【Python百日进阶-Web开发-Peewee】Day279 - SQLite 扩展(四)
文章目录
- 12.2.10 class FTSModel
12.2.10 class FTSModel
class FTSModel
与FTS3 和 FTS4 全文搜索扩展VirtualModel一起使用的子类。
FTSModel 子类应该正常定义,但是有几个注意事项:
- 不支持唯一约束、非空约束、检查约束和外键。
- 字段索引和多列索引被完全忽略
- Sqlite 会将所有列类型视为TEXT(尽管您可以存储其他数据类型,但 Sqlite 会将它们视为文本)。
- FTS 模型包含一个rowid由 SQLite 自动创建和管理的字段(除非您选择在模型创建期间显式设置它)。此列的查找快速而有效。
鉴于这些约束,强烈建议在FTSModel子类上声明的所有字段都是的实例 SearchField(尽管显式声明 a 时例外RowIDField)。使用SearchField将有助于防止您意外创建无效的列约束。如果您希望将元数据存储在索引中,但不希望将其包含在全文索引中,则unindexed=True在实例化 SearchField.
上述情况的唯一例外是rowid主键,可以使用RowIDField. 查找rowid非常有效。如果您使用的是 FTS4,您也可以使用DocIDField,这是 rowid 的别名(尽管这样做没有任何好处)。
rowid由于缺少二级索引,因此将主键用作指向常规表中行的指针通常是有意义的。例如:
class Document(Model):# Canonical source of data, stored in a regular table.author = ForeignKeyField(User, backref='documents')title = TextField(null=False, unique=True)content = TextField(null=False)timestamp = DateTimeField()class Meta:database = dbclass DocumentIndex(FTSModel):# Full-text search index.rowid = RowIDField()title = SearchField()content = SearchField()class Meta:database = db# Use the porter stemming algorithm to tokenize content.options = {'tokenize': 'porter'}
要将文档存储在文档索引中,我们将INSERT一行放入DocumentIndex表中,手动设置rowid,使其与相应的主键匹配Document:
def store_document(document):DocumentIndex.insert({DocumentIndex.rowid: document.id,DocumentIndex.title: document.title,DocumentIndex.content: document.content}).execute()
要执行搜索并返回排名结果,我们可以查询 Document表并在DocumentIndex. 这种连接会很有效,因为在 FTSModelrowid字段上的查找速度很快:
def search(phrase):# Query the search index and join the corresponding Document# object on each search result.return (Document.select().join(DocumentIndex,on=(Document.id == DocumentIndex.rowid)).where(DocumentIndex.match(phrase)).order_by(DocumentIndex.bm25()))
警告
除了全文搜索和查找之外,所有关于类的 SQL 查询FTSModel都将是全表扫描 。rowid
