Pytorch intermediate(四) Language Model (RNN-LM)
前一篇中介绍了一种双向的递归神经网络,将数据进行正序输入和倒序输入,兼顾向前的语义以及向后的语义,从而达到更好的分类效果。
之前的两篇使用递归神经网络做的是分类,可以发现做分类时我们不需要使用时序输入过程中产生的输出,只需关注每个时序输入产生隐藏信息,最后一个时序产生的输出即最后的输出。
这里将会介绍语言模型,这个模型中我们需要重点关注的是每个时序输入过程中产生的输出。可以理解为,我输入a,那么我需要知道这个时序的输出是不是b,如果不是那么我就要调整模型了。
import torch
import torch.nn as nn
import numpy as np
from torch.nn.utils import clip_grad_norm_
from data_utils import Dictionary, Corpusdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')embed_size = 128
hidden_size = 1024
num_layers = 1
num_epochs = 5
num_samples = 1000
batch_size = 20
seq_length = 30
learning_rate = 0.002 corpus = Corpus()
ids = corpus.get_data('data/train.txt', batch_size)
vocab_size = len(corpus.dictionary)
num_batches = ids.size(1) // seq_lengthprint(ids.size())
print(vocab_size)
print(num_batches)#torch.Size([20, 46479])
#10000
#1549参数解释
1、ids:从train.txt中获取的训练数据,总共为20条,下面的模型只对这20条数据进行训练。
2、vocab_size:词库,总共包含有10000个单词
3、num_batch:可能有人要问前面有batch_size,这里的num_batch是干嘛用的?前面的batch_size是从语料库中抽取20条,每条数据长度为46497,除以序列长度seq_length(输入时序为30),个num_batch可以理解为是输入时序块的个数,也就是一个epoch中我们将所有语料输入网络需要循环的次数。
模型构建
模型很简单,但是参数比较难理解,这里在讲流程的时候依旧对参数进行解释。
1、Embedding层:保存了固定字典和大小的简单查找表,第一个参数是嵌入字典的大小,第二个是每个嵌入向量的大小。也就是说,每个时间序列的特征都被转化成128维的向量。假设一个序列维[20, 30],经过嵌入会变成[20, 30, 128]
2、LSTM层:3个重要参数,输入维度即为嵌入向量大小embed_size = 128,隐藏层神经元个数hidden_size = 1024,lstm单元个数num_layers = 1
3、LSTM的输出结果out中包含了30个时间序列的所有隐藏层输出,这里不仅仅只用最后一层了,要用到所有层的输出。
4、线性激活层:LSTM的隐藏层有1024个特征,要把这1024个特征通过全连接组合成我们词库特征10000,得到的就是这10000个词被选中的概率了。
class RNNLM(nn.Module):def __init__(self,vocab_size,embed_size,hidden_size,num_layers):super(RNNLM,self).__init__()#parameters - 1、嵌入字典的大小 2、每个嵌入向量的大小self.embed = nn.Embedding(vocab_size,embed_size)self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first = True)self.linear = nn.Linear(hidden_size, vocab_size)def forward(self, x, h):#转化为词向量x = self.embed(x) #x.shape = torch.Size([20, 30, 128])#分成30个时序,在训练的过程中的循环中体现out,(h,c) = self.lstm(x,h) #out.shape = torch.Size([20, 30, 1024])#out中保存每个时序的输出,这里不仅仅要用最后一个时序,要用上一层的输出和下一层的输入做对比,计算损失out = out.reshape(out.size(0) * out.size(1), out.size(2)) #输出10000是因为字典中存在10000个单词out = self.linear(out) #out.shape = torch.Size([600, 10000])return out,(h,c)实例化模型
向前传播时,我们需要输入两个参数,分别是数据x,h0和c0。每个epoch都要将h0和c0重新初始化。
可以看到在训练之前对输入数据做了一些处理。每次取出长度为30的序列输入,相应的依次向后取一位做为target,这是因为我们的目标就是让每个序列输出的值和下一个字符项相近似。
输出的维度为(600, 10000),将target维度进行转化,计算交叉熵时会自动独热处理。
反向传播过程,防止梯度爆炸,进行了梯度修剪。
