【深度学习】- NLP系列文章之 1.文本表示以及mlp来处理分类问题
系列文章目录
1. 文本分类与词嵌入表示,mlp来处理分类问题
2. RNN、LSTM、GRU三种方式处理文本分类问题
3. 评论情绪分类
还是得开个坑,最近搞论文,使用lstm做的ssd的cache prefetching,意味着我不能再划水了。
文章目录
- 系列文章目录
- [1. 文本分类与词嵌入表示,mlp来处理分类问题](https://blog.csdn.net/weixin_40293999/article/details/132864421) 2. RNN、LSTM、GRU三种方式处理文本分类问题 3. 评论情绪分类 还是得开个坑,最近搞论文,使用lstm做的ssd的cache prefetching,意味着我不能再划水了。
- 1. 文本数据表示法与词嵌入
- 1.1 文本是什么,如何表示?
- 1.2 文本的词嵌入表示处理流程
- 1.3 代码展示分词过程
- 1.4 词嵌入表示
- 2.简单文本分类
1. 文本数据表示法与词嵌入
torch 是做张量计算的框架,张量只能存储数字类型的值,因此无论啥样的文本(中文、英文)都不能直接用张量表示,这就引出了文本数据的表示问题,如何表示文本数据?
1.1 文本是什么,如何表示?
文本是常用的序列化数据类型之一。文本数据可以看作是一
个字符序列或词的序列。对大多数问题,我们都将文本看作
词序列。
深度学习序列模型(如RNN及其变体)能够较好的对序列化
数据建模。
深度学习序列模型(如RNN及其变体)可以解决类似以下领
域中的问题:自然语言理解、文献分类、情感分类、问答系统等。
深度学习模型并不能理解文本,因此需要将文本转换为数值
的表示形式。
将文本转换为数值表示形式的过程称为向量化过程,可以用
不同的方式来完成,
词嵌入是单词的一种数值化表示方式,一般情况下会将一个单词映射到一个高维的向量中(词向量)
来代表这个单词
‘机器学习’表示为 [1, 2, 3]
‘深度学习’表示为 [1, 3, 3]
‘日月光华’表示为 [9, 9, 6]
对于词向量,我们可以使用余弦相似度在计算机中来判断
单词之间的距离。
词嵌入用密集的分布式向量来表示每个单词。词向量表示方式依赖于单词的使用习惯,这就使得具有相似使用方式的单词具有相似的表示形式。
Glove算法是对word2vec方法的拓展,并且更为有效。
1.2 文本的词嵌入表示处理流程
每个较小的文本单元称为token,将文本分解成token的过程称为分词(tokenization)。在 Python中有很多强大的库可以用来进行分词.
one-hot(独热)编码和词嵌入是将token映射到向量最流行的两种方法。
1.3 代码展示分词过程
import torch
import numpy as np
import string
s = "Life is not easy for any of us.We must work,and above all we must believe in ourselves.We must believe that each one of us is able to do some thing well.And that we must work until we succeed."
string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
for c in string.punctuation:s = s.replace(c," ").lower()
去掉标点符号
s
'life is not easy for any of us we must work and above all we must believe in ourselves we must believe that each one of us is able to do some thing well and that we must work until we succeed ’
s.split()
