AI系统论文阅读:SmartMoE

提出稀疏架构是为了打破具有密集架构的DNN模型中模型大小和计算成本之间的连贯关系的——最著名的MoE。
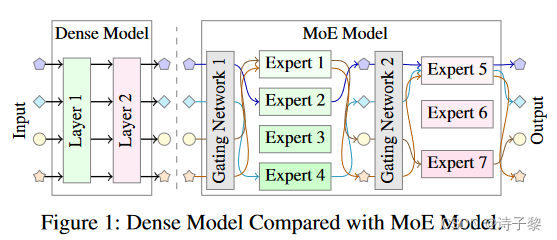
MoE模型将传统训练模型中的layer换成了多个expert sub-networks,对每个输入,都有一层special gating network 来将其分配到最适合它的expert中,然后被expert处理。于此对应,很多expert会不得不处理多个输入,但另一些则几乎不处理输入——data-sensitive (数据敏感的)
但现有的并行方法无法解决MoE遇到的问题,有以下两个原因:
Limited Optimization Space
当前工作并没有充分利用MoE模型的不同expert工作负载的差异,并且甚至假设子网络上的工作负载是相同的,从而排除了很多优化空间。
Large Searching Overhead
我没看懂这段对应的话与这个题目有什么关系。
然后提出了SMARTMoE – an automatic parallelization training system for sparsely activated models.
(稀疏激活模型的自动并行化训练系统)。
内容
模型基于两步:
static pool:基于离线构建的可相互转换的并行策略组成的静态池
dynamic adaption 动态自适应:运行时在构建的池内进行快速动态自适应 在线
两者结合来选择适合当前工作负载的策略。
2 Background and Motivation
MoE:Misture-of-Experts
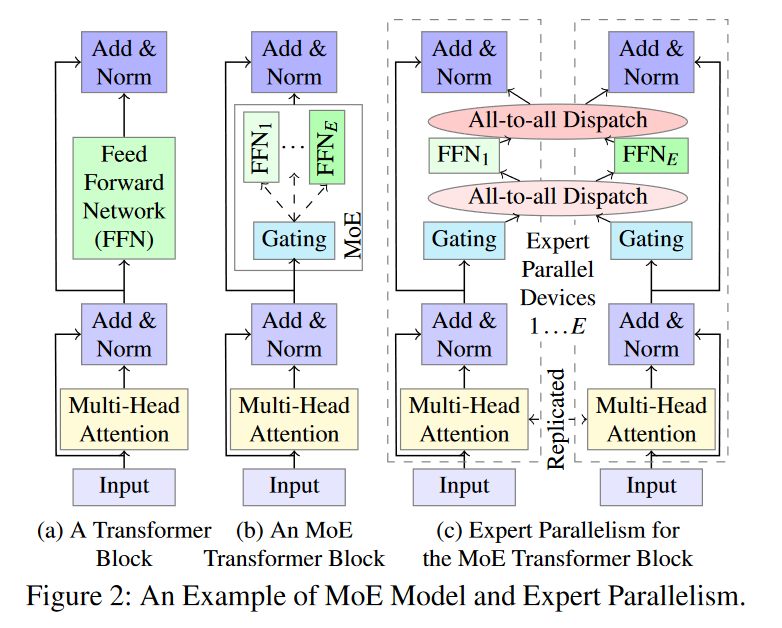
FFN为MoE模型中的专家,多个FFN和一个Gating组成了基本的MoE模型。
2.2 混合和自动并行化
训练密集型深度学习网络的常见的三种并行方式:
Data Parallelism(DP)
每个worker均存储一个完整的参数副本,分配给每个worker的训练样本都不同,并且前向传播和反向传播是在每个worker上独立完成的, then gradients on different workers will be aggregated before being used in the optimization of the model.
disadvantages: 由于参数需要在每个workder中同步和复制,因此会造成内存浪费和communication overhead.
Pipeline Model Parallelism(PP)
参见之前的DSP的文章,就用的PP这个思路:将训练过程分为多个阶段:Sampling,loading and training。
然后每个worker负责一个,会导致communication过程的时间花销变大。
Tensor Model Parallelism(TP)
张量模型并行(Tensor Model Parallelism,TP)是一种人工智能领域的技术。模型的单个运算符被分割成多个工作节点(workers)。每个工作节点存储运算符参数的一部分,并执行其中一部分的计算,例如矩阵的一个瓦片(tile)。不同运算符的TP需要由专家专门设计,分割方法对分布式训练性能至关重要。Megatron [35] 提供了在Transformer模型上使用TP的最佳实践。其他研究[36, 38]探讨了TP的统一表示和最高效分割的自动生成。
最后,总结了任何自动并行化训练系统的三个关键挑战:
- Space of Hybrid Parallelism(混合并行空间)
不同策略的混合使用可能会带来适应的问题
- Performance Modeling 性能建模
性能建模有助于有效探索巨大的混合并行空间。
- Searching Algorithm 搜索算法
因为搜索空间巨大,因此要找一个好的搜索算法。
2.3 Challenges of Automatic Parallelization for MoE Models
用下图解释自动并行MoE模型的挑战性:

- 更大的混合并行空间。
因为模型要额外考虑不同expert之间的组合差异,如E0与E1组合还是E0与E3组合。(一个MoE layer 有四个expert)
- 工作负载感知性能建模
传统的性能建模方式仅使用模型结构和硬件信息来估计性能,缺乏对工作负载的考虑。因为在上图中,上下两个工作负载使得同一个方案出现了效率上的差异。
- 自适应动态并行化
由于MoE训练过程会出现不同工作负载,因此我们需要自适应自动并行化,该方法采用运行时执行方案搜索和切换来保持训练过程高效率。训练系统可以在每次迭代时更新执行计划,以实现最终的高性能。
3 Overview——SmartMoE
以往的自动并行系统仅在训练前搜索最佳执行计划。SmartMoE则采用两阶段方法:
他们使用了更大的混合并行空间来搜索最优执行计划,并且把自动并行过程分为了两阶段:offline and online,具体见图4:

阶段1:offline pool construction
SmartMoE将一些执行计划划分为一个聚类,作为一个pool(一共就构建这一个),他们彼此之间进行切换的代价适中。该模型会在训练之前构建一个较好的pool,并使其保持在线适应能力。
怎么构建?设计了一个数据敏感的性能模型,利用模型规范来估计工作负载,然后再借助传统的搜索算法在运行前就划分出良好的pool。
此处为为池子选择合适的并行策略组合。
阶段2:online adaptive parallelization
阶段1使得在SmartMoE模型进行训练之前就找到一个良好的pool,但这个pool往往很大,在具体训练时候我们需要再极短的时间内在pool中选择出合适的execution plan(执行方案)。因此作者开发了轻量级算法来完成这个任务。
此处为:pool中给定的并行策略组合,expert placement有多种方案,在在线阶段,依据工作负载的不同,切换合适的expert placement。
4
SmartMoE支持混合并行:支持任意的 数据和张量,管道和expert并行,此外还支持expert placement(专家分布)
expert placement:通常指的是将具有不同领域知识和技能的专家(此处专家通常指具有特定领域知识或技能的实体,可以是机器学习模型、算法、软件程序,较少指人类专家等)或者算法分配到合适的任务或者问题上,以最大程度地发挥其潜力和效率。
SmartMoE使用“expert slot”概念来支持现有并行性的任意组合。专家槽为worker上存储专家子网络参数的基本单元。
"Expert slot"是一种在自然语言处理中使用的概念。它是指一个特定的语言模型中,专门用于识别特定类型的实体或信息的插槽。例如,一个旅游应用程序可能会使用一个专家插槽来识别用户输入中的日期、地点、酒店名称等信息。这些插槽可以帮助应用程序更好地理解用户的意图,并提供更准确的响应。
此处使用三个属性来表示专家槽的配置:
- 每个槽位的容量(Capacity):一个0到1的分数,表示存储了专家子网络的多少
- 每个worker上专家槽的数量(Slots):应该为正数。
- 每个worker上MoE层的数量(Layers)。
举例:假设有一个模型,有 L L L层MoE层,每层MoE层有 E E E个专家,训练在一个有 N N N个worker的集群上, D 、 T 、 P D、T、P D、T、P分别代表数据,张量和管道并行方式,则表1展示了如何为不同的并行策略设置属性:

具体实例: ( L , E , N ) = ( 2 , 4 , 4 ) (L, E, N) = (2, 4, 4) (L,E,N)=(2,4,4) ,两个MoE层,每层有4个专家,在有4个worker的集群上训练。

