Pytorch 多卡并行(2)—— 使用 torchrun 进行容错处理
- 前文 Pytorch 多卡并行(1)—— 原理简介和 DDP 并行实践 介绍了使用 Pytorch 的 DDP 库进行单机多卡训练的方法,本文进一步说明如何用 torchrun 改写前文代码,以提高模型训练的效率和容错性
- torchrun 是从 Pytorch 1.9.0 开始引入的一个命令,请保证您的 pytorch 版本符合要求
- 完整代码下载:wxc971231/ddp-tutorial-series
文章目录
- 1. torchrun
- 2. 使用 torchrun 改写 DDP 代码
- 3. 调试代码
1. torchrun
-
在训练过程中,很容易遇到各种各样的错误,比如内存不足、网络故障、硬件故障等等。这些错误会导致训练过程中断或失败,从而浪费了训练时间和计算资源。 torchrun 允许我们在训练过程中按一定周期保存快照(snapshots),一旦某一并行进程出错退出,torchrun 会自动从最近 snapshots 重启所有进程。Snapshots 中要保存的参数由我们自行设定,它是模型 checkpoint 的超集,要包含恢复训练所需的全部参数,比如
- 当前 epoch 值
- 模型参数 model.state_dict()
- 学习率调度器参数 lr_scheduler.state_dict()
- 优化器参数 optimizer.state_dict()
- 其他必要参数
-
除了以上自动重启功能外,torchrun 还有其他一些功能
- torchrun 可以自动完成所有环境变量的设置,可以从环境变量中获取 rank 和 world size 等信息
os.environ['RANK'] # 得到在所有node的所有进程中当前GPU进程的rank os.environ['LOCAL_RANK'] # 得到在当前node中当前GPU进程的rank os.environ['WORLD_SIZE'] # 得到GPU的数量 - torchrun 可以完成进程分配工作,不再需要使用
mp.spawn手动分发进程,只需要设置一个通用的 main() 函数入口,然后用torchrun命令启动脚本即可 - 快照功能允许进行断点续训
- torchrun 可以自动完成所有环境变量的设置,可以从环境变量中获取 rank 和 world size 等信息
-
使用 torchrun 时,程序通常有以下结构
def main(args):ddp_setup() # 初始化进程池load_train_objs(args) # 设置 dataset, model, optimizer, trainer 等组件,若存在 snapshot 则从中加载参数trian(args) # 进行训练destroy_process_group() # 销毁进程池 def train(args):for batch in iter(dataset):train_step(batch)if should_checkpoint:save_snapshot(snapshot_path) # 用 rank0 保存 snapshotif __name__ == "__main__":# 加载参数args = parser.parse_args() # 现在 torchrun 负责在各个 GPU 上生成进程并执行,不再需要 mp.spawn 了main(args) -
使用 torchrun 命令来启动程序
torchrun --standalone --nproc_per_node=gpu XXX.py--standalone代表单机运行--nproc_per_node=gpu代表使用所有可用GPU。等于号后也可写gpu数量n,这样会使用前n个GPU
如果想要进一步指定要运行的 GPU,可以通过 CUDA_VISIBLE_DEVICES 设置GPU可见性,比如
CUDA_VISIBLE_DEVICES=2,3 torchrun --standalone --nproc_per_node=gpu multi_gpu_torchrun.py这样会把本机上的 GPU2 和 GPU3 看做 GPU0 和 GPU1 运行
2. 使用 torchrun 改写 DDP 代码
- 使用 torchrun 改写以下 DDP 代码
# 使用 DistributedDataParallel 进行单机多卡训练 import torch import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader import os# 对 python 多进程的一个 pytorch 包装 import torch.multiprocessing as mp# 这个 sampler 可以把采样的数据分散到各个 CPU 上 from torch.utils.data.distributed import DistributedSampler # 实现分布式数据并行的核心类 from torch.nn.parallel import DistributedDataParallel as DDP # DDP 在每个 GPU 上运行一个进程,其中都有一套完全相同的 Trainer 副本(包括model和optimizer) # 各个进程之间通过一个进程池进行通信,这两个方法来初始化和销毁进程池 from torch.distributed import init_process_group, destroy_process_group def ddp_setup(rank, world_size):"""setup the distribution process groupArgs:rank: Unique identifier of each processworld_size: Total number of processes"""# MASTER Node(运行 rank0 进程,多机多卡时的主机)用来协调各个 Node 的所有进程之间的通信os.environ["MASTER_ADDR"] = "localhost" # 由于这里是单机实验所以直接写 localhostos.environ["MASTER_PORT"] = "12355" # 任意空闲端口init_process_group(backend="nccl", # Nvidia CUDA CPU 用这个 "nccl"rank=rank, world_size=world_size)torch.cuda.set_device(rank)class Trainer:def __init__(self,model: torch.nn.Module,train_data: DataLoader,optimizer: torch.optim.Optimizer,gpu_id: int,save_every: int,) -> None:self.gpu_id = gpu_idself.model = model.to(gpu_id)self.train_data = train_dataself.optimizer = optimizerself.save_every = save_every # 指定保存 ckpt 的周期self.model = DDP(model, device_ids=[gpu_id]) # model 要用 DDP 包装一下def _run_batch(self, source, targets):self.optimizer.zero_grad()output = self.model(source)loss = F.cross_entropy(output, targets)loss.backward()self.optimizer.step()def _run_epoch(self, epoch):b_sz = len(next(iter(self.train_data))[0])print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")self.train_data.sampler.set_epoch(epoch) # 在各个 epoch 入口调用 DistributedSampler 的 set_epoch 方法是很重要的,这样才能打乱每个 epoch 的样本顺序for source, targets in self.train_data: source = source.to(self.gpu_id)targets = targets.to(self.gpu_id)self._run_batch(source, targets)def _save_checkpoint(self, epoch):ckp = self.model.module.state_dict() # 由于多了一层 DDP 包装,通过 .module 获取原始参数 PATH = "checkpoint.pt"torch.save(ckp, PATH)print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")def train(self, max_epochs: int):for epoch in range(max_epochs):self._run_epoch(epoch)# 各个 GPU 上都在跑一样的训练进程,这里指定 rank0 进程保存 ckpt 以免重复保存if self.gpu_id == 0 and epoch % self.save_every == 0:self._save_checkpoint(epoch)class MyTrainDataset(Dataset):def __init__(self, size):self.size = sizeself.data = [(torch.rand(20), torch.rand(1)) for _ in range(size)]def __len__(self):return self.sizedef __getitem__(self, index):return self.data[index]def load_train_objs():train_set = MyTrainDataset(2048) # load your datasetmodel = torch.nn.Linear(20, 1) # load your modeloptimizer = torch.optim.SGD(model.parameters(), lr=1e-3)return train_set, model, optimizerdef prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=False, # 设置了新的 sampler,参数 shuffle 要设置为 False sampler=DistributedSampler(dataset) # 这个 sampler 自动将数据分块后送个各个 GPU,它能避免数据重叠)def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):# 初始化进程池ddp_setup(rank, world_size)# 进行训练dataset, model, optimizer = load_train_objs()train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, rank, save_every)trainer.train(total_epochs)# 销毁进程池destroy_process_group()if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('--total-epochs', type=int, default=50, help='Total epochs to train the model')parser.add_argument('--save-every', type=int, default=10, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()world_size = torch.cuda.device_count()# 利用 mp.spawn,在整个 distribution group 的 nprocs 个 GPU 上生成进程来执行 fn 方法,并能设置要传入 fn 的参数 args# 注意不需要 fn 的 rank 参数,它由 mp.spawn 自动分配mp.spawn(fn=main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size) - 改写后的代码如下所示,请参考注释自行对比
# 使用 DistributedDataParallel 进行单机多卡训练的基础上,使用 torchrun 进行容错处理,增强程序稳定性 # torchrun 允许我们在训练过程中按一定保存 snapshots,其中应当包含当前 epoch、模型参数(ckpt)、优化器参数、lr调度器参数等恢复训练所需的全部参数 # 一旦程序出错退出,torchrun 会自动从最近 snapshots 重启所有进程 # 除了增强稳定性外,torchrun 还会自动完成所有环境变量设置和进程分配工作,所以不再需要手动设置 rank 或用 mp.spawn 生成并分配进程import torch import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader import os# 对 python 多进程的一个 pytorch 包装 import torch.multiprocessing as mp# 这个 sampler 可以把采样的数据分散到各个 CPU 上 from torch.utils.data.distributed import DistributedSampler # 实现分布式数据并行的核心类 from torch.nn.parallel import DistributedDataParallel as DDP # DDP 在每个 GPU 上运行一个进程,其中都有一套完全相同的 Trainer 副本(包括model和optimizer) # 各个进程之间通过一个进程池进行通信,这两个方法来初始化和销毁进程池 from torch.distributed import init_process_group, destroy_process_group def ddp_setup():# torchrun 会处理环境变量以及 rank & world_size 设置os.environ["MASTER_ADDR"] = "localhost" # 由于这里是单机实验所以直接写 localhostos.environ["MASTER_PORT"] = "12355" # 任意空闲端口init_process_group(backend="nccl")torch.cuda.set_device(int(os.environ['LOCAL_RANK'])))class Trainer:def __init__(self,model: torch.nn.Module,train_data: DataLoader,optimizer: torch.optim.Optimizer,save_every: int, snapshot_path: str, # 保存 snapshots 的位置 ) -> None:self.gpu_id = int(os.environ['LOCAL_RANK']) # torchrun 会自动设置这个环境变量指出当前进程的 rankself.model = model.to(self.gpu_id)self.train_data = train_dataself.optimizer = optimizerself.save_every = save_every # 指定保存 snapshots 的周期self.epochs_run = 0 # 存储将要保存在 snapshots 中的 epoch num 信息self.snapshot_path = snapshot_path# 若存在 snapshots 则加载,这样重复运行指令就能自动继续训练了if os.path.exists(snapshot_path):print('loading snapshot')self._load_snapshot(snapshot_path)self.model = DDP(self.model, device_ids=[self.gpu_id]) # model 要用 DDP 包装一下def _load_snapshot(self, snapshot_path):''' 加载 snapshot 并重启训练 '''loc = f"cuda:{self.gpu_id}"snapshot = torch.load(snapshot_path, map_location=loc)self.model.load_state_dict(snapshot["MODEL_STATE"])self.epochs_run = snapshot["EPOCHS_RUN"]print(f"Resuming training from snapshot at Epoch {self.epochs_run}")def _run_batch(self, source, targets):self.optimizer.zero_grad()output = self.model(source)loss = F.cross_entropy(output, targets)loss.backward()self.optimizer.step()def _run_epoch(self, epoch):b_sz = len(next(iter(self.train_data))[0])print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")self.train_data.sampler.set_epoch(epoch)for source, targets in self.train_data:source = source.to(self.gpu_id)targets = targets.to(self.gpu_id)self._run_batch(source, targets)def _save_snapshot(self, epoch):# 在 snapshot 中保存恢复训练所必须的参数snapshot = {"MODEL_STATE": self.model.module.state_dict(), # 由于多了一层 DDP 包装,通过 .module 获取原始参数 "EPOCHS_RUN": epoch,}torch.save(snapshot, self.snapshot_path)print(f"Epoch {epoch} | Training snapshot saved at {self.snapshot_path}")def train(self, max_epochs: int):for epoch in range(self.epochs_run, max_epochs): # 现在从 self.epochs_run 开始训练,统一重启的情况self._run_epoch(epoch)# 各个 GPU 上都在跑一样的训练进程,这里指定 rank0 进程保存 snapshot 以免重复保存if self.gpu_id == 0 and epoch % self.save_every == 0:self._save_snapshot(epoch)class MyTrainDataset(Dataset):def __init__(self, size):self.size = sizeself.data = [(torch.rand(20), torch.rand(1)) for _ in range(size)]def __len__(self):return self.sizedef __getitem__(self, index):return self.data[index]def load_train_objs():train_set = MyTrainDataset(2048) # load your datasetmodel = torch.nn.Linear(20, 1) # load your modeloptimizer = torch.optim.SGD(model.parameters(), lr=1e-3)return train_set, model, optimizerdef prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=False, # 设置了新的 sampler,参数 shuffle 要设置为 False sampler=DistributedSampler(dataset) # 这个 sampler 自动将数据分块后送个各个 GPU,它能避免数据重叠)def main(save_every: int, total_epochs: int, batch_size: int, snapshot_path: str="snapshot.pt"):# 初始化进程池ddp_setup()# 进行训练dataset, model, optimizer = load_train_objs()train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, save_every, snapshot_path)trainer.train(total_epochs)# 销毁进程池destroy_process_group()if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('--total-epochs', type=int, default=50, help='Total epochs to train the model')parser.add_argument('--save-every', type=int, default=10, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()# 现在 torchrun 负责在各个 GPU 上生成进程并执行,不再需要 mp.spawn 了main(args.save_every, args.total_epochs, args.batch_size)''' 运行命令: torchrun --standalone --nproc_per_node=gpu multi_gpu_torchrun.py参数说明:--standalone 代表单机运行 --nproc_per_node=gpu 代表使用所有可用GPU, 等于号后也可写gpu数量n, 这样会使用前n个GPU运行后获取参数:os.environ['RANK'] 得到在所有机器所有进程中当前GPU的rankos.environ['LOCAL_RANK'] 得到在当前node中当前GPU的rankos.environ['WORLD_SIZE'] 得到GPU的数量通过 CUDA_VISIBLE_DEVICES 指定程序可见的GPU, 从而实现指定GPU运行:CUDA_VISIBLE_DEVICES=0,3 torchrun --standalone --nproc_per_node=gpu multi_gpu_torchrun.py '''
3. 调试代码
- 如果使用 VScode 的话,可以如下编辑 launch.json 文件,然后像往常一样设置断点按 f5 调试即可
注意其中 “program” 是你的 torchrun 脚本路径,可使用{"version": "0.2.0","configurations": [{"name": "Python: torchrun","type": "python","request": "launch",// 设置 program 的路径为 torchrun 脚本对应的绝对路径"program": "/home/tim/anaconda3/envs/project/lib/python3.8/site-packages/torch/distributed/run.py",// 设置 torchrun 命令的参数"args":["--standalone","--nproc_per_node=gpu","multi_gpu_torchrun.py"],"console": "integratedTerminal","justMyCode": true}] }pip show torch查看 torch 的安装路径进而找到它
相关文章:
—— 使用 torchrun 进行容错处理)
Pytorch 多卡并行(2)—— 使用 torchrun 进行容错处理
前文 Pytorch 多卡并行(1)—— 原理简介和 DDP 并行实践 介绍了使用 Pytorch 的 DDP 库进行单机多卡训练的方法,本文进一步说明如何用 torchrun 改写前文代码,以提高模型训练的效率和容错性torchrun 是从 Pytorch 1.9.0 开始引入的…...
