【自学开发之旅】Flask-标准化返回-连接数据库-分表-orm-migrate-增删改查(三)
业务逻辑不能用http状态码判断,应该有自己的逻辑判断。想要前端需要判断(好多if…else),所以需要标准化,标准化返回。
json标准化返回:
最外面:data,message,code三个字段。
data:返回的数据
code:应用状态码:先设计好,成功-0,失败–登录失败1,注册失败2
msg:返回的说明
我们写的接口也要按照这个格式来
添加libs/response.py
def generate_response(data = None, msg = "success!", code = 10000):# 约定返回的数据格式if data is None:data = []return {"code": code,"msg": msg,"data": data}
然后修改返回:
login.py
from flask import Blueprint, request
from config.settings import user_dict
from libs.response import generate_responselogin_bp = Blueprint("login_bp", __name__, url_prefix="/v1")@login_bp.route("login")
def login():user = request.json.get("username")passwd = request.json.get("passwd")local_user_passwd = user_dict.get(user)if local_user_passwd and passwd == local_user_passwd:return generate_response(msg="success")return generate_response(msg="login fail!", code=10001)
register.py
from flask import Blueprint, request
from config.settings import user_dict
from libs.response import generate_responseregister_bp = Blueprint("register_bp", __name__, url_prefix="/v1")@register_bp.route("register")
def register():username = request.json.get("username")passwd = request.json.get("passwd")re_passwd = request.json.get("re_passwd")if not (username and passwd and re_passwd):return generate_response(msg="参数传递不完整", code=3)elif passwd != re_passwd:return generate_response(msg="注册密码不一致", code=2)elif username in user_dict:return generate_response(msg="用户已注册",code=1)else:user_dict[username] = passwdprint(f"user_dict is {user_dict}")return generate_response(msg="register success!", code=10000)
连接数据库(为了避免频繁的打开关闭消耗过多资源)
libs/conn_mysql.py
import pymysql
from config.settings import DB_PASS, DB_PORT, DB_SCHEM, DB_USER, DB_HOSTdef conn_mysql():conn = pymysql.connect(host = DB_HOST,port = DB_PORT,user = DB_USER,password = DB_PASS,db = DB_SCHEM)return conn
为了只连一次,绑到app上
app.py添加:
上面返回了一个连接对象conn,把他作为一个属性交给了sq_app对象,再给sq_app对象随意的可以设置属性,自己定义(mysql_db)。所以把连接交给了app。
def create_app():#连接数据库sq_app.mysql_db = conn_mysql()
刚好flask提供了一个current_app,在你请求过来的时候,会把你当前的app的上下文内容放在current_app里。
router/product_view/product.py
from . import product_bp
from flask import current_app
from libs.response import generate_response@product_bp.route("/product/get")
def get_product():# import pymysql# db = pymysql.connect(host='192.168.1.150',# user='jiangda97',# password='Jiangda123#',# database='sq-flask')cursor = current_app.mysql_db.cursor()cursor.execute("select * from product_info")data = cursor.fetchall()print(data)# db.close()if data:return generate_response(data=data, msg="get product info success!")else:return generate_response(msg="get data empty", code = 4)
router/product_view/__init__.py
from flask import Blueprint
product_bp = Blueprint("product_bp", __name__, url_prefix="/v1")from . import product
分表
优点:节省空间,避免数据不必要的膨胀。
缺点:
新增了一个product_kind_table表
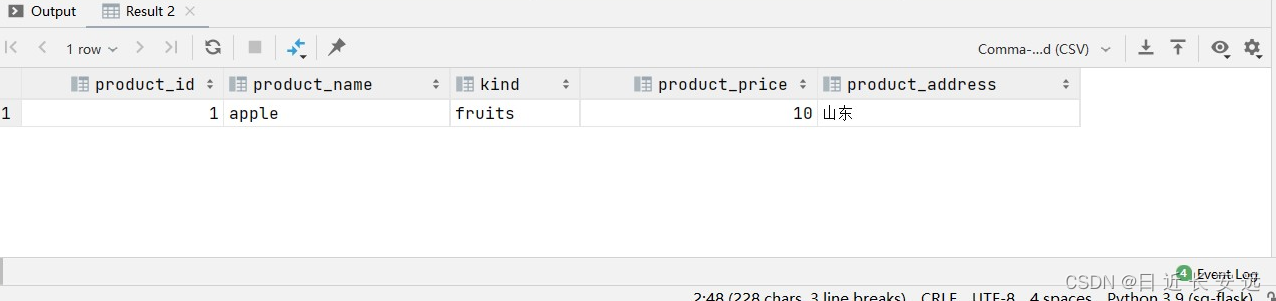
select product_info.product_id, product_info.product_name, product_kind_table.kind, product_info.product_price, product_info.product_address
from product_info inner join product_kind_table
on product_kind = id
where product_id = 1
修改代码router/product_view/product.py
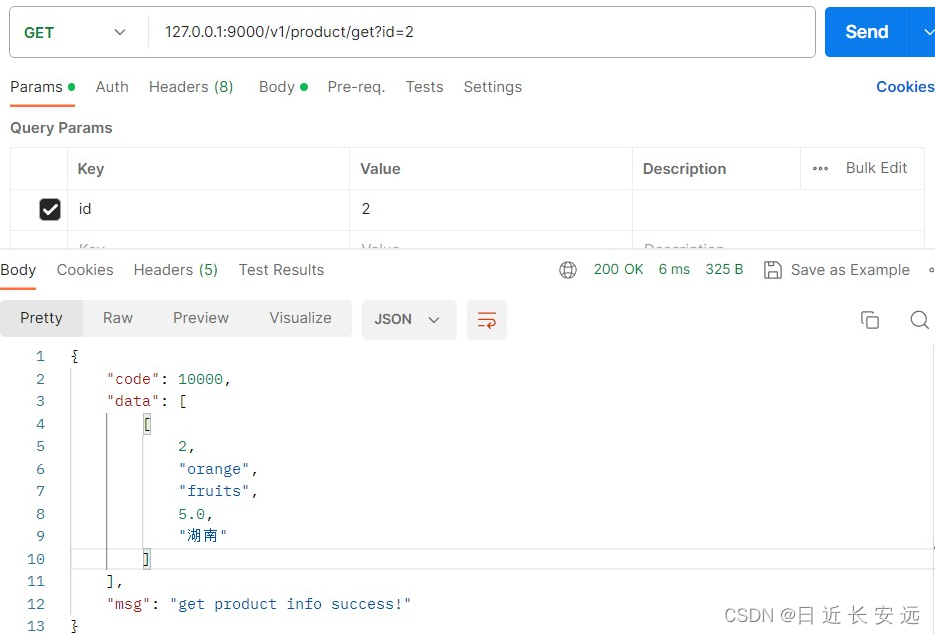
# 通过url携带参数来传递idid = request.args.get("id")if id is None:sql_str = f"select product_info.product_id, product_info.product_name, product_kind_table.kind, product_info.product_price, product_info.product_address \from product_info inner join product_kind_table \on product_kind = id\where product_id = {id}"else:sql_str = f"select product_info.product_id, product_info.product_name, product_kind_table.kind, product_info.product_price, product_info.product_address \from product_info inner join product_kind_table \on product_kind = id\where product_id = {id}"cursor = current_app.mysql_db.cursor()cursor.execute(sql_str)data = cursor.fetchall()# print(data)# db.close ()if data:return generate_response(data=data, msg="get product info success!")else:return generate_response(msg="get data empty", code = 4)
ORM
object relation mapping对象关系映射