model = RNNLM(vocab_size, embed_size, hidden_size, num_layers).to(device)criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)def detach(states):return [state.detach() for state in states] for epoch in range(num_epochs):# Set initial hidden and cell statesstates = (torch.zeros(num_layers, batch_size, hidden_size).to(device),torch.zeros(num_layers, batch_size, hidden_size).to(device))for i in range(0, ids.size(1) - seq_length, seq_length):# Get mini-batch inputs and targetsinputs = ids[:, i:i+seq_length].to(device) #input torch.Size([20, 30])targets = ids[:, (i+1):(i+1)+seq_length].to(device) #target torch.Size([20, 30])# Forward passstates = detach(states)#用前一层输出和下一层输入计算损失outputs, states = model(inputs, states) #output torch.Size([600, 10000])loss = criterion(outputs, targets.reshape(-1))# Backward and optimizemodel.zero_grad()loss.backward()clip_grad_norm_(model.parameters(), 0.5) #梯度修剪optimizer.step()step = (i+1) // seq_lengthif step % 100 == 0:print ('Epoch [{}/{}], Step[{}/{}], Loss: {:.4f}, Perplexity: {:5.2f}'.format(epoch+1, num_epochs, step, num_batches, loss.item(), np.exp(loss.item())))测试模型
测试时随机选择一个词作为输入,因为没有一个停止的标准,所以我们需要利用循环来控制到底输出多少个字符。
输入维度[1, 1],我们之前的输入是[20, 30]。
本来有一种想法:我们现在只有一个时序了,但是我们的训练时有30个时序,那么还有什么意义?忽然想起来我们训练的参数是公用的!!!所以只要输入一个数据就能预测下面的数据了,并不要所谓的30层。
这里的初始输入是1,那么能不能是2呢?或者是根据我们之前的输入取预测新的字符?其实是可以的,但是由于初始化h0和c0的问题,我们更改了输入的长度,相应的h0和c0也要改变的。
我们最后的输出结果需要转化成为概率,然后随机抽取
# Test the model
with torch.no_grad():with open('sample.txt', 'w') as f:# Set intial hidden ane cell statesstate = (torch.zeros(num_layers, 1, hidden_size).to(device),torch.zeros(num_layers, 1, hidden_size).to(device))# Select one word id randomlyprob = torch.ones(vocab_size)input = torch.multinomial(prob, num_samples=1).unsqueeze(1).to(device)for i in range(num_samples):# Forward propagate RNN output, state = model(input, state) #output.shape = torch.Size([1, 10000])# Sample a word idprob = output.exp()word_id = torch.multinomial(prob, num_samples=1).item() #根据输出的概率随机采样# Fill input with sampled word id for the next time stepinput.fill_(word_id)# File writeword = corpus.dictionary.idx2word[word_id]word = '\n' if word == '<eos>' else word + ' 'f.write(word)if (i+1) % 100 == 0:print('Sampled [{}/{}] words and save to {}'.format(i+1, num_samples, 'sample.txt'))相关文章:
 Language Model (RNN-LM))
Pytorch intermediate(四) Language Model (RNN-LM)
前一篇中介绍了一种双向的递归神经网络,将数据进行正序输入和倒序输入,兼顾向前的语义以及向后的语义,从而达到更好的分类效果。 之前的两篇使用递归神经网络做的是分类,可以发现做分类时我们不需要使用时序输入过程中产生的输出&…...
C++零碎记录(十)
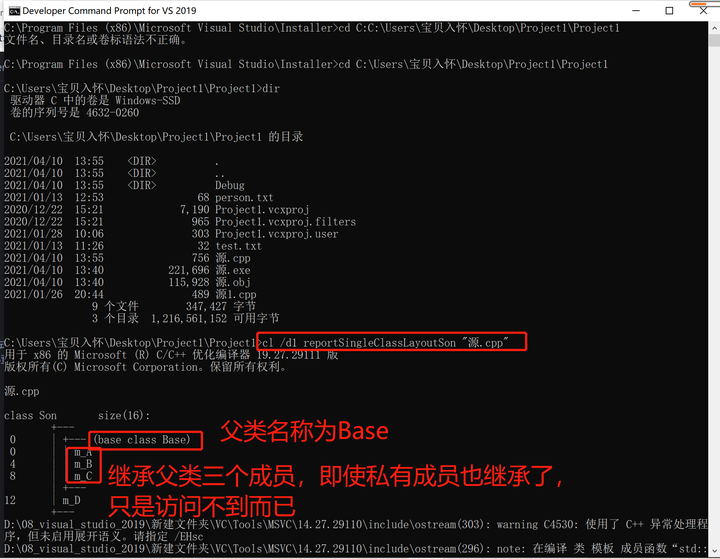
17. 继承对象内存 17.1 查询继承对象所占内存 #include <iostream> using namespace std; #include<string>//继承中的对象模型class Base { public:int m_A; protected:int m_B; private:int m_C; };//公共继承 class Son:public Base {int m_D; };//利用开发人…...

