(二十三)大数据实战——Flume数据采集之采集数据聚合案例实战
前言
本节内容我们主要介绍一下Flume数据采集过程中,如何把多个数据采集点的数据聚合到一个地方供分析使用。我们使用hadoop101服务器采集nc数据,hadoop102采集文件数据,将hadoop101和hadoop102服务器采集的数据聚合到hadoop103服务器输出到控制台。其整体架构如下:
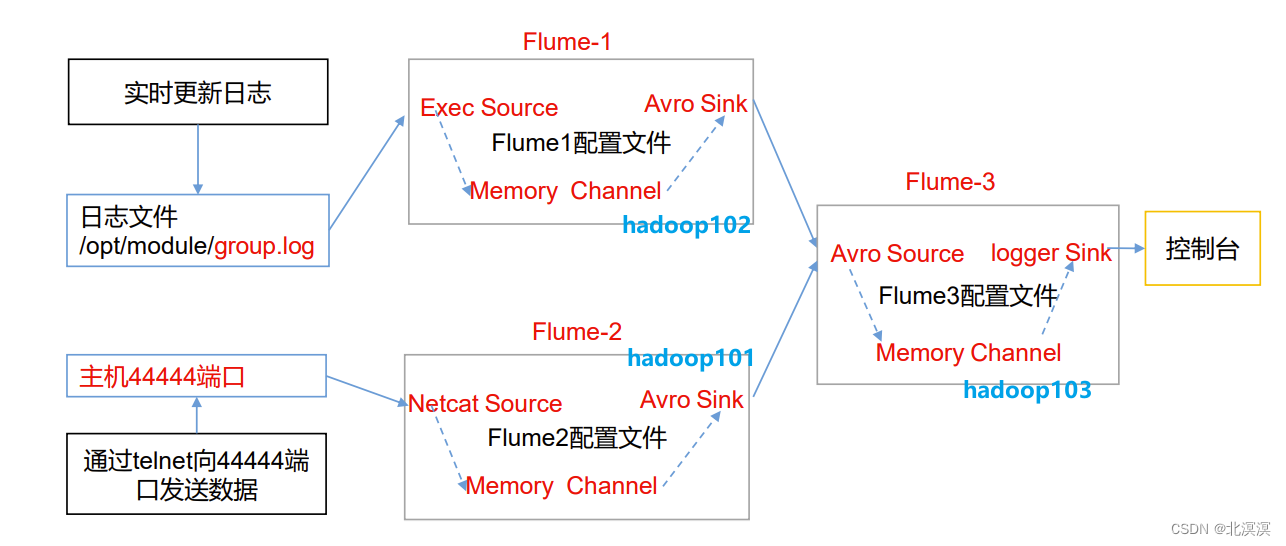
正文
①在hadoop101服务器的/opt/module/apache-flume-1.9.0/job/group1目录下创建job-nc-flume-avro.conf配置文件,用于监控nc发送的数据,通过avro sink传输到avro source
- job-nc-flume-avro.conf配置文件
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/apache-flume-1.9.0/a.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop103 a1.sinks.k1.port = 4141 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1

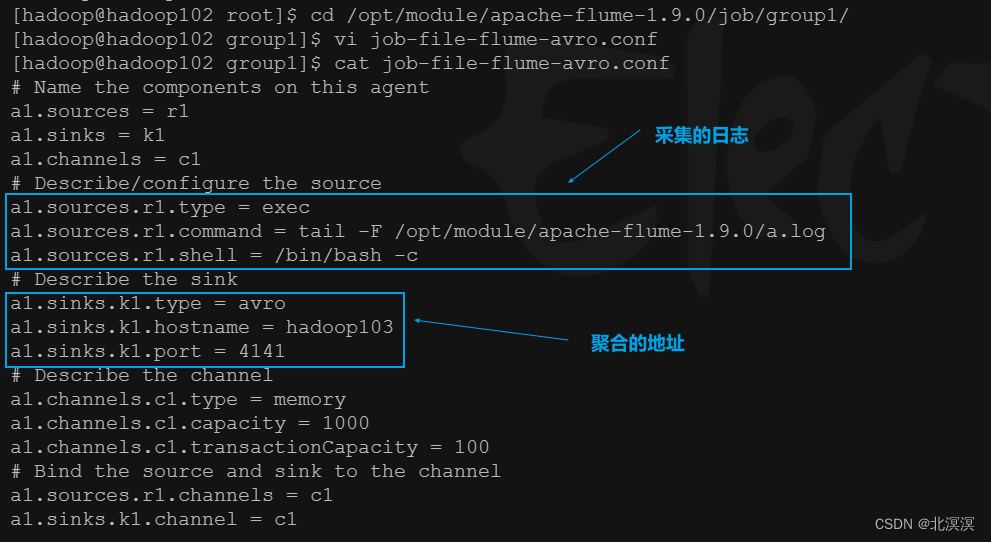
②在hadoop102服务器的/opt/module/apache-flume-1.9.0/job/group1目录下创建job-file-flume-avro.conf配置文件,用于监控目录/opt/module/apache-flume-1.9.0/a.log的数据,通过avro sink传输到avro source
- job-file-flume-avro.conf配置文件
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/apache-flume-1.9.0/a.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop103 a1.sinks.k1.port = 4141 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
③在hadoop103服务器的/opt/module/apache-flume-1.9.0/job/group1目录下创建job-avro-flume-console.conf配置文件,用户将avro source聚合的数据输出到控制台
- job-avro-flume-console.conf配置文件
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro a1.sources.r1.bind = hadoop103 a1.sources.r1.port = 4141 # Describe the sink # Describe the sink a1.sinks.k1.type = logger # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1