['life','is','not','easy','for','any','of','us','we','must','work','and','above','all','we','must','believe','in','ourselves','we','must','believe','that','each','one','of','us','is','able','to','do','some','thing','well','and','that','we','must','work','until','we','succeed']
分词方式(三):n-gram
向量化:one-hot emdeding
import numpy as np
np.unique(s.split())
array([‘able’, ‘above’, ‘all’, ‘and’, ‘any’, ‘believe’, ‘do’, ‘each’,
‘easy’, ‘for’, ‘in’, ‘is’, ‘life’, ‘must’, ‘not’, ‘of’, ‘one’,
‘ourselves’, ‘some’, ‘succeed’, ‘that’, ‘thing’, ‘to’, ‘until’,
‘us’, ‘we’, ‘well’, ‘work’], dtype=‘<U9’)
vocab = dict((word,index) for index, word in enumerate(np.unique(s.split())))
vocab
建立映射关系
{‘able’: 0,
‘above’: 1,
‘all’: 2,
‘and’: 3,
‘any’: 4,
‘believe’: 5,
‘do’: 6,
‘each’: 7,
‘easy’: 8,
‘for’: 9,
‘in’: 10,
‘is’: 11,
‘life’: 12,
‘must’: 13,
‘not’: 14,
‘of’: 15,
‘one’: 16,
‘ourselves’: 17,
‘some’: 18,
‘succeed’: 19,
‘that’: 20,
‘thing’: 21,
‘to’: 22,
‘until’: 23,
‘us’: 24,
‘we’: 25,
‘well’: 26,
‘work’: 27}
这是one-hot的表示方法
for index, i in enumerate(s):b[index,i] = 1
b[0:5]
array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
1.4 词嵌入表示
import torch
em = torch.nn.Embedding(len(vocab), 20)
s_em = em(torch.LongTensor(s))
s_em.shape
torch.Size([42, 20])
2.简单文本分类
这里要说明一下,torch1.8 gpu 和 torchtext 0.90 版本,这俩个要匹配,否则安装torchtext的时候,会吧torch uninstall 再install,特别麻烦。
对应关系 ref:https://pypi.org/project/torchtext/0.14.0/
可以看到2.0的torch还没有对应的torchtext
import torch
import torchtext
from torchtext import data
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from torchtext.vocab import GloVe
from torchtext.datasets import IMDB
用的是这个数据集:
IMDB:http://ai.stanford.edu/~amaas/data/sentiment/
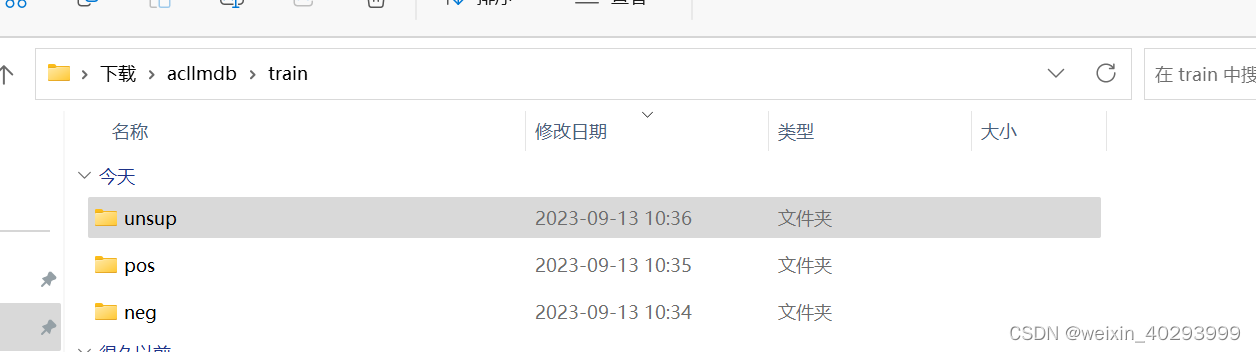
是影评,包括三个标签,正向、负向和未知。