人类学习 vs. 机器学习
摘要: 机器学习与人类学习的范式有一定的联系. 本文发掘这些联系, 作用是指导人类的学习. 1. 什么是学习? 对于人类而言, 学习是改造大脑皮层的过程. 我们会发现, 不同人学习不同东西的能力也不一样, 如有些人数学厉害, 有些人音乐厉害. 同时, 也有些牛人, 学习到了学习的方…...
【LeetCode-中等题】15. 三数之和
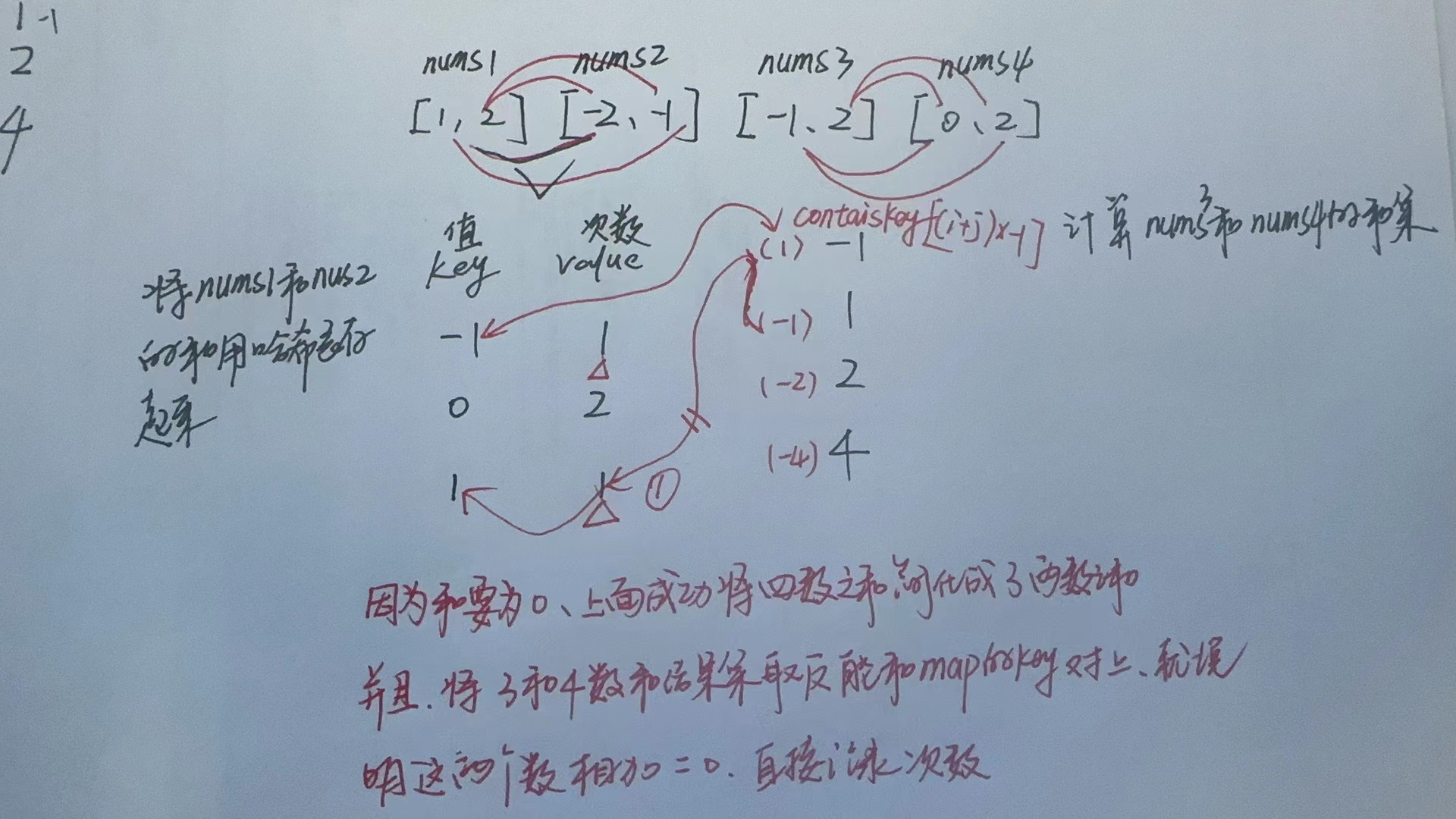
文章目录 题目方法一:哈希表 题目 方法一:哈希表 将四数之和 借助哈希表简化成两数之和 class Solution {public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {int res 0; //结果集数量Map<Integer,Integer> map n…...