如果要索引的内容的主要来源存在于单独的表中,则可以通过指示 SQLite 不存储搜索索引内容的附加副本来节省一些磁盘空间。SQLite 仍将创建对内容执行搜索所需的元数据和数据结构,但内容本身不会存储在搜索索引中。
为此,您可以使用该content 选项指定表或列。FTS4 文档 有更多信息。
这是一个简短的示例,说明如何使用 peewee 实现此功能:
class Blog(Model):title = TextField()pub_date = DateTimeField(default=datetime.datetime.now)content = TextField() # We want to search this.class Meta:database = dbclass BlogIndex(FTSModel):content = SearchField()class Meta:database = dboptions = {'content': Blog.content} # <-- specify data source.db.create_tables([Blog, BlogIndex])# Now, we can manage content in the BlogIndex. To populate the
# search index:
BlogIndex.rebuild()# Optimize the index.
BlogIndex.optimize()
该content选项接受 singleField或 a Model并且可以减少database文件使用的存储量。但是,内容将需要手动移入/移出关联的FTSModel.
classname match(term)
参数: term– 搜索词或表达。
生成表示在表中搜索给定术语或表达式的 SQL 表达式。SQLite 使用MATCH运算符来指示全文搜索。
例子:
# Search index for "search phrase" and return results ranked
# by relevancy using the BM25 algorithm.
query = (DocumentIndex.select().where(DocumentIndex.match('search phrase')).order_by(DocumentIndex.bm25()))
for result in query:print('Result: %s' % result.title)
classmethod search(term[, weights=None[, with_score=False[, score_alias=‘score’[, explicit_ordering=False]]]])
参数:
- term ( str ) – 要使用的搜索词。
- weights – 列的权重列表,根据列在表中的位置排序。或者,以字段或字段名称为键并映射到值的字典。
- with_score – 分数是否应作为SELECT语句的一部分返回。
- score_alias ( str ) – 用于计算排名分数的别名。这是您将用于访问分数的属性 if with_score=True。
- explicit_ordering ( bool ) – 使用完整的 SQL 函数来计算排名,而不是简单地在 ORDER BY 子句中引用分数别名。
搜索术语并按匹配质量对结果进行排序的简写方式。
笔记
该方法使用简化的算法来确定结果的相关等级。要获得更复杂的结果排名,请使用该search_bm25()方法。
# Simple search.
docs = DocumentIndex.search('search term')
for result in docs:print(result.title)# More complete example.
docs = DocumentIndex.search('search term',weights={'title': 2.0, 'content': 1.0},with_score=True,score_alias='search_score')
for result in docs:print(result.title, result.search_score)
