org.apache.flink.table.api.TableException: Sink does not exists
FlinkSQL_1.12_用DDL实现Kafka到MySQL的数据传输_实现按照条件进行过滤写入MySQL_flink从kafka拉取数据并过滤数据写入mysql_旧城里的阳光的博客-CSDN博客
参考这篇文章,写了kafka到mysql的代码例子,因为自己改了表结构,运行下面代码:
package org.test.flink;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;//TODO 用DDL实现Kafka到MySQL的数据传输
public class FlinkSQL15_SQL_DDL_Kafka_MySQL {public static void main(String[] args) throws Exception {//1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);//2.使用DDL的方式加载数据--注册SourceTabletableEnv.executeSql("create table source_sensor(account_id BIGINT)" +"with (" +"'connector.type' = 'kafka'," +"'connector.version' = 'universal'," +"'connector.topic' = 'testtopic'," +"'connector.properties.bootstrap.servers' = '11.0.24.216:9092'," +"'connector.properties.group.id' = 'bigdata1109'," +"'format.type' = 'json'"+ ")");Table table = tableEnv.sqlQuery("select * from source_sensor");//3.注册SinkTable:MysqltableEnv.executeSql("CREATE TABLE spend_report (\n" +" account_id BIGINT,\n" +" PRIMARY KEY (account_id) NOT ENFORCED)" +"with (" +"'connector' = 'jdbc'," +"'url' = 'jdbc:mysql://11.0.24.216:4306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false',"+"'table-name' = 'spend_report',"+"'username' = 'root',"+"'password' = '123456'"+ ")");//4.执行查询kafka数据
// Table source_sensor = tableEnv.from("source_sensor");
// //5.将数据写入Mysql
// source_sensor.executeInsert("sink_sensor");
//table.executeInsert("sink_sensor");//6.执行任务env.execute();}
}发现报错如下:
Exception in thread "main" org.apache.flink.table.api.TableException: Sink `default_catalog`.`default_database`.`sink_sensor` does not existsat org.apache.flink.table.planner.delegation.PlannerBase.translateToRel(PlannerBase.scala:247)at org.apache.flink.table.planner.delegation.PlannerBase.$anonfun$translate$1(PlannerBase.scala:159)at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)at scala.collection.Iterator.foreach(Iterator.scala:943)at scala.collection.Iterator.foreach$(Iterator.scala:943)at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)at scala.collection.IterableLike.foreach(IterableLike.scala:74)at scala.collection.IterableLike.foreach$(IterableLike.scala:73)at scala.collection.AbstractIterable.foreach(Iterable.scala:56)at scala.collection.TraversableLike.map(TraversableLike.scala:286)at scala.collection.TraversableLike.map$(TraversableLike.scala:279)at scala.collection.AbstractTraversable.map(Traversable.scala:108)at org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:159)at org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:1329)at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:676)at org.apache.flink.table.api.internal.TableImpl.executeInsert(TableImpl.java:572)at org.apache.flink.table.api.internal.TableImpl.executeInsert(TableImpl.java:554)at org.test.flink.FlinkSQL15_SQL_DDL_Kafka_MySQL.main(FlinkSQL15_SQL_DDL_Kafka_MySQL.java:50)点击table.executeInsert看了下源码:
/*** Writes the {@link Table} to a {@link TableSink} that was registered under the specified path,* and then execute the insert operation.** <p>See the documentation of {@link TableEnvironment#useDatabase(String)} or {@link* TableEnvironment#useCatalog(String)} for the rules on the path resolution.** <p>A batch {@link Table} can only be written to a {@code* org.apache.flink.table.sinks.BatchTableSink}, a streaming {@link Table} requires a {@code* org.apache.flink.table.sinks.AppendStreamTableSink}, a {@code* org.apache.flink.table.sinks.RetractStreamTableSink}, or an {@code* org.apache.flink.table.sinks.UpsertStreamTableSink}.** <p>Example:** <pre>{@code* Table table = tableEnv.fromQuery("select * from MyTable");* TableResult tableResult = table.executeInsert("MySink");* tableResult...* }</pre>** @param tablePath The path of the registered TableSink to which the Table is written.* @return The insert operation execution result.*/TableResult executeInsert(String tablePath);发现executeInsert方法的参数tablePath需要传入表名,这里的表名应该和
tableEnv.executeSql("create table source_sensor(account_id BIGINT)"的表名source_sensor一致。
将:
table.executeInsert("sink_sensor");改成:
table.executeInsert("source_sensor");后执行成功。
flink1.2的demo完整代码:flink-java-1.12.7: flink1.12.7的java demo,包括flink wordcount示例,如何连接kafka
相关文章:

org.apache.flink.table.api.TableException: Sink does not exists
FlinkSQL_1.12_用DDL实现Kafka到MySQL的数据传输_实现按照条件进行过滤写入MySQL_flink从kafka拉取数据并过滤数据写入mysql_旧城里的阳光的博客-CSDN博客 参考这篇文章,写了kafka到mysql的代码例子,因为自己改了表结构,运行下面代码&#x…...
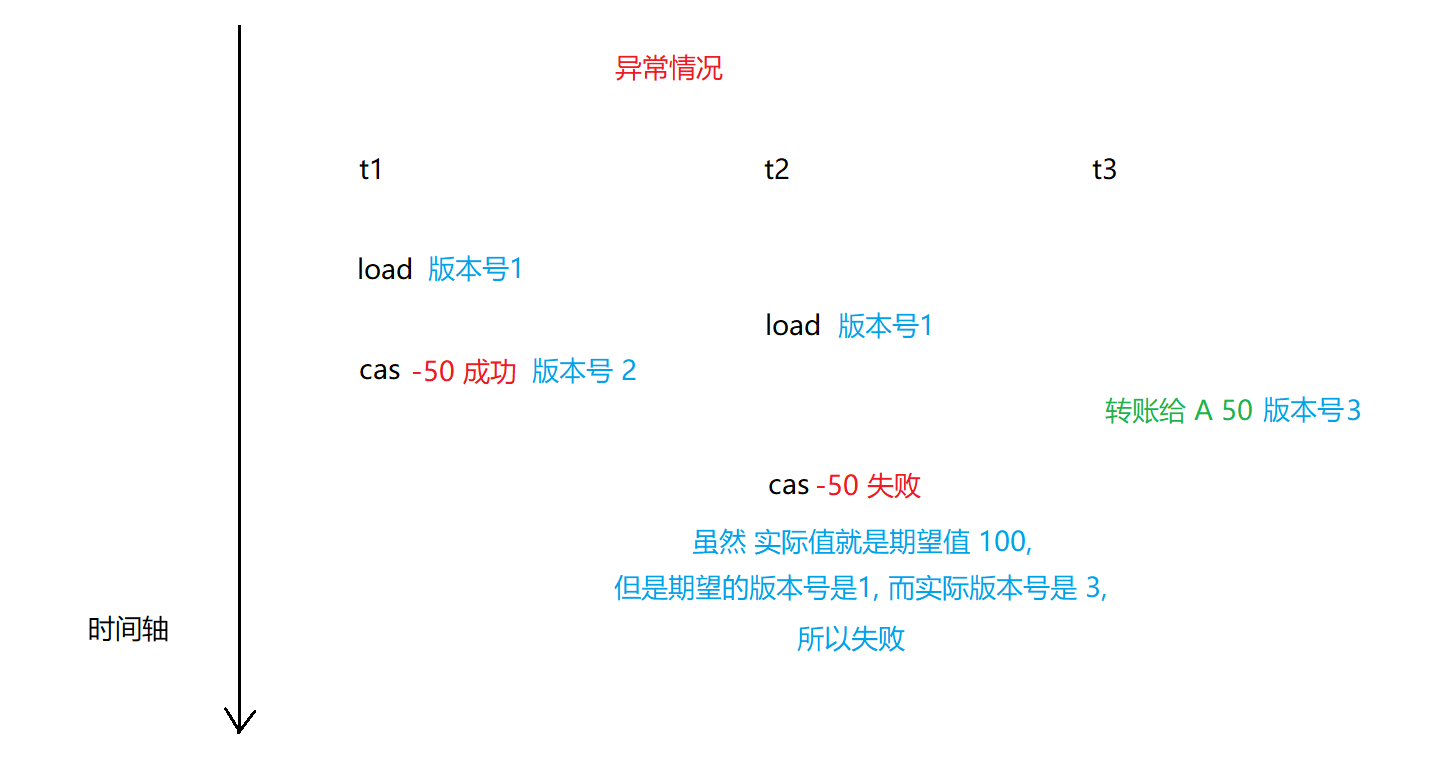
【多线程】CAS 详解
CAS 详解 一. 什么是 CAS二. CAS 的应用1. 实现原子类2. 实现自旋锁 三. CAS 的 ABA 问题四. 相关面试题 一. 什么是 CAS CAS: 全称Compare and swap,字面意思:”比较并交换“一个 CAS 涉及到以下操作: 我们假设内存中的原数据 V,旧的预期值…...