Apache Tomcat漏洞复现
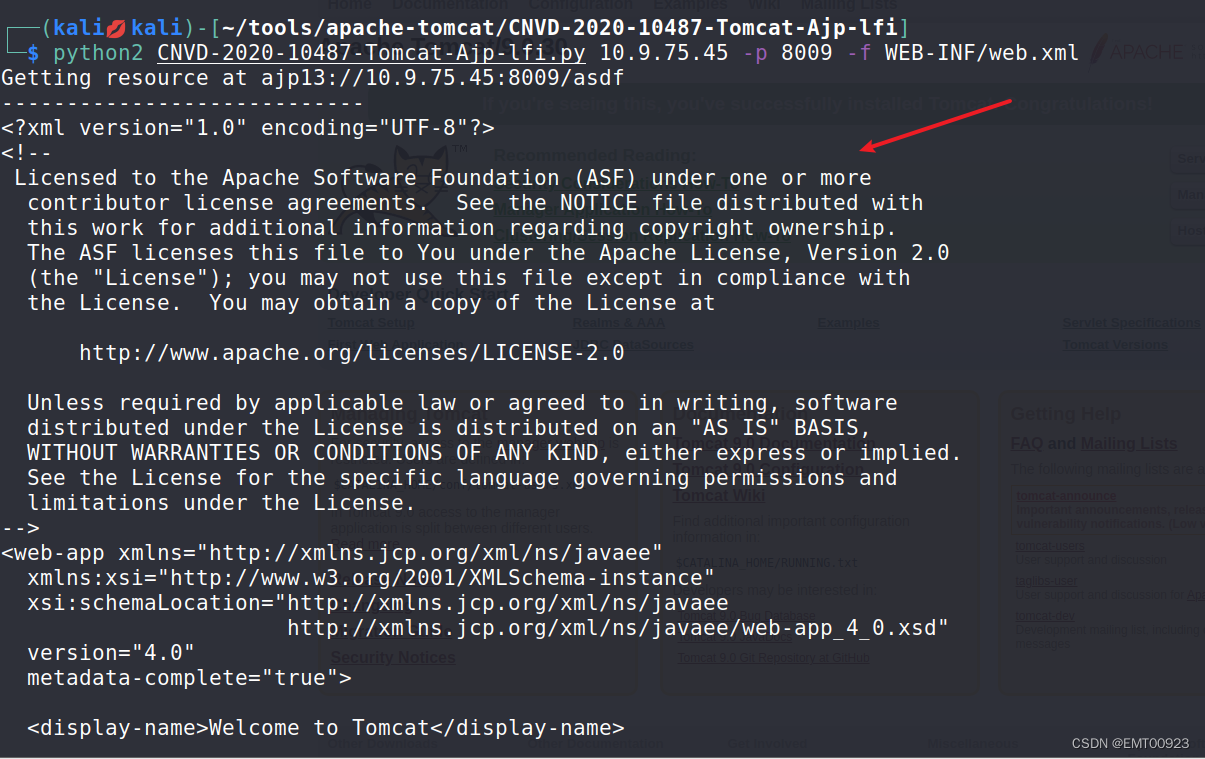
文章目录 弱口令启动环境漏洞复现 本地文件包含启动环境漏洞复现 弱口令 启动环境 来到vulhub/tomcat/tomcat8/靶场 cd vulhub/tomcat/tomcat8/安装环境并启动: sudo docker-compose up -d && sudo docker-compose up -d修改端口后启动: su…...
C++模版基础
代码地址 gitgithub.com:CHENLitterWhite/CPPWheel.git 专栏介绍 本专栏会持续更新关于STL中的一些概念,会先带大家补充一些基本的概念,再慢慢去阅读STL源码中的需要用到的一些思想,有了一些基础之后,再手写一些STL代码。 (如果你…...

