微博情绪分类
引自:https://blog.csdn.net/no1xiaoqianqian/article/details/130593783
友好借鉴,总体抄袭。
所需要的文件如下:https://download.csdn.net/download/m0_37567738/88340795
import os
import torch
import torch.nn as nn
import numpy as npclass TextRNN(nn.Module):def __init__(self, Config):super(TextRNN, self).__init__()self.hidden_size = 128 # lstm隐藏层self.num_layers = 2 # lstm层数self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)self.lstm = nn.LSTM(Config.embed_dim, self.hidden_size, self.num_layers,bidirectional=True, batch_first=True, dropout=Config.dropout)self.fc = nn.Linear(self.hidden_size * 2, Config.num_classes)def forward(self, x):out = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]out, _ = self.lstm(out)out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden statereturn outimport torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import copyclass Transformer(nn.Module):def __init__(self, Config):super(Transformer, self).__init__()self.hidden = 1024self.last_hidden = 512self.num_head = 5self.num_encoder = 2self.dim_model = 300self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)self.postion_embedding = Positional_Encoding(Config.embed_dim, Config.all_seq_len, Config.dropout, Config.device)self.encoder = Encoder(self.dim_model, self.num_head, self.hidden, Config.dropout)self.encoders = nn.ModuleList([copy.deepcopy(self.encoder)# Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)for _ in range(self.num_encoder)])self.fc1 = nn.Linear(Config.all_seq_len * self.dim_model, Config.num_classes)# self.fc2 = nn.Linear(config.last_hidden, config.num_classes)# self.fc1 = nn.Linear(config.dim_model, config.num_classes)def forward(self, x):out = self.embedding(x)out = self.postion_embedding(out)for encoder in self.encoders:out = encoder(out)out = out.view(out.size(0), -1)# out = torch.mean(out, 1)out = self.fc1(out)return outclass Encoder(nn.Module):def __init__(self, dim_model, num_head, hidden, dropout):super(Encoder, self).__init__()self.attention = Multi_Head_Attention(dim_model, num_head, dropout)self.feed_forward = Position_wise_Feed_Forward(dim_model, hidden, dropout)def forward(self, x):out = self.attention(x)out = self.feed_forward(out)return outclass Positional_Encoding(nn.Module):def __init__(self, embed, pad_size, dropout, device):super(Positional_Encoding, self).__init__()self.device = deviceself.pe = torch.tensor([[pos / (10000.0 ** (i // 2 * 2.0 / embed)) for i in range(embed)] for pos in range(pad_size)])self.pe[:, 0::2] = np.sin(self.pe[:, 0::2])self.pe[:, 1::2] = np.cos(self.pe[:, 1::2])self.dropout = nn.Dropout(dropout)def forward(self, x):out = x + nn.Parameter(self.pe, requires_grad=False).to(self.device)out = self.dropout(out)return outclass Scaled_Dot_Product_Attention(nn.Module):'''Scaled Dot-Product Attention '''def __init__(self):super(Scaled_Dot_Product_Attention, self).__init__()def forward(self, Q, K, V, scale=None):'''Args:Q: [batch_size, len_Q, dim_Q]K: [batch_size, len_K, dim_K]V: [batch_size, len_V, dim_V]scale: 缩放因子 论文为根号dim_KReturn:self-attention后的张量,以及attention张量'''attention = torch.matmul(Q, K.permute(0, 2, 1))if scale:attention = attention * scale# if mask: # TODO change this# attention = attention.masked_fill_(mask == 0, -1e9)attention = F.softmax(attention, dim=-1)context = torch.matmul(attention, V)return contextclass Multi_Head_Attention(nn.Module):def __init__(self, dim_model, num_head, dropout=0.0):super(Multi_Head_Attention, self).