map-reduce执行过程
Map阶段
Map 阶段是 MapReduce 框架中的一个重要阶段,它负责将输入数据转换为中间数据。Map 阶段由一个或多个 Map 任务组成,每个 Map 任务负责处理输入数据的一个子集。
执行步骤
Map 阶段的过程可以分为以下几个大步骤:
- 输入数据分配:MapReduce 框架会将输入数据分配给每个 Map 任务。
- Map 函数执行:Map 函数会对每个输入数据进行处理,并将处理结果写入一个临时文件。
- Map 函数完成:Map 函数完成后,会向 JobTracker 报告完成状态。
详细来说,便是如下过程:
- 初始化:Map 任务在执行之前会进行初始化,包括加载配置信息、初始化状态等。
- 读取输入数据:Map 任务会从输入数据源读取数据。
- 应用用户自定义的 Map 函数:Map 任务会应用用户自定义的 Map 函数来处理输入数据。
- 写出输出数据:Map 任务会将输出数据写入一个临时文件。
Map 阶段的输入数据可以是文件、数据库表或其他数据源。Map 阶段的输出数据是键值对,其中键是 Map 函数的输出 key,值是 Map 函数的输出 value。
Map 阶段的 Map 函数由用户编写,它可以根据不同的需求来处理输入数据。Map 函数的输出 key 和 value 可以是任意类型,但通常是字符串、数字或二进制数据。
Map 阶段是 MapReduce 作业的第一个阶段,它决定了 MapReduce 作业的输出数据的格式。Map 阶段的效率直接影响了 MapReduce 作业的整体性能。
执行效率
影响效率的因素
Map 阶段的效率取决于以下几个因素:
- 输入数据的大小:输入数据越大,Map 阶段的执行时间越长。
- Map 函数的复杂度:Map 函数越复杂,Map 阶段的执行时间越长。
- 输出数据的大小:输出数据越大,Map 阶段的执行时间越长。
提高效率的方法
为了提高 Map 阶段的效率,可以通过以下方式:
- 减少输入数据的大小**:可以通过过滤数据或压缩数据来减少输入数据的大小。
- 简化 Map 函数的复杂度**:可以通过优化 Map 函数的代码来简化 Map 函数的复杂度。
- 减少输出数据的大小**:可以通过压缩数据或合并数据来减少输出数据的大小。
以下是一些可以提高 Map 阶段效率的具体的建议:
- 使用过滤器来过滤掉不必要的数据。
- 使用压缩算法来压缩数据。
- 使用合并分组来减少分组数。
- 使用 Hadoop 的 DistributedCache 机制来缓存常用的数据。
- 使用 Apache Spark 等更高效的计算框架来替代 MapReduce。
以下是一个简单的 Map 函数示例:
def map(key, value):# 对输入数据进行处理...# 返回输出数据return (key, value)
这个 Map 函数接受两个参数:key 和 value。key 是输入数据的唯一标识,value 是输入数据的值。Map 函数可以对输入数据进行任何处理,然后返回输出数据。
Reduce阶段
Reduce 阶段是 MapReduce 作业中的第二个阶段,它负责将 Map 阶段的输出数据聚合到一起。Reduce 阶段的输入数据是 Map 阶段的输出数据,通常是键值对的形式。Reduce 阶段的输出数据通常是单个值或多个值的集合。
执行步骤
Reduce 阶段的过程可以分为以下几个步骤:
- 初始化:Reduce 任务在执行之前会进行初始化,包括加载配置信息、初始化状态等。
- 读取输入数据:Reduce 任务会从 Shuffle 阶段得到的分组数据中读取数据。
- 应用用户自定义的 Reduce 函数:Reduce 任务会应用用户自定义的 Reduce 函数来处理输入数据。
- 写出输出数据:Reduce 任务会将输出数据写入一个文件。
执行效率
影响因素
Reduce 阶段的效率取决于以下几个因素:
- 输入数据的大小:输入数据越大,Reduce 阶段的执行时间越长。
- Reduce 函数的复杂度:Reduce 函数越复杂,Reduce 阶段的执行时间越长。
- 输出数据的大小:输出数据越大,Reduce 阶段的执行时间越长。
提高效率
为了提高 Reduce 阶段的效率,可以通过以下方式:
- 减少输入数据的大小**:可以通过过滤数据或压缩数据来减少输入数据的大小。
- 简化 Reduce 函数的复杂度**:可以通过优化 Reduce 函数的代码来简化 Reduce 函数的复杂度。
- 减少输出数据的大小**:可以通过压缩数据或合并数据来减少输出数据的大小。
以下是一个简单的 Reduce 函数示例:
def reduce(key, values):# 对输入数据进行处理...# 返回输出数据return output
这个 Reduce 函数接受两个参数:key 和 values。key 是输入数据的唯一标识,values 是属于同一个 key 的所有输入数据。Reduce 函数可以对输入数据进行任何处理,然后返回输出数据。
Shuffle
MapReduce 中的 Shuffle 是指在 Map 阶段和 Reduce 阶段之间的数据传输过程。在 Map 阶段,每个 Map 任务都会产生一个中间结果文件,这些中间结果文件会在 Shuffle 阶段被复制到 Reduce 任务所在的节点。Reduce 任务会从这些中间结果文件中读取数据,并进行进一步的处理。
Shuffle 可以分为以下几个步骤:
- Map 阶段:Map 任务将输入数据根据 key 进行分区,并将每个分区的数据写入一个文件。
- Shuffle 阶段:Shuffle 服务器将 Map 阶段的输出文件读取到内存中,并按照 Reduce 阶段的 key 进行分区。
- Reduce 阶段:Reduce 任务从 Shuffle 服务器读取数据,并根据 key 将数据合并到一起。
Shuffle 是 MapReduce 中的一个关键步骤,它影响了 MapReduce 的性能和可扩展性。Shuffle 的效率取决于以下几个因素:
- 数据的大小:如果数据量很大,Shuffle 会消耗更多的时间和资源。
- 数据的格式:如果数据格式复杂,Shuffle 会消耗更多的时间和资源。
- 数据的分布:如果数据分布不均匀,Shuffle 会导致部分节点负载过重。
Shuffle优化
Shuffle 的优化可以从以下几个方面进行:
- 提高 Shuffle 服务器的性能:可以使用更高性能的硬件来构建 Shuffle 服务器,或者使用更高效的 Shuffle 算法。
- 优化 Shuffle 的算法:可以使用更均匀的数据分布算法,或者使用更合适的 Shuffle 参数。
- 减少 Shuffle 的数据量:可以使用预聚合等技术来减少 Shuffle 的数据量。
Hive中的针对优化
在 Hive 中,Shuffle 可以通过以下方式进行优化:
- 使用 Hive 的压缩功能来压缩数据。
- 使用 Hive 的自动分区功能来均匀分布数据。
- 使用 Hive 的推送谓词功能来减少数据量。
优化总结
以下是一些可以提高 Shuffle 效率的具体的建议:
- 使用过滤器来过滤掉不必要的数据。
- 使用压缩算法来压缩数据。
- 使用合并分组来减少分组数。
- 使用 Hadoop 的 DistributedCache 机制来缓存常用的数据。
- 使用 Apache Spark 等更高效的计算框架来替代 MapReduce。
总体而言,Shuffle 是 MapReduce 中的关键环节,它决定了 MapReduce 的性能。通过优化 Shuffle,可以提高 MapReduce 的性能。
总结
也就是说,在Map Reduce执行过程中,Map操作是将任务分离到每个节点上,先在每个节点单独把任务问题解决掉,得到目标结果;Reduce阶段则是把每个节点的结果组合起来的过程
相关文章:

map-reduce执行过程
Map阶段 Map 阶段是 MapReduce 框架中的一个重要阶段,它负责将输入数据转换为中间数据。Map 阶段由一个或多个 Map 任务组成,每个 Map 任务负责处理输入数据的一个子集。 执行步骤 Map 阶段的过程可以分为以下几个大步骤: 输入数据分配&a…...

技术人员怎样提升对业务的理解
技术服务于业务。 一个技术人员想要走得更远,不能仅局限于技术,需要对自己所从事的业务领域有不断深入和全面的理解。 所谓业务领域,就是大家平常自我介绍,不会仅简单说我是搞C的,我是搞JAVA的,而是游戏后台…...
【分布式】分布式事务:2PC
分布式事务的问题可以分为两部分: 并发控制 concurrency control原子提交 atomic commit 分布式事务问题的产生场景:一份数据被分片存在多台服务器上,那么每次事务处理都涉及到了多台机器。 可序列化(并发控制)&…...
回归与聚类算法系列④:岭回归
目录 1. 背景 2. 数学模型 3. 特点 4. 应用领域 5. 岭回归与其他正则化方法的比较 6、API 7、代码 8、总结 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数…...
idea配置git(gitee)并提交(commit)推送(push)
Intellij Idea VCS | 版本控制 - 知乎 IDEA项目上传到gitee仓库_idea上传代码到gitee_robin19712的博客-CSDN博客 git程序下载国内镜像地址: https://registry.npmmirror.com/binary.html?pathgit-for-windows/v2.42.0.windows.2/ 解压后放到固定路径:…...