解决 Elasticsearch 分页查询记录超过10000时异常
查询结果中 hits.total.value 值最大为10000的限制 解决方法: 1、请求设置rest_total_hits_as_inttrue 注意参数需要放在请求头上 builder.addHeader("rest_total_hits_as_int","true"); 2、修改setting的值 #设置返回最大记录条数为1000000 PUT /in…...
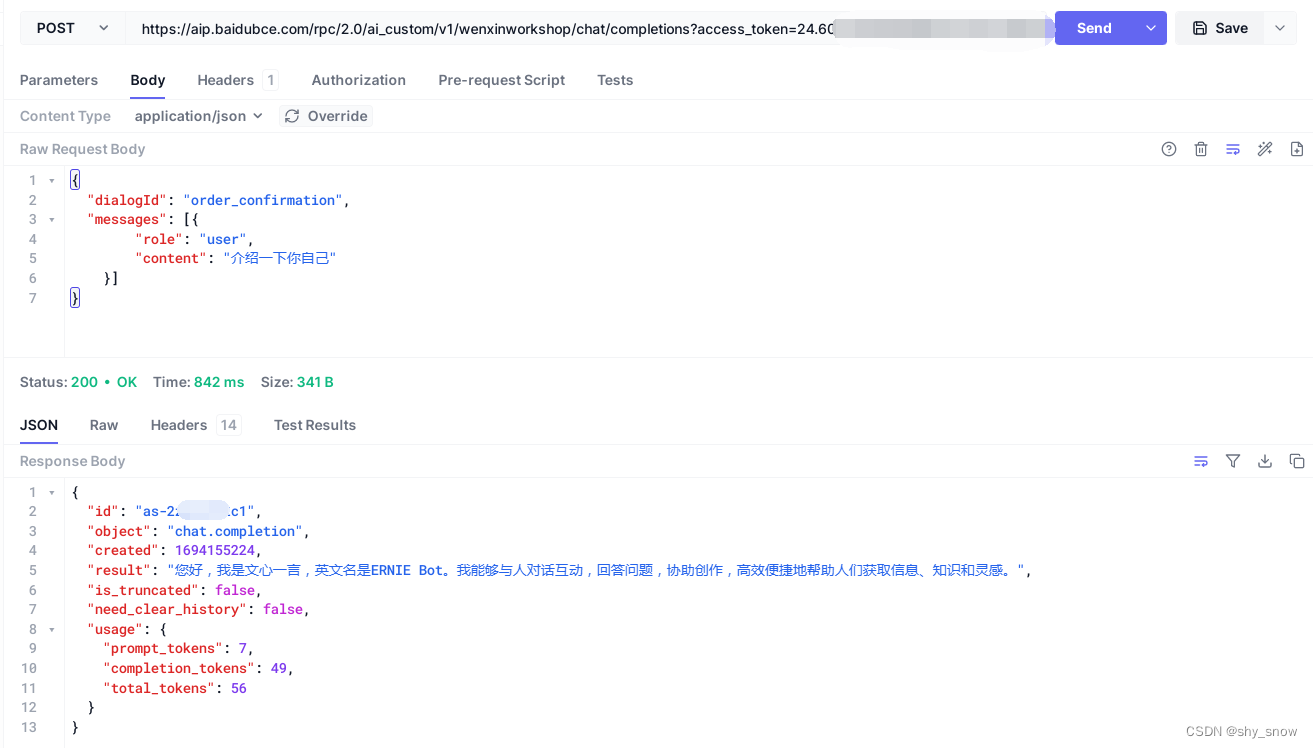
百度千帆大模型文心一言api调用
注册百度智能云账号并申请文心千帆大模型资格 https://login.bce.baidu.com/ https://cloud.baidu.com/product/wenxinworkshop 创建应用用于获取access_token 创建应用成功后,可以获取到API Key和Secret Key 获取access_token curl https://aip.baidubce.com/oauth/2.0/to…...
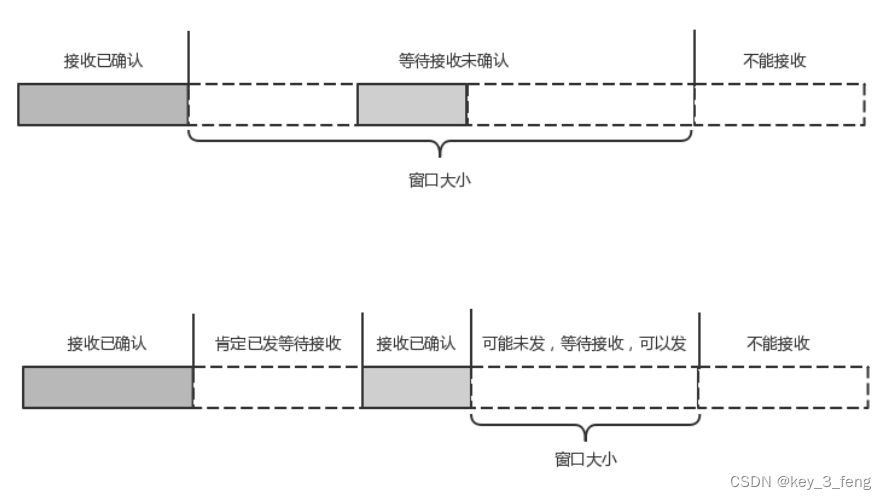
关于HTTP协议的概述
HTTP 的报文大概分为三大部分。第一部分是请求行,第二部分是请求的首部,第三部分才是请求的正文实体。 POST 往往是用来创建一个资源的,而 PUT 往往是用来修改一个资源的。 Accept-Charset,表示客户端可以接受的字符集。防止传过…...

