从原理到实践 | Pytorch tensor 张量花式操作
文章目录
- 1.张量形状与维度
- 1.1标量(0维张量):
- 1.2 向量(1维张量):
- 1.3矩阵(2维张量):
- 1.4高维张量:
- 2. 张量其他创建方式
- 2.1 创建全零或全一张量:
- 2.2 创建随机张量:
- 2.3 创建单位矩阵:
- 2.4 创建序列张量:
- 3. 张量元素
- 3.1 查看元素类型
- 3.2 张量元素类型转换
- 4. 张量运算
- 4.1 张量的基本运算
- p.2 张量间乘法点积运算
- 4.3 张量元素运算函数
- 4.3.1逐元素运算函数:
- 4.3.2 统计汇总运算函数
- 5.张量的拼接 切片 扩展 重塑 改变形状等操作
- 5.1 张量拼接(Concatenation):
- 5.2 张量切片(Slicing):
- 5.3 张量转置(Transpose):
- 5.4 张量形状重塑:
- 6.广播机制
- 6.1 张量+标量
- 6.2 张量+张量
Tensor(张量)是一种多维数组(通常是数字)数据类型,是深度学习和机器学习中最基本的数据结构之一。
PyTorch提供了一种直观的方式来创建和操作张量,而且它还支持GPU加速,这对于深度学习任务非常重要。我们可以使用PyTorch来定义神经网络模型、进行前向传播和反向传播,以及许多其他深度学习任务,因而了解张量是了解这些任务的基础。
1.张量形状与维度
维度(Rank):张量的维度也称为秩(rank),表示张量中轴(或维度)的数量。标量是0维张量,向量是1维张量,矩阵是2维张量,以此类推。
我们使用**.shape** 查看形状,.ndim属性查看维度
当使用PyTorch库时,我们可以轻松地创建和操作张量。下面是使用PyTorch创建不同秩的张量的示例代码:
1.1标量(0维张量):
import torchscalar = torch.tensor(5) # 创建一个标量
print("Scalar:", scalar)
print("Scalar的秩(Rank):", scalar.ndim) # 输出0,表示秩为0
print("Scalar的形状", scalar.shape) #输出torch.Size([]) #输出torch.Size([])此时形状向量输出为空
1.2 向量(1维张量):
import torchvector = torch.tensor([1, 2, 3, 4]) # 创建一个向量
print("Vector:", vector)
print("Vector的秩(Rank):", vector.ndim ) # 输出1,表示秩为1
print("vector的形状", vector.shape) #输出torch.Size([4])
1.3矩阵(2维张量):
import torchmatrix = torch.tensor([[1, 2, 3], [4, 5, 6]]) # 创建一个2x3的矩阵
print("Matrix:")
print(matrix)
print("Matrix的秩(Rank):", matrix.ndim # 输出2,表示秩为2
print("Matrix的形状:", matrix.shape # 输出torch.Size([2,3]) 2x3的矩阵
1.4高维张量:
import torch
tensor_3d = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) # 创建一个2x2x2的3维张量
print("3D Tensor:")
print(tensor_3d)
print("3D Tensor的秩(Rank):", tensor_3d.ndim) # 输出3,表示秩为3
print("3D Tensor的形状:", tensor_3d.shape ) # 输出torch.Size([2,2,2]) 2x2x2的3维张量
2. 张量其他创建方式
以上我们实际上是通过torch.tensor函数把列表转换为tensor张量
除此之外,还有一些其他torch内置函数的创建方式
2.1 创建全零或全一张量:
# 创建特定形状的全零张量
zeros_tensor = torch.zeros(3, 2) #创建形状(3,2)的全零张量# 创建特定形状的全一张量
ones_tensor = torch.ones(2, 3)#创建形状(2,3)的全一张量
2.2 创建随机张量:
# 创建特定形状的随机均匀分布的张量 每个元素都会随机生成,取值范围是大于等于0且小于1的浮点数。
uniform_random = torch.rand(2, 2) #形状(2,2)# 创建随机正态分布的张量
normal_random = torch.randn(3, 3) #形状(3,3)
2.3 创建单位矩阵:
# 创建单位矩阵
identity_matrix = torch.eye(4)
输出
tensor([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
2.4 创建序列张量:
# 创建从0到4的张量
sequence_tensor = torch.arange(5)# 创建从2到10的张量,步长为2
sequence_with_step = torch.arange(2, 11, step=2)
3. 张量元素
张量中的每个值称为元素。根据张量的维度和形状,可以有不同数量的元素。例如,一个形状为(3, 4)的张量将包含12个元素。
