EDA(Exploratory Data Analysis)探索性数据分析
EDA(Exploratory Data Analysis)中文名称为探索性数据分析,是为了在特征工程或模型开发之前对数据有个基本的了解。数据类型通常分为两类:连续类型和离散类型,特征类型不同,我们探索的内容也不同。
1. 特征类型
1.1 连续型特征
定义:取值为数值类型且数值之间的大小具有实际含义。例如:收入。对于连续型变量,需要进行EDA的内容包括:
- 缺失值
- 均值
- 方差
- 标准差
- 最大值
- 最小值
- 中位数
- 众数
- 四分位数
- 偏度
- 最大取值类别对应的样本数
1.2 离散型特征
定义:不具有数学意义的特征。如:性别。对于离散型变量,需要进行EDA的内容包括:
- 缺失值
- 众数
- 取值个数
- 最大取值类别对应的样本数
- 每个取值对应的样本数
2. EDA目的
通过EDA,需要达到以下几个目的:
(1)可以有效发现变量类型、分布趋势、缺失值、异常值等。
(2)缺失值处理:(i)删除缺失值较多的列,通常缺失超过50%的列需要删除;(ii)缺失值填充。对于离散特征,通常将NAN单独作为一个类别;对于连续特征,通常使用均值、中值、0或机器学习算法进行填充。具体填充方法因业务的不同而不同。
(3)异常值处理(主要针对连续特征)。如:Winsorizer方法处理。
(4)类别合并(主要针对离散特征)。如果某个取值对应的样本个数太少,就需要将该取值与其他值合并。因为样本过少会使数据的稳定性变差,且不具有统计意义,可能导致结论错误。由于展示空间有限,通常选择取值个数最少或最多的多个取值进行展示。
(5)删除取值单一的列。
(6)删除最大类别取值数量占比超过阈值的列。
3.实验
3.1 统计变量类型、分布趋势、缺失值、异常值等
#!/usr/bin/pythonimport pandas as pd
import numpy as npdef getTopValues(series, top = 5, reverse = False):"""Get top/bottom n valuesArgs:series (Series): data seriestop (number): number of top/bottom n valuesreverse (bool): it will return bottom n values if True is givenReturns:Series: Series of top/bottom n values and percentage. ['value:percent', None]"""itype = 'top'counts = series.value_counts()counts = list(zip(counts.index, counts, counts.divide(series.size)))if reverse:counts.reverse()itype = 'bottom'template = "{0[0]}:{0[2]:.2%}"indexs = [itype + str(i + 1) for i in range(top)]values = [template.format(counts[i]) if i < len(counts) else None for i in range(top)]return pd.Series(values, index = indexs)def getDescribe(series, percentiles = [.25, .5, .75]):"""Get describe of seriesArgs:series (Series): data seriespercentiles: the percentiles to include in the outputReturns:Series: the describe of data include mean, std, min, max and percentiles"""d = series.describe(percentiles)return d.drop('count')def countBlank(series, blanks = []):"""Count number and percentage of blank values in seriesArgs:series (Series): data seriesblanks (list): list of blank valuesReturns:number: number of blanksstr: the percentage of blank values"""if len(blanks)>0:isnull = series.replace(blanks, None).isnull()else:isnull = series.isnull()n = isnull.sum()ratio = isnull.mean()return (n, "{0:.2%}".format(ratio))def isNumeric(series):"""Check if the series's type is numericArgs:series (Series): data seriesReturns:bool"""return series.dtype.kind in 'ifc'def detect(dataframe):""" Detect dataArgs:dataframe (DataFrame): data that will be detectedReturns:DataFrame: report of detecting"""numeric_rows = []category_rows = []for name, series in dataframe.items():# 缺失值比例nblank, pblank = countBlank(series)# 最大类别取值占比biggest_category_percentage = series.value_counts(normalize=True, dropna=False).values[0] * 100if isNumeric(series):desc = getDescribe(series,percentiles=[.01, .1, .5, .75, .9, .99])details = desc.tolist()details_index = ['mean', 'std', 'min', '1%', '10%', '50%', '75%', '90%', '99%', 'max']row = pd.Series(index=['type', 'size', 'missing', 'unique', 'biggest_category_percentage', 'skew'] + details_index,data=[series.dtype, series.size, pblank, series.nunique(), biggest_category_percentage, series.skew()] + details)row.name = namenumeric_rows.append(row)else:top5 = getTopValues(series)bottom5 = getTopValues(series, reverse=True)details = top5.tolist() + bottom5[::-1].tolist()details_index = ['top1', 'top2', 'top3', 'top4', 'top5', 'bottom5', 'bottom4', 'bottom3', 'bottom2', 'bottom1']row = pd.Series(index=['type', 'size', 'missing', 'unique', 'biggest_category_percentage'] + details_index,data=[series.dtype, series.size, pblank, series.nunique(), biggest_category_percentage] + details)row.name = namecategory_rows.append(row)return pd.DataFrame(numeric_rows), pd.DataFrame(category_rows)demo(数据来自:https://www.kaggle.com/competitions/home-credit-default-risk/data)
import os
import eda
import pandas as pd
import numpy as npdata_dir = "./"df = pd.read_csv(os.path.join(data_dir, "bureau.csv"))
numeric_df, category_df = eda.detect(df)


