Spark On YARN时指定Python版本
坑很多,直接上兼容性最佳的命令,将python包上传到hdfs或者file:/home/xx/(此处无多余的/)
# client 模式
$SPARK_HOME/spark-submit \
--master yarn \
--deploy-mode client \
--num-executors 2 \
--conf "spark.yarn.dist.archives=<Python包路径>/Python包名字.tgz#Python别名" \
--conf "spark.yarn.appMasterEnv.PYSPARK_PYTHON=./Python别名/bin/python" \
本地python路径比如Hello.py# cluster 模式
$SPARK_HOME/spark-submit \
--master yarn \
--deploy-mode cluster \
--num-executors 2 \
--conf "spark.yarn.dist.archives=<Python包路径>/Python包名字.tgz#Python别名" \
--conf "spark.yarn.appMasterEnv.PYSPARK_PYTHON=./Python别名/bin/python" \
本地python路径比如Hello.py
具体细节
关于 Python包
-
打包可以参考 https://www.jianshu.com/p/d77e16008957,https://blog.csdn.net/sgyuanshi/article/details/114648247 非官方的python,比如anaconda的python可能会有坑,所以最好先用官方版本进行测试
-
此处使用官方2.7.9打包了一个
myPython.tgz-
这个文件解压 后是
./bin、lib、share等文件夹 -
python指令在./bin录下,dddd(懂的都懂) -
myPython.tgz可以上传到hdfs也可以放在服务器本地
-
-
然后用
archives参数指向myPython.tgz,以下2种都可以--conf "spark.yarn.dist.archives=<Python包路径>/Python包名字.tgz#Python别名"--archives "<Python包路径>/Python包名字.tgz#Python别名"
-
#Python别名是必须的,比如是#py279,则YARN会把压缩文件解压到py279文件夹中,后续就可以直接使用./py279/bin/python来指向 运行时的python了 -
myPython.tgz的存放位置- hdfs时基本没有坑,比如是
hdfs://aaa:port/home/xxx/yy/myPython.tgz- 则上述archive参数为
--archives hdfs://aaa:port/home/xxx/yy/myPython.tgz#py279
- 则上述archive参数为
- 存在本地时,有坑,比如是 在
/home/haha/myPython.tgz- 则上述archive参数为
--archives file:/home/haha/myPython.tgz#py279,此处并不是file:///home/hahaxxx(即正确的形式并没有多余的/)
- 则上述archive参数为
- hdfs时基本没有坑,比如是
至此,python包已经放好了,也重命名了,比如是存到了hdfs:
--archives "hdfs://aaa:port/home/xxx/yy/myPython.tgz#py279"
然后就需要 driver和executor把python指向上述 python,即py279
关于Driver、Executor指向python
指定Python版本主要有两组参数:小写字母and大写字母;两组参数在使用的时候,根据client模式和cluster模式的不同,会有区别,经过测试,建议使用大写字母
- 小写字母:兼容性较差
- spark.pyspark.driver.python
- spark.pyspark.python
- 大写字母:兼容性较好
spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHONspark.yarn.appMasterEnv.PYSPARK_PYTHON
具体测试结果如下