__init__()self.num_head = num_headassert dim_model % num_head == 0self.dim_head = dim_model // self.num_headself.fc_Q = nn.Linear(dim_model, num_head * self.dim_head)self.fc_K = nn.Linear(dim_model, num_head * self.dim_head)self.fc_V = nn.Linear(dim_model, num_head * self.dim_head)self.attention = Scaled_Dot_Product_Attention()self.fc = nn.Linear(num_head * self.dim_head, dim_model)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(dim_model)def forward(self, x):batch_size = x.size(0)Q = self.fc_Q(x)K = self.fc_K(x)V = self.fc_V(x)Q = Q.view(batch_size * self.num_head, -1, self.dim_head)K = K.view(batch_size * self.num_head, -1, self.dim_head)V = V.view(batch_size * self.num_head, -1, self.dim_head)# if mask: # TODO# mask = mask.repeat(self.num_head, 1, 1) # TODO change thisscale = K.size(-1) ** -0.5 # 缩放因子context = self.attention(Q, K, V, scale)context = context.view(batch_size, -1, self.dim_head * self.num_head)out = self.fc(context)out = self.dropout(out)out = out + x # 残差连接out = self.layer_norm(out)return outclass Position_wise_Feed_Forward(nn.Module):def __init__(self, dim_model, hidden, dropout=0.0):super(Position_wise_Feed_Forward, self).__init__()self.fc1 = nn.Linear(dim_model, hidden)self.fc2 = nn.Linear(hidden, dim_model)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(dim_model)def forward(self, x):out = self.fc1(x)out = F.relu(out)out = self.fc2(out)out = self.dropout(out)out = out + x # 残差连接out = self.layer_norm(out)return outimport torch.nn as nn
import torch
import torch.nn.functional as Fclass TextCNN(nn.Module):def __init__(self, Config):super(TextCNN, self).__init__()self.filter_sizes = (2, 3, 4) # 卷积核尺寸self.num_filters = 64 # 卷积核数量(channels数)self.embedding = nn.Embedding(Config.n_vocab, Config.embed_dim)self.convs = nn.ModuleList([nn.Conv2d(1, self.num_filters, (k, Config.embed_dim)) for k in self.filter_sizes])self.dropout = nn.Dropout(Config.dropout)self.fc = nn.Linear(self.num_filters * len(self.filter_sizes), Config.num_classes)def conv_and_pool(self, x, conv):x = F.relu(conv(x))x = x.squeeze(3)x = F.max_pool1d(x, x.size(2)).squeeze(2)return xdef forward(self, x):out = self.embedding(x)out = out.unsqueeze(1)out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)out = self.dropout(out)out = self.fc(out)return outimport matplotlib.pyplot as plt
import numpy as npdef draw_loss_pic(train_loss, test_loss, y):x = np.linspace(0, len(train_loss), len(train_loss))plt.plot(x, train_loss, label="train_" + y, linewidth=1.5)plt.plot(x, test_loss, label="test_" + y, linewidth=1.5)plt.xlabel("epoch")plt.ylabel(y)plt.legend()plt.show()import torchclass Config():train_data_path = '../data/virus_train.txt'test_data_path = '../data/virus_eval_labeled.txt'vocab_path = '../data/vocab.pkl'split_word_all_path = '../data/split_word_all.txt'model_file_name_path = '../data/vec_model.txt'id_vec_path = '../data/id_vec.pkl'device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')word_level = True # 按照字级别进行分词embedding_pretrained = False # 是否使用预训练的词向量label_fields = {'neural': 0, 'happy': 1, 'angry': 2, 'sad': 3, 'fear': 4, 'surprise': 5}all_seq_len = 64 # 句子长度,长剪短补batch_size = 128learning_rate = 0.0001epoches = 50dropout = 0.5num_classes = 6embed_dim = 300n_vocab = 0import re
import os
import json
#import jieba
import pickle as pkl
import numpy as np
import gensim.models.word2vec as w2v
import torch
#from src.Config import Config