classmethod search_bm25(term[, weights=None[, with_score=False[, score_alias=‘score’[, explicit_ordering=False]]]])
参数:
- term ( str ) – 要使用的搜索词。
- weights – 列的权重列表,根据列在表中的位置排序。或者,以字段或字段名称为键并映射到值的字典。
- with_score – 分数是否应作为SELECT语句的一部分返回。
- score_alias ( str ) – 用于计算排名分数的别名。这是您将用于访问分数的属性 if with_score=True。
- explicit_ordering ( bool ) – 使用完整的 SQL 函数来计算排名,而不是简单地在 ORDER BY 子句中引用分数别名。
使用 BM25 算法根据匹配质量搜索术语和排序结果的简写方式。
注意
BM25 排名算法仅适用于 FTS4。如果您使用的是 FTS3,请改用该search()方法。
classmethod search_bm25f(term[, weights=None[, with_score=False[, score_alias=‘score’[, explicit_ordering=False]]]])
与 相同FTSModel.search_bm25(),但使用 BM25 排名算法的 BM25f 变体。
classmethod search_lucene(term[, weights=None[, with_score=False[, score_alias=‘score’[, explicit_ordering=False]]]])
与 相同FTSModel.search_bm25(),但使用来自 Lucene 搜索引擎的结果排名算法。
classname rank([col1_weight , col2_weight…coln_weight])
参数: col_weight( float ) - (可选) 赋予模型第 i列的权重。默认情况下,所有列的权重为1.0.
生成将计算并返回搜索匹配质量的表达式。这rank可用于对搜索结果进行排序。较高的排名分数表示更好的匹配。
该rank函数接受允许您为各个列指定权重的可选参数。如果未指定权重,则认为所有列都具有同等重要性。
笔记
使用的算法rank()简单且相对较快。要获得更复杂的结果排名,请使用:
- bm25()
- bm25f()
- lucene()
query = (DocumentIndex.select(DocumentIndex,DocumentIndex.rank().alias('score')).where(DocumentIndex.match('search phrase')).order_by(DocumentIndex.rank()))for search_result in query:print(search_result.title, search_result.score)
classname bm25([col1_weight , col2_weight…coln_weight])
参数: col_weight( float ) - (可选) 赋予模型第 i列的权重。默认情况下,所有列的权重为1.0.
生成一个表达式,该表达式将使用BM25 算法计算并返回搜索匹配的质量。该值可用于对搜索结果进行排序,分数越高,匹配越好。
像rank(),bm25function 接受可选参数,允许您为各个列指定权重。如果未指定权重,则认为所有列都具有同等重要性。
注意
BM25结果排名算法需要FTS4。如果您使用的是 FTS3,请rank()改用。
query = (DocumentIndex.select(DocumentIndex,DocumentIndex.bm25().alias('score')).where(DocumentIndex.match('search phrase')).order_by(DocumentIndex.bm25()))for search_result in query:print(search_result.title, search_result.score)