- EP:expert parallelism:专家并行:同时运行多个专家或者算法,每个专家或算法都负责处理任务的一部分,并在某种程度上独立工作。比如:在分布式计算中,多个计算节点(worker)可以并行地运行不同的任务,每个节点都具有一定的专业知识或者算法来处理特定类型的数据或问题。
- TP:task parallelism任务并行:任务并行是将一个大任务分解成多个较小的子任务,然后并行执行这些子任务的策略。每个子任务可以在不同的处理器核心、线程或计算节点上执行。这种并行策略特别适用于处理大规模数据集或执行多步骤的计算任务。此处应该指上文的Tensor Model parallelism
- DP:data parallelism数据并行:数据并行是将相同的操作应用于多个数据元素的并行策略。通常,多个处理单元会同时处理不同的数据元素,以加速数据处理过程。这种策略常见于并行计算中,如图像处理、矩阵运算等领域。
- PP:pipeline parallelism管道并行:管道并行是将一个任务分成多个阶段,每个阶段由不同的处理单元并行执行。每个处理单元完成其特定阶段的任务,然后将结果传递给下一个处理单元。这种策略通常用于流式数据处理,如编译器优化、音频处理和图像处理。
expert placement plan 指的是从专家子网络到专家槽的一个映射,如图5中的(d),专家槽中指明了设备A,C和则个紫色专家,图则说明了他们的3中不同分布方法。
5 offline pool constrution
5.1 design principle of a pool
- pool产生于训练之前,借助性能模型来完成pool的划分
- pool在整个训练过程中保持不变,在训练时在这个pool中切换执行计划
在SmartMoE中,作者将pool定义为一组执行计划,其中expert placement(这本质上是一种expert到设备dev的映射,即哪些专家放在哪些设备上)是唯一可变的并行策略。
SmartMoE在离线池构建阶段,寻找典型并行策略的优秀组合,在线阶段,再进行组合内部专家分布计划的切换。
优点
1: 灵活性高
2: 切换执行方案时候开销小。因为不同方案仅体现为expert placement的不同,他们具有相同的expert slot,切换时无需内存的变动,而仅需worker之间进行参数交换。
5.2 工作负载感知的性能模型 Workload-Aware Performance Modeling
**性能模型使得在训练之前就能评估不同pool的性能,**但动态工作负载使得我们在实际运行之前无法得知。
因此要估计训练工作量:在训练之前估计专家选择的输出,具体来说,是估计门控(gating)网络(见下图2)的输出。
然后我们将该性能模型应用于候选池,并在开始分布式训练之前枚举搜索空间。
相关文章:
AI系统论文阅读:SmartMoE
提出稀疏架构是为了打破具有密集架构的DNN模型中模型大小和计算成本之间的连贯关系的——最著名的MoE。 MoE模型将传统训练模型中的layer换成了多个expert sub-networks,对每个输入,都有一层special gating network 来将其分配到最适合它的expert中&…...
AD20多层板设计中的平电层设计规则
一般情况下的多层板设计非常复杂,尤其层叠的次序以及平电层的电源层设计,Gnd层的设计比较简单,不需要过多的关注,但是电源层的设计非常关键,常常让人感到无法下手的感觉,这里介绍一个简单的防盲很快的让你上…...

压力测试有哪些评价指标
在进行压力测试时,您可以评估多个指标来确定系统的性能和稳定性。以下是一些常见的压力测试评价指标: 响应时间(Response Time): 平均响应时间:请求的平均处理时间。 最大响应时间:最长处理时…...

简单 php结合WebUploader实现文件上传功能
WebUploader 资源下载 http://fex.baidu.com/webuploader/download.html WebUploader 使用方法 http://fex.baidu.com/webuploader/getting-started.html php 上传代码 <?php header(Content-type:text/html;charsetutf-8);if($_FILES[file][error] 0){ // 判断上传是…...

Pandas数据分析一览-短期内快速学会数据分析指南(文末送书)
前言 三年耕耘大厂数据分析师,有些工具是必须要掌握的,尤其是Python中的数据分析三剑客:Pandas,Numpy和Matplotlib。就以个人经验而已,Pandas是必须要掌握的,它提供了易于使用的数据结构和数据操作工具&am…...

应用程序分类与相关基本概念介绍
0、引言 在从事软件开发的过程中,由于笔者并不是计算机专业的同学,所以时常会对一些概念感到困惑。比如: 前些年很火的前端和后端是什么意思?什么是 GUI?什么是 CLI?计算机的应用程序分为哪些种类&#x…...

springcloude gateway的意义
应用场景 1、南北向流量 需要流量网关和微服务网关配合使用,将内部的微服务能力,以统一的 HTTP 接入点对外提供服务。 流量网管主要是接入流量进行负载均衡,上游的微服务网关地址和数量变化不大,对服务发现要求不高。 微服务网…...

