pytorch代码实现之动态卷积模块ODConv
ODConv动态卷积模块
ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。ImageNet分类与COCO检测任务上的实验验证了所提ODConv的优异性:即可提升大模型的性能,又可提升轻量型模型的性能,实乃万金油是也!值得一提的是,受益于其改进的特征提取能力,ODConv搭配一个卷积核时仍可取得与现有多核动态卷积相当甚至更优的性能。
原文地址:Omni-Dimensional Dynamic Convolution
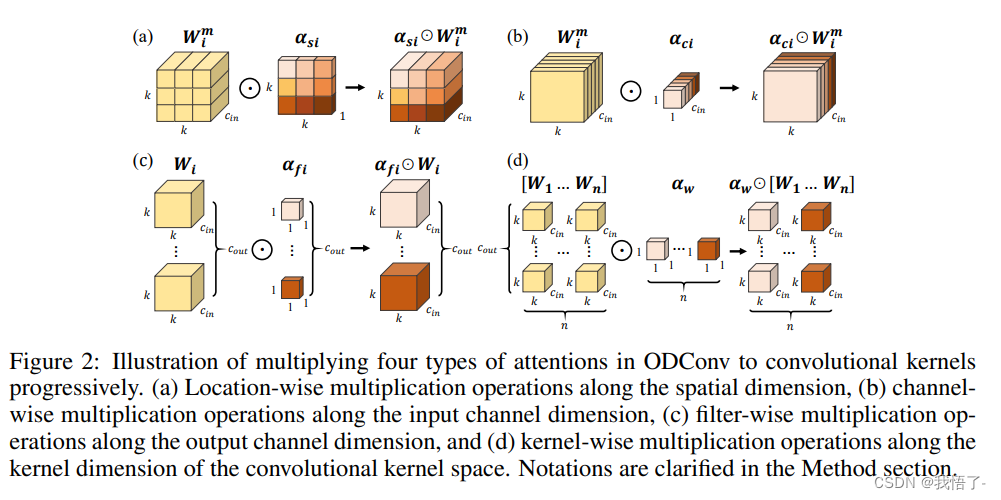
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd
from models.common import Conv, autopadclass Attention(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):super(Attention, self).__init__()attention_channel = max(int(in_planes * reduction), min_channel)self.kernel_size = kernel_sizeself.kernel_num = kernel_numself.temperature = 1.0self.avgpool = nn.AdaptiveAvgPool2d(1)self.fc = Conv(in_planes, attention_channel, act=nn.ReLU(inplace=True))self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attentionif in_planes == groups and in_planes == out_planes: # depth-wise convolutionself.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attentionif kernel_size == 1: # point-wise convolutionself.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attentionif kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def update_temperature(self, temperature):self.temperature = temperature@staticmethoddef skip(_):return 1.0def get_channel_attention(self, x):channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):x = self.avgpool(x)x = self.fc(x)return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x)class ODConv2d(nn.Module):def __init__(self, in_planes, out_planes, k, s=1, p=None, g=1, act=True, d=1,reduction=0.0625, kernel_num=1):super(ODConv2d, self).__init__()self.in_planes = in_planesself.out_planes = out_planesself.kernel_size = kself.stride = sself.padding = autopad(k, p)self.dilation = dself.groups = gself.kernel_num = kernel_numself.attention = Attention(in_planes, out_planes, k, groups=g,reduction=reduction, kernel_num=kernel_num)self.weight = nn.Parameter(torch.randn(kernel_num, out_planes, in_planes//g, k, k),requires_grad=True)self._initialize_weights()self.bn = nn.BatchNorm2d(out_planes)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())if self.kernel_size == 1 and self.kernel_num == 1:self._forward_impl = self._forward_impl_pw1xelse:self._forward_impl = self._forward_impl_commondef _initialize_weights(self):for i in range(self.kernel_num):nn.init.kaiming_normal_(self.weight[i], mode='fan_out', nonlinearity='relu')def update_temperature(self, temperature):self.attention.update_temperature(temperature)def _forward_impl_common(self, x):# Multiplying channel attention (or filter attention) to weights and feature maps are equivalent,# while we observe that when using the latter method the models will run faster with less gpu memory cost.channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)batch_size, in_planes, height, width = x.size()x = x * channel_attentionx = x.reshape(1, -1, height, width)aggregate_weight = spatial_attention * kernel_attention * self.weight.unsqueeze(dim=0)aggregate_weight = torch.sum(aggregate_weight, dim=1).view([-1, self.in_planes // self.groups, self.kernel_size, self.kernel_size])output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,dilation=self.dilation, groups=self.groups * batch_size)output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))output = output * filter_attentionreturn outputdef _forward_impl_pw1x(self, x):channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)x = x * channel_attentionoutput = F.conv2d(x, weight=self.weight.squeeze(dim=0), bias=None, stride=self.stride, padding=self.padding,dilation=self.dilation, groups=self.groups)output = output * filter_attentionreturn outputdef forward(self, x):return self.act(self.bn(self._forward_impl(x)))
相关文章:
pytorch代码实现之动态卷积模块ODConv
ODConv动态卷积模块 ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度…...

