深入探索智能问答:从检索到生成的技术之旅
目录
- 一、智能问答概述
- 1. **语义理解**
- 2. **知识库和数据库**
- 3. **上下文感知**
- 4. **动态学习和自适应**
- 二、发展历程
- 1. **基于规则的系统**
- 2. **统计方法的兴起**
- 3. **深度学习和神经网络的突破**
- 4. **预训练模型**
- 三、智能问答系统的主要类型
- 四、基于知识库的问答系统
- 五、基于检索的问答系统
- 六、基于对话的问答系统
- 七、基于生成的问答系统
- 八、总结
在本文中,我们深入探讨了自然语言处理中的智能问答系统,从其发展历程、主要类型到不同的技术实现。文章详细解析了从基于检索、对话到基于生成的问答系统,展示了其工作原理和具体实现。通过对技术和应用的深度剖析,旨在帮助读者对这一令人兴奋的领域有更全面的认识。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、智能问答概述
智能问答 (Intelligent Question Answering, IQA) 是自然语言处理(NLP)中的一个核心子领域,旨在设计和开发可以解析、理解并回答用户提出的自然语言问题的系统。这些系统的目标不仅仅是返回与问题相关的文本,而是提供精确、凝练且直接的答案。

1. 语义理解
智能问答系统的核心组件之一是语义理解,即系统需要深入地理解用户提问的意图和背后的意义。
例子:当用户问:“金星是太阳系的第几颗行星?”而不是简单地返回与“金星”和“太阳系”相关的一段文本,系统应理解用户的真正意图并回答:“金星是太阳系的第二颗行星。”
2. 知识库和数据库
为了回答问题,智能问答系统通常需要访问大型的知识库或数据库,这些知识库包含了大量的事实、数据和信息。
例子:当用户询问:“苹果公司的创始人是谁?”系统会查询其知识库,并返回:“苹果公司的创始人是史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩。”
3. 上下文感知
高级的智能问答系统可以感知上下文,这意味着它们可以根据前面的对话或提问为用户提供更相关的答案。
例子:如果用户首先问:“巴黎位于哪个国家?”得到答案后,又问:“那里的官方语言是什么?”系统应该能够识别出“那里”指的是“巴黎”,并回答:“官方语言是法语。”
4. 动态学习和自适应
随着时间的推移,优秀的智能问答系统能够从用户的互动中学习,并改进其回答策略和准确性。
例子:如果一个系统频繁地收到关于某一新闻事件的问题,并且用户对其回答表示满意,系统应该能够识别这一事件的重要性,并在未来的查询中更加重视与之相关的信息。
二、发展历程

智能问答的历史是自然语言处理和计算机科学发展史的一个缩影。从最初的基于规则的系统到现在的深度学习模型,它不断地推动技术界前进,试图更好地理解和回应人类语言。
1. 基于规则的系统
在20世纪60、70年代,早期的问答系统主要依赖于硬编码的规则和固定的模式匹配。这些系统是基于人类定义的明确规则来识别问题并提供答案。
例子:一个基于规则的系统可能有一个简单的查找表,当用户询问“日本的首都是什么?”时,它会匹配“首都”和“日本”的关键词,然后返回存储的答案“东京”。
2. 统计方法的兴起
随着大数据和计算能力的增长,90年代和21世纪初,研究人员开始使用统计方法来改进问答系统。这些方法通常基于从大量文本中提取的概率来预测答案。
例子:当用户询问“谁写了《哈利·波特》?”系统会搜索大量的文档,统计与“哈利·波特”和“作者”相关的句子,最后确定“J.K.罗琳”是最可能的答案。
3. 深度学习和神经网络的突破
近十年来,随着深度学习技术的突破,问答系统得到了质的飞跃。神经网络,尤其是循环神经网络(RNN)和Transformer架构,使得模型可以处理复杂的语义结构和长距离依赖。
例子:BERT模型可以处理复杂的问题,如:“《安徒生童话》中描述的‘皇帝的新装’的寓意是什么?”BERT可以深入分析文本内容,识别出该故事是关于虚荣和盲目从众的。
4. 预训练模型
近年来,预训练模型如GPT-4、GPT-3.5、T5和XLNet等,已经在各种NLP任务上取得了前所未有的成果。这些模型首先在大量文本上进行预训练,然后可以通过迁移学习快速地适应特定的任务,如智能问答。
例子:使用GPT-4,当用户提出抽象问题,如:“人生的意义是什么?”GPT-3可以返回哲学、文学和各种文化背景下的多个观点,提供深入而全面的回答。
三、智能问答系统的主要类型

