《动手学深度学习 Pytorch版》 4.10 实战Kaggle比赛:预测比赛
4.10.1 下载和缓存数据集
import hashlib
import os
import tarfile
import zipfile
import requests#@save
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
def download(name, cache_dir=os.path.join('..', 'data')): #@save"""下载一个DATA_HUB中的文件,返回本地文件名"""assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"url, sha1_hash = DATA_HUB[name]os.makedirs(cache_dir, exist_ok=True)fname = os.path.join(cache_dir, url.split('/')[-1])if os.path.exists(fname):sha1 = hashlib.sha1()with open(fname, 'rb') as f:while True:data = f.read(1048576)if not data:breaksha1.update(data)if sha1.hexdigest() == sha1_hash:return fname # 命中缓存print(f'正在从{url}下载{fname}...')r = requests.get(url, stream=True, verify=True)with open(fname, 'wb') as f:f.write(r.content)return fname
def download_extract(name, folder=None): #@save"""下载并解压zip/tar文件"""fname = download(name)base_dir = os.path.dirname(fname)data_dir, ext = os.path.splitext(fname)if ext == '.zip':fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'):fp = tarfile.open(fname, 'r')else:assert False, '只有zip/tar文件可以被解压缩'fp.extractall(base_dir)return os.path.join(base_dir, folder) if folder else data_dirdef download_all(): #@save"""下载DATA_HUB中的所有文件"""for name in DATA_HUB:download(name)
4.10.2 Kaggle
好久没用的老帐号给我删了?
4.10.3 访问和读取数据集
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
# 使用前面定义的脚本下载并缓存数据DATA_HUB['kaggle_house_train'] = ( #@saveDATA_URL + 'kaggle_house_pred_train.csv','585e9cc93e70b39160e7921475f9bcd7d31219ce')DATA_HUB['kaggle_house_test'] = ( #@saveDATA_URL + 'kaggle_house_pred_test.csv','fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
# 使用pandas分别加载数据train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
print(train_data.shape)
print(test_data.shape)
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]) # 查看前四个和后两个
(1460, 81)
(1459, 80)Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:])) # 删除不带预测信息的Id
4.10.4 数据预处理
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index # 定位数值列
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std())) # 标准化数据
all_features[numeric_features] = all_features[numeric_features].fillna(0) # 将缺失值设为0
# 处理离散值 “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(2919, 331)
n_train = train_data.shape[0] # 获取样本数
# 从pandas格式中提取NumPy格式,并将其转换为张量表示用于训练
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
4.10.5 训练
# 整一个带有损失平方的线性模型作为基线模型loss = nn.MSELoss()
in_features = train_features.shape[1]def get_net():# net = nn.Sequential(nn.Linear(in_features, 1))net = nn.Sequential(nn.Linear(in_features, 256),nn.ReLU(),nn.Linear(256, 64),nn.ReLU(),nn.Linear(64, 1))return net
# 由于房价预测更在意相对误差,故进行取对数处理def log_rmse(net, features, labels):clipped_preds = torch.clamp(net(features), 1, float('inf')) # 将房价范围限制在1到无穷大,进一步稳定其值rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels))) # 取对数再算均方根误差return rmse.item()
# 使用对学习率不敏感的Adam优化器def train(net, train_features, train_labels, test_features, test_labels,num_epochs, learning_rate, weight_decay, batch_size):train_ls, test_ls = [], []train_iter = d2l.load_array((train_features, train_labels), batch_size) # 加载训练集数据optimizer = torch.optim.Adam(net.parameters(),lr = learning_rate,weight_decay = weight_decay) # 使用Adam优化算法for epoch in range(num_epochs):for X, y in train_iter:optimizer.zero_grad()l = loss(net(X), y)l.backward()optimizer.step()train_ls.append(log_rmse(net, train_features, train_labels))if test_labels is not None:test_ls.append(log_rmse(net, test_features, test_labels))return train_ls, test_ls
4.10.6 K折交叉验证
def get_k_fold_data(k, i, X, y):assert k > 1fold_size = X.shape[0] // k # 计算子集数据量X_train, y_train = None, Nonefor j in range(k):idx = slice(j * fold_size, (j + 1) * fold_size)X_part, y_part = X[idx, :], y[idx] # 截取当前子集数据if j == i:X_valid, y_valid = X_part, y_partelif X_train is None:X_train, y_train = X_part, y_partelse:X_train = torch.cat([X_train, X_part], 0)y_train = torch.cat([y_train, y_part], 0)return X_train, y_train, X_valid, y_valid
# 完成训练后需要求误差的平均值def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,batch_size):train_l_sum, valid_l_sum = 0, 0for i in range(k):data = get_k_fold_data(k, i, X_train, y_train)net = get_net()train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,weight_decay, batch_size)train_l_sum += train_ls[-1]valid_l_sum += valid_ls[-1]if i == 0:d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],legend=['train', 'valid'], yscale='log')print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, 'f'验证log rmse{float(valid_ls[-1]):f}')return train_l_sum / k, valid_l_sum / k
4.10.7 模型选择
k, num_epochs, lr, weight_decay, batch_size = 10, 100, 0.03, 0.05, 256
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, 'f'平均验证log rmse: {float(valid_l):f}')
折1,训练log rmse0.099098, 验证log rmse0.162470
折2,训练log rmse0.091712, 验证log rmse0.114310
折3,训练log rmse0.107151, 验证log rmse0.151471
折4,训练log rmse0.103659, 验证log rmse0.167303
折5,训练log rmse0.102100, 验证log rmse0.165151
折6,训练log rmse0.110199, 验证log rmse0.131012
折7,训练log rmse0.105075, 验证log rmse0.146769
折8,训练log rmse0.109164, 验证log rmse0.123824
折9,训练log rmse0.096305, 验证log rmse0.174747
折10,训练log rmse0.096146, 验证log rmse0.136332
10-折验证: 平均训练log rmse: 0.102061, 平均验证log rmse: 0.147339