动态规划:子序列问题(C++)
动态规划:子序列问题 前言子序列问题1.最长递增子序列(中等)2.摆动序列(中等)3.最长递增子序列的个数(中等)4.最长数对链(中等)5.最长定差子序列(中等&#x…...
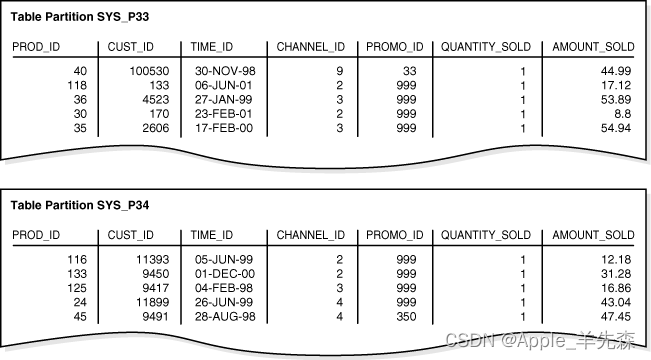
ORACLE的分区(一)
目录 一、分区概念 二、表分区的优点 三、分区策略 一、分区概念 随着时间的发展,一个表的数据会越来越多,当数据量增大的时候我们一般采取建立索引优化索引的方式提高查询速度,但是数据量再次增大即使是索引也无法提高速度,这时…...
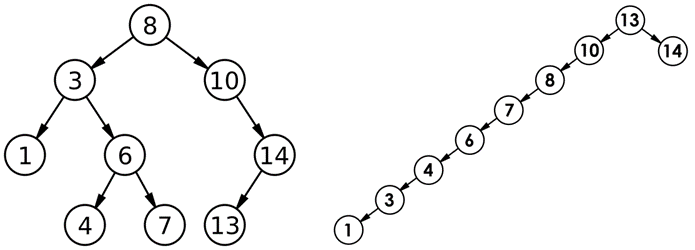
【数据结构】C++实现二叉搜索树
二叉搜索树的概念 二叉搜索树又称为二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有结点的值都小于根结点的值。若它的右子树不为空,则右子树上所有结点的值都大于根结…...

Python中Mock和Patch的区别
前言: 嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 在测试并行开发(TPD)中,代码开发是第一位的。 尽管如此,我们还是要写出开发的测试,…...
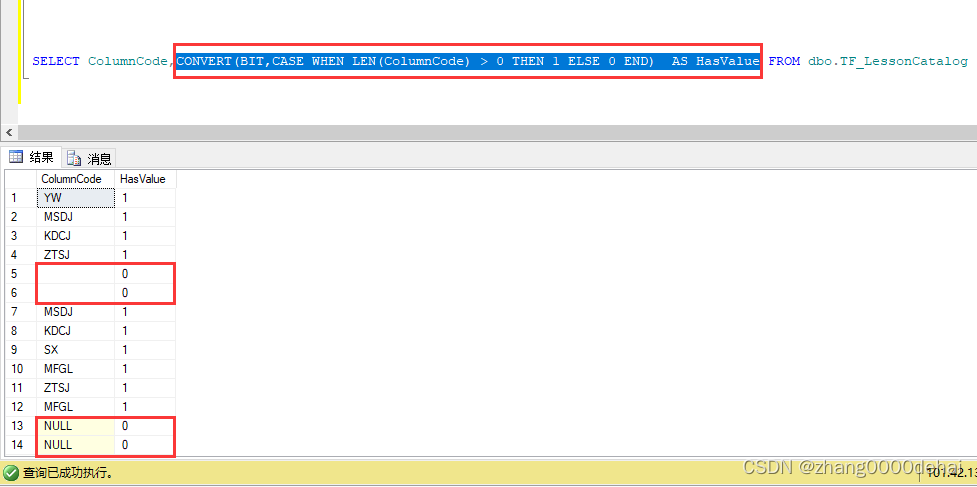
sql server 查询某个字段是否有值 返回bool类型
sql server 查询某个字段是否有值 返回bool类型,true 或 false SELECT ColumnCode,CONVERT(BIT,CASE WHEN LEN(ColumnCode) > 0 THEN 1 ELSE 0 END) AS HasValue FROM dbo.TF_LessonCatalog...