3.2 缺失值处理(示例)
#连续特征
df[col].fillna(-df[col].mean(), inplace=True)
#离散特征
df[col].fillna('nan', inplace=True)
3.3 删除无用特征
def get_del_columns(df):del_columns = {}for index, row in df.iterrows():if row["unique"] < 2:del_columns[row["Feature"]] = "取值单一"continueif row["missing"] > 90:del_columns[row["Feature"]] = "缺失值数量大于90%"continueif row["biggest_category_percentage"] > 99:del_columns[row["Feature"]] = "取值最多的类别占比超过99%"continuedel_columns[row["Feature"]] = "正常"return del_columns
3.4 异常值处理
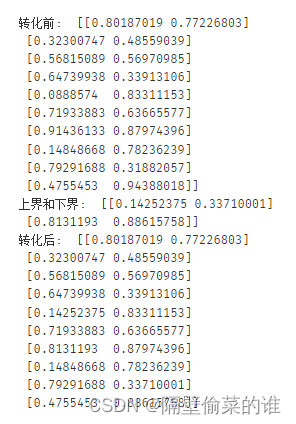
Winsorizer算法(定义某个变量的上界和下界,取值超过边界的话会用边界的值取代):

class Winsorizer():"""Performs Winsorization 1->1*Warning: this class should not be used directly.""" def __init__(self,trim_quantile=0.0):self.trim_quantile=trim_quantileself.winsor_lims=Nonedef train(self,X):# get winsor limitsself.winsor_lims=np.ones([2,X.shape[1]])*np.infself.winsor_lims[0,:]=-np.infif self.trim_quantile>0:for i_col in np.arange(X.shape[1]):lower=np.percentile(X[:,i_col],self.trim_quantile*100)upper=np.percentile(X[:,i_col],100-self.trim_quantile*100)self.winsor_lims[:,i_col]=[lower,upper]def trim(self,X):X_=X.copy()X_=np.where(X>self.winsor_lims[1,:],np.tile(self.winsor_lims[1,:],[X.shape[0],1]),np.where(X<self.winsor_lims[0,:],np.tile(self.winsor_lims[0,:],[X.shape[0],1]),X))return X_
winsorizer = Winsorizer (0.1)
a=np.random.random((10,2))
print("转化前: ", a)
winsorizer.train(a)
print("上界和下界: ", winsorizer.winsor_lims)
b = winsorizer.trim(a)
print("转化后: ", b)
4.总结
这篇文章只总结了EDA的常用做法,实际应用过程中还需要根据具体业务来做调整。
相关文章:
EDA(Exploratory Data Analysis)探索性数据分析
EDA(Exploratory Data Analysis)中文名称为探索性数据分析,是为了在特征工程或模型开发之前对数据有个基本的了解。数据类型通常分为两类:连续类型和离散类型,特征类型不同,我们探索的内容也不同。 1. 特征类型 1.1 连续型特征 …...