4.10.8 提交 Kaggle 预测
def train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size):net = get_net()train_ls, _ = train(net, train_features, train_labels, None, None,num_epochs, lr, weight_decay, batch_size)d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',ylabel='log rmse', xlim=[1, num_epochs], yscale='log')print(f'训练log rmse:{float(train_ls[-1]):f}')# 将网络应用于测试集。preds = net(test_features).detach().numpy()# 将其重新格式化以导出到Kaggletest_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)submission.to_csv('submission.csv', index=False)
train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size)
训练log rmse:0.091832

相关文章:
《动手学深度学习 Pytorch版》 4.10 实战Kaggle比赛:预测比赛
4.10.1 下载和缓存数据集 import hashlib import os import tarfile import zipfile import requests#save DATA_HUB dict() DATA_URL http://d2l-data.s3-accelerate.amazonaws.com/def download(name, cache_diros.path.join(.., data)): #save"""下载一个…...

jQuery补充
文章目录 简介安装语法选择器元素选择器#id 选择器.class 选择器事件常用事件方法 效果显示隐藏淡入淡出滑动动画停止动画获取内容和属性添加元素删除元素操作css父辈 💛💛孔子云:温故而知新,可以为师矣💛💛…...

goaccess 日志分析 nginx
分析命令: goaccess -a -d -f /mnt/winshare/access-2023070112.log -p goaccess.conf -o /mydata/nginx/html/2023070112_new.html分析日志时的参数 goaccess使用参数详解-a 开启 UserAgent 列表。开启后会降低解析速度 -c 在程序开始运行时显示 日志/日期 配…...

