Spark 【Spark SQL(一)DataFrame的创建、保存与基本操作】
前言
今天学习Spark SQL,前面的RDD编程要想熟练还是得通过项目来熟练,所以先把Spark过一遍,后期针对不足的地方再加强,这样效率会更高一些。
简介
在RDD编程中,我们使用的是SparkContext接口,接下来的Spark SQL中,我们使用到的是SparkSession接口。Spark2.0 出现的 SparkSession 接口替代了 Spark 1.6版本中的 SQLContext 和 HiveContext接口,来实现对数据的加载、转换、处理等功能。此外,SparkSession 封装了SparkContext、SparkConf 和 StreamingContext 等。
也就是说,在Spark1.0 中,需要创建 SparkContext 对象用于 RDD编程 ,创建 SQLContext 对象用于 SQL 编程。而在Spqrk 2.x和3.x版本下,只需要创建一个 SparkSession 对象,就可以执行各种 Spark 操作。
其实在我们的 spark-shell 中默认已经为我们提供了一个 SparkContext 对象(“sc”)和一个SparkSession 对象(“spark”)了。
从Spark 2.x 开始,RDD被降级为底层的API,所有通过高层的 DataFrame API 表达的计算,都会被分解,生成优化好的底层的 RDD 操作,然后转化为Scala 字节码,交给执行器的JVM虚拟机。
结构化数据 DataFrame
Spark SQL 所使用的数据抽象并非 RDD,而是 DataFrame。DataFrame 的推出,让 Spark具备了处理大规模结构化数据的能力。
DataFrame 概述
DataFrame 是一种以 RDD 为基础的表格型的数据结构,提供了详细的结构信息,就相当于关系数据库中的一张表。
和 RDD 一样,DataFrame 的操作也分为转换和行动操作,DataFrame 的计算过程也是“惰性”的,只有触发行动操作,Spark才会真正从头到尾进行一次计算。
入门案例
给定一组键值对(书名,销量),现在求每个键对应的平均值,也就是图书的平均销量。
def main(args: Array[String]): Unit = {//创建SparkSession对象val spark: SparkSession = SparkSession.builder().master("local[*]").appName("test01").getOrCreate()val df: DataFrame = spark.createDataFrame(Array(("spark", 2), ("hadoop", 5), ("spark", 3), ("hadoop", 6))).toDF("book", "amount")val df2: DataFrame = df.groupBy("book") agg(avg("amount"))df2.show()spark.stop()}运行结果:
+------+-----------+
| book|avg(amount)|
+------+-----------+
| spark| 2.5|
|hadoop| 5.5|
+------+-----------+DataFrame 的创建与保存
Spark SQL 支持多种数据源创建 DataFrame,也支持把 DataFrame 保存成各种数据格式。
1、Parquet
读取
//1.第一种创建方式
val df1 = spark.read.foramt("parquet").load("文件路径")
//2.第二种创建方式
val df2 = spark.read.parquet("文件路径")保存
//1.使用 Snappy 压缩算法压缩后输出
df.write.foramt("parquet").mode("overwrite").option("compression","snappy").save("输出路径")
//2.
df.write.parquet("输出路径")2、JSON
//1.第一种创建方式
val df1 = spark.read.foramt("json").load("文件路径")
//2.第二种创建方式
val df2 = spark.read.json("文件路径")保存
df.write.format("json").mode("overwrite").save("输出路径")
df.write.json("输出路径")3、CSV
//两种创建方式都需要定义数据模式