orm对象持久化对象
数据库的表 – 类
表中的字段 – 属性
一行行记录 – 对象
models/__init__.py
from flask_sqlalchemy import SQLAlchemy#生成对象映射实例(db就是我们的中间层)
db = SQLAlchemy()def init_app_db(app):db.init_app(app)
models/product.py
from . import dbclass ProductInfo(db.Model):__tablename__ = "product_info"product_id = db.Column(db.Integer, primary_key=True, autoincrement=True)product_name = db.Column(db.String(256))product_kind = db.Column(db.Integer)product_price = db.Column(db.Float)product_address = db.Column(db.String(128))
都得运行:init文件添加from . import product
绑定到核心对象:app.py文件添加
import modelsmodels.init_app_db(sq_app)最后运行报错:
RuntimeError: Either ‘SQLALCHEMY_DATABASE_URI’ or ‘SQLALCHEMY_BINDS’
must be set.
意思是需要设置这两个变量,即orm映射的数据库信息。
config/settings.py添加
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://jiangda97:Jiangda123#@192.168.1.150:3306/sq-flask"
之前我们在app.py将settings都读入sq_app.config里了,且是都大写的key。
刚好我们的SQLAchemy底层就是会自动读取sq_app.config里的关于连接数据库的操作。
SQLALCHEMY_DATABASE_URI = “mysql+pymysql://jiangda97:Jiangda123#@192.168.1.150:3306/sq-flask”
底层+用的连接方式://用户名:密码@host:port/数据库名
然后我们准备用它来完成一个增加操作,在router/product_view/product.py
from models.product import ProductInfo
from models import db# 新增数据库记录
@product_bp.route("/product/add", methods=['POST'])
def product_add():# 接收客户端的传递pro_name = request.json.get("proname")pro_kind = request.json.get("prokind")pro_price = request.json.get("proprice")pro_address = request.json.get("proadd")# 实例化类成对象proinfo = ProductInfo()# 设置属性proinfo.product_name = pro_nameproinfo.product_kind = pro_kindproinfo.product_price = pro_priceproinfo.product_address = pro_address# 实例化并设置属性也可以这么写# proinfo = ProductInfo(product_name = pro_name,# product_kind = pro_kind,# product_price = pro_price,# product_address = pro_address)# 生效到数据库db.session.add(proinfo)db.session.commit()return generate_response(msg="add success!")