每个元素可以有不同的类型
张量可以包含不同的数据类型,如整数、浮点数、布尔值等。常见的数据类型包括int32、float32、bool等
3.1 查看元素类型
使用 .dtype 属性可以查看张量的数据类型。例如:
pythonCopy codeimport torch# 创建一个张量
tensor = torch.tensor([1, 2, 3, 4], dtype=torch.float32)# 查看张量的数据类型
print(tensor.dtype)
输出将显示张量的数据类型,例如 torch.float32
注意,python其他数据类型查看是通过type函数(),注意区分,距离如下
# 定义不同类型的变量
integer_variable = 42
float_variable = 3.14
string_variable = "Hello, World!"
list_variable = [1, 2, 3]
dictionary_variable = {"name": "John", "age": 30}# 使用 type() 函数查看数据类型
print(type(integer_variable)) # <class 'int'>
print(type(float_variable)) # <class 'float'>
print(type(string_variable)) # <class 'str'>
print(type(list_variable)) # <class 'list'>
print(type(dictionary_variable)) # <class 'dict'>
3.2 张量元素类型转换
通过to函数() 或者用type()函数
注意这里的type()函数是tensor张量自己带的,不是上面讲到3.1讲到的python内的type函数
import torch
# 创建一个整数类型的张量
int_tensor = torch.tensor([1, 2, 3, 4],dtype=torch.int32)# 将整数类型的张量转换为浮点数类型 或者 float_tensor = int_tensor.type(torch.float32)
float_tensor = int_tensor.to(torch.float32)# 查看新的张量的数据类型
print(float_tensor.dtype)
输出为 torch.float32
注意 执行to函数之后必须进行赋值操作,否则该操作就丢失了,查看下面的代码
import torch
# 创建一个整数类型的张量
int_tensor = torch.tensor([1, 2, 3, 4],dtype=torch.int32)
# 将整数类型的张量转换为浮点数类型
int_tensor.to(torch.float32)
# 查看新的张量的数据类型
print(int_tensor.dtype)
最开始我觉得会输出torch.float32 实际输出torch.int32
4. 张量运算
4.1 张量的基本运算
- 加法和减法:可以使用
+和-运算符执行张量的逐元素加法和减法。 - 乘法和除法:可以使用
*和/运算符执行逐元素的乘法和除法。 - 幂运算:使用
**运算符进行幂运算。 - 取负值:使用
-运算符取张量的负值。
import torch# 创建两个示例张量
tensor1 = torch.tensor([1.0, 2.0, 3.0])
tensor2 = torch.tensor([4.0, 5.0, 6.0])# 加法和减法
result_addition = tensor1 + tensor2 # 逐元素加法
result_subtraction = tensor1 - tensor2 # 逐元素减法# 乘法和除法
result_multiplication = tensor1 * tensor2 # 逐元素乘法
result_division = tensor1 / tensor2 # 逐元素除法# 幂运算
exponent = 2
result_power = tensor1 ** exponent # 每个元素求平方# 取负值
result_negation = -tensor1 # 每个元素取负值print("Addition:", result_addition)
print("Subtraction:", result_subtraction)
print("Multiplication:", result_multiplication)
print("Division:", result_division)
print("Power:", result_power)
print("Negation:", result_negation)输出
p.2 张量间乘法点积运算
-
矩阵相乘:
使用
torch.matmul()函数或@运算符 或**torch.mm()** 可以执行两个张量(矩阵)的矩阵相乘。矩阵相乘要求左边矩阵的列数等于右边矩阵的行数。import torch# 创建两个示例矩阵 matrix1 = torch.tensor([[1, 2], [3, 4]]) matrix2 = torch.tensor([[5, 6], [7, 8]])# 矩阵相乘 matmul result_matrix_mul_1 = torch.matmul(matrix1, matrix2) # 或者使用 @ 运算符 result_matrix_mul_2 = matrix1 @ matrix2 # 矩阵相乘 mm result_matrix_mul_3=torch.mm(matrix1, matrix2)print("Matrix Multiplication:") print(result_matrix_mul_1) print(result_matrix_mul_2) print(result_matrix_mul_3)输出将是两个矩阵相乘的结果