val schema = "name:STRING,age INT,sex STRING"
//1.第一种创建方式
val df1 = spark.read.foramt("csv").schema(schema).option("header","true").option("seq",";").load("文件路径")
//2.第二种创建方式
val df2 = spark.read.schema(schema).option("header","true").option("seq",";").csv("文件地")保存
//1.
df.write().format("csv").mode("overwrite").save("输出路径")
//2.
df.write.csv("输出路径")4、文本文件
//1.第一种创建方式
val df1 = spark.read.foramt("text").load("文件路径")
//2.第二种创建方式
val df2 = spark.read.text("文件路径")保存
//1.
df.write.text("输出路径")
//2.
df.write.foramt("text").save("输出路径")集合类型
通过 SparkSession 对象调用 createDataFrame(集合) 方法。
val df: DataFrame = spark.createDataFrame(Array(("spark", 2), ("hadoop", 5), ("spark", 3), ("hadoop", 6))).toDF("book", "amount")DataFrame 基本操作
我们将这个JSON文件作为输入源进行数据分析:
{"name":"Michael", "age":30, "sex": "男"}
{"name":"Andy", "age":19, "sex": "女"}
{"name":"Justin", "age":19, "sex": "男"}
{"name":"Bernadette", "age":20, "sex": "男"}
{"name":"Gretchen", "age":23,"sex": "女"}
{"name":"David", "age":27, "sex": "男"}
{"name":"Joseph", "age":33,"sex": "女"}
{"name":"Trish", "age":27,"sex": "女"}
{"name":"Alex", "age":33,"sex": "女"}
{"name":"Ben", "age":25, "sex": "男"}生成DataFrame对象:
val df: DataFrame = spark.read.json("data/sql/people.json")在操作 DataFrame 时,有两种不同风格的语句,即DSL和SQL语句。但无论是执行 DSL 语句还是 SQL 语句,本质上都会被转换为对 RDD 的操作 。
DSL 语法
1、printSchema()
输出DataFrame对象的模式信息。
df.printSchema()运行结果:
root|-- _corrupt_record: string (nullable = true)|-- age: long (nullable = true)|-- name: string (nullable = true)
2、show()
显示一个DataFrame的二维表格。
//Scala中如果方法没有参数 括号可省略
df.show()运行结果:
+----------+----+
| name| age|
+----------+----+
| null|null|
| Michael| 30|
| Andy| 19|
| Justin| 19|
|Bernadette| 25|
| Gretchen| 23|
| David| 27|
| Joseph| 33|
| Trish| 27|
| Alex| 33|
| Ben| 25|
| null|null|
+----------+----+3、select()
从DataFrame中选取部分列的数据,还可以对列进行重命名,对某一列的值也可以统一进行操作(比如age都+1)。
df.select(df("name").as("username"),df("age")+1).show() //显示出DataFrame的name和age字段并将age字段的值都+1,将name用username代替运行结果:
+----------+---------+