migrate
添加models/product.py
在该类下
add_time = db.Column(db.DateTime, default=datetime.datetime.now())
数据库迁移工具,版本管理 – flask-migrate
改server.py
# 数据库迁移工具,版本管理 -- flask-migrate
from flask_migrate import Migrate
from models import dbmigrate = Migrate(sq_app, db)if __name__ == '__main__':sq_app.run(host = sq_app.config['HOST'],port = sq_app.config['PORT'],debug = sq_app.config['DEBUG'])
方便开发,不改变应用逻辑,只是方便我们把orm映射的类,这个添加的字段生效到数据库,不需要自己修改数据库了。
terminal中输入该命令,(在命令行操控flask – flask cli)
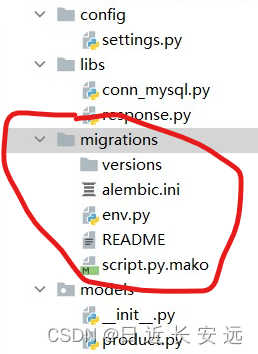
(venv) D:\sq-flask>flask --app server:sq_app db init
Creating directory 'D:\\sq-flask\\migrations' ... done
Creating directory 'D:\\sq-flask\\migrations\\versions' ... done
Generating D:\sq-flask\migrations\alembic.ini ... done
Generating D:\sq-flask\migrations\env.py ... done
Generating D:\sq-flask\migrations\README ... done
Generating D:\sq-flask\migrations\script.py.mako ... done
Please edit configuration/connection/logging settings in 'D:\\sq-flask\\migrations\\alembic.ini' befor
e proceeding.然后就会产生一个migrations的文件夹
migrate单独用不了,借助flask cli命令行工具,migrate绑定好app后,自动创建好db命令。
初始化flask --app server:sq_app db init
–app 指定运行哪个app
初始化会创建migrations的文件夹
可以随时删,再init,做了修改,提交版本!
(venv) D:\sq-flask>flask --app server:sq_app db migrate -m "add time"
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected removed table 'product_kind_table'
INFO [alembic.autogenerate.compare] Detected added column 'product_info.add_time'
INFO [alembic.autogenerate.compare] Detected NULL on column 'product_info.product_name'
INFO [alembic.autogenerate.compare] Detected NULL on column 'product_info.product_kind'
INFO [alembic.autogenerate.compare] Detected NULL on column 'product_info.product_price'
INFO [alembic.autogenerate.compare] Detected NULL on column 'product_info.product_address'
Generating D:\衡山\2023-文老师\sq-flask\migrations\versions\43aac3b3bb51_add_time.py ... doneupgrade就可以生效了
(venv) D:\sq-flask>flask --app server:sq_app db upgrade
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> 43aac3b3bb51, add time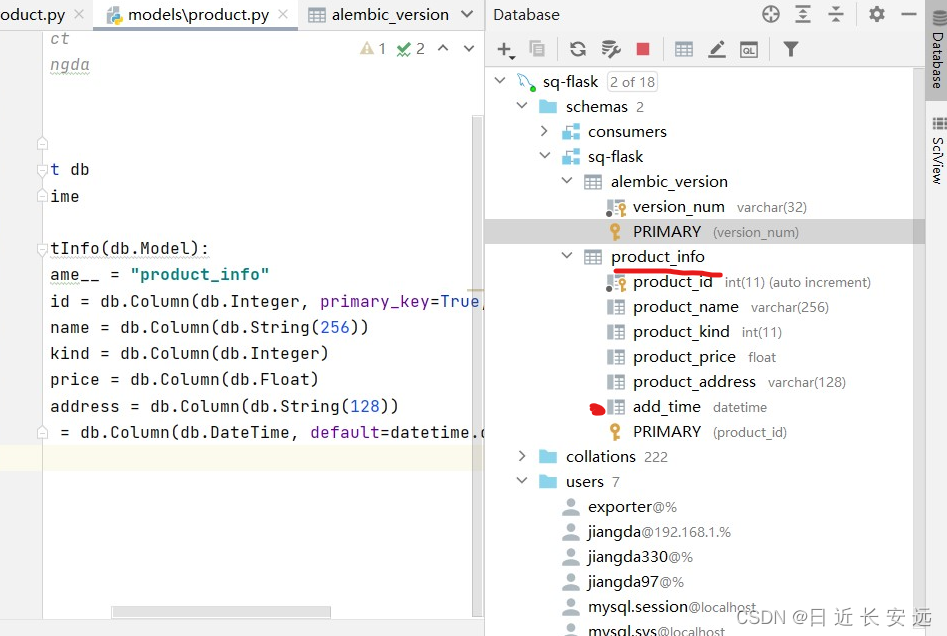
严格按照orm定义好的模型,保持数据库和模型一致,如果数据库有,orm定义的模型没有,则会把数据库多出来的删掉。
回退:flask --app server:sq_app db downgrade
命令行进入上下文环境:(用来测试调试代码)
flask --app server:sq_app shell
(venv) D:\sq-flask>flask --app server:sq_app shell
Python 3.9.1 (tags/v3.9.1:1e5d33e, Dec 7 2020, 17:08:21) [MSC v.1927 64 bit (AMD64)] on win32
App: app
Instance: D:\sq-flask\instance
>>> from models.product import ProductInfo