认养一头牛———众筹+合伙人商业模式解析
2016年成立以来,认养一头牛致力于打造数字化乳业第一品牌,只为一杯好牛奶。公司在创立三年内完成了10个亿销售目标,被业界称为新消费品牌黑马,一举闯入互联网新消费梯队的视线。未来三年,认养一头牛将着力打造全国最大…...
)
前端面试的话术集锦第 11 篇:高频考点(React和Vue两大框架)
这是记录前端面试的话术集锦第十一篇博文——高频考点(React和Vue两大框架),我会不断更新该博文。❗❗❗ React 和Vue应该是国内当下最火热的前端框架。当然,Angular也是一个不错的框架,但是这个产品,国内使用的人很少,因而,框架的章节中不会涉及到Angular的内容。 这…...
前端js下载zip文件异常问题解决
目录 一,本文解决问题如下 二,原下载代码 1,ajax get 下载文件 2,下载异常图: 三,成功下载的 1, JQuery 实现文件下载xhr 2,图例 引言: 本人使用的ajax 下载&…...

深度学习面试八股文(2023.9.06)
一、优化器 1、SGD是什么? 批梯度下降(Batch gradient descent):遍历全部数据集算一次损失函数,计算量开销大,计算速度慢,不支持在线学习。随机梯度下降(Stochastic gradient desc…...
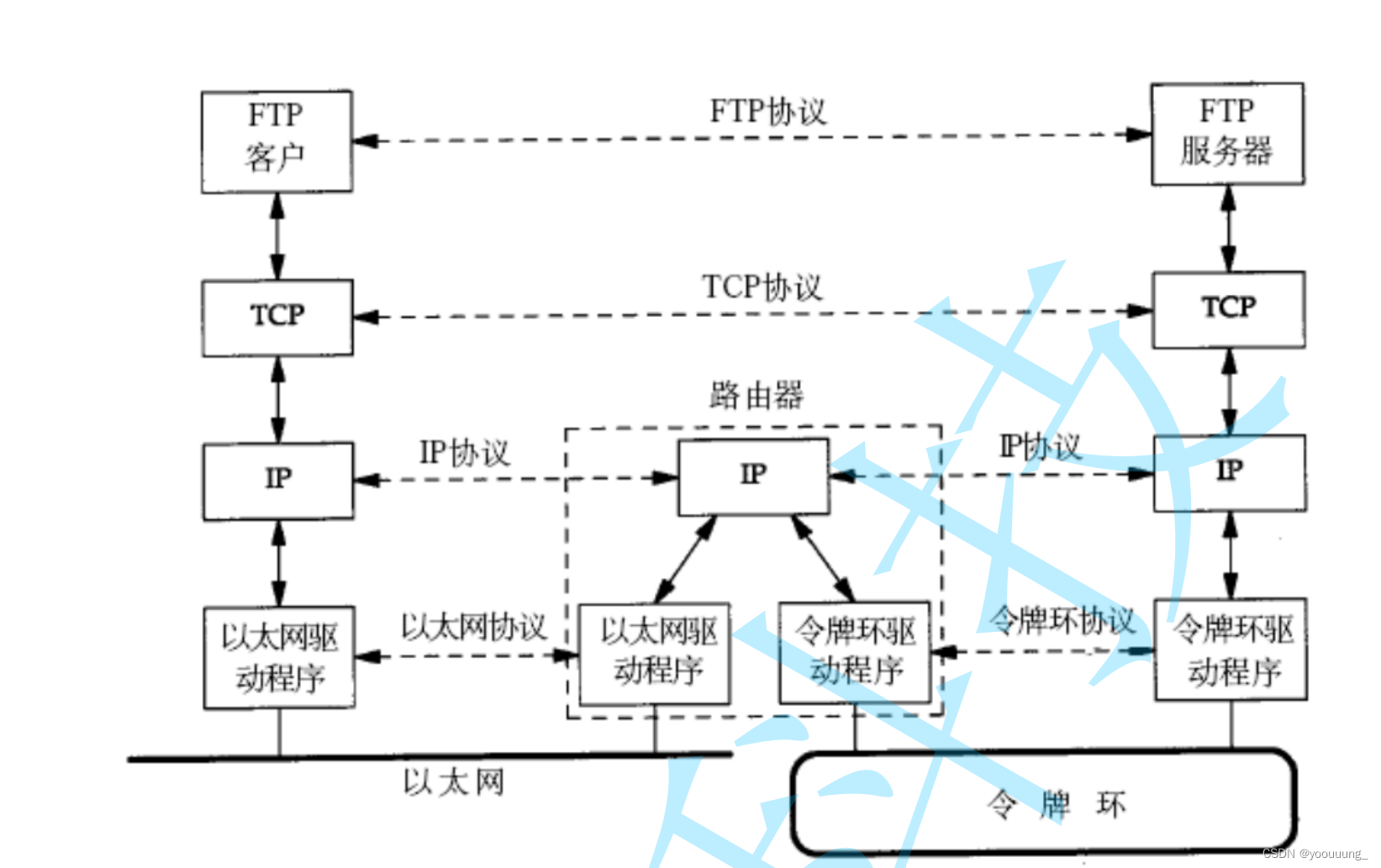
Linux入门-网络基础|网络协议|OSI七层模型|TCP/IP五层模型|网络传输基本流程
文章目录 一、网络基础 二、网络协议 1.OSI七层模型 2.TCP/IP五层(或四层)模型 三、网络传输基本流程 1.网络传输流程图 2.数据包封装和分用 四、网络中的地址管理 1.IP地址 2.MAC地址 一、网络基础 网络发展最初是独立模式,即计算…...