import torch.utils.data as Datatrain_data_path = Config.train_data_path
test_data_path = Config.test_data_path
vocab_path = Config.vocab_pathlabel_fields = Config.label_fields
all_seq_len = Config.all_seq_lenUNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号def build_vocab(content_list, tokenizer):file_split_word = open(Config.split_word_all_path, 'w', encoding='utf-8')vocab_dic = {}for content in content_list:word_lines = []for word in tokenizer(content):vocab_dic[word] = vocab_dic.get(word, 0) + 1word_lines.append(word)str = " ".join(word_lines) + "\n"file_split_word.write(str)file_split_word.close()vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})vocab_dic = {word_count: idx for idx, word_count in enumerate(vocab_dic)}return vocab_dicdef build_id_vec(vocab_dic, model):model.wv.add_vector(UNK, np.zeros(300))model.wv.add_vector(PAD, np.ones(300))id2vec = {}for word in vocab_dic.keys():id = vocab_dic.get(word, vocab_dic.get(UNK))vec = model.wv.get_vector(word)id2vec.update({id: vec})return id2vecdef train_vec():model_file_name = Config.model_file_name_pathsentences = w2v.LineSentence(Config.split_word_all_path)model = w2v.Word2Vec(sentences, vector_size=300, window=20, min_count=0)model.save(model_file_name)def load_data(root):content_list = []content_token_list = []label_list = []if Config.word_level:tokenizer = lambda x: [y for y in x]else:tokenizer = lambda x: jieba.cut(x, cut_all=False)file = open(root, 'r', encoding='utf-8')datas = json.load(file)# pattern = re.compile(r'[^\u4e00-\u9fa5|,|。|!|?|\[|\]]')pattern = re.compile(r'[^\u4e00-\u9fa5|,|。|!|?]')# pattern = re.compile(r'[^\u4e00-\u9fa5|,|。]') # seq_len=32 CNN:67%-68% RNN:61%-62% Transformer:63-64%# pattern = re.compile(r'[^\u4e00-\u9fa5|,|。|!]') # CNN:65%-66%for data in datas:content_after_clean = re.sub(pattern, '', data['content'])content_list.append(content_after_clean)label_list.append(label_fields[data['label']])if os.path.exists(vocab_path):vocab = pkl.load(open(vocab_path, 'rb'))else:vocab = build_vocab(content_list, tokenizer)pkl.dump(vocab, open(vocab_path, 'wb'))if Config.embedding_pretrained:train_vec()model = w2v.Word2Vec.load(Config.model_file_name_path)id_vec = build_id_vec(vocab, model)pkl.dump(id_vec, open(Config.id_vec_path, 'wb'))for content in content_list:word_line = []token = list(tokenizer(content))seq_len = len(token)if seq_len < all_seq_len:token.extend([PAD] * (all_seq_len - seq_len))else:token = token[:all_seq_len]for word in token:word_line.append(vocab.get(word, vocab.get(UNK)))content_token_list.append(word_line)n_vocab = len(vocab)return content_token_list, label_list, n_vocabclass WeiBboDataset(Data.Dataset):def __init__(self, content_token_list, label_list):super(WeiBboDataset, self).__init__()self.content_token_list = content_token_listself.label_list = label_listdef __getitem__(self, index):label = float(self.label_list[index])return torch.tensor(self.content_token_list[index]), torch.tensor(label)def __len__(self):return len(self.label_list)def get_data(batch_size):train_content_token_list, train_label_list, n_vocab = load_data(train_data_path)test_content_token_list, test_label_list, _ = load_data(test_data_path)train_dataset = WeiBboDataset(train_content_token_list, train_label_list)test_dataset = WeiBboDataset(test_content_token_list, test_label_list)train_dataloader = Data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)test_dataloader = Data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)return train_dataloader, test_dataloader, n_vocabif __name__ == '__main__':get_data(32)import os