(19)Task异步:任务创建,返回值,异常捕捉,任务取消,临时变量
一、Task任务的创建 1、用四种方式创建,界面button,info各一。 程序代码 private void BtnStart_Click(object sender, EventArgs e){Task t new Task(() >{DisplayMsg($"[{Environment.CurrentManagedThreadId}]new Task.---1");});t.Start()…...
设备树的理解与运用
设备树: 本质是一个文件,包含很多节点,每个节点里边是对设备属性的描述(包括GPIO,时钟,中断等等),其中节点(node)和属性(property)就是设备树最重…...

【AIGC】提示词 Prompt 分享
提示词工程是什么? Prompt engineering(提示词工程)是指在使用语言模型进行生成性任务时,设计和调整输入提示(prompts)以改善模型生成结果的过程。它是一种优化技术,旨在引导模型产生更加准确、…...

【Axure视频教程】取整函数
今天教大家在Axure里如何使用三种不同的取整函数,包括向上取整、向下取整和四舍五入取整。具体效果可以参考下方视频。该教程从0开始制作,手把手教学,无论是新手小白还是有一定基础的同学,都可以学习的哦。 【视频教程——试看版…...

MySQL清空表
当我们需要清空一个表中的所有行时,除了使用 DELETE * FROM table 还可以使用 TRUNCATE TABLE 语句。 如果想要清空一个表, TRUNCATE TABLE 语句比 DELETE语句更加有效。 TRUNCATE TABLE 语法 TRUNCATE TABLE 的语法很简单,如下:…...

使用IDEA创建Vue3通过Vite实现工程化
1、创建Vite项目的分步说明 IntelliJ IDEA与Vite构建工具集成,改善了前端开发体验。Vite 由一个开发服务器和一个构建命令组成。构建服务器通过本机 ES 模块提供源文件。生成命令将代码与汇总捆绑在一起,汇总预配置为输出高度优化的静态资产以供生产。In…...

GitLab使用的最简便方式
GitLab介绍 GitLab是一个基于Git版本控制系统的开源平台,用于代码托管,持续集成,以及协作开发。它提供了一套完整的工具,以帮助开发团队协同工作、管理和部署代码。 往往在企业内部使用gitlab管理代码,记录一下将本地代…...

MySQL数据库20G数据迁移至其他服务器的MySQL库或者云MySQL库
背景:20G的MySQL数据迁移至火山云MySQL库,使用navicat的数据传输工具迁移速度耗费时间过长。 方案一:使用火山云提供的MySQL数据迁移服务(其他大厂应该提供的也有) 方案二:使用数据迁移工具kettle&#x…...