TORCHTEXT.DATASETS, 所有数据集都是子类 torch.data.Dataset, 她们继承自torch.utils.data.Dataset,并且具有split和iters实现的方法
切分数据集:
TEXT = torchtext.legacy.data.Field(lower=True, fix_length=200,batch_first=True)
LABEL = torchtext.legacy.data.Field(sequential=False)
# make splits for data
train,test = torchtext.legacy.datasets.IMDB.splits(TEXT,LABEL)
构建词嵌入:
最多容量10000个词,最小的频率是出现10次。
# 构建词表 vocab 构建train训练集的 top 10000个单词做训练, vectors用来提供预训练模型
TEXT.build_vocab(train, max_size = 10000,min_freq=10, vectors=None)
LABEL.build_vocab(train)
查看频率
TEXT.vocab.freqs
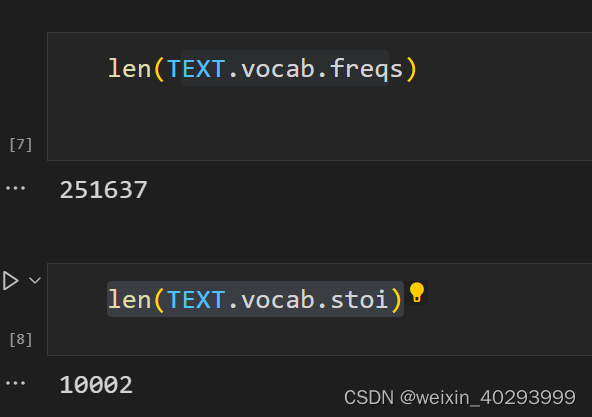
一共10002行数据,因为0是unknown, 1是padding。 超过10000的词都标记为unknown
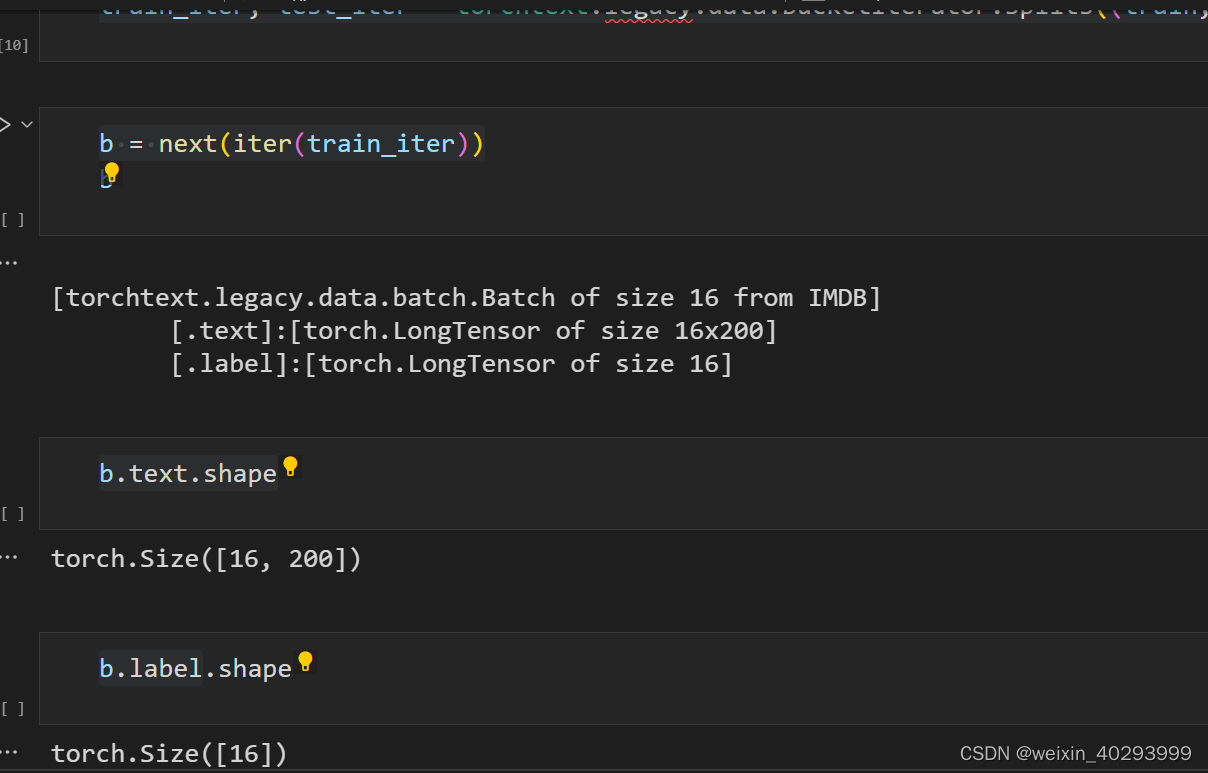
train_iter, test_iter = torchtext.legacy.data.BucketIterator.splits((train,test),batch_size=16)
创建模型
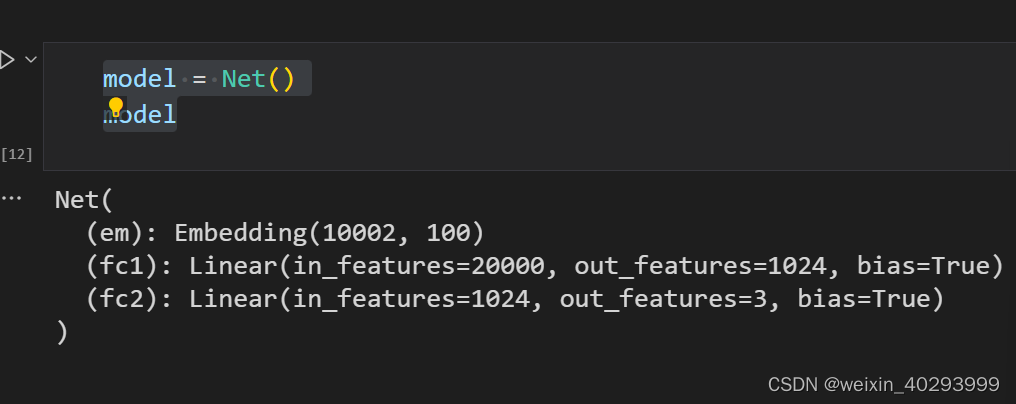
class Net(nn.Module):def __init__(self):super().__init__()self.em = nn.Embedding(len(TEXT.vocab.stoi),100) # batch*200-->batch*200*100self.fc1 = nn.Linear(200*100,1024)self.fc2 = nn.Linear(1024,3)def forward(self,x):x = self.em(x)x = x.view(x.size(0), -1)x = self.fc1(x)x = F.relu(x)x = self.fc2(x)return x
model = Net()
model
损失函数:
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
训练过程:这个代码是固定的,和我其它的文章里面也有很多
def fit(epoch, model, trainloader, testloader):correct = 0total = 0running_loss = 0model.train()for b in trainloader:x, y = b.text, b.labelif torch.cuda.is_available():x, y = b.text.to('cuda'), b.label.to('cuda')y_pred = model(x)loss = loss_fn(y_pred, y)optimizer.zero_grad()loss.backward()optimizer.step()with torch.no_grad():y_pred = torch.argmax(y_pred, dim=1)correct += (y_pred == y).sum().item()total += y.size(0)running_loss += loss.item()