④ 在hadoop103启动job-avro-flume-console.conf任务
- 命令:
bin/flume-ng agent -c conf/ -n a1 -f job/group1/job-avro-flume-console.conf -Dflume.root.logger=INFO,console

⑤在hadoop101启动job-nc-flume-avro.conf任务
- 命令:
bin/flume-ng agent -c conf/ -n a1 -f job/group1/job-nc-flume-avro.conf -Dflume.root.logger=INFO,console

⑥在hadoop102启动job-file-flume-avro.conf任务
- 命令:
bin/flume-ng agent -c conf/ -n a1 -f job/group1/job-file-flume-avro.conf -Dflume.root.logger=INFO,console

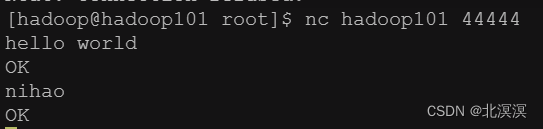
⑦使用nc工具向hadoop101发送数据
- nc发送数据
- hadoop103接收到数据

⑧在hadoop102的a.log中写入数据
- 写入数据
- hadoop103接收到数据
结语
flume数据聚合就是为了将具有相同属性的数据聚合到一起,便于管理、分析、统计等。至此,关于Flume数据采集之采集数据聚合案例实战到这里就结束了,我们下期见。。。。。。
相关文章:

(二十三)大数据实战——Flume数据采集之采集数据聚合案例实战
前言 本节内容我们主要介绍一下Flume数据采集过程中,如何把多个数据采集点的数据聚合到一个地方供分析使用。我们使用hadoop101服务器采集nc数据,hadoop102采集文件数据,将hadoop101和hadoop102服务器采集的数据聚合到hadoop103服务器输出到…...

Linux: network: dhcp: mtu 这个里面也有关于网卡的MTU设置;
https://linux.die.net/man/5/dhcp-options 需注意这个DHCP配置选项。 option interface-mtu uint16; This option specifies the MTU to use on this interface. The minimum legal value for the MTU is 68. 假如在网卡的配置文件中设置了dhcp获取IP信息,可能导…...

Android中使用图片水印,并且能够在线下载字体并应用于水印
Android中使用图片水印,并且能够在线下载字体并应用于水印 要在Android中使用图片水印,并且能够在线下载字体并应用于水印,可以按照以下步骤进行: 1.使用Picasso、Glide或其他图片加载库加载图片: ImageView imageV…...

HTTP文件服务
在工作中,往往会需要将文件同时共享给很多台电脑。 本篇介绍HHDESK的HTTP文件服务功能,通过浏览器,将本地资源共享给任意主机。 1 共享文件 首页——资源管理——服务端——“”,在弹出框中选择HTTP文件服务。 填写各项内容。…...

nginx配置获取客户端的真实ip
场景描述: 访问路径: A机器 - > B机器的 ->C虚拟机 : A机器为客户端用户,本地地址为 192.168.0.110 B机器为服务端反向代理服务器 本地地址为192.168.0.128 –>(192.168.56.1) C机器为B主机安…...