卷积神经网络实现咖啡豆分类 - P7
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制🚀 文章来源:K同学的学习圈子 目录 环境步骤环境设置包引用全局设备对象 数据准备查看图像的信息制作数据集 模型设…...

C++之默认与自定义构造函数问题(二百一十七)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
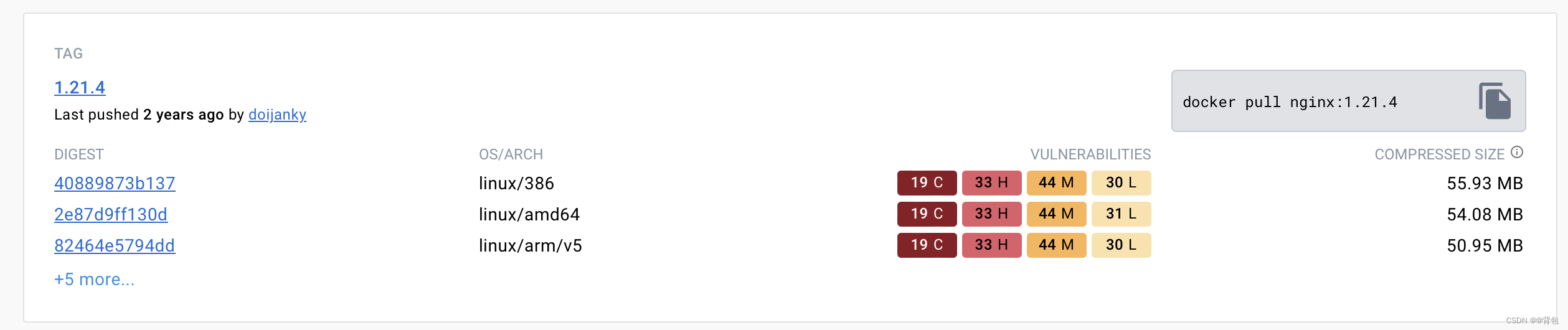
Docker从认识到实践再到底层原理(五)|Docker镜像
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总 然后就是博主最近最花时间的一个专栏…...

【Flowable】任务监听器(五)
前言 之前有需要使用到Flowable,鉴于网上的资料不是很多也不是很全也是捣鼓了半天,因此争取能在这里简单分享一下经验,帮助有需要的朋友,也非常欢迎大家指出不足的地方。 一、监听器 在Flowable中,我们可以使用监听…...

spring-kafka中ContainerProperties.AckMode详解
近期,我们线上遇到了一个性能问题,几乎快引起线上故障,后来仅仅是修改了一行代码,性能就提升了几十倍。一行代码几十倍,数据听起来很夸张,不过这是真实的数据,线上错误的配置的确有可能导致性能…...
)
【rpc】Dubbo和Zookeeper结合使用,它们的作用与联系(通俗易懂,一文理解)
目录 Dubbo是什么? 把系统模块变成分布式,有哪些好处,本来能在一台机子上运行,为什么还要远程调用 Zookeeper是什么? 它们进行配合使用时,之间的关系 服务注册 服务发现 动态地址管理 Dubbo是…...