| username|(age + 1)|
+----------+---------+
| null| null|
| Michael| 31|
| Andy| 20|
| Justin| 20|
|Bernadette| 26|
| Gretchen| 24|
| David| 28|
| Joseph| 34|
| Trish| 28|
| Alex| 34|
| Ben| 26|
| null| null|
+----------+---------+4、filter()
进行条件查询,找到满足条件要求的数据。
df.filter(df("age")>30).show() //输出所有30岁以上的人的信息运行结果:
+------+---+
| name|age|
+------+---+
|Joseph| 33|
| Alex| 33|
+------+---+5、groupBy()
对记录进行分组。
df.groupBy(df("sex")).count().show()运行结果:
+----+-----+
| sex|count|
+----+-----+
| 男| 3|
| 女| 4|
+----+-----+6、sort()
根据某一字段进行升序(asc)或降序排列(desc)。
df.select(df("name"),df("age"),df("sex")).sort(df("age").desc,df("name").asc).show() //先根据age降序排列 age相同根据name升序排列
运行结果:
+----------+----+----+
| name| age| sex|
+----------+----+----+
| Alex| 33| 女|
| Joseph| 33| 女|
| Michael| 30| 男|
| David| 27| 男|
| Trish| 27| 女|
| Ben| 25| 男|
| Gretchen| 23| 女|
|Bernadette| 20| 男|
| Andy| 19| 女|
| Justin| 19| 男|
| null|null|null|
| null|null|null|
+----------+----+----+7、withColumn()
用于为 DataFrame 增加一个新的列。
//新增一列 isYoung 如果age>25 为young 否则为 old
df.select(df("name"),df("age"),df("sex")).withColumn("isYoung",when(df("age")>25,"young").otherwise("old")).show()
运行结果:
+----------+----+----+-------+
| name| age| sex|isYoung|
+----------+----+----+-------+
| null|null|null| old|
| Michael| 30| 男| old|
| Andy| 19| 女| young|
| Justin| 19| 男| young|
|Bernadette| 20| 男| young|
| Gretchen| 23| 女| young|
| David| 27| 男| old|
| Joseph| 33| 女| old|
| Trish| 27| 女| old|
| Alex| 33| 女| old|
| Ben| 25| 男| old|
| null|null|null| old|
+----------+----+----+-------+8、drop()
可以删除DataFrame中的一列,上面我们是直接在 DataFrame对象的基础上进行查询并展示,show() 方法并不会有返回对象,但其实其它操作(比如select、withColumn、filter、sort等)都会返回一个新的 DataFrame对象,相当于一张新的二维表格。同样,drop() 后会返回一个新的 DataFrame 对象,相当于删除某列后的新表。
val df: DataFrame = spark.read.json("data/sql/people.json")val df2: DataFrame = df.select(df("name"), df("age"), df("sex")).withColumn("isYoung", when(df("age") < 25, "young").otherwise("old"))val df3: DataFrame = df2.drop(df("isYoung"))
df3.show()9、其它操作