docker系列(2) - 常用命令篇
文章目录 2. docker常用命令2.1 参数说明(tomcat案例)2.2 基本命令2.3 高级命令2.4 其他 2. docker常用命令 2.1 参数说明(tomcat案例) 注意如果分成多行,\后面不能有空格 # 拉取运行 docker run \ -d \ -p 8080:8080 \ --privilegedtrue \ --restartalways \ -m…...

Debian11安装MySQL8.0,链接Navicat
图文小白教程 1 下载安装MySQL1.1 从MySQL官网下载安装文件1.2 安装MySQL1.3 登录MySQL 2 配置Navicat远程访问2.1 修改配置2.2 Navicat 连接 end: 卸载 MySQL 记录于2023年9月,Debian11 、 MySQL 8.0.34 1 下载安装MySQL 1.1 从MySQL官网下载安装文件 打开 MySQ…...
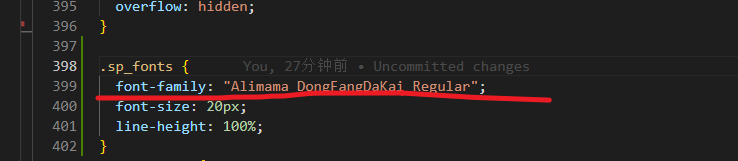
vue项目中使用特殊字体的步骤
写在前面 在项目中使用特殊字体,需要注意,所使用的特殊字体是否被允许商用或是个人开发,以及如何使用,切记不要侵权。 首先需要在对应字体网站下载字体文件,取出里面后缀名为.ttf的文件 然后把该文件放到src -> ass…...
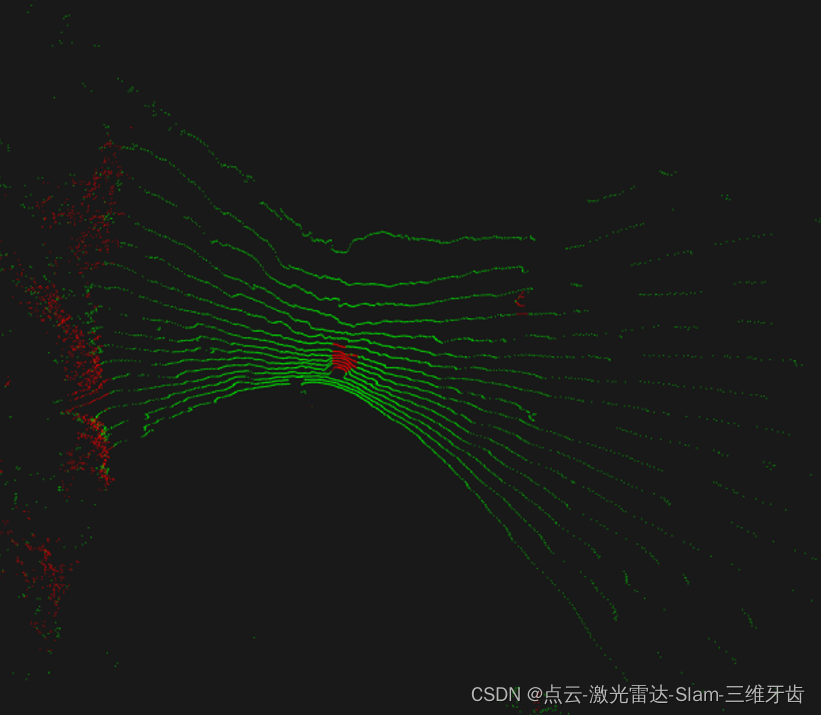
激光雷达检测负障碍物(附大概 C++ 代码)
检测效果如图,红色是正负的障碍物点: 障碍物根据其相对于地面的高度可以分为两类:正向障碍物和负向障碍物。在室外环境中,负障碍物是沟渠、悬崖、洞口或具有陡峭负坡度的地形,可能会造成安全隐患。 不慎通过道路坑洼处…...