Python中的多媒体处理库有哪些?
在Python中,有几个常用的多媒体处理库,包括: Pillow - 一个强大的图像处理库,可以进行图像的读取、保存、剪裁、调整大小、滤镜处理等操作。 OpenCV - 一个用于图像和视频处理的开源计算机视觉库,提供了许多图像处理和…...
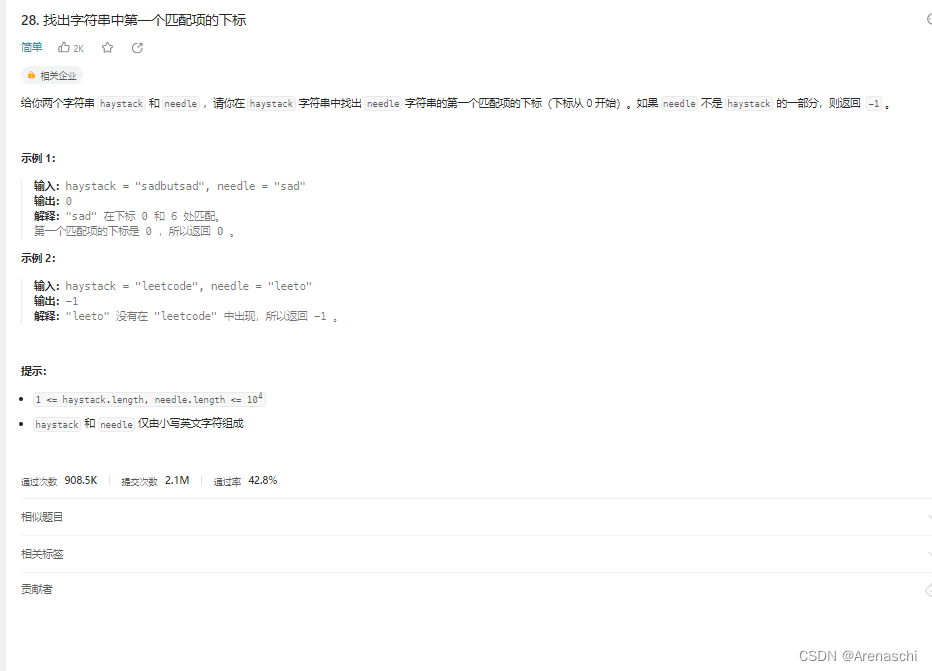
LeetCode【28. 找出字符串中第一个匹配项的下标】
不要用珍宝装饰自己,而要用健康武装身体 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。 …...

产业互联网开始从简单的概念,逐渐成为可以落地的存在
当流量不再是红利,几乎所有的消费互联网模式开始失效。这一现象,并不仅仅只是体现在流量获取成本的不断增加上,同样还体现在流量激活的难度不断增加上。事实证明,以产业链末端为主要驱动力的发展模式,正在走入到死胡同…...

element-ui tree组件实现在线增删改
这里要实现一个tree 增删改 <!--oracle巡检项--> <template><div class"oracle_instanceType"><el-row type"flex" align"middle" justify"space-between"><iclass"el-icon-s-fold iBox"click&q…...
华为开源自研AI框架昇思MindSpore应用案例:消噪的Diffusion扩散模型
目录 一、环境准备1.进入ModelArts官网2.使用CodeLab体验Notebook实例 二、案例实现构建Diffusion模型位置向量ResNet/ConvNeXT块Attention模块组归一化条件U-Net正向扩散数据准备与处理采样训练过程推理过程(从模型中采样) 本文基于Hugging Face&#x…...
华为CD32键盘使用教程
华为CD32键盘使用教程 用爱发电写的教程! 最后更新时间:2023.9.12 型号:华为有线键盘CD32 基本使用 此键盘在不安装驱动的情况下可以直接使用,但是不安装驱动指纹识别是无法使用的!并且NFC功能只支持华为的部分电脑…...