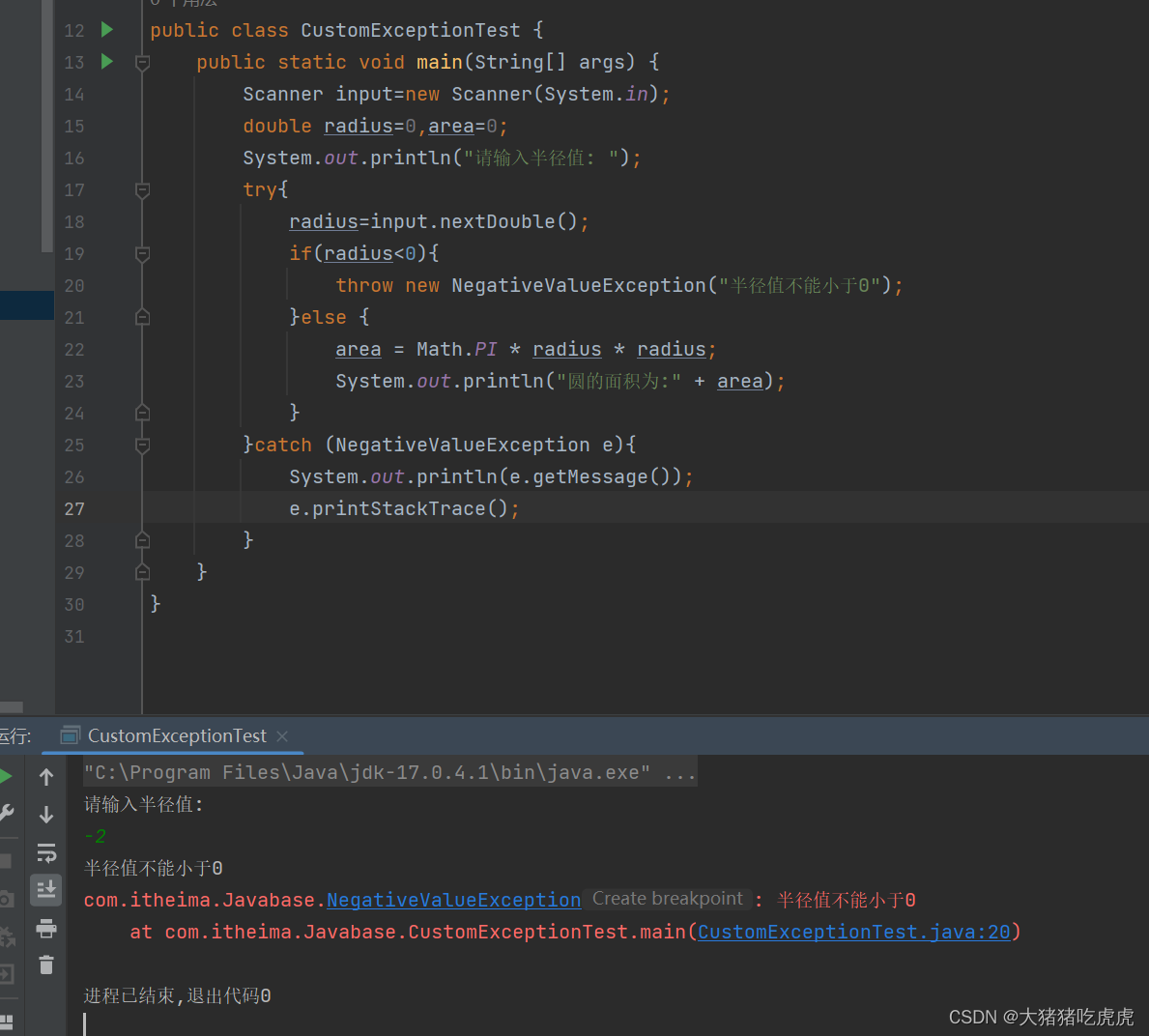
Java异常处理(详解)
Java异常处理 前言一、异常与异常类1.异常的概念2.异常类Error类Exception类(1)非检查异常(2)检查异常 二、异常处理1.异常的抛出与捕获2.try-catch-finally语句3.声明方法抛出异常3.用throw 语句抛出异常 三、自定义异常类 前言 …...

嵌入式-数据进制之间的转换
目录 一.简介 1.1十进制 1.2二进制 1.3八进制 1.4十六进制 二.进制转换 2.1二进制-十进制转换 2.2八进制-十进制转换 2.3十六进制-十进制转换 2.4十进制-二进制转换 2.5十进制-八进制转换 2.6十进制-十六进制转换 2.7小数部分转换 一.简介 被传入到计算机的数据要…...
腾讯mini项目-【指标监控服务重构】2023-08-20
今日已办 PPT制作 答辩流程 概述:对项目背景、架构进行介绍(体现我们分组的区别和需求)人员:小组成员进行简短的自我介绍和在项目中的定位,分工进展:对项目进展介绍,其中a、b两组的区别和工作…...
智能文本纠错API的应用与工作原理解析
引言 在数字时代,文本撰写和传播变得日益重要,无论是在学校里写论文、在职场中发送邮件,还是在社交媒体上发表观点。然而,文字错误、标点符号错误、语法问题和不当的表达常常会削弱文本的质量,降低信息传达的效果。为…...

在springboot下将mybatis升级为mybatis-plus
在springboot下将mybatis升级为mybatis-plus 1. 整体描述2. 具体步骤2.1 更新pom引用2.2 更新yml配置2.3 更新config配置2.4 BaseEntity修改 3. 程序启动4. 总结 1. 整体描述 之前项目工程用的是mybatis,现在需要将其替换为mybatis-plus,mybatis-plus的…...
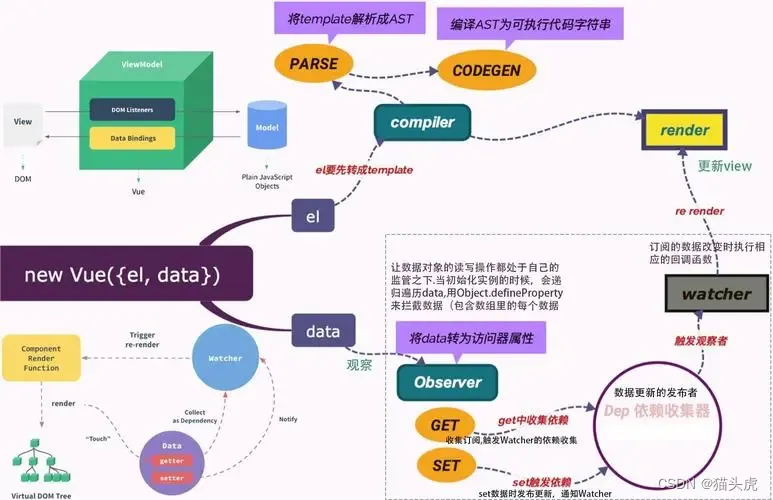
Vuex详解:Vue.js的状态管理方案
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
栈与队列经典题目——用队列实现栈
本篇文章讲解栈和队列这一部分知识点的经典题目:用栈实现队列、用队列实现栈。对应的题号分别为:Leetcode.225——用队列实现栈,。 在对两个题目进行解释之前,先回顾以下栈和队列的特点与不同: 栈是一种特殊的线性表…...