1990-2022上市公司董监高学历工资特征信息数据/上市公司高管信息数据
1990-2022上市公司董监高学历工资特征信息数据/上市公司高管信息数据 1、时间:1990-2022年(统计截止日期为 2022年7月) 2、指标:证券代码、统计截止日期、姓名、国籍、籍贯、籍贯所在地区代码、出生地、出生地所在地区代码、性别…...

Java程序连接 Mysql 超时问题 - 数据包过大,导致超时,# 配置网络超时时间 socketTimeout: 1800000
问题 Java程序连接 Mysql 超时问题 解决方法 如果存在 yml 等类似的配置文件,那么可以配置一下 socket 连接超时的参数,例如 # 配置网络超时时间 半小时,计算公式 60秒*1000毫秒*30分钟 socketTimeout: 1800000...
acwing版)
c++分层最短路(洛谷飞行路线)acwing版
分层最短路算法是在SPFA算法的基础上,将每个点分成若干层,从而使得每个点之间的转移只在同一层次或上下两个相邻层次之间进行,减少了每轮的迭代次数,优化了算法的效率。 #include <iostream> #include <cstdio> #inc…...

Python bs4 BeautifulSoup库使用记录
目录 介绍 安装 初始化 解析器 使用方法 优势 Python标准库 lxml HTML lxml XML html5lib 格式化输出 对象 tag Name 多值属性 其他方法 NavigableString BeautifulSoup Comment 遍历 子节点 父节点 兄弟节点 回退和前进 搜索 过滤器 字符串 正则表达…...
Jmeter系列-插件安装(5)
前言 jmeter4.0以上,如现在最新的5.2.1版本是有集成插件的只需要在官网下载 plugins-manager.jar 包,放在jmeter安装路径的lib/ext目录下即可使用:https://jmeter-plugins.org/install/Install/但并不能满足所有需求,仍然需要安装…...

spring aop源码解析
spring知识回顾 spring的两个重要功能:IOC、AOP,在ioc容器的初始化过程中,会触发2种处理器的调用, 前置处理器(BeanFactoryPostProcessor)后置处理器(BeanPostProcessor)。 前置处理器的调用时机是在容器基本创建完成时ÿ…...
控制物体移动、旋转)
使用Unity的Input.GetAxis(““)控制物体移动、旋转
使用Unity的Input.GetAxis("")控制物体移动、旋转 Input.GetAxis("") 是 Unity 引擎中的一个方法,用于获取游戏玩家在键盘或游戏手柄上输入的某个轴(Axis)的值。这里的 "" 是一个字符串参数,表示要…...

【CSS】画个三角形或圆形或环
首先通过调整边框,我们可以发现一些端倪 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><style>.box{width: 150px;height:150px;border: 50px solid black;}</style&g…...

AI项目六:基于YOLOV5的CPU版本部署openvino
若该文为原创文章,转载请注明原文出处。 一、CPU版本DEMO测试 1、创建一个新的虚拟环境 conda create -n course_torch_openvino python3.8 2、激活环境 conda activate course_torch_openvino 3、安装pytorch cpu版本 pip install torch torchvision torchau…...

记录YDLidar驱动包交叉编译时出现的一点问题
由于一不小心把交叉编译的系统根目录破坏了,所以一股脑将交叉编译系统根目录全删了重新安装,安装后,交叉编译发现ydlidar的ros包驱动出现了库无法链接的错误(刚刚还是好好的),但是又想不起来之前是怎么解决的了,所以还…...

嵌入式学习笔记(32)S5PV210的向量中断控制器
6.6.1异常处理的2个阶段 可以将异常处理分为2个阶段来理解。第一个阶段是异常向量表跳转;第二个阶段是进入了真正的异常处理程序irq_handler之后的部分。 6.6.2回顾:中断处理的第一个阶段(异常向量表跳转阶段)处理 (…...

linux下安装qt、qt触摸屏校准tslib
linux下安装qt 在 Linux 系统下安装 Qt,可以通过以下步骤进行操作:1. 下载 Qt 安装包:首先,你需要从 Qt 官方网站(https://www.qt.io/)下载适用于 Linux 的 Qt 安装包。选择与你的系统和需求相匹配的版本&…...

C++之unordered_map,unordered_set模拟实现
unordered_map,unordered_set模拟实现 哈希表源代码哈希表模板参数的控制仿函数增加正向迭代器实现*运算符重载->运算符重载运算符重载! 和 运算符重载begin()与end()实现 unordered_set实现unordered_map实现map/set 与 unordered_map/unordered_set对比哈希表…...