笔记
上面的代码示例等价于调用 search_bm25()方法:
query = DocumentIndex.search_bm25('search phrase', with_score=True)
for search_result in query:print(search_result.title, search_result.score)
classname bm25f([col1_weight , col2_weight…coln_weight])
与 相同bm25(),只是它使用 BM25 排名算法的 BM25f 变体。
classname lucene([col1_weight , col2_weight…coln_weight])
与 相同bm25(),只是它使用 Lucene 搜索结果排名算法。
classname rebuild()
重建搜索索引——这仅content在创建表期间指定选项时有效。
classname optimize()
优化搜索索引。
相关文章:
)
【Python百日进阶-Web开发-Peewee】Day279 - SQLite 扩展(四)
文章目录 12.2.10 class FTSModel 12.2.10 class FTSModel class FTSModel与FTS3 和 FTS4 全文搜索扩展VirtualModel一起使用的子类。 FTSModel 子类应该正常定义,但是有几个注意事项: 不支持唯一约束、非空约束、检查约束和外键。字段索引和多列索引…...
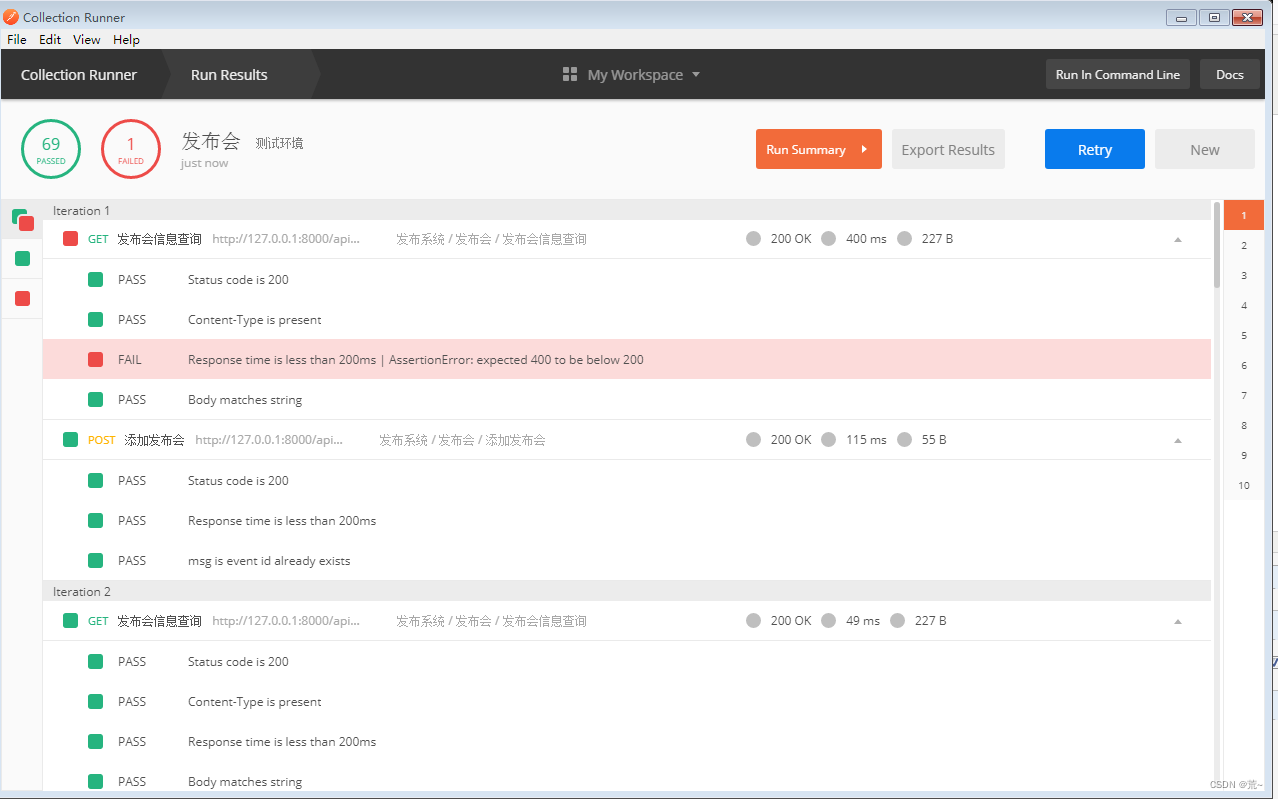
Postman接口压力测试 ---- Tests使用(断言)
所谓断言,主要用于测试返回的数据结果进行匹配判断,匹配成功返回PASS,失败返回FAIL。 下图方法一,直接点击右侧例子函数,会自动生成出现在左侧窗口脚本,只需修改数据即可。 方法二:直接自己写脚…...
nvue文件中@click.stop失效
在nvue文件中在子元素使用click.stop失效,父元素的事件触发了 在uniapp开发中nvue文件是跟vue文件是不一样的,就比如click.stop阻止点击事件继续传播就失效了,这时我们需要在子元素事件中添加条件编译,这样就会解决这个问题 // …...
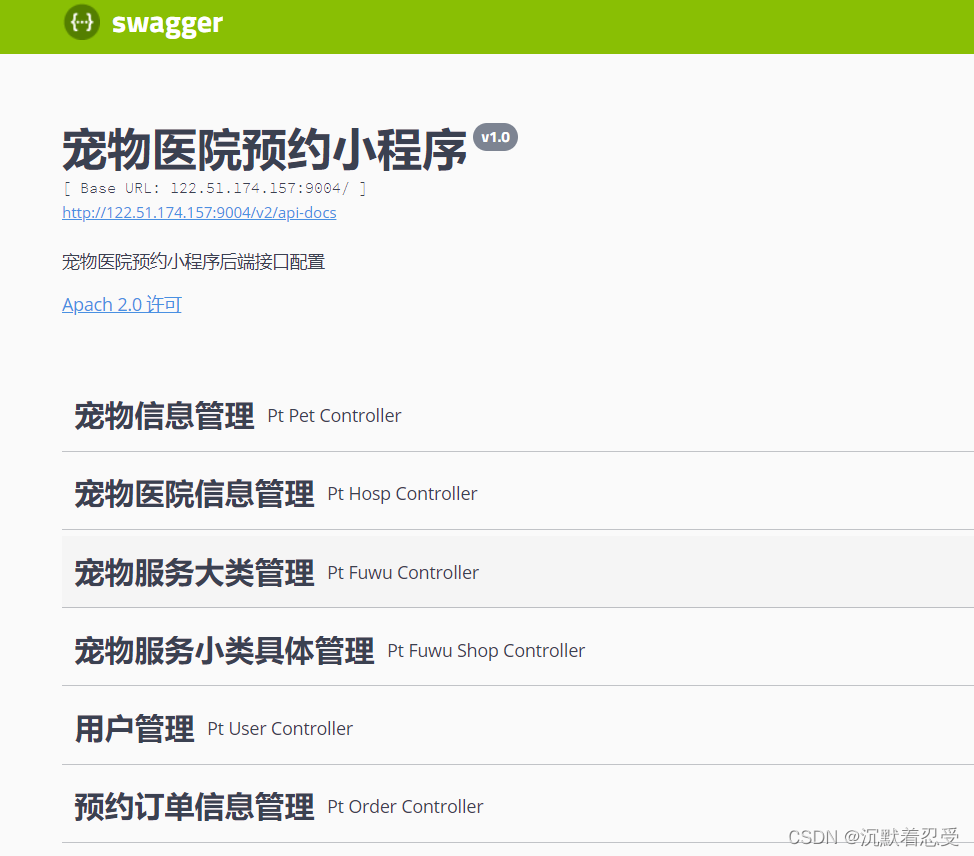
【微信小程序开发】宠物预约医疗项目实战-开发功能介绍
【微信小程序开发】宠物医院项目实战-开发功能介绍 前言 本项目主要带领大家学习微信小程序开发技术,通过一个完整的项目系统的学习微信小程序的开发过程。鉴于一些同学对视频教学跟不上节奏,为此通过图文描述的方式,完整的将系统开发过程记…...
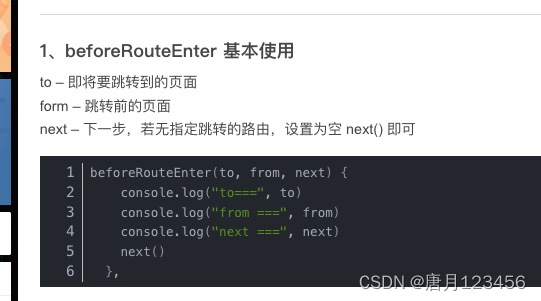
vue网页缓存页面与不缓存页面处理
在主路由页面 <template><div style"height: 100%"><!-- 缓存 --><keep-alive><router-view v-if"$route.meta.keepAlive"></router-view></keep-alive><!-- 不缓存 --><router-view v-if"!$rou…...
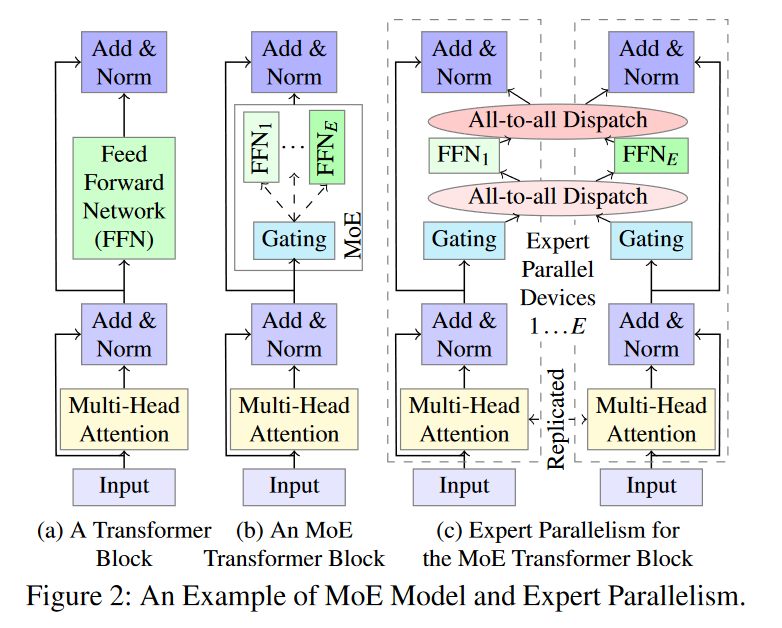
AI系统论文阅读:SmartMoE
提出稀疏架构是为了打破具有密集架构的DNN模型中模型大小和计算成本之间的连贯关系的——最著名的MoE。 MoE模型将传统训练模型中的layer换成了多个expert sub-networks,对每个输入,都有一层special gating network 来将其分配到最适合它的expert中&…...
AD20多层板设计中的平电层设计规则
一般情况下的多层板设计非常复杂,尤其层叠的次序以及平电层的电源层设计,Gnd层的设计比较简单,不需要过多的关注,但是电源层的设计非常关键,常常让人感到无法下手的感觉,这里介绍一个简单的防盲很快的让你上…...