# exp_lr_scheduler.step()epoch_loss = running_loss / len(trainloader.dataset)epoch_acc = correct / totaltest_correct = 0test_total = 0test_running_loss = 0 model.eval()with torch.no_grad():for b in testloader:x, y = b.text, b.labelif torch.cuda.is_available():x, y = x.to('cuda'), y.to('cuda')y_pred = model(x)loss = loss_fn(y_pred, y)y_pred = torch.argmax(y_pred, dim=1)test_correct += (y_pred == y).sum().item()test_total += y.size(0)test_running_loss += loss.item()epoch_test_loss = test_running_loss / len(testloader.dataset)epoch_test_acc = test_correct / test_totalprint('epoch: ', epoch, 'loss: ', round(epoch_loss, 3),'accuracy:', round(epoch_acc, 3),'test_loss: ', round(epoch_test_loss, 3),'test_accuracy:', round(epoch_test_acc, 3))return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
训练:
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,model,train_iter,test_iter)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)
结果输出:
epoch: 0 loss: 0.046 accuracy: 0.55 test_loss: 0.041 test_accuracy: 0.618
epoch: 1 loss: 0.026 accuracy: 0.809 test_loss: 0.046 test_accuracy: 0.69
epoch: 2 loss: 0.009 accuracy: 0.945 test_loss: 0.053 test_accuracy: 0.721
epoch: 3 loss: 0.004 accuracy: 0.975 test_loss: 0.068 test_accuracy: 0.729
epoch: 4 loss: 0.002 accuracy: 0.985 test_loss: 0.115 test_accuracy: 0.708
epoch: 5 loss: 0.002 accuracy: 0.989 test_loss: 0.098 test_accuracy: 0.737
epoch: 6 loss: 0.002 accuracy: 0.991 test_loss: 0.096 test_accuracy: 0.744
epoch: 7 loss: 0.001 accuracy: 0.996 test_loss: 0.108 test_accuracy: 0.742
epoch: 8 loss: 0.001 accuracy: 0.994 test_loss: 0.12 test_accuracy: 0.744
epoch: 9 loss: 0.001 accuracy: 0.994 test_loss: 0.128 test_accuracy: 0.74相关文章:
【深度学习】- NLP系列文章之 1.文本表示以及mlp来处理分类问题
系列文章目录 1. 文本分类与词嵌入表示,mlp来处理分类问题 2. RNN、LSTM、GRU三种方式处理文本分类问题 3. 评论情绪分类 还是得开个坑,最近搞论文,使用lstm做的ssd的cache prefetching,意味着我不能再划水了。 文章目录 系列文章…...