ChatGPT的未来
随着人工智能的快速发展,ChatGPT作为一种自然语言生成模型,在各个领域都展现出了巨大的潜力。它不仅可以用于日常对话、创意助手和知识查询,还可以应用于教育、医疗、商业等各个领域,为人们带来更多便利和创新。 在教育领域&#…...

Pytorch模型转ONNX部署
开始以为会很困难,但是其实非常方便,下边分两步走:1. pytorch模型转onnx;2. 使用onnx进行inference 0. 准备工作 0.1 安装onnx 安装onnx和onnxruntime,onnx貌似是个环境。。倒是没有直接使用,onnxruntim…...

k8s优雅停服
在应用程序的整个生命周期中,正在运行的 pod 会由于多种原因而终止。在某些情况下,Kubernetes 会因用户输入(例如更新或删除 Deployment 时)而终止 pod。在其他情况下,Kubernetes 需要释放给定节点上的资源时会终止 po…...

面试题五:computed的使用
题记 大部分的工作中使用computed的频次很低的,所以今天拿出来一文对于computed进行详细的介绍,因为Vue的灵魂之一就是computed。 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护…...
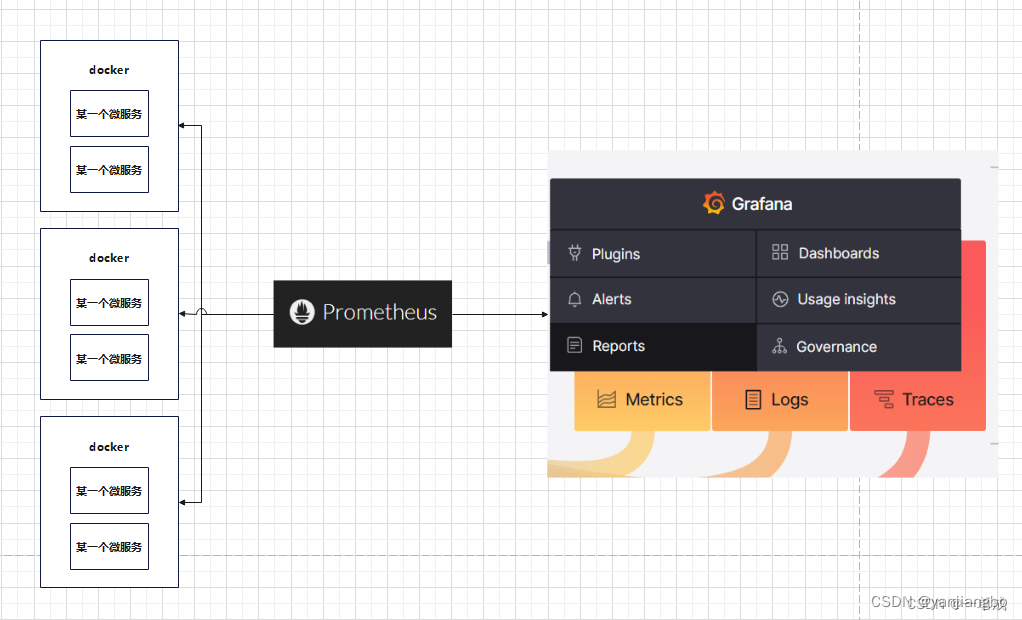
完美的分布式监控系统 Prometheus与优雅的开源可视化平台 Grafana
1、之间的关系 prometheus与grafana之间是相辅相成的关系。简而言之Grafana作为可视化的平台,平台的数据从Prometheus中取到来进行仪表盘的展示。而Prometheus这源源不断的给Grafana提供数据的支持。 Prometheus是一个开源的系统监控和报警系统,能够监…...
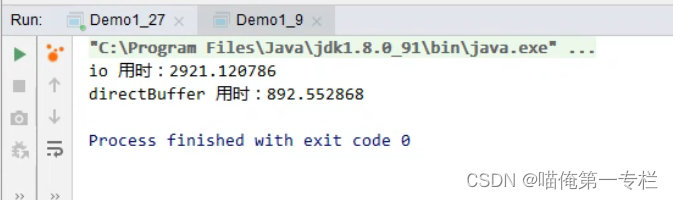
黑马JVM总结(九)
(1)StringTable_调优1 我们知道StringTable底层是一个哈希表,哈希表的性能是跟它的大小相关的,如果哈希表这个桶的个数比较多,元素相对分散,哈希碰撞的几率就会减少,查找的速度较快,…...