Matrix Multiplication:
tensor([[19, 22],
[43, 50]])
tensor([[19, 22],
[43, 50]])
tensor([[19, 22],
[43, 50]]) -
批量矩阵相乘:
使用
torch.matmul()函数和**@运算符可以执行两个张量的批量矩阵相乘。这对于同时处理多个矩阵非常有用,但要求最后两个维度必须是矩阵的维度**。而mm只能用于单个矩阵乘法import torch# 创建两个批量矩阵(3个2x2矩阵) batch_matrix1 = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]], [[9, 10], [11, 12]]]) batch_matrix2 = torch.tensor([[[2, 0], [1, 2]], [[-1, -2], [-3, -4]], [[0, 1], [-1, 0]]])# 执行批量矩阵相乘 result_batch_matrix_mul_1 = batch_matrix1 @ batch_matrix2 result_batch_matrix_mul_2 =torch.matmul(batch_matrix1,batch_matrix2) # 或者使用 @ 运算符 # result_batch_matrix_mul = batch_matrix1 @ batch_matrix2print("Batch Matrix Multiplication:") print(result_batch_matrix_mul_1) print(result_batch_matrix_mul_2)输出将是批量矩阵相乘的结果
输出
Batch Matrix Multiplication:
tensor([[[ 4, 4],
[ 10, 8]], [[-23, -34],
[-31, -46]],[[-10, 9],[-12, 11]]])tensor([[[ 4, 4],
[ 10, 8]],[[-23, -34],[-31, -46]], [[-10, 9],
[-12, 11]]]) -
点积:
点积是两个向量的内积,也可以视为两个矩阵的逐元素乘法后的和。在 PyTorch 中,可以使用
torch.dot()函数来计算两个一维张量的点积。import torch# 创建两个一维示例张量 vector1 = torch.tensor([1, 2, 3]) vector2 = torch.tensor([4, 5, 6])# 计算点积 dot_product = torch.dot(vector1, vector2)print("Dot Product:") print(dot_product)输出将是两个向量的点积结果
Dot Product:
tensor(32)
4.3 张量元素运算函数
tensor张量还会自带很多的运算函数,方便我们的操作
4.3.1逐元素运算函数:
这些运算将分别应用于张量的每个元素,结果将生成一个与原始张量相同形状的新张量。
torch.abs(tensor):计算张量中每个元素的绝对值。torch.sqrt(tensor):计算张量中每个元素的平方根。torch.exp(tensor):计算张量中每个元素的指数值。torch.log(tensor):计算张量中每个元素的自然对数。
4.3.2 统计汇总运算函数
这些运算将返回张量的单个标量值,通常用于统计和汇总。
torch.sum(tensor):计算张量中所有元素的和。torch.mean(tensor):计算张量中所有元素的平均值。torch.max(tensor)和torch.min(tensor):计算张量中的最大值和最小值。torch.argmax(tensor)和torch.argmin(tensor):返回张量中最大值和最小值的索引。torch.unique(tensor):返回张量中的唯一元素。torch.histc(tensor, bins=10, min=0, max=1):计算张量的直方图。
5.张量的拼接 切片 扩展 重塑 改变形状等操作
PyTorch 提供了一系列用于处理和操作张量的运算,包括拼接、切片、转置、扩展和重塑等。以下是这些运算的详细介绍:
5.1 张量拼接(Concatenation):
-
torch.cat(tensors, dim=0):将多个张量沿指定维度dim进行拼接,生成一个新的张量。这在将多个张量连接在一起时非常有用。import torch# 创建两个示例张量 tensor1 = torch.tensor([[1, 2,3], [4, 5,6]]) #(2×3) tensor2 = torch.tensor([[7, 8,9], [10, 11,12]]) #(2×3)# 沿行维度进行拼接 result_concatenation_row = torch.cat((tensor1, tensor2), dim=0) #行维度对应相加,最后拼接后的形状(4×3) result_concatenation_column=torch.cat((tensor1, tensor2), dim=1)#列维度对应相加,最后拼接后的形状(2×6)print("Concatenation:") print(result_concatenation_row) print(result_concatenation_column)