智能问答系统因应用场景、数据源和技术手段的不同而存在多种类型。以下是其中的一些主要类型及其特点:
-
基于知识库的问答系统:
-
依赖预定义的知识库来检索答案。
-
需要大量的知识工程师来维护和更新知识库。
-
在特定领域(如医学、法律)中表现较好,因为它们可以提供准确的、基于事实的答案。
例子:医学问答系统可能有一个知识库,其中包含各种疾病、症状和治疗方法的信息。
-
-
基于检索的问答系统:
-
从大量文本数据中检索与问题相关的片段。
-
依赖高效的信息检索技术。
-
能够处理开放领域的问题,但答案的准确性可能受限于数据源的质量。
例子:当用户询问某个历史事件的详细情况时,系统会从互联网上检索相关文章或百科全书来提供答案。
-
-
基于对话的问答系统:
-
与用户进行多轮对话,以便更好地理解其问题。
-
可以处理复杂和上下文依赖的问题。
-
通常依赖深度学习和上下文感知的模型。
例子:当用户问:“你知道巴黎吗?”系统回答:“当然,你想知道巴黎的哪方面信息?”用户继续:“它的历史建筑。”系统再进行具体的答复。
-
-
基于生成的问答系统:
-
不是从固定的数据源检索答案,而是实时生成答案。
-
通常使用神经网络,如序列到序列模型。
-
可以提供个性化和创造性的答案,但可能缺乏事实上的准确性。
例子:当用户询问:“如果莎士比亚是现代人,他会怎么评价智能手机?”系统可能生成一个富有创意的答案,尽管这不是基于真实事实的答案。
-
四、基于知识库的问答系统
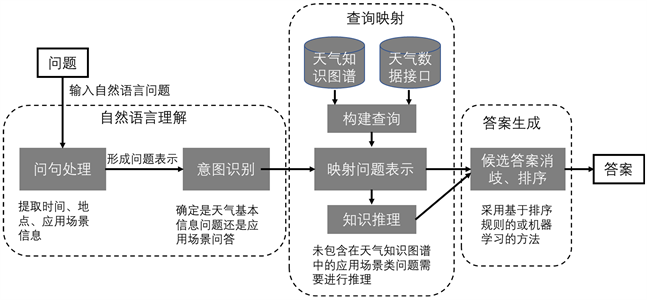
基于知识库的问答系统是一种专为解答基于事实和数据的问题而设计的系统。它们依赖于预定义的知识库,这些知识库通常包含大量的事实、关系和其他结构化信息。
定义:基于知识库的问答系统主要依赖于一个结构化的知识库,将用户的问题映射到知识库中的相关实体和关系,从而找到或生成答案。
例子:考虑一个知识库,其中包含关于国家、首都和地理位置的信息。对于问题“巴西的首都是什么?”,系统查询知识库并返回“巴西利亚”。
一个简单的基于知识库的问答系统实现如下:
# 定义简单的知识库
knowledge_base = {'巴西': {'首都': '巴西利亚', '语言': '葡萄牙语'},'法国': {'首都': '巴黎', '语言': '法语'},# 更多的条目...
}def knowledge_base_qa_system(question):# 简单的字符串解析来提取实体和属性(真实系统会使用更复杂的NLP技术)for country, attributes in knowledge_base.items():if country in question:for attribute, answer in attributes.items():if attribute in question:return answerreturn "我不知道答案。"# 测试问答系统
question = "巴西的首都是什么?"
print(knowledge_base_qa_system(question)) # 输出:巴西利亚
在这个简单示例中,我们定义了一个知识库,其中包含一些国家及其属性(如首都和官方语言)。问答系统通过简单地解析问题字符串来查询知识库并找到答案。实际上,真实的基于知识库的问答系统会使用更复杂的自然语言处理和知识图谱查询技术来解析问题和查找答案。
五、基于检索的问答系统
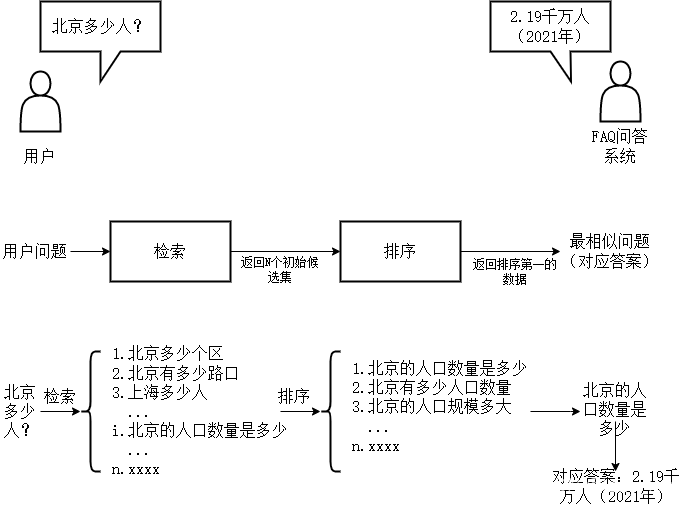
基于检索的问答系统是指根据用户问题的语义信息,从一个预先存在的大型文档或FAQ集中检索并返回最相关的答案。与基于知识库的问答系统不同,基于检索的系统不依赖于结构化数据,而是依赖于大量的文本数据。
定义:基于检索的问答系统使用语义搜索技术,对用户的问题和数据集中的问题进行比较,从而找到最匹配的答案。
例子:在一个包含医学文献的数据集中,对于问题“怎样预防流感?”,系统可能会返回一个相关医学研究中的段落,如“接种流感疫苗是预防流感的最有效方法。”