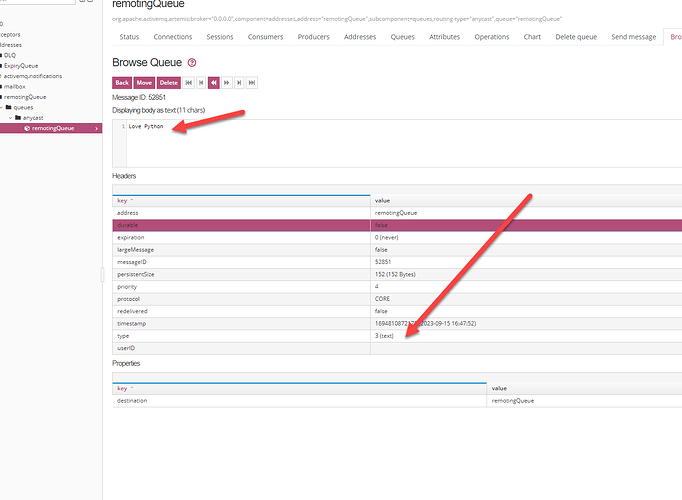
Python stomp 发送消息无法显示文本
我们向消息服务器通过 stomp 发送的是文本消息。 当消息服务器发送成功后,消息服务器上的文本没有显示,显示的是 2 进制的数据。 如上图,消息没有作为文本来显示。 问题和解决 消息服务器是如何判断发送的小时是文本还是二进制的。 根据官…...
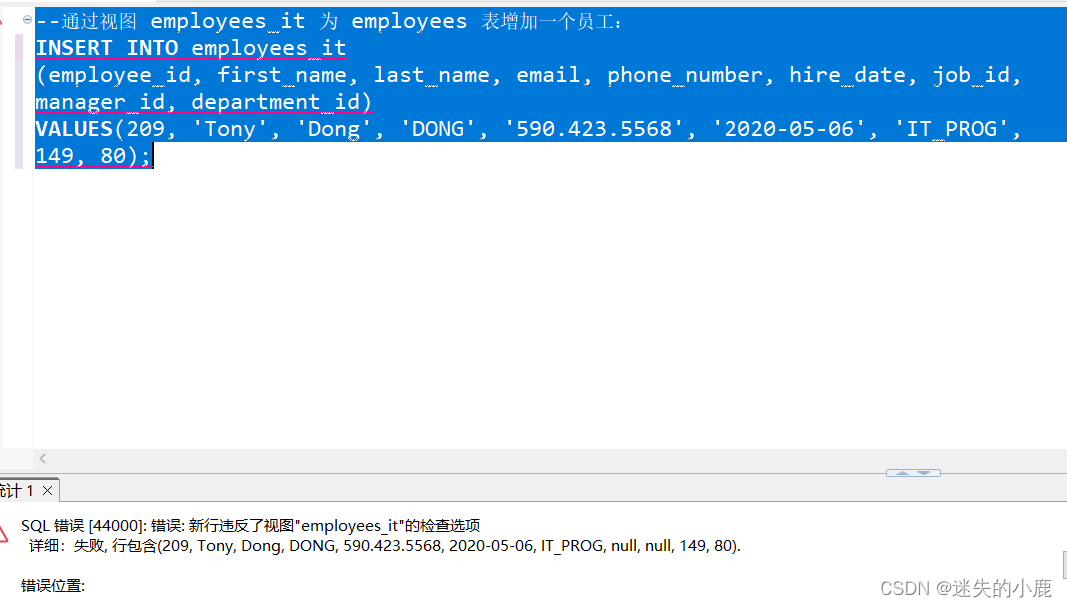
postgresql-视图
postgresql-视图 视图概述使用视图的好处 创建视图修改视图删除视图递归视图可更新视图WITH CHECK OPTION 视图概述 视图(View)本质上是一个存储在数据库中的查询语句。视图本身不包含数据,也被称为 虚拟表。我们在创建视图时给它指定了一个…...

科技资讯|Vision Pro头显无损音频仅限USB-C AirPods Pro 2耳机
彭博社的马克・古尔曼在最新发布的推文中表示,苹果 Vision Pro 头显的无损音频仅限于 USB-C AirPods Pro 2 耳机。 新款采用 USB-C 的 AirPods Pro 2 升级到了 IP54 级别(原版不防尘,仅 IPX4 级抗水),可陪伴用户在恶劣…...