【每日一题】9.13 PING是怎么工作的?
PING命令的作用是什么? PING命令是计算机网络中常用的命令之一,它的作用是测试两台计算机之间的连通性以及测量数据包往返的时间。 PING命令的工作原理是什么? PING命令的工作原理涉及到ICMP(Internet Control Message Protocol)和网络协议栈的操作: 1.发送ICMP …...
)
【Python百日进阶-Web开发-Peewee】Day279 - SQLite 扩展(四)
文章目录 12.2.10 class FTSModel 12.2.10 class FTSModel class FTSModel与FTS3 和 FTS4 全文搜索扩展VirtualModel一起使用的子类。 FTSModel 子类应该正常定义,但是有几个注意事项: 不支持唯一约束、非空约束、检查约束和外键。字段索引和多列索引…...
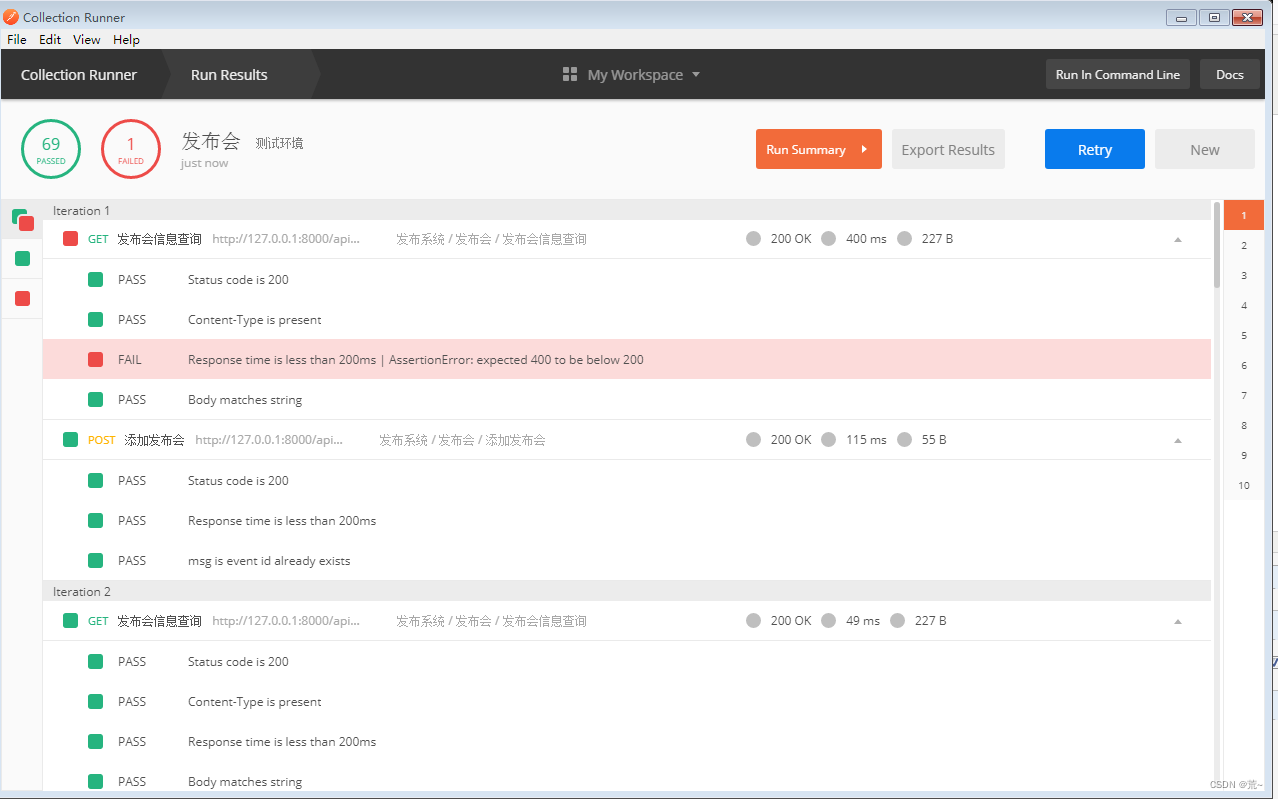
Postman接口压力测试 ---- Tests使用(断言)
所谓断言,主要用于测试返回的数据结果进行匹配判断,匹配成功返回PASS,失败返回FAIL。 下图方法一,直接点击右侧例子函数,会自动生成出现在左侧窗口脚本,只需修改数据即可。 方法二:直接自己写脚…...