力扣236 补9.14
做不来,我做中等题基本上都是没有思路,这里需要先遍历祖先节点,那必然用先序遍历,这题还是官方题解容易理解,第二火的题解反而把我弄得脑袋昏昏的。 class Solution { TreeNode ans; public TreeNode lowestCommonAnce…...

一文搞定Postman(菜鸟必看)
什么是Postman? Postman是一个可扩展的 API 测试工具,可以快速集成到 CI/CD 管道中。它于 2012 年作为 Abhinav Asthana 的一个副项目启动,旨在简化测试和开发中的 API 工作流程。API 代表应用程序编程接口,它允许软件应用程序通…...

位图+布隆过滤器+海量数据并查集(它们都是哈希的应用)
一)位图: 首先计算一下存储一下10亿个整形数据,需要多大内存呢,多少个G呢? 2^3010亿,10亿个字节 byte kb mb gb 100000000个字节/1024/1024/10241G 所以10亿个字节就是1G,所以40亿个字节就是4G,也就是10个整…...

MYSQL:Select语句顺序
SELECT子句及其顺序整理表格: 子句 说明是否必须使用SELECT 要返回的列或表达式是FROM 从中检索数据的表仅在从表选择数据使用WHERE 行级过滤否GROUP BY 分组说明仅在按组计算聚…...
Pytest系列-数据驱动@pytest.mark.parametrize(7)
简介 unittest 和 pytest参数化对比: pytest与unittest的一个重要区别就是参数化,unittest框架使用的第三方库ddt来参数化的 而pytest框架: 前置/后置处理函数fixture,它有个参数params专门与request结合使用来传递参数&#x…...

【Qt】QGroundControl入门2:下载、编译、错误处理、运行
1、源码下载 git clone https://github.com/mavlink/qgroundcontrol.git 2、下载依赖库 2.1 查看依赖库的github路径 cat .gitmodules[submodule "src/GPS/Drivers"]path = src/GPS/Driversurl = https://github.com/PX4/GpsDrivers.git [submodule "libs/m…...
【深度学习】Pytorch 系列教程(十):PyTorch数据结构:2、张量操作(Tensor Operations):(4)索引和切片详解
目录 一、前言 二、实验环境 三、PyTorch数据结构 0、分类 1、张量(Tensor) 2、张量操作(Tensor Operations) 1. 数学运算 2. 统计计算 3. 张量变形 4. 索引和切片 使用索引访问单个元素 使用切片访问子集 使用索引和…...
)
2024字节跳动校招面试真题汇总及其解答(三)
6.jwt与cookie区别 JWT 和 Cookie 都是用于在客户端和服务器之间传输信息的常用方法。但是,它们之间存在一些关键差异。 JWT 是 JSON Web Token 的缩写,它是一种基于 JSON 的加密令牌。JWT 由三部分组成:Header、Payload 和 Signature。Header 包含令牌的类型、加密算法和…...