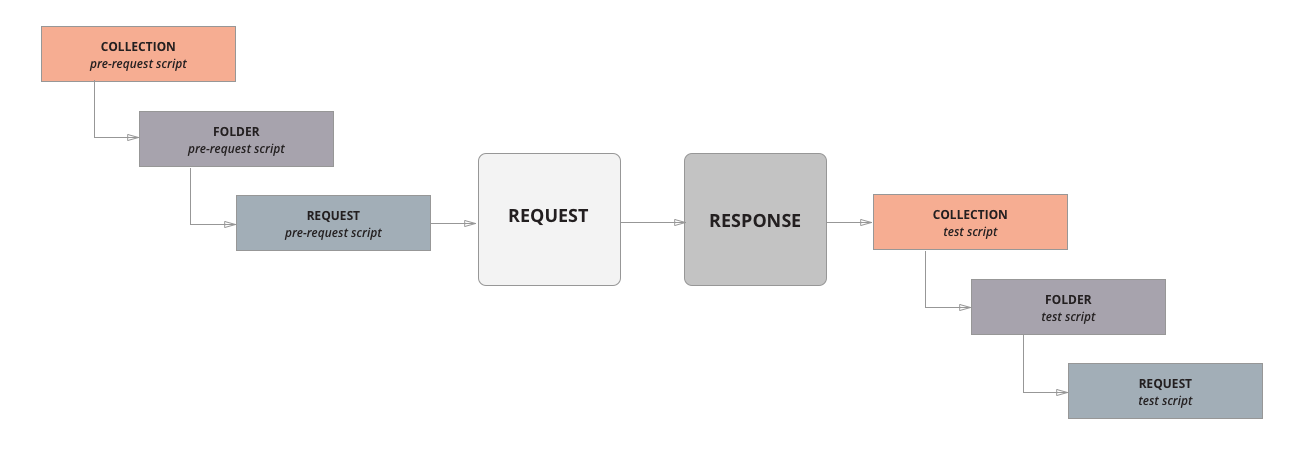
Postman应用——初步了解postman
Postman 是一个用于构建和使用 API 的 API 平台,Postman 简化了 API 生命周期的每个步骤并简化了协作,可以更快地创建更好的 API。 Postman 包含一个基于Node.js的强大的运行时,允许您向请求(request)和分组ÿ…...

分析报告显示,PHP是编程语言主力军,且在电商领域占据“统治地位”
日前有有业内专家透露了PHP语言的使用数据,并强调了PHP语言对于互联网的作用。 而根据W3 Techs发布的《全球前1000万个网站使用的编程语言分析(截至 2023.8)》中,有这样一组数据引起广泛的关注。PHP占比 77.2%、ASP占比 6.9%、Ruby 占比5.4%。 此外&am…...
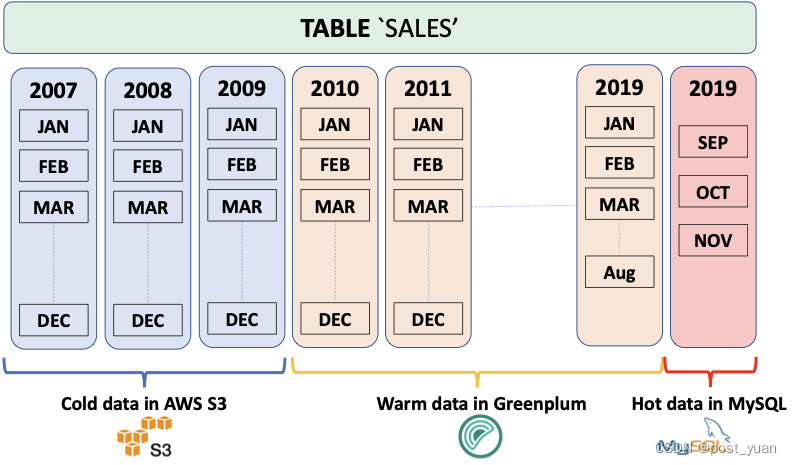
关于Greenplum Platform Extension Framework(PXF)
本文翻译自 https://docs.vmware.com/en/VMware-Greenplum-Platform-Extension-Framework/6.6/greenplum-platform-extension-framework/overview_pxf.html 随着数据存储和云服务的爆炸式增长,数据现在以各种格式驻留在许多不同的系统中。通常,数据根据…...

编程获取图像中的圆半径
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 即将推出EmguCV的教程,请大家还稍作等待。 之前网友咨询如何获得图像中圆形的半径,其中有两个十字作为标定…...

什么是Scrum?如何实施Scrum(敏捷开发)以及敏捷工具
什么是Scrum? Scrum是一个敏捷开发框架,它是一个增量的、迭代的开发过程。它被广泛应用于敏捷软件开发,在Scrum中,开发过程由若干个短的迭代周期组成,每个迭代周期称为一个Sprint。 那么Scrum如何实施呢…...