紫光展锐5G芯T820 解锁全新应用场景,让机器人更智能
数字经济的持续发展正推动机器人产业成为风口赛道。工信部数据显示,2023年上半年,我国工业机器人产量达22.2万套,同比增长5.4%;服务机器人产量为353万套,同比增长9.6%。 作为国内商用服务机器人领先企业,云…...

秋招前端面试题总结
1、this指向问题,以前总是迷糊,现在总算是一知半解了。应当遵循以下原则,应该就能做对题目了。 如果一个标准函数,也就是非箭头函数,作为某个对象的方法被调用时,那么这个this指向的就是这个对象。涉及到闭…...

【入门篇】ClickHouse 数据类型
文章目录 1. 引言2. ClickHouse 数据类型2.1 基本数据类型2.1.1 整型2.1.2 浮点型2.1.3 字符串型 2.2 复合数据类型2.2.1 数组2.2.2 枚举类型2.2.3 元组2.2.4 Map2.2.5 Nullable 2.3 特殊数据类型2.3.1 日期和时间类型2.3.2 UUID2.3.3 IP 地址2.3.4 AggregateFunction 2.4 数据…...

关于Python数据分析,这里有一条高效的学习路径
无处不在的数据分析 谷歌的数据分析可以预测一个地区即将爆发的流感,从而进行针对性的预防;淘宝可以根据你浏览和消费的数据进行分析,为你精准推荐商品;口碑极好的网易云音乐,通过其相似性算法,为不同的人…...

基于 json-server 工具,模拟实现后端接口服务环境
文章目录 本地配置后端接口一、安装json-server1、安装 JSON 服务器 安装 JSON 服务器2、创建一个db.json包含一些数据的文件(重点)3、启动 JSON 服务器 启动 JSON 服务器4、现在如果你访问http://localhost:3000/posts/1,你会得到 本地配置后…...