重新定义每天进步一点点
日拱一卒,每天进步一点点~ 这个主题之前写过一次,今天看了《全情投入》又有了新的感触,于是将其记录下来。 关于目标的设定问题 目标不是改变自己的日常行动,而是改变进行活动时的思维! 有些事情,坚持下…...

代码随想录算法训练营第51天 | ● 309.最佳买卖股票时机含冷冻期 ● 714.买卖股票的最佳时机含手续费
文章目录 前言一、309.最佳买卖股票时机含冷冻期二、714.买卖股票的最佳时机含手续费总结 前言 买卖股票 完结; 一、309.最佳买卖股票时机含冷冻期 确定dp数组以及下标的含义 dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]。 其实本题很多…...
李佳琦掉粉,国货品牌却从“商战大剧”走向“情景喜剧”
李佳琦直播间带货怼网友,“哪里贵了,国货很难的”“这么多年工资没涨,有没有认真工作?”本人事后垂泪道歉仍掉粉百万,但是闻风而来的国货品牌却迎来了一场流量盛宴。 从蜂花蹲点“捡”粉丝,上架三款79元洗…...
linux 下 C++ 与三菱PLC 通过MC Qna3E 二进制 协议进行交互
西门子plc 有snap7库 进行交互,并且支持c 而且跨平台。但是三菱系列PLC并没有现成的开源项目,没办法只能自己拼接,我这里实现了MC 协议 Qna3E 帧,并使用二进制进行交互。 #pragma once#include <stdio.h> #include <std…...

Spring基础(2w字---学习总结版)
目录 一、Spirng概括 1、什么是Spring 2、什么是容器 3、什么是IoC 4、模拟实现IoC 4.1、传统的对象创建开发 5、理解IoC容器 6、DI概括 二、创建Spring项目 1、创建spring项目 2、Bean对象 2.1、创建Bean对象 2.2、存储Bean对象(将Bean对象注册到容器…...
07 目标检测-YOLO的基本原理详解
一、YOLO的背景及分类模型 1、YOLO的背景 上图中是手机中的一个app,在任何场景下(工业场景,生活场景等等)都可以试试这个app和这个算法,这个app中间还有一个button,来调节app使用的模型的大小,更大的模型实时性差但精…...
)
每日一题 78子集(模板)
题目 78 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 示例 1: 输入:nums [1,2,3] 输出:[[],[1],[2]…...