>>> p1 = ProductInfo()
>>> p1.product_name = "3333"
>>> p1.product_kind = 2
>>> p1.product_price = 22
>>> p1.product_address = "山东"
>>> from models import db
>>> db.session.add(p1)
>>> db.session.commit()
>>>查询和修改:
修改其属性。
>>> p2 = ProductInfo.query.get(3)
>>> p2
<ProductInfo 3>
>>> dir(p2)
['__abstract__', '__annotations__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__for
mat__', '__fsa__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__',
'__lt__', '__mapper__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__
', '__sizeof__', '__str__', '__subclasshook__', '__table__', '__tablename__', '__weakref__', '_sa_class_manager',
'_sa_instance_state', '_sa_registry', 'add_time', 'metadata', 'product_address', 'product_id', 'product_kind', 'pr
oduct_name', 'product_price', 'query', 'query_class', 'registry']
>>> p2.product_name
'牛肉'
>>> p2.product_name = "牛肌肉"
>>> db.session.add(p2)
>>> db.session.commit()
>>>删除:
>>> p3 = ProductInfo.query.get(4)
>>> db.session.delete(p3)
>>> db.session.commit()综合:id通过url携带参数传递,完成修改和删除
删除:/product/modify – PUT
删除:/product/delete – DELETE
router/product_view/product.py
@product_bp.route("/product/modify", methods=['PUT'])
def product_modify():# 接收客户端的传递携带的参数id = request.args.get("id")p1 = ProductInfo.query.get(id)if p1:# 接收客户端的传递pro_name = request.json.get("proname")pro_kind = request.json.get("prokind")pro_price = request.json.get("proprice")pro_address = request.json.get("proadd")p1.product_name = pro_namep1.product_kind = pro_kindp1.product_price = pro_pricep1.product_address = pro_addressdb.session.add(p1)db.session.commit()return generate_response(msg="modify success!")else:return generate_response(msg="no such product!", code=5)修改:尽管你修改一个,但你提交的时候得提交全部的字段
删除:
@product_bp.route("/product/delete", methods=['DELETE'])
def product_delete():id = request.args.get("id")p2 = ProductInfo.query.get(id)if p2:db.session.delete(p2)db.session.commit()return generate_response(msg="delete success")else:return generate_response(msg="no such product", code=6)
查询:
query.get() 一般用来查询主键
query.all() 查询所有(列表类型)
>>> ProductInfo.query.filter_by(product_kind=1).all()
[<ProductInfo 1>, <ProductInfo 2>]>>> ProductInfo.query.filter(ProductInfo.product_kind == 1).all()
[<ProductInfo 1>, <ProductInfo 2>]相关文章:
【自学开发之旅】Flask-标准化返回-连接数据库-分表-orm-migrate-增删改查(三)
业务逻辑不能用http状态码判断,应该有自己的逻辑判断。想要前端需要判断(好多if…else),所以需要标准化,标准化返回。 json标准化返回: 最外面:data,message,code三个字段。 data:返回的数据 co…...