nvue文件中@click.stop失效
在nvue文件中在子元素使用click.stop失效,父元素的事件触发了 在uniapp开发中nvue文件是跟vue文件是不一样的,就比如click.stop阻止点击事件继续传播就失效了,这时我们需要在子元素事件中添加条件编译,这样就会解决这个问题 // …...
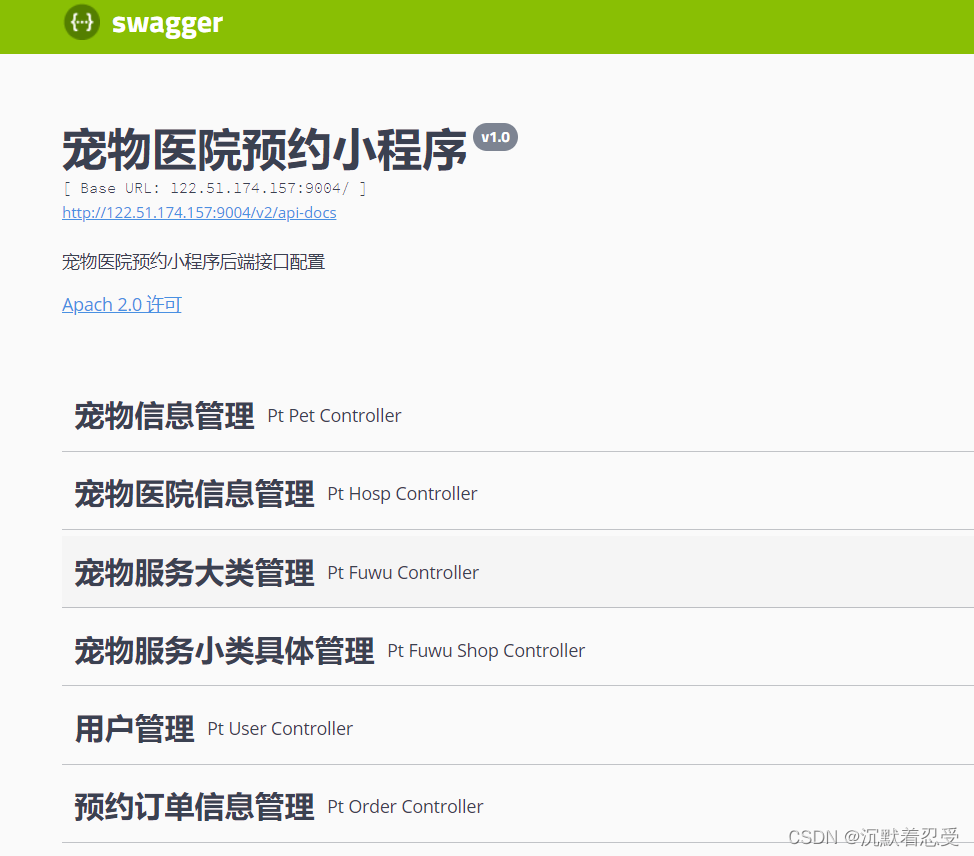
【微信小程序开发】宠物预约医疗项目实战-开发功能介绍
【微信小程序开发】宠物医院项目实战-开发功能介绍 前言 本项目主要带领大家学习微信小程序开发技术,通过一个完整的项目系统的学习微信小程序的开发过程。鉴于一些同学对视频教学跟不上节奏,为此通过图文描述的方式,完整的将系统开发过程记…...
vue网页缓存页面与不缓存页面处理
在主路由页面 <template><div style"height: 100%"><!-- 缓存 --><keep-alive><router-view v-if"$route.meta.keepAlive"></router-view></keep-alive><!-- 不缓存 --><router-view v-if"!$rou…...