除此之外,还有其它一些操作比如min()、max()、sum()和avg()等,比较简单,用的时候再学。
SQL 语法
相比较 DSL 语句,SQL 语句徐需要在执行 SQL 语句之前先创建一张临时表,因为毕竟SQL语句本来就是对关系型表进行操作的语句,所以我们的数据源需要先通过createTempView()或createOrReplaceTempView()方法转换为临时表。
这两个方法没太大区别,只不过createOrReplaceTempView()会判断是否已存在这么张表,如果存在同名的表,就用新表替换掉。而createTempView()的话,如果已经存在同名的表,它就会报错。
我们继续使用上面的 people.json 文件进行操作。
SQL 案例1
//通过JSON文件创建 DataFrame 对象val df = spark.read.format("json").load("data/sql/people.json")//创建临时表 不需要返回值 df.createTempView("people")spark.sql("SELECT * FROM PEOPLE").show()运行结果:
+---+----------+---+
|age| name|sex|
+---+----------+---+
| 30| Michael| 男|
| 19| Andy| 女|
| 19| Justin| 男|
| 20|Bernadette| 男|
| 23| Gretchen| 女|
| 27| David| 男|
| 33| Joseph| 女|
| 27| Trish| 女|
| 33| Alex| 女|
| 25| Ben| 男|
+---+----------+---+SQL 案例2
统计男女人数。
spark.sql("SELECT sex,COUNT(*) AS nums FROM people group by sex").show()
注意:AS 后面的新字段名不能带引号,不能是中文!
运行结果:
+---+----+
|sex|nums|
+---+----+
| 男| 4|
| 女| 6|
+---+----+SQL 函数
Spark SQL 提供了200多个函数供用户选择,涵盖了大部分的日常应用场景。此外,用户也可以自定义函数。
案例:
假设一张用户信息表中有 name、age、create_time 这3列数据,这里要求使用Spark的系统函数 from_unixtime(),将时间戳类型的 create_time 格式化成时间字符串,然后使用自定义的函数将用户名转为大写英文字母。
def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local").appName("spark func").getOrCreate()val schema: StructType = StructType(List(StructField("name", StringType, true),StructField("age", IntegerType, true),StructField("create_time", LongType, true)))val javaList:util.ArrayList[Row] = new util.ArrayList[Row]()javaList.add(Row("XiaoMei",24,System.currentTimeMillis()/1000))javaList.add(Row("XiaoShuai",23,System.currentTimeMillis()/1000))javaList.add(Row("XiaoLiu",21,System.currentTimeMillis()/1000))javaList.add(Row("XiaoMa",21,System.currentTimeMillis()/1000))val df = spark.createDataFrame(javaList, schema)df.show()df.createTempView("student")spark.sql("SELECT name,age,from_unixtime(create_time,'yyyy-MM-dd HH:mm:ss') FROM student").show()//注册一个新的用户自定义函数spark.udf.register("toUpperCaseUDF",(column:String)=>column.toUpperCase)//调用自定义函数spark.sql("SELECT toUpperCaseUDF(name) AS name,age,from_unixtime(create_time,'yyyy-MM-dd HH:mm:ss') AS create_time FROM student").show()spark.stop()}运行结果:
默认查询结果:
+---------+---+-----------+
| name|age|create_time|
+---------+---+-----------+
| XiaoMei| 24| 1694256797|
|XiaoShuai| 23| 1694256797|
| XiaoLiu| 21| 1694256797|
| XiaoMa| 21| 1694256797|
+---------+---+-----------+调用from_unixtime()函数:
+---------+---+-----------------------------------------------+
| name|age|from_unixtime(create_time, yyyy-MM-dd HH:mm:ss)|
+---------+---+-----------------------------------------------+
| XiaoMei| 24| 2023-09-09 18:53:17|
|XiaoShuai| 23| 2023-09-09 18:53:17|
| XiaoLiu| 21| 2023-09-09 18:53:17|
| XiaoMa| 21| 2023-09-09 18:53:17|
+---------+---+-----------------------------------------------+
使用自定义函数:
+---------+---+-------------------+
| name|age| create_time|
+---------+---+-------------------+
| XIAOMEI| 24|2023-09-09 18:53:17|
|XIAOSHUAI| 23|2023-09-09 18:53:17|
| XIAOLIU| 21|2023-09-09 18:53:17|
| XIAOMA| 21|2023-09-09 18:53:17|
+---------+---+-------------------+
总结
今天就写到这里,明天周日继续努力,今天我新开了章节-Spark SQL,我学习了Spark SQL中一个重要的抽象数据结构-DataFrame,学习了DataFrame的成绩以及保存,还有DataFrame的两张操作方式:DSL语句和SQL语句。
至于书上提到的 StructType、StructFeild 明天好好研究一下。
相关文章:
DataFrame的创建、保存与基本操作】)
Spark 【Spark SQL(一)DataFrame的创建、保存与基本操作】
前言 今天学习Spark SQL,前面的RDD编程要想熟练还是得通过项目来熟练,所以先把Spark过一遍,后期针对不足的地方再加强,这样效率会更高一些。 简介 在RDD编程中,我们使用的是SparkContext接口,接下来的Spar…...
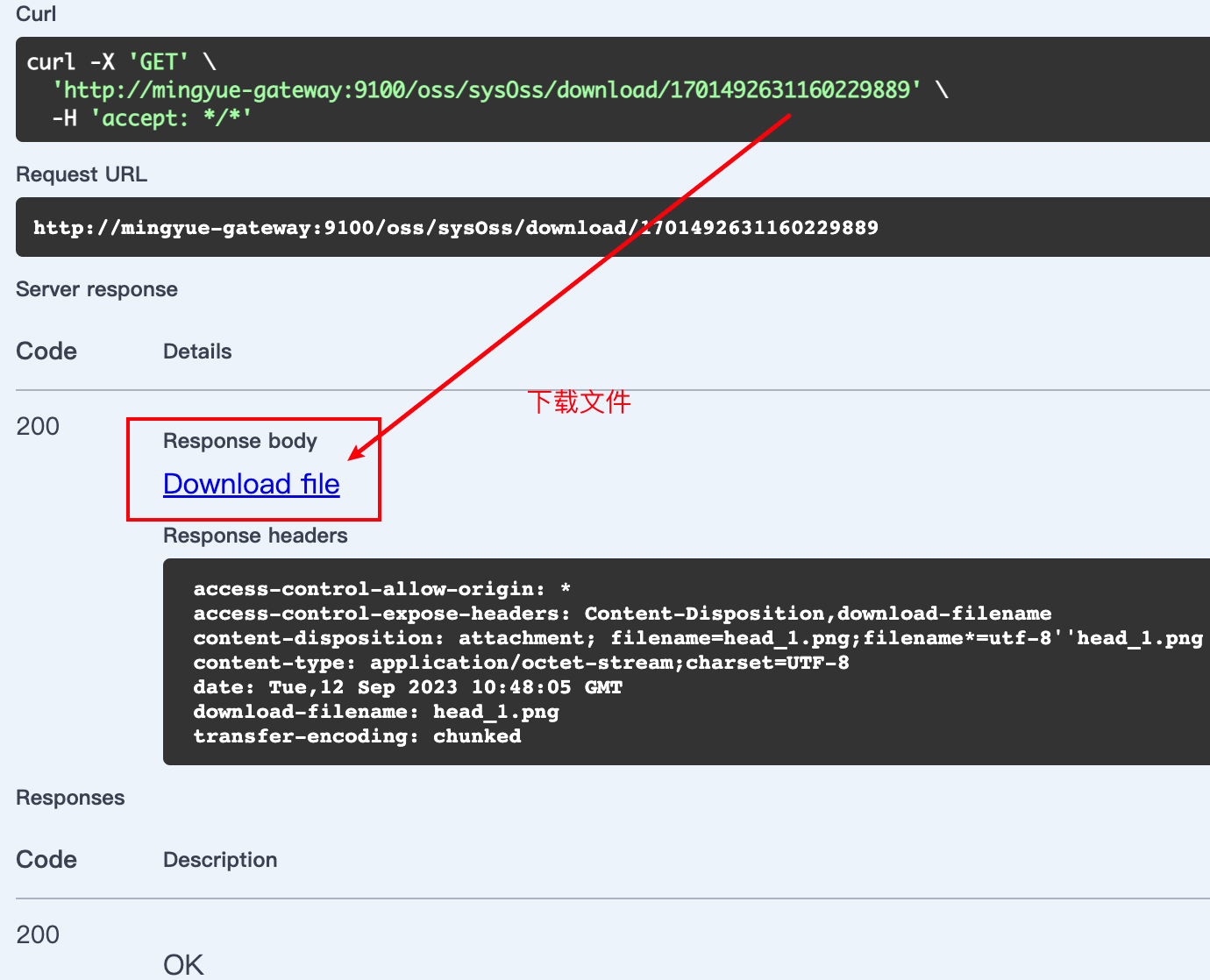
026-从零搭建微服务-文件服务(二)
写在最前 如果这个项目让你有所收获,记得 Star 关注哦,这对我是非常不错的鼓励与支持。 源码地址(后端):https://gitee.com/csps/mingyue 源码地址(前端):https://gitee.com/csps…...
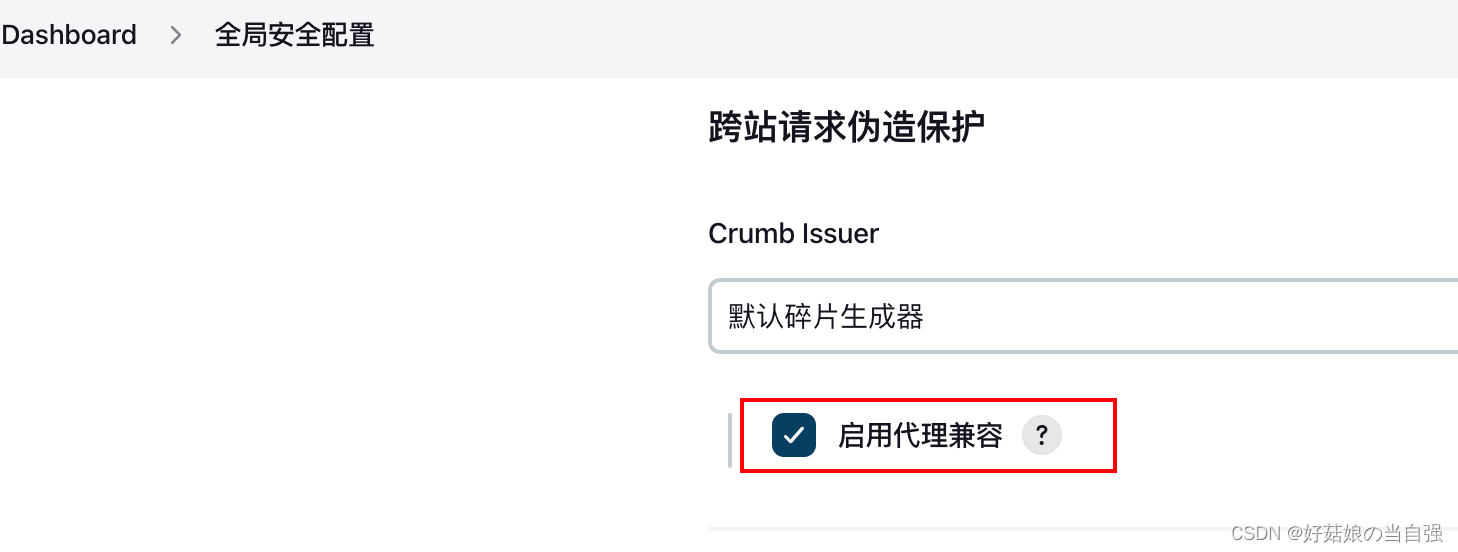
Jenkins 页面部分显示Http状态403 被禁止
前言 生产环境Jenkins部署了一段时间了,结果今天在流水线配置中,部分页面显示Jenkins 页面部分显示Http状态403 被禁止,修改配置点击保存之后偶尔也会出现这个。 问题 以下是问题图片 解决 在全局安全配置里面,勾选上启用代…...
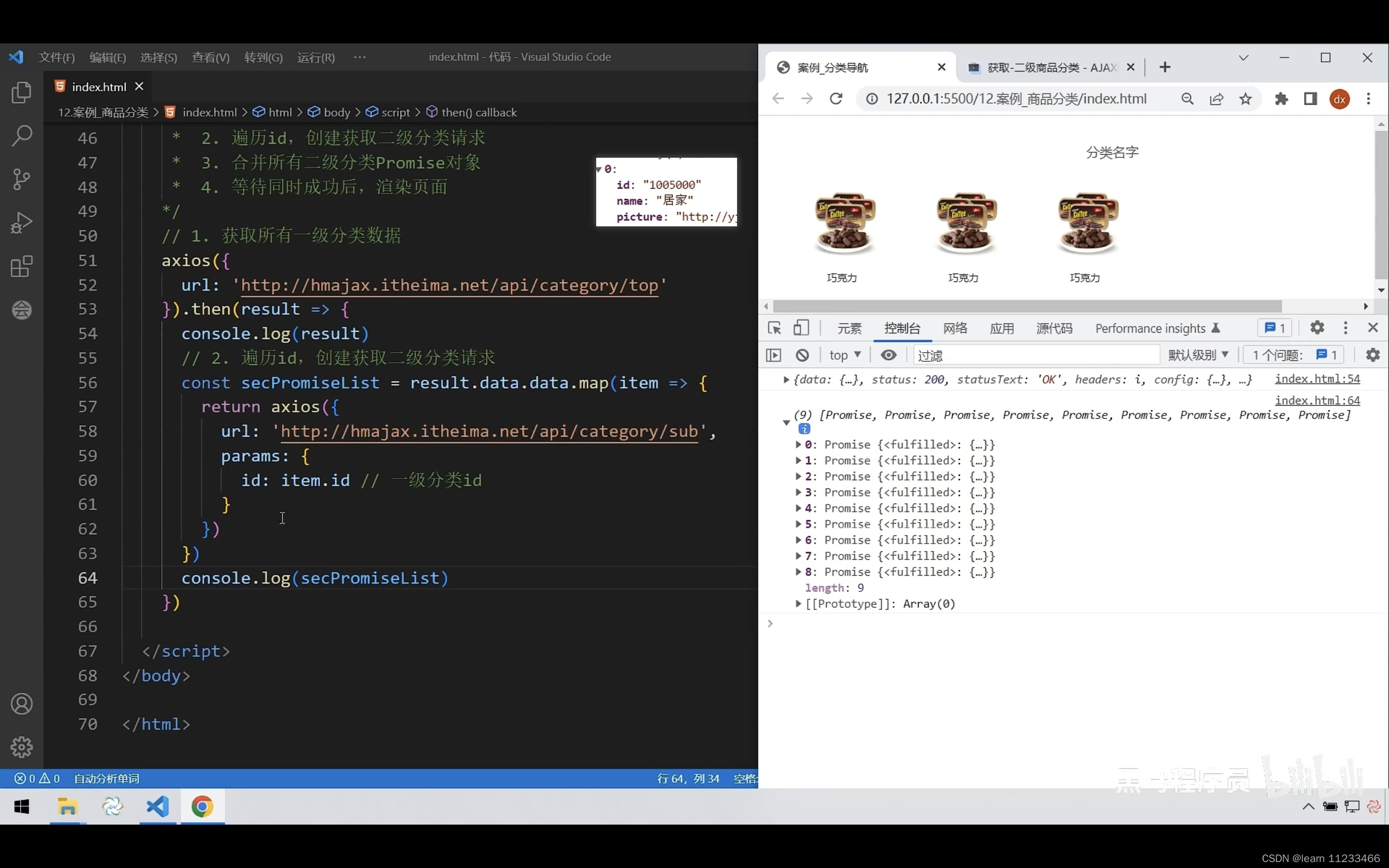
ajax day4
1、promise链式调用 /*** 目标:把回调函数嵌套代码,改成Promise链式调用结构* 需求:获取默认第一个省,第一个市,第一个地区并展示在下拉菜单中*/let pname axios({url: http://hmajax.itheima.net/api/province,}).t…...