关于表格中“指本地”、“指集群”、“有无driver路径”的理解,首先简单介绍一下client与cluser模式的区别,这更容易理解。直观的讲:
client模式时,Driver在当前服务器,Executor在集群中,所以Driver的python版本可以指向本地服务器的地址,
而Executor使用的python必须要由上面的参数提交后由YARN发布到各个Executor所在的节点。
cluster模式时,Driver和Executor都在集群中,所以Driver的python也要由YARN通过刚刚的路径提供。
因此,
测试1:client,小写, 有driver路径, 【成功】
$SPARK_HOME/bin/sbmit client \ 其他参数
--archives "hdfs://aaa:port/home/xxx/yy/myPython.tgz#py279" \
--conf "spark.pyspark.driver.python=客户端本地路径如/home/localPython/bin/python" \
--conf "spark.pyspark.python=必须是 ./py279/bin/python" \
本地python路径比如Hello.py
测试2:client, 小写,无driver路径, 【失败 】
$SPARK_HOME/bin/sbmit client \ 其他参数
--archives "hdfs://aaa:port/home/xxx/yy/myPython.tgz#py279" \
--conf "spark.pyspark.python=必须是 ./py279/bin/python" \ # driver的路径已经删了
本地python路径比如Hello.py
测试3:cluster, 小写,指本地,有driver路径, 【失败 】
$SPARK_HOME/bin/sbmit cluster \ 其他参数
--archives "hdfs://aaa:port/home/xxx/yy/myPython.tgz#py279" \
--conf "spark.pyspark.driver.python=客户端本地路径如/home/localPython/bin/python" \
--conf "spark.pyspark.python=必须是 ./py279/bin/python" \
本地python路径比如Hello.py
测试4:cluster, 小写,指集群,有driver路径, 【成功 】
$SPARK_HOME/bin/sbmit cluster \ 其他参数
--archives "hdfs://aaa:port/home/xxx/yy/myPython.tgz#py279" \
--conf "spark.pyspark.driver.python=./py279/bin/python"\ #driver指向了与executor相同python
--conf "spark.pyspark.python=必须是 ./py279/bin/python" \
本地python路径比如Hello.py
大写字母的 spark.yarn.appMasterEnv.PYSPARK_PYTHON同理,
所以,测试之后,最简单的方案就是文章开头的方案。
如果参数使用不合理,或者打包的python包有问题(比如anaconda的),会报错误如下:
Caused by: java.io.IOException: Cannot run program "/xxxx/xxx/py279/myPy279/bin/python": error=13, Permission deniedLast 4096 bytes of stderr :
eason: User class threw exception: java.io.IOException: Cannot run program "/xxxx/xxx/py279/myPy279/bin/python": error=13, Permission deniedException in thread "main" java.io.IOException: Cannot run program "/xxxx/xxx/py279/myPy279/bin/python": error=2, No such file or directory
不是找不到python路径就是权限不够
相关文章:
Spark On YARN时指定Python版本
坑很多,直接上兼容性最佳的命令,将python包上传到hdfs或者file:/home/xx/(此处无多余的/) # client 模式 $SPARK_HOME/spark-submit \ --master yarn \ --deploy-mode client \ --num-executors 2 \ --conf "spark.yarn.dist.archives<Python包…...

[数据库]库的增删改查
●🧑个人主页:你帅你先说. ●📃欢迎点赞👍关注💡收藏💖 ●📖既选择了远方,便只顾风雨兼程。 ●🤟欢迎大家有问题随时私信我! ●🧐版权:本文由[你帅…...
Wine零知识学习1 —— 介绍
一、什么是Wine Wine是“Wine Is Not an Emulator” 的首字母缩写,是一个能够在多种POSIX-compliant操作系统(诸如Linux、macOS及BSD等)上运行 Windows 应用的兼容层。Wine不像虚拟机或者模拟器那样模仿内部的Windows逻辑,而是將…...

设计模式--建造者模式 builder
设计模式--建造者模式 builder)建造者模式简介建造者模式--小例子(电脑购买)1.产品类2.抽象构建者3.实体构建类4.指导者类5.客户端测试类小结建造者模式简介 建造者模式有四个角色,概念划分如下: Product : 产品类&a…...

终于周末啦,继续来总结一下Python的一些知识点啦
目录 Python概念梳理 常见概念梳理 Python经典判断题 判断题 选择题 Python概念梳理 常见概念梳理 Python中,不仅仅变量的值是可以变化的,类型也是可以随时变化的 1、Python的变量必须初始化否则提示 is not defined 2、if、while中定义的变量在…...
CUDA By Example(八)——流
文章目录页锁定主机内存可分页内存函数页锁定内存函数CUDA流使用单个CUDA流使用多个CUDA流GPU的工作调度机制高效地使用多个CUDA流遇到的问题(未解决)页锁定主机内存 在之前的各个示例中,都是通过 cudaMalloc() 在GPU上分配内存,以及通过标准的C库函数 …...
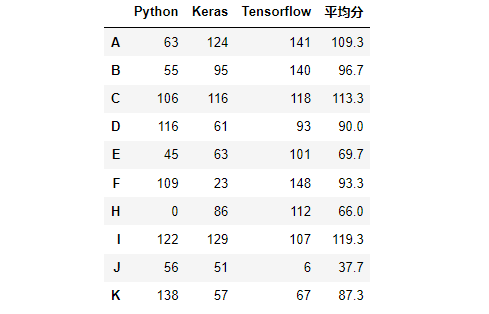
02- pandas 数据库 (数据库)
pandas 数据库重点: pandas 的主要数据结构: Series (一维数据)与 DataFrame (二维数据)。 pd.DataFrame(data np.random.randint(0,151,size (5,3)), # 生成pandas数据 index [Danial,Brandon,softpo,Ella,Cindy], # 行索引 …...