压力测试有哪些评价指标
在进行压力测试时,您可以评估多个指标来确定系统的性能和稳定性。以下是一些常见的压力测试评价指标: 响应时间(Response Time): 平均响应时间:请求的平均处理时间。 最大响应时间:最长处理时…...

简单 php结合WebUploader实现文件上传功能
WebUploader 资源下载 http://fex.baidu.com/webuploader/download.html WebUploader 使用方法 http://fex.baidu.com/webuploader/getting-started.html php 上传代码 <?php header(Content-type:text/html;charsetutf-8);if($_FILES[file][error] 0){ // 判断上传是…...

Pandas数据分析一览-短期内快速学会数据分析指南(文末送书)
前言 三年耕耘大厂数据分析师,有些工具是必须要掌握的,尤其是Python中的数据分析三剑客:Pandas,Numpy和Matplotlib。就以个人经验而已,Pandas是必须要掌握的,它提供了易于使用的数据结构和数据操作工具&am…...

应用程序分类与相关基本概念介绍
0、引言 在从事软件开发的过程中,由于笔者并不是计算机专业的同学,所以时常会对一些概念感到困惑。比如: 前些年很火的前端和后端是什么意思?什么是 GUI?什么是 CLI?计算机的应用程序分为哪些种类&#x…...

springcloude gateway的意义
应用场景 1、南北向流量 需要流量网关和微服务网关配合使用,将内部的微服务能力,以统一的 HTTP 接入点对外提供服务。 流量网管主要是接入流量进行负载均衡,上游的微服务网关地址和数量变化不大,对服务发现要求不高。 微服务网…...