build.gradle配置文件详解
Andorid Studio高版本和低版本的build.gradle配置逻辑有些差异 安卓项目中相关编译文件的介绍 gradle-wrapper.properites:配置Gradle Wrapper gradle.properties:配置Gradle的编译参数。具体配置见Gradle官方文档:com.android.build.gradle | Andro…...
)
2024拼多多校招面试真题汇总及其解答(二)
6. 【算法题】归并排序 归并排序(Merge Sort)是一种分治算法,它将待排序的序列递归地分成两个子序列,然后将两个有序的子序列合并成一个有序的序列。 归并排序的算法流程如下: 递归地将待排序的序列分成两个子序列,直到每个子序列只有一个元素。将两个有序的子序列合并…...
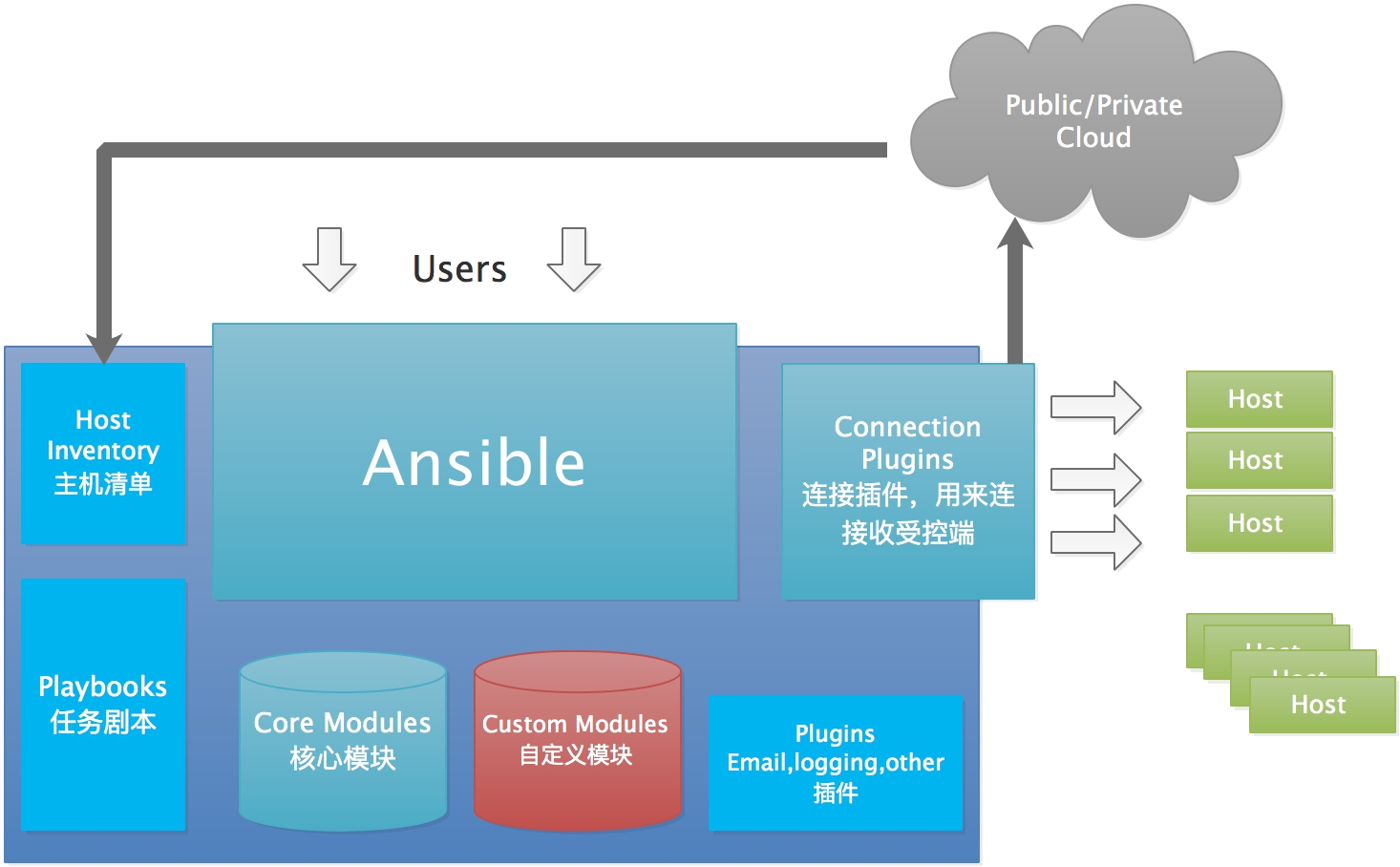
自动化运维工具Ansible教程(一)【入门篇】
文章目录 前言Ansible 入门到精通入门篇进阶篇精通篇入门篇1. Ansible 简介2. 安装 Ansible1. 通过包管理器安装:2. 通过源码安装: 3. Ansible 的基本概念和核心组件4. 编写和运行第一个 Ansible Playbook5. 主机清单和组织结构主机清单组织结构 6. Ansi…...

计算机毕业设计 微信小程序 uniapp+vue大学生兼职平台
任何系统都要遵循系统设计的基本流程,本系统也不例外,同样需要经过市场调研,需求分析,概要设计,详细设计,编码,测试这些步骤,本系统前台采用微信开发者结合后台Java语言设计并实现了…...

JavaScript框架:构建交互性、现代化Web应用的利器
💂 个人网站:【工具大全】【游戏大全】【神级源码资源网】🤟 前端学习课程:👉【28个案例趣学前端】【400个JS面试题】💅 寻找学习交流、摸鱼划水的小伙伴,请点击【摸鱼学习交流群】 引言 JavaScript框架已…...