8.Spring EL与ExpressionParser
Spring EL与ExpressionParser 文章目录 Spring EL与ExpressionParser介绍**使用SpEL来计算评估文字字符串表达式**使用SpEL来计算评估 bean 属性 – “item.name” 介绍 Spring表达式语言(SpEL)支持多种功能,并且可以测试这个特殊的“ExpressionParser”接口的表达…...

Go和Java实现迭代器模式
Go和Java实现迭代器模式 1、迭代器模式 迭代器模式是 Java 和 .Net 编程环境中非常常用的设计模式。这种模式用于顺序访问集合对象的元素,不需要知道 集合对象的底层表示。 迭代器模式属于行为型模式。 意图:提供一种方法顺序访问一个聚合对象中各个…...

如何在 Vue.js 和 Nuxt.js 之间做出选择?
开篇 今天看了一位国外大佬的文章,主要是他对在项目中如何选择 Vue.js 或 Nuxt.js 的看法,欢迎大家在评论区发表看法,以下内容是他关于这个问题看法的整理,由于翻译水平有限,欢迎大家指正。 国外大佬的看法 Vue.js在开…...

(二十三)大数据实战——Flume数据采集之采集数据聚合案例实战
前言 本节内容我们主要介绍一下Flume数据采集过程中,如何把多个数据采集点的数据聚合到一个地方供分析使用。我们使用hadoop101服务器采集nc数据,hadoop102采集文件数据,将hadoop101和hadoop102服务器采集的数据聚合到hadoop103服务器输出到…...