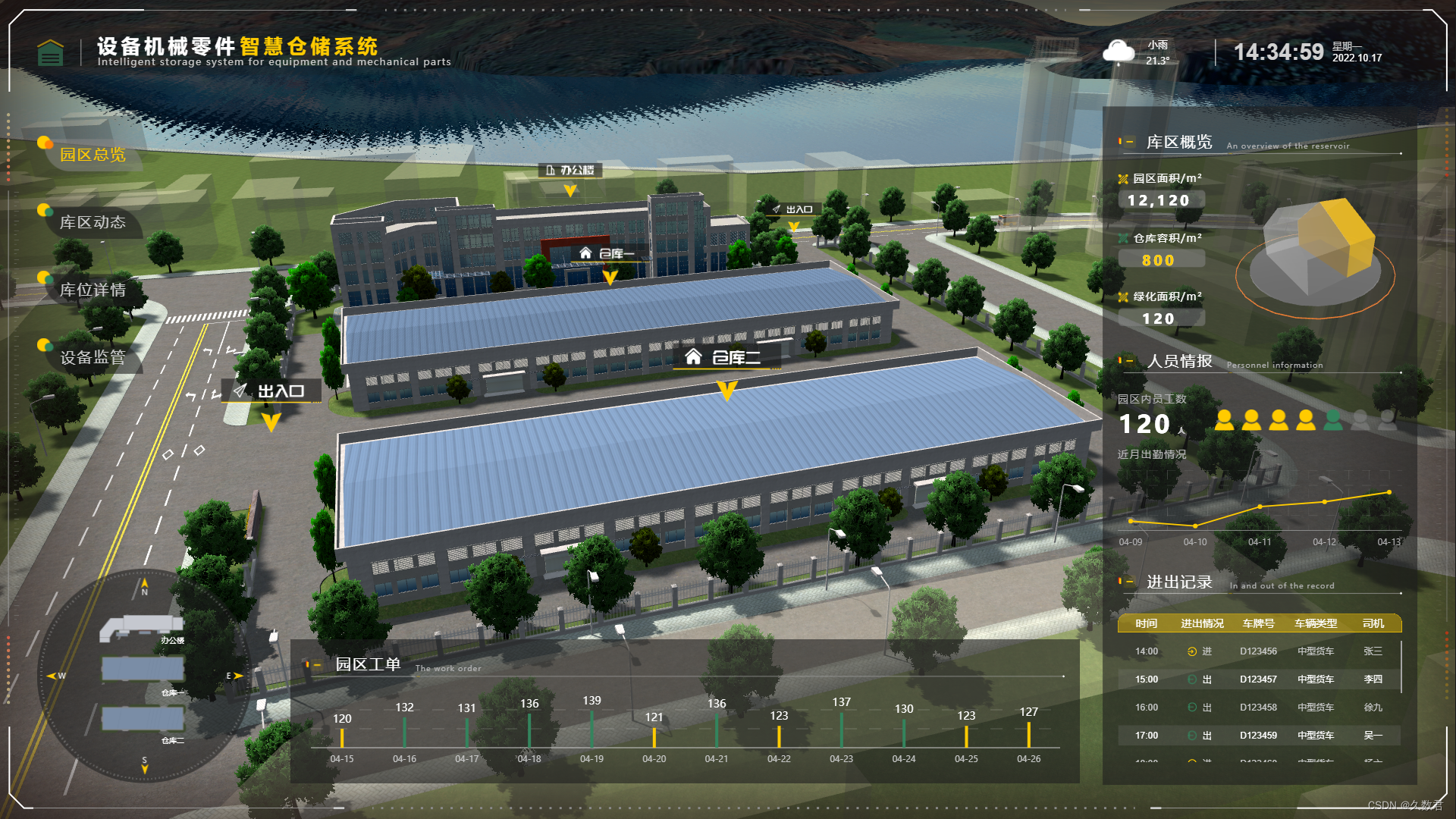
提升运营效率:仓储可视化的实时监控与优化
当今,仓储管理已经不再是简单的储存和分发商品的过程。随着供应链的复杂性增加,企业需要更高效的方式来管理和优化其仓储运营。在这个背景下,仓储可视化成为了一项关键的技术,它利用先进的数字化工具和数据分析来提升仓储管理的效…...
)
代理模式和单一职责原理一文读懂(设计模式与开发实践 P6)
文章目录 代理模式实现保护代理虚拟代理单一职责原理代理和本体 - 接口一致性虚拟代理 - 合并请求缓存代理其他代理 代理模式 定义:为一个对象提供一个代用品 & 占位符,以便 控制对他的访问 关键:不方便直接访问某个对象或不满足需要的时…...
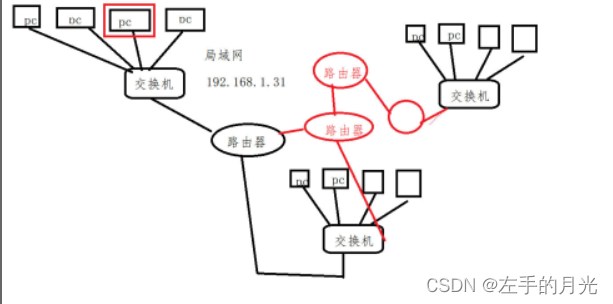
Linux网络编程|TCP编程
一.网络基础 1.1网络发展史 Internet-“冷战”的产物 1957年10月和11月,前苏联先后有两颗“Sputnik”卫星上天 1958年美国总统艾森豪威尔向美国国会提出建立DARPA (Defense Advanced Research Project Agency),即国防部高级研究计划署&#…...