第三节:在WORD为应用主窗口下关闭EXCEL的操作(2)
【分享成果,随喜正能量】凡事好坏,多半自作自受,既不是神为我们安排,也不是天意偏私袒护。业力之前,机会均等,毫无特殊例外;好坏与否,端看自己是否能应机把握,随缘得度。…...
(04))
Layui + Flask | 弹出层(组件篇)(04)
提示:点击阅读原文体验更佳 https://layui.dev/docs/2.8/layer/ 弹出层组件 layer 是 Layui 最古老的组件,也是使用覆盖面最广泛的代表性组件。在实现网页弹出层的首选交互方案,使用的非常频繁。 打开弹层 layer.open(options); 参数 options : 基础属性配置项。打开弹层的核…...

Electron和vue3集成(推荐仅用于开发)
本篇我们仅实现Electron和vue3通过先运行起vue3项目,再将vue3的url地址交由Electron打开的方案,仅由Electron在vue3项目上套一层壳来达到脱离本机浏览器运行目的 1、参考快速上手 | Vue.js搭建起vue3初始项目 npm install -g vue npm install -g vue/c…...
Vue.js和TypeScript:如何完美结合
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

034:vue项目利用qrcodejs2生成二维码示例
第034个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...
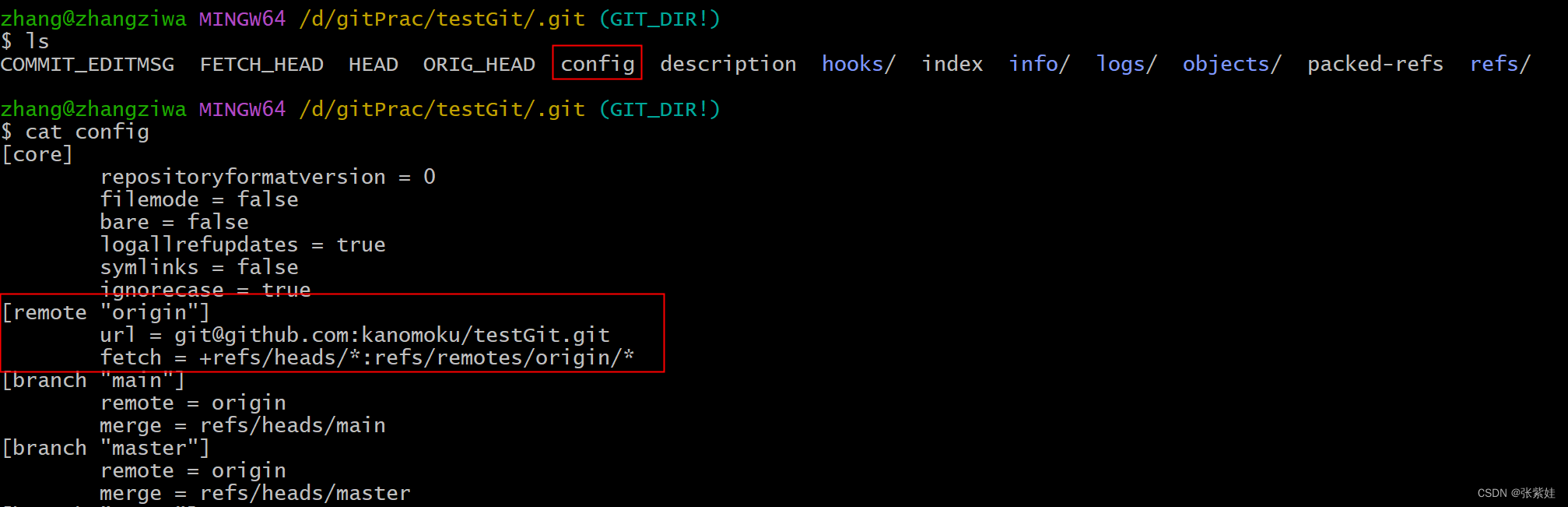
执行 git remote add github git@github.com:xxxx/testGit.git时,git内部做了啥?
git remote add 往 .git/config 中写入了一个叫 [remote "origin"] 配置 url → 表示该远程名称对应的远程仓库地址fetch 参数分为两部分,以冒号 : 进行分割冒号左边 ☞ 本地仓库文件夹冒号右边 ☞ 远程仓库在本地的副本文件夹 ☞ 往里面添加数据的意思 可…...