Linux: network: dhcp: mtu 这个里面也有关于网卡的MTU设置;
https://linux.die.net/man/5/dhcp-options 需注意这个DHCP配置选项。 option interface-mtu uint16; This option specifies the MTU to use on this interface. The minimum legal value for the MTU is 68. 假如在网卡的配置文件中设置了dhcp获取IP信息,可能导…...

Android中使用图片水印,并且能够在线下载字体并应用于水印
Android中使用图片水印,并且能够在线下载字体并应用于水印 要在Android中使用图片水印,并且能够在线下载字体并应用于水印,可以按照以下步骤进行: 1.使用Picasso、Glide或其他图片加载库加载图片: ImageView imageV…...

HTTP文件服务
在工作中,往往会需要将文件同时共享给很多台电脑。 本篇介绍HHDESK的HTTP文件服务功能,通过浏览器,将本地资源共享给任意主机。 1 共享文件 首页——资源管理——服务端——“”,在弹出框中选择HTTP文件服务。 填写各项内容。…...

nginx配置获取客户端的真实ip
场景描述: 访问路径: A机器 - > B机器的 ->C虚拟机 : A机器为客户端用户,本地地址为 192.168.0.110 B机器为服务端反向代理服务器 本地地址为192.168.0.128 –>(192.168.56.1) C机器为B主机安…...

1990-2022上市公司董监高学历工资特征信息数据/上市公司高管信息数据
1990-2022上市公司董监高学历工资特征信息数据/上市公司高管信息数据 1、时间:1990-2022年(统计截止日期为 2022年7月) 2、指标:证券代码、统计截止日期、姓名、国籍、籍贯、籍贯所在地区代码、出生地、出生地所在地区代码、性别…...

Java程序连接 Mysql 超时问题 - 数据包过大,导致超时,# 配置网络超时时间 socketTimeout: 1800000
问题 Java程序连接 Mysql 超时问题 解决方法 如果存在 yml 等类似的配置文件,那么可以配置一下 socket 连接超时的参数,例如 # 配置网络超时时间 半小时,计算公式 60秒*1000毫秒*30分钟 socketTimeout: 1800000...
acwing版)
c++分层最短路(洛谷飞行路线)acwing版
分层最短路算法是在SPFA算法的基础上,将每个点分成若干层,从而使得每个点之间的转移只在同一层次或上下两个相邻层次之间进行,减少了每轮的迭代次数,优化了算法的效率。 #include <iostream> #include <cstdio> #inc…...

Python bs4 BeautifulSoup库使用记录
目录 介绍 安装 初始化 解析器 使用方法 优势 Python标准库 lxml HTML lxml XML html5lib 格式化输出 对象 tag Name 多值属性 其他方法 NavigableString BeautifulSoup Comment 遍历 子节点 父节点 兄弟节点 回退和前进 搜索 过滤器 字符串 正则表达…...
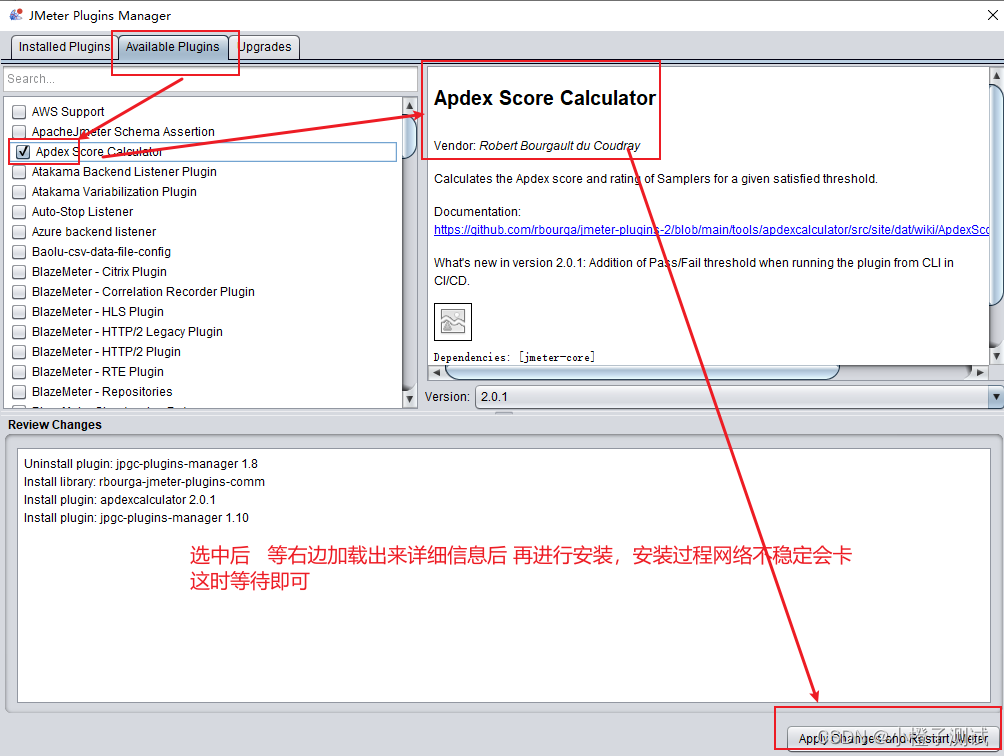
Jmeter系列-插件安装(5)
前言 jmeter4.0以上,如现在最新的5.2.1版本是有集成插件的只需要在官网下载 plugins-manager.jar 包,放在jmeter安装路径的lib/ext目录下即可使用:https://jmeter-plugins.org/install/Install/但并不能满足所有需求,仍然需要安装…...