import torch
import torch.nn as nn
from torch.autograd import Variable
#from utils.draw_loss_pic import draw_loss_picos.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"def train(net, loss, optimizer, train_loader, test_loader, epoches, device):train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epoches):net.train()total_loss = 0.0correct = 0sample_num = 0for batch_idx, (data, target) in enumerate(train_loader):data = data.to(device).long()target = target.to(device).long()optimizer.zero_grad()output = net(data)ls = loss(output, target)ls.backward()optimizer.step()total_loss += ls.item()sample_num += len(target)max_output = output.data.max(1, keepdim=True)[1].view_as(target)correct += (max_output == target).sum()print('epoch %d, train_loss %f, train_acc: %f' % (epoch + 1, total_loss/sample_num, float(correct.data.item()) / sample_num))train_loss.append(total_loss/sample_num)train_acc.append(float(correct.data.item()) / sample_num)test_ls, test_accury = test(net, test_loader, device, loss)test_loss.append(test_ls)test_acc.append(test_accury)draw_loss_pic(train_loss, test_loss, "loss")draw_loss_pic(train_acc, test_acc, "acc")def test(net, test_loader, device, loss):net.eval()total_loss = 0.0correct = 0sample_num = 0for batch_idx, (data, target) in enumerate(test_loader):data = data.to(device)target = target.to(device).long()output = net(data)ls = loss(output, target)total_loss += ls.item()sample_num += len(target)max_output = output.data.max(1, keepdim=True)[1].view_as(target)correct += (max_output == target).sum()print('test_loss %f, test_acc: %f' % (total_loss / sample_num, float(correct.data.item()) / sample_num))return total_loss / sample_num, float(correct.data.item()) / sample_numimport torch
import torch.nn as nn
import torch.optim as optim
import pickle as pkl
#from src.models.textCNN import TextCNN
#from src.models.textRNN import TextRNN
#from src.models.Transformer import Transformer
#from src.Config import Config
#from src.get_data import get_data
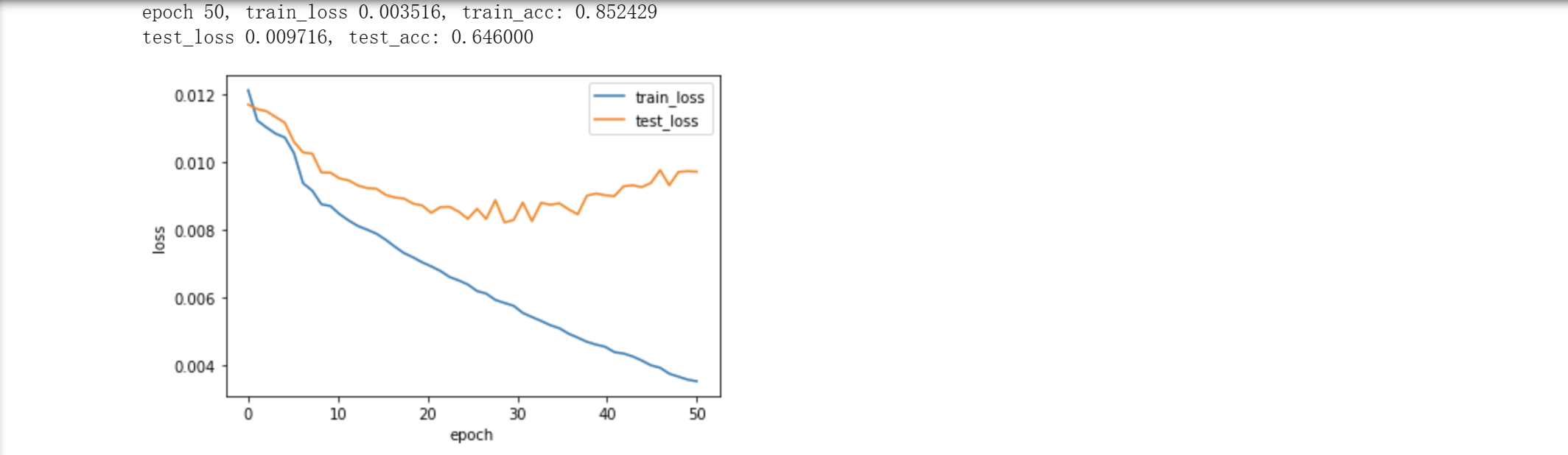
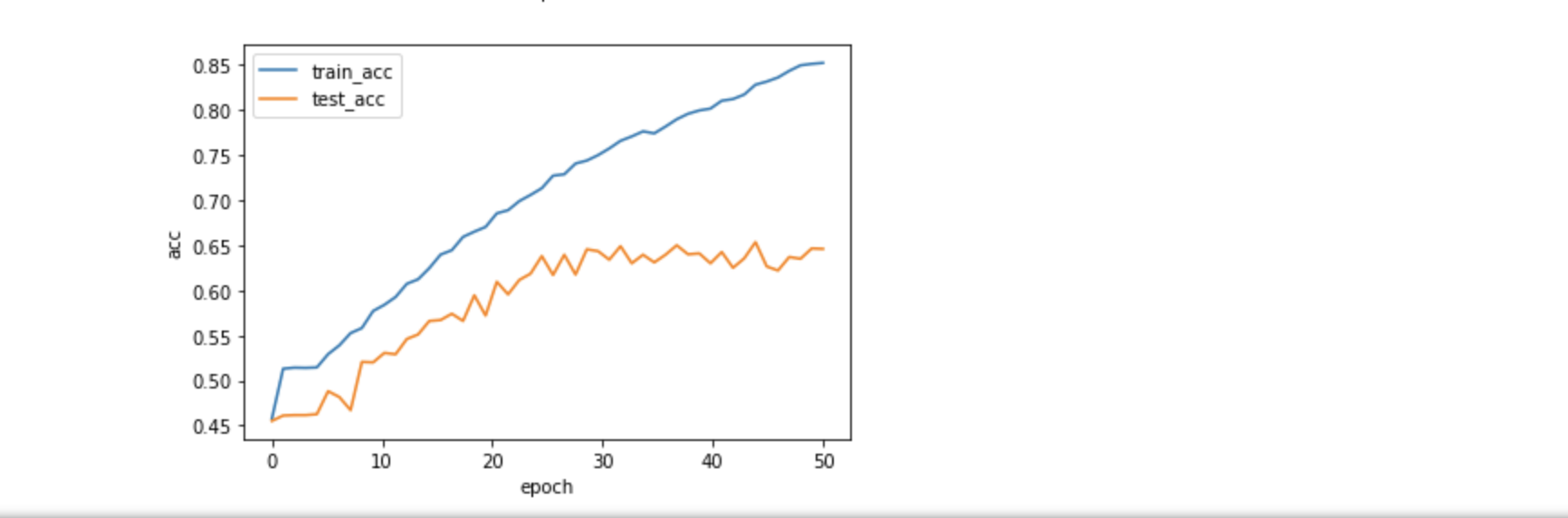
#from src.train import trainif __name__ == '__main__':config = Config()batch_size = config.batch_sizelearning_rate = config.learning_ratetrain_dataloader, test_dataloader, n_vocab = get_data(batch_size)config.n_vocab = n_vocab# model = TextCNN(config).to(Config.device)model = TextRNN(config).to(Config.device)# model = Transformer(config).to(Config.device)# 导入word2vec训练出来的预训练词向量id_vec = open(Config.id_vec_path, 'rb')id_vec = pkl.load(id_vec)id_vec = torch.tensor(list(id_vec.values())).to(Config.device)if config.embedding_pretrained:model.embedding = nn.Embedding.from_pretrained(id_vec)loss = nn.CrossEntropyLoss().to(Config.device)optimizer = optim.Adam(params=model.parameters(), lr=learning_rate)train(model, loss, optimizer, train_dataloader, test_dataloader, Config.epoches, Config.device)运行结果(准确率和错误率):
正确率达到85%。
相关文章:
微博情绪分类
引自:https://blog.csdn.net/no1xiaoqianqian/article/details/130593783 友好借鉴,总体抄袭。 所需要的文件如下:https://download.csdn.net/download/m0_37567738/88340795 import os import torch import torch.nn as nn import numpy a…...
探索项目追踪平台的多样性及功能特点
项目追踪平台是现代项目管理中不可或缺的工具,它可以帮助团队高效地跟踪和管理项目进度、任务和资源分配。在当今快节奏的商业环境中,有许多热门的项目追踪平台可供选择。 本文总结了当下热门的项目追踪平台,供您参考~ 1、Zoho Projects&am…...