less常用语法总结
CSS预处理器 CSS 预处理器是什么?一般来说,它们基于 CSS 扩展了一套属于自己的 DSL,来解决我们书写 CSS 时难以解决的问题: 语法不够强大,比如无法嵌套书写导致模块化开发中需要书写很多重复的选择器;没有变量和合理的样式复用机制,使得逻辑上相关的属性值必须以字面量…...
DHCP Relay中继实验
DHCP Relay实验拓扑图设备配置结果验证拓扑图 要求PC1按照地址池自动分配,而PC要求分配固定的地址,网段信息已经在图中进行标明。 设备配置 AR1: AR1作为DHCP Server基本配置跟DHCP Server没区别,不过要加一条静态路由ÿ…...

“1+1>2”!《我要投资》与天际汽车再度“双向奔赴”!
文|螳螂观察 作者| 图霖 胡海泉老师重磅回归、创始人现场真情告白……新一季的《我要投资》,不仅维持了往季在专业度上的高水准,也贡献了不少高话题度的“出圈”时刻。 在竞争激烈的的综艺节目竞技场,能举办数季的节目,往往都是…...
【分享】订阅金蝶KIS集简云连接器同步OA付款审批数据至金蝶KIS
方案简介 集简云基于钉钉连接平台完成与钉钉的深度融合,实现钉钉OA审批与数百款办公应用软件(如金蝶KIS、用友等)的数据互通,让钉钉的OA审批流程与企业内部应用软件的采购、付款、报销、收款、人事管理、售后工单、立项申请等环节…...

dubbo服务消费
dubbo在服务消费时调用的方法栈比较深,所以得一边看一边记,还是比较费力的。在dubbo服务发现中,我们看到通过ReferenceConfig#get()返回的是要调用接口的代理对象,因此通过接口的代理对象调用方法时是调用InvocationHandler(Invok…...
Python调用API接口,实现人脸识别
人生苦短,我用Python 在开始之前,先问问大家: 什么是百度Aip模块? 百度AI平台提供了很多的API接口供开发者快速的调用运用在项目中 本文写的是使用百度AI的**在线接口SDK模块(baidu-aip)**进行实现人脸识…...

2月10日刷题总结
编辑距离题目描述设 AA 和 BB 是两个字符串。我们要用最少的字符操作次数,将字符串 AA 转换为字符串 BB。这里所说的字符操作共有三种:删除一个字符;插入一个字符;将一个字符改为另一个字符。A, BA,B 均只包含小写字母。输入格式第…...
C++学习/温习:新型源码学编程(三)
写在前面(祝各位新春大吉!兔年如意!) 【本文持续更新中】面向初学者撰写专栏,个人原创的学习C/C笔记(干货)所作源代码输出内容为中文,便于理解如有错误之处请各位读者指正请读者评论回复、参与投票…...

阿里云ecs服务器搭建CTFd(ubuntu20)
1.更新apt包索引 sudo apt-get update更新源 1、使用快捷键【ctrlaltt】打开终端。 2、输入以下命令备份原有软件源文件。 cp /etc/apt/sources.list /etc/apt/sources.list.bak_yyyymmdd 3、再输入以下命令打开sources.list文件并添加新的软件源地址。 vim /etc/apt/sources.…...
视频号小店新订单如何实时同步企业微信
随着直播带货的火热,视频号小店也为商家提供商品信息服务、商品交易,支持商家在视频号运营电商,许多企业也将产品的零售路径渗透至视频号小店中了。如果我们希望在视频号小店接收到订单后,能尽快及时发货,给用户较好的…...

ag-Grid Enterprise
ag-Grid Enterprise Ag-Grid被描述为一种商业产品,已在EULA下分发,它非常先进,性能就像Row分组一样,还有范围选择、master和case、行的服务器端模型等等。 ag Grid Enterprise的巨大特点: 它具有以下功能和属性&#x…...