下面是一个简单的基于检索的问答系统的实现:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity# 定义一个简单的文档集合
documents = ["接种流感疫苗是预防流感的最有效方法。","猫是可爱的宠物。","巴黎是法国的首都。",# 更多文档...
]vectorizer = TfidfVectorizer()
document_vectors = vectorizer.fit_transform(documents)def retrieval_based_qa_system(question):question_vector = vectorizer.transform([question])similarities = cosine_similarity(question_vector, document_vectors)best_match = documents[similarities.argmax()]return best_match# 测试问答系统
question = "如何避免得流感?"
print(retrieval_based_qa_system(question)) # 输出:接种流感疫苗是预防流感的最有效方法。
在这个简化的示例中,我们首先使用TF-IDF方法将文档转换为向量。当接收到一个问题时,我们同样将其转换为向量并使用余弦相似度来确定哪个文档与问题最为相似。然后返回最匹配的文档作为答案。
实际应用中,基于检索的问答系统可能会采用更复杂的深度学习模型、BERT等预训练模型来提高检索的准确性。
六、基于对话的问答系统
基于对话的问答系统不仅仅回答单一的问题,而是能与用户进行持续的交互,理解并维护对话上下文,从而为用户提供更加准确和个性化的答案。
定义:基于对话的问答系统是一种可以处理多轮对话、维护和利用对话上下文的系统,从而在与用户交互时提供更有深度和持续性的回答。
例子:用户可能会问:“推荐一部好看的电影。”系统回答:“你喜欢哪种类型的电影?”用户回答:“我喜欢科幻。”系统随后推荐:“那你可能会喜欢《星际穿越》。”
以下是一个简单的基于对话的问答系统的实现:
import random# 对话上下文和推荐数据
context = {'genre': None
}
recommendations = {'科幻': ['星际穿越', '银河系漫游指南', '阿凡达'],'爱情': ['泰坦尼克号', '爱情公寓', '罗马假日'],# 更多类别...
}def dialog_based_qa_system(question):if "推荐" in question and "电影" in question:return "你喜欢哪种类型的电影?", contextif context.get('genre') is None:for genre, movies in recommendations.items():if genre in question:context['genre'] = genrereturn f"那你可能会喜欢{random.choice(movies)}。", contextreturn "对不起,我不确定如何回答。", context# 测试问答系统
question1 = "推荐一部好看的电影。"
response1, updated_context = dialog_based_qa_system(question1)
print(response1) # 输出:你喜欢哪种类型的电影?question2 = "我喜欢科幻。"
response2, updated_context = dialog_based_qa_system(question2)
print(response2) # 输出:那你可能会喜欢星际穿越。