基于springboot+vue的便利店信息管理系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...
在ubuntu18.04上编译C++版本jsoncpp/opencv/onnxruntime且如何配置CMakelist把他们用起来~
这篇文章背景是笔者在ubuntu上编译C代码,依赖一些包,然后需要编译并配置到CMakelist做的笔记。主要也是一直不太懂CMakellist,做个笔记以防忘记,也给读者提供一站式的参考,可能您需要的不是这几个包,但大同…...

大二上学期学习计划
这个学期主要学习的技术有SpringBoot,Vue,MybatisPlus,redis,还有要坚持刷题,算法不能落下,要坚持一天至少刷2道题目,如果没有布置任务就刷洛谷上面的,有任务的话就尽量完成任务&…...

【python爬虫—星巴克产品】
文章目录 需求爬取星巴克产品以及图片,星巴克菜单 python爬虫爬取结果 需求 爬取星巴克产品以及图片,星巴克菜单 网页分析: 首先,需要分析星巴克官方网站的结构,了解菜单栏的位置、布局以及菜单项的标签或类名等信息…...

shell SQL 变量 Oracle shell调用SQL操作DB
注意 : v\\\$ 用法, “v\\\$session ” ""不能用 sqlplus -S / as sysdba << EOF set pagesize 0 set verify off set feedback off set echo off col coun new_value v_coun select count(*) coun from dual; EOF value"$?"VALUE…...
【校招VIP】java线程池考点之核心线程数
考点介绍: 线程池是这一两年java大厂提问频度飙升的考点,需要从池子的概念理解相关参数和方法 java线程池考点之核心线程数-相关题目及解析内容可点击文章末尾链接查看! 一、考点试题 1、请列举一下启动线程有哪几种方式,之后再…...

[每周一更]-(第61期):Rust入门策略(持续更新)
一门语言的学习,就要从最基本的语法开始认识,再分析不同语言的区别,再加上实战,才能更快的学会,领悟到作者的设计思想; 介绍 Rust编程练习 开发工具VSCode及插件 社区驱动的 rust-analyzerEven Better T…...

线程安全问题的原因及解决方案
要想知道线程安全问题的原因及解决方案,首先得知道什么是线程安全,想给出一个线程安全的确切定义是复杂的,但我们可以这样认为:如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该的结果,…...
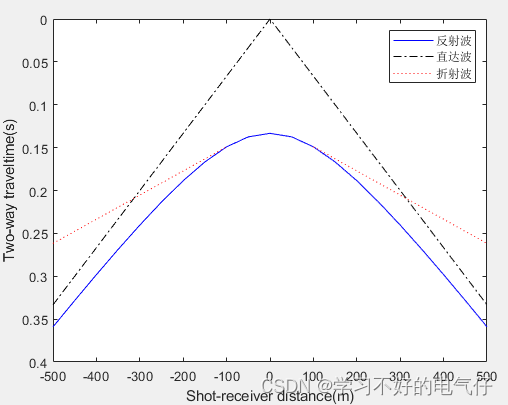
基于matlab中点放炮各类地震波时距曲线程序
完整程序: clear all dx50;x-500:dx:500;%炮检距 h100;V11500; theta25*pi/180; V2V1/sin(theta); t1sqrt(x.*x4*h*h)/V1;%反射波时距曲线 t2abs(x)./V1;%直达波时距曲线 %折射波时距曲线 xm2*h*tan(theta);%求盲区 k1; for i1:length(x) if x(i)<-xm …...

vue中el-dialog 中的内容没有预先加载,因此无法获得内部元素的ref 的解决方案 使用强制提前加载dialog方法
问题描述 在没有进行任何操作的时候,使用 this.$refs.xxxx 无法获取el-dialog中的内部元素,这个问题会导致很多bug,其中目前网络上也有许多关于这个问题的解决方案,但是大多数是使用el-dialog中的open在dialog打开的时候使用thi…...

vue-h5移动Web的rem配置
H5移动的适配方案 rem rem适配方案是兼容性比较好的移动端适配方案,rem支持大部分的移动端系统和机型。 rem是相对于根元素的字体大小的单位。本质上就是一个相对单位,和em的区别是:em是依赖父元素的字体来计算,rem是依赖根元素…...