Makefile基础
迷途小书童 读完需要 4分钟 速读仅需 2 分钟 1 引言 下面这个 C 语言的代码非常简单 #include <stdio.h>int main() {printf("Hello World!.\n");return 0; } 在 Linux 下面,我们使用下面的命令编译就可以 gcc hello.c -o hello 但是随着项目的变大…...

【PickerView案例08-国旗搭建界面加载数据 Objective-C预言】
一、来看我们第三个案例 1.来看我们第三个关于PickerView的一个案例, 首先呢,我要问大家一下, 咱们这个是几组数据呢, 这是一个pickerView,只不过,它显示的是什么,一个界面, 前面两个案例,都是文字 这个案例,开始有图片了, 总结一下这三个案例: 1)第一个案例…...

2023-09-15力扣每日一题
链接: [LCP 50. 宝石补给](https://leetcode.cn/problems/queens-that-can-attack-the-king/) 题意 略 解: 简单题 模拟 实际代码: int giveGem(vector<int>& gem, vector<vector<int>>& operations) {for(…...
系列七、Nginx负载均衡配置
一、目标 浏览器中访问http://{IP地址}:9002/edu/index.html,浏览器交替打印清华大学8080、清华大学8081. 二、步骤 2.1、在tomcat8080、tomcat8081的webapps中分别创建edu文件夹 2.2、将index.html分别上传至edu文件夹 注意事项:tomcat8080的edu文件…...

Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据。更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import time import json#数据下载器 class HtmlDownloader(object):def download(self, url, paramsNone):if url is None:return Noneuser_agent …...
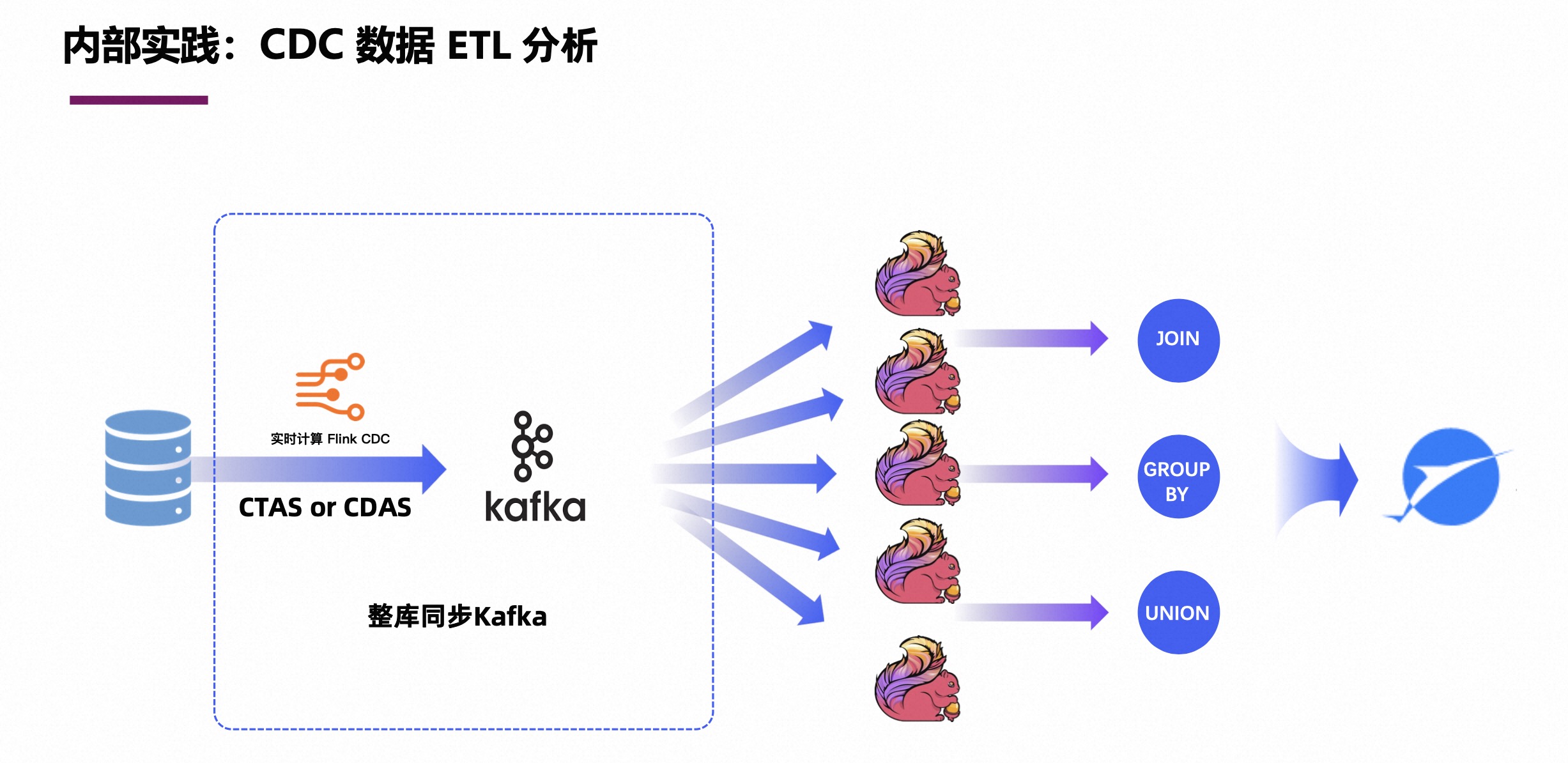
基于 Flink CDC 高效构建入湖通道
本文整理自阿里云 Flink 数据通道负责人、Flink CDC 开源社区负责人, Apache Flink PMC Member & Committer 徐榜江(雪尽),在 Streaming Lakehouse Meetup 的分享。内容主要分为四个部分: Flink CDC 核心技术解析数…...
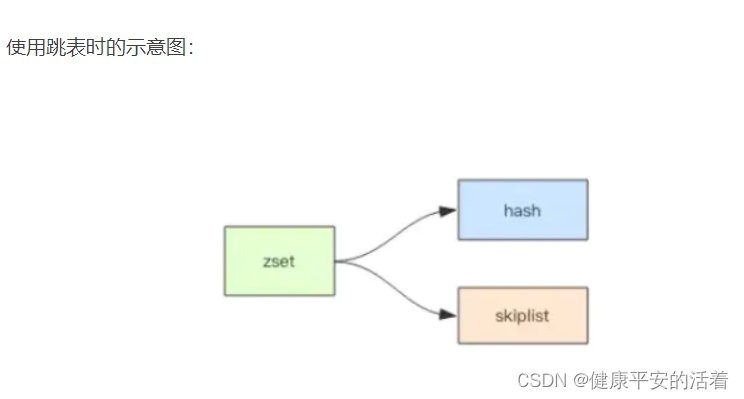
redis的基础底层篇 zset的详解
一 zset的作用以及结构 1.1 zset作用 redis的zset是一个有序的集合,和普通集合set非常相似,是一个没有重复元素的字符串集合。常用作排行榜等功能,以用户 id 为 value,关注时间或者分数作为 score 进行排序。 1.2 zset的底层结…...