git简单命令
简易的命令行入门教程: Git 全局设置: git config --global user.name “yyyyjinying” git config --global user.email “12343343qq.com” 创建 git 仓库: mkdir wx-project cd wx-project git init touch README.md git add README.md git commit -m “first commit” …...

Fiber 架构的起源和含义
Fiber 架构的起源 Fiber 架构的起源可以追溯到 React 团队在 2017 年提出的一项重大改进计划。在过去的 React 版本中,渲染过程是基于递归的,即组件树的遍历是通过递归函数来完成的。这种方式在大规模复杂应用中可能会引发一些性能问题,例如…...

Vue3高频面试题+八股文
Vue3.0中的Composition Api 开始之前 Compos:1 tion API可以说是ue3的最大特点,那么为什么要推出Compos1t1on Api,解决了什么问趣? 通常使用Vue2开发的项目,普遍会存在以下问题: 代码的可读性随着组件变大而变差每一种代码复用的…...

对数据库三大范式的理解
首先,要明确一个概念,范式的提出到逐步精进,从第一范式到第三范式,甚至于BCNF范式,逐步优化是为了解决插入异常、删除异常以及改善数据冗余的。 第一范式:符合第一范式的要求,即数据表的属性值均…...
(matplotlib)如何不显示x轴或y轴刻度(ticks)
文章目录 背景plt版本ax子图版本 解决办法plt版本ax子图版本 背景 import numpy as np import matplotlib.pyplot as pltplt版本 x[1,2,3] y[4,5,6] plt.plot(x,y)ax子图版本 x[1,2,3] y[4,5,6] axplt.subplot() ax.plot(x,y)可以发现,正常情况下是有刻度的&…...
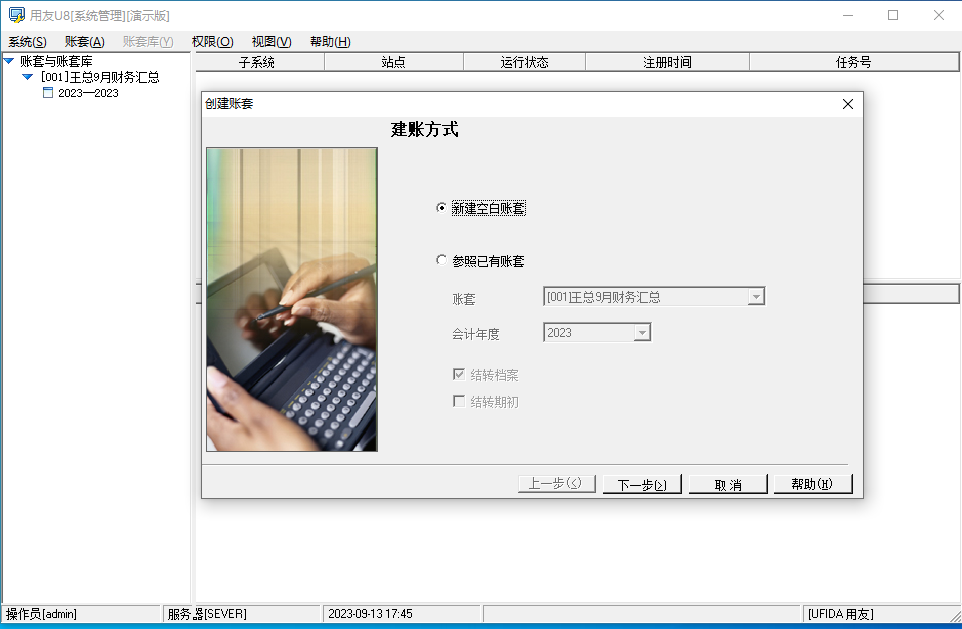
U8用友ERP本地部署异地远程访问:内网端口映射外网方案
文章目录 前言1. 服务器本机安装U8并调试设置2. 用友U8借助cpolar实现企业远程办公2.1 在被控端电脑上,点击开始菜单栏,打开设置——系统2.2 找到远程桌面2.3 启用远程桌面 3. 安装cpolar内网穿透3.1 注册cpolar账号3.2 下载cpolar客户端 4. 获取远程桌面…...