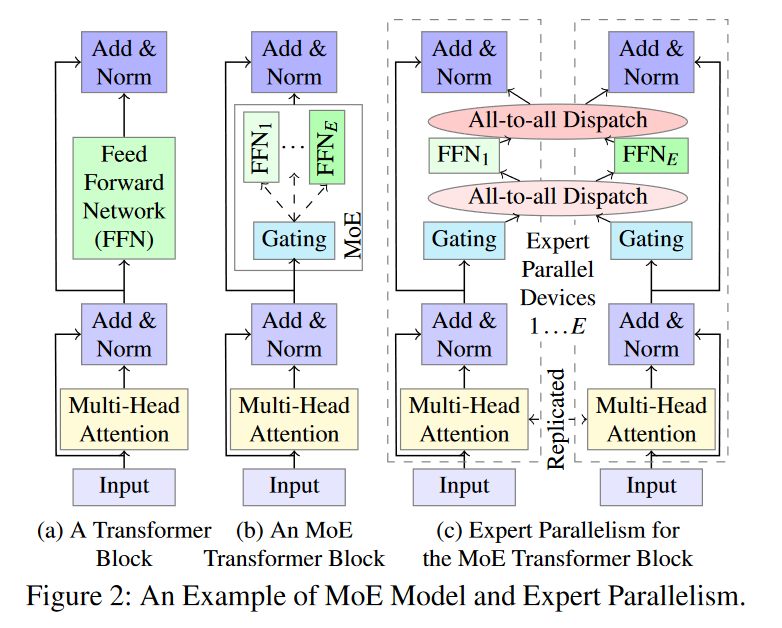
AI系统论文阅读:SmartMoE
提出稀疏架构是为了打破具有密集架构的DNN模型中模型大小和计算成本之间的连贯关系的——最著名的MoE。 MoE模型将传统训练模型中的layer换成了多个expert sub-networks,对每个输入,都有一层special gating network 来将其分配到最适合它的expert中&…...
AD20多层板设计中的平电层设计规则
一般情况下的多层板设计非常复杂,尤其层叠的次序以及平电层的电源层设计,Gnd层的设计比较简单,不需要过多的关注,但是电源层的设计非常关键,常常让人感到无法下手的感觉,这里介绍一个简单的防盲很快的让你上…...
)
Google Maps路线优化突遭瓶颈?Gemini大模型如何将平均行程时间压缩23.6%(2024Q2实测数据)
更多请点击: https://intelliparadigm.com 第一章:Google Maps路线优化突遭瓶颈?Gemini大模型如何将平均行程时间压缩23.6%(2024Q2实测数据) 当Google Maps在高并发城市网格中遭遇动态交通建模失准、实时事件响应延迟…...