重新定义每天进步一点点
日拱一卒,每天进步一点点~ 这个主题之前写过一次,今天看了《全情投入》又有了新的感触,于是将其记录下来。 关于目标的设定问题 目标不是改变自己的日常行动,而是改变进行活动时的思维! 有些事情,坚持下…...

代码随想录算法训练营第51天 | ● 309.最佳买卖股票时机含冷冻期 ● 714.买卖股票的最佳时机含手续费
文章目录 前言一、309.最佳买卖股票时机含冷冻期二、714.买卖股票的最佳时机含手续费总结 前言 买卖股票 完结; 一、309.最佳买卖股票时机含冷冻期 确定dp数组以及下标的含义 dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]。 其实本题很多…...
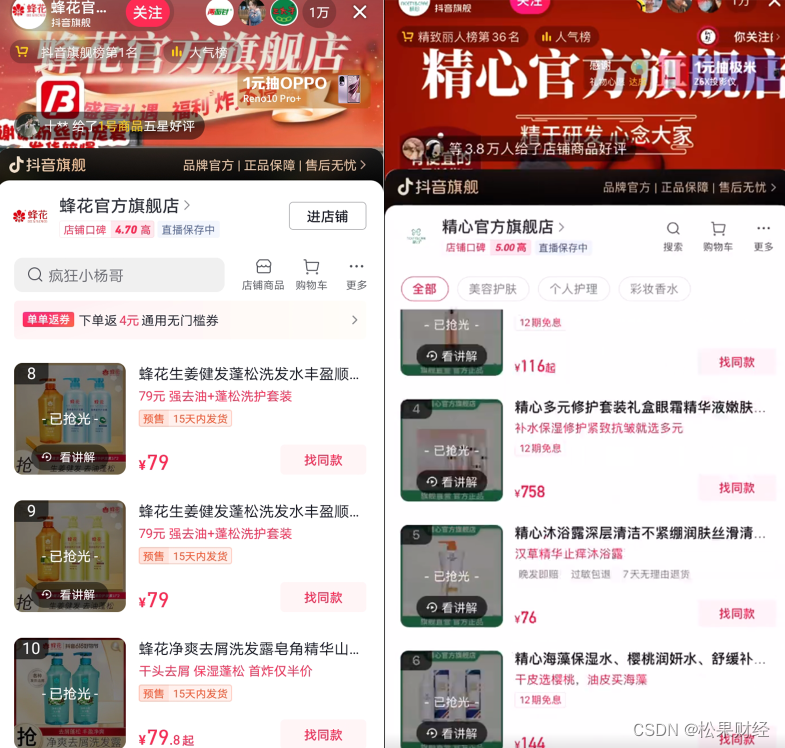
李佳琦掉粉,国货品牌却从“商战大剧”走向“情景喜剧”
李佳琦直播间带货怼网友,“哪里贵了,国货很难的”“这么多年工资没涨,有没有认真工作?”本人事后垂泪道歉仍掉粉百万,但是闻风而来的国货品牌却迎来了一场流量盛宴。 从蜂花蹲点“捡”粉丝,上架三款79元洗…...
linux 下 C++ 与三菱PLC 通过MC Qna3E 二进制 协议进行交互
西门子plc 有snap7库 进行交互,并且支持c 而且跨平台。但是三菱系列PLC并没有现成的开源项目,没办法只能自己拼接,我这里实现了MC 协议 Qna3E 帧,并使用二进制进行交互。 #pragma once#include <stdio.h> #include <std…...

Spring基础(2w字---学习总结版)
目录 一、Spirng概括 1、什么是Spring 2、什么是容器 3、什么是IoC 4、模拟实现IoC 4.1、传统的对象创建开发 5、理解IoC容器 6、DI概括 二、创建Spring项目 1、创建spring项目 2、Bean对象 2.1、创建Bean对象 2.2、存储Bean对象(将Bean对象注册到容器…...
07 目标检测-YOLO的基本原理详解
一、YOLO的背景及分类模型 1、YOLO的背景 上图中是手机中的一个app,在任何场景下(工业场景,生活场景等等)都可以试试这个app和这个算法,这个app中间还有一个button,来调节app使用的模型的大小,更大的模型实时性差但精…...
)
每日一题 78子集(模板)
题目 78 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 示例 1: 输入:nums [1,2,3] 输出:[[],[1],[2]…...