这是一个非常简化的例子。在这里,我们使用一个简单的上下文字典来跟踪对话中的状态。实际应用中,基于对话的问答系统可能会使用RNN、Transformer或其他深度学习架构来维护和利用对话上下文。此外,更高级的系统还可能包括情感分析、个性化推荐等特性。
七、基于生成的问答系统
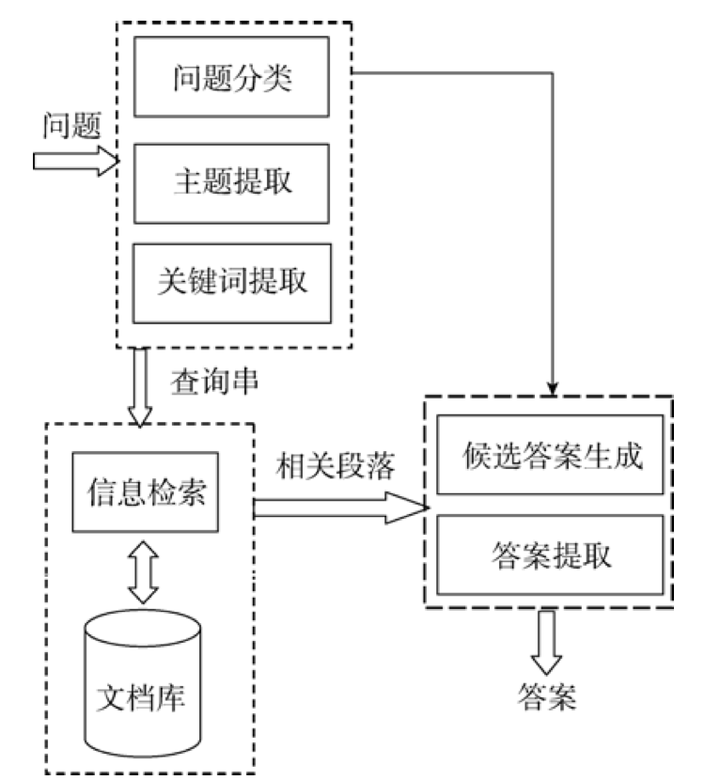
与基于检索或对话的问答系统不同,基于生成的问答系统的目标是生成全新的答案文本,而不是从预先定义的答案集或文档中选择答案。这些系统通常使用深度学习模型,特别是序列到序列(seq2seq)模型。
定义:基于生成的问答系统使用深度学习技术(如RNN、LSTM或Transformer)从头开始生成答案,而不是从现有文档或数据库中检索答案。
例子:当问到“太阳是什么?”时,系统可能会生成答案“太阳是一个主序星,位于我们的太阳系中心,它通过核聚变产生能量。”
下面是一个简化的基于PyTorch的生成问答系统的示例:
import torch
import torch.nn as nn
import torch.optim as optim# 假设我们有一个预训练的seq2seq模型
class Seq2SeqModel(nn.Module):def __init__(self):super(Seq2SeqModel, self).__init__()# ... 模型定义(如编码器、解码器等)def forward(self, input):# ... 前向传播passmodel = Seq2SeqModel()
model.load_state_dict(torch.load("pretrained_seq2seq_model.pth"))
model.eval()def generate_based_qa_system(question):question_tensor = torch.tensor(question) # 将问题转化为张量with torch.no_grad():generated_answer = model(question_tensor)return generated_answer# 测试问答系统
question = "太阳是什么?"
print(generate_based_qa_system(question))
这只是一个高级的框架,实际的生成问答系统会涉及许多其他复杂性,包括词嵌入、注意机制、解码策略等。实际的seq2seq模型实现也要复杂得多。使用如BERT、GPT-2或T5等预训练模型可以进一步提高生成问答系统的性能。
八、总结
经过深入的探索和技术解析,我们对自然语言处理中的智能问答系统有了更加深入的了解。从简单的基于检索的问答系统,到能与用户进行复杂多轮对话的对话系统,再到具备生成全新答案能力的生成式问答系统,我们目睹了问答技术的迅猛发展和应用广泛性。
然而,背后的技术进步并不仅仅是算法的改进或计算能力的增强。关键在于,随着大量数据的积累和开放,我们的机器学习模型得以在更加真实和多样的数据上进行训练。这也反映了一个核心原则:真实世界的多样性和复杂性是无法通过简单规则来完全捕获的。只有当我们的模型能够在真实的、多样的数据上进行学习,它们才能更好地为我们服务。
但我们也需要意识到,无论技术如何进步,真正的挑战并非仅仅在于如何构建一个更高效或更准确的问答系统。更为根本的挑战在于,如何确保我们的技术在为人类提供帮助的同时,也能够尊重用户的隐私、确保信息的真实性并避免偏见。在AI的发展中,技术和伦理应该并行发展。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
深入探索智能问答:从检索到生成的技术之旅
目录 一、智能问答概述1. **语义理解**2. **知识库和数据库**3. **上下文感知**4. **动态学习和自适应** 二、发展历程1. **基于规则的系统**2. **统计方法的兴起**3. **深度学习和神经网络的突破**4. **预训练模型** 三、智能问答系统的主要类型四、基于知识库的问答系统五、基…...