如何使用 RunwayML 进行创意 AI 创作
标题:如何使用 RunwayML 进行创意 AI 创作 介绍 RunwayML 是一个基于浏览器的人工智能创作工具,可让用户使用各种 AI 功能来生成图像、视频、音乐、文字和其他创意内容。RunwayML 的功能包括: * 图像生成:使用生成式对抗网络 (…...

【css】能被4整除 css :class,判断一个数能否被另外一个数整除,余数
判断一个数能否被另外一个数整除 一个数能被4整除的表达式可以表示为:num%40,其中,num为待判断的数,% 为取模运算符,为等于运算符。这个表达式的意思是,如果num除以4的余数为0,则返回true&…...

ChatGPT与日本首相交流核废水事件-精准Prompt...
了解更多请点击:ChatGPT与日本首相交流核废水事件-精准Prompt...https://mp.weixin.qq.com/s?__bizMzg2NDY3NjY5NA&mid2247490070&idx1&snebdc608acd419bb3e71ca46acee04890&chksmce64e42ff9136d39743d16059e2c9509cc799a7b15e8f4d4f71caa25968554…...
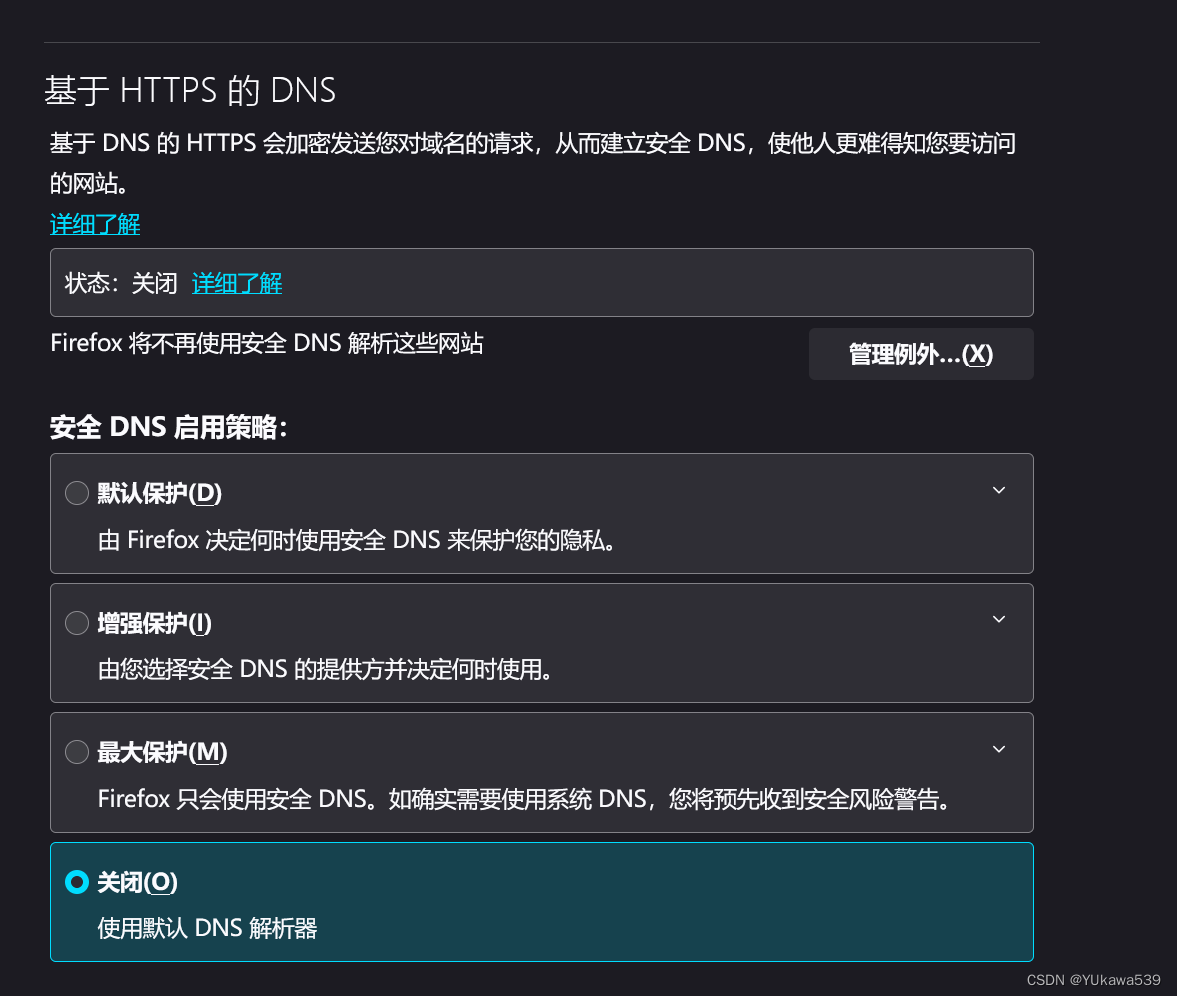
关于 firefox 不能访问 http 的解决