三极直接耦合放大电路参数优化
简 介: 本文探讨了三极直接耦合放大电路的优化设计。通过调整R3、R6等电阻参数,使Q3集电极偏置电压达到6V左右,实现了10V的输出动态范围。理论分析电路放大倍数为1000倍,实测为800倍。研究发现第一级放大管Q1处于弱放大状态&#…...

QAbstractTableModel进阶实战:构建可编辑数据表格的完整指南
1. 从零理解QAbstractTableModel的核心机制 第一次接触Qt模型视图框架时,很多人会被QAbstractTableModel这个抽象类吓到。但当我真正用它完成第一个可编辑表格后,发现它的设计其实非常优雅。想象你正在开发一个学生管理系统,需要展示包含姓名…...

AI时代数据中心架构变革:从计算中心到加速基础设施
1. 从“计算中心”到“加速基础设施”:数据中心架构的范式转移最近和几个在头部云厂商做架构设计的老朋友聊天,话题总绕不开一个词:加速基础设施。这词儿听起来挺高大上,但说白了,就是咱们传统数据中心那套“通用计算存…...

从F103到F407:老STM32玩家升级指南,详解性能差异与项目移植实战
从F103到F407:老STM32玩家升级指南,详解性能差异与项目移植实战 对于熟悉STM32F1系列开发的工程师来说,升级到F407系列既是一次性能跃迁的机会,也伴随着学习曲线和移植挑战。本文将深入剖析两款芯片的差异,并提供可落地…...

FreeRTOS在RISC-V上的第一个main.c:从创建任务到理解Hook函数的完整流程
FreeRTOS在RISC-V上的第一个main.c:从创建任务到理解Hook函数的完整流程 当你在RISC-V平台上第一次打开main.c文件准备编写FreeRTOS应用时,可能会被那些看似神秘的函数和配置选项所困扰。这篇文章将带你从零开始,逐步构建一个完整的FreeRTOS应…...

Topit:突破macOS窗口层级限制,打造极致高效的多任务工作流
Topit:突破macOS窗口层级限制,打造极致高效的多任务工作流 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 想象一下这样的场景ÿ…...

别再乱用STOP模式了!STM32L4三种STOP模式深度对比与选型实战
STM32L4低功耗设计实战:STOP模式选型与能效优化全解析 在物联网终端设备与便携式仪器开发中,每微安电流的节省都直接关系到产品的市场竞争力。最近为一个农业传感器项目做方案评审时,发现团队在STOP模式选择上存在严重误区——工程师们习惯性…...

League-Toolkit:基于LCU API的英雄联盟客户端自动化工具深度解析
League-Toolkit:基于LCU API的英雄联盟客户端自动化工具深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit是…...
)
从IR2184到全桥驱动:搞懂H桥电路防短路与死区设置(附电路图分析)
从IR2184到全桥驱动:H桥电路防短路与死区设置的工程实践 在电机控制系统中,H桥电路的设计可靠性直接决定了整个驱动方案的成败。许多工程师在初次设计基于IR2184的全桥驱动时,往往会被"上下桥臂直通"问题困扰——这种短路状态能在微…...