OpenCV之形态学操作
形态学操作包含以下操作: 腐蚀 (Erosion)膨胀 (Dilation)开运算 (Opening)闭运算 (Closing)形态梯度 (Morphological Gradient)顶帽 (Top Hat)黑帽(Black Hat) 其中腐蚀和膨胀操作是最基本的操作,其他操作由这两个操作变换而来。 腐蚀 用一个结构元素…...
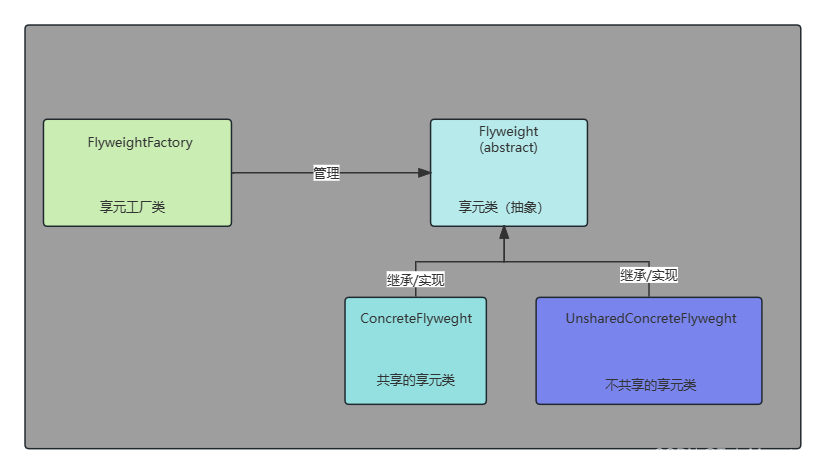
设计模式:享元模式
设计模式:享元模式 什么是享元模式 首先我们需要简单了解一下什么是享元模式。享元模式(Flyweight Pattern):主要用于减少创建对象的数量,以减少内存占用和提高性能。享元模式的重点就在这个享字,通过一些共享技术来减少对象的创建ÿ…...
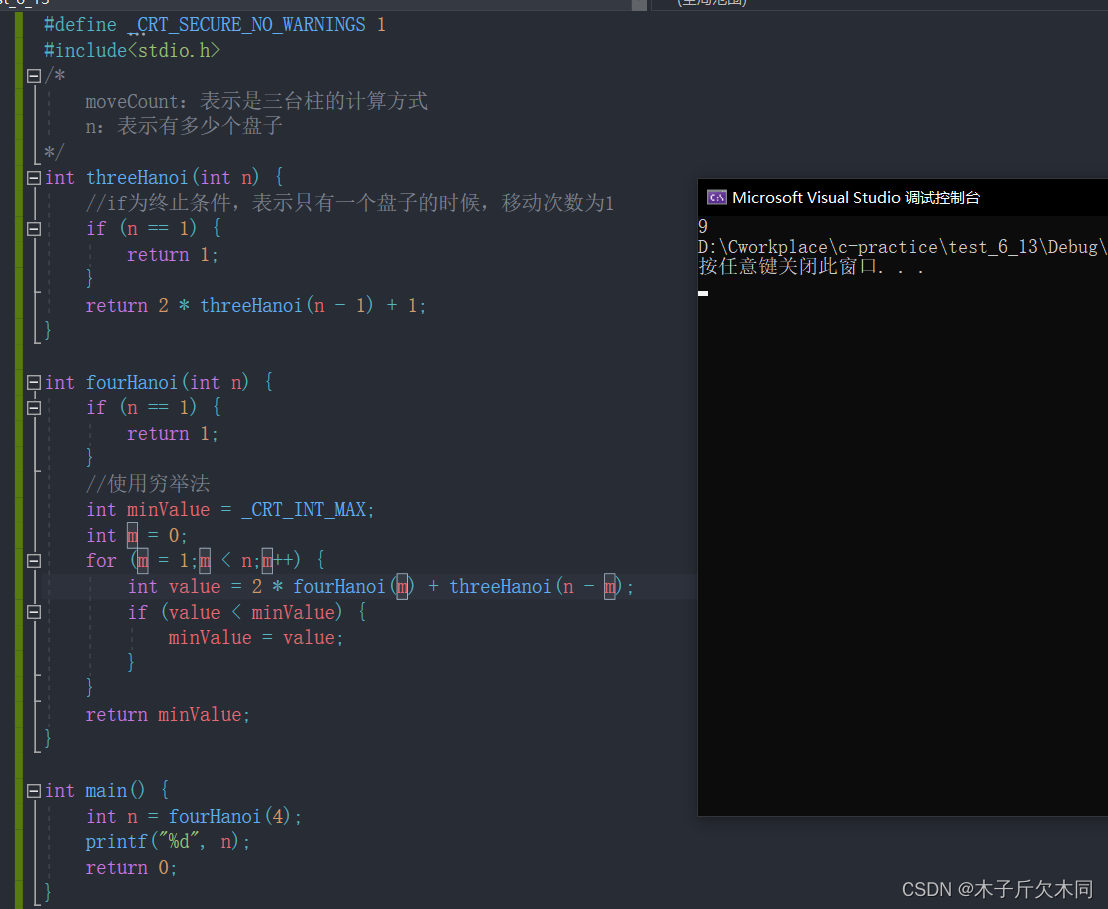
汉诺塔问题(包含了三台柱和四台柱)——C语言版本
目录 1. 什么是汉诺塔 2. 三座台柱的汉诺塔 2.1 思路 2.2 三座台柱的汉诺塔代码 3. 四座台柱的汉诺塔 3.1 思路 3.2 四座台柱的汉诺塔代码 1. 什么是汉诺塔 汉诺塔代码的功能:计算盘子的移动次数,由数学公式知,汉诺塔的盘子移动次数与…...
【实训项目】滴滴电竞APP
1.设计摘要 2013年国家体育总局决定成立一支由17人组成的电子竞技国家队,第四届亚室会中国电竞代表队 出战第四届亚洲室内和武道运动会。 2014年1月13日CCTV5《体育人间》播放英雄联盟皇族战队的纪录片。 在2015到2019年间,我国电竞战队取得的无数值得…...
C++核心编程--类篇
C核心编程 1.内存分区模型 C程序在执行时,将内存大方向分为4个区域 意义:不同区域存放数据,赋予不同的生命周期,更能灵活编程 代码区:存放函数体的二进制代码,由操作系统进行管理的全局区:存放…...