情景: 我在虚拟机 192.168.x.111 上配置了 DNS 服务器,在 kali 上设置 192.168.x.111 为 DNS 服务器后,使用 firefox 地址栏搜索域名 www.xxx.com ,访问在 192.168.x.111 搭建的网站,本来经 192.168.x.111 DNS 服务器解…...
68、Spring Data JPA 的 方法名关键字查询
★ 方法名关键字查询(全自动) (1)继承 CrudRepository 接口 的 DAO 组件可按特定规则来定义查询方法,只要这些查询方法的 方法名 遵守特定的规则,Spring Data 将会自动为这些方法生成 查询语句、提供 方法…...
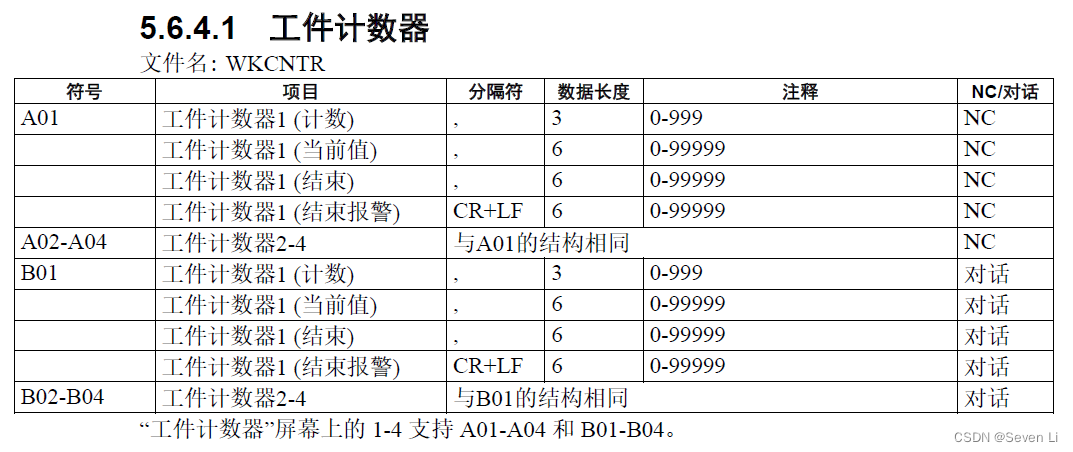
Brother CNC联网数采集和远程控制
兄弟CNC IP地址设定参考:https://www.sohu.com/a/544461221_121353733没有能力写代码的兄弟可以提前下载好网络调试助手NetAssist,这样就不用写代码来测试连接CNC了。 以上是网络调试助手抓取CNC的产出命令,结果有多个行string需要自行解析&…...
Windows 11任务栏透明化神器:TranslucentTB让你的桌面焕然一新!
Windows 11任务栏透明化神器:TranslucentTB让你的桌面焕然一新! 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你…...