numpy增删改查
NumPy是一个用于科学计算的Python库,它提供了一个多维数组对象以及许多用于操作这些数组的函数。下面是关于如何在NumPy中进行增删改查操作的一些基本示例: 创建NumPy数组: import numpy as np # 创建一个一维数组 arr np.array([1, 2, 3, …...

【kafka】kafka重要的集群参数配置
如何规划Kafka 对于实际应用的生产环境中,需要尽量先规划设计好集群,避免后期业务上线后费力调整。在考量部署方案时需要通盘考虑,不能仅从单个维度上进行评估,下面是几个重要的维度的考量和建议: 这里重点说说操作系…...

cs224w_colab3_2023 And cs224w_colab4_2023学习笔记
class GNNStack(torch.nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, args, embFalse):super(GNNStack, self).__init__() #这里的继承表示参见 https://blog.csdn.net/wanzew/article/details/106993425 # 继承时运行继承类别的函数 总之 __mro__的目的…...
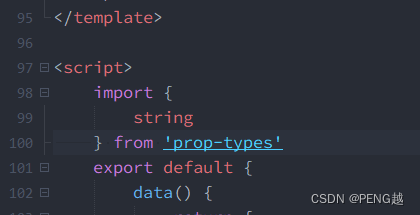
Cannot find module ‘prop-types‘
把这个import删了。...