5分钟搞定Windows激活:KMS_VL_ALL_AIO一键激活全指南
5分钟搞定Windows激活:KMS_VL_ALL_AIO一键激活全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否刚重装完系统,面对"Windows未激活"的提示感到头疼&…...

如何轻松解锁Cursor Pro完整功能:一键激活与无限使用的完整指南
如何轻松解锁Cursor Pro完整功能:一键激活与无限使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

Python 爬虫进阶技巧:多线程异步爬取大幅提升数据采集速度
前言 常规单线程爬虫采用串行阻塞式请求模式,严格按照 “请求页面 — 解析数据 — 保存入库 — 下一页请求” 的线性流程执行,每一次网络请求都需要等待服务器响应、网络传输延时完成后,才能发起下一次任务。在大批量站点列表、分页数据、多…...

Fujirebio宣布全自动Lumipulse® G pTau 217血浆检测试剂盒获得CE认证
H.U. Group Holdings Inc.及其全资子公司Fujirebio今日宣布,Fujirebio Europe N.V.已依据《欧盟(EU) 2017/746体外诊断医疗器械法规》(IVDR)取得Lumipulse G pTau 217血浆检测试剂盒的CE认证。该化学发光酶免疫分析(CLEIA)检测可对人体血浆(K2 EDTA)中的苏氨酸217磷…...
)
从原理图到PCB:手把手教你搞定PCIE X4接口的完整电路设计(附时钟、电源、热插拔信号详解)
从原理图到PCB:手把手教你搞定PCIE X4接口的完整电路设计 在高速数字电路设计中,PCIE接口因其出色的带宽和稳定性,已成为现代计算机系统中不可或缺的组成部分。无论是主板设计、显卡开发还是各类扩展卡,PCIE接口的正确实现直接关…...
)
不止于透传:用VirtIO-GPU为你的KVM虚拟机开启3D加速(附XML配置详解)
VirtIO-GPU虚拟化加速实战:从原理到配置的深度解析 在虚拟化技术日益成熟的今天,GPU加速已成为开发测试、图形工作站和云桌面等场景的刚需。传统GPU透传方案虽然性能接近原生,但受限于硬件数量且缺乏灵活性。VirtIO-GPU结合virglrenderer的软…...

独立开发者工具箱:模块化架构与全栈实践指南
1. 项目概述:一个独立开发者的工具箱 如果你是一个独立开发者,或者正在尝试构建自己的数字产品,那么你一定经历过这样的时刻:一个想法在脑海中成型,你迫不及待地想把它变成现实,但当你打开编辑器࿰…...

3个步骤搭建Sunshine游戏串流服务器:从零到一的完整指南
3个步骤搭建Sunshine游戏串流服务器:从零到一的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想过在客厅的电视上玩书房电脑里的3A大作…...

AI编程助手代码质量守护:Quality Guardian MCP实战指南
1. 项目概述:为AI编程助手打造的“质量守门员”如果你和我一样,日常重度依赖 Claude Code、Cursor 这类 AI 编程助手来写代码,那你肯定也遇到过这个头疼的问题:助手写的代码,语法上没问题,但一跑静态检查&a…...

低价轻小件承压明显之后跨境卖家如何重设利润安全线
薄利之困:跨境卖家如何重塑利润防线当全球电商平台的促销战鼓擂响,价格一降再降,那些曾经依赖“低价轻小件”策略的跨境卖家们,正感受到前所未有的压力。物流成本波动、平台佣金上涨、同质化竞争加剧……多重因素交织下࿰…...