02_Flutter自定义Sliver组件实现分组列表吸顶效果
02_Flutter自定义Sliver组件实现分组列表吸顶效果 一.先上效果图 二.列表布局实现 比较简单,直接上代码,主要使用CustomScrollView和SliverToBoxAdapter实现 _buildSection(String title) {return SliverToBoxAdapter(child: RepaintBoundary(child: C…...

uniapp实现大气质量指标图(app端小程序端均支持,app-nvue不支持画布)
效果图如下: 思路: 1.首先我想到的就是使用图标库echarts或ucharts,可是找了找没有找到类似的。 2.其次我就想用画布来实现这个效果,直接上手。(app-vue和小程序均可以实现,但是在app-nvue页面不支持画布…...
Oracle for Windows安装和配置——2.1.Oracle for Windows安装
2.1.1. 准备Oracle软件 1)下载或拷贝安装软件 下载地址:otn.oracle.com或my oracle support。下载文件列表。具体如图2.1.1-1所示。 图2.1.1-1 下载文件列表 --说明: 1)通过otn.oracle.com站点,可以免费下载用于安装的Oracle…...

2.SpringEL bean引用实例
SpringEL bean引用实例 文章目录 SpringEL bean引用实例介绍Spring EL以注解的形式Spring EL以XML的形式 介绍 在Spring EL,可以使用点(.)符号嵌套属性参考一个bean。例如,“bean.property_name” public class Customer {Value("#{addressBean.c…...

通用商城项目(下)之——Nginx的安装及使用
(作为通用商城项目的一个部分,单独抽离了出来。查看完整见父页面: ) 加入Nginx-完成反向代理、负载均衡和动静分离 1.配置SSH-使用账号密码,远程登录Linux 1.1配置实现 1、配置sshd 1)sudo vi /etc/ssh/sshd_confi…...
滑动时间窗口的思想和实现,环形数组,golang
固定时间窗口 在开发限流组件的时候,我们需要统计一个时间区间内的请求数,比如以分钟为单位。所谓固定时间窗口,就是根据时间函数得到当前请求落在哪个分钟之内,我们在统计的时候只关注当前分钟之内的数量,即 [0s, 60…...

SpringBoot 使用异步方法
SpringBoot 使用异步方法 在pom文件引入相关依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframe…...

Django框架学习大纲
对于使用 Python 的 Django 框架进行 web 开发的程序员来说,以下几点是必须了解的。 环境配置与项目初始化 命令: pip install django django-admin startproject myproject解析: 使用 pip 安装 Django。使用 django-admin startproject …...
基于matlab实现的电力系统稳定性分析摆幅曲线代码
完整程序: clear; clc; t 0; tf 0; tfl 0.5; tc 0.5; % tc 0.05, 0.125, 0.5 sec for 2.5 cycles, 6.25 cycles & 25 cycles resp ts 0.05; m 2.52 / (180 * 50); i 2; dt 21.64 * pi / 180; ddt 0; time(1) 0; ang(1) 21.64; pm 0.9; pm1 2.44;…...
mybatis基本构成mybatis与hibernate的区别添加mybatis支持
目录 1. mybatis简介 2. mybatis基本构成 3. mybatis与hibernate的区别 4. 项目中添加mybatis支持 1. mybatis简介 Mybatis是Apache的一个Java开源项目,是一个支持动态Sql语句的持久层框架。Mybatis可以将Sql语句配置在XML文件中,避免将Sql语句硬编…...