数据结构——二分查找法
二分查找法(Binary Search)是一种高效的查找算法,通常用于在已排序的数组或列表中查找特定的目标值。这个算法的基本思想是不断将查找范围缩小为原来的一半,直到找到目标值或确定目标值不存在。 二分查找是一种在每次比较之后将查…...

服务端渲染(SSR):提升Web应用性能和用户体验的关键技术
💂 个人网站:【工具大全】【游戏大全】【神级源码资源网】🤟 前端学习课程:👉【28个案例趣学前端】【400个JS面试题】💅 寻找学习交流、摸鱼划水的小伙伴,请点击【摸鱼学习交流群】 引言 服务端渲染&#…...

从单片机寄存器到多线程标志:volatile关键字的5个硬核使用场景详解
从单片机寄存器到多线程标志:volatile关键字的5个硬核使用场景详解 在嵌入式系统和并发编程的世界里,volatile关键字就像一位沉默的守护者,确保编译器不会自作聪明地优化掉那些看似冗余但实际上至关重要的代码。对于习惯了高层抽象语言的开发…...

安全生产隐患识别太难?实测实在Agent:AI模型语义分析能力测评详解与信创落地指南
摘要: 步入2026年,安全生产已进入“全量数字化”与“法制化”深度融合的高压期。随着《安全生产法》的持续深化执行,企业面临着海量隐患识别、跨系统数据流转及信创环境适配的三重挑战。传统的人工排查与基于API的自动化手段,在面…...

JAVA:类和对象完全解析
一、编程世界的乐高积木在面向对象编程(OOP)的宇宙中,类(Class)和对象(Object)如同乐高积木的基础模块。如果把程序看作一个虚拟城市,类就是建筑设计图,而对象则是根据图…...

nslookup-mcp:基于MCP协议的DNS查询工具部署与实战指南
1. 项目概述:一个为安全与开发场景设计的DNS查询工具如果你经常需要排查网络问题、分析域名配置,或者像我一样,在渗透测试或安全研究时,需要快速、批量地查询DNS记录,那么命令行里的nslookup或dig工具可能已经让你感到…...

别再被代码劝退!用LilyPond 2.20.0写《铃儿响叮当》乐谱,5分钟搞定你的第一份五线谱
别再被代码劝退!用LilyPond 2.20.0写《铃儿响叮当》乐谱,5分钟搞定你的第一份五线谱 第一次看到LilyPond的界面,很多人会下意识皱眉——满屏的代码和符号,仿佛在劝退非程序员背景的音乐爱好者。但事实上,用LilyPond制…...
)
从JAR包到原生二进制:我的SpringBoot应用在Linux服务器上‘瘦身’实战记录(GraalVM 22.1.0 + Maven)
从JAR包到原生二进制:我的SpringBoot应用在Linux服务器上‘瘦身’实战记录 去年接手的一个电商促销系统,随着业务增长,JAR包启动时间从最初的8秒延长到23秒。某次大促期间,服务扩容时JVM预热导致的响应延迟直接影响了转化率——这…...

ZimaOS Blue:本地优先AI代理运行时,打造私有化智能助手
1. 项目概述:ZimaOS Blue,一个为“大胆构建者”准备的本地优先AI代理运行时 如果你和我一样,对当前AI应用生态里那些动辄需要联网、依赖特定云服务、数据隐私存疑的“智能助手”感到厌倦,同时又渴望一个能真正运行在自己设备上、…...

Android原生AI智能体平台Zero:Rust核心与多通道集成的工程实践
1. 项目概述:一个运行在Android上的原生AI智能体平台如果你和我一样,对手机上那些“大模型助手”感到有些审美疲劳——它们要么是套壳的Web应用,响应慢、功能受限,要么就是纯粹的聊天玩具,没法真正帮你处理点“脏活累累…...

基于Tauri与Rust构建跨平台Claude桌面客户端:架构设计与工程实践
1. 项目概述:一个为Claude设计的“圣杯”级桌面应用 如果你和我一样,在日常开发、写作或信息处理中重度依赖Anthropic的Claude模型,那么你肯定也经历过在浏览器标签页间反复横跳、复制粘贴、以及管理冗长对话历史的烦恼。 CoderLuii/HolyCla…...

拒绝无效熬夜!Paperxie 本科论文智能写作,把毕业季还给你
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 凌晨三点的图书馆,光标在空白文档里闪了又闪,Word 字数统计停在 478;导师的修…...