怎么提取一个python文件中所有得函数名称
可以通过创建一个Python脚本来读取一个文件(其中包含函数名称),并将这些函数名称写入另一个文件。以下是一个简单的示例: 假设你有一个名为 mytest.py 的文件,其中包含一些函数: # mytest.py def functi…...
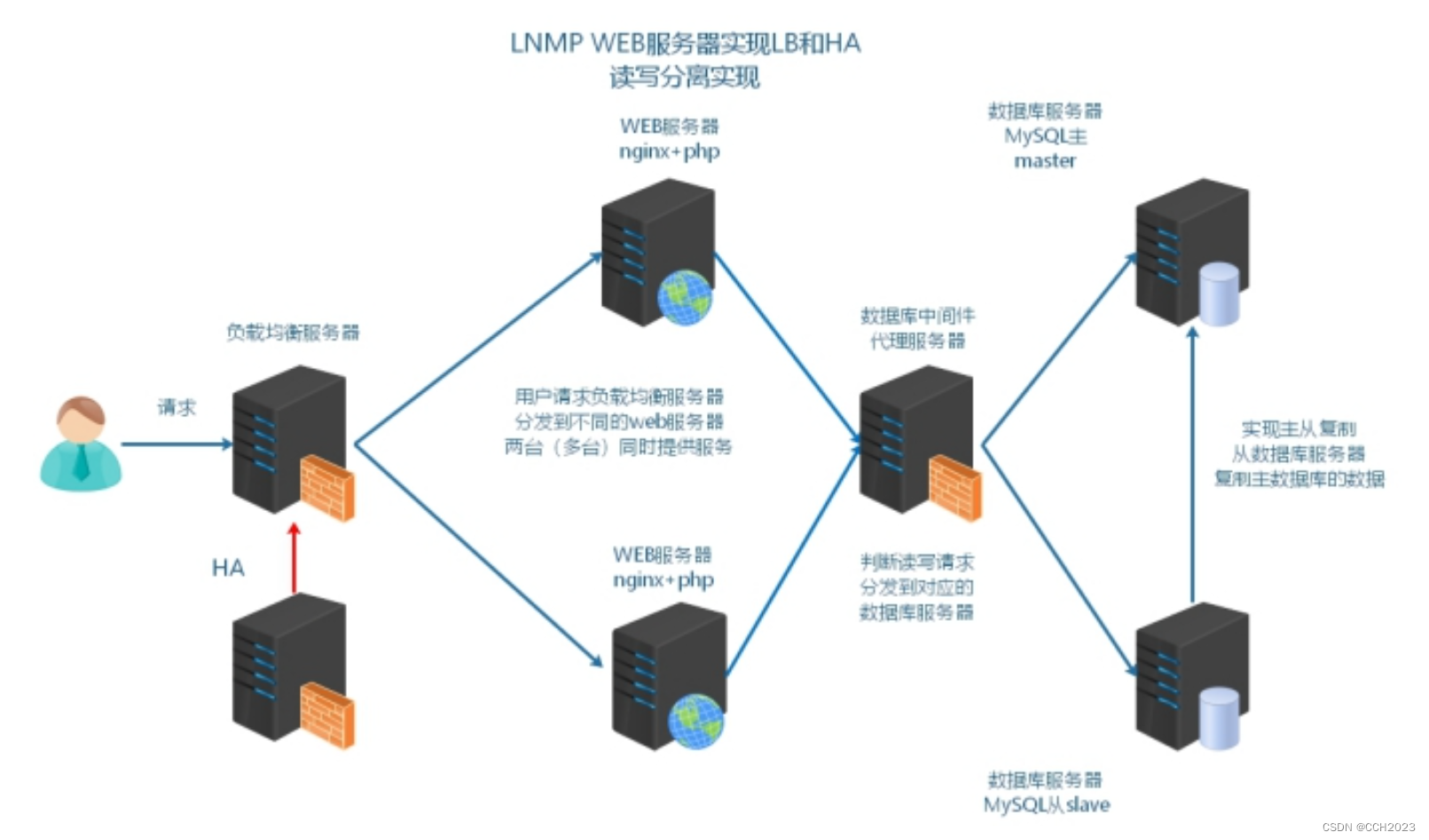
企业架构LNMP学习笔记37
1、能够理解读写分离的目的; 2、能够描述读写分离的常见实现方式; 3、能够通过项目框架配置文件实现读写分离; 4、能够通过中间件实现读写分离; 业务背景描述: 时间:2014.6.-2015.9 发布产品类型&#x…...

vue3 自定义组件 v-model 原理解析
1. input 中的 v-model <!-- my-input.vue --> <!-- props:value值必须用modelValue命名 --> <!-- emits:方法必须用update:modelValue命名 --> <script setup>const props defineProps({modelValue: String,});let emits de…...
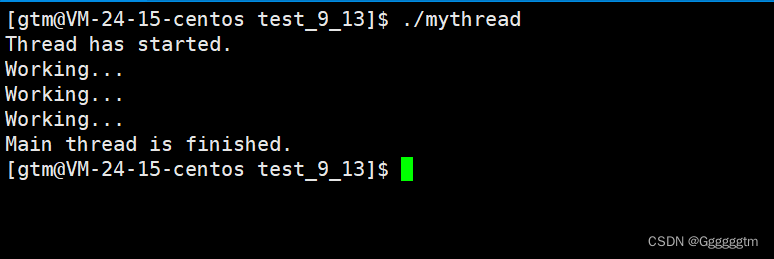
【Linux从入门到精通】线程 | 线程介绍线程控制
本篇文章主要对线程的概念和线程的控制进行了讲解。其中我们再次对进程概念理解。同时对比了进程和线程的区别。希望本篇文章会对你有所帮助。 文章目录 一、线程概念 1、1 什么是线程 1、2 再次理解进程概念 1、3 轻量级进程 二、进程控制 2、1 创建线程 pthread_create 2、2…...
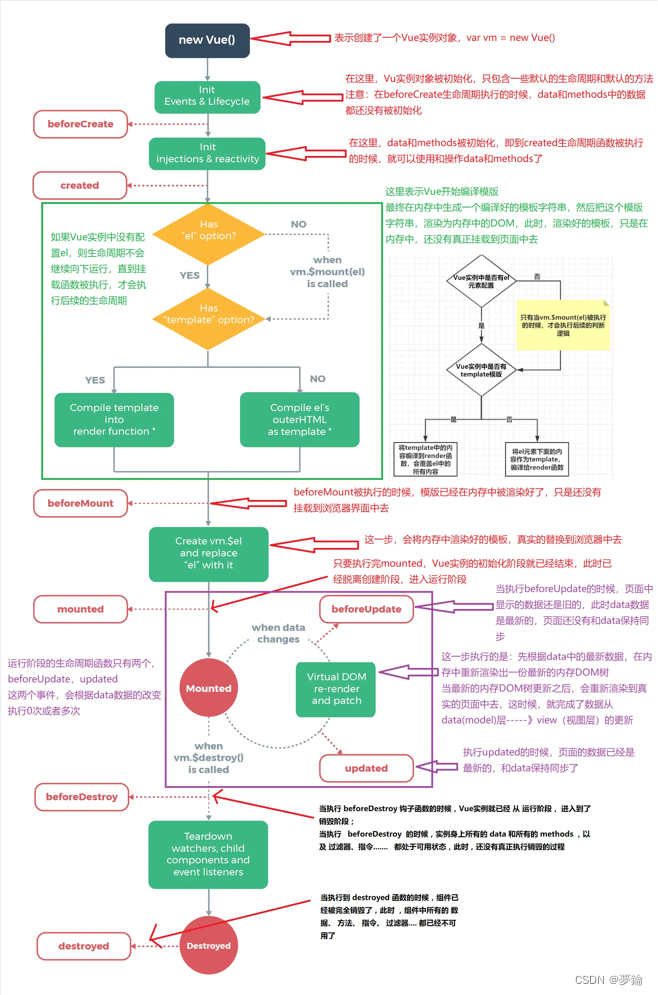
2023Web前端面试题及答案(一)
答案仅供参考,每人的理解不一样。 文章目录 1、简单说一说事件流原理 事件流: (1)事件流是指页面 接收事件的顺序; (2)假设页面中的元素都具备相同的事件,并且这些个元素之间是相互嵌套的 关系. (3…...