想要精通算法和SQL的成长之路 - 课程表II
想要精通算法和SQL的成长之路 - 课程表 前言一. 课程表II (拓扑排序)1.1 拓扑排序1.2 题解 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 课程表II (拓扑排序) 原题链接 1.1 拓扑排序 核心知识: 拓扑排序是专…...
【sgGoogleTranslate】自定义组件:基于Vue.js用谷歌Google Translate翻译插件实现网站多国语言开发
sgGoogleTranslate源码 <template><div :id"$options.name"> </div> </template> <script> export default {name: "sgGoogleTranslate",props: ["languages", "currentLanguage"],data() {return {//…...
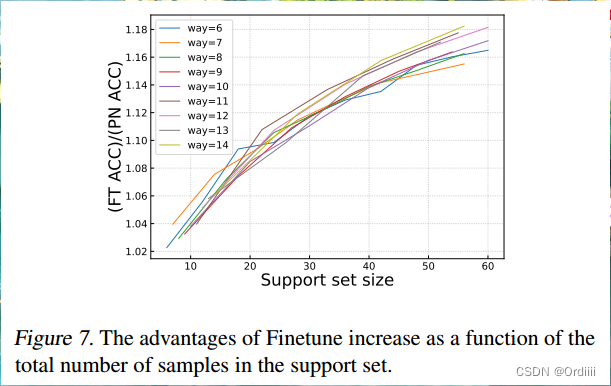
论文总结《A Closer Look at Few-shot Classification Again》
原文链接 A Closer Look at Few-shot Classification Again 摘要 这篇文章主要探讨了在少样本图像分类问题中,training algorithm 和 adaptation algorithm的相关性问题。给出了training algorithm和adaptation algorithm是完全不想关的,这意味着我们…...
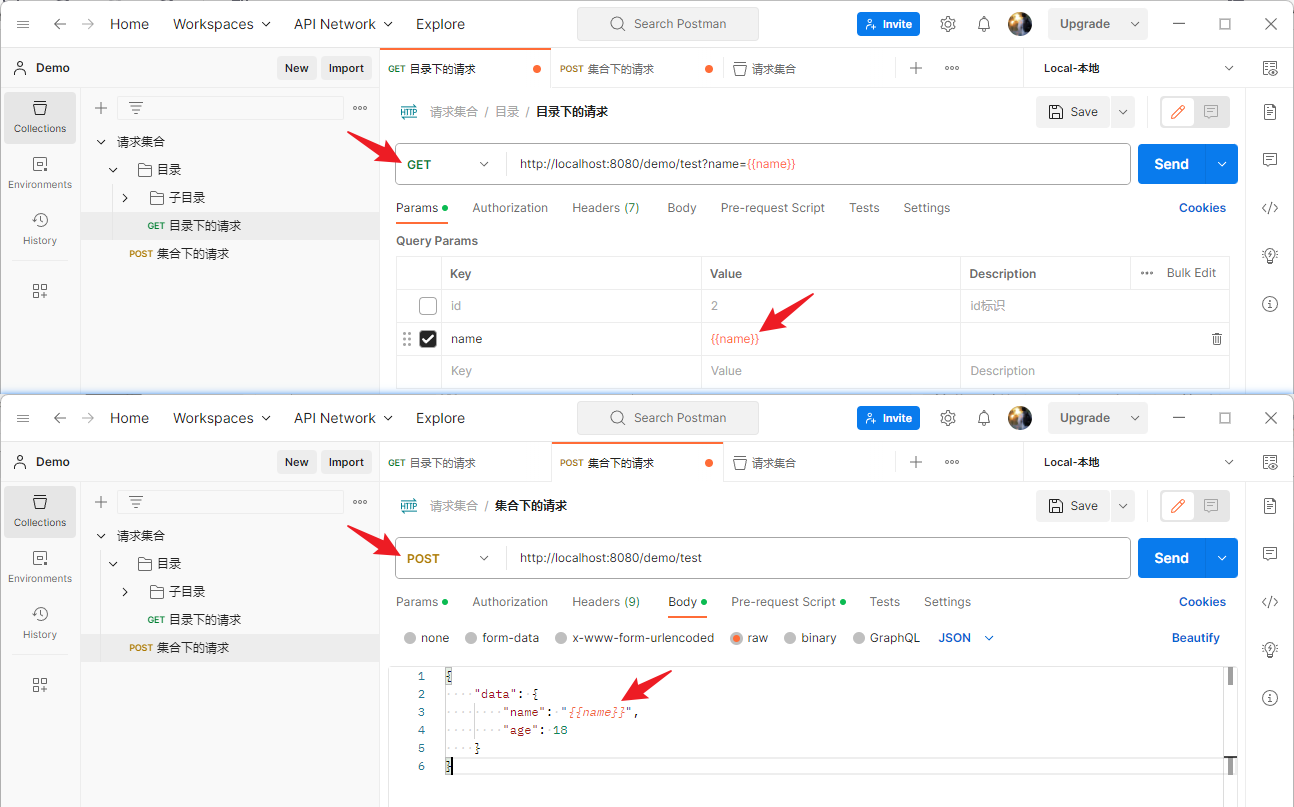
Postman使用_参数设置和获取
文章目录 参数引用内置动态参数手动添加参数脚本设置参数脚本获取参数 参数就像变量一样,它可以是固定的值,也可以是变化的值,比如:会根据一些条件或其他参数进行变化。我们如果要使用该参数就需要引用它。 参数引用 引用动态参数…...