java中用feign远程调用注解FeignClient的时候不重写Encoder和Decoder怎么格式不对呢?
如果在使用 Feign 进行远程调用时,没有重写 Encoder 和 Decoder,但仍然遇到格式不对的问题,可能是由于以下原因之一: 服务端返回的数据格式与客户端期望的格式不匹配:Feign 默认使用基于 Jackson 的 Encoder 和 Decode…...

Android设备指纹采集指南:从get_token协议看短视频SDK如何生成唯一设备ID
Android设备指纹生成机制深度解析:从基础原理到合规实践 在移动应用生态中,设备指纹技术扮演着至关重要的角色。它不仅关系到用户体验的连贯性,更是风控系统的基础支撑。本文将系统性地剖析Android平台下设备指纹的生成逻辑、技术实现方案以及…...

GEC6818嵌入式Linux智能车库系统开发实战
1. 项目概述这个基于GEC6818嵌入式Linux的智能车库系统,是我去年为一个商业停车场改造项目开发的解决方案。当时客户的主要痛点在于传统人工管理效率低下,经常出现收费纠纷和停车位利用率不高的问题。经过三个月的开发和调试,最终实现了这套集…...

springboot+vue基于web的在线试题库考试系统的设计系统
目录同行可拿货,招校园代理 ,本人源头供货商功能模块设计技术实现要点扩展功能建议安全注意事项项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块设计 后端(SpringB…...

嵌入式Linux接入阿里飞燕物联网平台实战指南
1. 嵌入式Linux设备接入飞燕物联网平台全流程解析作为一名在嵌入式领域摸爬滚打多年的工程师,最近刚完成了一个将智能家居设备从旧平台迁移到阿里飞燕物联网平台的项目。这个过程中踩了不少坑,也积累了一些实战经验,今天就来详细分享一下基于…...

SpringAI集成Ollama实战:从零构建本地AI对话服务
1. 环境准备:搭建Ollama本地AI模型服务 想要在本地运行AI对话服务,首先需要部署Ollama这个轻量级的大模型运行环境。Ollama最大的优势在于它能让开发者在普通配置的电脑上就能运行各种开源大模型,而不需要昂贵的GPU服务器。 安装过程非常简单…...

利用HunyuanVideo-Foley为游戏开发赋能:动态环境音效与技能音效生成实践
利用HunyuanVideo-Foley为游戏开发赋能:动态环境音效与技能音效生成实践 1. 游戏音效开发的痛点与机遇 在游戏开发过程中,音效设计往往是最容易被低估却又至关重要的环节之一。传统音效制作需要大量预录制音频素材,一个中型游戏项目动辄需要…...

【Python MCP服务器开发终极模板】:20年架构师亲授源码级解析与高并发优化实战
第一章:Python MCP服务器开发模板概览与核心设计哲学Python MCP(Model-Controller-Protocol)服务器开发模板是一套面向协议驱动、可插拔架构的轻量级服务框架,专为构建高内聚、低耦合的模型交互后端而设计。其核心不依赖于特定Web…...

Qwen3-ForcedAligner-0.6B在字幕制作中的落地应用:SRT自动导出全流程
Qwen3-ForcedAligner-0.6B在字幕制作中的落地应用:SRT自动导出全流程 1. 引言:告别手动打轴,让字幕制作快10倍 如果你做过视频字幕,一定体会过手动打轴的痛苦。一集45分钟的视频,台词稿早就准备好了,但你…...

告别重复造轮子:用快马AI一键生成高复用性imToken集成代码模块
告别重复造轮子:用快马AI一键生成高复用性imToken集成代码模块 开发涉及钱包集成的DApp时,最让人头疼的就是那些重复性的基础代码。每次新项目都要重新写一遍连接钱包、处理授权、监听网络切换的逻辑,不仅浪费时间,还容易引入安全…...

终极窗口尺寸编辑器:SRWE让你的应用程序窗口自由伸缩
终极窗口尺寸编辑器:SRWE让你的应用程序窗口自由伸缩 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE Simple Runtime Window Editor (SRWE) 是一款革命性的开源工具,它能让你实时调整任何…...