spring aop源码解析
spring知识回顾 spring的两个重要功能:IOC、AOP,在ioc容器的初始化过程中,会触发2种处理器的调用, 前置处理器(BeanFactoryPostProcessor)后置处理器(BeanPostProcessor)。 前置处理器的调用时机是在容器基本创建完成时ÿ…...
控制物体移动、旋转)
使用Unity的Input.GetAxis(““)控制物体移动、旋转
使用Unity的Input.GetAxis("")控制物体移动、旋转 Input.GetAxis("") 是 Unity 引擎中的一个方法,用于获取游戏玩家在键盘或游戏手柄上输入的某个轴(Axis)的值。这里的 "" 是一个字符串参数,表示要…...

【CSS】画个三角形或圆形或环
首先通过调整边框,我们可以发现一些端倪 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><style>.box{width: 150px;height:150px;border: 50px solid black;}</style&g…...

[STM32U3] 【每周分享】【STM32U385RG 测评】+调试串口通讯,字符串打印
接着上一回,这会进行串口打印实验 一、查询原理图,找到我们需要配置的串口 如上图:PA9、PA10、USART1 二、按流程打开IDE软件,建立新的工程文件。 配置如下:debug、RCC、USART1 配置完成后就可以生成代码了 三、代…...

Anno 1800模组加载器:3分钟解锁游戏无限可能的终极指南
Anno 1800模组加载器:3分钟解锁游戏无限可能的终极指南 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com/gh_mirrors/an…...

PX4倾转垂起固定翼混控配置与硬件适配实战
1. PX4倾转垂起固定翼的核心概念解析 第一次接触倾转垂起固定翼的朋友可能会被这个名词吓到,其实它的原理并不复杂。简单来说,这是一种既能像多旋翼一样垂直起降,又能像固定翼飞机一样高效巡航的混合飞行器。我经手过的项目中,这种…...

从零上手CircuitJS1:开源电路仿真工具的核心功能与实战演练
1. 初识CircuitJS1:浏览器里的电子实验室 第一次打开CircuitJS1时,我仿佛回到了大学电子实验室——只不过这次所有仪器都装进了浏览器窗口。这个完全开源的工具用JavaScript重构了经典的Falstad电路模拟器,不需要安装任何插件就能在Chrome或…...

卡尔曼滤波中的‘信任度’分配:从高斯分布乘积公式看估计与观测谁更重要
卡尔曼滤波中的‘信任度’分配:从高斯分布乘积公式看估计与观测谁更重要 在机器人定位或金融时间序列预测中,我们常常面临一个核心问题:当预测值和观测值都存在不确定性时,如何决定更信任哪一个?这不仅仅是数学问题&a…...
)
别再瞎调了!OpenCV手动曝光参数CAP_PROP_EXPOSURE与快门时间换算表(附Python/C++代码)
OpenCV曝光参数与快门时间实战指南:从原理到精准控制 在计算机视觉项目中,摄像头曝光控制往往是影响图像质量的关键因素之一。许多开发者在使用OpenCV的CAP_PROP_EXPOSURE参数时,都会遇到一个共同的困惑:为什么设置的值是-13而不…...

auto-rednote:自动化信息整理工具的设计原理与实战应用
1. 项目概述与核心价值 最近在整理个人笔记和知识库时,我遇到了一个几乎所有内容创作者和开发者都会头疼的问题:如何高效地将散落在各处的、格式不一的“红色笔记”(比如微信收藏、网页剪藏、临时备忘录)自动整理成结构化的、可检…...

QSplitter实战:打造可动态调整的专业级应用界面
1. QSplitter:让界面布局活起来的魔法棒 第一次用QSplitter的时候,我正被一个IDE项目的界面布局折磨得焦头烂额。左侧导航栏、中间代码区、右侧属性面板,这三个区域就像三个固执的老头,死活不肯按照用户期望的比例显示。直到发现Q…...

HS2-HF_Patch:让Honey Select 2体验全面升级的智能补丁
HS2-HF_Patch:让Honey Select 2体验全面升级的智能补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾经因为语言障碍而无法完全享受Honey…...

Raycast扩展vscode-control:用全局启动器遥控VS Code提升开发效率
1. 项目概述:一个为Raycast打造的VS Code遥控器 如果你和我一样,每天大部分时间都泡在代码编辑器里,那么你一定对频繁在编辑器、终端、浏览器和启动器之间切换感到厌烦。尤其是当你需要快速执行一个格式化操作、运行一个NPM脚本,…...