基于 4SAPI 的 API 网关智能监控与故障诊断系统:MTTR 降低 90%,系统可用性提升至 99.99%
前言 在微服务架构盛行的今天,API 网关已经成为企业系统的核心入口,承担着流量路由、负载均衡、认证授权、限流熔断等关键功能。API 网关的稳定性直接决定了整个系统的可用性。但传统的 API 网关监控模式已经难以满足现代企业的需求: 告警风…...
)
避坑指南:海康威视工业相机SDK二次开发常见问题排查(从环境配置到图像采集)
海康威视工业相机SDK开发实战:从环境搭建到图像处理的深度避坑指南 工业视觉领域的开发者们,是否曾在深夜调试海康威视相机SDK时,被突如其来的"DLL缺失"错误打断思路?或是明明按照文档配置了项目属性,却始终…...
)
手把手教你ClickHouse(二、Windows下Docker部署与可视化实战)
1. Windows下Docker环境准备 在开始部署ClickHouse之前,我们需要先确保Windows系统已经正确配置Docker环境。这里我推荐使用Docker Desktop for Windows,它提供了图形化界面和完整的容器管理功能。安装过程可能会遇到几个常见坑点,我把自己实…...

观察不同时段通过Taotoken调用大模型的延迟稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同时段通过Taotoken调用大模型的延迟稳定性表现 在项目开发与线上服务中,API调用的响应延迟是影响开发者体验和系…...

期末课程论文不用卷!虎贲等考 AI:真文献 + 规范稿,轻松高效拿高分
一到期末、结课、学分冲刺阶段,课程论文就成了大学生最集中的压力点。选题不会定、框架搭不起来、文献找不到、内容写得太空、格式一塌糊涂、查重还容易超标…… 随便一项都能让原本简单的作业变得耗时又费力。 很多同学用通用 AI 凑字数,结果文献假、逻…...

AI智能体通过MCP协议连接Figma:实现设计稿自动化操作与代码生成
1. 项目概述:当AI智能体学会“看”设计稿最近在折腾一个挺有意思的东西:让AI智能体(比如Cursor、Claude Code)能直接和Figma对话。听起来有点科幻?其实原理不复杂,就是通过一个叫Model Context Protocol&am…...

基于 JiuwenClaw AgentTeam 集群模式的年会策划实战:从源码部署到多智能体协作落地
目录 摘要 一、引言:JiuwenClaw AgentTeam 让复杂任务迎刃而解 1.1 为什么选择年会策划作为 AgentTeam 实战场景 1.2 本文实战目标 二、JiuwenClaw 概述 2.1 JiuwenClaw 的核心特性 2.2 JiuwenClaw 的系统架构 2.3 JiuwenClaw 的三种运行模式 2.3.1 规划模…...

Meta发布最大视觉模型:DSG架构如何重构视觉理解范式
1. 项目概述:这不是一次普通更新,而是一次视觉理解边界的重写“Meta Just Updated the Largest Computer Vision Model in History”——这个标题乍看像科技媒体的快讯标题,但如果你在CV领域摸爬滚打过几年,第一反应不是点开链接&…...

喜马拉雅VIP音频下载指南:xmly-downloader-qt5完整解决方案
喜马拉雅VIP音频下载指南:xmly-downloader-qt5完整解决方案 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 你是否曾为…...

中小团队如何利用 Taotoken 统一管理多个大模型 API 调用与成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小团队如何利用 Taotoken 统一管理多个大模型 API 调用与成本 对于需要同时调用多种 AI 模型的中小开发团队而言,技术…...