Concatenation:
tensor([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
tensor([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 10, 11, 12]])
5.2 张量切片(Slicing):
-
使用索引和切片运算符
[]对张量进行切片。可以指定要提取的元素的索引或范围。这对于获取部分数据非常有用。import torch# 创建一个示例张量 tensor = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 提取特定元素 element = tensor[0, 1] # 获取第一行第二列的元素# 提取特定行或列 row = tensor[1, :] # 获取第二行的所有元素 column = tensor[:, 2] # 获取第三列的所有元素print("Element:", element) print("Row:", row) print("Column:", column)
Element: tensor(2)
Row: tensor([4, 5, 6])
Column: tensor([3, 6, 9])
5.3 张量转置(Transpose):
-
torch.transpose(tensor, dim0, dim1):将张量的指定维度进行转置,生成一个新的张量。这对于调整张量的维度顺序非常有用。import torch# 创建一个示例张量 tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])# 转置张量 transposed_tensor = torch.transpose(tensor, dim0=0, dim1=1) # 交换行和列print("Transposed Tensor:") print(transposed_tensor)
输出
Transposed Tensor:
tensor([[1, 4],
[2, 5],
[3, 6]])
5.4 张量形状重塑:
-
tensor.view(new_shape)或者函数tensor.reshape(new_shape)将张量的形状重塑为新的形状,生成一个新的张量。这对于改变张量的形状非常有用,但要确保新形状与原始形状兼容。pythonCopy codeimport torch# 创建一个示例张量 tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])# 重塑张量的形状 reshaped_tensor = tensor.view(3, 2) # 将2x3矩阵重塑为3x2矩阵print("Reshaped Tensor:") print(reshaped_tensor)
这些张量操作非常有用,可用于处理和操作 PyTorch 张量,适应不同的任务和需求。请根据您的具体情况选择适当的操作。
6.广播机制
广播(Broadcasting)是一种在 PyTorch 中执行元素级运算的机制,它允许在不同形状的张量之间进行运算,而无需显式地扩展(重复复制)其中一个张量。广播使得在不同形状的张量上执行操作更加方便,因为它自动调整张量的形状,以使其兼容。
6.1 张量+标量
import torch# 创建示例张量
tensor = torch.tensor([[1, 2], [3, 4]])# 使用广播将标量加到矩阵的每个元素上
scalar = 2
result_broadcasting = tensor + scalarprint("Broadcasting:")
print(result_broadcasting)
输出
Broadcasting:
tensor([[3, 4],
[5, 6]])
6.2 张量+张量
广播规则如下:
不要求两个张量维度数相等,但要求从右向左逐一比较张量的维度(直到维度低的向量比较完毕)满足以下两个条件之一即可
(1)两个张量该维度相等
(2)其中一个张量该维度是1
如果在某一维度的比较上两者都不满足,则会引发广播错误。
tensor_1=torch.ones(2,3,4) #2*3*4tensor_2=torch.ones(3,1) #3*1tensor=tensor_2+tensor_1
print(tensor)
如上,从右向左 ,第一维(4和1 )虽然不相等,但tensor_2为1 满足条件(2)
继续从右向左,第二维(3,3 )相等,满足条件(1)
此时低维向量比较完毕,所以上述两者可以广播
tensor_1=torch.ones(2,3,3)#2*3*2tensor_2=torch.ones(2,1) #2*3tensor=tensor_2+tensor_1
print(tensor)
而这个例子,从右向左 ,第一维(3和1 )虽然不相等,但tensor_2为1 满足条件(2)
继续从右向左,第二维(3,2 )不相等,不满足条件(1),也不满足条件(2),引发广播失败
相关文章:

从原理到实践 | Pytorch tensor 张量花式操作
文章目录 1.张量形状与维度1.1标量(0维张量):1.2 向量(1维张量):1.3矩阵(2维张量):1.4高维张量: 2. 张量其他创建方式2.1 创建全零或全一张量:2.2…...

无涯教程-JavaScript - TRANSPOSE函数
描述 TRANSPOSE函数将单元格的垂直范围作为水平范围返回,反之亦然。必须将TRANSPOSE函数作为数组公式输入,该范围必须具有与行范围和列范围相同的行和列数。 您可以使用TRANSPOSE在工作表上移动数组或范围的垂直和水平方向。 语法 TRANSPOSE (array)键入函数后,按CTRL SHI…...
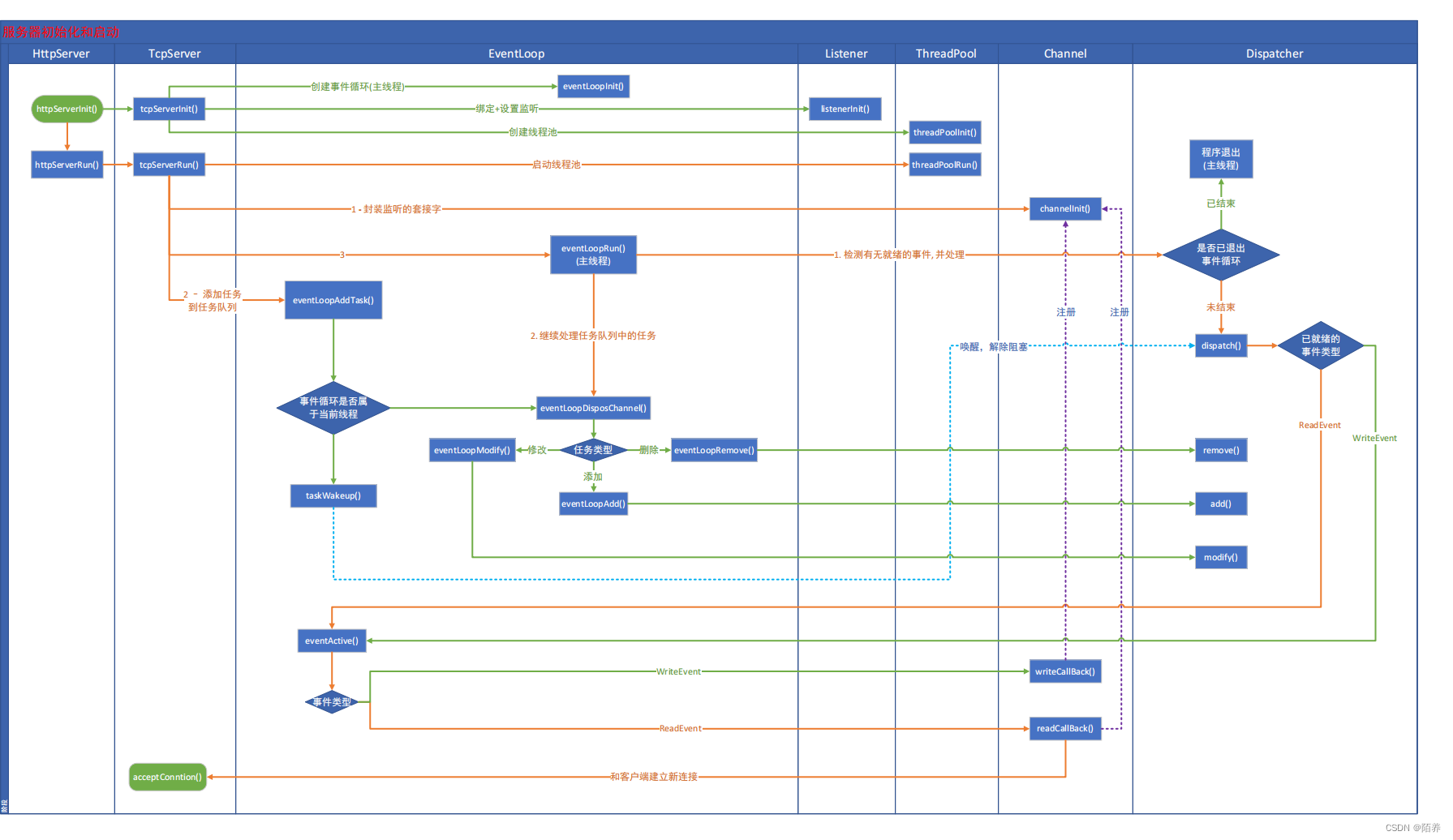
Webserver项目解析
一.webserver的组成部分 Buffer类 用于存储需要读写的数据 Channel类 存储文件描述符和相应的事件,当发生事件时,调用对应的回调函数 ChannelMap类 Channel数组,用于保存一系列的Channel Dispatcher 监听器,可以设置为epo…...