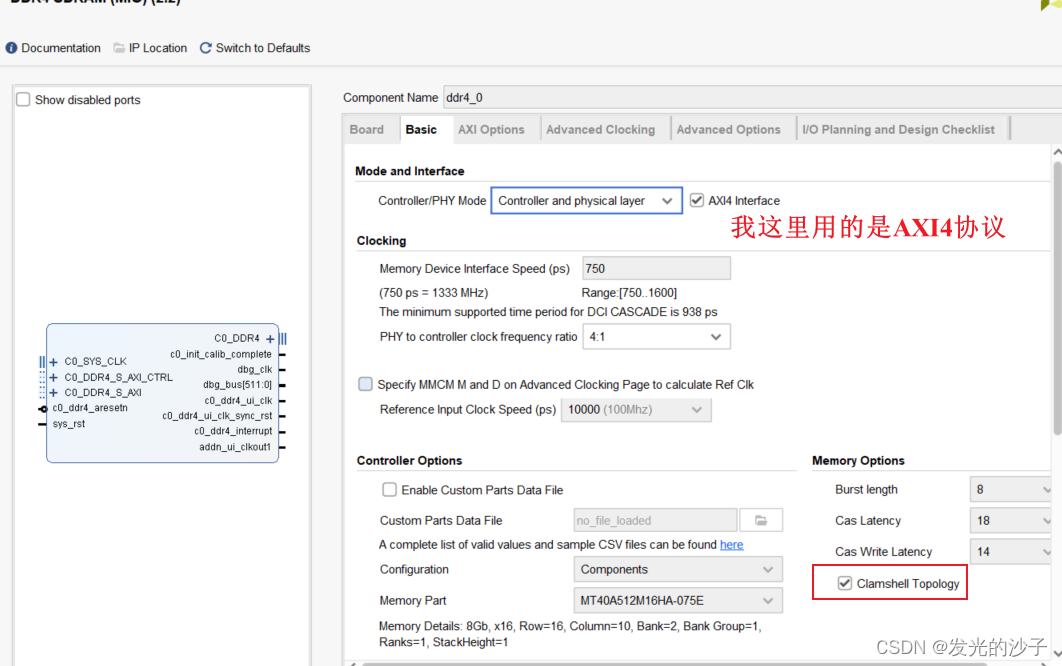
FPGA----VCU128的DDR4无法使用问题(全网唯一)
1、在Vivado 2019.1版本中使用DDR4的IP核会遇到如下图所示的错误,即便过了implementation生成了bit,DDR4也无法正常启动。 2、解决办法,上xilinx社区搜一下就知道了 AMD Customer Communityhttps://support.xilinx.com/s/article/69035?lan…...

PS图片文字修改教程 简单几步完美替换文字内容
日常设计、办公、自媒体创作中,我们经常会遇到需要修改图片文字的场景:海报文案调整、截图信息替换、照片文字修正等。很多人苦于改完文字后模糊留痕、背景破损,要么耗时半天还达不到理想效果。今天就给大家分享两种PS改图片文字的实用方法&a…...

Simulink Function子系统代码生成避坑指南:从Global配置到多输出端口的指针传递
Simulink Function子系统代码生成实战解析:从配置陷阱到高效集成 当你在Simulink中构建复杂算法时,是否遇到过这样的困境——生成的代码难以直接集成到现有系统中?传统的Simulink模型默认生成全局变量和void函数,这在需要精细控制…...

AI提示工程与创意工作流:Claude+Cursor高效协作心法
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫 zupp6869/claude-cursor-tips-for-creatives 。光看名字,你可能觉得这又是一个关于AI代码助手Cursor的普通教程合集。但如果你点进去,特别是你本身从事创意、设计、内容创作…...

ESP8266+STM32远程控制实战:如何通过华为云中转指令与数据
ESP8266STM32远程控制实战:华为云物联网全链路开发指南 在智能家居和工业监控领域,远程设备控制一直是核心技术痛点。当ESP8266遇上STM32,再通过华为云物联网平台搭建通信桥梁,这个组合能爆发出怎样的生产力?本文将带您…...

基于Python与MediaPipe的手势控制系统:从原理到实战
1. 项目概述:用摄像头读懂你的手,让手势成为新鼠标如果你厌倦了每天在键盘和鼠标之间来回切换,或者只是单纯想体验一下《少数派报告》里汤姆克鲁斯隔空操作电脑的酷炫感,那么这个基于Python的手势控制系统绝对值得你花时间折腾一下…...

RANSAC算法调参指南:迭代次数和容差阈值到底怎么设?附Python/Matlab实例
RANSAC算法实战调参手册:从理论到代码的深度解析 在三维重建、自动驾驶和工业检测等机器视觉应用中,数据噪声和异常值一直是模型拟合的噩梦。传统最小二乘法就像一位过分认真的学生,试图让所有数据点都满意,结果却被少数离群点带偏…...

Fujirebio宣布全自动Lumipulse® G pTau 217血浆检测试剂盒获得CE认证
H.U. Group Holdings Inc.及其全资子公司Fujirebio今日宣布,Fujirebio Europe N.V.已依据《欧盟(EU) 2017/746体外诊断医疗器械法规》(IVDR)取得Lumipulse G pTau 217血浆检测试剂盒的CE认证。该化学发光酶免疫分析(CLEIA)检测可对人体血浆(K2 EDTA)中的苏氨酸217磷…...
)
NotebookLM笔记生产力跃迁(仅限前500名早鸟用户的动态模板库已开放)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM笔记生产力跃迁(仅限前500名早鸟用户的动态模板库已开放) NotebookLM 正式引入基于语义理解的「上下文感知模板引擎」,早鸟用户可通过专属入口启用动态模板…...
)
不止于透传:用VirtIO-GPU为你的KVM虚拟机开启3D加速(附XML配置详解)
VirtIO-GPU虚拟化加速实战:从原理到配置的深度解析 在虚拟化技术日益成熟的今天,GPU加速已成为开发测试、图形工作站和云桌面等场景的刚需。传统GPU透传方案虽然性能接近原生,但受限于硬件数量且缺乏灵活性。VirtIO-GPU结合virglrenderer的软…...

独立开发者工具箱:模块化架构与全栈实践指南
1. 项目概述:一个独立开发者的工具箱 如果你是一个独立开发者,或者正在尝试构建自己的数字产品,那么你一定经历过这样的时刻:一个想法在脑海中成型,你迫不及待地想把它变成现实,但当你打开编辑器࿰…...