ATFX汇市:8月名义与核心CPI走势分化,美国通胀率算升高还是降低?
ATFX汇市:据美国劳工部昨日公布的数据,8月份,美国名义CPI增速最新值3.7%,高于前值3.2%,高于预期值3.6%,显示高通胀问题有抬头迹象。同一时间公布的8月核心CPI年率最新值4.3%,低于前值4.7%&#…...

c++ 中的函数指针
以下图片演示了c中函数指针的用法。如下图可见,把函数地址赋值给函数指针,用函数名或者函数名的地址,都可以,c编译器不报错。即 ptr f 和 ptr &f 都对。但准确的话,函数名就是地址,在编译时候&#x…...

奶牛个体识别 奶牛身份识别
融合YOLOv5s与通道剪枝算法的奶牛轻量化个体识别方法 Light-weight recognition network for dairy cows based on the fusion of YOLOv5s and channel pruning algorithm 论文链接 知网链接 DOI链接 该文章讨论了奶牛花斑、光照条件、不同剪枝方法、不同剪枝率对准确率的影响…...
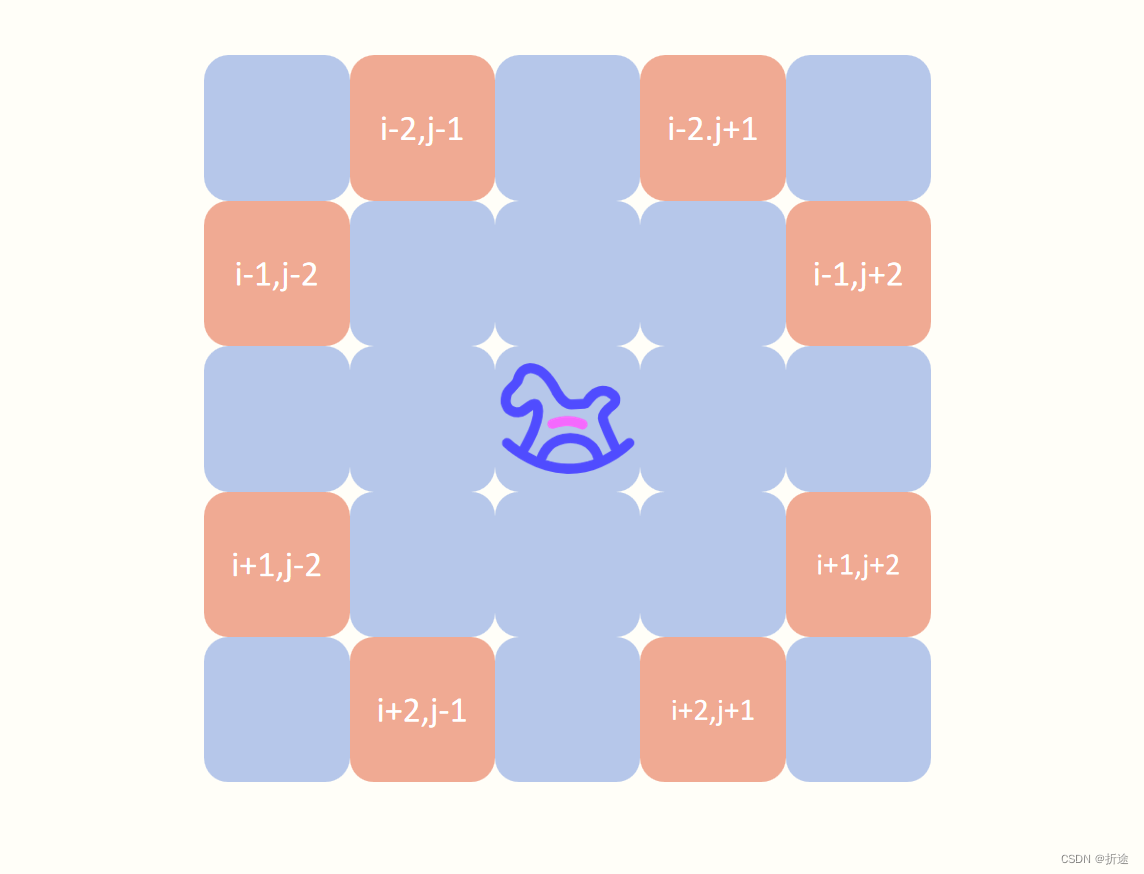
【力扣每日一题】2023.9.13 检查骑士巡视方案
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 题目给我们一个n*n大小的矩阵,矩阵的元素表示骑士已经行动的次数,问我们骑士能不能按照矩阵里元素顺序来巡视整个…...