扫雷——C语言【详解+全部码源】
前言:今天我们学习的是C语言中另一个比较熟知的小游戏——扫雷 下面开始我们的学习吧! 文章目录游戏整体思路游戏流程游戏菜单的打印创建数组并初始化布置雷排查雷完整代码game.hgame.ctest.c游戏整体思路 我们先来看一下网上的扫雷游戏怎么玩 需要打印…...
【C++】类和对象(下)
文章目录1. 再谈构造函数1.1 初始化列表1.2 explicit关键字2. static成员2.1 概念2.2 特性3. 友元3.1 友元函数3.1 友元类4. 内部类5. 匿名对象6. 拷贝对象时的一些编译器优化7. 再次理解类和对象1. 再谈构造函数 1.1 初始化列表 在创建对象时,编译器通过调用构造…...

通过稳定的路由与容灾机制保障关键业务中的AI服务连续性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过稳定的路由与容灾机制保障关键业务中的AI服务连续性 在将大模型能力集成到关键业务流程时,服务的连续性与可靠性是…...

NsEmuTools:5分钟搞定NS模拟器自动化管理的终极方案
NsEmuTools:5分钟搞定NS模拟器自动化管理的终极方案 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 你是否厌倦了手动安装和更新NS模拟器的繁琐过程?NsEmuTools作为…...

CCM实战调校:从原理到精准色彩还原
1. 色彩校正矩阵(CCM)的核心原理 色彩校正矩阵(CCM)是图像处理流水线中一个关键的数学工具,它的主要作用是修正相机传感器捕获的颜色与实际场景颜色之间的偏差。想象一下,你用手机拍了一张草莓的照片&…...

从数据提取到AI记忆:WeChatMsg项目开发者协作实战蓝图
从数据提取到AI记忆:WeChatMsg项目开发者协作实战蓝图 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

芯片人才危机破局:D.E.I.B.战略如何驱动创新与商业成功
1. 芯片行业人才危机的深度剖析与D.E.I.B.的战略价值 最近和几位在芯片设计公司和晶圆厂负责招聘的老友聊天,大家不约而同地提到了同一个词:“焦头烂额”。不是项目进度卡脖子,而是人根本招不到。一位在模拟芯片公司做HR总监的朋友告诉我&…...

多模型聚合平台在应对单一服务波动时的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台在应对单一服务波动时的体验差异 在构建依赖大模型能力的应用时,开发者常常面临一个现实挑战࿱…...

刚续费Basic的你务必立刻阅读:官方未公告的API调用封禁、历史图库自动归档及导出格式缩水清单
更多请点击: https://intelliparadigm.com 第一章:Midjourney Basic计划的核心定位与续费陷阱警示 Midjourney Basic 计划面向轻量级创作者,提供每月 200 张图像生成额度、标准排队优先级及基础风格控制能力。其核心定位并非长期主力生产工具…...

专业右键菜单管理:用ContextMenuManager一键重塑Windows操作效率
专业右键菜单管理:用ContextMenuManager一键重塑Windows操作效率 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 在Windows生态中,右键菜…...

AI智能体如何利用德国铁路实时数据与历史预测优化出行决策
1. 项目概述:一个为AI智能体打造的德国铁路工具箱如果你经常在德国乘坐火车,并且对DB Navigator(德国铁路官方App)的实时信息、延误预测有需求,那么你很可能已经习惯了在出行前反复刷新App,手动计算换乘时间…...

示波器平均值功能实战:从噪声中精准提取电机故障信号
1. 项目概述:用示波器诊断模型火车电机故障作为一名在电子工程领域摸爬滚打了十几年的老工程师,我手边最离不开的工具,除了万用表,就是示波器。很多人觉得示波器是研发实验室里的高端设备,离日常维修很远,但…...