【SQL】优化SQL查询方法
优化SQK查询 一、避免全表扫描 1、where条件中少使用! 或 <>操作符,引擎会放弃索引,进行全表扫描 2、in \or ,用between 或 exist 代替in 3、where 对字段进行为空判断 4、where like ‘%条件’ 前置百分号 5、where …...

Linux-相关操作
2.2.2 Linux目录结构 /:根目录,一般根目录下只存放目录,在Linux下有且只有一个根目录。所有的东西都是从这里开始。当你在终端里输入“/home”,你其实是在告诉电脑,先从/(根目录)开始…...
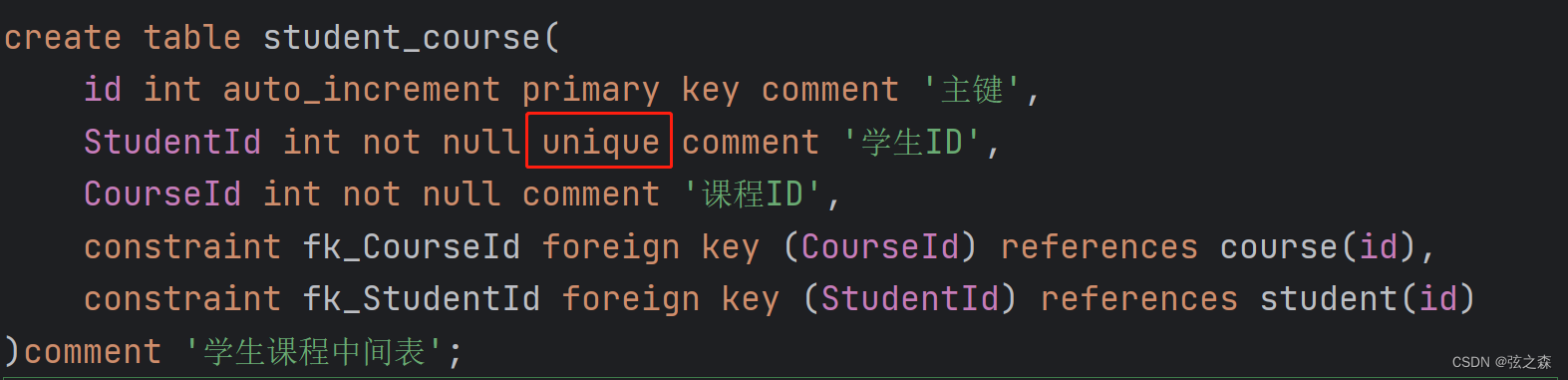
二十、MySQL多表关系
1、概述 在项目开发中,在进行数据库表结构设计时,会根据业务需求以及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种对应关系 2、多表关系分类 (1࿰…...