Rabbitmq参数优化
官网 ## https://www.rabbitmq.com/configure.html参考 ## https://blog.csdn.net/qq_37165235/article/details/132447907 优化参数 cat /etc/rabbitmq/rabbitmq.conf vm_memory_high_watermark.relative0.8...

typescript环境搭建,及tsc命令优化
typescript typescript. 是一种由微软开发的 开源 、跨平台的编程语言。. 它是 JavaScript 的超集,最终会被编译为JavaScript代码。. TypeScript添加了可选的静态类型系统、很多尚未正式发布的ECMAScript新特性(如装饰器 [1] )。. 2012年10月…...
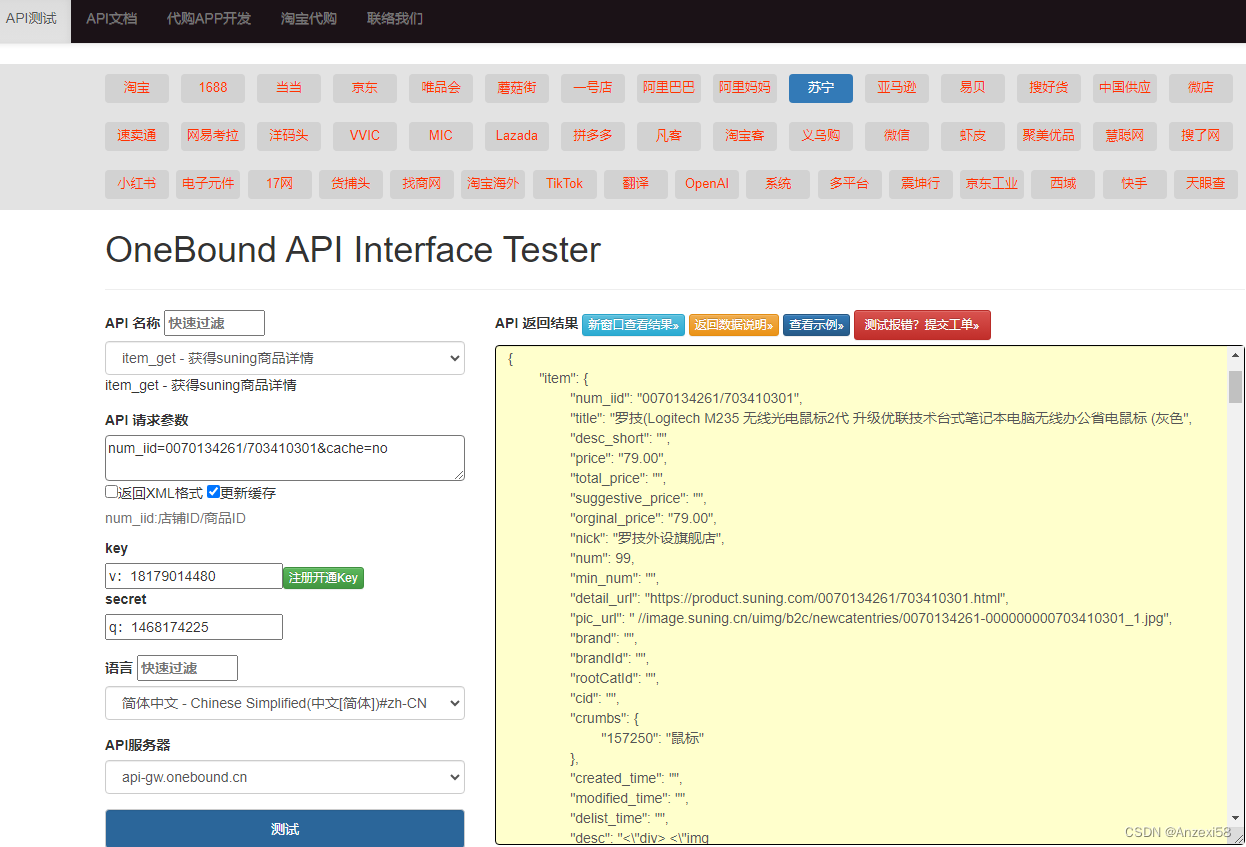
suning苏宁API接入说明(苏宁商品详情+关键词搜索商品列表)
API地址:https://o0b.cn/anzexi 调用示例:https://api-gw.onebound.cn/suning/item_get/?keytest_api_key& &num_iid0070134261/703410301&&langzh-CN&secret 参数说明 通用参数说明 version:API版本key:调用key,测试key:test_api_keyapi_na…...
类和对象(3)
文章目录 1.回顾上节2. 拷贝构造3. 运算符重载(非常重要)4. 赋值运算符重载 1.回顾上节 默认成员函数:我们不写,编译器自动生成。我们不写,编译器不会自动生成 默认生成构造和析构: 对于内置类型不做处理对…...
C++下基于粒子群算法解决TSP问题
粒子群优化算法求解TSP旅行商问题C(2020.11.12)_jing_zhong的博客-CSDN博客 混合粒子群算法(PSO):C实现TSP问题 - 知乎 (zhihu.com) 一、原理 又是一个猜答案的算法,和遗传算法比较像,也是设…...