【Vue】关于CSS样式绑定整理
因突发奇想设计一款组件,需要根据属性动态绑定样式,故而整理一些Vue的动态绑定样式方法(传参绑定类似,不做过多叙述),仅供参考.方式一: 直接在元素上绑定具体样式方式二: 定义属性对象,绑定到style,可以在style中使用定义的变量方式二: 通过引入自定义组件引入style数据,直接绑…...

Sql语句大全--更新
今天抽空整理下项目中的Sql语句 项目中用到的Sql语句大全 Update 语句 Update 语句 Update语句update OLASF1.LLB set CBBTHCC 52 WHERE CBPOLNUMC201728534update OLASF1.LLB set CBBTHCC 01 WHERE CBPOLNUMC201728534update OLASF1.LB set CBBTHCC 01 WHERE CBPOLNUMC…...

Java面试八股文宝典:序言
序言: Java作为一门广泛应用于企业级应用开发的编程语言,一直以来都是技术面试中的重要话题。无论您是刚刚踏入编程世界的新手,还是经验丰富的Java开发工程师,都需要通过面试来展示自己的技能和知识。 在面试中,除了…...

【多线程案例】单例模式
单例模式是设计模式的一种,先谈谈什么是设计模式? 大家应该都知道棋谱、剑谱之类的,就是一些“高手”在经历过长期的累计之后,更具经验写出的具有固定套路的处理“方法”,只要按照这个套路来,在对局之中必然…...