Spring Cloud 篇
1、什么是SpringCloud ? Spring Cloud 流应用程序启动器是基于 Spring Boot 的 Spring 集成应用程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微服务框架,用于快速构建执行有限数据处理的应用程序。 2、什么…...

vim,emacs,verilog-mode这几个到底是啥关系?
vim:不多说了被各类coder誉为地表最强最好用的编辑器;gvim,gui vim的意思; emacs:也是一个编辑器,类似vscode; vim在使用的时候为了增强其功能,有好多好多插件,都是以.…...

解决npm run build 打包出现XXXX.js as it exceeds the max of 500KB.
问题描述: npm run build 时出现下面的问题: Note: The code generator has deoptimised the styling of D:\base\node_modules\_element-ui2.15.12element-ui\lib\element-ui.common.js as it exceeds the max of 500KB.在项目的根目录加粗样式下找到 …...

Java 抖音小程序SDK
抖音小程序SDK,抖音SDK 码云地址:dy-open-sdk: 字节跳动,抖音小程序sdk...
Vue.js的服务器端渲染(SSR):为什么和如何
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

Gin 打包vue或react项目输出文件到程序二进制文件
Gin 打包vue或react项目输出文件到程序二进制文件 背景解决方案1. 示例目录结构2. 有如下问题要解决:3. 方案探索 效果 背景 前后端分离已成为行业主流,vue或react等项目生成的文件独立在一个单独目录,与后端项目无关。 实际部署中,通常前面套…...
深度解析shell脚本的命令的原理之pwd
pwd是Print Working Directory的缩写,是一个Unix和Linux shell命令,用于打印当前工作目录的绝对路径。以下是对这个命令的深度解析: 获取当前工作目录:pwd命令通过调用操作系统提供的getcwd(或相应的)系统调…...

Kafka3.0.0版本——消费者(分区的分配以及再平衡)
目录 一、分区的分配以及再平衡1.1、消费者分区及消费者组的概述1.2、如何确定哪个consumer来消费哪个partition的数据1.3、消费者分区分配策略 一、分区的分配以及再平衡 1.1、消费者分区及消费者组的概述 一个consumer group中有多个consumer组成,一个 topic有多…...
Kotlin文件遍历FileTreeWalk filter
Kotlin文件遍历FileTreeWalk filter import java.io.Filefun main(args: Array<String>) {val filePath "."val file File(filePath)val fileTree: FileTreeWalk file.walk()fileTree//.maxDepth(1) //遍历层级1,不检查子目录.filter {it.isFile…...

Activiti兼容达梦数据库
1. 自定义类继承SpringProcessEngineConfiguration类,重写initDatabaseType方法。 package com.ydtf.cbda.module.cbdacim.improcess.config;import org.activiti.engine.ActivitiException; import org.activiti.spring.SpringProcessEngineConfiguration; import…...

shell 流程控制
流程控制 if条件判断 可以使用if来实现多路跳转,条件通常使用test命令 #if语句的语法if condition1then command1elif condition2 then command2else commandNfi 如果then需要和if放在同一行的话,使用;分隔 fi用来结束if语句,相当于…...

【C++】红黑树插入操作实现以及验证红黑树是否正确
文章目录 前言一、红黑树的插入操作1.红黑树结点的定义2.红黑树的插入1.uncle存在且为红2.uncle不存在3.uncle存在且为黑 3.完整代码 二、是否为红黑树的验证1.IsBlance函数2.CheckColor函数 三、红黑树与AVL树的比较 前言 红黑树,是一种二叉搜索树,但在…...
学信息系统项目管理师第4版系列07_项目管理知识体系
1. 项目管理原则 1.1. 勤勉、尊重和关心他人 1.1.1. 关键点 1.1.1.1. 关注组织内部和外部的职责 1.1.1.2. 坚持诚信、关心、可信、合规原则 1.1.1.3. 秉持整体观 1.1.2. 职责 1.1.2.1. 诚信 1.1.2.2. 关心 1.1.2.3. 可信 1.1.2.4. 合规 1.2. 营造协作的项目管理团队…...

Leetcode 2851. String Transformation
Leetcode 2851. String Transformation 0. 吐槽1. 算法思路 1. 整体思路2. 字符串匹配优化 2. 代码实现 题目链接:2851. String Transformation 0. 吐槽 这道题多少有点坑爹,题目本身挺有意思的,是一道数组题目,其实用数学方法…...

在PHP8中对数组进行计算-PHP8知识详解
在php8中,提供了丰富的计算函数,可以对数组进行计算操作。常见的计算函数如下几个:array_sum()函数、array_merge()函数、array_diff()函数、array_diff_assoc()函数、array_intersect()函数、array_intersect_assoc()函数。 1、array_sum()函…...