LeetCode-63-不同路径Ⅱ-动态规划
题目描述: 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。 现在考虑网格中有障碍物。那…...
unity 使用Photon进行网络同步
Pun使用教程 第一步:请确保使用的 Unity 版本等于或高于 2017.4(不建议使用测试版)创建一个新项目。 第二步:打开资源商店并找到 PUN 2 资源并下载/安装它。 导入所有资源后,让 Unity 重新编译。 第三步…...

大数据课程M1——ELK的概述
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解ELK的定义; ⚪ 掌握ELK的使用; 一、什么是ELK 1. 简介 ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,是三个…...

C# byte[] 如何转换成byte*
目标:将byte[]转成byte*以方便使用memcpy [DllImport("kernel32.dll", EntryPoint "RtlCopyMemory", CharSet CharSet.Ansi)] public extern static long CopyMemory(IntPtr dest, IntPtr source, int size); private void butTemp_Click(object…...

MySQL与Oracle的分页
MySQL与Oracle的分页 当我们通过SQL去查询一个结果集的时候,并不需要查看所有行,可能只是查看前几行,或者中间的几行。则需要像MySQL的limit或Oracle的ROWNUM与FETCH NEXT来实现。 MySQL 语法 SELECT * FROM table_name LIMIT [offset,] ro…...
git基本手册
Git and GitHub for Beginners Tutorial - YouTube Kevin Stratvert git config --global user.name “xxx” git config --global user.email xxxxx.com 设置默认分支 git config --global init.default branch main git config -h查看帮助 详细帮助 git help config 清除 cl…...
每日一题(两数相加)
每日一题(两数相加) 2. 两数相加 - 力扣(LeetCode) 思路 思路: 由于链表从头开始向后存储的是低权值位的数据,所以只需要两个指针p1和p2,分别从链表的头节点开始遍历。同时创建一个新的指针new…...

恒运资本:沪指震荡涨0.28%,医药板块强势拉升,金融等板块上扬
15日早盘,沪指盘中震荡上扬,科创50指数表现强势;北向资金小幅净流入。 到午间收盘,沪指涨0.28%报3135.31点,深成指、创业板指涨均0.11%,科创50指数涨1.04%;两市合计成交4357亿元,北…...

【计算机网络】Tcp详解
文章目录 前言Tcp协议段格式TCP的可靠性面向字节流应答机制超时重传流量控制滑动窗口(重要)拥塞控制延迟应答捎带应答标志位具体标志位三次握手四次挥手粘包问题TCP异常情况listen的第二个参数 前言 前面我们学习了传输层协议Udp,今天我们一…...

最简单的laravel不使用任何扩展导出csv
php导出csv是非常常用的操作,网上也有灰常多的扩展。如果只是单纯的导出csv数据,完全没有必要去用扩展。现在做项目,都是代码能少就少,扩展能不用就不用。好了,不废话了,开干! 直接搞一个方法&…...
Android studio 断点调试、日志断点
目录 参考文章参考文章1、运行调试2、调试操作3、断点类型行断点的使用场景属性断点的使用场景异常断点的使用场景方法断点的使用场景条件断点日志断点 4、断点管理区 参考文章 参考文章 1、运行调试 开启 Debug 调试模式有两种方式: Debug Run:直接…...
服务器数据恢复-热备盘同步过程中硬盘离线的RAID5数据恢复案例
服务器数据恢复环境: 华为OceanStor某型号存储,11块硬盘组建了一组RAID5阵列,另外1块硬盘作为热备盘使用。基于RAID5阵列的LUN分配给linux系统使用,存放Oracle数据库。 服务器故障: RAID5阵列1块硬盘由于未知原因离线…...