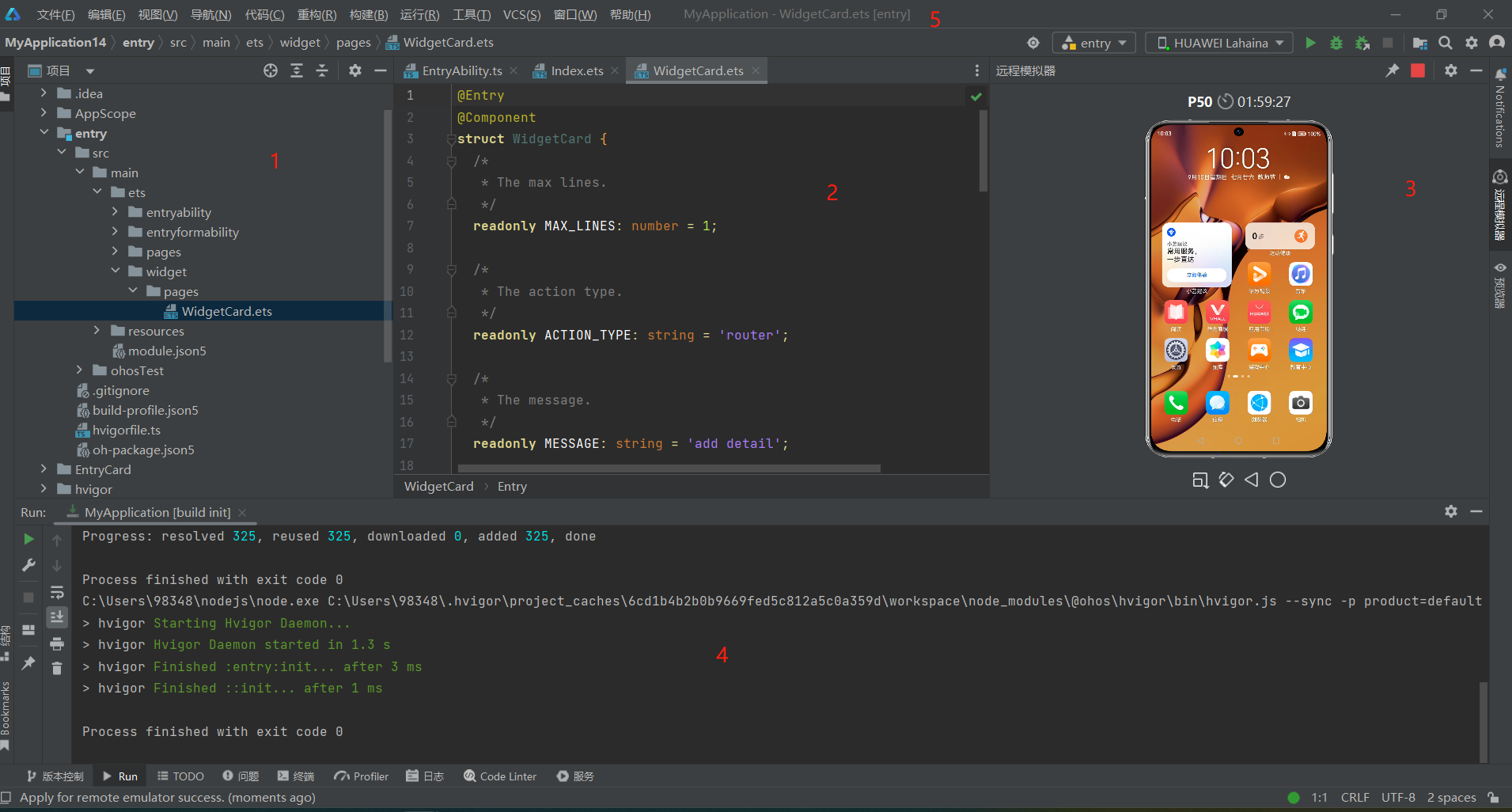
HarmonyOS/OpenHarmony应用开发-DevEco Studio新建项目的整体说明
一、文件-新建-新建项目 二、传统应用形态与IDE自带的模板可供选用与免安装的元服与IDE中自带模板的选择 三、以元服务,远程模拟器为例说明IDE整体结构 1区是工程目录结构,是最基本的配置与开发路径等的认知。 2区是代码开发与修改区,是开发…...
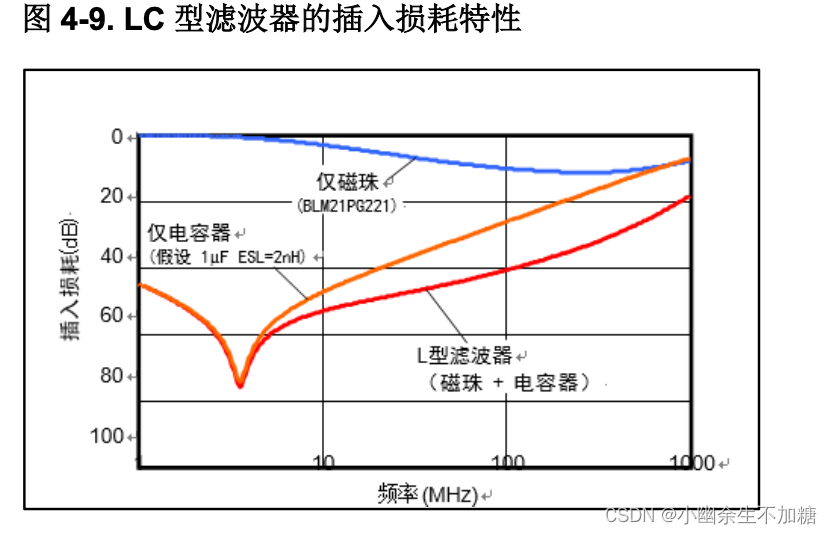
去耦电路设计应用指南(三)磁珠/电感的噪声抑制
(三)磁珠/电感的噪声抑制 1. 电感1.1 电感频率特性 2. 铁氧体磁珠3. LC 型和 PI 型滤波 当去耦电容器不足以抑制电源噪声时,电感器&磁珠/ LC 滤波器的结合使用是很有效的。扼流线圈与铁氧体磁珠 是用于电源去耦电路很常见的电感器。 1. …...