阿里云部署SpringBoot项目启动后被杀进程的问题
阿里云部署SpringBoot项目启动后被杀进程的问题 最近部署在公司虚拟主机上的SpringBoot项目频繁被杀,这个虚拟主机是个杂货铺,部署着各种项目,时间跨度还大,不同的人负责,个人自扫门前雪,不管他人瓦上霜&a…...

git仓库推送错误
错误背景 从github克隆仓库后,想推送到gitee,在推送时遇到 error: src refspec master does not match any. error: failed to push some refs to <REMOTE_URL>解决方法 rm -rf .github git init git add -A git commit -m "init for gite…...
(三))
计网第五章(运输层)(三)
一、UDP协议和TCP协议的对比 1、UDP无连接,TCP面向连接 使用UDP协议的通信双方可以随时发送数据,使用TCP协议的通信双方必须先进行3次握手建立连接,才能发送数据,最后还要进行4次挥手才能释放连接。 2、UDP支持单播、多播以及广…...

不只是连线:用立创EDA做PCB布局时,这5个提升电路板可靠性的细节你注意了吗?
不只是连线:用立创EDA做PCB布局时,这5个提升电路板可靠性的细节你注意了吗? 在电子设计领域,PCB布局的质量往往决定了产品的最终表现。许多工程师能够完成基本的电路连接,却容易忽视那些看似微小却至关重要的设计细节。…...

AnuPpuccin主题:面向Obsidian用户的可定制化视觉框架
AnuPpuccin主题:面向Obsidian用户的可定制化视觉框架 【免费下载链接】AnuPpuccin Personal theme for Obsidian 项目地址: https://gitcode.com/gh_mirrors/an/AnuPpuccin Obsidian作为一款功能强大的知识管理工具,其原生界面在视觉体验方面存在…...

Doccano自动标注功能深度评测:对比Brat、Prodigy,它真的适合你的团队吗?
Doccano自动标注功能深度评测:对比Brat、Prodigy,它真的适合你的团队吗? 在自然语言处理项目中,数据标注的质量和效率直接影响模型效果。面对市面上从开源到商业的各类标注工具,技术决策者常陷入选择困境——是追求Bra…...

基于WebGPU的浏览器端大模型本地部署:ChatLLM-Web项目实战解析
1. 项目概述:在浏览器里跑大模型,到底有多酷?如果你和我一样,对ChatGPT这类大语言模型(LLM)既着迷又有点“隐私焦虑”——总担心自己的对话数据在云端服务器上“裸奔”,那今天聊的这个项目绝对会…...

【信息科学与工程学】计算机科学与自动化——第一百五十一篇 云计算操作系统函数说明02
威胁情报与狩猎模块(361-370) 编号 模块/组件类型 模块中的函数名称和函数的参数列表和函数的实现方式 函数的详细功能和计算机科学的所有性能【含参数列表】和功能说明 关联的其他函数【含上下文关系】 和对应模块【含上下文关系】 关联的软件/硬件核心知识点【需要涵…...

NCE外汇:平台稳定性与用户体验的全面观察
金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。NCE外汇经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行多维度的解读,呈现一个具有结构感的平台画像…...

Windows窗口置顶终极指南:PinWin让你的多任务处理效率翻倍
Windows窗口置顶终极指南:PinWin让你的多任务处理效率翻倍 【免费下载链接】PinWin Pin any window to be always on top of the screen 项目地址: https://gitcode.com/gh_mirrors/pin/PinWin 你是否曾因频繁切换窗口而打断工作流程?是否需要在多…...

LinkedIn Liger Kernel:移动设备内核定制与性能优化实战
1. 项目概述:一个面向移动设备的开源内核探索如果你在移动设备开发、嵌入式系统或者内核研究的圈子里待过一段时间,大概率听说过或者接触过“Liger Kernel”这个名字。它不是一个商业产品,而是一个在GitHub上由LinkedIn开源并维护的Android内…...

Axure RP中文界面完整汉化指南:3分钟免费安装全系列版本
Axure RP中文界面完整汉化指南:3分钟免费安装全系列版本 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 对于中文用户…...

C# —— 结构体、类型转换与运算符
一、结构体(struct)与常量(const)结构体用于打包多个相关变量,常量用于定义不可修改的值,是规范数据的常用方式。1. 结构体(struct)作用:把多个变量打包成一个整体&#…...