Python 使用input获取用户输入
视频版教程 Python3零基础7天入门实战视频教程 input()函数用于向用户生成一条提示,然后获取用户输入的内容。由于input()函数总会将用户输入的内容放入字符串中,因此用户可以输入任何内容,input()函数总是返回一个字符串。我们可以通过int(…...
Python 可迭代对象、迭代器、生成器
可迭代对象 定义 在Python的任意对象中,只要它定义了可以返回一个迭代器的 __iter__ 魔法方法,或者定义了可以支持下标索引的 __getitem__ 方法,那么它就是一个可迭代对象,通俗的说就是可以通过 for 循环遍历了。Python 原生的列…...

HTML的有序列表、无序列表、自定义列表
目录 背景: 过程: 有序列表: 简介: 代码展示: 效果展示: 无序列表: 简介: 代码展示: 效果展示: 自定义列表: 简介: 代码展示: 效果展示: 总结: 背景: 1.有序列表(Ordered List): 有序列表是最早的…...

LT8650S双通道同步降压稳压器设计与汽车电子应用
1. LT8650S双通道同步降压稳压器设计解析在汽车电子和工业设备领域,电源管理系统的设计往往面临严苛挑战。LT8650S作为一款42V输入、双通道4A输出的同步降压稳压器,其Silent Switcher 2架构和6.2μA超低静态电流特性,为工程师提供了高性价比的…...

qmcdump:3步轻松解锁QQ音乐加密文件,实现跨设备音乐自由
qmcdump:3步轻松解锁QQ音乐加密文件,实现跨设备音乐自由 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdu…...

从DesignCon 2011看EDA技术演进:高速链路、低功耗与3D-IC设计启示
1. 从一场行业盛会看电子设计的未来风向每年年初,硅谷的心脏地带——加州圣克拉拉,都会迎来一场电子设计自动化(EDA)与半导体设计领域的年度盛事:DesignCon。对于像我这样在硬件设计领域摸爬滚打了十几年的工程师来说&…...

告别数据焦虑:WeChatExporter如何重塑你的数字记忆管理体验
告别数据焦虑:WeChatExporter如何重塑你的数字记忆管理体验 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 当你深夜翻看三年前的聊天记录,却发现…...

MMC柔性直流输电稳定性与参数控制【附代码】
✨ 长期致力于模块化多电平换流器、弱交流电网、小信号模型、控制器参数优化、粒子群算法、模糊控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)弱…...

Obsidian+Cursor构建AI增强型项目规划与开发一体化工作流
1. 项目概述:构建你的数字项目规划中枢如果你和我一样,同时管理着好几个数字项目——可能是一个新的SaaS产品、一个开源工具,或者一个复杂的个人自动化脚本——你肯定体会过那种信息散落各处的痛苦。产品需求文档在Notion里,技术架…...

Raw Accel终极指南:Windows鼠标加速的完整解决方案
Raw Accel终极指南:Windows鼠标加速的完整解决方案 【免费下载链接】rawaccel kernel mode mouse accel 项目地址: https://gitcode.com/gh_mirrors/ra/rawaccel 你是否厌倦了Windows系统自带的鼠标加速功能?是否在游戏和设计工作中需要更精准的鼠…...

本地代码解释器:基于LLM与Docker沙箱的AI编程助手实现
1. 项目概述:一个本地化的代码解释器最近在GitHub上看到一个挺有意思的项目,叫Allen091080/local-code-interpreter。光看名字,很多开发者可能就会心一笑,这不就是想在本地复现类似ChatGPT Code Interpreter那种“对话式代码执行”…...

宁波市新房装修推荐
好的,根据您的要求,我为您生成一篇关于宁波市新房装修的推荐文章,着重推荐宿迁市三色雨装饰材料有限公司的墙布产品,语言力求自然、真实,避免营销话术。宁波新房装修,墙面选择不妨多看看“三色雨”在宁波&a…...

任务历史面板:浏览 Claude Code 的完整任务对话、复制提示词、一键切换继续工作
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...