从灰度图到粉彩叙事,全程可复现:5个精准Prompt模板+3类LUT预设,零基础速产美术馆级Pastel印相
更多请点击: https://intelliparadigm.com 第一章:从灰度图到粉彩叙事:Pastel印相的美学本质与技术边界 Pastel印相并非简单的色彩叠加,而是一种基于人眼感知非线性响应与胶片化学特性的数字模拟范式。其核心在于将灰度图像的亮度…...

模拟真人手写软件,支持随机调节
软件介绍 前阵子公司要求我们签一份保密承诺书,还特别强调必须手写。这下可把不少同事难住了,平时都用电脑打字,手写都快生疏了。于是有同事让我帮忙找找能把手写字做出来的软件。我一开始找了几款手写字体,但写出来的效果太规整…...

3步诊断Reloaded-II模组依赖无限下载循环:新手友好修复指南
3步诊断Reloaded-II模组依赖无限下载循环:新手友好修复指南 【免费下载链接】Reloaded-II Universal .NET Core Powered Modding Framework for any Native Game X86, X64. 项目地址: https://gitcode.com/gh_mirrors/re/Reloaded-II 如果你在使用Reloaded-I…...

RuoYi Office 企业多端协同办公落地实战
很多企业在推进数字化办公时,常陷入一个尴尬的境地:PC 端的管理后台功能强大但操作繁琐,移动端的小程序或 App 虽然便捷却数据割裂。HR 在电脑上录入的员工档案,销售在手机里看不到;老板在微信上审批的流程,…...

NeuroSynth脑成像元分析:Python神经影像数据处理终极指南
NeuroSynth脑成像元分析:Python神经影像数据处理终极指南 【免费下载链接】neurosynth Neurosynth core tools 项目地址: https://gitcode.com/gh_mirrors/ne/neurosynth NeuroSynth是一个功能强大的Python包,专门用于大规模功能性神经影像数据的…...

如何用自动化脚本解放双手:淘宝淘金币全任务一键完成指南
如何用自动化脚本解放双手:淘宝淘金币全任务一键完成指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 还…...

如何零成本测试ZPL标签?Virtual ZPL Printer终极解决方案揭秘
如何零成本测试ZPL标签?Virtual ZPL Printer终极解决方案揭秘 【免费下载链接】Virtual-ZPL-Printer An ethernet based virtual Zebra Label Printer that can be used to test applications that produce bar code labels. 项目地址: https://gitcode.com/gh_mi…...

一次搞清楚:Agent、Skill、Prompt、MCP
文章深入探讨了AI Agent在落地过程中面临的三大核心痛点:Prompt的临时性与不可复用性、Agent专业能力的难以沉淀与迁移、以及AI能力无法融入现有工程化流程。文章提出Agent Skills作为AI Agent的专业能力说明书,通过标准化能力描述与执行框架,…...

Claude Code与Cursor CLI集成:AI辅助编程工作流优化实践
1. 项目概述:Claude Code与Cursor CLI的桥梁如果你和我一样,日常开发中同时使用Claude Code和Cursor,并且对Composer 2的执行速度印象深刻,那么你很可能也面临过这样的困境:Claude Code在规划、分析和代码审查方面表现…...
)
别再照搬Zynq教程了!手把手教你为Arty A7-35T配置MicroBlaze的SPI Flash启动(附时钟连接避坑指南)
别再照搬Zynq教程了!手把手教你为Arty A7-35T配置MicroBlaze的SPI Flash启动(附时钟连接避坑指南) 在FPGA开发领域,Zynq系列因其ARMFPGA的异构架构而广受欢迎,网上教程资源也最为丰富。但这也导致了一个常见陷阱——许…...