开源协作平台Octopal:整合Git、文档与任务的项目管理利器
1. 项目概述:一个为开发者量身定制的开源协作平台如果你是一名开发者,或者是一个小型技术团队的负责人,那么你一定对这样的场景不陌生:手头有几个并行的项目,团队成员分散,沟通主要靠即时通讯工具ÿ…...

如何通过HWInfo插件实现精准硬件监控与风扇控制:完整配置指南
如何通过HWInfo插件实现精准硬件监控与风扇控制:完整配置指南 【免费下载链接】FanControl.HWInfo FanControl plugin to import HWInfo sensors. 项目地址: https://gitcode.com/gh_mirrors/fa/FanControl.HWInfo 想要让电脑散热系统更智能、更安静吗&#…...

【Claude Kubernetes配置终极指南】:20年SRE亲授生产环境零失误部署的7大黄金法则
更多请点击: https://intelliparadigm.com 第一章:Claude Kubernetes配置的核心理念与演进脉络 Claude 并非原生 Kubernetes 组件,而是 Anthropic 推出的大型语言模型系列;当将其部署于 Kubernetes 集群时,“Claude K…...

STM32从Keil移植到GCC编译环境,搞定startup_stm32f10x_hd.S报错的完整流程
STM32从Keil到GCC编译环境迁移实战指南 当你决定将STM32项目从熟悉的Keil MDK环境迁移到GCC工具链时,可能会遇到一系列令人头疼的兼容性问题。作为一名经历过多次环境迁移的嵌入式开发者,我深知这个过程可能遇到的陷阱。本文将带你系统性地解决从启动文件…...

从丝杆到直线电机:半导体运动台驱动技术演进与选型指南
1. 半导体运动台驱动技术的核心挑战 在半导体制造领域,运动平台就像精密仪器的心脏,每一次跳动都关乎生产效率和产品质量。想象一下,光刻机要在指甲盖大小的芯片上绘制比头发丝还细的电路,这相当于让一台卡车在足球场上精准停到误…...
)
用Arduino UNO和L298N驱动板,手把手教你让麦轮小车原地画个‘8’字(附完整代码)
用Arduino UNO和L298N驱动板实现麦轮小车8字轨迹编程实战 想让你的麦克纳姆轮小车跳出机械舞步吗?一个完美的"8"字轨迹不仅能展示麦轮的全向移动特性,更是检验运动控制算法的绝佳试金石。作为已经完成基础搭建的Arduino玩家,这个项…...

RAG 系统优化全流程:从数据入库到召回排序
RAG(Retrieval-Augmented Generation)系统的检索质量直接决定生成内容的上限。本文从工程落地角度,系统梳理 RAG 检索链路的三个核心阶段——入库、查询与召回。针对每个阶段的关键技术(语义分割、问答模拟、查询改写、语义校验、混合检索、语义重排)给出定义、问题背景、…...

MCP Analytics Suite:用自然语言驱动AI数据分析,零代码生成专业报告
1. 项目概述:当AI助手遇上专业数据分析如果你和我一样,日常工作中需要处理大量的业务数据——可能是Shopify的订单报表、Stripe的支付流水,或者是一堆从各个渠道导出的CSV文件——那你一定体会过那种“数据在手,却无从下手”的焦虑…...
)
VMware 17 Pro 中 Ubuntu 虚拟机共享 Windows 文件夹(完美踩坑版)
前言 很多小伙伴在使用 VMware 虚拟机时,都会遇到一个头疼的问题:如何在主机和虚拟机之间快速传递文件? 使用 U 盘拷贝?来回插拔太麻烦;用 scp 命令传文件?对于新手来说又有点门槛。其实,VMware…...