c++23中的新功能之十四输入输出指针
一、介绍 在c的发展过程中,无论如何发展,c都尽量保持着与C语言的兼容,当然这也是它的一个特点。在实际的应用中,开发者经常遇到的一个问题是,如何把一个指针的值给传出来?有人会说,简单啊&…...
Day42:网易云项目,路由进阶
网易云项目 创建、启动项目并配置路由 npm init vite npm i npm i vue-router npm i sass -D 在main.js中 import router from ./router createApp(App).use(router).mount(#app) 在index中配置路由 import {createRouter,createWebHistory} from vue-router import H…...

Open3D(C++) 三维点云边界提取
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、算法原理 见:PCL 点云边界提取 二、代码实现 BoundaryEstimation.h #pragma...

AUTOSAR汽车电子嵌入式编程精讲300篇-经典 AUTOSAR 安全防御能力的分析及改善
目录 前言 研究现状 经典 AUTOSAR 概述 2.1 经典 AUTOSAR 架构 2.2 经典 AUTOSAR 应用层...
LeetCode 1584. 连接所有点的最小费用【最小生成树】
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

超简单,几行js代码就实现一个 vue3 的数字滚动效果!
预览效果 1. 创建一个template <template><div class"num-warp"><template v-for"item in numStr"><div v-if"item ," class"dot">,</div><divv-elseclass"num-box":style"{transf…...
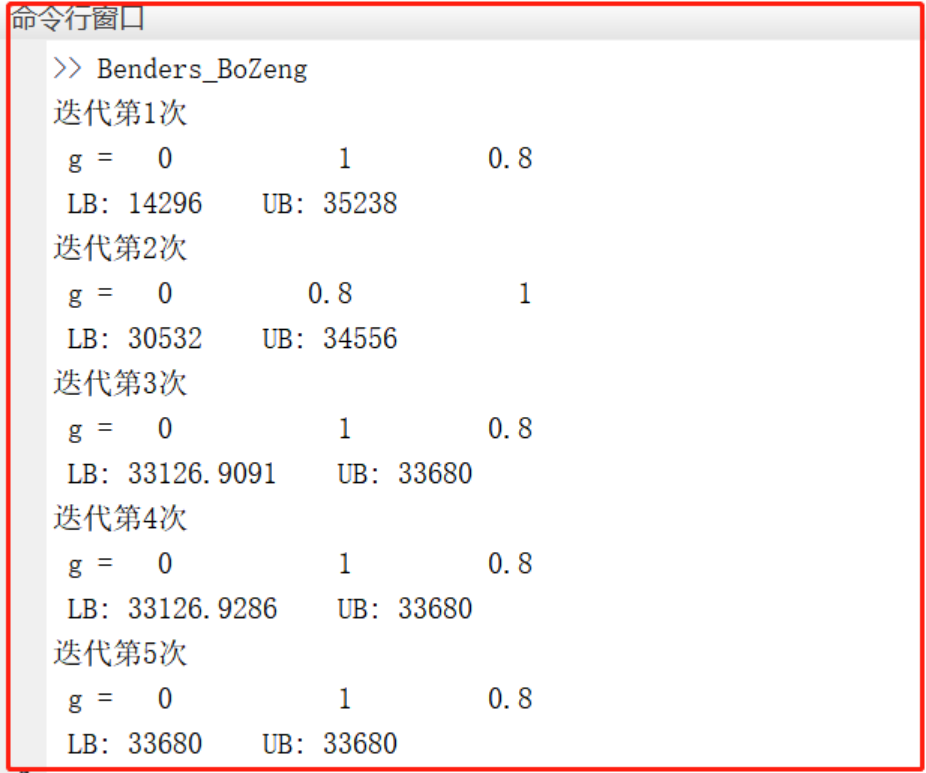
两阶段鲁棒优化matlab实现——CCG和benders
目录 1 主要内容 2 部分代码 3 程序结果 4 程序链接 1 主要内容 程序采用matlab复现经典论文《Solving two-stage robust optimization problems using a column-and-constraint generation method》算例,实现了C&CG和benders算法两部分内容,通过…...