vue3 ElementUI Switch before-change自动调用问题
使用 :beforeChange 这个属性 但是这个属性不能直接传值 如果直接传值依然会自动调用,需要使用自执行函数来****传值 解决 <el-switchv-model"rows[index].ifInjection":before-change"() > beforeChange(row)"/> :before-change"() > b…...
【chromium】windows 获取源码到本地
从github的chromium 镜像git clone 到2.5G失败了官方说不能,要去 windows_build_instructions vs2017和19都是32位的 vs2022是x64的 vs2022_install You may also have to set variable vs2022_install to your installation path of Visual Studio 2022,...

Tree of Thoughts详解:思维树搜索算法
🌳 多路径探索 | 广度优先 深度优先搜索 | 自我评估 回溯机制 | LangChain实现 | 完整项目代码 📖 什么是Tree of Thoughts? 核心思想 ToT Tree of Thoughts(思维树) 传统LLM: 输入 → 线性思考 → 输出…...

半导体失效分析技术跨界应用:显微镜下的口罩材料与工艺质量深度解析
1. 项目概述:当半导体失效分析技术遇上日常口罩作为一名长期在半导体测试与失效分析领域工作的人,我习惯于用显微镜、电子束和各种精密仪器去审视芯片内部那些纳米级的缺陷。当新冠疫情席卷全球,口罩成为日常生活必需品时,我和团队…...

国际B2B企业平台表达框架:IBM式重构与ServiceNow式统一执行
如果把国际B2B品牌表达看成一个系统问题,IBM / ServiceNow这组样本可以拆成一套判断框架。它不是讨论文案怎么写,而是讨论输入什么业务条件,输出什么品牌角色、结构和证据链。框架结论:IBM与ServiceNow都服务企业转型,…...


TinyML中的数据感知NAS技术解析与应用
1. TinyML与神经网络架构搜索概述在嵌入式设备和物联网终端上部署机器学习模型(TinyML)面临着严峻的资源约束问题。典型的微控制器(MCU)仅有几十KB内存和几百MHz主频,这迫使开发者必须在模型精度与资源消耗之间寻找平衡…...

Timoni高级功能揭秘:类型验证、签名和OCI分发
Timoni高级功能揭秘:类型验证、签名和OCI分发 【免费下载链接】timoni Timoni is a package manager for Kubernetes, powered by CUE and inspired by Helm. 项目地址: https://gitcode.com/gh_mirrors/ti/timoni Timoni是一个基于CUE的Kubernetes包管理器&…...

从A*到平滑:拉绳算法如何为游戏角色“剪裁”最优路径
1. 游戏寻路为什么需要平滑处理? 想象一下你在玩一款开放世界游戏,控制角色从城堡出发前往远处的森林。如果直接使用A*算法生成的路径,角色可能会像喝醉酒一样左右摇摆,贴着导航网格的边缘移动。这种"锯齿状路径"不仅看…...

初创团队如何利用Token Plan套餐控制大模型API开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Token Plan套餐控制大模型API开发成本 对于初创团队而言,在原型开发和产品迭代阶段,技术选…...

高速数字设计中的抖动:从概念到测量与抑制的完整指南
1. 项目概述:从“抖动”说起,高速数字设计的隐形杀手如果你在高速数字电路设计或者信号完整性测试领域摸爬滚打过几年,那么“抖动”这个词对你来说,绝对不是一个陌生的概念。它就像电路板上的幽灵,平时看不见摸不着&am…...

量子生成模型电路设计:特征相似性优化方法
1. 量子生成建模与电路设计概述量子生成模型作为量子机器学习的重要分支,正逐渐展现出其在特定任务上的潜在优势。这类模型的核心思想是利用量子系统的固有概率特性,通过参数化量子电路(PQC)来学习目标数据集的概率分布。与传统生…...