边实习边准备秋招了,这半年把(技术栈八股文面经算法题项目)吃透,希望…...

【C++的OpenCV】第三课-OpenCV图像加载和显示
我们开始学习OpenCV一、OpenCV加载图片和显示图片1.1 imread()函数的介绍1.2 cv::namedWindow()函数的介绍1.4 imshow()函数介绍1.5 Mat容器介绍二、 代码实例(带注释)2.1 代码2.2 执行结果一、OpenCV加载图片和显示图片 本章节中,将会学习到…...

【面试1v1实景模拟】Spring事务 一文到底
老面👴:小伙子,了解Spring的事务吗? 解读🔔:这个必须了解,不了解直接挂~😂😂😂,但面试官肯定不是想听你了解两个字,他是想让你简单的介绍下。 笑小枫🍁:了解,事务在逻辑上是一组操作,要么执行,要不都不执行。主要是针对数据库而言的,比如说 MySQL。为…...
Neuron Selectivity Transfer 原理与代码解析
paper:Like What You Like: Knowledge Distill via Neuron Selectivity Transfercode:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/NST.py本文的创新点本文探索了一种新型的知识 - 神经元的选择性知识,…...

vue项目关闭子页面,并更新父页面的数据
今天下午是一个非常痛苦的,想要实现一个功能: 父页面打开了一个新的页面(浏览器打开一个新的窗口),并在子页面提交数据之后,父页面的数据要同步更新。 难点:父页面是一个表格列表,…...

基于离散阻抗与线性回归的嵌入式电池健康状态在线估计方法
1. 项目概述:当电池健康遇上“轻量级”机器学习在电动汽车、储能电站乃至消费电子领域,锂离子电池的健康状态(State of Health, SoH)都是一个绕不开的核心指标。它直接决定了设备的续航能力、安全边界乃至剩余价值。传统的BMS&…...

全域轨迹可回溯,高效破解煤矿灾害搜救难题 ——基于视频孪生无感定位的矿山轨迹溯源搜救技术解析方案
全域轨迹可回溯,高效破解煤矿灾害搜救难题——基于视频孪生无感定位的矿山轨迹溯源搜救技术解析方案一、方案前言煤矿井下瓦斯爆炸、顶板垮塌、透水冲击等灾害发生后,巷道结构损毁、通信供电中断、有害气体弥漫,现场环境瞬息万变。传统人员监…...

图神经网络与最近邻算法融合:硬件木马门级网表定位技术解析
1. 项目概述:当图神经网络遇上硬件木马在芯片设计这个精密如微雕的领域,每一根连线的走向、每一个逻辑门的布局都关乎着最终产品的性能与安全。然而,一个幽灵——“硬件木马”(Hardware Trojan)——正游荡在全球化的集…...
)
macOS上VirtualBox虚拟机卡顿?试试这个‘丝滑’增强包(含CentOS 7依赖安装避坑)
macOS上VirtualBox虚拟机卡顿终极优化指南:从依赖安装到性能调优刚在Mac上装好VirtualBox虚拟机,满心欢喜准备大展拳脚,却发现鼠标移动像在糖浆里游泳?窗口拖拽时仿佛在跟系统拔河?这种体验简直让人想摔键盘。别急着放…...

BiliBiliCCSubtitle终极指南:如何3秒下载B站CC字幕并转换SRT格式
BiliBiliCCSubtitle终极指南:如何3秒下载B站CC字幕并转换SRT格式 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法下载B站CC字幕而烦恼吗&am…...

Windows右键菜单终极优化:ContextMenuManager完全掌控指南
Windows右键菜单终极优化:ContextMenuManager完全掌控指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是日常操作中使用最频繁的…...

四款免费抓包工具实战选型指南:HTTPS解密与跨平台调试
1. 抓包这件事,为什么90%的人从一开始就搞错了方向 “免费抓包工具有哪些?”——这是我在技术群、论坛和私信里被问得最多的问题之一。但每次看到这个问题,我都会先反问一句:“你到底想抓什么包?” 不是所有抓包场景…...

鸣潮工具箱:3大核心功能解锁120FPS与专业抽卡分析
鸣潮工具箱:3大核心功能解锁120FPS与专业抽卡分析 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools是一款专为《鸣潮》玩家打造的开源工具箱,通过智能帧率解锁、专业画质优…...

YCbCr 转 RGB:揭秘那串神奇公式背后的百年故事
一、一个让我"开窍"的翻译故事 我大学时有个学语言学的朋友,他给我讲过一个让我至今难忘的故事。他说翻译界有一个著名的"中间语言"问题——如果你要把一本书从 50 种语言互相翻译,最笨的办法是给每两种语言之间都准备一个翻译&…...

RAG:终结AI“一本正经胡说八道”,让AI回答问题不再答非所问!
本文用通俗易懂的方式解释了RAG技术,即“检索增强生成”,它通过为AI构建专属知识库,在回答问题时先检索相关信息再生成答案,有效解决AI“答非所问”和“幻觉”问题。文章详细介绍了RAG的工作原理、核心价值及实用场景,…...