OpenCV之形态学操作
形态学操作包含以下操作: 腐蚀 (Erosion)膨胀 (Dilation)开运算 (Opening)闭运算 (Closing)形态梯度 (Morphological Gradient)顶帽 (Top Hat)黑帽(Black Hat) 其中腐蚀和膨胀操作是最基本的操作,其他操作由这两个操作变换而来。 腐蚀 用一个结构元素…...
图灵测试作为智能与否的标准)
图解人工智能(8)图灵测试作为智能与否的标准
有人不同意将图灵测试作为智能与否的标准。他们认为,就算机器表现得和人一样,也不能说机器拥有了智能,因为它只是一堆电路,和人的思维方式完全不同。你是否赞同这种说法?说说你赞同或反对的理由。开放讨论题。有几种观…...

告别运行库安装烦恼:Visual C++ AIO合集一键搞定所有版本
告别运行库安装烦恼:Visual C AIO合集一键搞定所有版本 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经为了运行某个软件而四处寻找不同版…...

5分钟快速上手:如何用Video2X免费AI工具让老旧视频焕发4K新生
5分钟快速上手:如何用Video2X免费AI工具让老旧视频焕发4K新生 【免费下载链接】video2x A machine learning-based video super resolution and frame interpolation framework. Est. Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trending/v…...

嵌入式固件安全更新与密钥管理实践
1. 嵌入式固件安全更新概述在嵌入式系统开发中,固件更新是设备生命周期管理的关键环节。不同于传统PC软件的更新,嵌入式设备的固件更新面临更多挑战:受限的计算资源、不稳定的通信环境、严苛的安全要求等。我曾参与过多个工业控制设备的OTA升…...

GDScript Mod Loader:为Godot游戏打造专业模组生态的完整指南
1. 项目概述:为你的Godot游戏注入社区活力如果你是一名使用Godot引擎的独立游戏开发者,或者是一位热衷于为喜爱的游戏创造新内容的玩家,那么“模组”这个概念你一定不陌生。模组,或者说Mod,是游戏社区生命力的重要源泉…...

AI技能文件管理工具agent-skills-lint:多助手环境下的统一质检方案
1. 项目概述:为什么我们需要一个AI技能文件“质检员”如果你和我一样,同时在使用Claude Code、Cursor、Aider这些AI编程助手,那你一定遇到过这个烦人的问题:每个助手都有自己的“技能”(Skills)系统&#x…...

Cursor-Buddy:基于AI的Web界面语音交互与视觉引导助手
1. 项目概述与核心价值最近在捣鼓一个挺有意思的开源项目,叫cursor-buddy。简单来说,它是一个能“住”在你鼠标光标里的AI助手,专门为Web应用设计。想象一下,你在浏览一个复杂的后台管理系统或者一个数据看板,突然想找…...

别只盯着SQL了!GaussDB健康度巡检,这5个‘外围’命令和日志文件更重要
别只盯着SQL了!GaussDB健康度巡检,这5个‘外围’命令和日志文件更重要 当数据库出现性能波动时,大多数DBA的第一反应是检查慢SQL或调整参数。但根据某金融客户的生产环境统计,超过60%的数据库故障其实源于日志溢出、网络闪断或备份…...

41《CAN总线报文周期、抖动与实时性分析》
CAN总线基础:从物理层到数据链路层的核心概念 一、一个让我熬夜的CAN问题 去年调试某款车载ECU时遇到个诡异现象:同一批次的控制器,有的在-20℃低温下CAN通信完全正常,有的却频繁丢帧。示波器挂上去一看,显性电平的下降沿斜率明显变缓,从正常的15ns拖到了40ns。查了三天…...

实测MPU6050低功耗电流:从Sleep到Cycle模式,不同唤醒频率下功耗到底差多少?
MPU6050低功耗模式实测:从微安级电流到唤醒策略的硬件优化指南 当你的智能手环在手腕上安静沉睡时,MPU6050这颗运动传感器正在以微安级的电流维持着生命体征——这不是魔法,而是现代嵌入式设计中精妙的低功耗艺术。作为硬件工程师,…...