React Router,常用API有哪些?
react-router React Router是一个用于构建单页面应用程序(SPA)的库,它是用于管理React应用中页面导航和路由的工具。SPA是一种Web应用程序类型,它在加载初始页面后,通过JavaScript来动态加载并更新页面内容࿰…...

JVM类加载和双亲委派机制
当我们用java命令运行某个类的main函数启动程序时,首先需要通过类加载器把类加载到JVM,本文主要说明类加载机制和其具体实现双亲委派模式。 一、类加载机制 类加载过程: 类加载的过程是将类的字节码加载到内存中的过程,主要包括…...

网络安全新态势与应对策略
网络安全新态势与应对策略 在数字化浪潮席卷全球的今天,网络空间已成为国家竞争的新战场、经济发展的新引擎和社会生活的新空间。然而,伴随技术飞速发展的,是日益严峻和复杂的网络安全挑战。传统的边界防御模式在AI驱动的自动化攻击、无孔不…...

3PEAK思瑞浦 TPA1811-S5TR SOT23-5 精密运放
特性 供电电压:4伏至30伏 低功耗:在25C时为55A(典型值) 低偏置电压:8V在25C(最大值) 零漂:0.01V/C 轨到轨输出 增益带宽积:500kHz 斜率:0.3V/us...

环境配置与基础教程:保姆级教程:在 Mac M 芯片上利用 MPS 加速 YOLO 训练与推理的完整环境搭建
写在前面:为什么你的 Mac 也能跑深度学习? 几年前,如果有人告诉你用 MacBook 训练深度学习模型,你大概会笑出声。那时候 Mac 上的 PyTorch 只能依赖 CPU 吭哧吭哧地算,训练一个小模型都要等到天荒地老。但自从 Apple Silicon 芯片(M1、M2、M3、M4,以及最新的 M5)横空出…...

别再只会用StegSolve了!深入理解LSB隐写原理,手写Python脚本提取隐藏信息
从像素到秘密:手写Python脚本破解LSB隐写的核心技术 当你面对一张看似普通的图片,是否曾想过它可能隐藏着重要信息?在CTF竞赛和数字取证领域,LSB(最低有效位)隐写术是最基础却最常被忽视的技术之一。大多数…...
)
从Figma到Midjourney的极简工作流革命:1套可复用的“视觉降噪SOP”(含内部团队验证版Checklist)
更多请点击: https://intelliparadigm.com 第一章:从Figma到Midjourney的极简工作流革命 设计师不再需要在多个平台间反复导出、重命名、上传——一个轻量级自动化桥接层,即可将 Figma 的视觉输出精准转化为 Midjourney 的提示工程输入。核心…...

从 SU01 到 SAP HANA,DBMS 用户管理里的 SSO 选项到底在管什么
项目里讨论 SSO 时,大家很容易把它想成一个单点登录按钮,好像在某处勾选一下,用户就能从 SAP GUI、Fiori、报表工具一路无感访问到数据库。到了 SAP NetWeaver AS 和 SAP HANA 组合的系统里,这个理解会带来不少误会。因为从 ABAP 侧维护 DBMS 用户的 SSO 选项,只是在用户主…...

Android端ChatGPT应用开发:MVVM架构、流式响应与性能优化实践
1. 项目概述:一个能“随身携带”的ChatGPT最近在折腾Android开发,特别是想把手头的一些AI能力集成到移动端应用里。我发现了一个挺有意思的开源项目,叫“AnywhereGPT-Android”。光看名字就挺吸引人——“Anywhere GPT”,顾名思义…...

告别繁琐操作:用League Akari重新定义英雄联盟游戏体验
告别繁琐操作:用League Akari重新定义英雄联盟游戏体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在紧张的英雄选择阶…...

day15 C语言 指针3
13.字符指针的常见错误#include<stdio.h>#if 0int main(int argc, char **argv){//char *p"hello"; //error,会发生段错误 hello在内存中只有一份,只能读取不能修改char p[]"hello"; //char [] 开辟空间,会把hello复制一份给…...

基于MCP协议的TikTok趋势数据获取与AI助手集成实战
1. 项目概述与核心价值 最近在折腾AI应用开发,特别是想让AI助手能实时获取和分析社交媒体上的热点趋势,TikTok自然成了绕不开的数据金矿。但直接让AI去爬取和分析TikTok内容,不仅技术门槛高,还容易踩到各种合规和反爬的坑。直到我…...