Android BottomSheetDialog最大展开高度问题
修改界面的时候遇到了这个问题,这个问题比较简单,网上解决方案也很多,这是 peekHeight 半展开高度,毕竟只是 dialog,全铺满就我们不必考虑 dialog 了 方法是在DialogFragment初始化dialog时处理 companion object {/*** 设置弹窗高度 默认展开无折叠情况 */ const val …...

记录Linux部署人脸修复GFPGAN项目Docker Python 使用
记录Linux 服务器使用人脸修复GFPGAN 项目 1:阿里云安装docker,用docker 是隔离环境,Python环境还真是麻烦… https://help.aliyun.com/zh/ecs/use-cases/deploy-and-use-docker-on-alibaba-cloud-linux-2-instances 2:关于docker 镜像,想找个好的镜像也是很难,百度吧,很多Li…...

AI编程助手集成飞书MCP:零依赖单文件实现工作流自动化
1. 项目概述:连接AI编程助手与飞书工作流 如果你和我一样,每天的工作流都离不开飞书(Lark)——写文档、拉群沟通、排会议日程、更新多维表格,然后在IDE和浏览器之间来回切换,那么你一定会对这个项目感兴趣…...

物联网安全认证:X.509证书的局限与替代方案实战解析
1. 项目概述:当X.509证书认证在IoT安全中“失灵”的深度剖析几年前,一份在DEFCON大会上披露的论文揭示了一个令人震惊的事实:互联网上存在大量未受保护的MQTT代理服务器。这些“门户大开”的代理,结合MQTT协议本身允许使用通配符订…...

一文搞懂JTT1078:车载视频监控协议科普+开发入门
之前聊过JTT808,很多朋友私信问我,车载监控里的视频画面、语音对讲靠什么实现的?答案很简单——JTT1078协议。如果说JTT808是车载监控的“骨架”,负责定位和基础状态传输,那JTT1078就是“神经”,专门管音视…...

硬件项目规划:从确定性预测到适应性导航的思维重构
1. 项目概述:硬件项目规划的“信心危机”“计划失败就是计划失败”,这个标题乍一看像是一句绕口令,但当你身处一个硬件开发团队,尤其是负责ASIC、FPGA或复杂嵌入式系统时,这句话背后的沉重感会瞬间变得无比真实。我们常…...

基于RAG与向量数据库的本地化个人知识库构建实践
1. 项目概述:一个为个人量身定制的知识库构建引擎 如果你和我一样,每天在浏览器、笔记软件、PDF文档和各种聊天记录之间疲于奔命,试图抓住那些一闪而过的灵感和零散的知识点,那么你肯定理解“知识碎片化”的痛苦。我们收藏了无数…...

【PyTorch实战】从零构建CNN模型:MNIST手写数字识别全流程解析
1. 环境准备与数据加载 第一次接触PyTorch时,我对着官方文档折腾了半天环境配置。后来发现用Anaconda管理Python环境真是省心,这里分享我的配置经验。建议先安装Anaconda最新版,然后创建专属环境: conda create -n pytorch_env py…...

新手小白必看!AI大模型自学路线图,从入门到精通_自学AI大模型学习路线推荐
自学AI大模型学习路线推荐 今天,我想和大家分享一条自学AI大模型的学习路线,希望能帮助新手小白们更好地进入这个领域。 1. 打好基础:数学与编程 数学基础 线性代数:理解矩阵、向量、特征值、特征向量等概念。推荐课程:…...

LLM长文本处理实战:模块化分割策略与向量化预处理指南
1. 项目概述:一个为LLM打造的文本处理中心如果你和我一样,经常和大型语言模型打交道,无论是用它来总结文档、分析代码,还是处理客服对话,那你肯定遇到过这个痛点:喂给模型的文本太长了怎么办?模…...

鸣潮帧率解锁终极指南:用WaveTools轻松突破120FPS限制
鸣潮帧率解锁终极指南:用WaveTools轻松突破120FPS限制 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 还在为鸣潮游戏中被锁定的60FPS帧率而烦恼吗?想让你的高刷新率显示器发挥真正…...

从零构建开发者效率工具:CLI脚手架与自动化工作流实践
1. 项目概述与核心价值最近在开源社区里,一个名为smouj/smouj的项目引起了我的注意。乍一看这个标题,可能会让人有些摸不着头脑,它不像常见的vue/vue或tensorflow/tensorflow那样直白地揭示了其技术栈。但恰恰是这种看似“神秘”的命名&#…...