二进制安全虚拟机Protostar靶场(4)写入shellcode,基础知识讲解 Stack Five
前言 这是一个系列文章,之前已经介绍过一些二进制安全的基础知识,这里就不过多重复提及,不熟悉的同学可以去看看我之前写的文章 二进制安全虚拟机Protostar靶场 安装,基础知识讲解,破解STACK ZERO https://blog.csdn.net/qq_45894840/artic…...
【Flink实战】玩转Flink里面核心的Source Operator实战
🚀 作者 :“大数据小禅” 🚀 文章简介 :【Flink实战】玩转Flink里面核心的Source Operator实战 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 目录导航 Flink 的API层级介绍Source Operator速览Flin…...
的研究者如何让AI记忆力翻倍)
香港科技大学(广州)的研究者如何让AI记忆力翻倍
这项由香港科技大学(广州)主导的研究成果发表于2026年第43届国际机器学习大会(ICML 2026),会议地点为韩国首尔,论文收录于PMLR第306卷。论文预印本编号为arXiv:2605.05838,有兴趣深入了解的读者…...

华为MateBook D 2018款升级Win11遇阻?手把手教你通过修改BIOS隐藏参数开启TPM2.0
华为MateBook D 2018款解锁Win11升级全攻略:深入BIOS底层参数调整实战 华为MateBook D系列作为商务本中的性价比代表,2018款用户近期在升级Windows 11时普遍遇到TPM 2.0无法启用的困扰。这台搭载第八代Intel处理器的设备其实完全具备TPM 2.0的硬件基础&a…...

面壁智能开源端侧多模态大模型MiniCPM-V 4.6,性能登顶同尺寸榜首,降低开发门槛
【导语:5月13日,面壁智能联合清华大学与OpenBMB开源社区,发布并开源新一代端侧多模态大模型MiniCPM-V 4.6。该模型以轻量级参数实现性能与效率突破,在评测中超越竞品,还降低了运行内存需求和计算成本,支持多…...

Windows系统美化终极指南:如何快速实现个性化定制与性能优化 [特殊字符]
Windows系统美化终极指南:如何快速实现个性化定制与性能优化 🚀 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and usability. 项目地址: https://gitcode.com/…...

终极开源解决方案:用Video-subtitle-extractor高效提取视频硬字幕的完整指南
终极开源解决方案:用Video-subtitle-extractor高效提取视频硬字幕的完整指南 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含…...

Cangaroo:开源CAN总线分析软件架构解析与深度优化指南
Cangaroo:开源CAN总线分析软件架构解析与深度优化指南 【免费下载链接】cangaroo Open source can bus analyzer software - with support for CANable / CANable2, CANFD, and other new features 项目地址: https://gitcode.com/gh_mirrors/ca/cangaroo Ca…...
OpenMMLab MMTracking 目标跟踪算法库
MMTracking是OpenMMLab(商汤科技与港中文MMLab联合推出)体系下的一款开源视频目标感知工具箱。你可以把它理解为“视频版”的MMDetection,它将该领域内纷繁复杂的算法、数据集和评估标准,统一整合到了一个高效、模块化的框架中。 …...

UWB车内目标探测技术【附仿真】
✨ 长期致力于UWB雷达、活体、目标检测、生命体征、信号模型研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)UWB雷达生命体征信号建模与自适应杂波抑制…...
)
基于Java的私人牙科诊所管理系统(10008)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

Keil 5 Debug隐藏技巧:手把手教你配置软件仿真,避开‘no read permission’等常见报错
Keil 5 Debug高阶实战:从软件仿真配置到逻辑分析仪深度应用 在嵌入式开发领域,Keil MDK作为ARM架构的主流开发环境,其Debug功能尤其是软件仿真模块往往被开发者低估。许多工程师仅停留在基础调试层面,对逻辑分析仪等高级功能要么望…...